
CAPTCHA – полностью автоматизированный публичный обратный тест Тьюринга для различения компьютеров и людей путем автоматической настройки определенных заданий, которые трудны для компьютеров, но просты для людей. Эта технология стала стандартом безопасности, используемым для предотвращения автоматического голосования, регистрации, спама, словарных атак на пароли веб-сайтов и т. п.
1. Категории капч
Существующие капчи разделяют на три категории: текстовые, графические и аудио/видео. Ниже мы рассмотрим, как генерируются различные капчи и какие успехи сейчас есть с их обходом. Не ругайте за качество изображений – мы взяли рисунки из научных публикаций, на которые даём ссылки =) Полный список публикаций, взятых для анализа, приведён в конце статьи.
1.1. Текстовая капча
Текстовые капчи являются наиболее часто используемыми, но из-за простой структуры они и наиболее уязвимы. Такой вид капч, как правило, требует распознать геометрически искаженную последовательность, состоящую из букв или цифр.
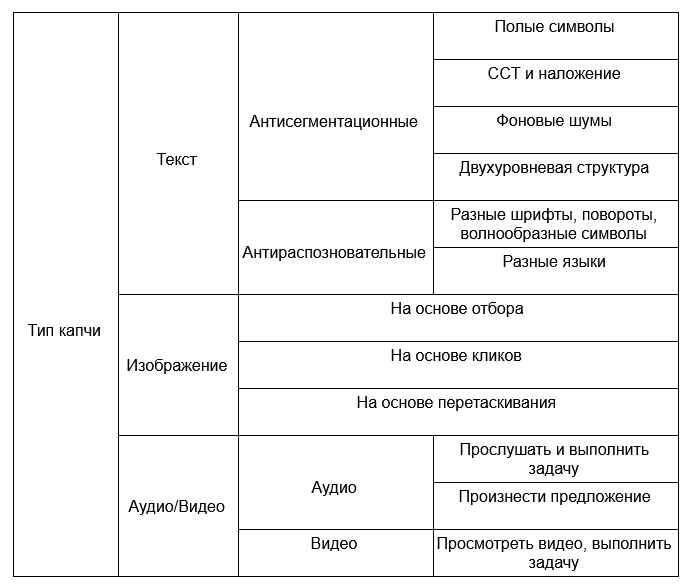
Для повышения безопасности применяются различные механизмы защиты, которые можно разделить на антисегментационные и антираспознавательные. Первая группа механизмов нацелена на ухудшение процесса выделения отдельных символов, вторая – на распознавание самих символов. На Рис. 1 сведены в табличное представление примеры капч для различных подходов.
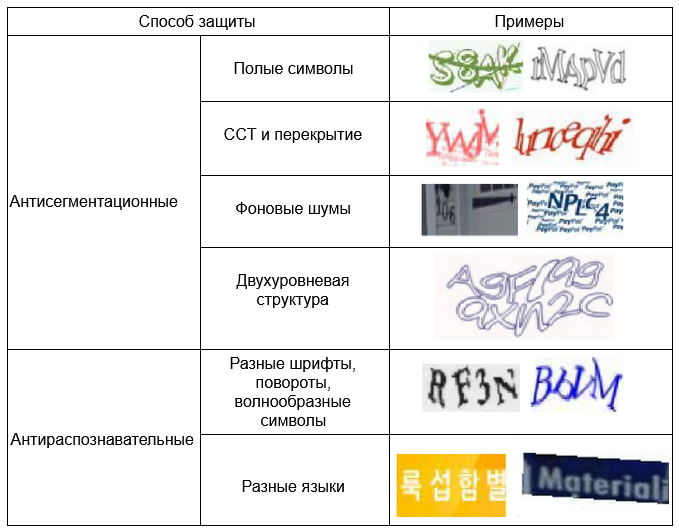
1.1.1. Полые символы
В случае стратегии создания капчи «полые символы» для
формирования каждого символа используются
контурные линии.

Такие символы трудно сегментировать, но они легко видны людям. К сожалению, этот механизм не так безопасен, как ожидалось. В исследованиях Гао [1] сверточная нейронная сеть успешно распознает от 36% до 89% изображений (в зависимости от типа искажений и обучающей выборки).
1.1.2. Перекрытие символов
Объединение и перекрытие символов (англ. сrowing characters together, CCT) усложняют сегментацию, но при этом также снижает удобство для чтения пользователем. То есть и сами люди не всегда успешно могут обойти такую капчу.

Исследователям из Китая и Пакистана удалось взломать CTT с вероятностью от 27.1% до 53.2% [2].
1.1.3. Фоновые шумы

Google's reCAPTCHA, использующая изображения из Street View, ломается в 96% случаев [3].
1.1.4. Двухуровневая структура
Двухуровневая структура представляет собой вертикальную комбинацию двух горизонтальных капч, что усложняет сегментацию изображения.

Гао [4] предложил подход к сегментации для разделения изображения капчи как по вертикали, так и по горизонтали, и добился успеха в 44.6% (9 с на изображение), используя свёрточную нейронную сеть.
1.2. Капча-изображение
1.2.1. Капча на основе отбора
В случае капчи на основе отбора пользователи должны выбрать правильные ответы в соответствии с подсказкой для капчи, основанной на выборе. Это самая простая форма капчи на основе изображений. Например, нужно выделить среди предъявленных изображений все машины, все дорожные знаки, все светофоры.

Голль [5] предложила использовать метод опорных векторов (SVM) для различения изображений кошек и собак в капче Asirra с вероятностью успешного распознавания 82.7%.
Команда Гао [6] использовала OpenCV для обнаружения лиц во FR-CAPTCHA. Удалось получить вероятность обнаружения от 8% до 42% с обработкой изображения менее, чем за 14 секунд. FaceDCAPTCH была распознана с вероятностью 48% в среднем за 6.2 секунды.
Сотрудники Колумбийского университета обошли reCAPTCHA и Facebook CAPTCHA с вероятностью 70.78% и 83.5% соответственно.
1.2.2. Капча на основе кликов
В 2008 году Ричард Чоу с коллегами [7] впервые предложили капчу, основанную на кликах. Она требует от пользователей нажимать на символы, находящиеся на сложном фоне в соответствии с подсказкой, как показано на Рис. 7.
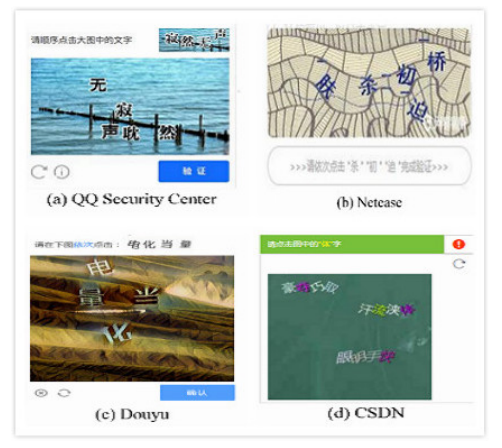
Такие кликовые капчи имеют два защитных механизма: антивыявление и антираспознавание. Правильное распознавание символов с развитием машинного обучения уже не является сложной задачей. Поэтому почти все механизмы защиты ориентированы на то, чтобы помешать злоумышленникам правильно выявить символы.
1.2.3. Капча на основе перетаскивания
Капча на основе перетаскивания определяет, является ли пользователь человеком, через трек мыши, скорость перемещения указателя и время отклика.
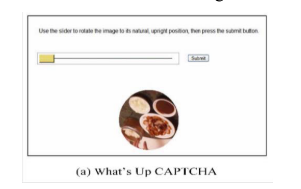
Пользователям необходимо повернуть изображение предмета так, чтобы он находился в естественном положении. Например, перевернуть изображение стола так, чтобы он оказался на ножках. Это просто для человека, но трудно для ботов.
1.3. Аудио/видеокапчи
1.3.1 Аудиокапча
Эта капча
обычно рассматривается как альтернатива
зрительной
в случае пользователей с ослабленным
зрением. Слушателям предлагается выполнить
задание исходя из того, что они услышали, например, определить конкретный звук,
например, звук колокольчика или фортепиано [8].
Существует еще один тип капчи на основе аудио, в котором от пользователей требуется не просто слушать, а произносить. Например, Гао [9] предложил звуковую капчу (Рис. 9), в которой пользователь должен зачитать предложение, выбираемое случайным образом из книги. Сгенерированный аудиофайл анализируется, чтобы определить, является ли пользователь человеком.
Но и аудиокапча взламывается: ученые из Стэнфордского университета научились взламывать аудиокапчу с вероятностью 75%.
1.3.2 Видеокапча
В видеокапче пользователям предоставляется видеофайл, и они должны выбрать предложение, которое описывает движение человека на видео.
Японские исследователи использовали решение на базе HMM (скрытой марковской модели) и получили точность 31.75%.
Рассмотрим теперь, как именно для взлома капчи используются нейронные сети.
2. Нейронные сети с архитектурами DenseNet и DFCR
В 2017 году Гао Хуан, Чжуан Лю и другие [10] построили 4 глубоких свёрточных нейронных сети с архитектурой, называемоей теперь DenseNet. Плотные блоки нейронных сетей чередовались со слоями skip-connection (Рис. 10). Вход каждого слоя в блоке являлся объединением выхода всех предыдущих слоев. Это отличало новую архитектуру от традиционных на тот момент нейросетей, где слои были соединены последовательно.
![Рис. 11. DenseNet с тремя плотными блоками [11]](https://media.proglib.io/posts/2020/03/02/662cf05534d69dc36de2c5f84fab67d3.png)
Архитектура DenseNet имеет ряд преимуществ: она решает проблему дисперсии и эффективно использует особенности всех предшествующих сверточных слоев, понижая вычислительную сложность параметров сети и демонстрируя хорошую производительность классификации.
Примером вариации архитектуры DenseNet является нейросеть DFCR. Исходные изображения капчи размером 224x224 проходили через слой свертки и объединялись в пулы для вывода изображений размером 56x56. После этого поочередно соединялись 4 «плотных» блока, чередуясь с переходными слоями (Рис. 11). Структура переходного слоя позволяла уменьшить размерность карты признаков и ускорить вычисления.
![Рис. 12: Архитектура DFCR на примере распознавания изображения с символами «W52S» [11]](https://media.proglib.io/posts/2020/03/02/7b108045a5d39f92f1d6f958f9fb1600.jpg)
Далее карты признаков использовались для проверки соответствия карты и класса. Значения в каждой карте признаков суммировались для получения среднего значения, которое принималось за значение класса и выводилось в соответствующий softmax-слой классификации.
Эксперименты показывают, что DFCR не только сохраняет основные преимущества DenseNet, но и снижает потребление памяти. Кроме того, точность распознавания капчи с фоновым шумом и наложенными друг на друга символами выше 99.9% [11].
3. Генеративно-состязательная нейросеть
![Рис. 13. Процесс обучения генератора текстовых капч на GAN [12]](https://media.proglib.io/posts/2020/03/02/ef75268c2a223312b32a3157d2a0545c.png)
Генератор
капч на GAN (генеративно-состязательная сеть) cостоит
из двух частей:
1) сеть, создающая
капчи, приближенные к оригинальным; 2) нейросеть, отличающая
искусственную капчу от
настоящей (солвер).
Перед подачей капчи солверу, в ней удаляются использованные средства защиты и нормализуется шрифт. Например, производится заполнение полых символов и нормализация промежутков между ними. Модель препроцессинга основывается на Pix2Pix.
![Рис. 14. Схема алгоритма. Сначала используется небольшой датасет реальных капч для обучения синтезатора капчи (1). Далее генерируются искусственные капчи (2) для обучения солвера (3). Совершенствование солвера (4) [12]](https://media.proglib.io/posts/2020/03/02/f51b0f257ad89c15f56db42e6d0d900a.png)
Затем генерируется большое количество капч с маркировкой, которые используются для обучения солвера. Обученный солвер принимает капчу после препроцессинга и выдает соответствующие символы. Тонкая настройка солвера происходит с помощью небольшого набора вручную размеченных капч, которые собираются с целевого сайта.
В качестве конкретной свёрточной нейронной сети хорошим вариантом оказалось использование архитектуры LeNet-5, которая изначально применялась для распознавания одиночных символов. Добавление двух сверточных слоев и трех слоев пулинга расширило ее возможности до распознавания нескольких символов.
![Рис. 15: Алгоритм тренировки солвера [12]](https://media.proglib.io/posts/2020/03/02/d63ed0313f6555f65ddbcb6b5d9b53a1.png)
Информация, полученная на ранних слоях нейронных сетей, полезна для решения множества других классификационных задач. Более дальние слои более специализированы. Это свойство используется для калибровки солвера, чтобы избежать систематической ошибки или переобучения.
Выходной слой солвера состоит из ряда нейронов с одним нейроном на символ. Например, если в капче n символов, выходной слой будет содержать n нейронов, где каждый нейрон соответствует возможному символу. Если количество символов не фиксировано, то необходимо тренировать солвер для каждого возможного n.
Результаты вероятности взлома :
- Перекрытие (в зависимости от сложности) – от 25.1% до 65%
- Поворот (15°, 30°, 45°, 60°) – 100%, 100%, 99.85%, 99.55%
- Искажение – 92.9%
- Эффект волны – 98.85%
- Комбинация вышеперечисленных – 46.30%
4. Свёрточная нейронная сеть + долгая краткосрочная память (LTSM)
Чтобы распознать последовательность символов без сегментации, можно использовать модель, состоящую из свёрточной нейронной сети, соединенной с нейросетью с долгой краткосрочной памятью (LSTM) и механизмом внимания.
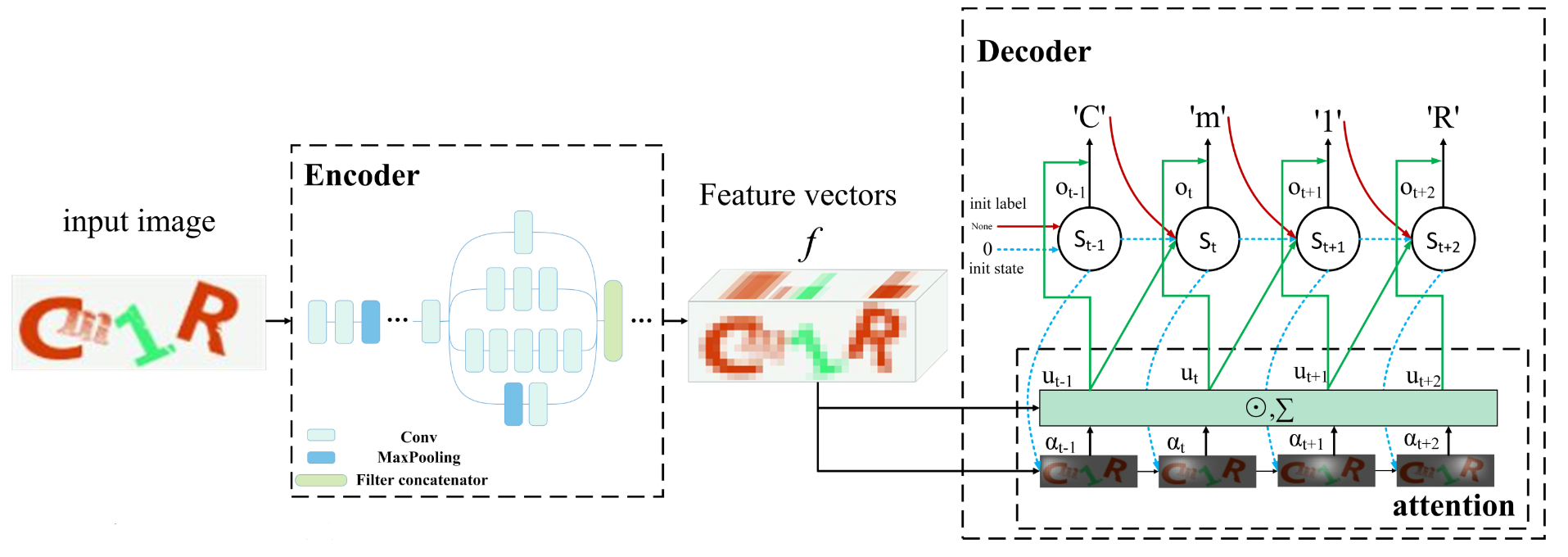
Свёрточная нейронная сеть представляет собой энкодер, извлекающий признаки из капчи. Исходное изображение представляется в виде линейного векторного пространства. Созданный энкодером вектор признаков обозначается fijc, где i и j – индексы местоположения на карте признаков, c – индекс каналов.
LSTM работает как декодер и переводит вектор признаков в текстовую последовательность. В отличие от рекуррентной нейронной сети, LSTM умеет хранить информацию в течение длительных промежутков времени.
В традиционной модели sequence-to-sequence на каждом временном шаге на вход передается вектор f. Но узким местом стандартной модели является то, что вход является постоянным. Механизм внимания позволяет декодеру игнорировать неактуальную информацию, сохраняя при этом наиболее значимую информацию о векторе f. Различным частям вектора признаков присваиваются различные веса, так что модель может фокусироваться на каждом шаге на определенной части вектора, делая прогнозы более точными. Это является основной причиной того, что предложенный метод может распознавать отдельные символы без сегментации.
В экспериментах для декодирования использовалась сокращенная модель Inception-v3. Декодер состоял из LTSM-ячеек, каждая из которых содержала 256 скрытых нейронов. Количество ячеек LSTM равнялось максимальной длине строки капчи. Для всей структуры число обучаемых параметров составило 9 млн. В зависимости от исходного размера каждая капча масштабировалась так, чтобы короткая сторона находилась в диапазоне от 100 до 200 пикселей. На тренировочном этапе модель тренировалась по стохастическому градиентному спуску с использованием момента 0.9. Скорость обучения равнялась 0.004. На обучение было потрачено 200 эпох с размером батча 64.

После каждой эпохи происходила проверка модели. Если производительность модели была лучше, чем у текущей лучшей модели, веса лучшей модели обновлялись. В качестве данных для эксперимента были собраны CCT-капчи (текст с перекрытием) (Рис. 17).
Для образца капчи в тестовом наборе полная прогнозируемая последовательность символов считалась правильно определенной только в том случае, если она была идентична ответу, помеченному вручную. Для выборки в 10 000 образцов (обучающая и тестовая в соотношении 3:1) вероятность успешного распознавания составила 42.7%. По мере увеличения количества образцов до 50 000, 100 000, 150 000 и 200 000 вероятность увеличилась до 87.9%, 94.5%, 97.4% и 98.3% соответственно.
5. Обучение с подкреплением
Обучение с подкреплением использовалось для обхода Google reCAPTCHA v3 [14].
Взаимодействие
бота со средой было смоделировано как марковский
процесс принятия решений (MDP).
MDP задавался кортежем
(S, A, P, r), где S – конечное множество состояний, A – конечное множество действий, P – вероятность перехода между состояниями P(s, a, s'), r – вознаграждение, получаемое после перехода в состояние s' из состояния s с вероятностью P.
Целью похода было найти оптимальное правило π*, которое максимизирует ожидаемые вознаграждения в будущем. Предположим, что правило параметризируется набором весов w, таким, что π = π(s, w). Затем задача задается как
где γ – некоторая константа (discount factor), rt – вознаграждение в момент времени t.
Обучение с подкреплением оценивает градиенты по формуле
Для прохождения reCAPTCHA пользователь перемещает курсор, пока не установит флажок reCAPTCHA. В зависимости от этого взаимодействия система reCAPTCHA «наградит» пользователя баллом. Этот процесс был смоделирован как MDP, где пространство состояний S – это возможные позиции курсора на веб-странице, а пространство действий A = {вверх, влево, вправо, вниз}. Такой подход делает задачу похожей на задачу grid world.
Как
показано на Рис. 18, отправной точкой
является начальная позиция курсора, а целью
является позиция reCAPTCHA. Для каждого теста отправная точка выбирается
случайным образом из верхней правой
или верхней левой области. Затем строится
сетка, где каждый пиксель между начальной
и конечной точками является возможным
положением курсора. Размер
ячейки c – количество пикселей между
двумя последовательными позициями.
Например, если курсор
находится на позиции (x0, y0) и совершает
действие влево, то следующей позицией
будет (x0 – c, y0).
![Рис. 18. Сетка в MDP [14]](https://media.proglib.io/posts/2020/03/01/b42128ad3bd30e7d062746e19f33b923.png)
В каждом тесте позиция курсора случайная, бот выполняет последовательность действий до достижения reCAPTCHA или предела T, где a и b – это высота и ширина сетки соответственно.
По окончании теста бот получает обратную связь от reCAPTCHA, как и любой обычный пользователь.
В большинстве предыдущих работ для автоматизации действий веб-браузера использовался Selenium, однако он часто проваливал тест, так как в HTTP-запросах обнаруживался автоматически сгенерированный заголовок и другие дополнительные переменные, которые отсутствуют в обычном браузере.
Эту проблему можно решить двумя разными способами. Первый заключается в создании прокси для удаления автоматического заголовка. Второй вариант заключается в запуске браузера из командной строки и управлении мышью с помощью специальных пакетов Python, таких, как библиотека PyAutoGUI.
Забавно, что симуляции, выполняемые в браузере с подключенным аккаунтом Google, с большей вероятностью проходили проверку, чем симуляции без авторизации.
В экспериментах с discount factor γ = 0.99, скоростью обучения – 10-3 и размером батча 2000. капча взламывалась с вероятностью 97.4%.
6. Решение капч людьми
Как можно заметить уже из этой статьи, машинное обучение имеет высокий порог вхождения, а ведь все, что было описано в публикации – только вершина айсберга. Если копать глубже, то скоро можно претендовать на звание джуниора по нейронным сетям =)
А ведь для реальной работы нужна команда специалистов и аренда вычислительных мощностей. Добавим к этому время обучения/переобучения сетей, растущее количество видов капч, разнообразие языков, и получится, что быстрее и дешевле воспользоваться онлайн-сервисами, где капчи решают живые люди.
Среди подобных сервисов выделяется ruCaptcha. На сервисе есть тонкая настройка солвера: количество слов, регистр, цифры и/или буквы, язык (55 на выбор), математические действия и т. д.
Решаются следующие виды капч: обычная текстовая, ReCaptcha версий 2 и 3, GeeTest, hCaptcha, ClickCaptcha, RotateCaptcha, FunCaptcha, KeyCaptcha.
Взаимодействие с сервером происходит через API, то есть можно встроить решение в собственный продукт. Есть функция возврата за неправильное распознавание, а на возникшие вопросы отвечает техподдержка (адекватная в сравнении с конкурентами).
Конечно, за решение капч, сервис платит конкретным людям, готовым решать задания за небольшую плату. Соответственно эти деньги сервис берёт у клиентов, которым не приходится заниматься рутиной. Расценки на момент написания статьи были следующие: 1000 капч взламывались не более, чем за 44 ₽ (в среднем 7.5 с на капчу), 1000 рекапч за 160 ₽ (в среднем 32 с на капчу). То есть единая цена независимо от нагрузки и от того, сколько заплатили другие заказчики.
Для сравнения: один мидл-специалист по машинному обучению обойдется на рынке минимум в 150 000 ₽/мес.
Напишите, если пользовались сервисом – интересно узнать ваше мнение (пока мы основываемся на мнении авторов следующих статей: англоязычная и три русских: раз, два, три).
Источники
[7] Chow, R., Golle, P., Jakobsson, M., Wang, L., & Wang, X. (2008, February). Making captchas clickable
[11] CAPTCHA recognition based on deep convolutional neural network
[12] Yet Another Text Captcha Solver: A Generative Adversarial Network Based Approach Guixin
[13] An end-to-end attack on text CAPTCHAs
[14] Hacking Google reCAPTCHA v3 using Reinforcement Learning
Комментарии