
Рассказ пойдёт от имени бэкенд-разработчика. Несмотря на горизонтальную масштабируемость архитектуры с очередями, воркерами и stateless-интерфейсами, временами база данных становится слабым местом, поскольку некоторые программисты пишут такие запросы, что страшно глянуть.
Посмотрите на следующий план запроса, в котором найдёте и CTE, и APPEND, и GROUP BY, и ORDER BY. Представьте, каково это оптимизировать.

Обсудим обыкновенные запросы в упрощённом варианте.
Пересмотрите схему данных
В первом примере разработчик сохраняет JSON в словаре – в PostgreSQL это тип hstore. Дальше разворачивает значение в строку внутри подзапроса, а во внешнем запросе делает поиск поля token и сравнивает его с конкретным параметром.

Такие операции приводят к последовательному сканированию (SeqScan) всей таблицы. Какое оправдание нашёл человек: из-за JSON внутри hstore индекс не сделаешь, то есть не оптимизируешь.
Решение оказалось простым. Анализ показал, что JSON с таким токеном у нас меньше 1%, поэтому колонку убрали и вынесли таблицу в отдельную сущность.
Осторожнее с CTE
Часто разработчики заблуждаются насчёт CTE-команды WITH: это не представление (VIEW), которое подставляется в следующий запрос. Вначале исполняется WITH, а только потом его результат передаётся в другой запрос. Поэтому такой запрос сканирует все документы на диске, чтобы во внешнем запросе разработчик получил единственный необходимый файл:

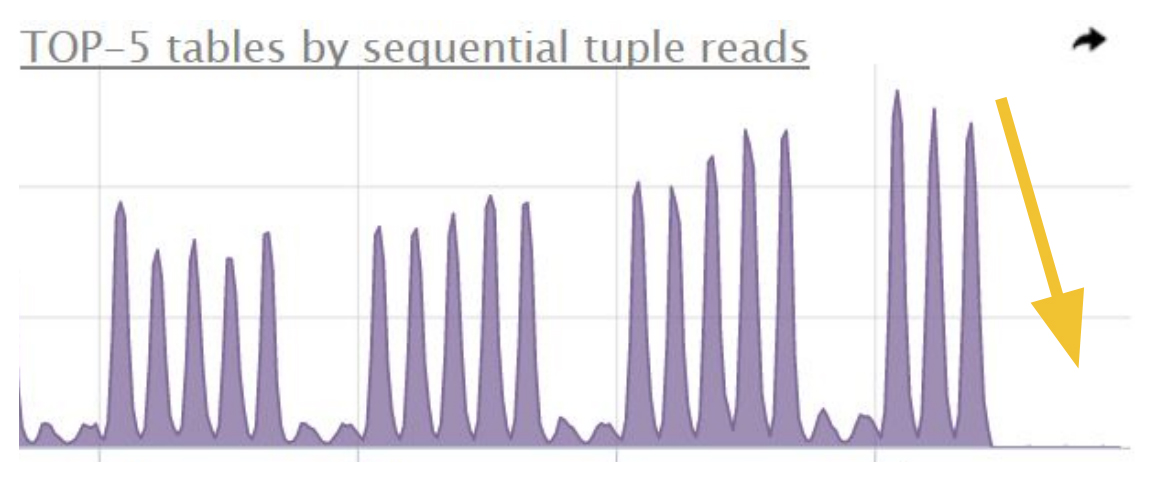
Как уменьшить выборку WITH из кучи строк до одной? Перенесите туда проверку условия. По этому полю был маленький индекс B-Tree.

Результат такой оптимизации:
Избавляйтесь от лишних данных
Рассмотрим хранение ненужных данных на примере списка системных новостей. Представьте, разработчик вносит в отдельную колонку типа hstore список идентификаторов пользователей, подписавшихся на показ этой новости – людей сотни тысяч. Пришло время, когда один пользователь устроил глобальную отписку, и без проверки выполняется вот такой запрос:
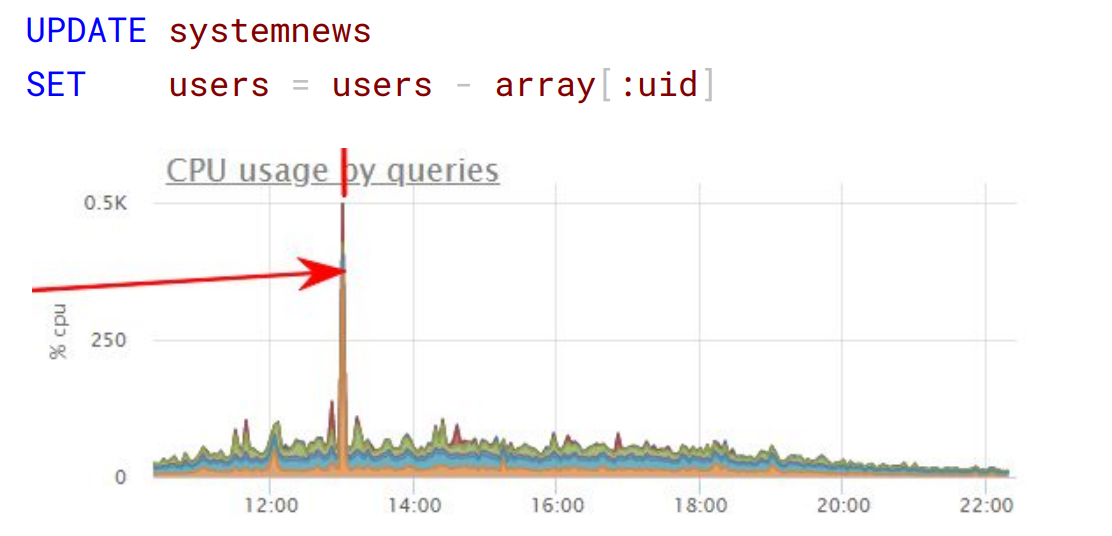
Так как в PostgreSQL при обновлении записи оригинал помечается на удаление и создаётся новая строка, подобный запрос по факту скопировал почти всю таблицу с гигабайтами данных, нагрузив диск и процессор.
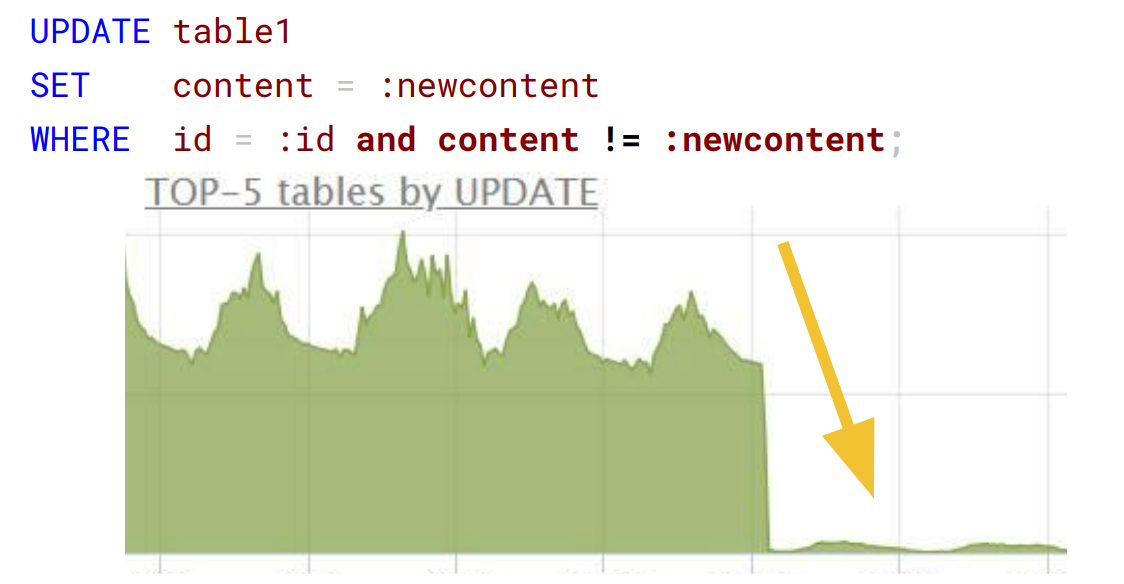
Что не так с этим запросом? На первый взгляд, идеальное обновление по первичному ключу:

На самом деле, запрос рассчитывал метрики на основании действий пользователя в личном кабинете. Но чаще результат расчёта равнялся значению, сохранённому в базе данных, а обновления становились бесполезными. Добавление проверки content != :new content на порядок сократило количество UPDATE:
Проверьте код на бэкенде
Следующий пример безобидного запроса: установка нового значения и ключа в hstore. Проблема в том, что разработчик запускал этот запрос при итерации, добавляя туда кучу новых идентификаторов. В масштабе 100 тысяч пользователей словарь увеличивался и давал непомерную для конкретного сервиса нагрузку:
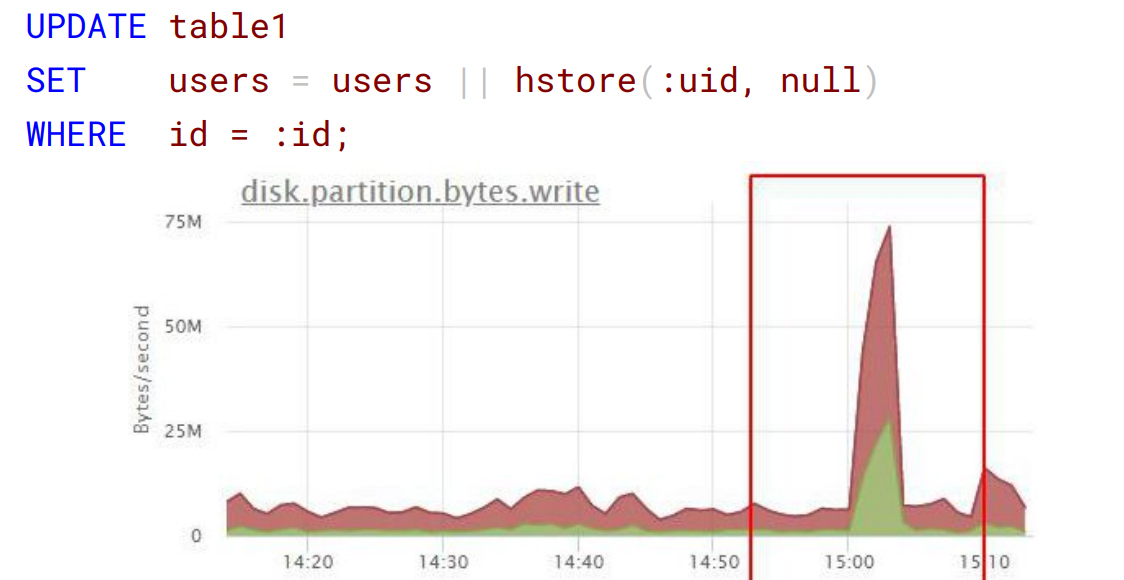
Вариант оптимизации – сформировать на бэкенде один запрос и отправить сразу все изменения в базу.
Следите за размерами IN
Иногда разработчик, казалось бы, оправданно делает гигантский запрос, вместо того чтобы тысячу раз обращаться к базе данных в цикле за дополнительной информацией:

Но здесь подвела куча индексов в одной таблице. Между индексом на companyid и простым B-Tree на companyid + groupname PostgreSQL выбрал первое: прочитал миллионы операций по companyid и отфильтровал результат по groupname. Хотя groupname содержал всего тысячу элементов.
Для решения проблемы сперва уменьшили индекс, поскольку groupname встречался не у всех компаний:

При детальном анализе кода обнаружилось, что дополнительная информация нужна в редких случаях, поэтому запрос наоборот перенесли в ветвления цикла. Несмотря на увеличение количества запросов, скорость возросла, потому что из большого IN получили одноэлементный.
Исправляйте структуру запроса
Помните пример с системными новостями? Рассмотрим похожий, только с привязкой к двум сущностям: пользователям и компаниям.
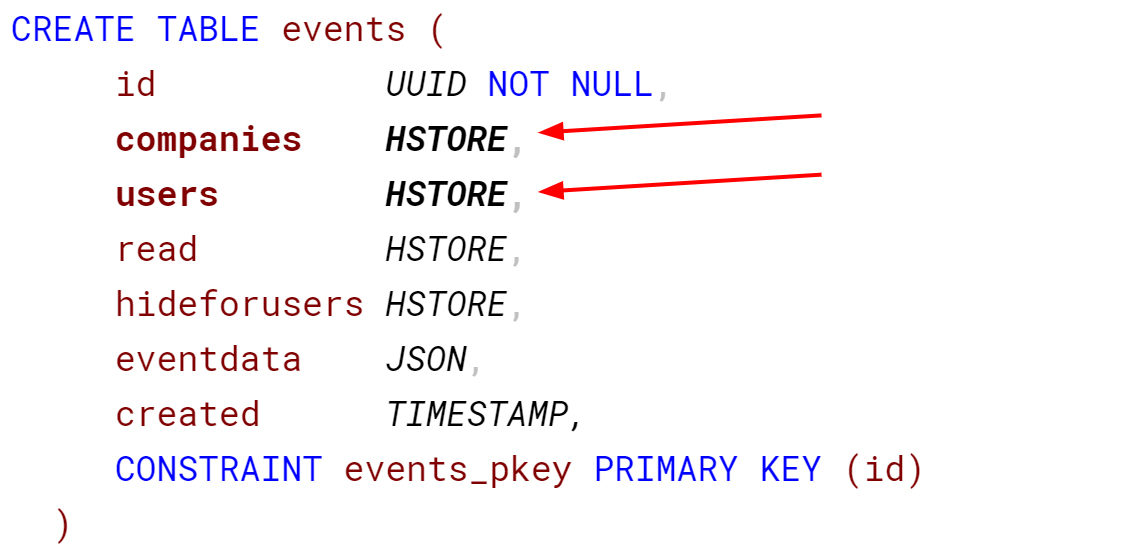
Чтобы пользователь при входе в личный кабинет видел свои сообщения, а попадая в компанию – соответствующее окружение, написали такой запрос:

На hstore навешивают GIN-индекс, который возвращает битовую карту, или при большом количестве данных – слабую карту с идентификаторами страниц. Но выполнение сортировки для компании с сотней тысяч записей переполнило рабочую память и привело к такому сумасшествию на диске:
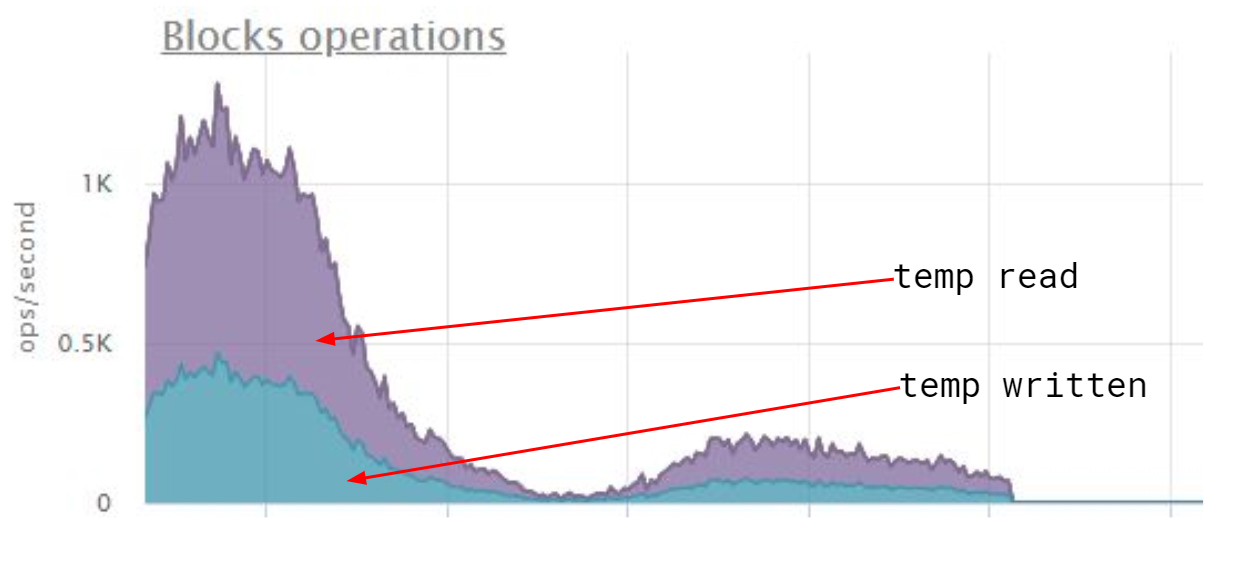
Поскольку GIN-индекс хранит данные без определённого порядка, пришлось исправить структуру запроса: когда сделали первичным ключом userid + companyid + id, скорость выполнения выросла на глазах.

Назначайте тайм-ауты
Для некоторых запросов медленная скорость – нормальное явление. Представьте: ваш сервис делает расчёты и собирает отчёт по конкретным категориям, а пользователь сам выбирает период для выборки.
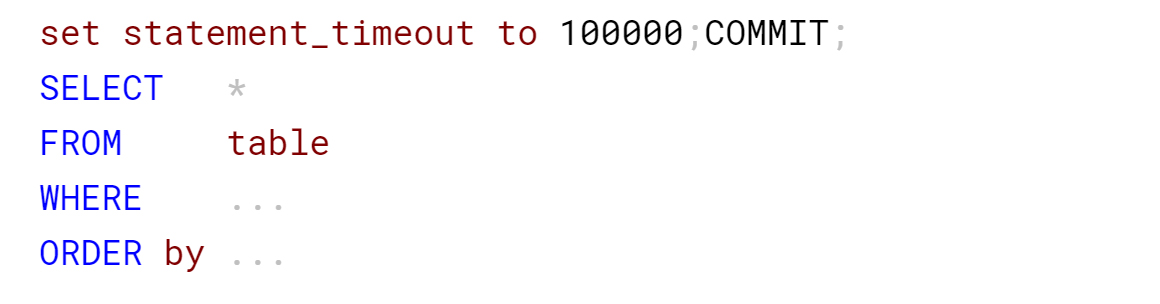
Стояло ограничение времени выполнения в 100 секунд на SQL Provider: через заданное время прилетала ошибка сервера баз данных, на что пользователь повторял запрос. Но при этом провайдер не завершал первый запрос, и на сервере выполнялось уже два одинаковых тяжёлых запроса, которые боролись за системные ресурсы.
Как удалось заставить провайдер завершать запрос по истечении тайм-аута? Установили переменную сессии statement_timeout в 100 секунд.
Проверяйте на существование правильно
Когда разработчикам говорят проверить существование хоть одной записи в базе данных, некоторые вычисляют общее количество строк с проверкой кучи условий и пишут return count > 0:

Вместо этого используйте EXISTS с константой, поскольку оператор завершает запрос, как только встретит подходящую запись:

Используйте BRIN-индекс
Иногда от бизнеса прилетает задание посчитать общее количество. Вы хоть раз интересовались, сколько получили всего сообщений на почте или в мессенджере? А кому-то подобное понадобилось, и запрос выглядел жутко:
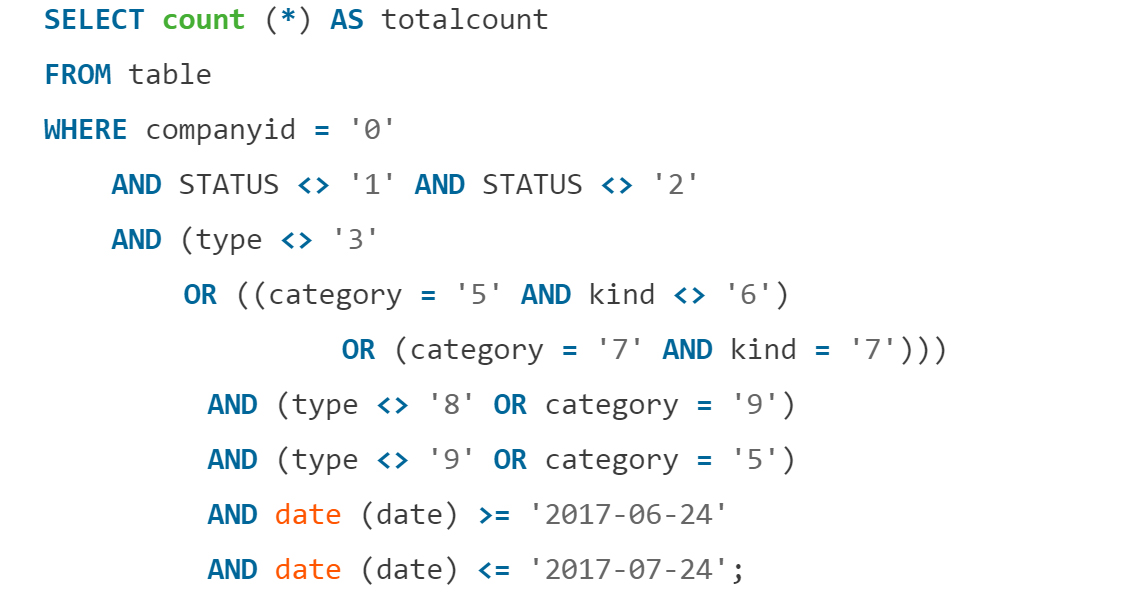
Позднее выяснилось, что в пользовательском интерфейсе эта информация не выводится, потому как фронтенд-разработчики убрали её при редизайне, тем самым сделали оптимизацию.
А если итоговое количество нужно? Например, в админке сайта человек анализирует посещаемость в определённые периоды. Такой запрос выполняется медленно без индекса по дате:
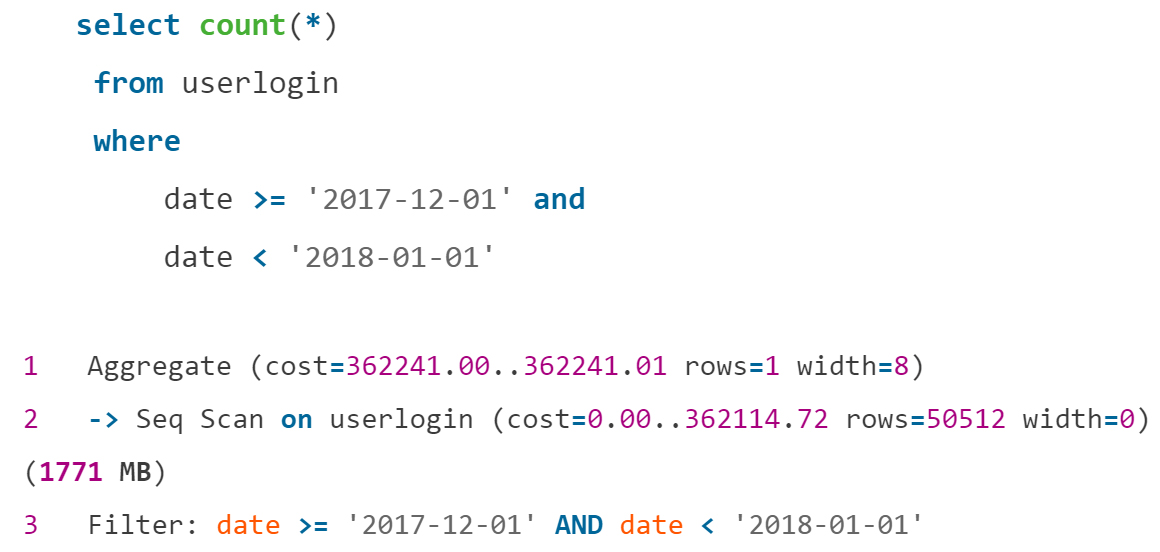
Но целесообразно ли навешивать огромный индекс B-Tree на маленькую табличку? Последовательное сканирование занимало здесь 5–6 минут. На помощь пришёл Block Range Index (BRIN). BRIN-индекс возвращает номера страниц с подходящими данными и выполняет проверку всей страницы на соответствие условиям.

Поскольку он не хранит идентификаторы строк и значения, его размер гораздо меньше: у BRIN-индекса – 72 KB, а для сравнения, у B-Tree – 216 Mb.
Вот результат оптимизации с помощью BRIN-индекса:
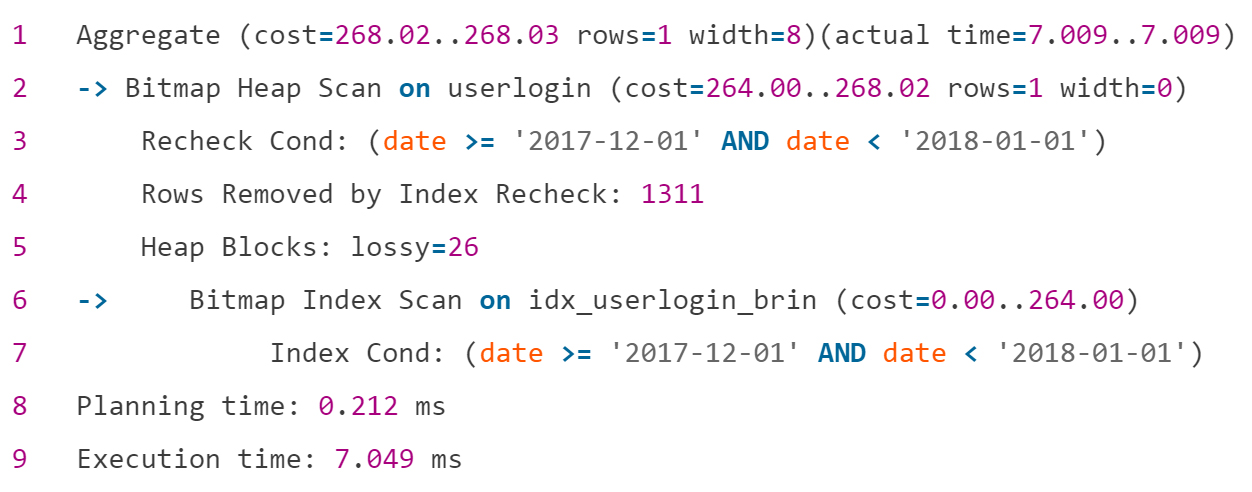
Такой маленький индекс легко поддерживать и удобно использовать, когда значения колонок и физическое расположение на диске коррелируют, например, для журнала. Документация рекомендует создавать этот индекс на много колонок, если фильтруете по ним. И тогда в связке с операцией AND в условиях вы получите быструю скорость выполнения.
Сокращайте количество сохраняемой информации
Уменьшайте не только индексы, но и таблицы. Допустим, в одной колонке у вас JSON со старыми данными, а в другой – с новыми.
Вместо того, чтобы сохранять кортеж полностью, избавьтесь от дефолтных значений типа NULL и пустой строки. Во вторую колонку записывайте только изменённые значения. Это сэкономит не только место на диске, но и время на резервное копирование.

Как ещё уменьшить время на бэкапы? Замените тип timestamp на date, если время в таблице нулевое. Так, разработчики получили экономию 1,3 гигабайт на пустом месте и сократили время на ежедневное резервное копирование.

Оптимизируйте LIKE
Некоторые считают, что для запроса с LIKE нельзя создать индекс. Мнение ошибочное, и здесь вам пригодится индекс SP-GIST, который разделит значения на отдельные группы. Для строк он создаст отдельные ветки на каждую букву:
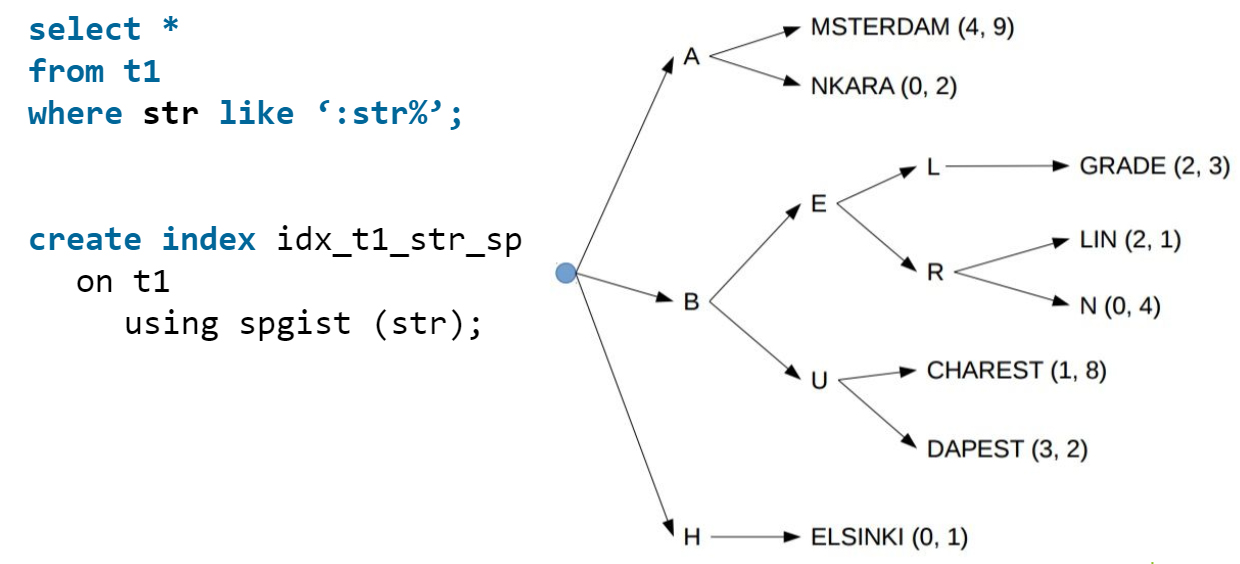
SP-GIST подойдёт для списков товаров, услуг, городов или других строк. При автодополнении на сайте вы передаёте в запрос перед знаком % то, что ввёл пользователь, а планировщику даже не придётся лезть в кучу, ведь все данные уже в индексе.
А что, если искомое в справочнике слово идёт не с начала строки? Используйте GIN-индекс, похожий на алфавитный указатель в книге: он указывает номера страниц, где вы вручную ищете нужное слово.

В результате уйдёте от последовательных сканов и получите ускорение запроса в несколько раз:
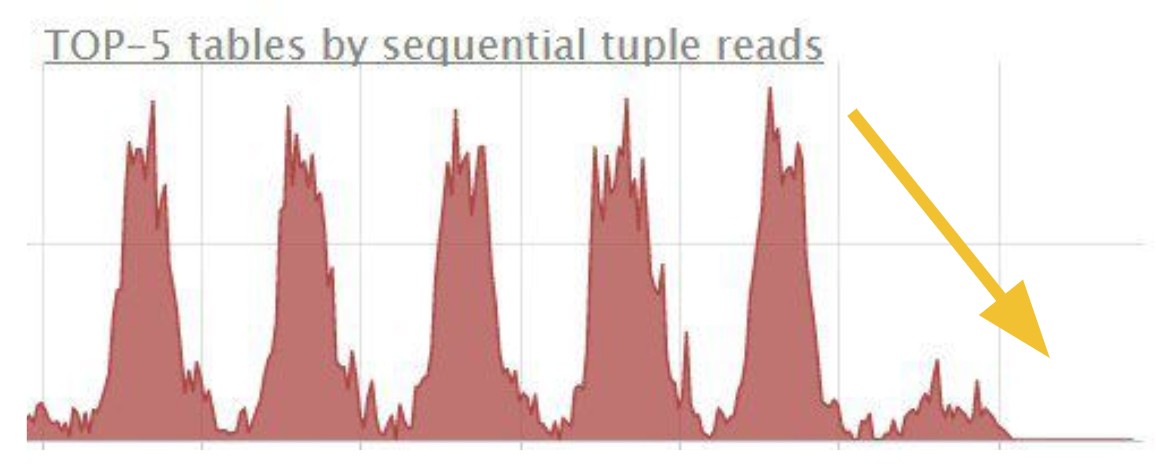
Применяйте Partial index
Partial index – индексы c ограничением по условию. Представьте, что нужна проверка операций компании за последний год по двум постоянным условиям:
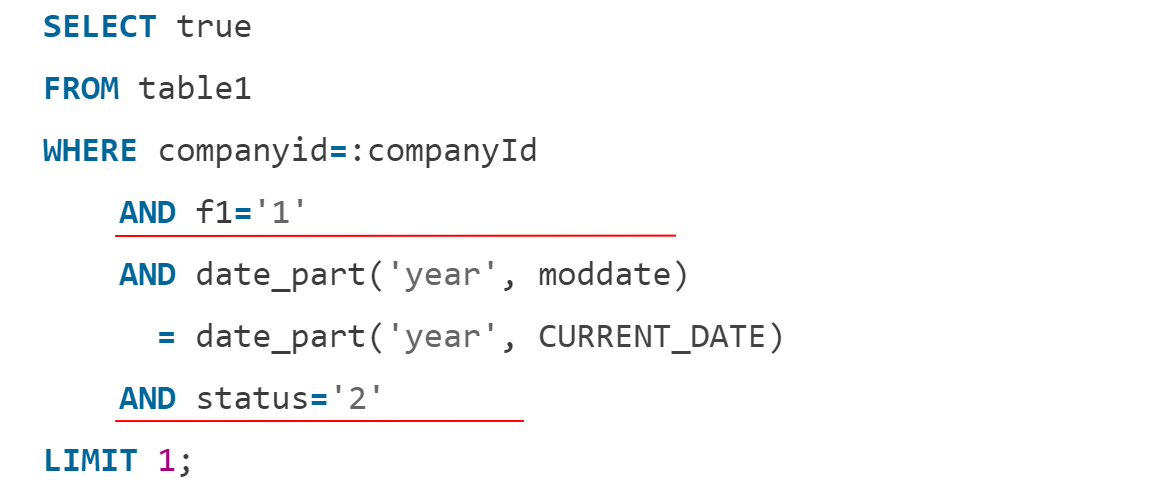
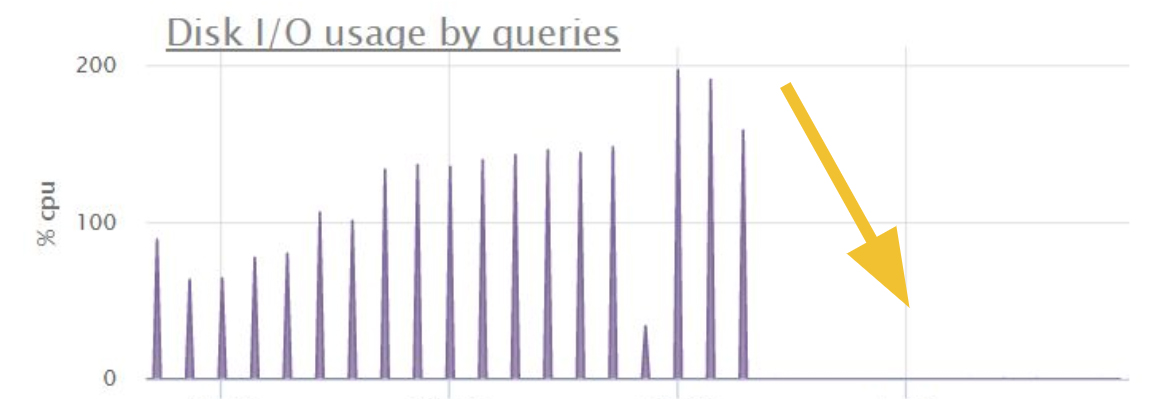
Вместо написания предварительного обработчика с очередью и проверками, создайте маленький индекс с отобранными по условию значениями:

Тогда запрос начнёт выполняться только по индексу, а использование диска упадёт до нуля:
Разберитесь со сложной сортировкой
У продуктов встречаются очень сложные правила сортировки:
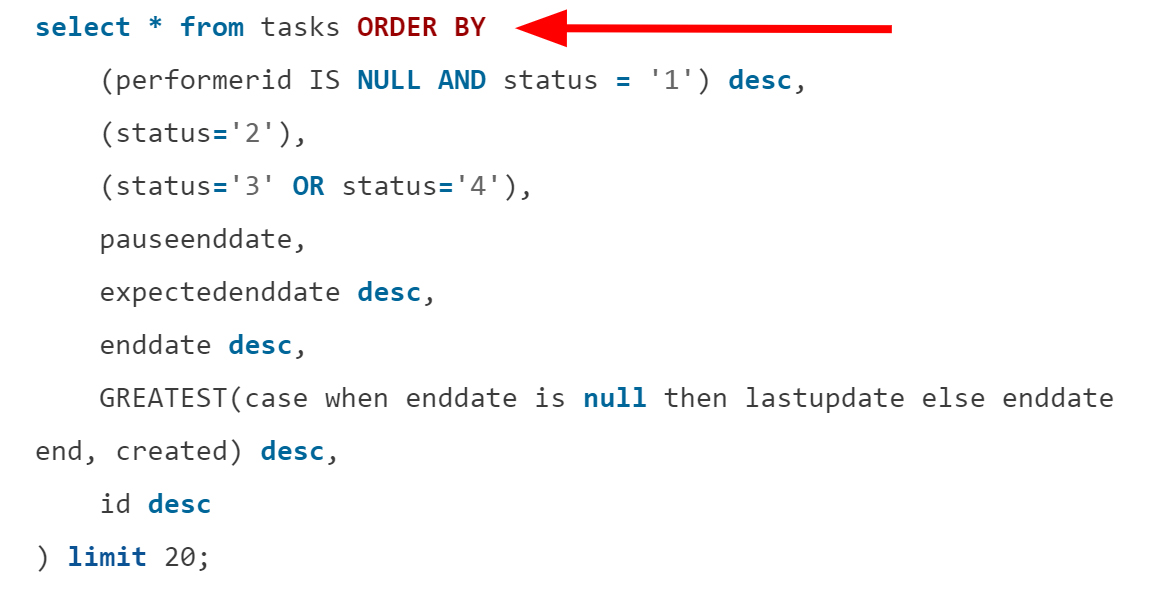
И первым делом разработчики пытаются оптимизировать фильтрацию WHERE. В такой ситуации рассмотрите создание индекса для сложной сортировки. Для примера выше такая оптимизация сократила время выполнения и количество сканов:
В стремлении написать всё зараз не забывайте, что подзапросы и UNION обходятся недёшево. Посмотрите на запрос:

Когда в таблице больше сотен тысяч подходящих записей, на этапе сортировки диск упадёт. А нужно было 20 элементов.
Для решения вопроса создают отдельную таблицу или назначают единственную из необходимых мастер-таблицей. Переносите в неё данные из остальных таблиц под другими категориями и получаете обыкновенный select * from mastertable вместо объединений.
Анализируйте код и планы запросов
Когда вы приходите к необходимости создания hints для планировщика запросов или костылей, чтобы объяснить PostgreSQL, что делать, то пересмотрите собственную схему и код. Возможно, там придётся всё менять.
Поскольку план запроса на локальной машине, в тестовой среде и в продакшене сильно отличается, то для анализа планов в проде включают модуль auto_explain. Вы задаёте время выполнения, превышение которого будет сигналом для логирования запроса.
Для получения более детальной информации разработчикам нужны логи с продакшена. Чтобы разобраться, скормите логи утилите pgbadger и увидите отчёт.
Заключение
Как видите, нагрузить базу данных на ровном месте проще простого. Иногда разработчики используют тяжёлые конструкции и принимают неверные решения по незнанию. Не бойтесь изменения схемы базы данных, избавляйтесь от лишней информации, перепроверяйте код и структуру запросов, а также создавайте индексы.
Комментарии