

Научные статьи по ИИ, которые стоит прочитать в 2020-м
Эти статьи стоит прочитать, чтобы не отставать от последних и классических прорывов в ИИ и Data Science
Искусственный интеллект (AI) – одна из самых быстрорастущих областей науки, а также один из самых востребованных навыков за последние несколько лет, обычно называемый Data Science. Эта область имеет масштабные приложения, которые обычно делятся по типу входных данных: текст, аудио, изображение, видео или график, а также по постановке задачи: обучение с учителем, без учителя и обучение с подкреплением (reinforcement learning). Следить за развитием всего этого – грандиозное усилие, которое обычно заканчивается разочаровывающей попыткой. Поэтому я предоставлю вам несколько рекомендаций по чтению, чтобы вы не отстали от последних и классических прорывов в ИИ и Data Science.
Хотя большинство перечисленных статей обрабатывают тексты и изображения, многие концепции, которые в них изложены, мало зависят от входных данных и предоставляют анализ, далеко выходящий за рамки задач машинного зрения и обработки естественного языка. Для каждой рекомендации я перечислил причины, по которым, как мне кажется, вам стоит прочитать (или перечитать) эту статью, а также добавил несколько ссылок для дальнейшего чтения, если вы захотите погрузиться в эту тему немного глубже.
Прежде, чем мы начнем, я хочу извиниться перед сообществами Аудио и Обучения с Подкреплением за то, что в моем списке нет статей по этим темам, поскольку у меня лишь небольшой опыт в этих областях.

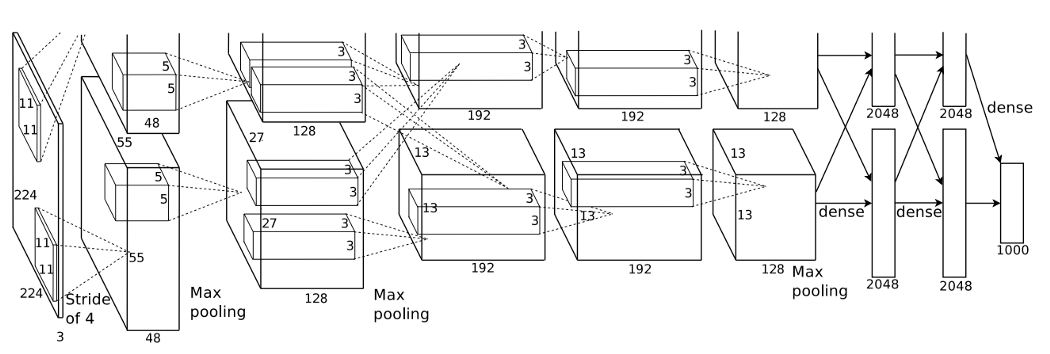
№1. AlexNet (2012)
Крижевский, Алекс., Илья Суцкевер и Джеффри Е. Хинтон "Классификация ImageNet с помощью глубоких сверточных нейронных сетей". Достижения в нейронных системах обработки информации, 2012.
Эти авторы в 2012-м году предложили использовать GPU для обучения сверточных нейронных сетей (CNN) в соревновании ImageNet. Это был смелый шаг, поскольку считалось, что CNN'ы требуют слишком много ресурсов, чтобы их можно было использовать для такой масштабной задачи. Ко всеобщему удивлению, они заняли первое место с уровнем ошибок ~15% против ~26% у команды, занявшей второе место и использовавшей самые современные технологии обработки изображений.
Причина 1: несмотря на то, что многим из нас известно историческое значение AlexNet, не каждому известно, какие из техник, используемых нами до сих пор, уже существовали до этого бума. Вы можете удивиться тому, насколько знакомыми покажутся многие концепции, представленные в этой статье – например, исключение (dropout) и ReLU.
Причина 2: Предложенная нейронная сеть имела 60 миллионов параметров – полное сумасшествие по стандартам 2012-го года. Сегодня мы можем встретить модели, имеющие более миллиарда параметров. Чтение статьи об AlexNet позволяет нам окинуть взглядом гигантский путь, пройденный нейронными сетями за это время.
Дальнейшее чтение: продолжая следить за историей чемпионов ImageNet, вы можете прочитать статьи про ZF Net, VGG, Inception-v1 и ResNet. Последняя из них достигла сверхчеловеческих способностей, решив поставленную задачу. После этого внимание исследователей перешло к другим соревнованиям. Сегодня ImageNet в основном используется для Transfer Learning и оценки моделей с низким количеством параметров, таких, как:
№2. MobileNet (2017)
Хоуард, Эндрю Г. и пр. "Mobilenets: эффективные сверточные нейронные сети для мобильных приложений машинного зрения". Препринт ArXiv 1704.04861 (2017).
MobileNet – одна из самых знаменитых нейронных сетей с низким количеством параметров. Такие модели идеальны для устройств с небольшими ресурсами и для ускорения приложений, которые должны работать в реальном времени – таких, как распознавание объектов на мобильных телефонах. Идея, лежащая в основе MobileNet и прочих моделей с низким количеством параметров – разложение дорогостоящих операций на несколько меньших операций, которые выполняются быстрее. Такие комбинированные операции часто на порядок быстрее и используют намного меньше параметров.
Причина 1: у большинства из нас и близко нет таких ресурсов, которые есть у больших технологических корпораций. Понимание того, как работают нейронные сети с низким количеством параметров, критически важно для того, чтобы сделать ваши модели дешевле в обучении и применении. По моему опыту, использование глубинной свертки (depth-wise convolution) сэкономит вам сотни долларов, которые вы могли бы потратить на облачный вывод (cloud inference) практически без потери точности.
Причина 2: Считается, что большие модели достигают лучших результатов. Статьи вроде MobileNet доказывают, что существует намного больше трюков, чем простое наращивание количества слоев. Изысканность имеет значение.
Дальнейшее чтение: к настоящему времени выпущены MobileNet v2 и v3, обеспечивающие новые улучшения точности и размеров. Параллельно с этим, другие авторы разработали множество методов дальнейшего сокращения размеров модели (таких, как SqueezeNet) и уменьшения размеров обычных моделей с минимальной потерей точности. Эта статья содержит полную сводку точности нескольких моделей в зависимости от их размеров.
№3. Attention is all you need (2017)
Васвани, Ашиш и пр. "Внимание – это все, что вам нужно". Достижения в нейронных системах обработки информации, 2017.
Эта статья представила модель Трансформера. До нее модели обработки естественного языка в основном полагались на рекуррентные нейронные сети (RNN), чтобы выполнять обработку последовательностей текста. Однако RNN ужасно медленные, и они очень плохо параллелизуются на нескольких GPU. Предложенные в статье принципы достигли существенно лучших передовых результатов и обучались намного быстрее, чем предыдущие модели RNN.
Причина 1: большинство архитектур современных моделей обработки естественного языка (NLP) происходят от Трансформера. Такие модели, как GPT-2 и BERT, находятся на переднем краю инновации. Понимание Трансформера – это ключ к пониманию большинства современных моделей NLP.
Причина 2: большинство трансформерных моделей имеют миллиарды параметров. В то время, как иследования MobileNet создают более эффективные модели, исследования NLP предоставляет более эффективное обучение. Комбинация обоих подходов создает отличный набор техник для эффективного обучения и вывода.
Причина 3: хотя трансформерная модель и была в основном ограничена NLP, предлагаемый механизм внимания (Attention) имеет широкий спектр приложений. Такие модели, как Self-Attention GAN, демонстрируют пользу изучения множества задач на глобальном уровне. Новые статьи о приложениях Attention появляются каждый месяц.
Дальнейшее чтение: я крайне рекомендую прочитать статьи о BERT и SAGAN. Первая из них – это развитие модели Трансформера, а вторая – приложение механизма Attention к изображениям при настройке GAN.

№4. Stop Thinking With Your Head / Reformer (~2020)
Мерити, Стивен. "RNN с одной головкой внимания: перестаньте думать своей головой". Препринт arXiv:1911.11423 (2019).
Китаев, Никита, Лукаш Кайзер и Ансельм Левская. "Реформер: эффективный трансформер". Препринт arXiv:2001.04451 (2020).
Модели на основе Трансформера / Attention привлекли огромное внимание. Однако эти модели обычно требуют массу ресурсов и непригодны для "железа", имеющегося у большинства людей. Обе приведенные статьи критикуют эту архитектуру и предлагают эффективные с вычислительной точки зрения альтернативы модулю Attention. Как и в случае MobileNet, изысканность имеет значение.
Причина 1: "Перестаньте думать своей головой" – чрезвычайно смешная статья. Это само по себе причина прочитать ее.
Причина 2: Крупные компании легко могут масштабировать свои исследования на сотни GPU, но мы, обычные люди, этого не можем. Масштабирование – это не только широкий проспект к улучшению, это невозможно переоценить. Читать статьи о повышении эффективности – лучший путь гарантировать, что вы эффективно используете те ресурсы, которые у вас есть.
Дальнейшее чтение: поскольку эти статьи вышли в конце 2019-го и в 2020-м, более поздних статей пока нет. Подумайте о том, чтобы перечитать статью о MobileNet (если вы еще этого не сделали), в которой есть другие рассуждения об эффективности.
№5. Human Baselines for Pose Estimation (2017)
Ксяо, Бин, Хайпинг Ву и Йичен Вэй. "Простые основы оценки и отслеживания позы человека". Материалы Европейской конференции по компьютерному зрению (ECCV), 2018.
До сих пор большинство статей предлагали новые техники для усовершенствования переднего края науки. Эта статья, напротив, доказывает, что простая модель, используя лучшие на сегодняшний день методы, может быть удивительно эффективной. В общем, авторы предложили нейронную сеть, оценивающую позу человека, основанную исключительно на базовой нейронной сети, за которой следуют три операции обратной свертки. На тот момент их подход выдавал самую лучшую оценку по бенчмарку COCO, несмотря на свою простоту.
Причина 1: иногда простой подход и есть самый эффективный. Несмотря на то, что все мы хотели бы попробовать новые и сверкающие архитектуры, написать базовую модель будет намного проще, и она может показать сходные результаты. Эта статья напоминает нам, что не все хорошие модели должны быть сложными.
Причина 2: наука движется вперед небольшими шагами. Каждая новая статья продвигает передний край науки немного вперед. Однако эта дорога не обязана вести только в одну сторону. Иногда стоит немного отступить и свернуть в другую сторону. "Перестаньте думать своей головой" и "Reformer" – два отличных примера такого подхода.
Причина 3: правильная обработка данных (data augmentation), расписание обучения и правильная постановка задачи значат больше, чем признает большинство людей.
Дальнейшее чтение: если вы интересуетесь оценкой позы, вас может заинтересовать чтение этого полного обзора переднего края.
№6. Bag of Tricks for Image Classification (2019)
Хе, Тонг и пр. "Мешок трюков для классификации изображений с помощью сверточных нейронных сетей". Материалы конференции IEEE по компьютерному зрению и распознаванию шаблонов, 2019.
Очень часто вам нужна не новая модель, а просто пара новых трюков. В большинстве статей предлагается один-два трюка, чтобы улучшить результат на пару процентов. Однако они часто теряются среди основных идей статьи. Эта статья собирает набор полезных советов из разных источников и суммирует их для нашего удовольствия.
Причина 1: большинство советов легко применить.
Причина 2: скорее всего, вы не знакомы с большинством предлагаемых подходов. Это не обычные советы вроде "используйте ELU".
Дальнейшее чтение: существует множество различных трюков, некоторые из них специфичны для конкретной задачи, другие нет. Тема, которая, по-моему, заслуживает больше внимания – веса классов и выборок. Подумайте о том, чтобы прочесть эту статью о весах классов для несбалансированных датасетов.

№7. The SELU Activation (2017)
Кламбауер, Гюнтер и пр. "Само-нормализующиеся нейронные сети". Достижения в нейронных системах обработки информации, 2017.
Большинство из нас использует слои пакетной нормализации (Batch Normalization) и функции активации ReLU или ELU. В статье о SELU авторы предлагают унифицированный подход: активация, которая само-нормализует свои выходы. На практике это делает слои пакетной нормализации устаревшими. Таким образом, модели, использующие активацию SELU, проще и требуют меньше операций.
Причина 1: в этой статье авторы в основном решают традиционные задачи машинного обучения (с табличными данными). Большинство data scientist'ов в основном работают с изображениями. Статья о полносвязных нейронных сетях может приятно вас освежить.
Причина 2: если вам приходится работать с табличными данными, эта статья предлагает самый современный подход к этой теме во всей литературе о нейронных сетях.
Причина 3: эта статья наполнена математикой и приводит доказательства. Это само по себе редко встречается и очень красиво.
Дальнейшее чтение: если вы хотите погрузиться в историю и способы применения большинства популярных функций активации, я написал руководство по функциям активации, которое вы можете прочитать.
№8. Bag-of-Local-Features (2019)
Бренделл, Виланд и Маттиас Бефге. "Аппроксимация сверточных нейронных сетей моделями на основе мешка локальных признаков работает чрезвычайно хорошо на ImageNet". Препринт arXiv:1904.00760 (2019).
Если разрезать изображение на кусочки вроде паззлов, перемешать их и показать ребенку, он не сможет распознать исходное изображение, но CNN может. В этой статье авторы обнаружили, что классификация всех 33*33 кусочков изображения с последующим усреднением предсказания их классов почти достигает передовых результатов на ImageNet. Более того, они проверили эту идею на моделях VGG и ResNet-50, доказав, что CNN полагаются в основном на локальную информацию, а влияние глобальных признаков минимально.
Причина 1: многие люди верят, что сверточные нейронные сети "видят", а эта статья доказывает, что они гораздо глупее, и за них не стоит держать пари.
Причина 2: статьи, содержащие свежий взгляд на ограничения CNN и способность интерпретировать их результаты, очень редки.
Дальнейшее чтение: литература о состязательных атаках (adversarial attacks) также демонстрирует ограничения CNN. Подумайте о прочтении этой статьи и ее перечня ссылок.
№9. The Lottery Ticket Hypothesis (2019)
Фрэнкл, Джонатан и Майкл Кэрбин. "Гипотеза о лотерейном билете: нахождение редких, обучаемых нейронных сетей". Препринт arXiv:1803.03635 (2018).
Продолжаем рассматривать теоретические статьи. Фрэнкл и пр. обнаружили, что если вы обучите большую нейронную сеть, обрежете все малозначащие веса, откатите обрезанную сеть назад и снова обучите ее, вы получите сеть, выдающую лучшие результаты. Аналогия с лотереей рассматривает каждый вес как лотерейный билет. Имея миллиард билетов, вы точно выиграете приз. Однако большинство билетов не выиграют, выиграют только некоторые из них. Если вы вернетесь назад во времени и купите только выигравшие билеты, вы максимизируете свои доходы. "Миллиард билетов" – это исходная большая нейронная сеть. "Обучение" – это запуск лотереи, чтобы увидеть, какие веса получили высокие значения. "Возврат во времени" – это возврат к исходной, необученной сети и новый запуск лотереи. В результате вы получите сеть с лучшей производительностью.
Причина 1: это невероятно крутая идея.
Причина 2: как и статья о Мешке локальных признаков, эта статья проливает свет на то, как ограничено наше нынешнее понимание CNN. Прочитав эту статью, я понял, как мало используются наши миллионы параметров. Мы даже не знаем, насколько мало. Авторы сумели сократить некоторые сети в десять раз, а во сколько раз их удастся сократить в будущем?
Причина 3: эти идеи также позволяют нам увидеть, насколько неэффективны титанические нейронные сети. Вспомните упомянутую прежде статью о Reformer'е. Она серьезно сократила размер Трансформера, улучшив алгоритм. Насколько еще его можно будет сократить, используя технику лотереи?
Дальнейшее чтение: люди часто не обращают внимания на инициализацию весов. По моему опыту, большинство людей не меняют значения по умолчанию, что далеко не всегда лучший вариант. Основополагающая статья на эту тему – "Все, что вам нужно – это хорошая инициализация". Что касается гипотезы о лотерейном билете, вот простой для чтения обзор.
№10. Pix2Pix и CycleGAN (2017)
Айзола, Филипп и пр. "Перевод изображения в изображение с помощью условных состязательных сетей". Материалы конференции IEEE по компьютерному зрению и распознаванию шаблонов, 2017.
Жу Юн-Ян "Непарный перевод изображения в изображение, используя циклически-согласованные состязательные сети" Материалы конференции IEEE по компьютерному зрению и распознаванию шаблонов, 2017.
Наш список был бы неполным без каких-либо статей по GAN.
Pix2Pix и CycleGAN – две основополагающие работы по условным генеративным моделям. Обе выполняют задачу преобразования изображений из домена А в домен Б, и отличаются использованием парных и непарных датасетов. Первая выполняет такие задачи, как преобразование нарисованных линий в полностью отрендеренные изображения, а вторая непревзойденна в замене объектов, например, замена коней на зебр или яблок на апельсины. Будучи "условными", эти модели предоставляют пользователю определенный уровень контроля над результатом генерации путем небольших изменений исходных изображений.
Причина 1: статьи по GAN обычно фокусируются исключительно на качестве результатов генерации и не уделяют внимания творческому контролю. Условные модели, такие, как эти, обеспечивают GANам широкую дорогу к тому, чтобы стать действительно полезными на практике. Например, стать виртуальными ассистентами художников.
Причина 2: состязательные подходы – лучшие примеры мульти-сетевых моделей. Даже если генерация – не ваша тема, изучение мульти-сетевых моделей может пригодиться в большом количестве задач.
Причина 3: статья по CycleGAN, в частности, демонстрирует, как эффективная функция потерь может творить чудеса при решении некоторых сложных задач. Похожая идея приводится в статье о функции потерь Focal, существенно улучшающей детекторы объектов, всего лишь заменяя традиционные функции потерь на лучшую.
Дальнейшее чтение: хотя ИИ и развивается быстро, GANы развиваются еще быстрее. Я настоятельно рекомендую реализовать GAN, если вы никогда этого не делали. Вот официальные документы Tensorflow 2 на эту тему. Одно из не особенно известных приложений GANов (с которым вам стоит познакомиться) – это обучение с частичным привлечением учителя (semi-supervised learning).
Приведя эти 12 статей и рекомендации по дальнейшему чтению, я уверен, что теперь у вас есть множество материалов, которые стоит прочитать. Конечно, это далеко не полный список прекрасных статей, но я сделал все, что мог, чтобы выбрать самые вдохновляющие и основополагающие статьи из тех, которые я читал или просматривал. Приятного чтения!
Комментарии