
В этом пособии с соответствующими примерами кода рассказываем о том, как написать при помощи Python свой язык программирования и компилятор к нему.
Введение
Изучение компиляторов и устройства языков программирования по видеоурокам и руководствам – дело для новичков тяжелое. В этих материалах нередко отсутствуют важные составляющие. Цель публикации – помочь людям, ищущим способ создать свой язык программирования и компилятор. Пример игрушечный, но позволит понять, с чего начать и в каком направлении двигаться.
Системные требования
Если вы незнакомы с нижеприведенными понятиями, не беспокойтесь – мы проясним необходимость этих компонентов далее, по ходу создания компилятора. В качестве лексера и парсера используется PLY. В роли низкоуровневого языка-посредника для генерации оптимизированного кода выступает LLVMlite.
Таким образом, к системе предъявляются следующие требования:
- Среда Anaconda (более простой способ для инсталляции LLVMlite – conda, а не классический pip)
- LLVMlite
$ conda install --channel=numba llvmlite
- RPLY (то же, что PLY, но с более хорошим API)
$ conda install -c conda-forge rply
Свой язык программирования: с чего начать?
Начнем с того, что назовем свой язык программирования. В качестве примера он будет называться TOY. Пусть пример программы на языке TOY выглядит следующим образом:
var x;
x := 4 + 4 * 2;
if (x > 3) {
x := 2;
} else {
x := 5;
}
print(x);
Любой язык программирования включает множество составляющих его компонентов. Чтобы не застрять в мелочах, возьмем в качестве микропрограммы вызов одной функции нашего языка:
print(4 + 4 - 2);
Как для этой однострочной программы формально описать грамматику языка? Чтобы это сделать, необходимо использовать расширенную Бэкус – Наурову форму (РБНФ) (англ. Extended Backus–Naur Form (EBNF)). Это формальная система определения синтаксиса языка. Воплощается она при помощи метаязыка, определяющего в одном документе всевозможные грамматические конструкции. Чтобы в деталях разобраться с тем, как работает РБНФ, прочтите эту публикацию.
Создаем РБНФ (EBNF)
Создадим РБНФ, которая опишет минимальный функционал нашей микропрограммы. Начнем с операции суммирования:
4 + 2;
Соответствующая РБНФ будет выглядеть следующим образом:
expression = number, "+", number, ";"; number = digit+; digit = [0-9];
Дополним язык операцией вычитания:
4 + 4 - 2;
В соответствующем РБНФ изменится первая строка:
expression = number, { ("+"|"-"), number }, ";";
number = digit+;
digit = [0-9];
Наконец, опишем функцию print:
print(4 + 4 - 2);
В этом случае в РБНФ появится новая строка, описывающая работу с выражениями:
program = "print", "(", expression, ")", ";";
expression = number, { ("+"|"-"), number } ;
number = digit+
digit = [0-9];
В таком ключе развивается описание грамматики языка. Как же научить компьютер транслироваться эту грамматику в бинарный исполняемый код? Для этого нужен компилятор.
Компилятор
Компилятор – это программа, переводящая текст ЯП на машинный или другие языки. Программы на TOY в этом руководстве будут компилироваться в промежуточное представление LLVM IR (IR – сокращение от Intermediate Representation) и затем в машинный язык.
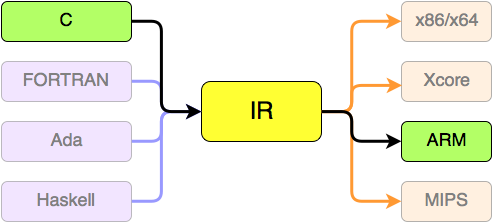
Использование LLVM позволяет оптимизировать процесс компиляции без изучения самого процесса оптимизации. У LLVM действительно хорошая библиотека для работы с компиляторами.
Наш компилятор можно разделить на три составляющие:
- лексический анализатор (лексер, англ. lexer)
- синтаксический анализатор (парсер, англ. parser)
- генератор кода
Для лексического анализатора и парсера мы будем использовать RPLY, очень близкий к PLY. Это библиотека Python с теми же лексическими и парсинговыми инструментами, но с более качественным API. Для генератора кода будем использовать LLVMLite – библиотеку Python для связывания компонентов LLVM.
1. Лексический анализатор
Итак, первый компонент компилятора – лексический анализатор. Роль этого компонента заключается в том, чтобы разделять текст программы на токены.
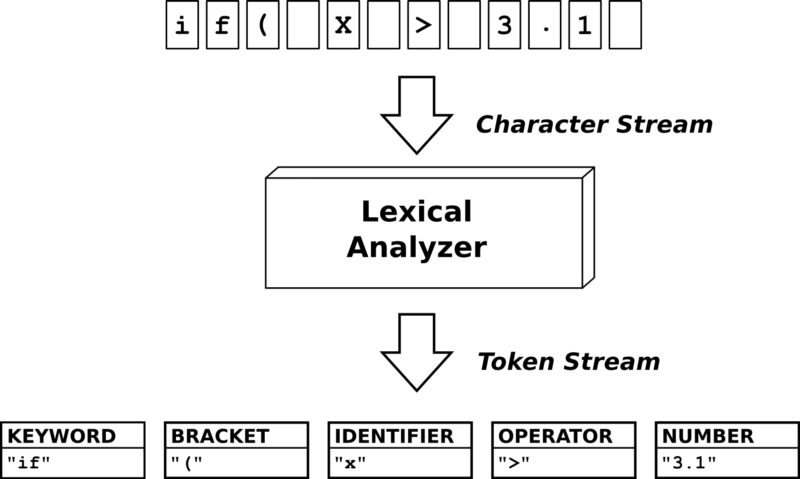
Воспользуемся последней структурой из примера для РБНФ и найдем токены. Рассмотрим команду:
print(4 + 4 - 2);
Наш лексический анализатор должен разделить эту строку на следующий список токенов:
Token('PRINT', 'print')
Token('OPEN_PAREN', '(')
Token('NUMBER', '4')
Token('SUM', '+')
Token('NUMBER', '4')
Token('SUB', '-')
Token('NUMBER', '2')
Token('CLOSE_PAREN', ')')
Token('SEMI_COLON', ';')
Напишем код компилятора. Для начала создадим файл lexer.py, в программном коде которого будут определяться токены. Для создания лексического анализатора воспользуемся классом LexerGenerator библиотеки RPLY.
from rply import LexerGenerator
class Lexer():
def __init__(self):
self.lexer = LexerGenerator()
def _add_tokens(self):
# Print
self.lexer.add('PRINT', r'print')
# Скобки
self.lexer.add('OPEN_PAREN', r'\(')
self.lexer.add('CLOSE_PAREN', r'\)')
# Точка с запятой
self.lexer.add('SEMI_COLON', r'\;')
# Операторы
self.lexer.add('SUM', r'\+')
self.lexer.add('SUB', r'\-')
# Числа
self.lexer.add('NUMBER', r'\d+')
# Игнорируем пробелы
self.lexer.ignore('\s+')
def get_lexer(self):
self._add_tokens()
return self.lexer.build()
Создадим основной файл программы main.py. В этом файле мы впоследствии объединим функционал трех компонентов компилятора. Для начала импортируем созданный нами класс Lexer и определим токены для нашей однострочной программы:
from lexer import Lexer
text_input = """
print(4 + 4 - 2);
"""
lexer = Lexer().get_lexer()
tokens = lexer.lex(text_input)
for token in tokens:
print(token)
При запуске main.py мы увидим на выходе вышеописанные токены. Вы можете изменить названия своих токенов, но для простоты согласования с функциями парсера их лучше оставить как есть.
2. Синтаксический анализатор
Второй компонент компилятора – синтаксический анализатор (он же парсер). Его роль – синтаксический анализ текста программы. Данный компонент принимает список токенов на входе и создает на выходе абстрактное синтаксическое дерево (АСД). Эта концепция более трудна, чем идея списка токенов, поэтому мы настоятельно рекомендуем хотя бы по приведенным выше ссылкам изучить принципы работы парсеров и синтаксических деревьев.
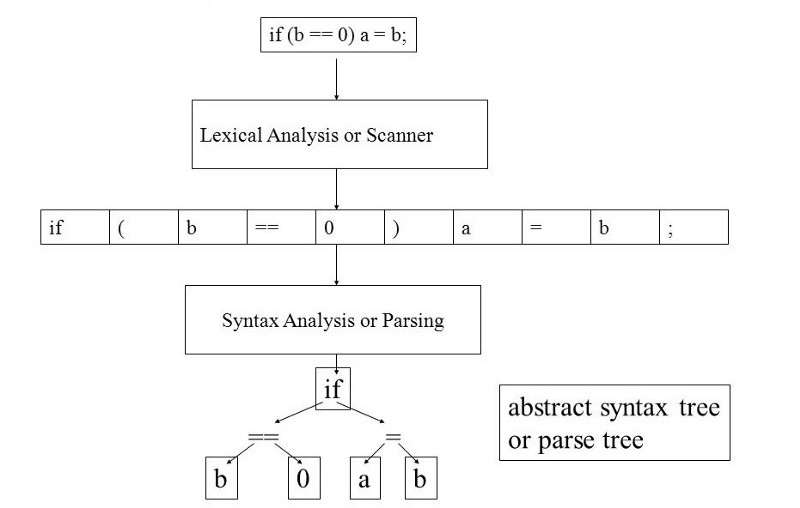
Чтобы воплотить в жизнь синтаксический анализатор, будем использовать структуру, созданную на этапе РБНФ. К счастью, анализатор RPLY использует формат, схожий с РБНФ. Самое сложное – присоединить синтаксический анализатор к АСД, но когда вы поймете идею, это действие станет действительно механическим.
Во-первых, создадим файл ast.py. Он будет содержать все классы, которые могут быть вызваны парсером, и создавать АСД.
class Number():
def __init__(self, value):
self.value = value
def eval(self):
return int(self.value)
class BinaryOp():
def __init__(self, left, right):
self.left = left
self.right = right
class Sum(BinaryOp):
def eval(self):
return self.left.eval() + self.right.eval()
class Sub(BinaryOp):
def eval(self):
return self.left.eval() - self.right.eval()
class Print():
def __init__(self, value):
self.value = value
def eval(self):
print(self.value.eval())
Во-вторых, нам необходимо создать сам анализатор. Для этого в новом файле parser.py аналогично лексеру используем класс ParserGenerator из библиотеки RPLY:
from rply import ParserGenerator
from ast import Number, Sum, Sub, Print
class Parser():
def __init__(self):
self.pg = ParserGenerator(
# Список всех токенов, принятых парсером.
['NUMBER', 'PRINT', 'OPEN_PAREN', 'CLOSE_PAREN',
'SEMI_COLON', 'SUM', 'SUB']
)
def parse(self):
@self.pg.production('program : PRINT OPEN_PAREN expression CLOSE_PAREN SEMI_COLON')
def program(p):
return Print(p[2])
@self.pg.production('expression : expression SUM expression')
@self.pg.production('expression : expression SUB expression')
def expression(p):
left = p[0]
right = p[2]
operator = p[1]
if operator.gettokentype() == 'SUM':
return Sum(left, right)
elif operator.gettokentype() == 'SUB':
return Sub(left, right)
@self.pg.production('expression : NUMBER')
def number(p):
return Number(p[0].value)
@self.pg.error
def error_handle(token):
raise ValueError(token)
def get_parser(self):
return self.pg.build()
Наконец, обновляем файл main.py, чтобы объединить возможности синтаксического и лексического анализаторов:
from lexer import Lexer from parser import Parser text_input = """ print(4 + 4 - 2); """ lexer = Lexer().get_lexer() tokens = lexer.lex(text_input) pg = Parser() pg.parse() parser = pg.get_parser() parser.parse(tokens).eval()
Теперь при запуске main.py мы получим значение 6. и оно действительно соответствует нашей однострочной программе "print(4 + 4 – 2);".
Таким образом, при помощи двух этих компонентов мы создали работающий компилятор, интерпретирующий язык TOY. Однако компилятор по-прежнему не создает исполняемый машинный код и не оптимизирован. Для этого мы перейдем к самой сложной части руководства – генерации кода с помощью LLVM.
3. Генератор кода
Третья и последняя часть компилятора – это генератор кода. Его роль заключается в том, чтобы преобразовывать АСД в машинный код или промежуточное представление. В нашем случае будет происходить преобразование АСД в промежуточное представление LLVM (LLVM IR).
LLVM может оказаться действительно сложным для понимания инструментом, поэтому обратите внимание на документацию LLVMlite. LLVMlite не имеет реализации для функции печати, поэтому вы должны определить собственную функцию.
Чтобы начать, создадим файл codegen.py, содержащий класс CodeGen. Этот класс отвечает за настройку LLVM и создание/сохранение IR-кода. В нем мы также объявим функцию печати.
from llvmlite import ir, binding
class CodeGen():
def __init__(self):
self.binding = binding
self.binding.initialize()
self.binding.initialize_native_target()
self.binding.initialize_native_asmprinter()
self._config_llvm()
self._create_execution_engine()
self._declare_print_function()
def _config_llvm(self):
# Config LLVM
self.module = ir.Module(name=__file__)
self.module.triple = self.binding.get_default_triple()
func_type = ir.FunctionType(ir.VoidType(), [], False)
base_func = ir.Function(self.module, func_type, name="main")
block = base_func.append_basic_block(name="entry")
self.builder = ir.IRBuilder(block)
def _create_execution_engine(self):
"""
Create an ExecutionEngine suitable for JIT code generation on
the host CPU. The engine is reusable for an arbitrary number of
modules.
"""
target = self.binding.Target.from_default_triple()
target_machine = target.create_target_machine()
# And an execution engine with an empty backing module
backing_mod = binding.parse_assembly("")
engine = binding.create_mcjit_compiler(backing_mod, target_machine)
self.engine = engine
def _declare_print_function(self):
# Функция Printf
voidptr_ty = ir.IntType(8).as_pointer()
printf_ty = ir.FunctionType(ir.IntType(32), [voidptr_ty], var_arg=True)
printf = ir.Function(self.module, printf_ty, name="printf")
self.printf = printf
def _compile_ir(self):
"""
Compile the LLVM IR string with the given engine.
The compiled module object is returned.
"""
# Создание LLVM модуля
self.builder.ret_void()
llvm_ir = str(self.module)
mod = self.binding.parse_assembly(llvm_ir)
mod.verify()
# Теперь добавляем модуль и убеждаемся, что он готов к выполнению
self.engine.add_module(mod)
self.engine.finalize_object()
self.engine.run_static_constructors()
return mod
def create_ir(self):
self._compile_ir()
def save_ir(self, filename):
with open(filename, 'w') as output_file:
output_file.write(str(self.module))
Теперь обновим основной файл main.py, чтобы вызывать методы CodeGen:
from lexer import Lexer
from parser import Parser
from codegen import CodeGen
fname = "input.toy"
with open(fname) as f:
text_input = f.read()
lexer = Lexer().get_lexer()
tokens = lexer.lex(text_input)
codegen = CodeGen()
module = codegen.module
builder = codegen.builder
printf = codegen.printf
pg = Parser(module, builder, printf)
pg.parse()
parser = pg.get_parser()
parser.parse(tokens).eval()
codegen.create_ir()
codegen.save_ir("output.ll")
Как вы можете видеть, для того, чтобы обработка происходила классическим образом, входная программа была вынесена в отдельный файл input.toy. Это уже больше похоже на классический компилятор. Файл input.toy содержит все ту же однострочную программу:
print(4 + 4 - 2);
Еще одно изменение – передача парсеру методов module, builder и printf. Это сделано, чтобы мы могли отправить эти объекты АСД. Таким образом, для получения объектов и передачи их АСД необходимо изменить parser.py:
from rply import ParserGenerator
from ast import Number, Sum, Sub, Print
class Parser():
def __init__(self, module, builder, printf):
self.pg = ParserGenerator(
# Список всех токенов, принятых парсером.
['NUMBER', 'PRINT', 'OPEN_PAREN', 'CLOSE_PAREN',
'SEMI_COLON', 'SUM', 'SUB']
)
self.module = module
self.builder = builder
self.printf = printf
def parse(self):
@self.pg.production('program : PRINT OPEN_PAREN expression CLOSE_PAREN SEMI_COLON')
def program(p):
return Print(self.builder, self.module, self.printf, p[2])
@self.pg.production('expression : expression SUM expression')
@self.pg.production('expression : expression SUB expression')
def expression(p):
left = p[0]
right = p[2]
operator = p[1]
if operator.gettokentype() == 'SUM':
return Sum(self.builder, self.module, left, right)
elif operator.gettokentype() == 'SUB':
return Sub(self.builder, self.module, left, right)
@self.pg.production('expression : NUMBER')
def number(p):
return Number(self.builder, self.module, p[0].value)
@self.pg.error
def error_handle(token):
raise ValueError(token)
def get_parser(self):
return self.pg.build()
Наконец, самое важное. Мы должны изменить файл ast.py, чтобы получать эти объекты и создавать LLMV АСД, используя методы из библиотеки LLVMlite:
from llvmlite import ir
class Number():
def __init__(self, builder, module, value):
self.builder = builder
self.module = module
self.value = value
def eval(self):
i = ir.Constant(ir.IntType(8), int(self.value))
return i
class BinaryOp():
def __init__(self, builder, module, left, right):
self.builder = builder
self.module = module
self.left = left
self.right = right
class Sum(BinaryOp):
def eval(self):
i = self.builder.add(self.left.eval(), self.right.eval())
return i
class Sub(BinaryOp):
def eval(self):
i = self.builder.sub(self.left.eval(), self.right.eval())
return i
class Print():
def __init__(self, builder, module, printf, value):
self.builder = builder
self.module = module
self.printf = printf
self.value = value
def eval(self):
value = self.value.eval()
# Объявление списка аргументов
voidptr_ty = ir.IntType(8).as_pointer()
fmt = "%i \n\0"
c_fmt = ir.Constant(ir.ArrayType(ir.IntType(8), len(fmt)),
bytearray(fmt.encode("utf8")))
global_fmt = ir.GlobalVariable(self.module, c_fmt.type, name="fstr")
global_fmt.linkage = 'internal'
global_fmt.global_constant = True
global_fmt.initializer = c_fmt
fmt_arg = self.builder.bitcast(global_fmt, voidptr_ty)
# Вызов ф-ии Print
self.builder.call(self.printf, [fmt_arg, value])
После изменений компилятор готов к преобразованию программы на языке TOY в файл промежуточного представления LLVM output.ll. Далее используем LLC для создания файла объекта output.o и GCC для получения конечного исполняемого файла:
$ llc -filetype=obj -relocation-model=pic output.ll $ gcc output.o -o output
Теперь вы можете запустить исполняем файл, для создания которого вами использовался свой язык программирования:
$ ./output
Следующие шаги
Мы надеемся, что после прохождения этого руководства вы разобрались в общих чертах в концепции РБНФ и трех основных составляющих компилятора. Благодаря этим знаниям вы можете создать свой язык программирования и написать оптимизированный компилятор при помощи Python. Мы призываем вас не останавливаться на достигнутом и добавить в свой язык и компилятор другие важные составляющие:
- Переменные
- Бинарные операторы
- Унарные операторы
- Условия
- Циклы
Итоговый программный код вы также найдете на GitHub.
Оригинал: https://medium.com/@marcelogdeandrade/writing-your-own-programming-language-and-compiler-with-python-a468970ae6df
Другие материалы по теме языков программирования
- Nim: совершенный язык программирования
- Ликбез по типизации в языках программирования
- 10 лучших языков программирования для изучения в 2018 году
- Мертвые и живые языки программирования: что изучать, а что обойти стороной?
- 30 книг для освоения языка программирования Go
- Лучшие языки программирования для Data Science

Комментарии