
Бо Карнс – разработчик и преподаватель расскажет о наиболее часто используемых и общих структурах данных. Специально для вас мы перевели его статью.
«Плохие программисты беспокоятся о коде. Хорошие программисты беспокоятся о структурах данных и их отношениях ». - Линус Торвальдс, создатель Linux
Структуры данных являются важной частью разработки программного обеспечения и одной из наиболее распространенных тем для вопросов на собеседованиях с разработчиками.
Хорошая новость в том, что они в основном являются просто специализированными форматами для организации и хранения данных.
Из этой статьи вы узнаете о 10 наиболее распространенных структурах данных. Также сюда добавлены видеоролики (на английском языке) по каждой из структур, и код их реализации на JS. А чтобы вы немного попрактиковались, я добавил сюда задачи из бесплатной учебной программы freeCodeCamp.
Обратите внимание, что некоторые из этих структур данных включают временную сложность в нотации Big O. Это не относится ко всем из них, поскольку временная сложность иногда основана на реализации. Если вы хотите узнать больше о нотации Big O, посмотрите видео от Briana Marie .
Несмотря на то, что для каждой структуры я привожу код реализации на JavaScript, вам вероятно, никогда не придется делать этого самостоятельно, только если вы не будете использовать низкоуровневый язык вроде С. JavaScript (как и большинство языков высокого уровня) имеет встроенные реализации многих из этих структур данных.
Тем не менее, знание того, как реализовать эти структуры данных, даст вам огромное преимущество в поиске работы и может пригодиться, когда вы попытаетесь написать высокопроизводительный код.
Связные списки
Связный список является одной из самых основных структур данных. Его часто сравнивают с массивом, поскольку многие другие структуры данных могут быть реализованы либо с помощью массива, либо с помощью связного списка. У каждого из них есть свои преимущества и недостатки.
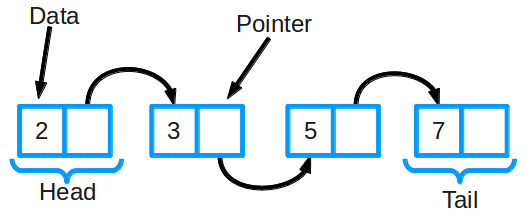
Связный список состоит из группы узлов, которые вместе представляют последовательность. Каждый узел содержит две вещи: фактические данные, которые хранятся (которые могут быть представлены любым типом данных), и указатель (или ссылка) на следующий узел в последовательности. Существуют также дважды связанные списки, в которых каждый узел имеет указатель и на следующий, и на предыдущий элемент в списке.
Самые основные операции в связанном списке включают добавление элемента в список, удаление элемента из списка и поиск в списке для элемента.
Временная сложность связного списка ╔═══════════╦═════════╦══════════════╗ ║ Алгоритм ║В среднем║Худший случай ║ ╠═══════════╬═════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════╩══════════════╝
Задания с freeCodeCamp:
- Work with Nodes in a Linked List
- Create a Linked List Class
- Remove Elements from a Linked List
- Search within a Linked List
- Remove Elements from a Linked List by Index
- Add Elements at a Specific Index in a Linked List
- Create a Doubly Linked List
- Reverse a Doubly Linked List
Стеки
Стек - это базовая структура данных, в которой вы можете только вставлять или удалять элементы в начале стека. Он напоминает стопку книг. Если вы хотите взглянуть на книгу в середине стека, вы сначала должны взять книги, лежащие сверху.
Стек считается LIFO (Last In First Out) - это означает, что последний элемент, который добавлен в стек, - это первый элемент, который из него выходит.

Существует три основных операции, которые могут выполняться в стеках: вставка элемента в стек (называемый «push»), удаление элемента из стека (называемое «pop») и отображение содержимого стека (иногда называемого «pip»).
Временная сложность стека ╔═══════════╦═════════╦══════════════╗ ║ Алгоритм ║В среднем║Худший случай ║ ╠═══════════╬═════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════╩══════════════╝
Задания с freeCodeCamp:
Очереди
Вы можете думать об этой структуре, как об очереди людей в продуктовом магазине. Стоящий первым будет обслужен первым. Также как очередь.

Если рассматривать очередь с точки доступа к данным, то она является FIFO (First In First Out). Это означает, что после добавления нового элемента все элементы, которые были добавлены до этого, должны быть удалены до того, как новый элемент будет удален.
В очереди есть только две основные операции: enqueue и dequeue. Enqueue означает вставить элемент в конец очереди, а dequeue означает удаление переднего элемента.
Временная сложность очереди ╔═══════════╦═════════╦══════════════╗ ║ Алгоритм ║В среднем║Худший случай ║ ╠═══════════╬═════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════╩══════════════╝
Задания с freeCodeCamp:
Множества
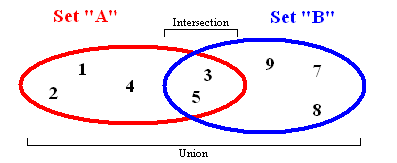
Множества хранят данные без определенного порядка и без повторяющихся значений. Помимо возможности добавления и удаления элементов, есть несколько других важных функций, которые работают с двумя наборами одновременно.
- Union (Объединение). Объединяет все элементы из двух разных множеств и возвращает результат, как новый набор (без дубликатов).
- Intersection (Пересечение). Если заданы два множества, эта функция вернет другое множество, содержащее элементы, которые имеются и в первом и во втором множестве.
- Difference (Разница). Вернет список элементов, которые находятся в одном множестве, но НЕ повторяются в другом.
- Subset(Подмножество) - возвращает булево значение, показывающее, содержит ли одно множество все элементы другого множества.
Задания с freeCodeCamp:
- Create a Set Class
- Remove from a Set
- Size of the Set
- Perform a Union on Two Sets
- Perform an Intersection on Two Sets of Data
- Perform a Difference on Two Sets of Data
- Perform a Subset Check on Two Sets of Data
- Create and Add to Sets in ES6
- Remove items from a set in ES6
- Use .has and .size on an ES6 Set
- Use Spread and Notes for ES5 Set()
Map
Map - это структура данных, которая хранит данные в парах ключ / значение, где каждый ключ уникален. Map иногда называется ассоциативным массивом или словарем. Она часто используется для быстрого поиска данных. Map’ы позволяют сделать следующее:
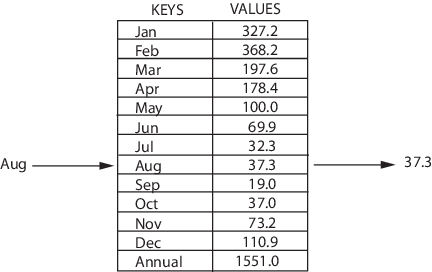
- Добавление пары в коллекцию
- Удаление пары из коллекции
- Изменение существующей пары
- Поиск значения, связанного с определенным ключом
Задания с freeCodeCamp:
Хэш-таблицы
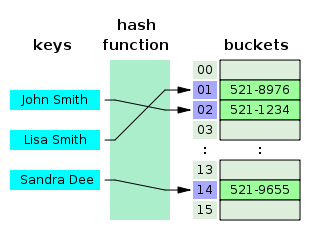
Хэш-таблица - это структура данных, реализующая интерфейс map, который позволяет хранить пары ключ / значение. Она использует хеш-функцию для вычисления индекса в массиве, по которым можно найти желаемое значение.
Хеш-функция обычно принимает строку и возвращает числовое значение. Хеш-функция всегда должна возвращать одинаковое число для одного и того же ввода. Когда два ввода хешируются с одним и тем же цифровым выходом, это коллизия. Суть в том, чтобы их было как можно меньше.
Поэтому, когда вы вводите пару ключ / значение в хеш-таблице, ключ проходит через хеш-функцию и превращается в число. Это числовое значение затем используется в качестве фактического ключа, в котором значение хранится. Когда вы снова попытаетесь получить доступ к тому же ключу, хеширующая функция обработает ключ и вернет тот же числовой результат. Затем число будет использовано для поиска связанного значения. Это обеспечивает очень эффективное время поиска O (1) в среднем.
Временная сложность хэш-таблицы ╔═══════════╦═════════╦═══════════════╗ ║ Алгоритм ║В среднем║Худший случай ║ ╠═══════════╬═════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(1) ║ O(n) ║ ║ Insert ║ O(1) ║ O(n) ║ ║ Delete ║ O(1) ║ O(n) ║ ╚═══════════╩═════════╩═══════════════╝
Задания с freeCodeCamp:
Двоичное дерево поиска
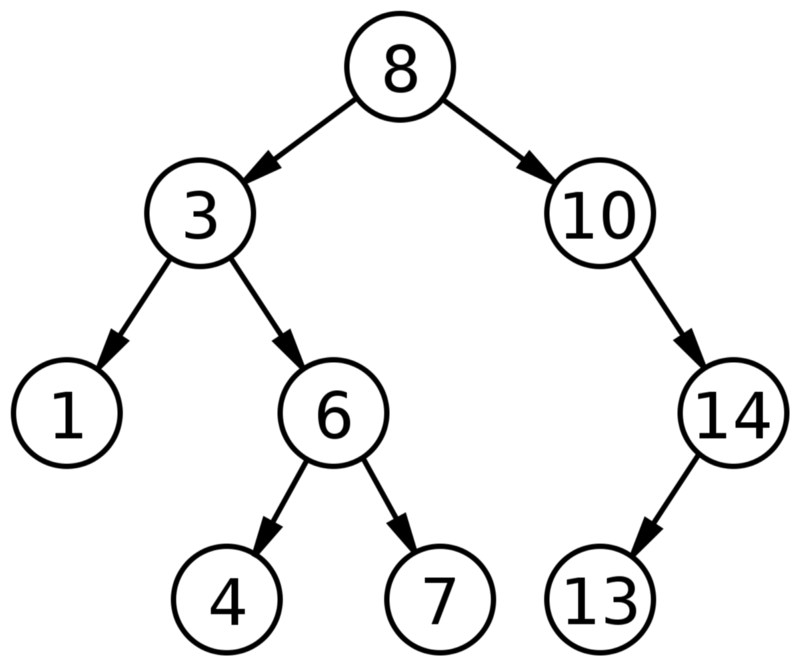
Дерево - это структура данных, состоящая из узлов. Она имеет следующие характеристики:
- Каждое дерево имеет корневой узел (вверху).
- Корневой узел имеет ноль или более дочерних узлов.
- Каждый дочерний узел имеет ноль или более дочерних узлов и т. д.
Двоичное дерево поиска имеет + две характеристики:
- Каждый узел имеет до двух детей(потомков).
- Для каждого узла его левые потомки меньше текущего узла, что меньше, чем у правых потомков.
Двоичные деревья поиска позволяют быстро находить, добавлять и удалять элементы. Способ их настройки означает, что в среднем каждое сравнение позволяет операциям пропускать половину дерева, так что каждый поиск, вставка или удаление занимает время, пропорциональное логарифму количества элементов, хранящихся в дереве.
Временная сложность двоичного поиска ╔═══════════╦══════════╦══════════════╗ ║ Алгоритм ║В среднем ║Худший случай ║ ╠═══════════╬══════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(log n) ║ O(n) ║ ║ Insert ║ O(log n) ║ O(n) ║ ║ Delete ║ O(log n) ║ O(n) ║ ╚═══════════╩══════════╩══════════════╝
Задания с freeCodeCamp:
- Find the Minimum and Maximum Value in a Binary Search Tree
- Add a New Element to a Binary Search Tree
- Check if an Element is Present in a Binary Search Tree
- Find the Minimum and Maximum Height of a Binary Search Tree
- Use Depth First Search in a Binary Search Tree
- Use Breadth First Search in a Binary Search Tree
- Delete a Leaf Node in a Binary Search Tree
- Delete a Node with One Child in a Binary Search Tree
- Delete a Node with Two Children in a Binary Search Tree
- Invert a Binary Tree
Префиксное дерево
Бор, луч или дерево префикса - это своего рода дерево поиска. Оно хранит данные в шагах, каждый из которых является его узлом. Префиксное дерево из-за быстрого поиска и функции автоматического дописания часто используют для хранения слов.
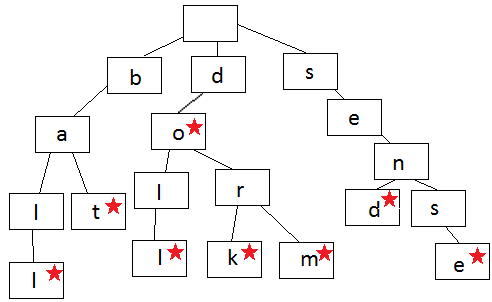
Каждый узел в префиксном дереве содержит одну букву слова. Вы следуете ветвям дерева, чтобы записать слово, по одной букве за раз. Шаги начинают расходиться, когда порядок букв отличается от других слов в дереве или, когда заканчивается слово. Каждый узел содержит букву (данные) и логическое значение, указывающее, является ли узел последним узлом в слове.
Посмотрите на изображение, и вы можете создавать слова. Всегда начинайте с корневого узла вверху и двигайтесь вниз. Показанное здесь дерево содержит слово ball, bat, doll, do, dork, dorm, send, sense.
Задания с freeCodeCamp:
Двоичная куча
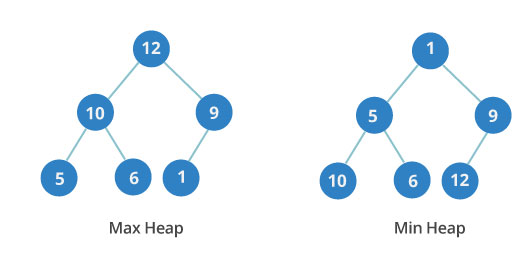
Двоичная куча - это очередное дерево, в каждом узле которого не более двух детей. Кроме того, это полное дерево. Это означает, что все уровни полностью заполнены до последнего уровня, а последний уровень заполняется слева направо.
Двоичная куча может быть либо минимальной, либо максимальной. В максимальной -ключи родительских узлов всегда больше или равны тем, что у детей. В минимальной -ключи родительских узлов меньше или равны ключам дочерних элементов.
Важен порядок между уровнями, но не узлами на одном уровне. На изображении вы можете видеть, что третий уровень минимальной кучи имеет значения 10, 6 и 12. Они расположены не по порядку.
Временная сложность двоичной кучи ╔═══════════╦══════════╦═══════════════╗ ║ Алгоритм ║В среднем ║ Худший случай ║ ╠═══════════╬══════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(log n) ║ ║ Delete ║ O(log n) ║ O(log n) ║ ║ Peek ║ O(1) ║ O(1) ║ ╚═══════════╩══════════╩═══════════════╝
Задания с freeCodeCamp:
- Insert an Element into a Max Heap
- Remove an Element from a Max Heap
- Implement Heap Sort with a Min Heap
Графы
Графы представляют собой совокупности узлов (также называемых вершинами) и связей (называемых ребрами) между ними. Графы также известны как сети.
Одним из примеров графов является социальная сеть. Узлы - это люди, а ребра - дружба.
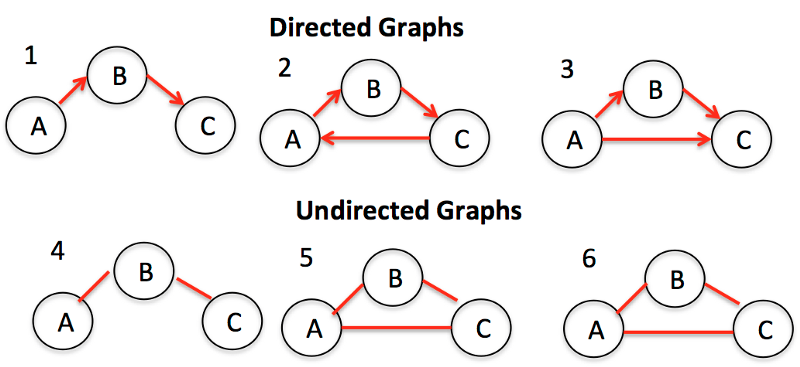
Существует два основных типа графов: ориентированные и неориентированные. Второй тип - это графы без какого-либо направления на ребрах между узлами. Ориентированные графы, напротив, представляют собой графы с направлением на них.
Два частых способа представления графа - это список смежности и матрица смежности.
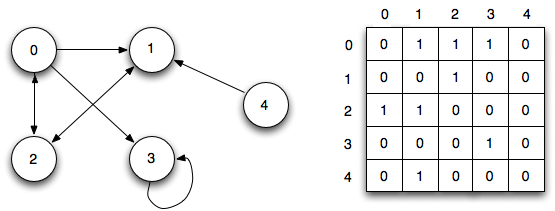
Список смежности может быть представлен как список, где левая сторона является узлом, а правая - списком всех других узлов, с которыми он соединен.
Матрица смежности представляет собой таблицу чисел, где каждая строка или столбец представляет собой другой узел на графе. На пересечении строки и столбца есть число, которое указывает на отношение. Нули означают, что нет ребер или отношений. Единицы означают, что есть отношения. Числа выше единицы могут использоваться для отображения разных весов.
Алгоритмы обхода - это алгоритмы для перемещения или посещения узлов в графе. Основными типами алгоритмов обхода являются поиск в ширину и поиск в глубину. Одно из применений заключается в определении того, насколько близко узлы расположены по отношению к корневому узлу. Посмотрите, как реализовать поиск по ширине в JavaScript в приведенном ниже видео.
Временная сложность списка смежности (граф) ╔═══════════════╦════════════╗ ║ Алгоритм ║ Время ║ ╠═══════════════╬════════════╣ ║ Storage ║ O(|V|+|E|) ║ ║ Add Vertex ║ O(1) ║ ║ Add Edge ║ O(1) ║ ║ Remove Vertex ║ O(|V|+|E|) ║ ║ Remove Edge ║ O(|E|) ║ ║ Query ║ O(|V|) ║ ╚═══════════════╩════════════╝
Задания с freeCodeCamp:
- Introduction to Graphs
- Adjacency List
- Adjacency Matrix
- Incidence Matrix
- Breadth-First Search
- Depth-First Search
Если хотите узнать больше:
Книга Grokking Algorithms - лучшая книга на эту тему, если вы новичок в структурах данных / алгоритмах и не обладаете базой компьютерных наук. Автор использует простые объяснения и юмор, рисованные иллюстрации (он является ведущим разработчиком в Etsy), чтобы объяснить некоторые структуры данных, представленные в этой статье.
Комментарии