

Текст публикуется в переводе, автор оригинальной статьи – Kenichi Nakanishi.
Глубже, лучше, быстрее, сильнее?
В статье "Создание базы данных изображений" мы прошерстили Сеть в поисках информации о растениях и о том, насколько они могут быть токсичными для домашних питомцев, установили перекрестные ссылки на вторую базу данных, а затем загрузили уникальные изображения для каждого класса.
Во второй статье, "Обучение с контролируемой случайностью", мы использовали фреймворк fast.ai для обучения нейронных сетей, чтобы идентифицировать вид растения по его картинке. Мы разработали способ введения случайности в набор данных с помощью пакетов NumPy, PyTorch и random, а также гибкие методы для разметки изображений как тренировочные или валидационные в разных проходах обучения. Это позволяет нам честно сравнить эффект от изменения других параметров нашего классификатора.
В третьей статье, "Нахождение и удаление плохих тренировочных данных" мы нашли неподходящие для обучения данные (например, неверно размеченные или плохие примеры своего класса), используя оптическое распознавание символов, анализ тонального распреления и исследование результатов обучения нейронных сетей на неочищенном наборе данных. Затем мы измеряли влияние их устранения на общую точность обученной сети, и обнаружили существенное улучшение точности после каждого шага очистки.
Теперь, когда у нас есть хороший набор данных, давайте сделаем следующий шаг и поиграем с несколькими архитектурами сверточных нейронных сетей, доступных на платформе fast.ai для обучения классификатора изображений.
Наша основная цель – исследование влияния архитектуры сверточных нейронных сетей на точность классификации изображений. Мы не станем пытаться оптимизировать каждый гиперпараметр для каждой архитектуры – вместо этого мы бросим быстрый взгляд на их особенности, детали реализации и результаты, не пытаясь добиться оптимальных результатов.
Заметьте, что все проходы обучения имеют следующие параметры, если не указано обратное:
- использовано 25% изображений, принадлежащих 517 классам. Меньшее количество изображений использовано для сокращения времени обучения.
- размер изображений равен 224 * 224 пикселям
- размер пакета (batch size) для обучения равен 64 изображениям.
- каждый раз использовался двухфазный протокол transfer learning, каждый раз используя fit_one_cycle: сначала выполняется 10 эпох обучения "головы" со скоростью lr=1e-02, а потом – еще 10 эпох дообучения всей сети с параметрами lr_max=slice(1e-5, 1e-4).
- использовался deterministic learner, включая фиксированное стратифицированное разделение на тренировочную и валидационную части.
- использовался алгоритм оптимизации Adam с параметрами mom=0.9, sqr_mom=0.99, eps=1e-05, wd=0.01, decouple_wd=True.
1. ResNet
Для хорошего старта мы рассмотрим один из важнейших прорывов в архитектуре CNN – ResNets.
1.1. Что такое ResNet?
ResNet'ы – это мощные глубокие нейронные сети, появившиеся на основании работ Кайминга Хе и пр. в 2015 и 2016, чьи прорывы позволили обучать сотни или даже тысячи слоев с хорошей производительностью. ResNet'ы достигли прекрасной общей производительности на задачах распознавания изображений, и быстро стала одной из самых популярных архитектур в различных задачах машинного зрения.
Решение проблемы исчезающих градиентов
До разработки ResNets, наращивание количества слоев для повышения глубины нейронной сети рано или поздно вызывало ограничение или даже быстрое ухудшение производительности сети. Это происходило из-за проблемы исчезающих градиентов, которая возникает из-за того, что множество функций активации (таких, как сигмоида) сокращают большое входное пространство до гораздо меньшего выходного (например, от 0 до 1 для сигмоиды). Поскольку большие изменения входа преобразуются в намного меньшие изменения выхода, производная, естественно, становится намного меньшей.
Это важно, поскольку цель повышения количества слоев, как правило, нахождение идеальных весов и порогов (обеспечивающих наилучшую производительность сети) с помощью последовательных прямых проходов, расчетов функции потерь и обратных распространений (backpropagations). Процесс обратного распространения находит производные всей сети, продвигаясь от последнего слоя к первому. Используя цепное правило вычисления производных, производные каждого слоя умножаются друг на друга, чтобы получить производные входных слоев. Это повторяющееся умножение может сделать производные бесконечно малыми, а это значит, что веса и пороги входных слоев не будут эффективно обновляться в каждой сессии обучения. Поскольку эти входные слои критически важны для распознавания ключевых элементов входных данных, это может привести к неточности всей сети.
ResNet: добавим входные данные к выходным, чтобы градиенты не исчезали так быстро.
Ключевая идея, лежащая за ResNet – это введение остаточных блоков (residual blocks), которые содержат "обходную связь идентичности" (identity shortcut connection), обходящую один или большее количество слоев.
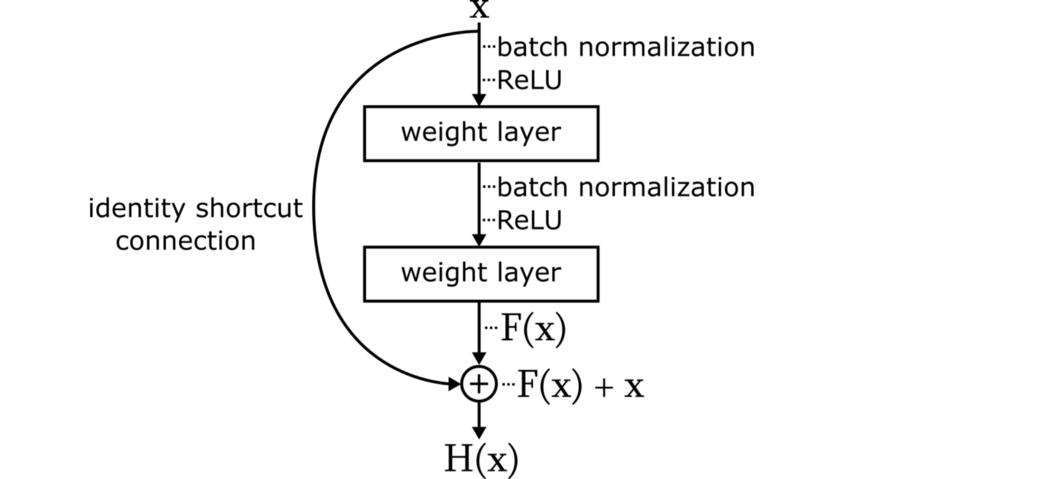
Этот остаточный блок изменяет цель набора слоев с обучения идеальных весов и порогов F(x) на обучение выхода остаточного блока H(x) = F(x) + x. Переставив члены этого уравнения, получим F(x) = H(x) – x, а это значит, что остаточный блок пытается обучать вход минус выход, иными словами остаточную функцию F(x) – отсюда и название "остаточный блок". Интуитивно, мы можем считать, что каждый блок теперь настраивает вывод предыдущего блока, и ему не приходится генерировать желаемый вывод с нуля.
Документ по ResNet эмпирически продемонстрировал, что оптимизация этих остаточных блоков была намного проще. Добавление обходных связей позволило распространить большие градиенты до исходных слоев, смягчая эффект проблемы исчезающих градиентов и улучшая точность глубоких остаточных сетей по сравнению с более поверхностными аналогами.
Нужно также отметить, что широкое использование пакетной нормализации (batch normalization) по всей структуре ResNet повышает стабильность сети, заново центрируя и масштабируя данные по мере их прохождения через сеть.
Строим ResNet'ы из ResBlock'ов
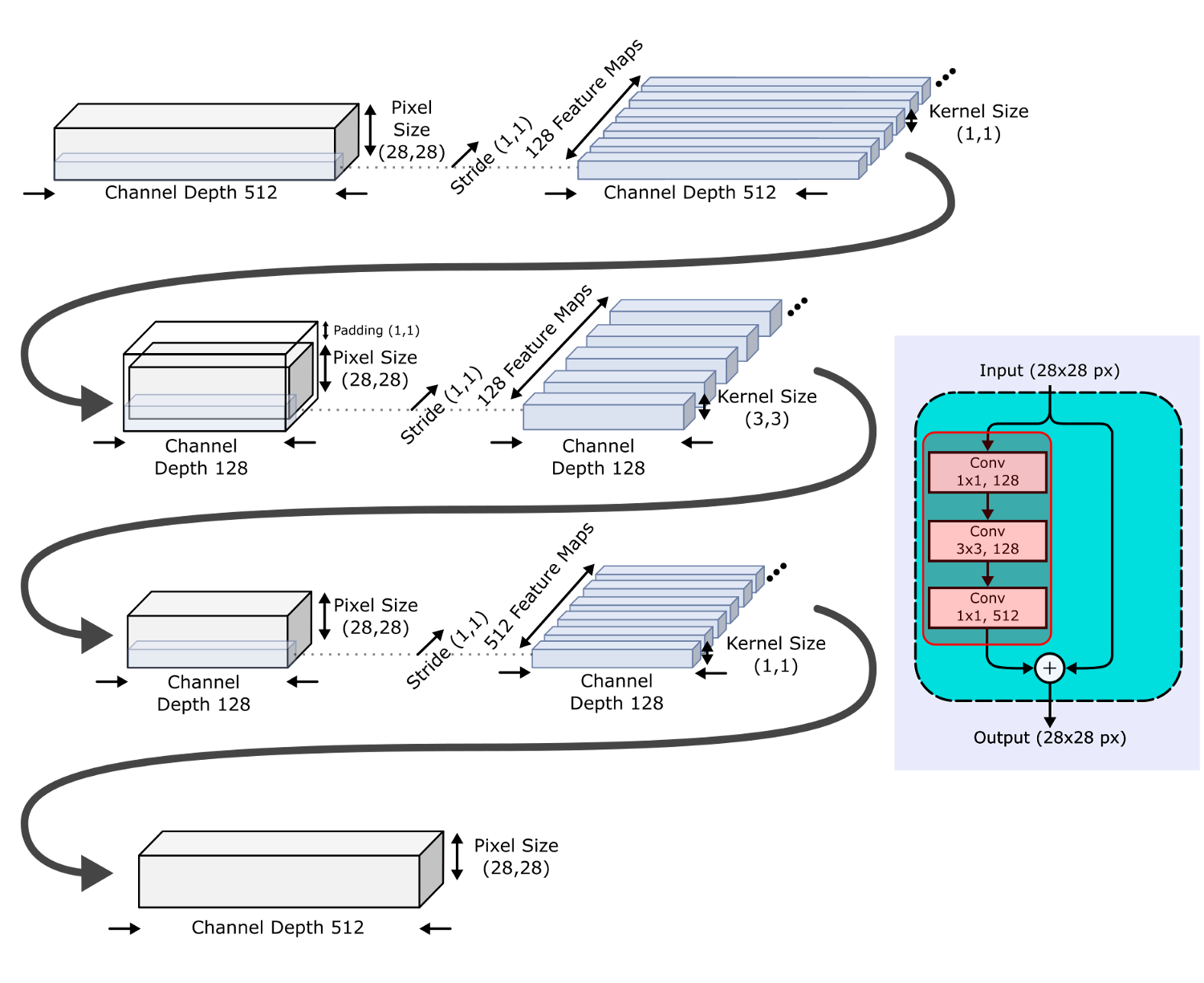
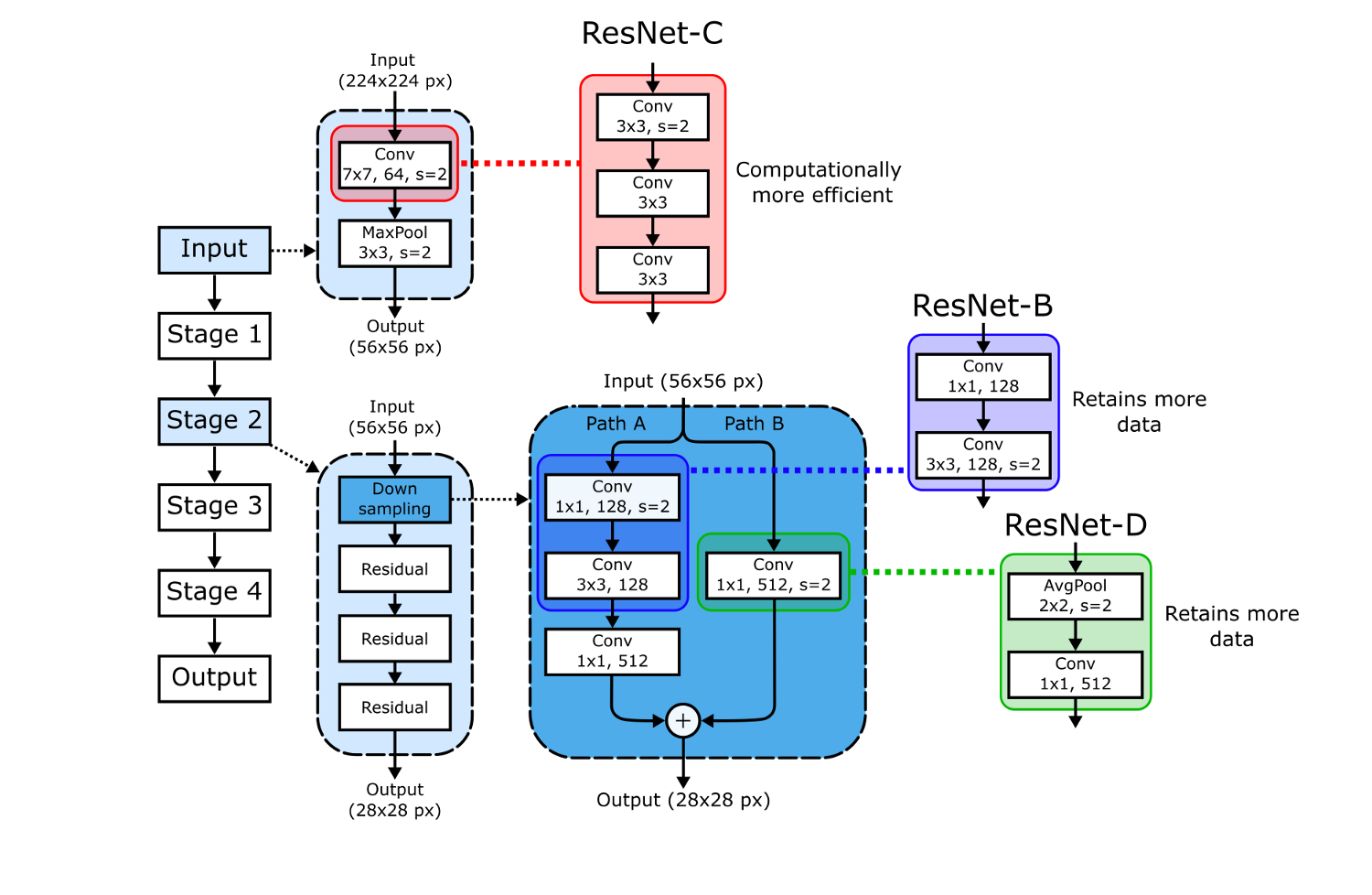
Ключевые компоненты ResNet50 показаны на следующем рисунке. CNN начинается со входного ствола (input stem), за которым следуют четыре блока, построенные по одному образцу:
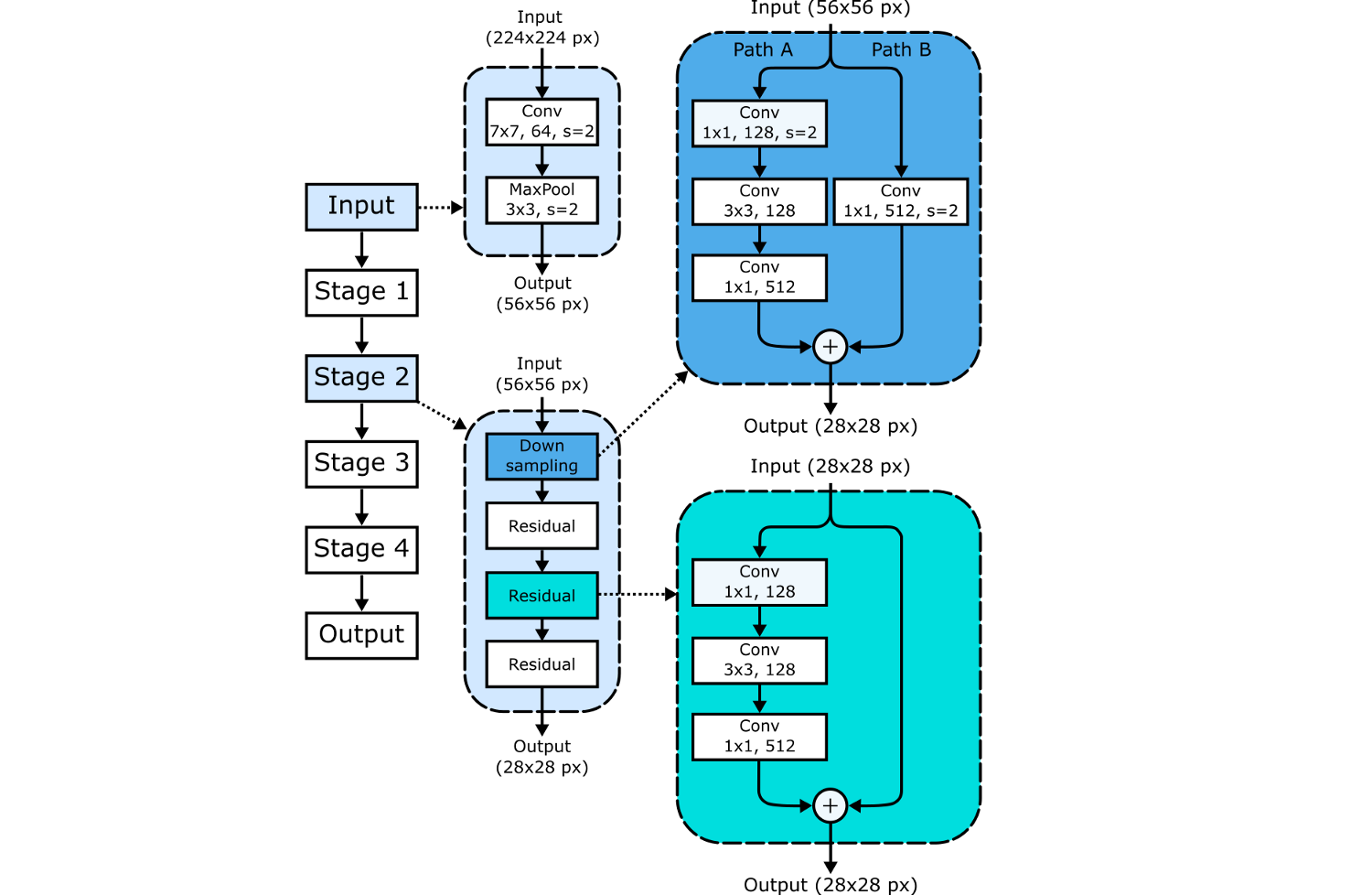
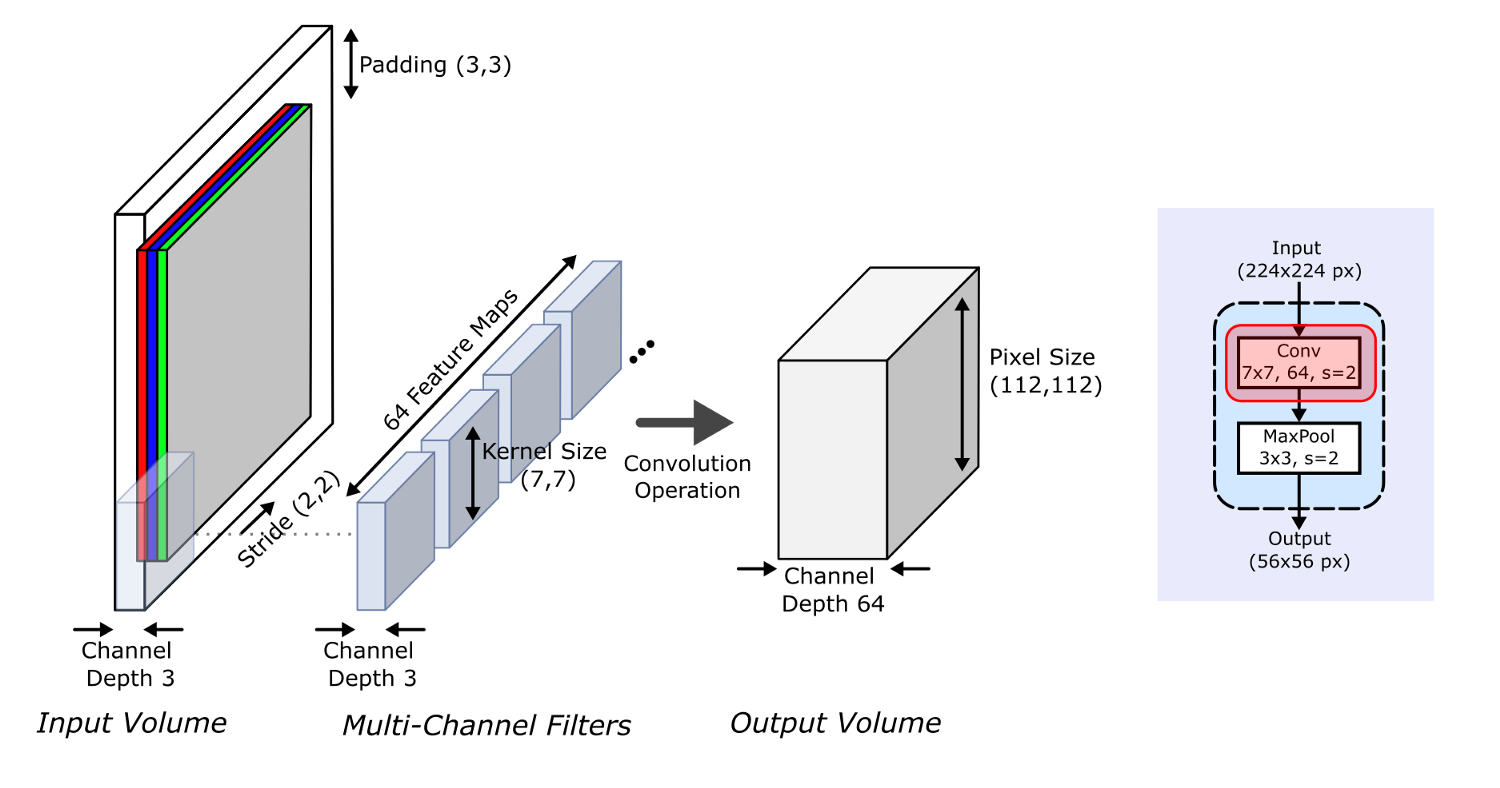
Первая секция известна как входной ствол (input stem), начинающийся со сверточного слоя 7*7 с картой признаков размером 64 и шагом 2, который запускается на входных данных с дополнением (padding) 3. Как показано ниже, эта свертка сокращает размеры изображения с 224 до 112, увеличивая глубину каналов с 3 до 64.
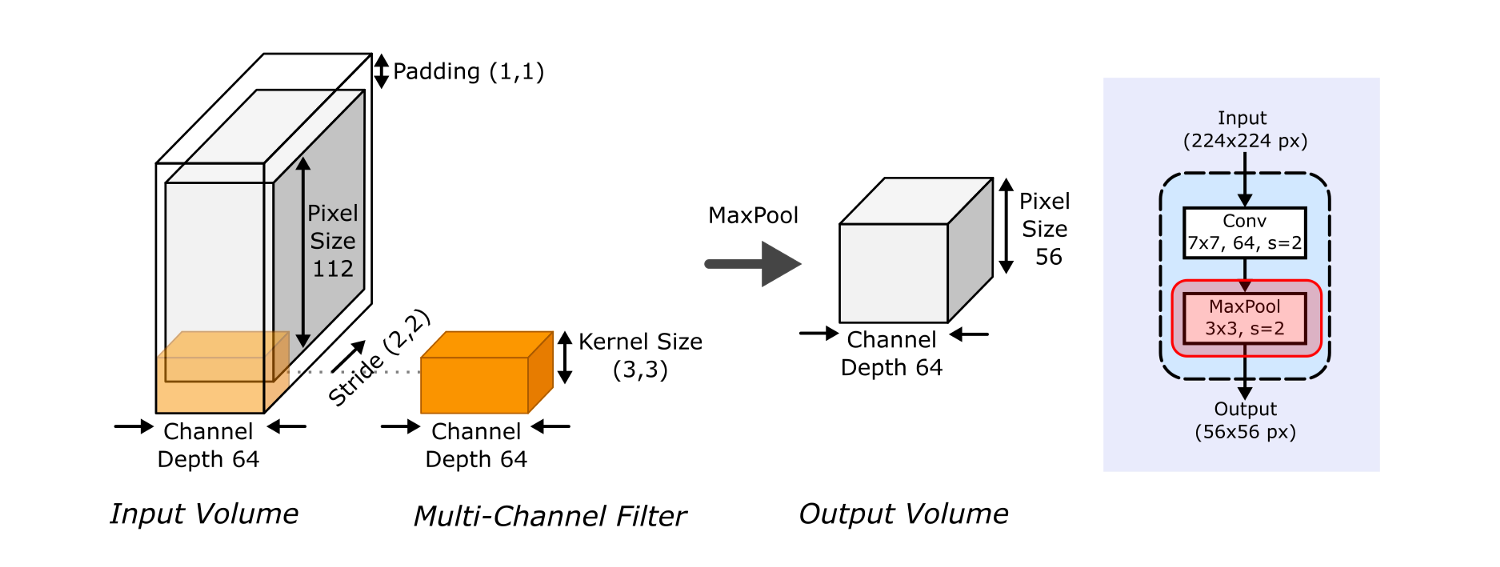
Затем идет слой максимальной группировки (max pooling), снова с шагом 2, на вход которому подается выход свертки 7*7 с дополнением (padding) 1. Это снова сокращает размеры изображений – теперь до 56*56 пикселей.
Выходной объем (output volume) входного ствола подается на Стадию 1, которая содержит три остаточных блока (ResBlocks), по три слоя в каждом. Каждый сверточный шаг этой стадии имеет шаги (1,1), что сохраняет размеры выходных данных, но содержит "узкое место", сокращающее глубину массива признаков (количества каналов) перед ее восстановлением. Чтобы этого добиться, свертки 3*3 закладываются между свертками 1*1, имеющими разные размеры массива признаков, что сокращает, а потом снова расширяет глубину каналов выходов. Основной результат этого – в том, что мы можем применить больше фильтров к массиву признаков за такое же количество времени, сокращая вычислительную нагрузку при расчете свертки 3*3.
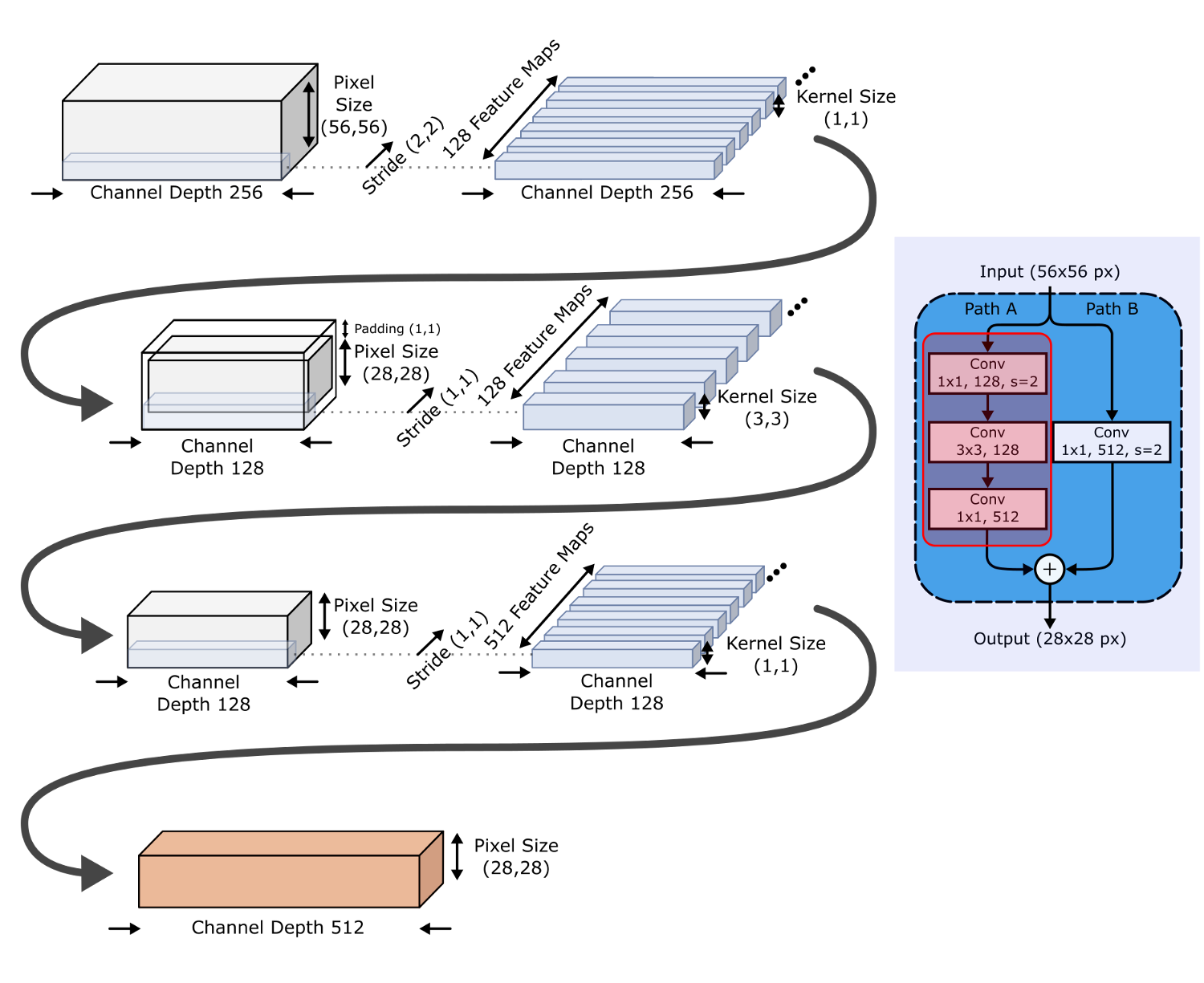
На каждой из Стадий 2-4 процесс похожий, кроме первого остаточного блока, который дополнительно обрезает массивы признаков, используя свертку 1*1 с шагом (2,2). Этот блок обрезки и устранения узкого места (Путь А) показан на следующей диаграмме.
Однако теперь размеры входного и выходного объемов у нас различаются (256*56*56 и 512*28*28 в приведенном выше примере), а это значит, что нам придется выровнять чрезвычайно важную связь идентичности! Это делается сверткой 1*1 с шагом (2,2), увеличивая глубину на 2, чтобы соответствовать выводу. Этот процесс показан ниже, и выходные объемы складываются вместе в конце первого остаточного блока.
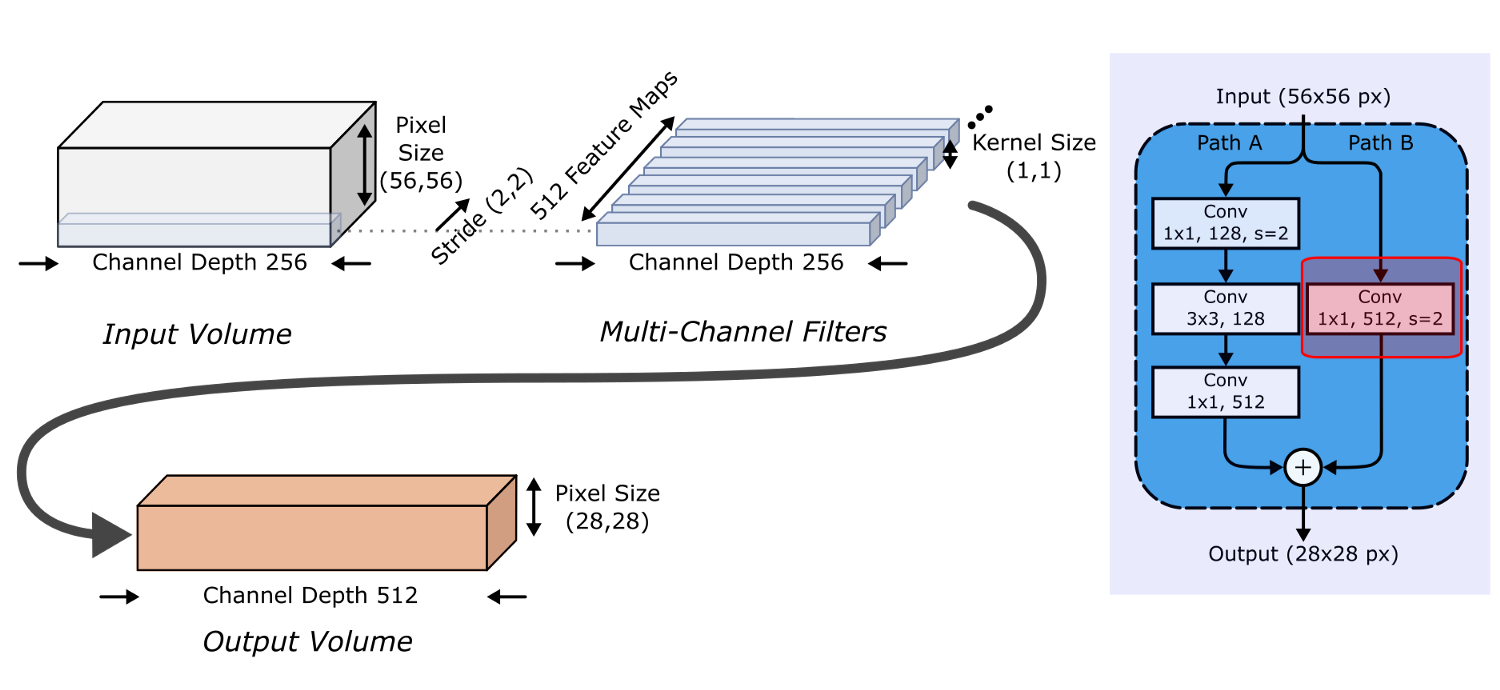
Таким образом, по мере продвижения от одной Стадии к другой, ширина каналов удваивается, а размеры входа уменьшаются вдвое.
Мы рассмотрели довольно много мелких деталей структурs ResNets и остаточных блоков, но все это нам понадобится для понимания современной эволюции ResNets!
1.2. Реализация ResNet
Предобученные ResNet'ы размерами с 18 до 152, унаследованные от предобученных моделей, имеющихся в torchvision, реализованы в fast.ai по умолчанию. Например, чтобы использовать предобученную ResNet-34, мы можем просто передать model='resnet34' и pretrained=true во вспомогательную функцию cnn_learner.
Подробные работающие примеры использования моделей ResNet см. в этом репозитории GitHub.
1.3. Использование ResNet
Давайте используем код, подготовленный в статье "Обучение с контролируемой случайностью" для обучения различных ResNet'ов на нашем очищенном наборе данных и сравним результаты.
learn = create_simple_cnn_learner(pct_images=1/3,
deterministic=True,
size=224,
img_path ='/content/plant_image_database/',
split_path = '/content/plant_image_database/',
log_name = '50baseline.csv')
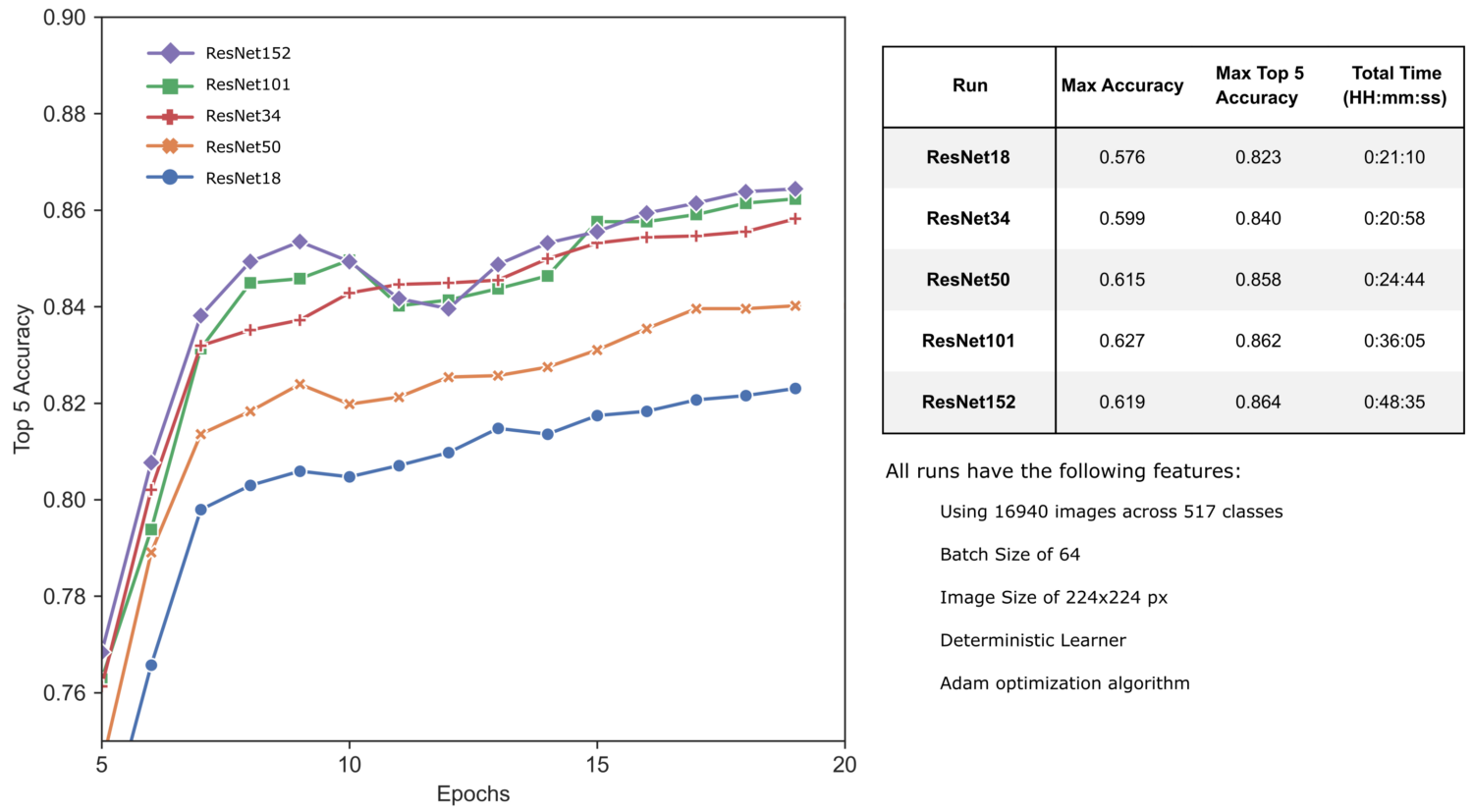
По мере увеличения размеров ResNet мы наблюдаем повышение точности наших предсказаний, наряду с увеличением общего времени, требуемого на обучение. Давайте взглянем на новые архитектуры, ведущие свое происхождение от ResNet.
2. XResNet
2.1. Что такое XResNet
XResNets были представлены Тонгом Хе из Amazon Web Services, основываясь на идее ResNet'ов и вводя "Мешок трюков для классификации изображений с помощью сверточных нейронных сетей". xResNet'ы просто вводят три различных улучшения с разными именами, стремясь к усовершенствованию трех различных шагов, присутствующих в архитектуре ResNet.
xResNet: ResNet'ы прекрасны, но давайте перестанем выбрасывать данные и ускорим первую свертку.
xResNets просто вводит три различных улучшения, каждое под собственным именем:
- ResNet-B. На пути А каждого блока обрезки мы перемещаем шаг (2, 2) на вторую свертку (3*3) и оставляем шаг 1 для первого слоя. Это сохраняет больше данных. Вместо пропуска большей части данных сверткой 1*1 с шагом (2, 2), мы можем сохранить такие же размеры выхода и использовать больше данных, перемещая обрезку на шаг свертки большего размера (3*3).
- ResNet-C. Мы убираем свертку 7*7 на входном стержне, и заменяем ее тремя последовательными свертками 3*3. Это эффективнее. Свертка 7*7 требует в 5.4 раз больше вычислительных операций, чем свертка 3*3, и мы все равно можем сохранить исходные размеры выхода, используя шаг (2, 2) на первой свертке 3*3.
- ResNet-D. На пути Б каждого блока обрезки заменяем свертку 1*1 с шагом (2, 2) слоем максимальной группировки с шагом (2, 2), за которым следует сверточный слой 1*1. Это сохраняет больше данных. Еще раз: свертка 1*1 с шагом (2, 2) теряет множество полезной информации. Здесь мы усредняем данные вместо того, чтобы выбрасывать половину данных.
2.2. Реализация xResNet
fast.ai по умолчанию поддерживает широкий диапазон xResNets, но предобученные веса есть только для xResNets50. Чтобы использовать эту архитектуру, надо импортировать соответствующие модули в глобальное пространство имен,
from fastai.vision.models.xresnet import *
а затем установить параметры xResNets, которые вы хотите использовать, перед передачей модели во вспомогательную функцию обучения. Здесь sa означает использование само-внимания (self-attention), а n_out соответствует количеству классов:
def xresnet50_custom(pretrained=False, sa=False, n_out=517):
model = xresnet50(sa=sa, n_out=n_out, pretrained=pretrained)
return model
2.3. Использование xResNet
Еще раз используя код, описанный в статье "Обучение с контролируемой случайностью", давайте обучим предобученную модель архитектуры xResNet50 на наших данных.
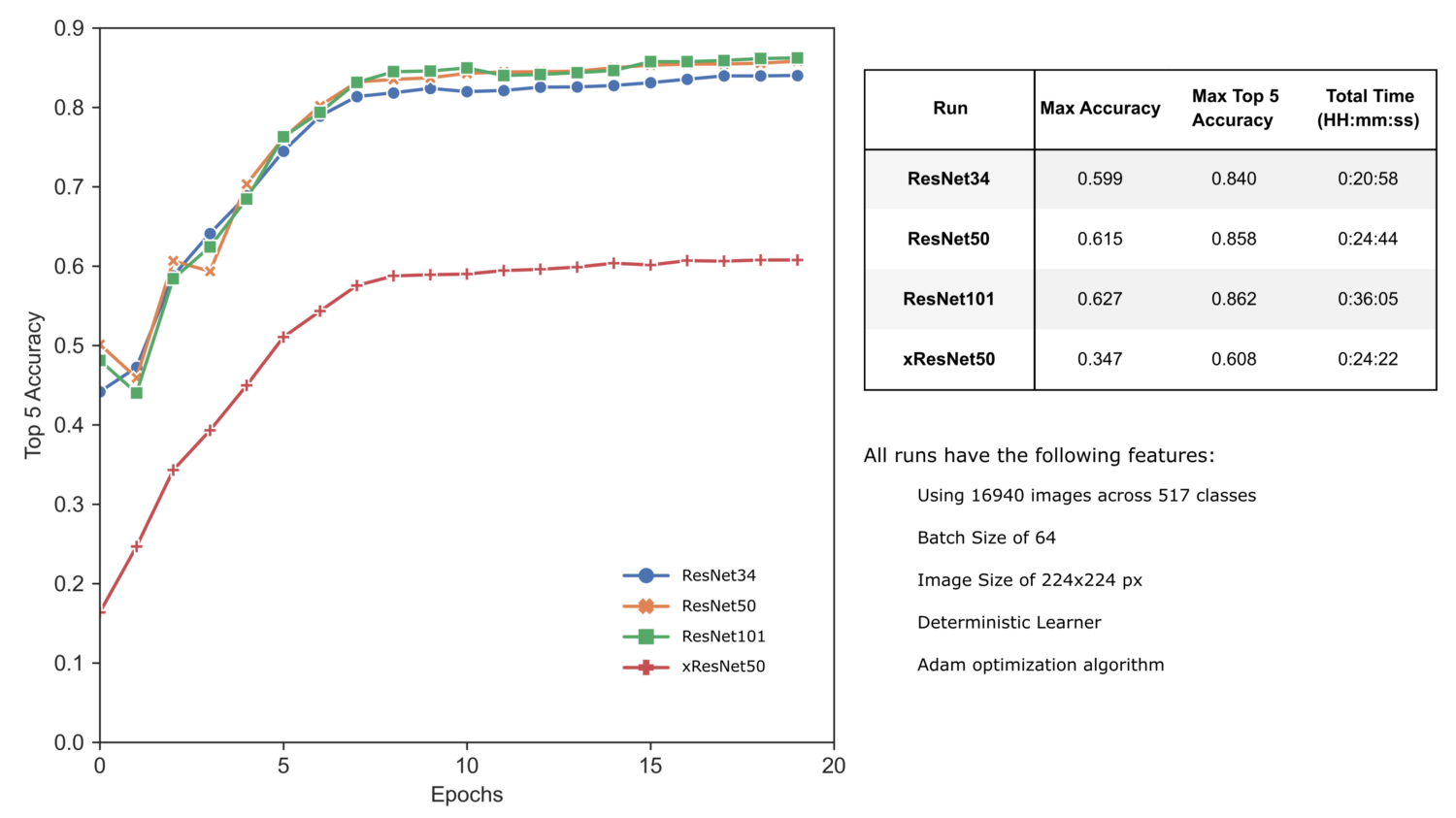
К сожалению, результаты обучения xResNet намного уступают результатам стандартной ResNet из-за качества весов, доступных в данный момент. Тем не менее, xResNet'ы показали лучшие результаты при тренировке с нуля, и все их улучшения демонстрируют, насколько существенно выбор даже мелких деталей реализации слоя в CNN может повлиять на ее точность.
3. Squeeze-and-Excitation ResNet (SE-ResNet)
3.1. Что такое ResNet'ы со сжатием и стимуляцией (Squueze-and-Excitation ResNets)
Все CNN используют сверточные фильтры для выделения информации из изображений на различных уровнях детализации. Слои, расположенные возле входа, обнаруживают границы или градиенты, тогда как верхние слои могут распознавать все более и более сложные геометрические фигуры и узоры. По мере прохождения данных через CNN пространственная и канальная информация смешиваются посредством мультиканальных фильтров, и разница на выходе происходит из-за обученных весов в каждом ядре (kernel). Что критически важно, все выходные каналы (пока) имеют одинаковый вес при создании выходных карт признаков (feature maps).
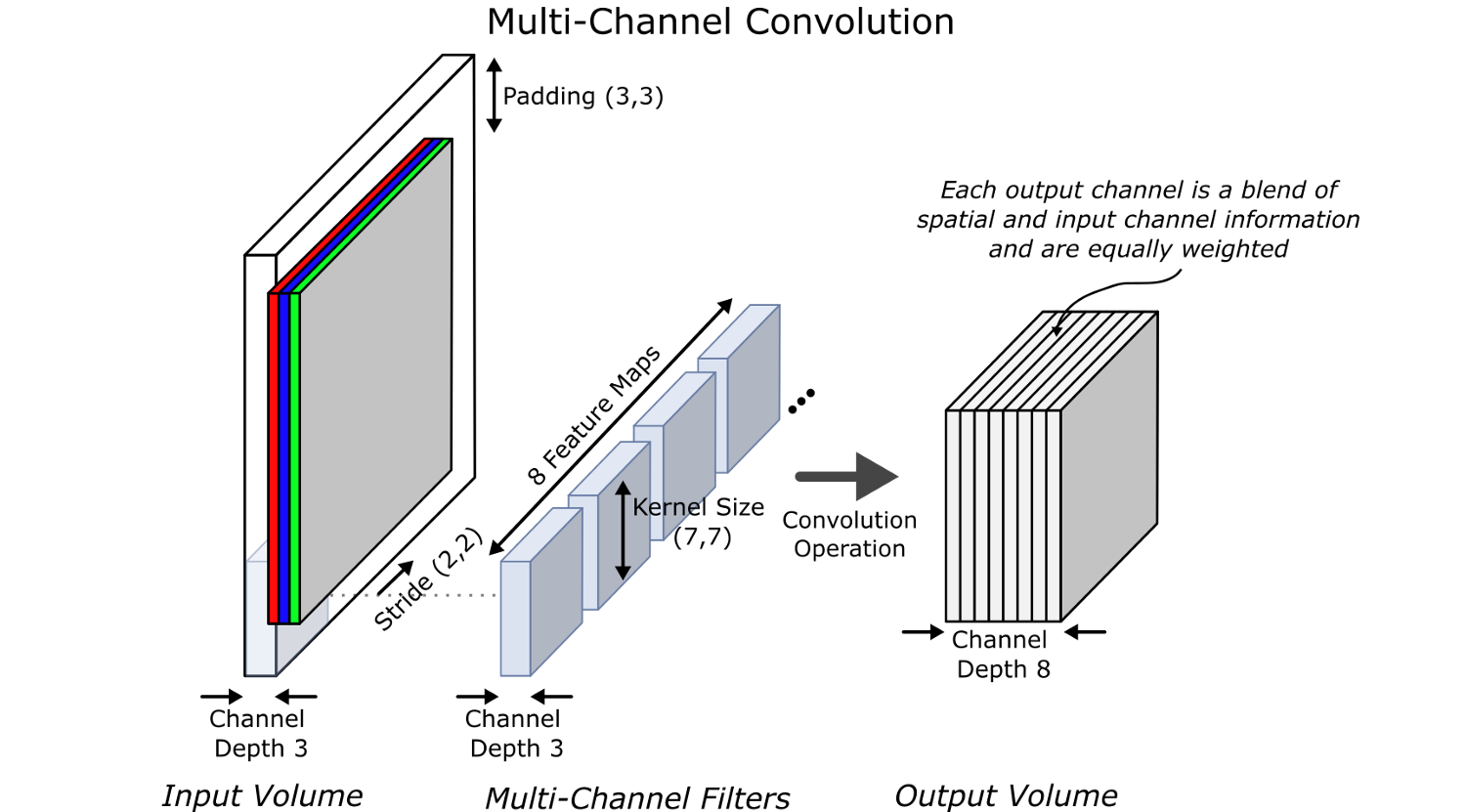
Squeeze-and-Excitation Net – Не все каналы одинаково важны, поэтому давайте присвоим им веса.
SE-Nets пытаются распределить имеющиеся вычислительные ресурсы в пользу более информативных компонентов сигнала, добавив механизм взвешивания каналов. Это взвешивание производится дополнительной нейронной сетью, которая параметризует веса и применяет их к карте признаков в конце этого блока. Эта нейронная сеть:
- Принимает в качестве входа сверточный блок.
- "Сжимает" каждый канал до единственного числового значения, используя максимальную группировку (max pooling).
- Вводит параметризацию, используя "узкое место" с двумя полносвязными слоями, чтобы обеспечить обучение нелинейным зависимостям между каналами. Первый слой имеет фунцкию активации ReLU, до некоторой степени сокращая сложность каналов. Второй полносвязный слой восстанавливает сложность и использует в качестве функции активации сигмоиду, позволяя выделить несколько каналов (а не только один).
- Использует этот вывод для взвешивания каждой карты каналов сверточного блока – "стимуляция".
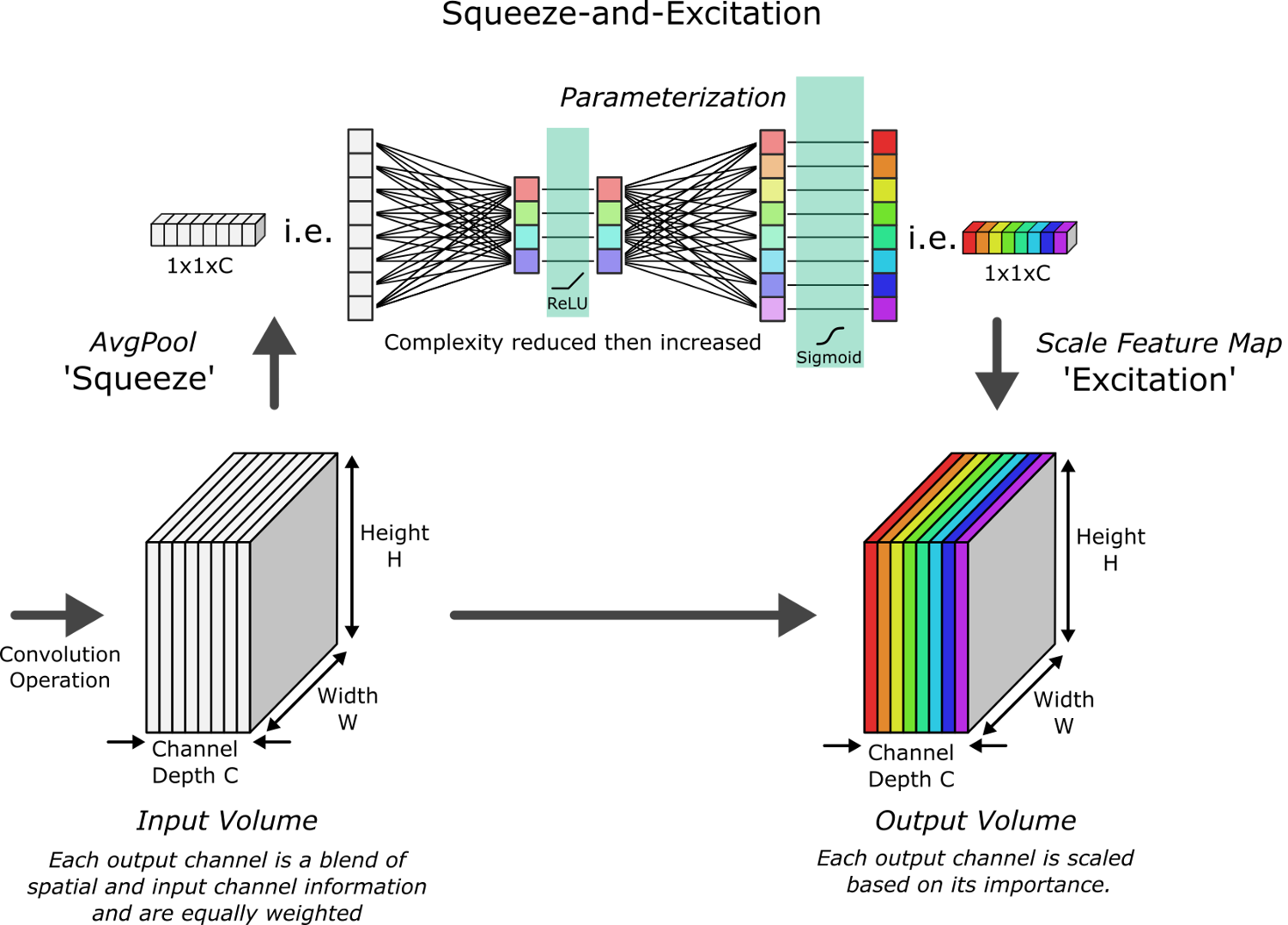
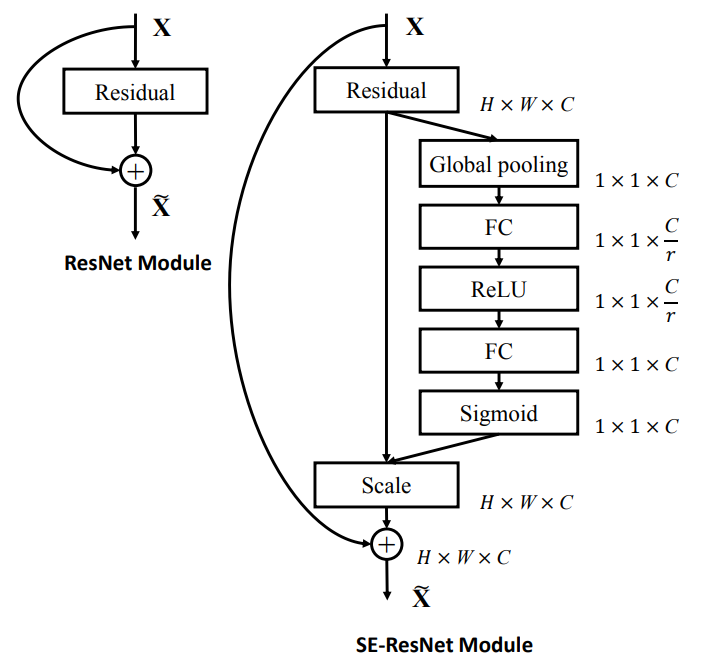
Используя эту структуру, для каждого трансформирующего блока CNN можно создать соответствующий блок сжатия-и-стимуляции.
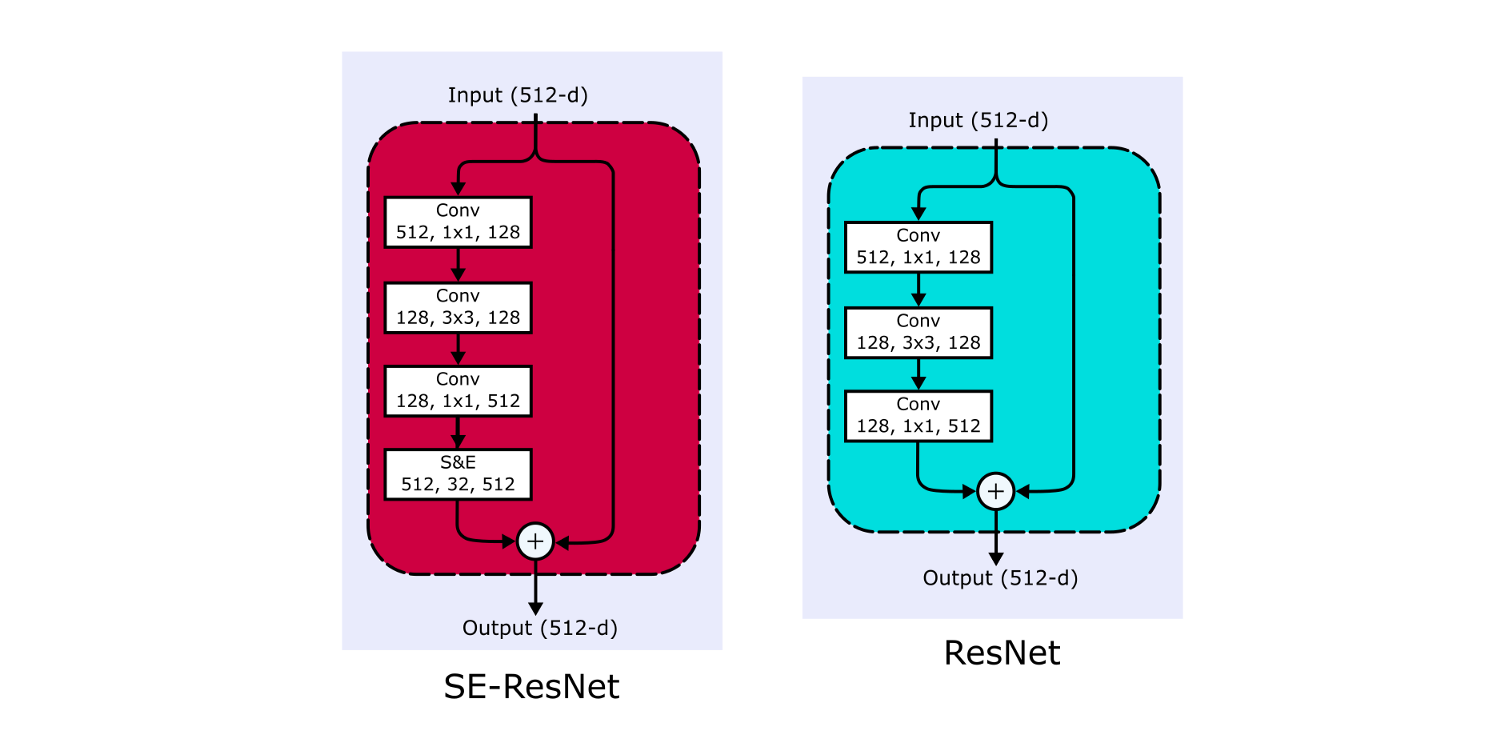
Авторы демонстрируют, что добавление SE-блоков в ResNet-50 позволяет модели достичь такой же точности, как ResNet-101, за минимальное повышение требуемых вычислительных ресурсов (менее 1%!) Давайте посмотрим на это сами.
3.2. Реализация SE-ResNet
Чтобы реализовать SE-ResNets в экосистеме fast.ai, нам нужны архитектуры CNN в виде nn.Sequentials из PyTorch. Репозиторий GitHub Олега Семери "Песочница для обучения сверточных нейронных сетей для машинного зрения" содержит целую кучу предобученных моделей в требуемом формате PyTorch, откуда мы и будем брать все наши SE-ResNets.
В Google Colabs мы можем установить и импортировать этот пакет с помощью следующего кода:
# Установим pytorchcv в Colabs
! pip install pytorchcv torch>=0.4.0 -q
# Импортируем pytorchcv model_provider
from pytorchcv.model_provider import get_model as ptcv_get_model
Теперь мы можем импортировать модели в глобальное пространство имен с помощью
# Каждая модель должна быть представлена в виде функции в глобальном пространстве имен.
def seresnet50(pretrained=True):
return ptcv_get_model("seresnet50", pretrained=pretrained).features
В этой библиотеке признаки модели инкапсулируются в model.features, как nn.Sequential. Каждый заголовок модели – это на самом деле model.output, поэтому приведенный выше код выделяет тело модели, пропуская заголовок. В этом случае последним слоем SE-ResNet50 будет AvgPool2d (группировка усреднения), ожидающий добавления заголовка, соответствующего вашей задачи классификации.
(0) ResInitBlock: 4 layers (total: 4)
(1) Sequential : 44 layers (total: 48)
(2) Sequential : 58 layers (total: 106)
(3) Sequential : 86 layers (total: 192)
(4) Sequential : 44 layers (total: 236)
(5) AvgPool2d : 1 layers (total: 237)`
В fast.ai мы можем просто передать эту предобученную модель вспомогательной функции cnn_learner, которая делает некоторые вещи за сценой. А именно:
- Находит последний слой группировки и обрезает модель на этом месте, чтобы создать тело, содержащее все признаки.
- Создает заголовок fast.ai для задач классификации изображений. См. nn.Sequential ниже (с подходящим количеством входов и выходов).
- Применяет инициализацию Кайминя к новому заголовку.
- Присоединяет этот заголовок к телу модели.
# Создаем заголовок вручную
# Поскольку мы используем AdaptiveConcatPool2d, слои BatchNorm1D требуют 2* количество входов последнего выходного слоя
custom_head = nn.Sequential(AdaptiveConcatPool2d(),
Flatten(),
nn.BatchNorm1d(4096),
nn.Dropout(p=0.25, inplace=False),
nn.Linear(in_features=4096, out_features=512, bias=False),
nn.ReLU(inplace=True),
nn.BatchNorm1d(512),
nn.Dropout(p=0.5, inplace=False),
nn.Linear(in_features=512, out_features=517, bias=False))
Теперь мы можем обучать нашу новую модель.
См. детализированную работающую реализацию моделей SE-ResNet в этом репозитории GitHub.
3.3. Использование SE-ResNet
Еще раз используя код, описанный в статье "Обучение с контролируемой случайностью", давайте обучим наши предобученные архитектуры SE-ResNet на нашем наборе данных о растениях.
Обратите внимание, что вследствие большого размера модели, SE-Res152 пришлось запускать с размером пакета 62, чтобы хватало памяти GPU.
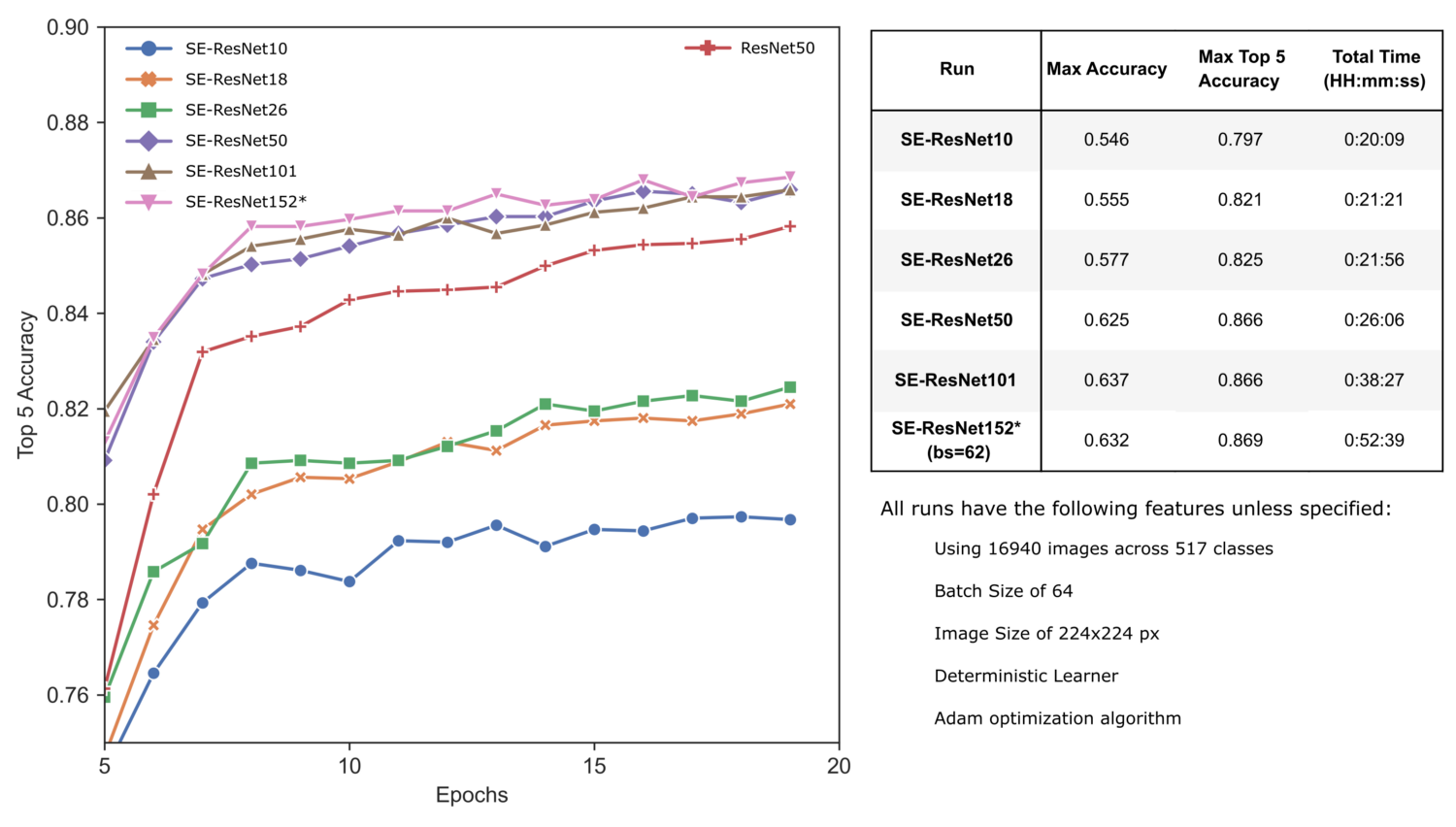
Как и для ResNet, по мере увеличения размеров SE-ResNet мы видим повышение точности наших предсказаний, как и увеличение общего времени обучения. Впечатляет, что SE-ResNet50 превзошел точность ResNet50 за существенно меньшее время (26 минут против 36).
4. ResNeXt
4.1. Что такое ResNeXt
Разработанный в Университете Сан-Диего и Facebook AI Research (FAIR) в 2017, ResNeXt вводит следующее (next) измерение в архитектуры сверточных нейронных сетей – "мощность" ("cardinality").
ResNeXt - переводим ResNet на следующее измерение с помощью стратегии "раздели-трансформируй-объедини".
ResNeXt наследует обходную связь идентичности из ResNet и адаптирует стратегию "раздели-трансформируй-объедини" из Inception для увеличения "ширины" сети, используя несколько фильтров, работающих на одном и том же уровне разветвленной архитектуры. Мощность в этом контексте контролирует размер множества трансформаций, то есть, количество ветвей.
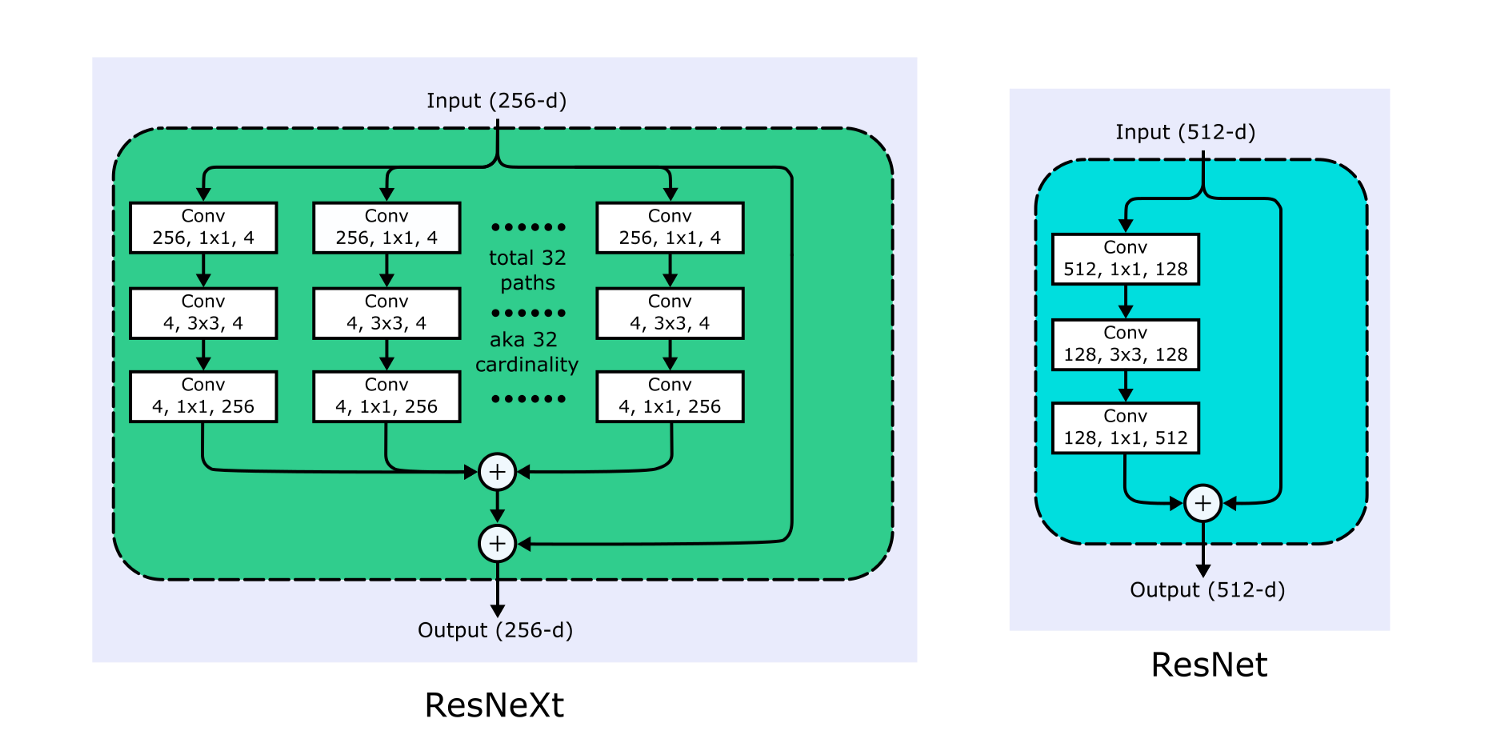
Как показано на приведенном выше рисунке, каждый блок ResNeXt делит вход на количество (равное мощности) представлений с низшей размерностью, каждое из которых затем трансформируется одним и тем же набором фильтров (следуя дизайну "узкого места", принятому в блоках ResNet), перед объединением и суммированием с идентичностью, переданной по обходной связи.
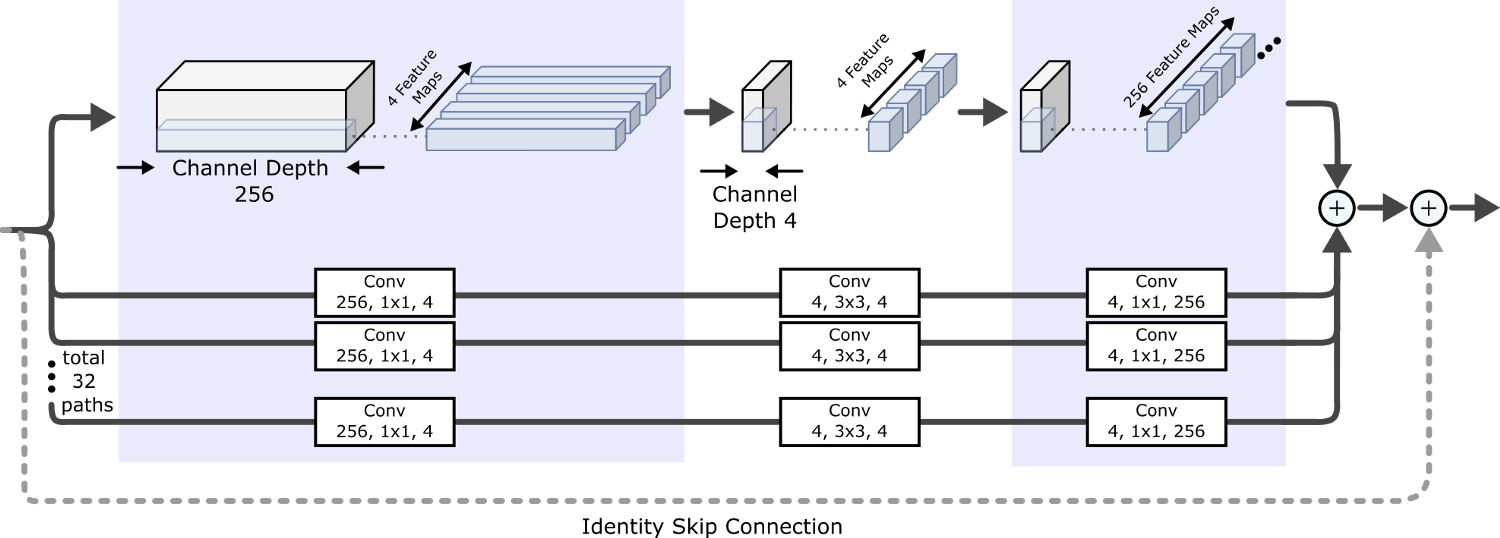
В реальности, разветвленные блоки заменяются функционально эквивалентными групповыми свертками (такими же, как AlexNet), намного более эффективными с вычислительной точки зрения. Повышение мощности оказалось более эффективным для повышения точности, чем увеличение ширины или глубины, особенно в тех случаях, когда повышение точности от увеличения ширины или глубины начинает приносить ничтожный рост точности.
Названия моделей ResNeXt отражают их мощность и ширину "узкого места" на каждом пути ветвления. Например, ResNeXt50_32x4d имеет мощность 32 и ширину узкого места 4.
4.2. Реализация ResNeXt
Для реализации ResNeXt в экосистеме fast.ai мы снова используем репозиторий GitHub Олега Семери "Песочница для обучения сверточных нейронных сетей для машинного зрения". Эти предобученные сети ResNeXt поставляются в виде nn.Sequentials PyTorch для облегчения реализации.
В Google Colab мы можем установить и импортировать пакет с помощью следующего кода:
# Установим pytorchcv в Colabs
! pip install pytorchcv torch>=0.4.0 -q
# Импортируем model_provider из pytorchcv
from pytorchcv.model_provider import get_model as ptcv_get_model
Затем мы можем импортировать модели в глобальное пространство имен следующим кодом:
# Каждая модель должна быть представлена в виде функции в глобальном пространстве имен
def resnext50_32x4d(pretrained=True):
return ptcv_get_model("resnext50_32x4d", pretrained=pretrained).features
После этого реализация идентична примеру SE-ResNets: мы просто передаем эту предобученную модель вспомогательной функции cnn_learner, которая обрежет все слои после последнего слоя группировки (pooling) и добавит вместо обрезанных слоев заголовок fast.ai для задач классификации машинного зрения, c инициализацией Кайминя.
См. детализированную работающую реализацию моделей ResNeXt в этом репозитории GitHub.
4.3. Использование ResNeXt
И снова используя код, описанный в статье "Обучение с контролируемой случайностью", давайте обучим наши предобученные архитектуры ResNeXt на нашем наборе данных о растениях.
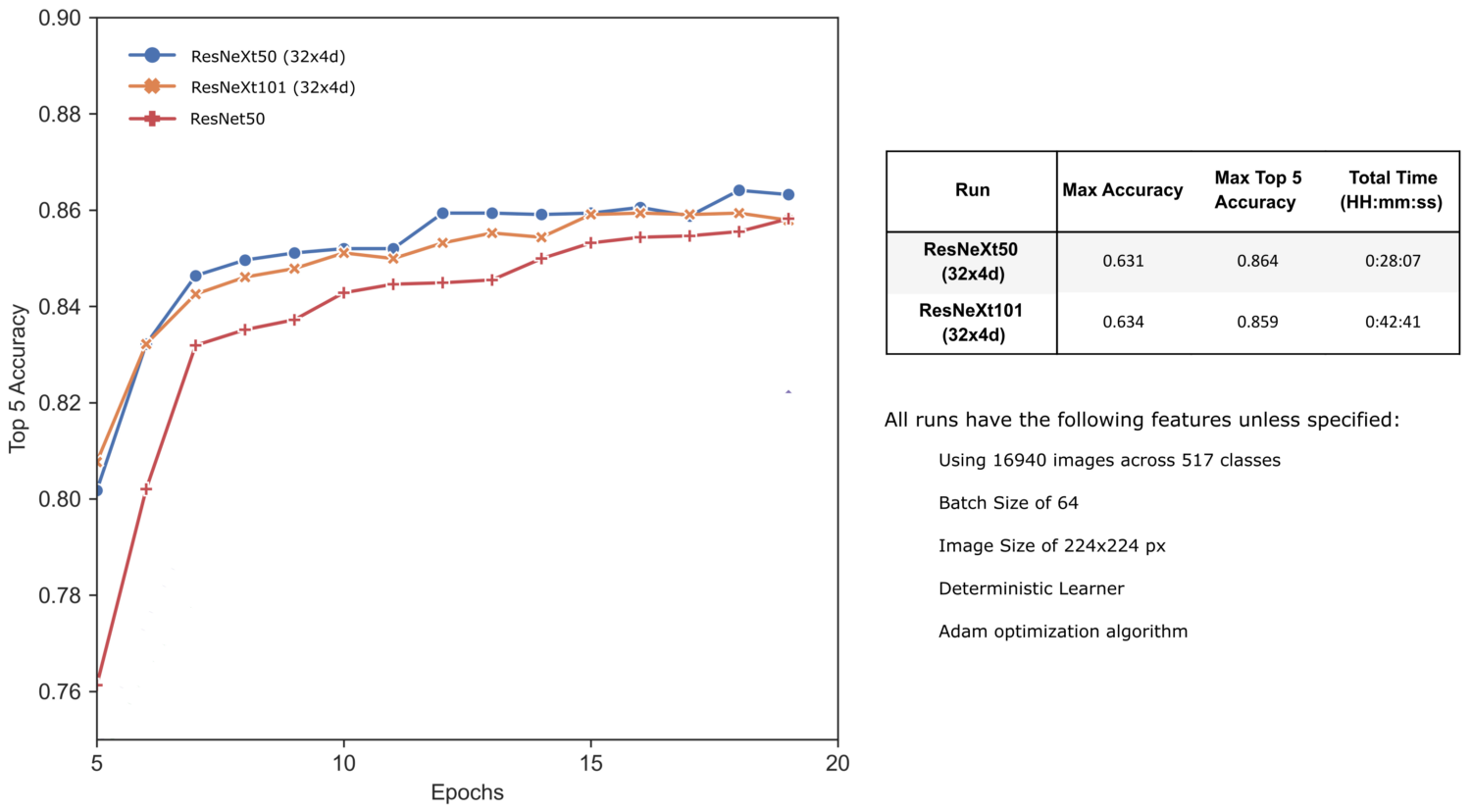
При указанных условиях обучения архитектуры ResNeXt выдают результаты, сравнимые с моделями SE-ResNet. Здесь мы наблюдаем исчезающий эффект увеличения размеров, когда серьезное увеличение времени обучения приносит лишь незначительное повышение точности. Однако, без серьезной оптимизации гиперпараметров нельзя делать выводы о потенциальной производительности большой модели ResNeXt101.
5. SE-ResNeXt
5.1. Что такое SE-ResNeXt
SE-ResNeXt – это, как вы и могли подумать, нейронные сети ResNeXt с добавлением шага сжатия-и-стимуляции.
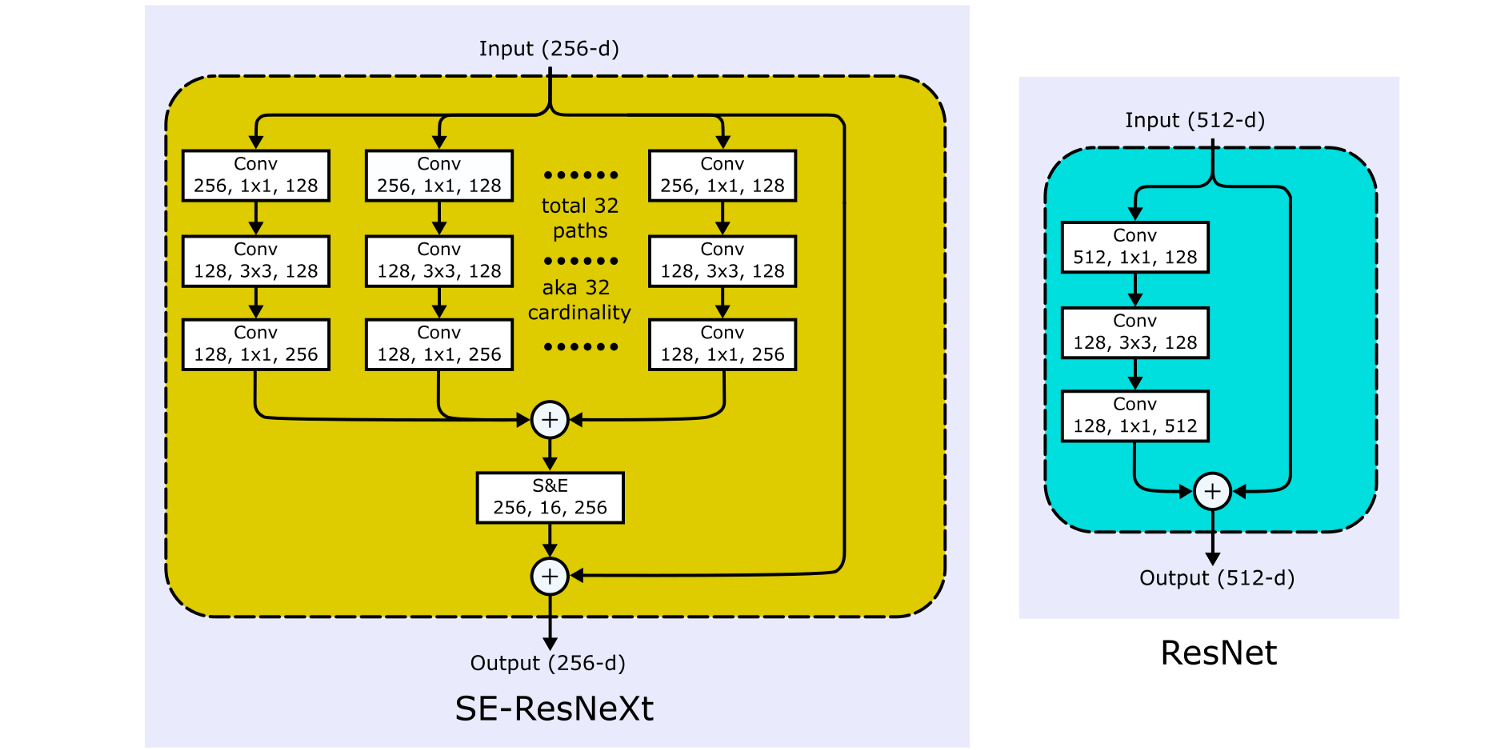
5.2. Реализация SE-ResNeXt
Предобученные модели SE-ResNeXt взяты из репозитория GitHub Олега Семери "Песочница для обучения сверточных нейронных сетей для машинного зрения".
В Google Colab мы можем установить и импортировать пакет с помощью следующего кода:
# Установим pytorchcv в Colabs
! pip install pytorchcv torch>=0.4.0 -q
# Импортируем model_provider из pytorchcv
from pytorchcv.model_provider import get_model as ptcv_get_model
Затем мы можем импортировать модели в глобальное пространство имен следующим кодом:
def resnext50_32x4d(pretrained=True):
return ptcv_get_model("resnext50_32x4d", pretrained=pretrained).features
После этого реализация идентична примеру SE-ResNets: мы просто передаем эту предобученную модель вспомогательной функции cnn_learner, которая обрежет все слои после последнего слоя группировки (pooling) и добавит вместо обрезанных слоев заголовок fast.ai для задач классификации машинного зрения, c инициализацией Кайминя.
См. детализированную работающую реализацию моделей SE-ResNeXt в этом репозитории GitHub.
5.3. Использование SE-ResNeXt
И снова используя код, описанный в статье "Обучение с контролируемой случайностью", давайте обучим наши предобученные архитектуры SE-ResNeXt на нашем наборе данных о растениях.
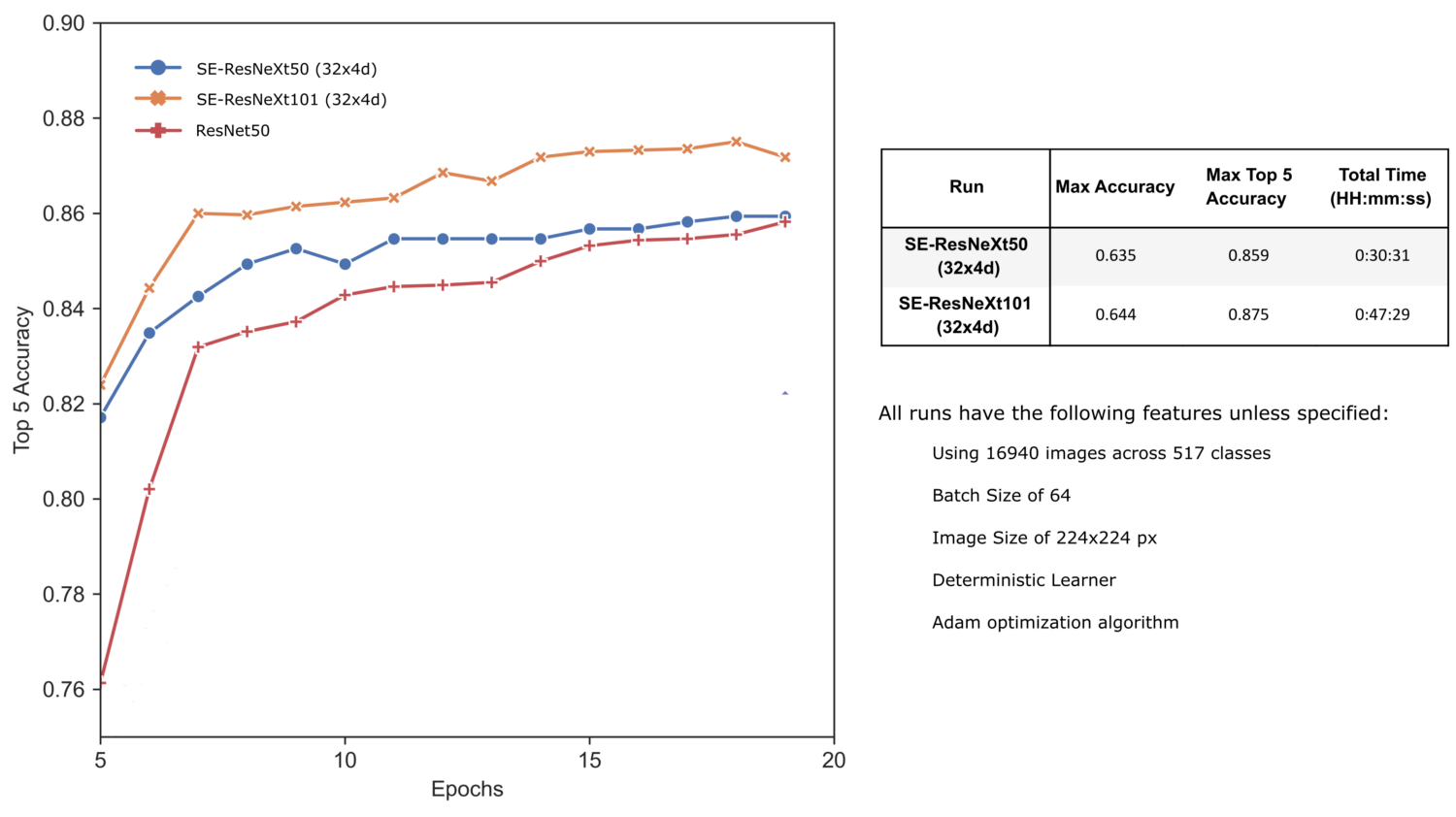
Объединяя улучшения сжатия-и-стимуляции и архитектур ResNeXt, модели SE-ResNeXt немного улучшили точность наших результатов. Пока что SE-ResNeXt101 дала нам самые лучшие результаты, без какой-либо дальнейшей оптимизации!
6. EfficientNet
6.1. Что такое EfficientNet?
EfficientNet'ы появились в результате слияния двух очень простых идей: используем самую лучшую архитектуру сети, которую мы сумели найти (EfficientNet-B0) и улучшим способности предсказания, масштабируя структуру базовой нейронной сети для повышения точности самым эффективным с точки зрения вычислительной мощности образом (комбинированное масштабирование).
EfficientNets: давайте придумаем лучшую структуру сети и эффективно ее масштабируем.
EfficientNet-B0
Базовая нейронная сеть, EfficientNet-B0, была разработана авторами, искавшими архитектуру сети, оптимизирующую как точность, так и требуемое количество вычислений. Основной строительный блок EfficientNet-B0 – это MBConv (мобильная обращенная свертка с узким местом), к которой добавлено сжатие-и-стимуляция.
В традиционном ResBlock'е количество каналов следует образцу широкое-узкое-широкое (также называемое "узким местом"), параллельно с обходной связью идентичности. Вход имеет большое количество каналов, сжимаемых сверткой 1*1. Затем количество опять увеличивается сверткой 1*1, чтобы можно было прибавить данные по связи идентичности.
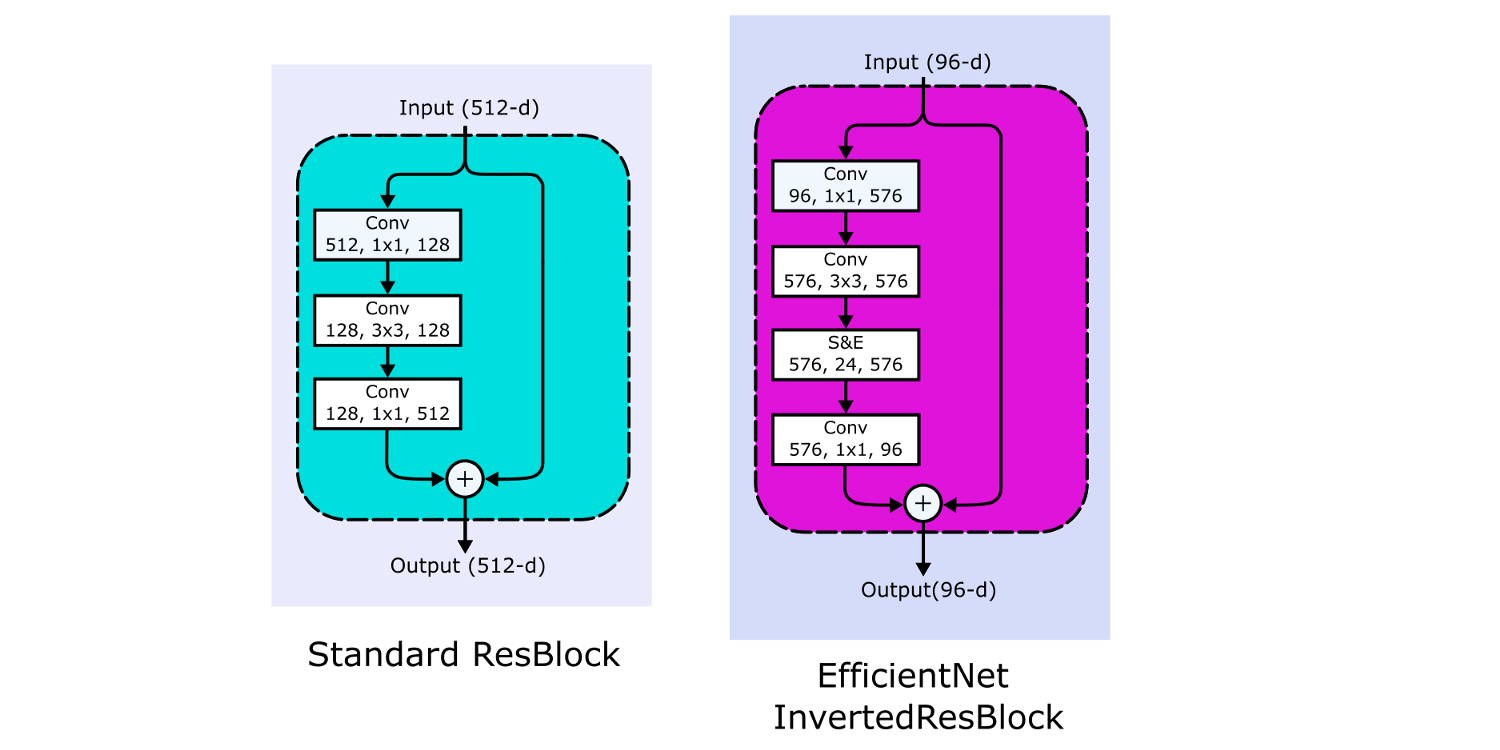
Инвертированный остаточный блок (Inverted Residual Block), как и предполагает его название, использует подход узкий/широкий/узкий. Плоский вход расширяется сверткой 1*1 перед применением глубинной свертки 3*3, сильно сокращающей количество параметров. Затем снова используется свертка 1*1 для сокращения количества каналов, чтобы можно было прибавить данные по связи идентичности.
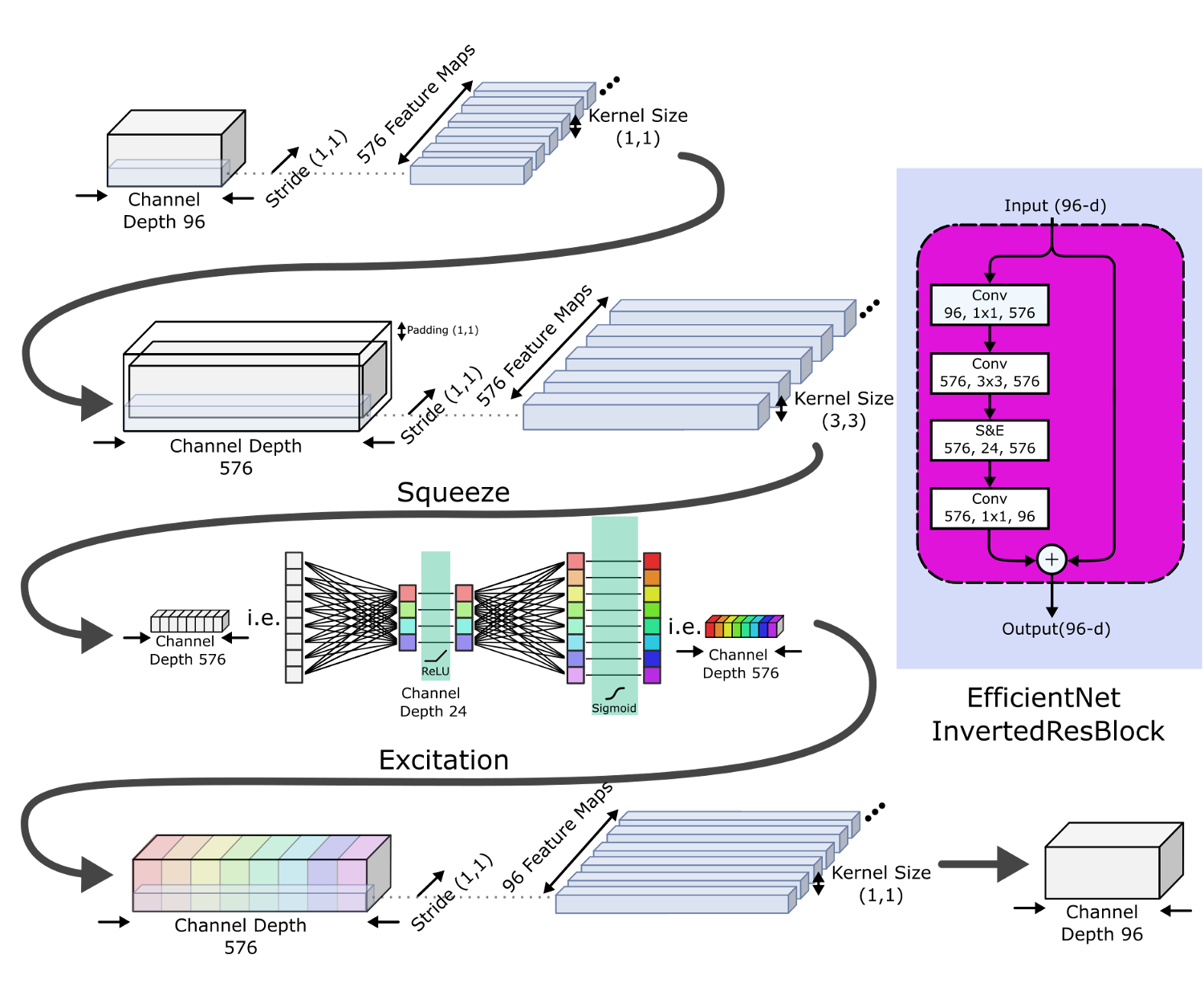
Эта структура уменьшает общее количество операций и размер модели, что позволяет EfficientNet-B0 иметь точность Топ-5, сравнимую с точностью ResNet-34, несмотря на то, что у нее вчетверо меньше тренируемых параметров, и ее обучение требует на порядок меньше вычислительных операций.
Комбинированное масштабирование
Все сверточные нейронные сети (CNN) имеют три измерения: ширину, глубину и разрешение. Глубина означает количество слоев, ширина – количество каналов (например, три канала для RGB), а разрешение – количество пикселей в изображении. Каждое из этих измерений можно масштабировать, и каждое в какой-то степени повышает точность CNN:
- Масштабирование ширины – повышает количество каналов в изображении (или нейронов в слое). Это позволяет слоям изучить более детализированные признаки и использовалось в таких архитектурах, как WideResNet и MobileNet. Однако, по мере увеличения ширины, растет и сложность изучения комплексных признаков.
- Масштабирование глубины – увеличение количества слоев CNN. Это позволяет сети изучать более сложные признаки. Однако, как было сказано выше, проблема исчезающих градиентов затрудняет обучение глубоких нейронных сетей. И хотя пакетная нормализация и обходные связи помогли ослабить эту проблему, эмпирические исследования продемонстрировали быстрое падение прироста точности. Например, ResNet-100 имеет такую же точность, как ResNet-1000.
- Масштабирование разрешения – увеличивает разрешение изображения, и, следовательно, количество пикселей. Это позволяет сети находить более мелкие структуры за счет дополнительных деталей изображения. Как и остальные виды масштабирования, само по себе масштабирование разрешения обеспечивает ограниченный прирост точности.
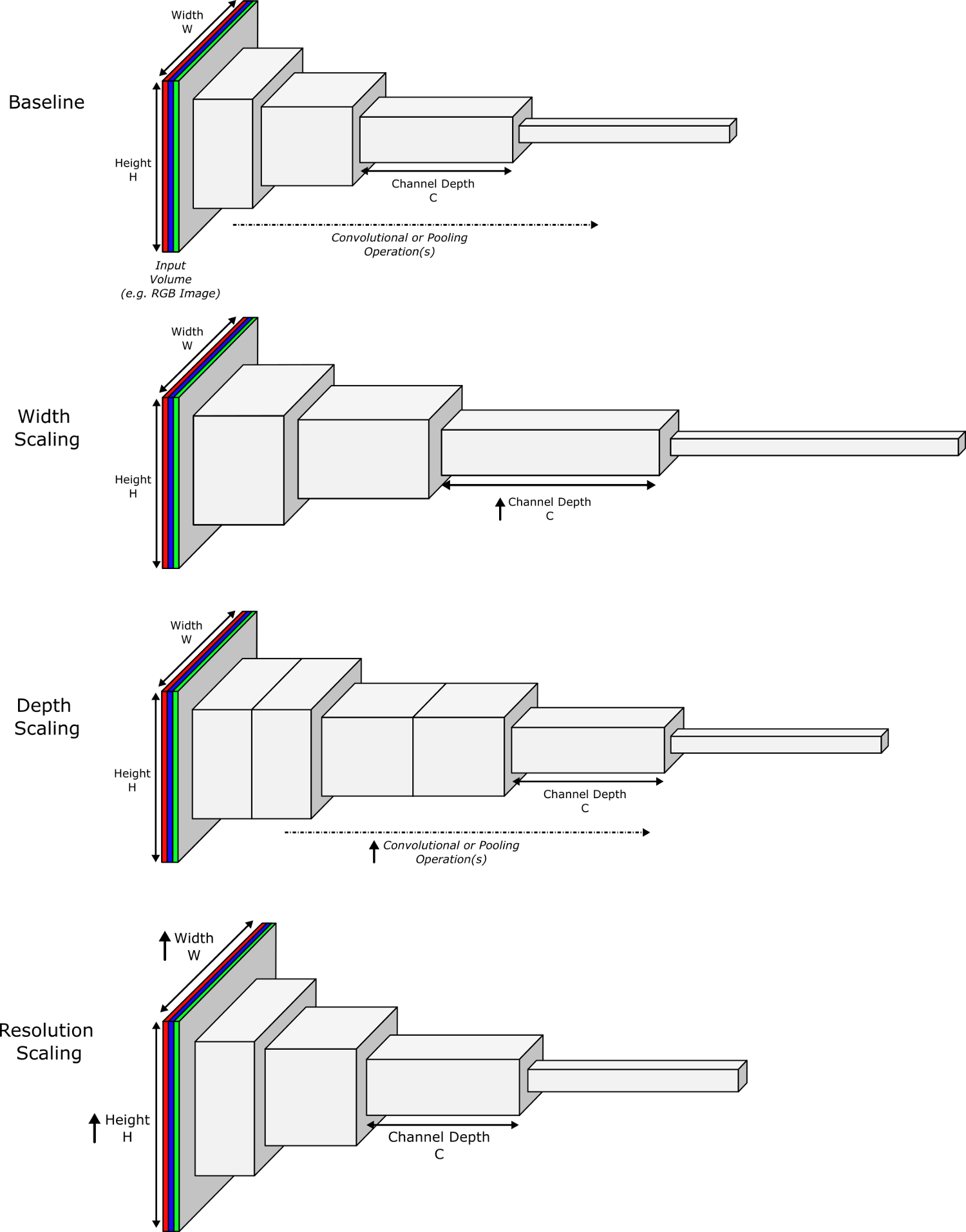
Исследователи обнаружили, что балансирование масштабированием по каждому из измерений (ширина, глубина и разрешение сети) было ключом к получению максимального прироста точности при минимальном росте вычислительной сложности.
Самые дорогостоящие в вычислительном смысле операции CNN – это операции свертки. Более того, количество операций с плавающей точкой (FLOP'ов) на операцию свертки примерно пропорционально d, w2 и r2 – то есть, удвоение глубины удвоит и количество FLOP'ов, а удвоение ширины и разрешения увеличит количество FLOP'ов вчетверо. Основываясь на этих предположениях, авторы предложили простую технику масштабирования, основанную на комбинированном коэффициенте phi (описывающем количество имеющихся ресурсов), чтобы определить, как эффективно масштабировать alpha, beta и gamma (относящиеся к ширине, глубине и разрешению нейронной сети).
Как обсуждалось выше, это соотношение устанавливает, что масштабирование сети (по ширине, глубине или разрешению) увеличит количество FLOP'ов в (aplha*beta2*gamma2)phi раз. Ограничение "(aplha*beta2*gamma2) примерно равно 2" введено, чтобы гарантировать, что количество FLOP'ов не вырастет больше, чем в 2phi раз. Таким образом, мы можем использовать комбинированный коэффициент phi для масштабирования требуемого количества FLOP'ов в известное количество раз – 2phi.
Базовая нейронная сеть EfficientNet-B0 использовалась для сетевого поиска оптимальных параметров масштабирования с фиксированным комбинированным коэффициентом phi, равным единице, и лучшими параметрами оказались aplha=1.2, beta=1.1 и gamma=1.15. Затем, фиксируя оптимальные значения aplha, beta и gamma, исследователи масштабировали количество имеющихся ресурсов phi для создания моделей большего размера от EfficientNet-B1 до EfficientNet-B7.
Еще одним интересным аспектом было использование функции активации Swish вместо ReLU – небольшое изменение, позволившее выиграть почти целый процент точности на нескольких очень сложных наборах данных.
6.2. Реализация EfficientNet
Чтобы реализовать EfficientNet в экосистеме fast.ai, мы обратимся к репозиторию GitHub Росса Уайтмана "Типовые EfficientNet для PyTorch", специализирующемуся на предоставлении набора предобученных моделей EfficientNet и MobileNet в требуемом формате PyTorch. Одна из основных причин использования этого репозитория – наличие EfficientNet'ов, само-тренированных с "Шумным Студентом", показывающих прекрасную точность на наборе данных ImageNet-1K.
В Google Colab мы можем установить и импортировать этот пакет, используя следующий код:
# Импортируем исходный код и веса моделей EfficientNet
!pip install geffnet -q
import geffnet
Теперь мы можем импортировать модели в глобальное пространство имен, запрашивая их:
# Каждая модель должна быть представлена в виде функции в глобальном пространстве имен
# geffnet уже генерирует модели как nn.Sequentials, что нам и нужно.
# drop_rate и drop_connect_rate описаны в документации к каждой архитектуре
# efficientnet_b3 ---- drop_rate=0.3, drop_connect_rate=0.2
# efficientnet_b5 ---- drop_rate=0.4, drop_connect_rate=0.2
# efficientnet_b7 ---- drop_rate=0.5, drop_connect_rate=0.2
def tf_efficientnet_b3(pretrained = False):
model = geffnet.tf_efficientnet_b3(pretrained=pretrained, drop_rate=0.3, drop_connect_rate=0.2, as_sequential=True)
return model
def tf_efficientnet_b5(pretrained = False):
model = geffnet.tf_efficientnet_b5(pretrained=pretrained, drop_rate=0.4, drop_connect_rate=0.2, as_sequential=True)
return model
def tf_efficientnet_b7(pretrained = False):
model = geffnet.tf_efficientnet_b7(pretrained=pretrained, drop_rate=0.5, drop_connect_rate=0.2, as_sequential=True)
return model
Начиная с этого места, реализация идентична всем прочим примерам сетей, основанных на ResNet: мы просто передаем эту предобученную модель вспомогательной функции cnn_learner, которая обрезает все слои после последнего слоя группировки и добавляет заголовок для задач классификации машинного зрения с инициализацией Кайминя.
См. детализированную работающую реализацию моделей EfficientNet в этом репозитории GitHub.
6.3. Использование EfficientNet
Заметьте, что EfficientNet'ы с предобученными весами, полученными в результате само-тренировки с "Шумным Студентом", обозначены суффиксом *ns.
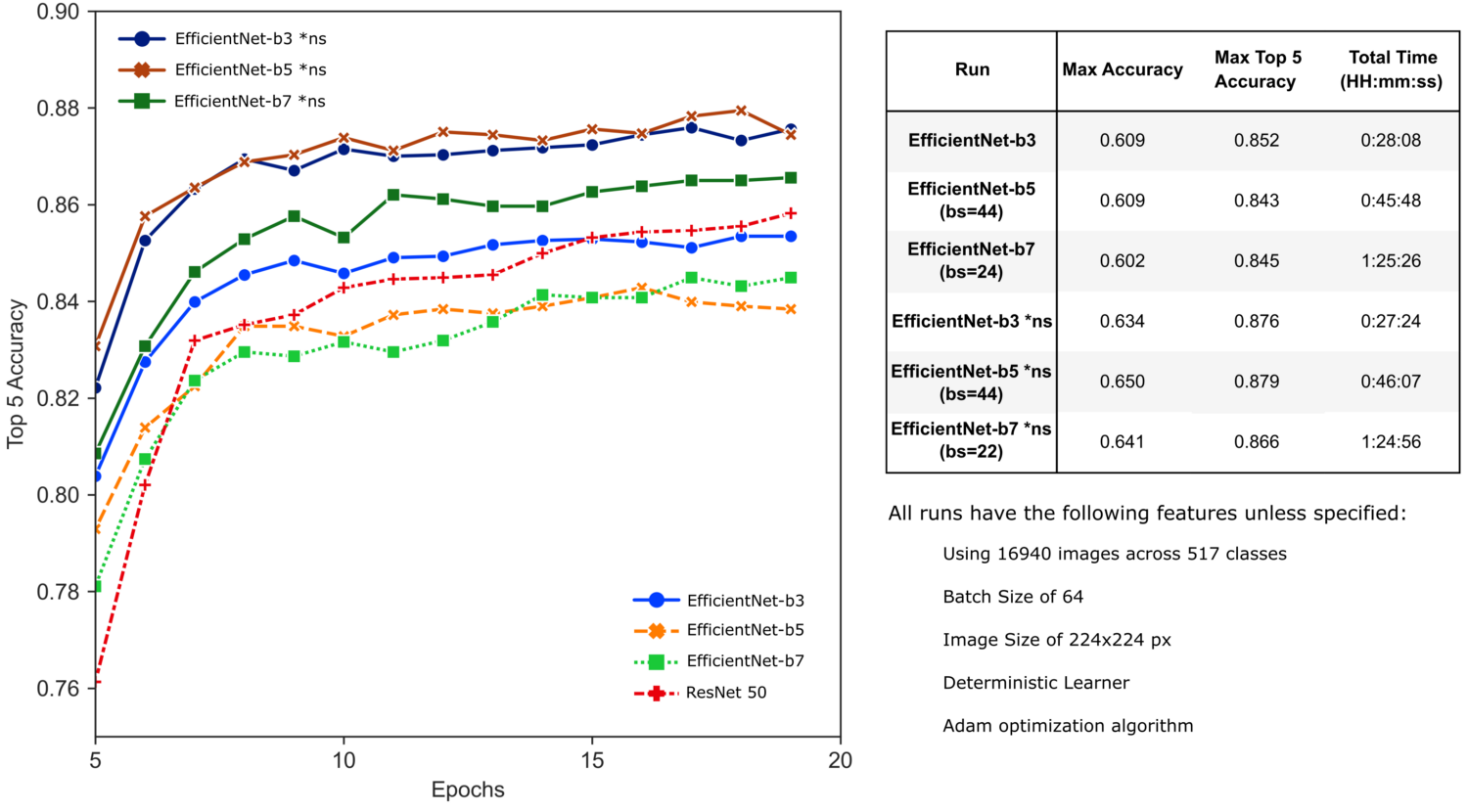
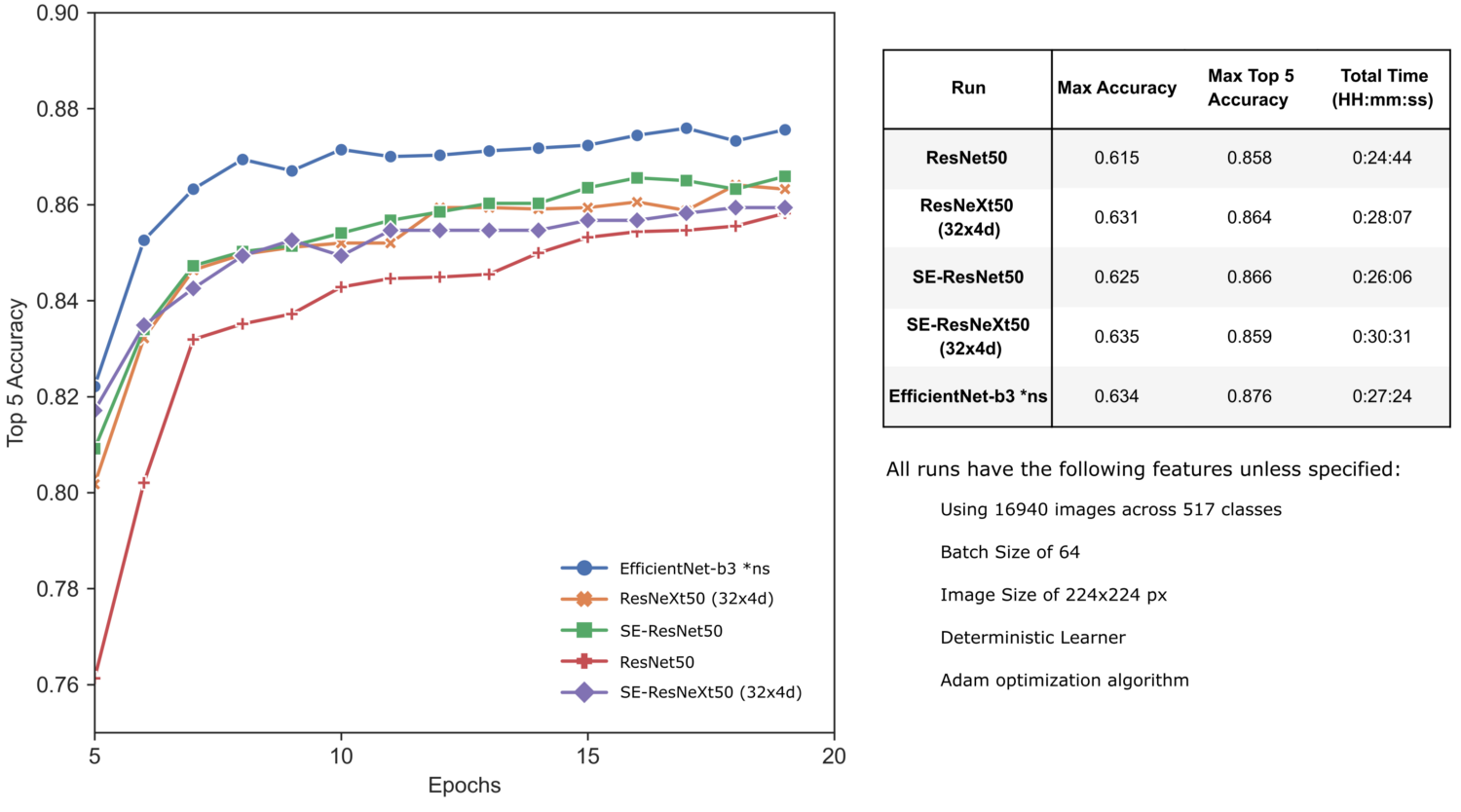
Интересно, что модели EfficientNet, использующие предобученные веса, конвертированные из TensorFlow, показывают сравнительно худшие результаты – возможно, вследствие предобучения на изображениях других размеров или влияния изменения размера пакета (batch size). Однако при использовании предобученных весов "Шумного Студента" результаты нашего обучения с заимствованием существенно улучшаются. Модели EfficientNet-b3 и -b5 действительно обеспечивают лучшую производительность за отведенное время обучения, а модель EfficientNet-b5 превосходит SE-ResNeXt101 на нашей задаче.
Заключение
Важно отметить, что все показанные здесь результаты получены без настройки важных гиперпараметров – таких, как скорость обучения или количество эпох. И в самом деле, в большинстве случаев потери обучения и валидации имеют тенденцию к снижению в конце обучения, что свидетельствует о наличии дальнейшего потенциала для обучения. Кроме того, мы не применяли k-fold кросс-валидацию, и представлены результаты единственного прогона каждой модели.
Тем не менее, мы все-таки можем видеть общую тенденцию улучшения точности нашего классификатора по мере перехода от одной модели к другой, каждая из которых предлагает несколько улучшений и дополнений архитектуры сверточных нейронных сетей.
Ссылки
ResNet
- Подробное руководство к пониманию и реализации ResNet'ов
- Обзор ResNet и его вариантов
- Описание глубоких остаточных нейронных сетей
- Описание и визуализация ResNet'ов
xResNet
SE-ResNet
- Нейронные сети сжатия-и-стимуляции
- Обзор: SENet – нейронная сеть сжатия-и-стимуляции, победитель ILSVRC 2017 (классификация изображений)
ResNeXt
- Обобщенные остаточные трансформации для глубоких нейронных сетей
- Обзор: ResNeXt – первый в ILSVRC 2016 (классификация изображений)
- Обзор ResNet и его вариантов
EfficientNet
- EfficientNet от Google – оптимально масштабируем архитектуры сверточных нейронных сетей с помощью "комбинированного масштабирования"
- EfficientNet – правильное масштабирование сверточных нейронных сетей
- Передовой алгоритм классификации изображений: FixEfficientNet-L2
- EfficientNet – переопределяем масштабирование моделей сверточных нейронных сетей
Комментарии