
Хотите добиться лучшего объяснения моделей машинного обучения? Нужна хорошая визуализация? Используйте эти Python библиотеки.

Из-за шума вокруг предвзятости искусственного интеллекта организации всё острее нуждаются в объяснении как прогнозов создаваемых моделей, так и принципов работы.
К счастью, растёт количество библиотек, которые предлагает язык программирования Python для решения этой проблемы. Ниже краткое руководство по четырём популярным библиотекам для интерпретации и объяснения моделей машинного обучения. Устанавливаются с использованием pip, поставляются с подробной документацией и делают упор на визуальную интерпретацию.
Yellowbrick
Эта Python библиотека и расширение пакета scikit-learn. Предоставляет некоторые полезные и симпатичные визуализации для моделей машинного обучения. Объекты визуализатора, основной интерфейс – оценки scikit-learn, поэтому если привыкли работать с scikit-learn, рабочий процесс покажется знакомым.
Предоставляемые визуализации охватывают выбор модели, определение значимости признаков и анализ производительности модели. Пройдёмся по нескольким кратким примерам.
Библиотека устанавливается с помощью pip.
pip install yellowbrick
Чтобы проиллюстрировать пару функциональных особенностей, будем использовать набор данных scikit-learn с именем «распознавание вина». Этот датасет с 13 признаками и 3 целевыми классами загружается непосредственно из библиотеки scikit-learn. В приведённом ниже коде импортируем набор данных и преобразуем в объект DataFrame. Классификатор умеет использовать информацию без предварительной обработки.
import pandas as pd from sklearn import datasets wine_data = datasets.load_wine() df_wine = pd.DataFrame(wine_data.data,columns=wine_data.feature_names) df_wine['target'] = pd.Series(wine_data.target)
Применяйте scikit-learn для дальнейшего разделения датасета на проверку и тренировку.
from sklearn.model_selection import train_test_split X = df_wine.drop(['target'], axis=1) y = df_wine['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
На следующем шаге используйте визуализатор Yellowbricks для просмотра корреляций между признаками в наборе данных.
from yellowbrick.features import Rank2D import matplotlib.pyplot as plt visualizer = Rank2D(algorithm="pearson", size=(1080, 720)) visualizer.fit_transform(X_train) visualizer.poof()
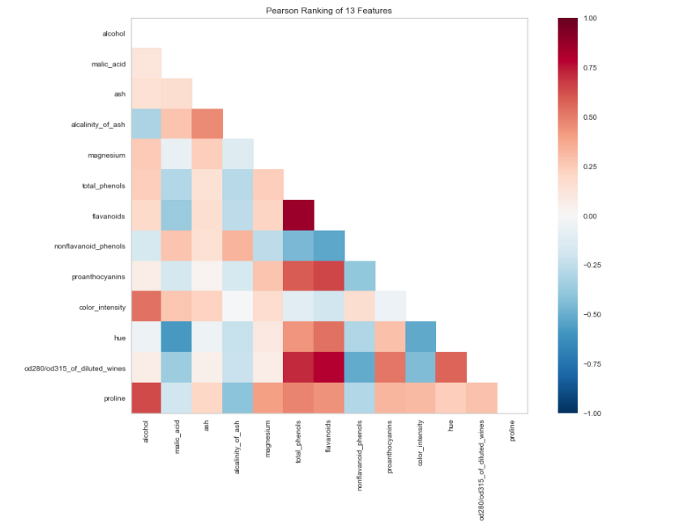
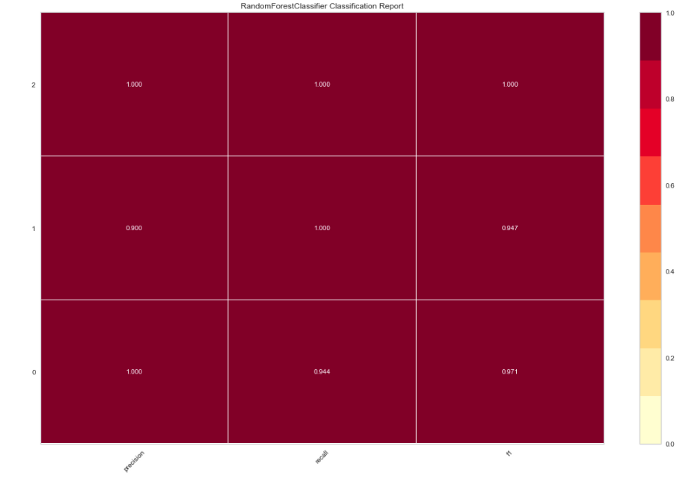
Теперь подгоним RandomForestClassifier и оценим производительность с помощью другого визуализатора.
from yellowbrick.classifier import ClassificationReport from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() visualizer = ClassificationReport(model, size=(1080, 720)) visualizer.fit(X_train, y_train) visualizer.score(X_test, y_test) visualizer.poof()
ELI5
ELI5 – ещё одна библиотека визуализации, которая пригодится для отладки моделей машинного обучения и объяснения сделанных прогнозов. Работает с самыми распространёнными инструментами машинного обучения на Python, включая scikit-learn, XGBoost и Keras.
Примените ELI5 для проверки значимости признаков модели, которую рассматривали выше.
import eli5 eli5.show_weights(model, feature_names = X.columns.tolist())
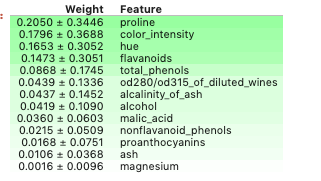
По умолчанию метод show_weights использует gain для расчёта веса, а когда понадобятся другие типы, добавьте аргумент importance_type.
И также применяйте show_prediction для проверки оснований отдельных прогнозов.
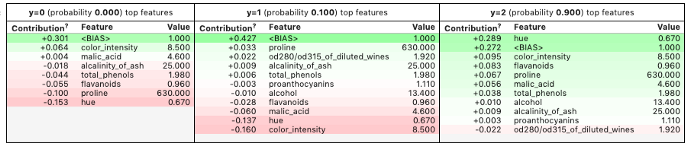
LIME
LIME расшифровывается как локальные интерпретируемые, независимые от модели объяснения. Интерпретирует предсказания, сделанные алгоритмами машинного обучения. Lime поддерживает объяснение единичных прогнозов из диапазона классификаторов, а также взаимодействует с scikit-learn «из коробки».
Воспользуемся Lime для интерпретации прогнозов модели, которую обучали раньше.
Устанавливаем библиотеку через pip.
pip install lime
Сначала создадим интерпретатор. Для этого берём тренировочный набор данных в виде массива из названий признаков, используемых в модели, и имён классов в целевой переменной.
import lime.lime_tabular explainer = lime.lime_tabular.LimeTabularExplainer(X_train.values, feature_names=X_train.columns.values.tolist(), class_names=y_train.unique())
Затем создаём лямбда-функцию, которая берёт модель для прогнозирования выборки данных. Строчку взяли из подробного руководства по Lime.
predict_fn = lambda x: model.predict_proba(x).astype(float)
Используйте интерпретатор, чтобы объяснить прогноз на отобранном образце. Результат увидите ниже. Lime создаёт визуализацию, которая показывает, как признаки внесли вклад в определённый прогноз.
exp = explainer.explain_instance(X_test.values[0], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)

MLxtend
В этой библиотеке найдёте массу вспомогательных функций для машинного обучения. Она охватывает классификаторы стекинга и голосования, оценку модели, выделение признаков, а также проектирование и построение графиков. Дополнительно к документации в помощь с Python библиотекой рекомендуем почитать углублённый материал.
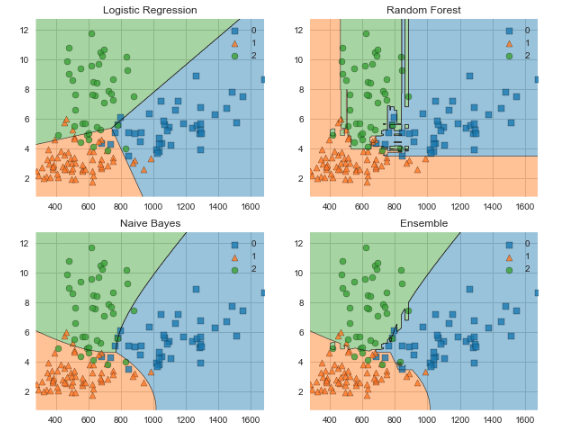
Обратимся к MLxtend для сравнения границ решения классификатора голосования и составного классификатора.
Снова понадобится pip для установки.
pip install mlxtend
Используемые импорты смотрите ниже.
from mlxtend.plotting import plot_decision_regions from mlxtend.classifier import EnsembleVoteClassifier import matplotlib.gridspec as gridspec import itertools from sklearn import model_selection from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import RandomForestClassifier
Следующая визуализация работает только с двумя признаками одновременно, поэтому сначала создадим массив со свойствами proline и color_intensity. Выбрали эти признаки из-за наибольшего веса по сравнению с теми, что проверяли выше с помощью ELI5.
X_train_ml = X_train[['proline', 'color_intensity']].values y_train_ml = y_train.values
Затем создаём классификаторы, подгоняем к данным обучения и получаем визуализацию границ решений с помощью MLxtend. Результат под кодом.
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3], weights=[1,1,1])
value=1.5
width=0.75
gs = gridspec.GridSpec(2,2)
fig = plt.figure(figsize=(10,8))
labels = ['Logistic Regression', 'Random Forest', 'Naive Bayes', 'Ensemble']
for clf, lab, grd in zip([clf1, clf2, clf3, eclf],
labels,
itertools.product([0, 1], repeat=2)):
clf.fit(X_train_ml, y_train_ml)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X_train_ml, y=y_train_ml, clf=clf)
plt.title(lab)
На этом не исчерпывается список библиотек для интерпретации, объяснения и визуализации моделей машинного обучения, которые использует Python разработчик. Попробуйте также другие полезные инструменты из длинного списка.
Комментарии