

В PostgreSQL и многих других СУБД для обеспечения согласованности данных при одновременной работе нескольких пользователей используется метод многоверсионного параллельного контроля (MVCC). MVCC создает снимок базы для каждой транзакции, позволяя параллельным операциям видеть согласованное состояние данных.
Хотя PostgreSQL обеспечивает строгую согласованность (все транзакции видят последовательное и правильное состояние данных), клиенты могут воспринимать базу как согласованную в конечном счете. Это приводит к недоразумениям при выводе данных на фронтенде – порядок записей может меняться при последующих запросах. Это происходит из-за того, как MVCC обрабатывает параллельные транзакции и как клиент видит результаты этих транзакций:
- Когда несколько транзакций выполняются одновременно, они могут завершаться в непредсказуемом порядке.
- Клиент, делающий последовательные запросы, может видеть результаты этих транзакций в порядке их завершения, а не в порядке их начала.
Пример:
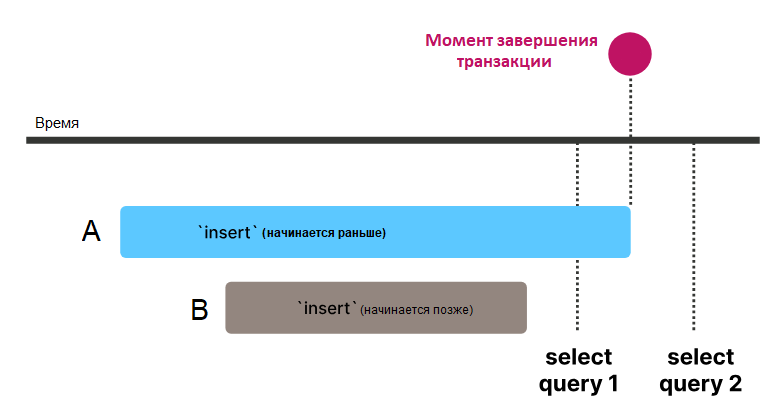
- Представьте, что два процесса (A и B) одновременно вставляют данные в таблицу.
- Процесс A начинается первым, но завершается позже процесса B.
- Клиент, делающий запрос сразу после завершения B, но до завершения A, увидит данные от B, но не от A.
- При повторном запросе после завершения обоих процессов клиент увидит данные и от A, и от B.
В результате клиент может пропустить некоторые записи или увидеть их в неожиданном порядке при попытке последовательно обработать все данные, например, при использовании курсорной пагинации. Но сама база данных при этом всегда находится в согласованном состоянии!
Чаще всего для решения этой проблемы используются два способа:
- Можно заставить процессы ждать своей очереди при добавлении данных – с помощью дополнительной таблицы для хранения последовательности и использования триггеров для установки значения последовательности при вставке записей. Этот метод гарантирует, что данные будут добавляться в определенном порядке, но может замедлить работу.
- Вместо изменения способа добавления данных можно изменить способ их чтения – то есть читать только те записи, которые точно завершили процесс добавления. Этот подход позволяет сохранить высокую производительность записи, но требует более сложной логики на стороне клиента для обработки потенциальных изменений порядка записей.
Автор этой публикации предлагает более оптимальное решение – с использованием рекомендательных блокировок. Этот метод позволяет приложению определять собственные семантики блокировок, которые система не соблюдает по умолчанию. Приложение должно самостоятельно управлять этими блокировками, учитывая их назначение и контекст использования. Решение работает так:
- Получение блокировки на уровне транзакции. Для каждой операции вставки в таблицу access_logs используется две рекомендательные блокировки. Первая блокировка (
pg_try_advisory_xact_lock_shared(1, 0)) указывает, что текущая сессия занимается операцией вставки в access_logs. Вторая блокировка (pg_try_advisory_xact_lock((select last_value + 1 from access_logs_seq))) устанавливает минимальное значение seq, которое будет использоваться в текущей транзакции. - Определение безопасного «потолка» для чтения. Для определения минимального значения seq среди всех активных транзакций используется запрос к таблице
pg_locks. Этот запрос позволяет найти минимальное значениеobjidдля блокировок сclassid=0, что соответствует второй блокировке, установленной при вставке. - Чтение данных с учетом предела. При чтении данных из таблицы
access_logsиспользуется полученное минимальное значениеseqв качестве верхнего предела для фильтрации записей.
Этот подход сохраняет высокую скорость записи и гарантирует, что читаемые данные будут согласованы и не будут включать записи, которые еще могут быть изменены другими транзакциями.
Как вы решаете проблемы с порядком транзакций в ваших приложениях на PostgreSQL? Поделитесь своим опытом и лучшими практиками.
Комментарии