

Кэширование – это техника, которая ускоряет работу приложений, снижает нагрузку на базу данных и улучшает пользовательский опыт. Однако память кэша ограничена, и в ней невозможно хранить все. Стратегии вытеснения кэша определяют, какие элементы будут удалены из кэша, когда место заканчивается. Здесь мы рассмотрим 7 основных стратегий.
Вытеснение давно использованных элементов (LRU)
Алгоритм вытеснения LRU (Least Recently Used) удаляет элемент, который дольше всего не использовался. Предполагается, что если к элементу давно не обращались, то вероятность его использования в ближайшее время мала.
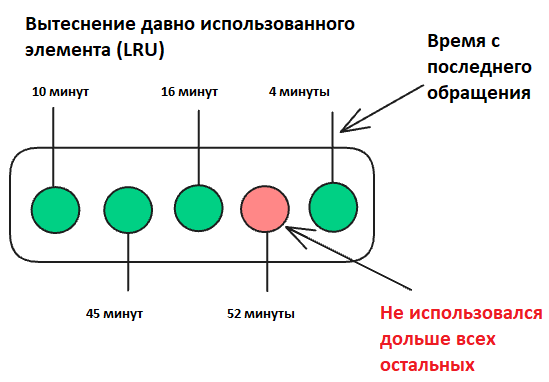
Как работает LRU
1. Отслеживание времени доступа:
LRU запоминает, когда каждый элемент кэша был использован последний раз. Для этого часто используют:
- Двусвязный список – для управления порядком элементов.
- Хеш-таблицу – для быстрого поиска элементов.
2. Элемент найден в кэше
Если элемент найден в кэше, он становится наиболее недавно использованным. В двусвязном списке он перемещается в начало.
3. Элемент отсутствует в кэше
- Если в кэше есть свободное место – новый элемент просто добавляется.
- Если кэш переполнен, удаляется элемент из конца списка, поскольку он является наименее востребованным.
Пример работы LRU с кэшем на 3 элемента
- Начальное состояние: кэш пустой.
- Добавляем A: [A].
- Добавляем B: [A, B].
- Добавляем C: [A, B, C] (кэш заполнен).
- Используем A: [B, C, A] (A становится недавно использованным).
- Добавляем D: [C, A, D] – B вытеснен как наименее востребованный.
Преимущества LRU:
- Прост в реализации и широко применяется.
- Эффективен для частых запросов – часто используемые данные гарантированно остаются в кэше.
- Отлично подоходит для кэширования веб-страниц и API-запросов.
Недостатки LRU:
- Нужно хранить метаданные о порядке использования.
- При большом кэше управление порядком может быть ресурсозатратным.
- Предполагает, что пользователи действуют в соответствии с паттернами, которые остаются более-менее неизменными.
Вытеснение наименее часто используемых элементов (LFU)
Алгоритм LFU (Least Frequently Used) удаляет из кэша элемент с наименьшей частотой доступа, предполагая, что если элемент редко использовался ранее, вероятность его использования в будущем низка.
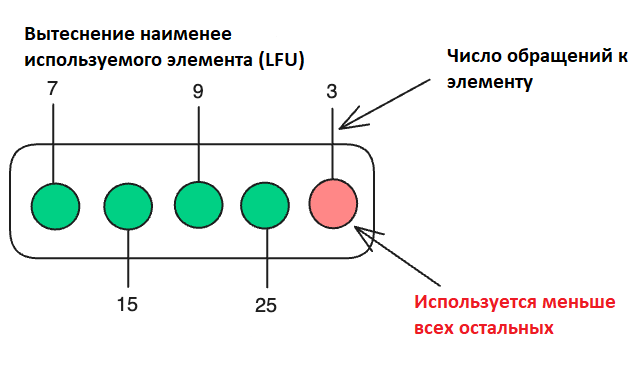
Как работает LFU
1. Отслеживание частоты доступа
Для каждого элемента в кэше сохраняется счетчик обращений, который увеличивается при каждом доступе.
2. Элемент найден в кэше
При обращении к элементу его частота увеличивается на 1.
3. Элемент отсутствует в кэше
- Если есть свободное место – добавить новый элемент с частотой 1.
- Если места нет – удалить элемент с наименьшей частотой доступа.
- Если несколько элементов имеют одинаково низкую частоту использования, нужно применить дополнительную стратегию, например, удалить самый старый по времени использования или самый первый добавленный.
Пример работы LFU (кэш размером 3)
- Начальное состояние: кэш пустой.
- Добавляем A: [A (freq=1)].
- Добавляем B: [A (freq=1), B (freq=1)].
- Добавляем C: [A (freq=1), B (freq=1), C (freq=1)].
- Доступ к A: увеличиваем частоту A, получаем [A (freq=2), B (freq=1), C (freq=1)].
- Добавляем D: кэш переполнен. Удаляем элемент с минимальной частотой. У B и C одинаковая частота – 1, поэтому удаляем B по принципу LRU или FIFO: [A (freq=2), C (freq=1), D (freq=1)].
- Доступ к C: увеличиваем частоту C, получаем [A (freq=2), C (freq=2), D (freq=1)].
Преимущества LFU:
- Эффективен для предсказуемых паттернов.
- Хорошо удерживает самые востребованные элементы.
Недостатки LFU:
- Высокие затраты на память (нужно хранить счетчики частоты для каждого элемента).
- Увеличение счетчиков при каждом доступе может снижать производительность.
- Плохая адаптивность – сохраняет элементы, которые были популярны давно, но сейчас уже не нужны.
«Первым пришел, первым ушел» (FIFO)
«Первым пришел, первым ушел» FIFO (First In, First Out) – стратегия управления кэшем, при которой первым удаляется элемент, который был добавлен раньше других, независимо от того, насколько часто он использовался. Этот метод предполагает, что самые старые элементы будут менее востребованы, когда кэш заполнится.
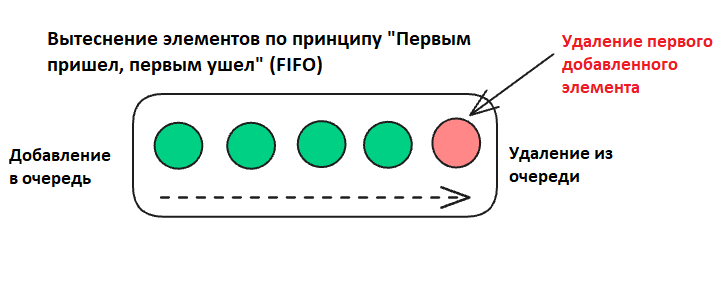
Как работает FIFO
1. Новый элемент добавляется в конец очереди.
2. Элемент найден в кэше
Если запрошенный элемент найден в кэше, порядок очереди остается неизменным. В отличие от других стратегий, FIFO не учитывает время или количество обращений.
3. Элемент отсутствует в кэше
- Если в кэше есть место, новый элемент добавляется в конец очереди.
- Если кэш полон, удаляется самый старый элемент (из начала очереди), чтобы освободить место.
Пример работы FIFO с кэшем емкостью 3
- Добавляем A: [A]
- Добавляем B: [A, B]
- Добавляем C: [A, B, C]
- Добавляем D: [B, C, D] (A удален, так как он был добавлен первым)
- Обращаемся к B: [B, C, D] (порядок не меняется)
- Добавляем E: [C, D, E] (B удален как самый старый оставшийся элемент)
Преимущества FIFO:
- Алгоритм легко реализовать через структуру данных очередь.
- Нет необходимости отслеживать частоту или давность использования элементов.
- Удаление происходит всегда по одному и тому же принципу – первым уходит самый старый элемент.
Недостатки FIFO:
- Игнорирует частоту использования (востребованные элементы могут быть удалены, что снижает эффективность кэша).
- Неоптимальность для большинства сценариев – в реальных системах обычно важнее учитывать последние обращения (LRU) или частоту (LFU).
Случайное вытеснение (RR)
Случайное вытеснение RR (Random Replacement) – это самая простая стратегия управления кэшем, при которой при переполнении кэша для освобождения места удаляется случайный элемент, независимо от частоты использования или времени добавления.
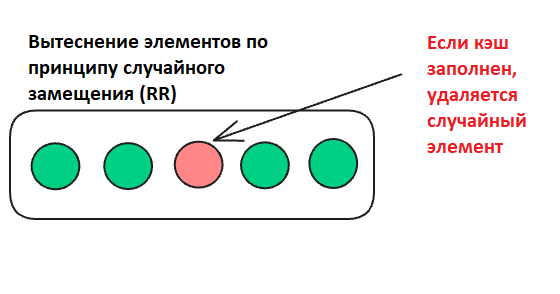
Как работает RR
1. Добавление элемента
Если в кэше есть место, новый элемент просто добавляется.
2. Элемент найден в кэше
Если запрошенный элемент найден в кэше, он используется без изменений порядка или состава кэша.
3. Элемент отсутствует в кэше
Если элемент отсутствует, а кэш полон:
- Удаляется случайный элемент.
- Новый элемент занимает освободившееся место.
Пример работы RR с кэшем на 3 элемента
- Добавляем A: [A].
- Добавляем B: [A, B].
- Добавляем C: [A, B, C].
- Добавляем D: [B, C, D] (A удален случайно).
- Добавляем E: [C, E, D] (B удален случайно).
Преимущества RR:
- Простота реализации – нет необходимости учитывать частоту или время обращения.
- Минимальная нагрузка.
- Подходит для хаотичных или непредсказуемых паттернов доступа.
Недостатки RR:
- Важные и часто используемые элементы могут быть случайно удалены.
- Неэффективность при стабильных паттернах доступа – если определенные данные запрашиваются регулярно, их случайное удаление снижает эффективность кэша.
- Из-за случайного подхода к удалению кэш может удерживать ненужные элементы.
Вытеснение самого последнего использованного элемента (MRU)
«Последним использован, первым удален» – это стратегия управления кэшем, противоположная LRU: при заполнении кэша и необходимости освободить место, MRU (Most Recently Used) удаляет элемент, который был использован самым последним. Логика здесь в том, что недавно использованный элемент, возможно, был нужен только временно и не понадобится в ближайшее время.
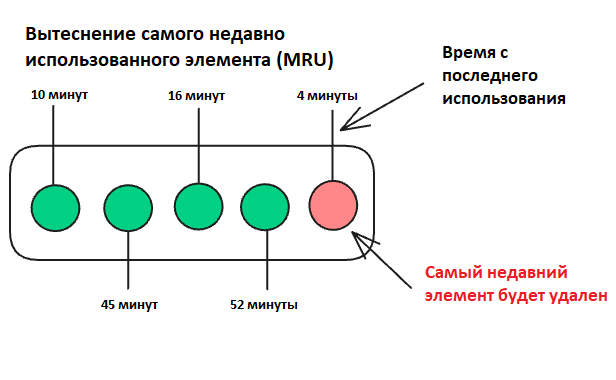
Как работает MRU
1. Добавление элемента
Новый элемент добавляется в кэш и помечается как последний использованный (MRU).
2. Элемент найден в кэше
Если запрошенный элемент найден, он становится последним использованным (MRU).
3. Элемент отсутствует в кэше
- Если есть свободное место – новый элемент просто добавляется.
- Если кэш полон – удаляется последний использованный (MRU) элемент, чтобы освободить место для нового.
Пример работы MRU с кэшем на 3 элемента
- Добавляем A: [A]
- Добавляем B: [A, B]
- Добавляем C: [A, B, C]
- Обращаемся к C: [A, B, C] (C – самый недавно использованный)
- Добавляем D: [A, B, D] (C удален, т. к. он был MRU)
- Обращаемся к B: [A, B, D] (B – теперь MRU)
- Добавляем E: [A, D, E] (B удален, т. к. он был MRU)
Преимущества MRU:
- Эффективен, когда ценные данные – это более старые записи, а недавние нужны временно.
- Простота реализации – требует минимального отслеживания порядка использования.
- Легко реализовать с помощью стека.
Недостатки MRU:
- Не подходит для большинства сценариев – во многих системах недавно использованные данные остаются востребованными.
- Если паттерны доступа повторяются, кэш будет терять нужные элементы.
- Уступает по эффективности алгоритмам LRU и LFU.
Время жизни элемента в кэше (TTL)
Time to Live (TTL) – стратегия управления кэшем, при которой каждому элементу назначается срок жизни. После окончания этого срока элемент автоматически удаляется из кэша, независимо от того, использовался он или нет. TTL активно используется в системах кэширования, к примеру, в Redis и Memcached.
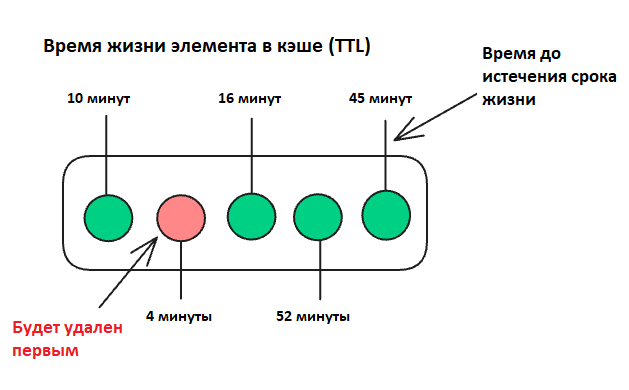
Как работает TTL
1. Добавление элемента
При добавлении элемента ему назначается TTL (например, 5 секунд). Время истечения срока жизни рассчитывается как текущее время + TTL.
2. Доступ к элементу
- Если элемент найден, но TTL истек – элемент удаляется из кэша.
- Если TTL еще действует – элемент возвращается.
3. Удаление элемента
Элементы удаляются:
- При обращении (ленивая очистка кэша) – если срок истек во время запроса.
- Периодически (запланированная очистка) – с помощью фоновых задач.
Пример работы TTL с кэшем (TTL = 5 секунд):
- Добавляем A (TTL = 5s): [A (5s)]
- Добавляем B (TTL = 10s): [A (5s), B (10s)]
- Через 6 секунд: [B (осталось 4s)] (A удален, т. к. TTL истек)
- Добавляем C (TTL = 5s): [B (4s), C (5s)]
- Обращаемся к A: элемент не найден, так как A уже удален.
Преимущества TTL:
- Актуальность данных – удаляет устаревшие элементы автоматически.
- Простота настройки – TTL легко назначить при добавлении данных.
- Не требует сложных метрик доступа или частоты использования.
- Подходит для систем, где важна свежесть информации (например, кэширование цен, данных API).
Недостатки TTL:
- Фиксированный срок жизни – элементы могут удаляться, даже если они остаются востребованными.
- Элементы с большим TTL занимают память, даже если они больше не нужны.
- Не учитывает шаблоны паттерны или частоту использования.
Двухуровневое кэширование
Двухуровневое кэширование TTC (Two-Tiered Caching) сочетает два уровня кэша – локальный (в памяти) и удаленный (распределенный или общий):
- Локальный кэш – первый уровень («горячий» кэш), который обеспечивает сверхбыстрый доступ к часто используемым данным.
- Удаленный кэш – второй уровень («холодный» кэш), используемый для данных, которых нет в локальном кэше, но которые нужно отдавать быстрее, чем из базы данных.
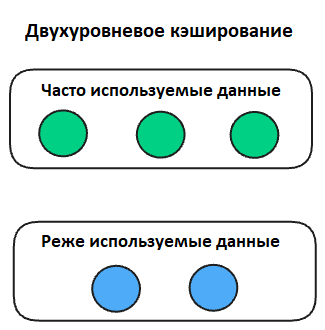
Как работает двухуровневый кэш
1. Локальный кэш (первый уровень):
- Располагается на том же сервере, где работает приложение (чаще всего – в оперативной памяти).
- Обеспечивает максимально быстрый доступ к часто используемым данным и снижение нагрузки на сервер.
Примеры:
- Структуры данных в памяти – хэш-таблицы, LRU-кэш.
- Библиотеки и фреймворки – Guava Cache (Java).
Удалeнный кэш (второй уровень):
- Располагается на отдельном сервере или кластере серверов.
- Представляет собой общий кэш для нескольких приложений.
- Доступ к данным медленнее, чем у локального кэша.
- Позволяет кэшировать большие объемы данных.
Пример – распределенные системы кэширования (Redis, Memcached).
Процесс работы двухуровневого кэша
1. Запрос клиента → проверка локального кэша:
- Если данные найдены, то они возвращаются мгновенно.
- Если не найдены – переходим к следующему шагу.
2. Проверка удаленного кэша:
- Если данные найдены, то они возвращаются и сохраняются в локальном кэше для будущих запросов.
- Если не найдены – переходим к следующему шагу.
3. Запрос к основной базе данных:
- Полученные данные возвращаются клиенту.
- Одновременно данные сохраняются в локальном и удаленном кэшах.
Преимущества двухуровневого кэширования:
- Быстрый доступ – локальный кэш обеспечивает моментальный ответ для часто запрашиваемых данных.
- Масштабируемость – удаленный кэш позволяет хранить больше данных и делиться ими между серверами.
- Снижение нагрузки на базу данных – большинство запросов обслуживается из кэша, уменьшая число обращений к БД.
- Отказоустойчивость – если локальный кэш выйдет из строя, данные будут получены из удаленного кэша.
Недостатки двухуровневого кэширования:
- Сложность управления – требуется синхронизация между двумя уровнями кэша.
- Проблема устаревших данных – если данные обновились в одном кэше, но не в другом, клиент может получить старую версию.
- Задержки при работе с удаленным кэшем – запросы ко второму уровню выполняются медленнее из-за сетевых задержек.
Подведем итоги
Выбор стратегии вытеснения кэша зависит от особенностей приложения, характера нагрузки и паттернов доступа к данным: LRU и LFU подходят для сценариев с предсказуемыми запросами, FIFO и RR пригодятся в простых системах, TTL эффективно поддерживает актуальность данных, а двухуровневое кэширование обеспечивает баланс скорости и масштабируемости. Используя подходящую стратегию или их комбинацию, можно добиться более эффективного использования памяти и улучшить пользовательский опыт.
Комментарии