
При решении ряда математических задач необходимо парсить исходное выражение. Для этого нужен токенизатор, созданием которого мы и займемся.
Что такое токенизатор?
Токенизатор – это программа, которая разбивает исходное выражение на отдельные части – лексические единицы, лексемы, или токены. Для примера возьмем выражение "I’m a big fat developer". Его можно токенизировать несколькими способами:
Например, используя в качестве токенов отдельные слова:
0 => I’m 1 => a 2 => big 3 => fat 4 => developer
Или непробельные символы:
0 => I 1 => ‘ 2 => m 3 => a 4 => b … 16 => p 17 => e 18 => r
Или вообще все символы:
0 => I 1 => ‘ 2 => m 3 => (space) 4 => a 5 => (space) 6 => b … 20 => p 21 => e 22 => r
Ну, идею вы поняли, правда?
Токенизаторы, или лексеры, лексические анализаторы, используются в разработке компиляторов различных языков программирования. Они помогают машине понять, что вы хотели сказать своим кодом.
Вместо кода мы будем работать с математическими выражениями, это почти то же самое.
Токены
Допустимое математическое выражение состоит из математически допустимых токенов, которые могут быть Литералами, Переменными, Операторами, Функциями или Разделителями Аргументов Функции.
- Литерал в нашем случае – это просто число. Оно может быть целое или десятичное.
- К Переменным мы давно привыкли в математике и программировании. В этом проекте они будут иметь самые простые однобуквенные имена, например,
a,b,m,n,x,y. Таким образом, мы сможем токенизировать выражениеmaкак произведение переменныхmиa, а не как самостоятельную переменнуюma. - Операторы работают с Литералами, Переменными и результатами функций. Мы будем использовать только следующие операторы:
+,_,*,/и^(возведение в степень). - Функции – это продвинутые операции, вроде
sin(),cos(),tan(),min(),max()и т. д. - Разделители Аргументов Функции – это обычные запятые вот в таком контексте:
max(4,5). Здесь вызывается функцияmaxс двумя аргументами, разделенными запятой.
Возьмем еще два токена, которые обычно не учитываются, но с ними будет проще: Левая и Правая Круглые Скобки.
Размышления
Неявное умножение
Зачастую оператор умножения в выражениях опускается. Пользователь может писать 5x вместо 5*x. Точно так же можно действовать и с функциями: 5sin(x) = 5*sin(x).
Можно даже позволить писать 5(x) и 5(sin(x)), но стоит ли?
С жесткими правилами синтаксиса токенизация будет проще. Также можно будет использовать многобуквенные имена переменных, например, price.
Если разрешить подобные вольности, платформа станет интуитивно понятнее. Плюс это еще один челлендж для разработчика. Пойдем по сложному пути и разрешим неявное умножение.
Синтаксис
Хотя мы и не пишем новый язык программирования, все равно необходимо установить ряд синтаксических правил. Они определят допустимый формат сочетания токенов. Так пользователи будут знать, что вводить, а программист – что ожидать.
- Токены могут быть разделены любым количеством пробельных символов, включая нулевое.
2+3, 2 +3, 2 + 3, 2 + 3 // Правильно 5 x - 22, 5x-22, 5x- 22 // Правильно
Другими словами, интервал между токенами не имеет значения. Разумеется, кроме многосимвольных токенов, например, числового Литерала
22. - Аргументы Функций должны находиться в скобках.
sin(y), cos(45) // Правильно sin y, cos 45 // Неправильно
Для чего это нужно? При парсинге из строки будут удалены все пробелы, поэтому важно знать, где начинается и заканчивается функция.
- Неявное умножение допускается только между Литералами и Переменными или Литералами и Функциями, при этом Литерал всегда должен быть первым множителем. Круглые скобки опциональны.
a(4) // вызов функции a с единственным аргументом 4 a4 // недопустимое выражение 4a или 4(a) // допустимое неявное умножение
А теперь приступим к работе.
Моделирование данных
Как должны быть представлены данные? Разберемся на простом примере 2y + 1.
Мы ожидаем получить из этого выражения массив токенов с указанием их типов и значений:
0 => Literal (2) 1 => Variable (y) 2 => Operator (+) 3 => Literal (1)
Значит, прежде всего нужно определить класс для токенов, чтобы проще было с ними работать:
function Token(type, value) {
this.type = type;
this.value = value
}
Алгоритм
Теперь можно построить скелет функции-лексера.
Наш токенизатор будет перебирать массив str посимвольно и создавать токены на основе найденных значений.
Важно: мы предполагаем, что входящее значение, полученное от пользователя, изначально допустимо. В этом проекте не будет валидации, но в реальности она необходима.
function tokenize(str) {
var result=[]; // массив токенов
// удалить пробелы
str.replace(/\s+/g, "");
// конвертировать строку в массив символов
str=str.split("");
str.forEach(function (char, idx) {
if(isDigit(char)) {
result.push(new Token("Literal", char));
} else if (isLetter(char)) {
result.push(new Token("Variable", char));
} else if (isOperator(char)) {
result.push(new Token("Operator", char));
} else if (isLeftParenthesis(char)) {
result.push(new Token("Left Parenthesis", char));
} else if (isRightParenthesis(char)) {
result.push(new Token("Right Parenthesis", char));
} else if (isComma(char)) {
result.push(new Token("Function Argument Separator", char));
}
});
return result;
}
Этот код очень прост. Функции-помощники, которые в нем встретились (isComma(), isDigit(), isLetter(), isOperator(), isLeftParenthesis(), isRightParenthesis() могут быть легко определены с помощью регулярных выражений:
function isComma(ch) {
return (ch === ",");
}
function isDigit(ch) {
return /\d/.test(ch);
}
function isLetter(ch) {
return /[a-z]/i.test(ch);
}
function isOperator(ch) {
return /\+|-|\*|\/|\^/.test(ch);
}
function isLeftParenthesis(ch) {
return (ch === "(");
}
function isRightParenthesis(ch) {
return (ch == ")");
}
Обратите внимание, здесь нет функций isFunction(), isLiteral() или isVariable(). Мы тестируем каждый символ отдельно от других.
Парсер уже работает. Вы можете протестировать его на выражениях:
2 + 34a + 15x + (2y)- 1
1 + sin(20.4)
Все хорошо? Не совсем.
В последнем выражении число 11 отображается как два Литеральных токена вместо одного. А функция sin вообще выглядит как три отдельных токена.
Действительно, некоторые токены могут состоять из нескольких символов: и Литералы (55, 7.9, .5), и Функции (sin, cos). Переменные односимвольны, но они могут объединяться в выражениях неявного умножения. Как решить эту проблему?
Буфер
На помощь приходит буфер. Два буфера: один – для хранения Литеральных символов (цифр и десятичных точек), второй – для букв (Переменных и Функций).
Когда токенизатор встречает число, десятичную точку или букву, он помещает их в соответствующий буфер. Это продолжается, пока не встретится токен другого типа.
Например, анализ выражения 456.7 xy + 6sin(7.04 x) — min(a, 7) будет выглядеть так:
read 4 => numberBuffer read 5 => numberBuffer read 6 => numberBuffer read . => numberBuffer read 7 => numberBuffer x это буква, поэтому все содержимое numberBuffer объединяется в один Литерал 456.7 => result read x => letterBuffer read y => letterBuffer + это оператор, поэтому извлекается все содержимое letterBuffer, делится на односимвольные Переменные и записывается в результат x => result, y => result + => result read 6 => numberBuffer s это буква, поэтому все содержимое numberBuffer объединяется в один Литерал 6 => result read s => letterBuffer read i => letterBuffer read n => letterBuffer ( это Левая Скобка, поэтому все содержимое letterBuffer объединяется в одну функцию function sin => result read 7 => numberBuffer read . => numberBuffer read 0 => numberBuffer read 4 => numberBuffer x это буква, поэтому все содержимое numberBuffer объединяется в один Литерал 7.04 => result read x => letterBuffer ) это Правая Скобка, поэтому весь контент letterBuffer извлекается и записывается в результат как Переменная x => result - это Оператор, но оба буфера пусты, поэтому удалять нечего read m => letterBuffer read i => letterBuffer read n => letterBuffer ( это Левая Скобка, поэтому все содержимое letterBuffer объединяется в одну функцию function min => result read a=> letterBuffer , это запятая, поэтому все содержимое letterBuffer записывается в результат как Переменная a => result, затем туда же записывается запятая как Разделитель Аргументов Функции => result read 7=> numberBuffer ) это Правая Скобка, поэтому весь контент numberBuffer объединяется в Литерал 7 => result
Готово, осталось совсем немного.
Инструкция
Что произойдет, если текущий символ является оператором, а numberBuffer не пуст? А могут ли оба буфера быть непустыми одновременно?
Соберем все вместе в небольшой инструкции. Слева от стрелки указан тип текущего символа (char), NB = numberBuffer, LB = letterBuffer, LP = левая скобка, RP = правая скобка.
- Цикл по массиву символов, определение типа текущего символа:
- цифра => отправить char в NB
- десятичная точка => отправить char в NB
- буква => объединить содержимое NB в один Литерал и отправить в результат, затем отправить char в LB
- оператор => объединить содержимое NB в один Литерал и отправить в результат или взять содержимое LB, разделить его на отдельные Переменные и отправить в результат, затем отправить char в результат
- LP => объединить содержимое LB в одну Функцию и отправить в результат или (объединить содержимое NB в один Литерал и отправить в результат и отправить Оператор * в результат), затем отправить char в результат
- RP => объединить содержимое NB в один Литерал и отправить в результат, взять содержимое LB, разделить его на отдельные Переменные и отправить в результат, затем отправить char в результат
- запятая => объединить содержимое NB в один Литерал и отправить в результат, взять содержимое LB, разделить его на отдельные Переменные и отправить в результат, затем отправить char в результат
- закончить цикл
- объединить содержимое NB в один Литерал и отправить в результат, взять содержимое LB, разделить его на отдельные Переменные и отправить в результат
Обратите внимание на две вещи:
- Неявное умножение преобразуется в явное, в результат добавляется оператор *. Также нужно помнить о том, что между отдельными переменными, извлеченными из LB необходимо вставлять тот же оператор умножения.
- После цикла нужно очистить все накопленное в буферах.
Оформление
Соберем все вместе и оформим токенизатор на реальном языке программирования:
function Token(type, value) {
this.type = type;
this.value = value;
}
function isComma(ch) {
return /,/.test(ch);
}
function isDigit(ch) {
return /\d/.test(ch);
}
function isLetter(ch) {
return /[a-z]/i.test(ch);
}
function isOperator(ch) {
return /\+|-|\*|\/|\^/.test(ch);
}
function isLeftParenthesis(ch) {
return /\(/.test(ch);
}
function isRightParenthesis(ch) {
return /\)/.test(ch);
}
function tokenize(str) {
str.replace(/\s+/g, "");
str=str.split("");
var result=[];
var letterBuffer=[];
var numberBuffer=[];
str.forEach(function (char, idx) {
if(isDigit(char)) {
numberBuffer.push(char);
} else if(char==".") {
numberBuffer.push(char);
} else if (isLetter(char)) {
if(numberBuffer.length) {
emptyNumberBufferAsLiteral();
result.push(new Token("Operator", "*"));
}
letterBuffer.push(char);
} else if (isOperator(char)) {
emptyNumberBufferAsLiteral();
emptyLetterBufferAsVariables();
result.push(new Token("Operator", char));
} else if (isLeftParenthesis(char)) {
if(letterBuffer.length) {
result.push(new Token("Function", letterBuffer.join("")));
letterBuffer=[];
} else if(numberBuffer.length) {
emptyNumberBufferAsLiteral();
result.push(new Token("Operator", "*"));
}
result.push(new Token("Left Parenthesis", char));
} else if (isRightParenthesis(char)) {
emptyLetterBufferAsVariables();
emptyNumberBufferAsLiteral();
result.push(new Token("Right Parenthesis", char));
} else if (isComma(char)) {
emptyNumberBufferAsLiteral();
emptyLetterBufferAsVariables();
result.push(new Token("Function Argument Separator", char));
}
});
if (numberBuffer.length) {
emptyNumberBufferAsLiteral();
}
if(letterBuffer.length) {
emptyLetterBufferAsVariables();
}
return result;
function emptyLetterBufferAsVariables() {
var l = letterBuffer.length;
for (var i = 0; i < l; i++) {
result.push(new Token("Variable", letterBuffer[i]));
if(i< l-1) { //there are more Variables left
result.push(new Token("Operator", "*"));
}
}
letterBuffer = [];
}
function emptyNumberBufferAsLiteral() {
if(numberBuffer.length) {
result.push(new Token("Literal", numberBuffer.join("")));
numberBuffer=[];
}
}
}
А вот небольшое демо работы этого лексического анализатора:
var tokens = tokenize("89sin(45) + 2.2x/7");
tokens.forEach(function(token, index) {
console.log(index + "=> " + token.type + "(" + token.value + ")":
});
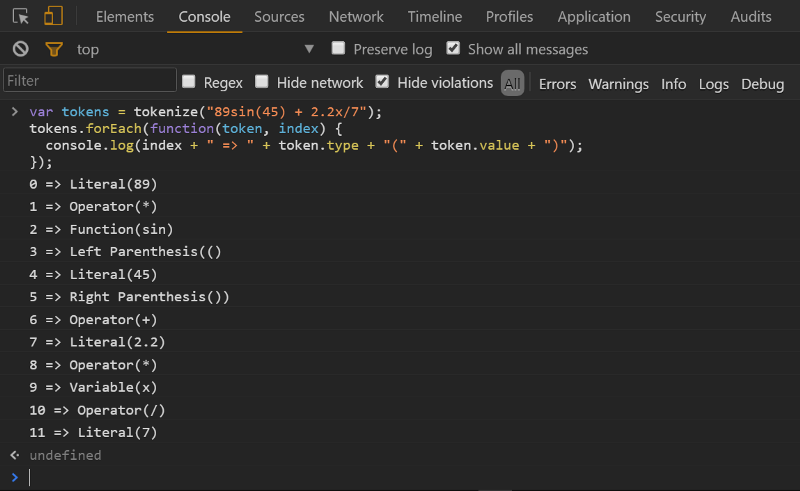
Для полноты картины нужно провести ряд тестов и учесть крайние случаи, например, отрицательные числа.
Оригинальная статья: How to build a math expression tokenizer using JavaScript (or any other language)
Комментарии