

Текст публикуется в переводе, автор оригинальной статьи – Rashida Nasrin Sucky.
В Python'е есть очень богатые графические библиотеки. Я уже писала о визуализации с помощью Pandas и Matplotlib. В основном это были основы, и мы слегка притронулись к некоторым продвинутым методам. Сейчас вы читаете еще одну обучающую статью по визуализации.
Я решила написать статью о продвинутых методах визуализации. В этой статье не будет базовых приемов визуализации – все примеры, приведенные в этой статье, будут продвинутыми. Если вам нужно освежить базовые приемы, пожалуйста, обратитесь к статье «Ваша повседневная шпаргалка по Matplotlib».
Напоминаю: если вы используете эту статью для обучения, загрузите набор данных и выполняйте все примеры вслед за мной. Это единственный способ чему-нибудь научиться. Также найдите какой-нибудь другой набор данных и попробуйте применить аналогичные методы визуализации на нем.
Вот ссылка на набор данных, который я буду использовать в этой статье. Мы начнем с немного проблематичных диаграмм для нескольких переменных и будем двигаться к более ясным, но и более сложным решениям.
Давайте импортируем необходимые пакеты и набор данных:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
import warnings
warnings.filterwarnings(action="once")
df = pd.read_csv("nhanes_2015_2016.csv")
Этот набор данных довольно велик, и я не могу показать его целиком. Но мы можем посмотреть список столбцов этого набора:
df.columns
Вывод:
Index(['SEQN', 'ALQ101', 'ALQ110', 'ALQ130', 'SMQ020', 'RIAGENDR', 'RIDAGEYR',
'RIDRETH1', 'DMDCITZN', 'DMDEDUC2', 'DMDMARTL', 'DMDHHSIZ', 'WTINT2YR',
'SDMVPSU', 'SDMVSTRA', 'INDFMPIR', 'BPXSY1', 'BPXDI1', 'BPXSY2',
'BPXDI2', 'BMXWT', 'BMXHT', 'BMXBMI', 'BMXLEG', 'BMXARML', 'BMXARMC',
'BMXWAIST', 'HIQ210'], dtype='object')
Вы наверняка думаете, что названия столбцов совершенно непонятные! Да, так и есть, но не волнуйтесь, я все объясню по мере использования данных, и вы все поймете.
В наборе данных есть несколько качественных (categorical) столбцов, которые мы будем широко использовать – такие, как пол (RIAGENDR), семейное положение (DMDMARTL) и уровень образования (DMDEDUC2). Я хочу преобразовать их значения в осмысленные вместо каких-то чисел.
df["RIAGENDRx"] = df.RIAGENDR.replace({1: "Male", 2: "Female"})
df["DMDEDUC2x"] = df.DMDEDUC2.replace({1: "<9", 2: "9-11", 3: "HS/GED", 4: "Some college/AA", 5: "College", 7: "Refused", 9: "Don't know"})
df["DMDMARTLx"] = df.DMDMARTL.replace({1: "Married", 2: "Widowed", 3: "Divorced", 4: "Separated", 5: "Never married", 6: "Living w/partner", 77: "Refused"})
Диаграммы рассеяния
Вероятно, самыми простыми диаграммами, которые мы изучили, были линейная диаграмма и диаграмма рассеяния. В данном случае мы начнем с диаграммы рассеяния, но с небольшой модификацией.
В этом демонстрационном примере я выведу дистолическое давление крови (BPXDI1) по отношению к систолическому (BPXSY1). В качестве небольшой модификации я буду выводить точки разными цветами в зависимости от семейного положения. Будет интересно посмотреть, оказывает ли семейное положение какое-нибудь влияние на давление крови.
Для начала найдем, сколько уникальных видов семейного положения встречается в наборе данных.
category = df["DMDMARTLx"].unique()
category
Вывод:
array(['Married', 'Divorced', 'Living w/partner', 'Separated',
'Never married', nan, 'Widowed', 'Refused'], dtype=object)
Теперь выберем цвет для каждой категории.
colors = [plt.cm.tab10(i/float(len(category)-1)) for i in range(len(category))]
colors
Вывод:
[(0.12156862745098039, 0.4666666666666667, 0.7058823529411765, 1.0),
(1.0, 0.4980392156862745, 0.054901960784313725, 1.0),
(0.17254901960784313, 0.6274509803921569, 0.17254901960784313, 1.0),
(0.5803921568627451, 0.403921568627451, 0.7411764705882353, 1.0),
(0.5490196078431373, 0.33725490196078434, 0.29411764705882354, 1.0),
(0.4980392156862745, 0.4980392156862745, 0.4980392156862745, 1.0),
(0.7372549019607844, 0.7411764705882353, 0.13333333333333333, 1.0),
(0.09019607843137255, 0.7450980392156863, 0.8117647058823529, 1.0)]
Вы можете явно задать список имен своих любимых цветов. Теперь мы готовы нарисовать нашу визуализацию. Мы пройдем по каждой категории и нарисуем их по одной, чтобы собрать полную диаграмму.
plt.figure(figsize=(16, 10), dpi=80, facecolor="w", edgecolor="k")
for i, cat in enumerate(category):
plt.scatter("BPXDI1", "BPXSY1",
data=df.loc[df.DMDMARTLx == cat, :],
s = 20, c=colors[i], label=str(cat))
plt.gca().set(xlabel='BPXDI1', ylabel='BPXSY1')
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.title("Marital status vs Systolic blood pressure", fontsize=18)
plt.legend(fontsize=12)
plt.show()
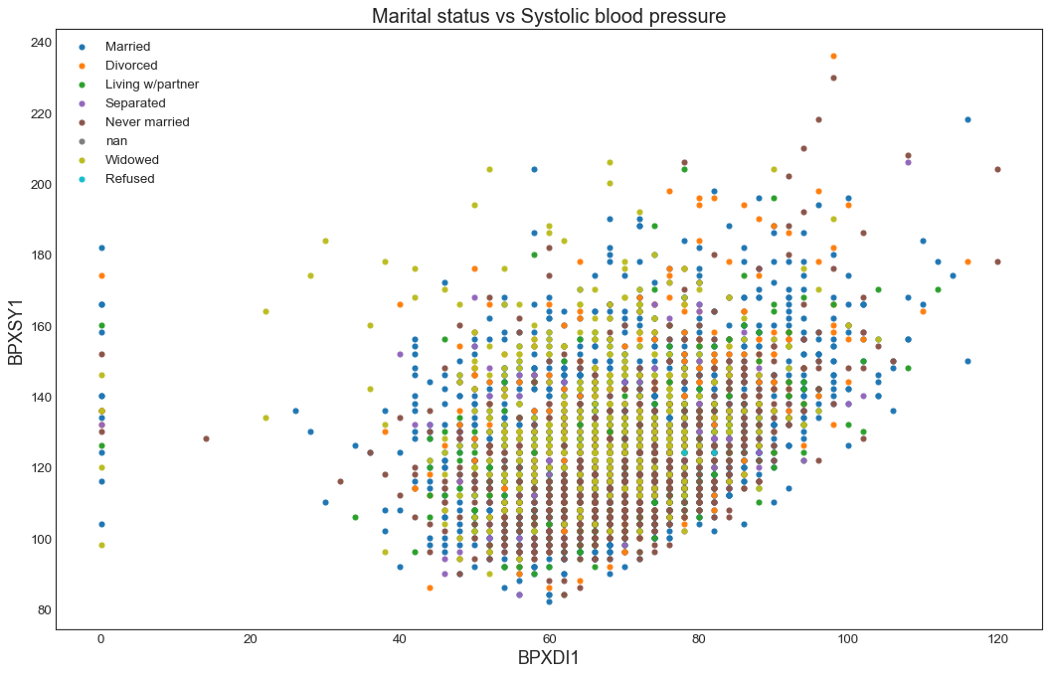
В этот набор данных можно добавить еще одну переменную, значение которой будет управлять размером точек. Для этого я включу в набор данных индекс массы тела (BMXBMI). Я создам отдельный столбец под названием 'dot_size', в котором будет храниться индекс массы тела, умноженный на 10.
df["dot_size"] = df.BMXBMI*10
Теперь сделаем нашу новую визуализацию:
fig = plt.figure(figsize=(16, 10), dpi= 80, facecolor='w', edgecolor='k')
for i, cat in enumerate(category):
plt.scatter("BPXDI1", "BPXSY1", data=df.loc[df.DMDMARTLx == cat, :], s='dot_size', c=colors[i], label=str(cat), edgecolors='black')
plt.gca().set(xlabel='Diastolic Blood Pressure ', ylabel='Systolic blood Pressure')
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.legend(fontsize=12)
plt.show()
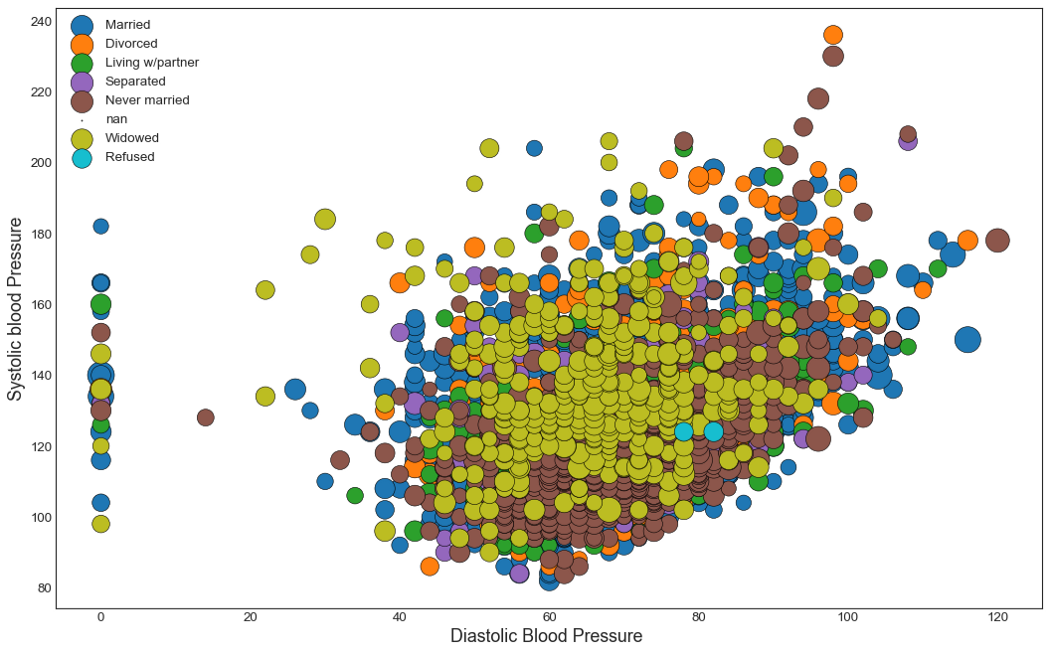
Выглядит слишком скомканно, не правда ли? Из такой диаграммы трудно что-либо понять. Вы найдете несколько решений этой проблемы в наших следующих диаграммах.
Один из путей к решению таких проблем – это взять случайную выборку из нашего набора данных. Поскольку наш набор данных слишком велик, если мы возьмем выборку из 500 элементов, визуализацию этого типа будет намного проще понять.
В следующей диаграмме я нарисую только первые 500 элементов из набора данных, предполагая, что весь набор организован случайным образом. Но я добавлю к этому набору еще один трюк. Я добавлю еще одну переменную – возраст, поскольку возраст может влиять на давление крови. Здесь я окружу те данные, для которых возраст больше 40. Вот этот код.
from scipy.spatial import ConvexHull
df2 = df.loc[:500, :]
fig = plt.figure(figsize=(16, 10), dpi= 80, facecolor='w', edgecolor='k')
for i, cat in enumerate(category):
plt.scatter("BPXDI1", "BPXSY1", data=df2.loc[df2.DMDMARTLx==cat, :], s='dot_size', c=colors[i], label=str(cat), edgecolors='black', alpha = 0.6, linewidths=.5)
def encircle(x,y, ax=None, **kw):
if not ax: ax=plt.gca()
p = np.c_[x,y]
hull = ConvexHull(p)
poly = plt.Polygon(p[hull.vertices,:], **kw)
ax.add_patch(poly)
# Select data where age is more than 40
df_encircle = df2.loc[(df2["RIDAGEYR"] > 40), :].dropna()
# Drawing a polygon surrounding vertices
encircle(df_encircle.BPXDI1, df_encircle.BPXSY1, ec="k", fc="gold", alpha=0.1)
encircle(df_encircle.BPXDI1, df_encircle.BPXSY1, ec="firebrick", fc="none", linewidth=1.5)
plt.gca().set(xlabel='BPXDI1', ylabel='BPXSY1')
plt.xticks(fontsize=12); plt.yticks(fontsize=12)
plt.title("Bubble Plot with Encircling", fontsize=22)
plt.legend(fontsize=12)
plt.show()
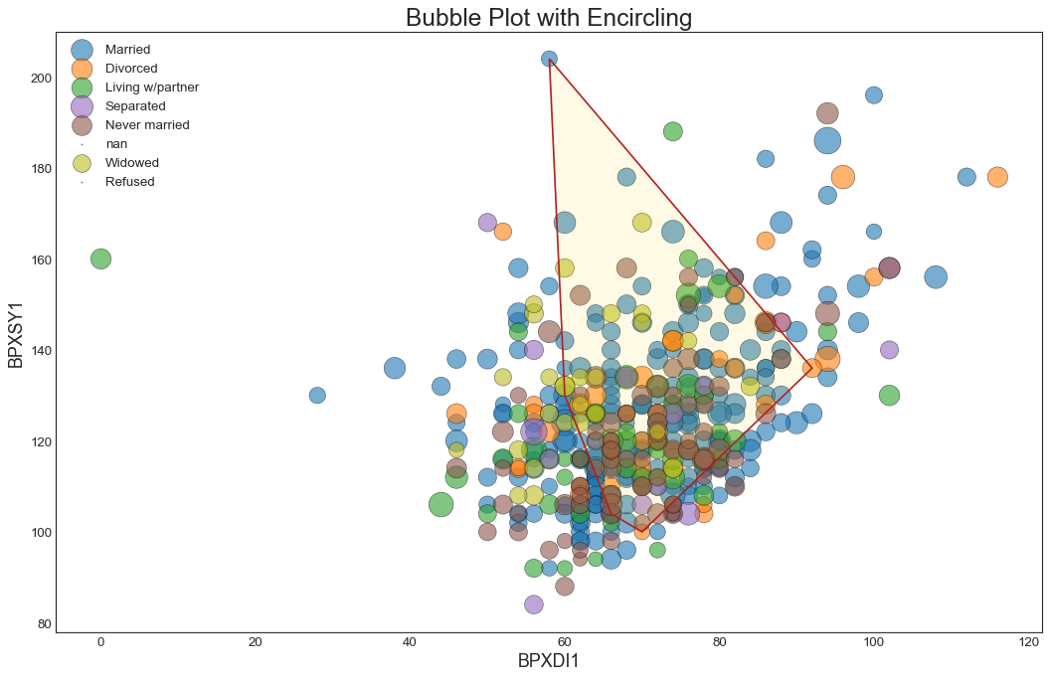
Что мы можем узнать из этой диаграммы?
Кружки, очерченные многоугольником, соответствуют людям, которым за 40 лет, из нашей выборки в 500 человек.
Размер кружков соответствует индексу массы тела – чем больше кружок, тем выше индекс. Я не смогла найти никакой зависимости между давлением крови и индексом массы тела из этой диаграммы.
Цвета показывают различное семейное положение. Видите ли вы доминирование одного цвета в какой-то определенной области? Едва ли. Я тоже не вижу никаких зависимостей между семейным положением и давлением крови.
Точечные диаграммы (stripplot)
Это интересный вид диаграмм. Когда множество точек данных перекрываются, и трудно увидеть все точки, стоит немного "растрясти" несколько точек, чтобы получить шанс ясно увидеть каждую точку. Точечная диаграмма делает именно это.
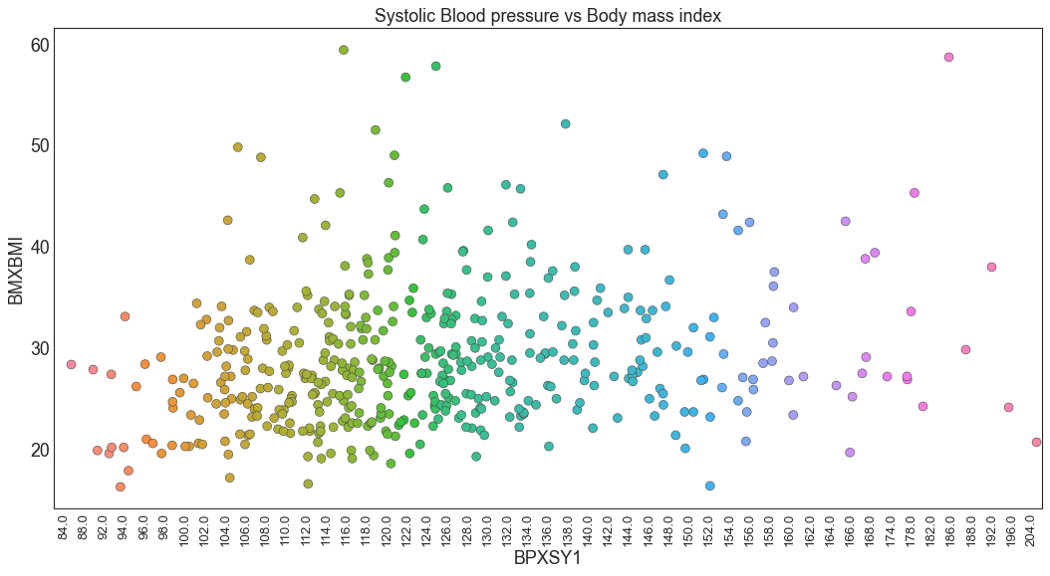
Для этой демонстрации я нарисую зависимость систолического давления крови от индекса массы тела.
fig, ax = plt.subplots(figsize=(16, 8), dpi=80)
sns.stripplot(df2.BPXSY1, df2.BMXBMI, jitter=0.45, size=8, ax=ax, linewidth=0.5)
plt.title("Systolic Blood pressure vs Body mass index")
plt.tick_params(axis='x', which='major', labelsize=12, rotation=90)
plt.show()
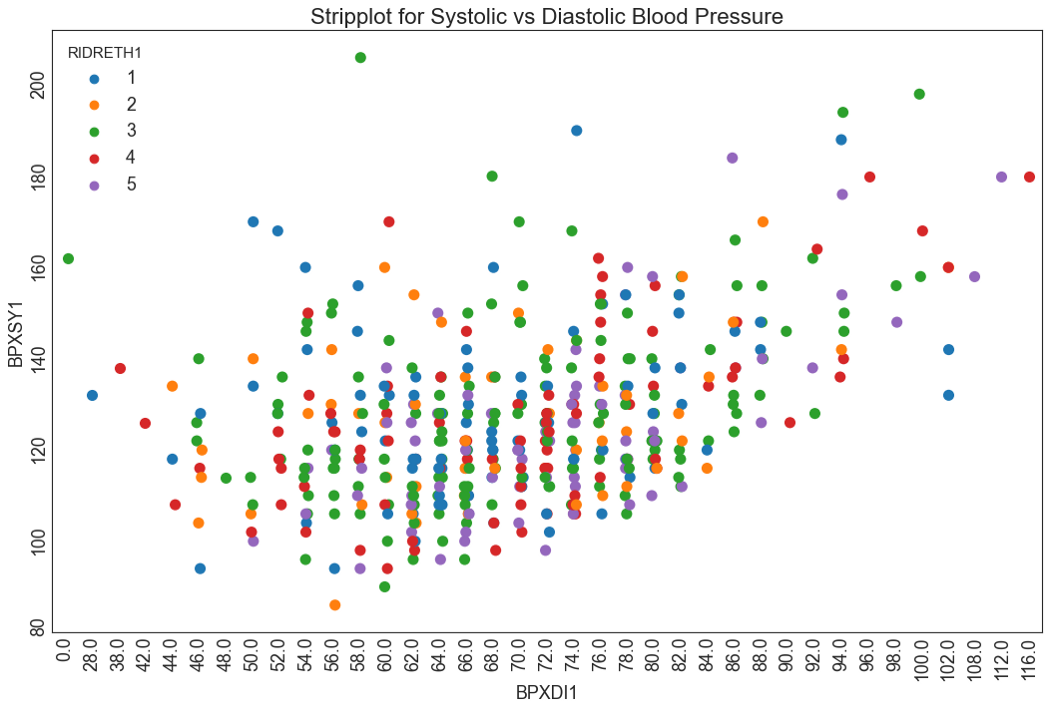
Точечные диаграммы тоже можно разделить с помощью качественной переменной, только теперь нам не придется делать это в цикле, как мы делали для диаграммы рассеяния. У функции stripplot есть параметр hue, который сделает за нас всю работу. Сейчас я выведу зависимость диастолического давления от систолического с разделением по этническому происхождению.
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
sns.stripplot(df2.BPXDI1, df2.BPXSY1, s=10, hue = df2.RIDRETH1, ax=ax)
plt.title("Stripplot for Systolic vs Diastolic Blood Pressure", fontsize=20)
plt.tick_params(rotation=90)
plt.show()
Точечные диаграммы с «ящиками»
Точечные диаграммы можно нарисовать с «ящиками с усами». Если набор данных очень большой, и точек много, это дает намного больше информации. Проверьте сами:
fig, ax = plt.subplots(figsize=(30, 12))
ax = sns.boxplot(x="BPXDI1", y = "BPXSY1", data=df)
ax.tick_params(rotation=90, labelsize=18)
ax = sns.stripplot(x = "BPXDI1", y = "BPXSY1", data=df)
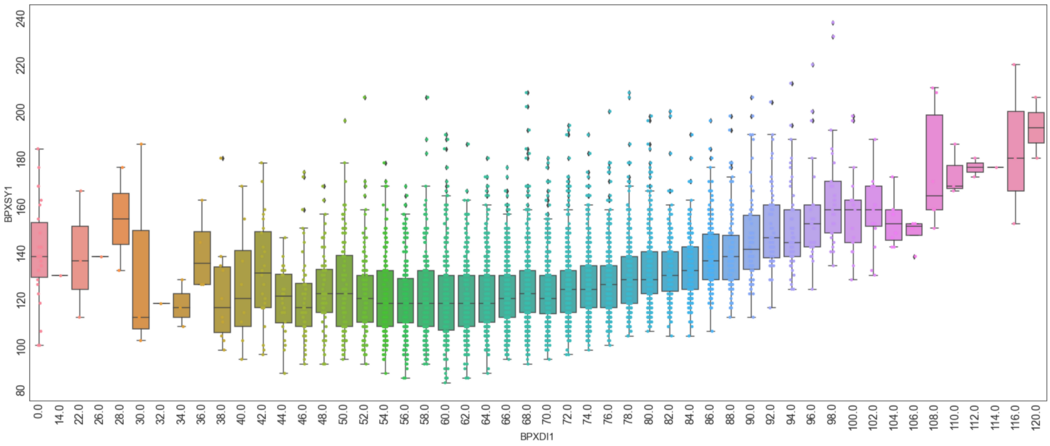
Вы можете увидеть медиану, минимум и максимум, диапазон, межквартильное расстояние и выбросы для каждого индивидуального значения. Разве это не прекрасно?
Если вам нужно вспомнить, как извлечь максимум информации из «ящика с усами», пожалуйста, обратитесь к статье «Понимание данных с помощью гистограмм и ящиков с усами на примере».
Точечные диаграммы со скрипичными
Мы выведем зависимость семейного положения (DMDMARTLx) от возраста (RIDAGEYR). Сначала посмотрим, как она выглядит, а потом сможем поговорить о ней дальше.
fig, ax = plt.subplots(figsize=(30, 12))
ax = sns.violinplot(x= "DMDMARTLx", y="RIDAGEYR", data=df, inner=None, color="0.4")
ax = sns.stripplot(x= "DMDMARTLx", y="RIDAGEYR", data=df)
ax.tick_params(rotation=90, labelsize=28)
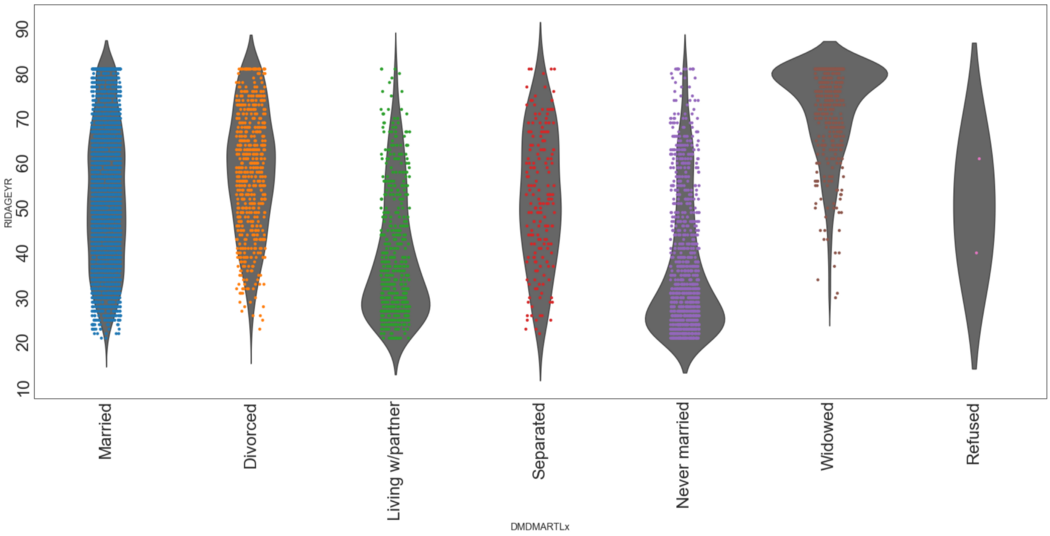
Эта диаграмма показывает семейное положение для каждого диапазона возраста. Посмотрите на скрипичную диаграмму для "Married" (женаты) – она почти одинаковой толщины независимо от возраста, с небольшими утолщениями. "Living with partner" («Живу с партнером») имеет максимальную толщину для возрастов около 30, а после 40 становится намного тоньше. Таким же образом вы можете сделать выводы и из других скрипичных диаграмм.
Скрипичные диаграммы, разделенные по полу
Скрипичные диаграммы, разделенные по полу, наверное, были бы намного информативнее. Давайте сделаем это. Вместо возраста вернемся к диастолическому давлению крови. На этот раз мы нарисуем зависимость диастолического давления крови от семейного положения, с разделением по полу. Сбоку мы также нарисуем распределение диастолического давления крови.
fig = plt.figure(figsize=(16, 8), dpi=80)
grid=plt.GridSpec(4, 4, hspace=0.5, wspace=0.2)
ax_main = fig.add_subplot(grid[:, :-1])
ax_right = fig.add_subplot(grid[:, -1], xticklabels=[], yticklabels=[])
sns.violinplot(x= "DMDMARTLx", y = "BPXDI1", hue = "RIAGENDRx", data = df, color= "0.2", ax=ax_main)
sns.stripplot(x= "DMDMARTLx", y = "BPXDI1", data = df, ax=ax_main)
ax_right.hist(df.BPXDI1, histtype='stepfilled', orientation='horizontal', color='grey')
ax_main.title.set_fontsize(14)
ax_main.tick_params(rotation=10, labelsize=14)
plt.show()
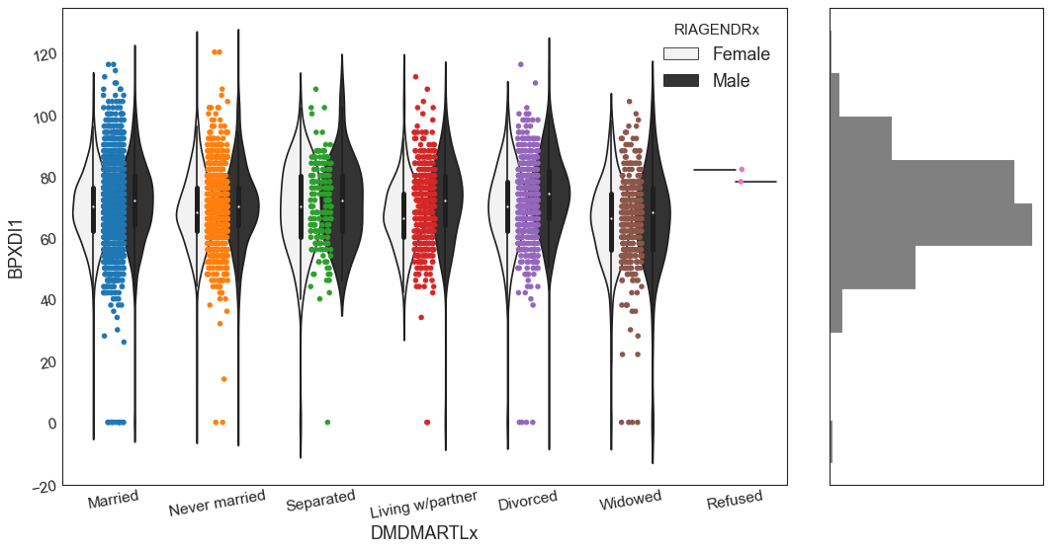
Здорово, правда? Посмотрите, как много информации можно получить из этой диаграммы! Этот вид диаграмм может быть очень полезным как для презентации, так и для исследовательского отчета.
Диаграммы с линией линейной регрессии
К диаграмме рассеяния можно добавить линию, показывающую ближайшее приближение распределения к линии. На этот раз мы выведем зависимость роста (BMXHT) от веса (BMXWT), разделенные по полу (RIAGENDR). Я объясню кое-что еще после вывода диаграммы.
g = sns.lmplot(x='BMXHT', y='BMXWT', hue = 'RIAGENDRx', data = df2,
aspect = 1.5, robust=True, palette='tab10',
scatter_kws=dict(s=60, linewidths=.7, edgecolors='black'))
plt.title("Height vs weight with line of best fit grouped by Gender", fontsize=20)
plt.show()
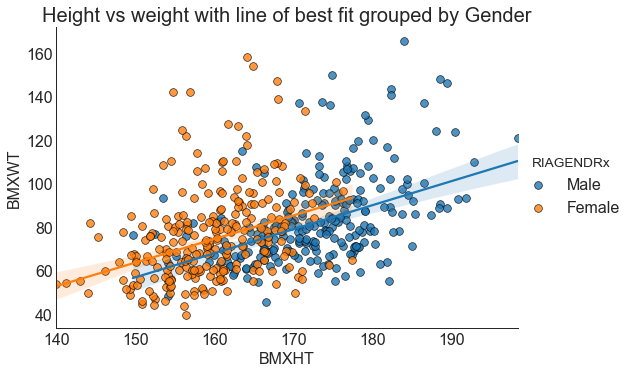
В этой диаграмме можно увидеть разделение на мужчин и женщин, выполняемое параметром 'hue'. Из этого рисунка очевидно, что рост и вес мужской популяции в среднем выше, чем женской. Как для мужчин, так и для женщин выведены линии линейной регрессии.
Индивидуальные диаграммы с линией регрессии
Мы поместили данные о мужчинах и женщинах в одну и ту же диаграмму, и это сработало, поскольку разделение четкое, и категорий всего две. Но иногда разделений слишком много, а категорий слишком много.
В этом пункте мы нарисуем lmplot'ы в различных диаграммах. Рост и вес могут быть разными для различного этнического происхождения (RIDRETH1). Вместо пола мы выведем рост и вес для каждой этнической группы в разных диаграммах.
fig = plt.figure(figsize=(20, 8), dpi=80)
g = sns.lmplot(x='BMXHT', y='BMXWT', data = df2, robust = True,
palette="Set1", col="RIDRETH1",
scatter_kws=dict(s=60, linewidths=0.7, edgecolors="black"))
plt.xticks(fontsize=12, )
plt.yticks(fontsize=12)
plt.show()

Парные диаграммы
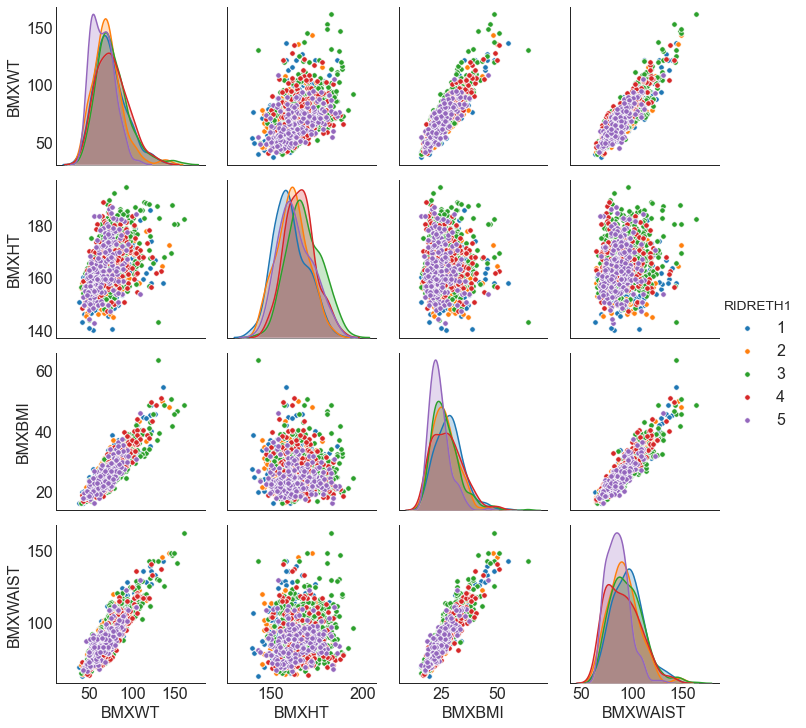
Парные диаграммы очень популярны при исследовательском анализе данных (exploratory data analysis, EDA). Парная диаграмма показывает зависимость каждой переменной от любой другой. Для примера я нарисую парную диаграмму для роста, веса, индекса массы тела и размеров по талии, разделенные по этнической группе. Я беру только первую 1000 элементов, поскольку это может сделать диаграмму немного более понятной.
df3 = df.loc[:1000, :]
plt.figure(figsize=(10,8), dpi= 80)
sns.pairplot(df3[['BMXWT', 'BMXHT', 'BMXBMI', 'BMXWAIST', "RIDRETH1"]], kind="scatter", hue="RIDRETH1", plot_kws=dict(s=30))
plt.show()
Расходящиеся столбики
Диаграмма с расходящимися столбиками (diverging bars) дает быстрый взгляд на данные. Буквально одним взглядом вы можете оценить, насколько данные отклоняются от одной метрики. Я покажу два вида диаграмм с расходящимися столбиками: в первой будет одна качественная переменная по оси x, а во второй – действительные переменные по обоим осям.
Вот первая из них. Я выведу размер дома (качественная переменная) по оси y, а по оси x будет выводиться нормализованное систолическое давление крови. Мы нормализуем систолическое давление с помощью стандартной формулы нормализации, и разделим данные в этом месте.
В этой диаграмме будет два цвета. Красный цвет будет отмечать отрицательные значения, а синий – положительные. Эта диаграмма позволит вам одним взглядом оценить, как распределяется давление крови в зависимости от размеров дома.
x = df.loc[:, "BPXSY1"]
df["BPXSY1_n"] = (x - x.mean())/x.std()
df['colors'] = ['red' if i < 0 else 'blue' for i in df["BPXSY1_n"]]
df.sort_values("BPXSY1_n", inplace=True)
df.reset_index(inplace=True)
plt.figure(figsize=(16, 10), dpi=80)
plt.hlines(y = df.DMDHHSIZ, xmin=0, xmax = df.BPXSY1_n, color=df.colors, linewidth=3)
plt.gca().set(ylabel="DMDHHSIZ", xlabel = "BPXSY1_n")
plt.yticks(df.DMDHHSIZ, fontsize=14)
plt.grid(linestyle='--', alpha=0.5)
plt.show()
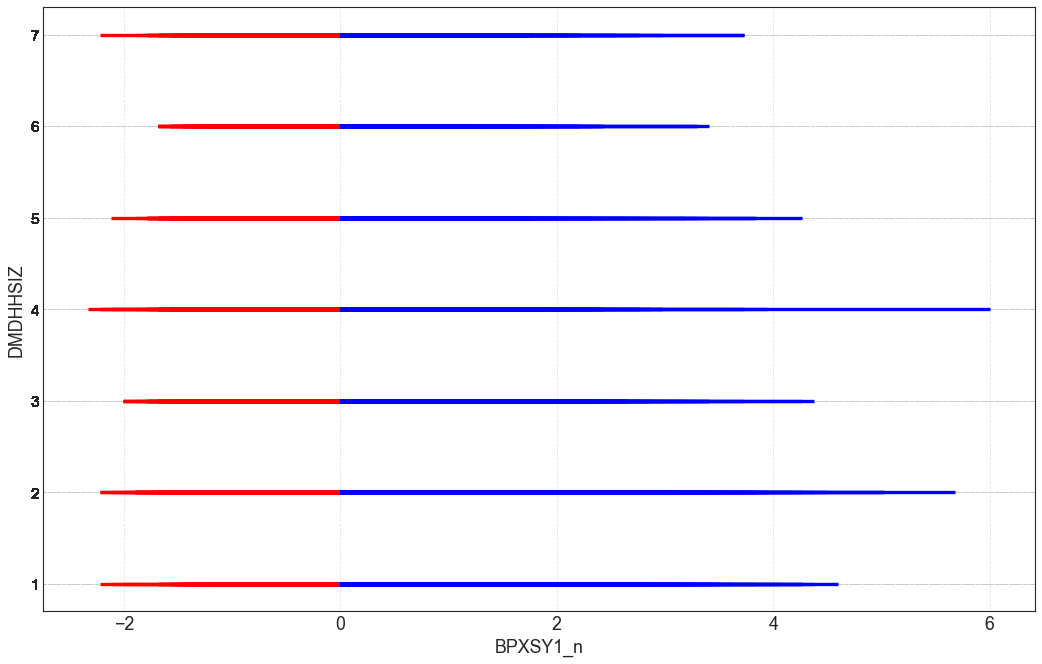
Здесь размер дома разделен на несколько групп. В наборе данных не указано, как размеры дома делятся на группы, но по этой диаграмме вы можете увидеть, как распределяется давление крови в зависимости от размеров дома. Теперь вы можете провести дальнейший анализ.
Я нарисую другую диаграмму, в которой покажу зависимость систолического давления крови от возраста. Мы уже нормализовали систолическое давление для предыдущей диаграммы, поэтому давайте просто погрузимся в нашу диаграмму.
x = df.loc[:, "BPXSY1"]
df['colors'] = ['coral' if i < 0 else 'lightgreen' for i in df["BPXSY1_n"]]
y_ticks = np.arange(16, 82, 8)
plt.figure(figsize=(16, 10), dpi=80)
plt.hlines(y = df.RIDAGEYR, xmin=0, xmax = df.BPXSY1_n, color=df.colors, linewidth=3)
plt.gca().set(ylabel="RIDAGEYR", xlabel = "BPXSY1")
plt.yticks(y_ticks, fontsize=14)
plt.grid(linestyle='--', alpha=0.5)
plt.show()
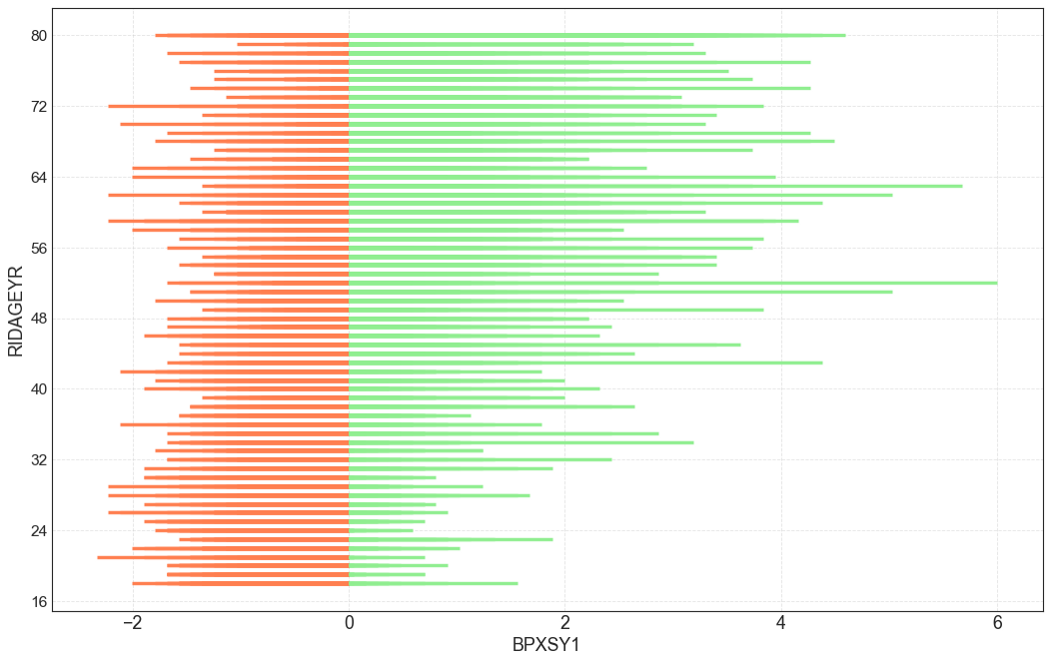
Этот вариант диаграммы выглядит таким очевидным. Систолическое давление крови в целом растет с возрастом. Не правда ли?
Заключение
На сегодня все. В различных библиотеках Python доступно множество прекрасных методов визуализации. Если вы регулярно имеете дело с данными, полезно знать как можно больше методов визуализации. Но помните, вам не нужно их запоминать. Просто знайте об их существовании и попрактикуйтесь в их использовании несколько раз, чтобы при необходимости вы смогли найти эти методы в Google, документации или статьях вроде этой. Надеюсь, что вы сможете использовать эти методы визуализации для достижения действительно красивых результатов.
Комментарии