
Регрессия используется в ML. Рассмотрим несколько алгоритмов и определим, как их использовать, исходя из преимуществ и недостатков.

Сталкиваясь с какой-либо проблемой в ML, помните, что есть множество алгоритмов, позволяющих её решить. Однако не существует такого универсального алгоритма, который подходил бы под все случаи и решал абсолютно все проблемы.
Выбор алгоритма строго зависит от размера и структуры ваших данных. Таким образом, выбор правильного алгоритма может быть неясен до тех пор, пока мы не проверим возможные варианты и не наткнёмся на ошибки.
Но каждый алгоритм обладает как преимуществами, так и недостатками, которые можно использовать в качестве руководства для выбора наиболее подходящего под ситуацию.
Линейная и полиномиальная регрессия
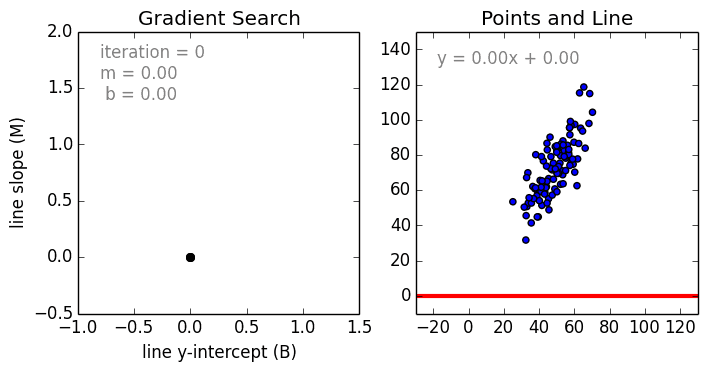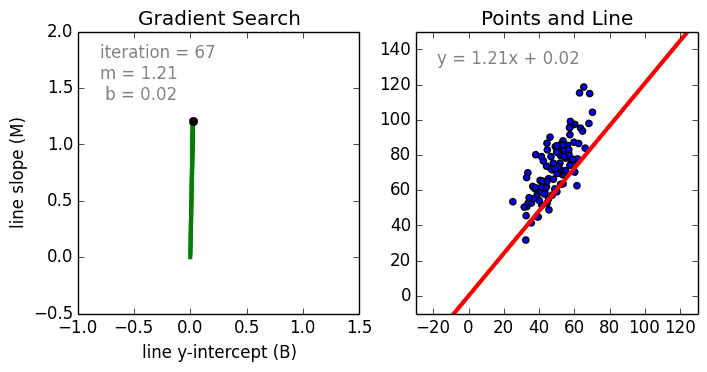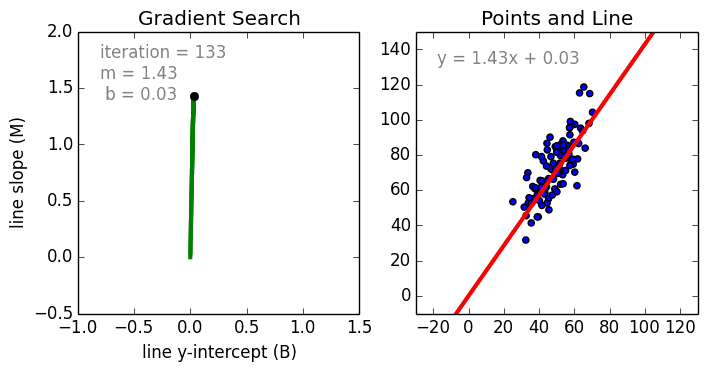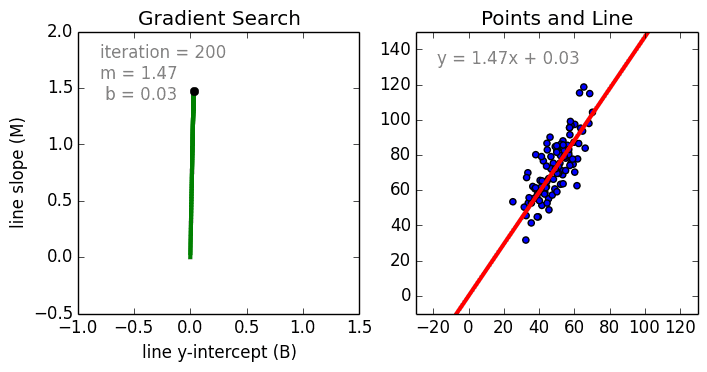
Начнём с простого. Одномерная (простая) линейная регрессия – это метод, используемый для моделирования отношений между одной независимой входной переменной (переменной функции) и выходной зависимой переменной. Модель линейная.
Более общий случай – множественная линейная регрессия, где создаётся модель взаимосвязи между несколькими входными переменными и выходной зависимой переменной. Модель остаётся линейной, поскольку выходное значение представляет собой линейную комбинацию входных значений.
Также стоит упомянуть полиномиальную регрессию. Модель становится нелинейной комбинацией входных переменных, т. е. среди них могут быть экспоненциальные переменные: синус, косинус и т. п. Модели регрессии можно обучить с помощью метода стохастического градиента.
Преимущества:
- Быстрое моделирование. В особенности, моделирование можно назвать простым, если отсутствует большой объём данных.
- Линейную регрессию легко понять. Она может быть ценна для различных бизнес-решений.
Недостатки:
- В случае нелинейных данных полиномиальную регрессию трудно спроектировать. Необходимо иметь информацию о структуре данных и взаимосвязи между переменными.
- Основываясь на изложенных выше фактах, линейная регрессия неэффективна, когда речь идёт об очень сложных данных и больших объёмах.
Нейронные сети
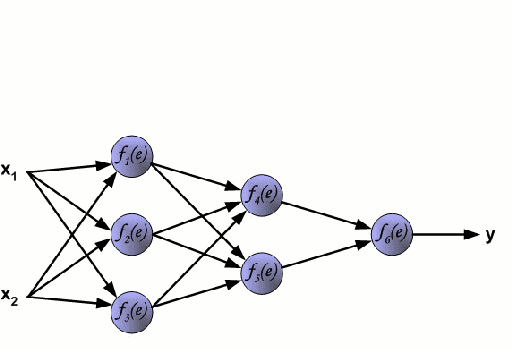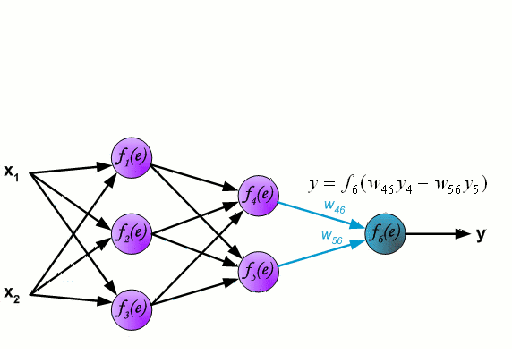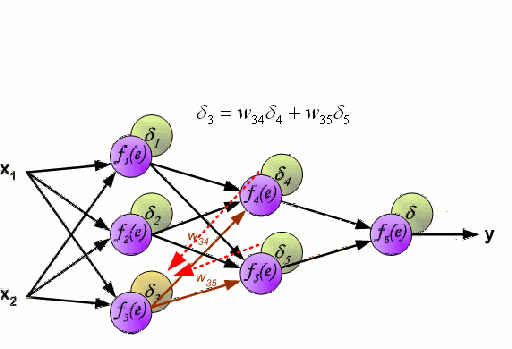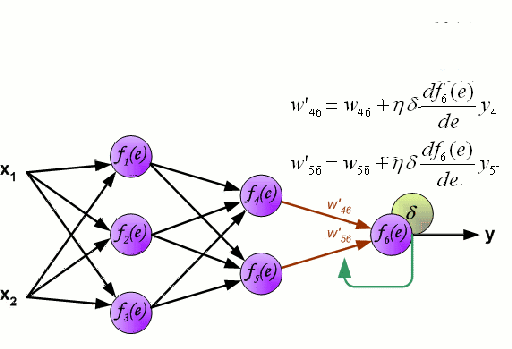
Нейронная сеть состоит из взаимосвязанных групп узлов, называемых нейронами. Входные данные передаются в эти нейроны в виде линейной комбинации со множеством переменных. Значение, умножаемое на каждую функциональную переменную, называется весом. Затем к этой линейной комбинации применяется нелинейность, что даёт нейронной сети возможность моделировать сложные нелинейные отношения. Чаще всего нейросети бывают многослойными: выход одного слоя передается следующему так, как описано выше. На выходе нелинейность не применяется.
Нейронные сети тренируются с помощью метода стохастического градиента и алгоритма обратного распространения ошибки.
Преимущества:
- Так как нейронные сети могут быть многослойными, они эффективны при моделировании сложных нелинейных отношений.
- Нам не нужно беспокоиться о структуре данных в нейронных сетях, которые очень гибки в изучении почти любого типа переменных признаков.
- Исследования постоянно показывают: чем больше обучающих данных “дают” нейронной сети, тем производительнее она становится.
Недостатки:
- Из-за сложности этой модели, её нелегко понять и реализовать.
- Нейронные сети требуют тщательной настройки гиперпараметров и скорости обучения.
- Для достижения высокой производительности нейронным сетям необходимо огромное количество данных, и в результате, как правило, нейросети уступают другим ML алгоритмам в тех случаях, когда данных мало.
Дерево принятия решений и Случайный лес
Начнём с простого случая. Дерево принятия решений – это представления правил, находящихся в последовательной, иерархической структуре, где каждому объекту соответствует узел, дающий решение. При построении дерева важно классифицировать атрибуты так, чтобы создать “чистые” узлы. То есть выбранный атрибут должен разбить множество так, чтобы получаемые в итоге подмножества состояли из объектов, принадлежащих к одному классу, или были максимально приближены к этому, т.е. количество объектов из других классов в каждом из этих множеств было как можно меньше.
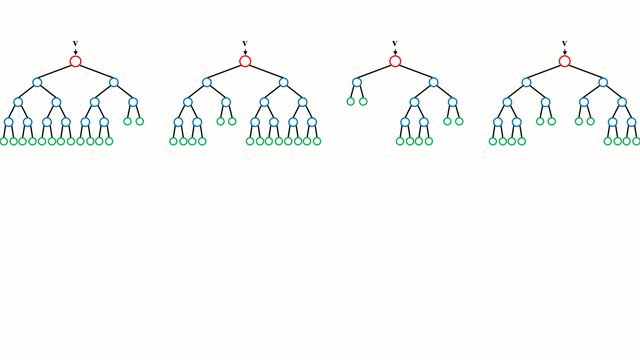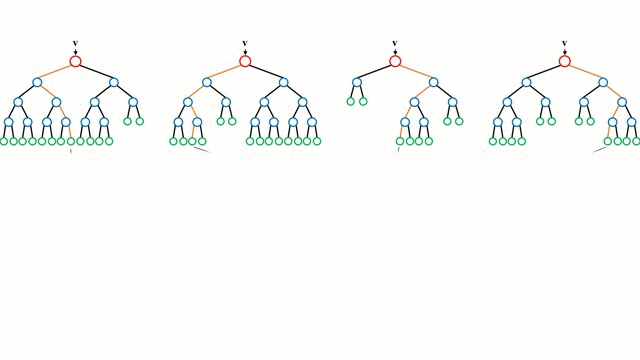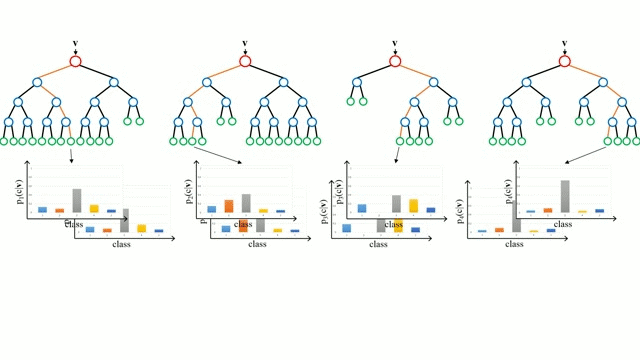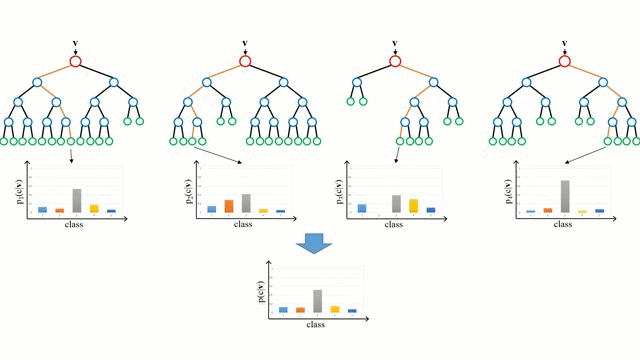
“Случайные лес” – совокупность деревьев принятия решений. Входной вектор проходит через несколько деревьев решений. Для регрессии выходное значение всех деревьев усредняется; для классификации используется схема голосования для определения конечного класса.
Преимущества:
- Отлично подходит для изучения сложных нелинейных отношений. Обычно достигают хорошей производительности: лучше, чем у полиномиальной регрессии, примерно наравне с нейронными сетями.
- Основные алгоритмы просты в понимании и реализации. Границы решений, которые создаются во время обучения, легко понять.
Недостатки:
- Деревья принятия решений могут быть склонны к серьёзному переобучению. Завершенная модель дерева решений может быть чрезмерно сложной и содержать ненужную структуру.
- Используя большие случайные леса для достижения более высокой производительности, вы жертвуете памятью и временем.
Комментарии