

Благодаря легкому доступу к публичным облачным вычислениям, оркестрации контейнеров и архитектуре микросервисов, создание распределенных систем почти безграничного масштаба и сложности стало тривиальной задачей. Хотя у всех этих инструментов есть свое предназначение, инженерам важно тщательно продумать, когда и нужно ли их использовать, особенно в небольших организациях. Неправильный выбор может усложнить процессы разработки, негативно повлиять на успех проекта.
Проблема
Мы начинаем со сложности
Когда мы проводим собеседования на работу в области разработки ПО, мы должны пройти синтетический, сложный и часто напряженный процесс собеседования, чтобы доказать потенциальным работодателям, что мы достаточно квалифицированы, чтобы продолжать делать то, что мы уже делали в течение последних нескольких лет. Во время этого процесса нас могут попросить решить несколько средних или сложных алгоритмических задач за короткое время, что больше похоже на зрелищный спорт, чем на программирование. Обычно нам требуется менее чем за час разработать новую систему, требования которой мы должны сначала выяснить у интервьюера. Ни одно из этих упражнений не очень похоже на то, что мы делаем на нашей реальной работе, а вместо этого представляют собой задачи, предназначенные для получения различной степени «сигнала», который компании по найму могут использовать для ранжирования и дифференциации кандидатов.
Собеседование по проектированию системы, в частности, представляет собой конструкцию, в которой кандидатов просят продемонстрировать широкое и глубокое понимание систем в масштабе, который можно найти в самых крупных компаниях. Мы используем такие концепции, как микросервисы, согласованное хеширование, шины событий, сервисная сетка, буферы протоколов, WebSockets, Kubernetes, шлюзы API, конвейеры данных, озера данных, и другие технологические модные словечки, чтобы показать, что мы знаем, что они из себя представляют и как они используются. Это дает потенциальным работодателям уверенность в том, что мы в курсе всех новейших методов и инструментов и можем сделать то, о чем нас могут попросить.
Сложность порождает сложность
Если мы получаем работу, нам предоставляется возможность использовать все передовые знания, которые мы продемонстрировали в процессе найма, для решения проблем бизнеса. Мы добросовестно используем эти технологии и часто в конечном итоге создаем довольно сложные системы, основанные на архитектурных шаблонах, впервые предложенных Google, LinkedIn, Meta*, Amazon, Apple и Netflix.
Корпоративное руководство часто радуется такой сложности, поскольку она демонстрирует, что компания теперь зрелая, «инженерная планка» высока, и системы компании смогут масштабироваться вместе с бизнесом независимо от того, насколько быстро растет бизнес. Эта сложность в дальнейшем используется в качестве инструмента рекрутинга, чтобы показать кандидатам, что они смогут работать со всеми новейшими технологиями и что их будущие коллеги умны и владеют современными инструментами и методами.
Что в этом плохого?
Проблема с этим подходом заключается в том, что многие компании никогда не станут достаточно большими или не достигнут масштаба, достаточного для того, чтобы такая сложность приносила пользу. Крупнейшие компании разработали эти новые технологии и шаблоны для решения серьезных проблем масштаба, с которыми они столкнулись, поскольку их пользовательская база и объемы транзакций росли экспоненциально в течение продолжительных периодов времени.
Во многих случаях не существовало хороших решений, поэтому они создавали собственные решения в соответствии с масштабом, достигнутым бизнесом, часто с большими первоначальными и текущими затратами. Многие из этих компаний любезно открыли исходный код некоторых своих технологий на благо более широкой технологической экосистемы, сделав их «бесплатными для использования» другими компаниями.
Многие из вышеперечисленных шаблонов и технологий, не работающие в масштабе, опасны, потому что они могут замедлить прогресс, резко увеличить затраты и увеличить когнитивную нагрузку на инженерный персонал. Это огромная проблема для небольших компаний, потому что это снижает эффективность бизнеса в самых важных направлениях – маневренности и экономичности. Это создает ловушку для компаний, оказавшихся в условиях экономического спада или резко возросшей конкуренции в секторе рынка из-за снижения маржи. Это несоответствие усугубляется тем, что системы вознаграждения инженерного персонала часто недостаточно связаны с повышением эффективности бизнеса.
Два примера
Давайте начнем с простой системы, которую относительно легко понять, и сравним ее минимальную форму с тем, что может произойти, если мы ее перепроектируем. Ради этого обсуждения давайте предположим, что у нас есть общий веб-сайт, на котором пользователи могут регистрироваться и покупать вещи.
Простая версия
Минимальную архитектуру для простого веб-сайта электронной коммерции часто называют монолитом, что означает, что вся кодовая база инкапсулирована в единый исходный репозиторий и обычно развертывается как единое целое. Многие стартапы начинают здесь, потому что это позволяет им быстро развиваться, когда кодовая база и инженерные группы небольшие. Дополнительным преимуществом является то, что вся система часто может поместиться на ноутбуке для легкой локальной разработки.
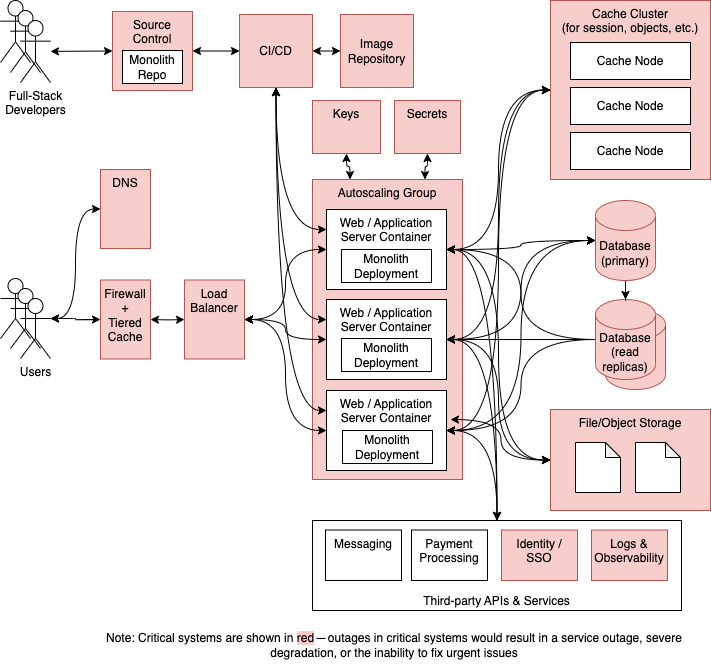
На приведенной выше диаграмме мы можем выбрать некоторые разумные значения по умолчанию от одного облачного провайдера (в данном случае Amazon Web Services или AWS), чтобы обеспечить согласованность инструментов инфраструктуры:
- Основной язык/фреймворк разработки: Ruby+Rails, мы также можем выбрать Python+Django, Go+Buffalo или любой другой язык/фреймворк.
- Язык внешнего интерфейса/фреймворк: JavaScript/TypeScript + React.
- Пакетная/фоновая обработка: Ruby+SidekiqPython+Celery, Go+Faktory были бы альтернативой, если бы мы выбрали другой основной язык.
- Система управления версиями: Git/GitHub.
- CI/CD: GitHub Actions + Terraform.
- Репозиторий изображений: AWS ECR.
- Система оркестрации контейнеров: AWS ECS.
- Ключи: AWS KMS.
- Секреты: менеджер секретов AWS.
- Брандмауэр/многоуровневый кэш: Cloudflare.
- DNS: CloudFlare.
- Балансировщик нагрузки: AWS ELB или ALB.
- Хранилище файлов/объектов: AWS S3.
- Кэш+кэш-узлы: AWS ElastiCache для Redis.
- База данных + реплики чтения: Postgres на AWS RDS.
- Обмен сообщениями: Sendgrid.
- Обработка платежей: Полоса.
- Идентификация/SSO: Okta.
- Журналы и наблюдаемость: DataDog.
Мы предполагаем, что внешние службы доступны через версионные REST API, поскольку большинство сторонних служб предлагают эту возможность. Мы можем снизить когнитивную нагрузку, сделав то же самое для внутренних вызовов API, чтобы мы могли использовать такие инструменты, как Postman, для тестирования всех наших API. Все внутренние вызовы между службами будут выполняться синхронно, хотя при необходимости можно добиться асинхронной функциональности с фоновой обработкой через Sidekiq. Любые API-интерфейсы, открытые для внешних пользователей, будут доступны через тот же вход, который используется для общего трафика веб-браузера. Нет ни «шины событий», ни конвейеров данных, хранилищ данных или озер данных. Вся аналитика выполняется по репликам чтения базы данных, когда это необходимо.
Этот проект включает в себя 16 критических компонентов, сбои в работе которых могут привести к сбоям в работе сайта, сбоям на уровне пользователя или деградации. Поскольку система минимальна, большинство компонентов являются критически важными, но развертывание с резервированием помогает снизить риск сбоев, вызывающих простои.
Сложная версия
Можно возразить, что приведенная выше простая версия не совсем проста, но мы можем напрячь наши архитектурные мускулы и сделать систему более впечатляющей.
Начнем с (частичного) разбиения монолита на микросервисы. Давайте также представим шлюз API, Kubernetes, шину событий (с использованием Kafka), сетку служб, несколько систем DNS, несколько конвейеров CI/CD, конвейеры данных (с использованием отдельного кластера Kafka) и озеро данных. В дополнение к API REST давайте добавим поддержку API gRPC (включая буферы протоколов), потому что мы знаем, что это намного быстрее, чем REST, и нам нужна высокая производительность. Мы добавим вторую систему CI/CD (Jenkins), потому что некоторые сотрудники предпочитают ее GitHub Actions.
Давайте добавим дополнительный язык и платформу (Python/Django/Celery), чтобы дать разработчикам больше возможностей, и не забудьте добавить Go и Groovy в наш список поддерживаемых языков, поскольку мы используем Jenkins (с Groovy DSL) и Kubernetes. поэтому нам, вероятно, понадобятся операторы Kubernetes (Go) для управления несколькими пользовательскими ресурсами, которые мы создадим. Для повышения производительности и разделения мы полностью отделим наше развертывание пользовательского интерфейса переднего плана от нашего монолита внутреннего интерфейса. Давайте также добавим еще одну опцию для регистрации и наблюдения (Sumo Logic), потому что наш первый вариант (DataDog) был сочтен слишком дорогим для доставки всех наших журналов.
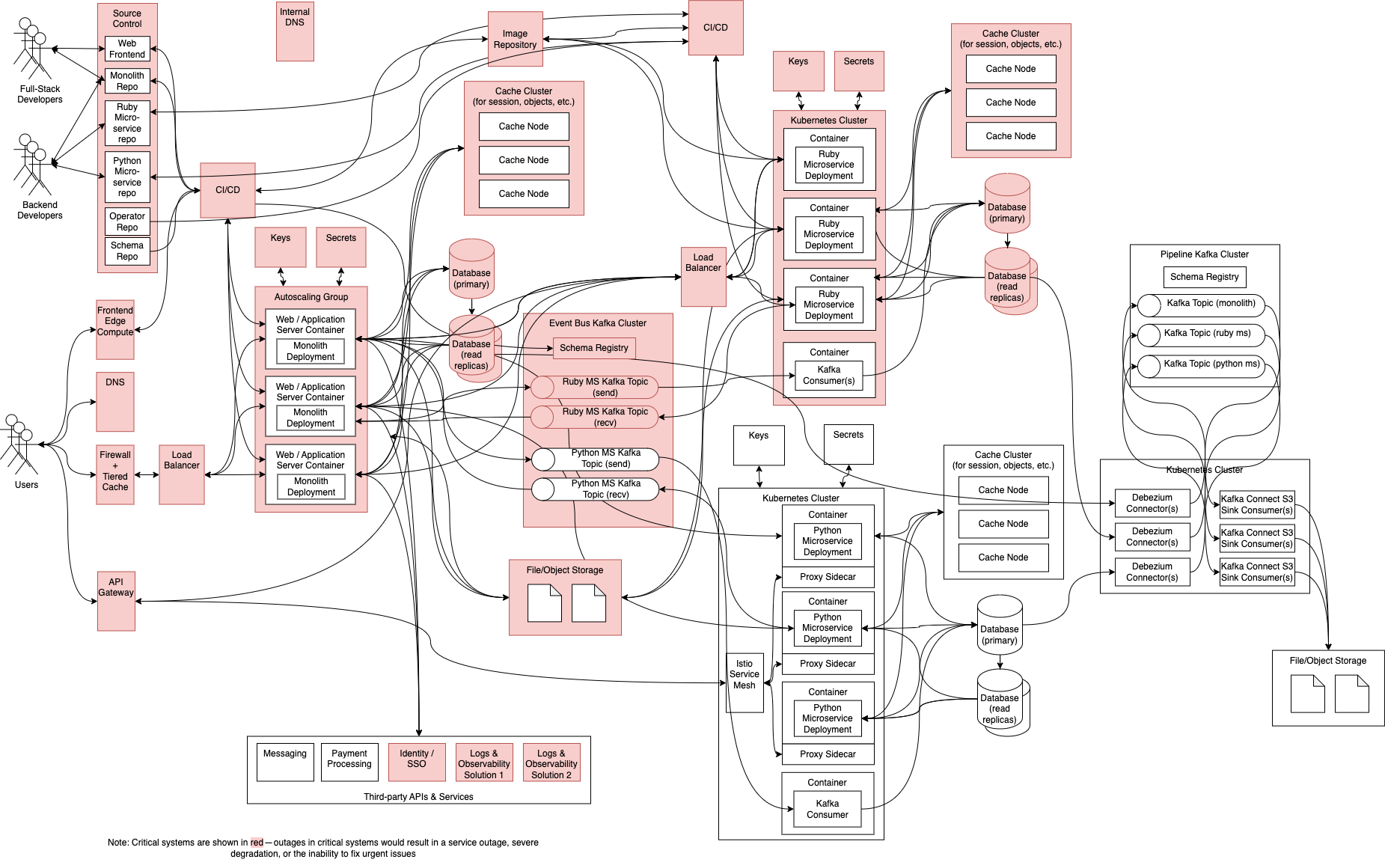
Давайте проанализируем, как эти архитектурные изыски изменили нашу систему.
Если мы предположим, что наша служба Python и платформа данных не являются критически важными, у нас теперь есть 33 критических компонента, в которых сбои отдельных компонентов могут вызвать проблемы в масштабах всего сайта. Основываясь на том, как мы рассчитываем доступность, это делает сбои гораздо более вероятными, потому что система в целом может быть доступна только настолько, насколько доступен ее наименее доступный зависимый компонент. У нас больше зависимых компонентов, поэтому поддержание той же доступности, что и в более простой системе, требует гораздо большей строгости. На практике, чем больше компонентов, тем труднее обеспечить соблюдение неизменно высоких стандартов.
Мы заменили надежные вызовы локальной библиотеки вызовами API по сети. Это оказывает двоякое влияние:
- Сеть увеличивает задержку, делая каждый вызов удаленной службы немного медленнее, чем вызов локальной библиотеки.
- Любой сетевой вызов может завершиться ошибкой или быть ограниченным по скорости, а это означает, что нам нужно быть более осторожными с обработкой ошибок, чем если бы мы просто вызывали код в локальной библиотеке.
Были введены 3 новых языка: Python, Groovy и Go . Хотя это расширяет возможности, но снижает возможность свободного перераспределения персонала по разным командам. Во многих случаях необходимо будет изучать новые языки, что требует времени на подготовку и снижает гибкость.
Теперь у нас есть 3 варианта шаблонов интеграции:
- REST API.
- gRPC.
- Event Bus.
Это означает, что при изменении API нам может потребоваться обновить реестр схемы в случае интеграции шины событий или получить новые клиентские «заглушки» с изменениями, отраженными в случае gRPC. Несмотря на это, теперь нам нужно знать три разных шаблона для работы в нашей распределенной экосистеме. Также существует риск, что если мы используем общий реестр центральной схемы, могут быть внесены критические изменения, которые могут повлиять на другие службы.
11 чистых новых компонентов:
- Шлюз API (Шлюз API Amazon).
- Платформа внешнего интерфейса + периферийные вычисления (Vercel).
- Внутренний DNS (AWS Route53).
- Kafka для Event Bus (AWS MSK).
- Kafka для конвейеров данных (AWS MSK).
- Несколько развертываний Kafka Connect Source и Sink для чтения/записи из различных баз данных и тем.
- Data Lake: мы предполагаем AWS Lake Formation с Amazon Athena для запросов и S3+Parquet для хранения данных.
- Istio Service Mesh для mTLS и маршрутизация между шлюзом API и нашим микросервисом Python.
- Несколько кластеров Kubernetes (AWS EKS).
- Входящие балансировщики нагрузки (AWS ALB).
- Дженкинс CI/CD.
Каждый дополнительный компонент требует нового или увеличенного персонала для обеспечения непрерывности бизнеса. Каждый новый компонент также требует мониторинга и регулярных обновлений, чтобы убедиться, что уязвимости устранены и компонент остается работоспособным. Каждый компонент сопряжен с риском неправильной настройки, что может увеличить стоимость его эксплуатации из-за избыточного выделения ресурсов или увеличить риск сбоя из-за недостаточного выделения ресурсов.
Приблизительно 16 дублированных компонентов:
- 3 базы данных + реплики чтения.
- 3 кластера Redis (один для монолита плюс один на микросервис).
- 2 кластера Кафки.
- 2 системы DNSCloudflare внешние + Route53 внутренние. Это не включает DNS внутреннего кластера Kubernetes.
- 2 системы CI/CD.
- 2 Решения для ведения журналов и наблюдения.
- 2 кластера Kubernetes.
В лучшем случае такое дублирование ограничивает радиус поражения для сбоев и позволяет настраивать каждую службу, а все развертывания одинаково хорошо управляются между командами и службами. В худшем случае все они управляются по-разному, с разным уровнем качества и инструментами. Независимо от того, как управляются эти повторяющиеся проблемы, обычно требуется больше усилий для управления большим количеством ресурсов.
Эксплуатационные расходы увеличиваются примерно в 10–15 раз
С учетом дополнительных контейнеров, развертываний, управляемых служб и необходимого персонала можно ожидать, что эксплуатационные расходы будут значительно выше. Даже Amazon, один из самых ярых сторонников микросервисов и публичных облаков, обнаружил, что затраты для некоторых внутренних целей непомерно высоки.
Слишком большой для локальной разработки с полным стеком
Даже при уменьшенных конфигурациях развертывания, скорее всего, будет слишком много движущихся частей, чтобы полную систему можно было запустить на ноутбуке разработчика в Docker или minikube. Есть способы включить разработку в облаке, но разработчикам потребуются макеты или общие экземпляры служб для разработки, чтобы смоделировать полностью функциональную систему.
Как нам избежать этих ошибок?
Технически нет ничего плохого в приведенных выше примерах простой или сложной системы. Обе они обеспечивают схожую функциональность, а сложная система, несмотря на то, что ее создание и эксплуатация обходится гораздо дороже, может подойти для некоторых компаний определенного размера и масштаба. Тем не менее сложный пример, вероятно, не лучшая отправная точка для большинства компаний. Чтобы избежать преждевременной оптимизации, полезны следующие подходы.
Развивайте культуру, поощряющую простоту
При собеседовании с кандидатами вместо того, чтобы поощрять их впечатлять вас широтой и глубиной знаний и разрабатывать системы в веб-масштабе, рассмотрите упрощение архитектуры как один из ключевых критериев, которые вы используете для их оценки. Задайте такие вопросы, как: «Можете ли вы придумать, как сделать эту систему проще или надежнее?». Если они могут определить в своей версии проектирования вещи, которые им не нужны, вознаградите их за это. Если они вообще не добавляют ненужных компонентов, даже лучше.
После найма отдельного сотрудника, особенно на более высоких уровнях, сделайте упрощение архитектуры частью оценки его производительности. Вознаграждайте сотрудников, которые берут сложные и хрупкие системы и делают их проще и надежнее. Наличие технического персонала, стремящегося к эффективности и упрощению, гарантирует, что системы будут настолько гибкими и надежными, насколько это возможно, когда вам нужно быстро двигаться.
Минимизируйте количество одновременных изменений
Когда компания приступает к такому сложному делу, как удаление ограниченных контекстов из монолита, возникает искушение извлечь, преобразовать и реорганизовать за одну операцию «большого взрыва». Если команды считают, что они хотели бы, чтобы проблема была реализована на другом языке или с использованием других инструментов (которые они также хотели бы изучить), обычно это упражнением по переводу считают как действительную и необходимую часть усилий по извлечению данных.
Предполагая, что существующий язык и платформа по-прежнему соответствуют рабочей нагрузке, обычно лучше сначала извлечь код во внешнюю службу, а после завершения извлечения рассмотреть возможность рефакторинга, переноса или иной реструктуризации службы, если чего-то все еще не хватает. Я видел много попыток миграции, которые пытались сделать слишком много вещей одновременно и рисковали успехом общих усилий или достигали очень, очень медленного прогресса. Если существующий код написан на Ruby, обычно лучше оставить его неизменным до тех пор, пока служба не станет действительно отдельной задачей. Вы можете получить больше помощи от других инженеров, если вы меняете как можно меньше, и они все еще могут понять код, который вы перемещаете.
Поощряйте стандарты и консенсус
Я видел битвы между директорами, инженерами и архитекторами, которые разрешались всеми сторонами, решившими сделать это по-своему и отказавшимися от условностей и стандартов в пользу разработки с нуля с использованием новых инструментов и технологий. Хотя это может расширить возможности бесстрашного инженера, обычно это приводит к созданию индивидуальных решений, которые плохо работают с другими частями экосистемы и увеличивают эксплуатационные расходы, потому что они «исключительны» во всех неправильных отношениях.
Вместо разделения поощряйте консенсус, который приводит к единому способу решения проблемы, который может быть широко принят. Вместо того чтобы разрабатывать инструменты для себя или своей непосредственной команды, подумайте обо всем, что вы создаете, как о чем-то, чем вы поделитесь со всей своей инженерной организацией. Если проблема является общей для многих инженеров, но вы не думаете, что ваше решение будет принято, рассмотрите возможность улучшения того, что уже широко используется, или обсудите проблему с другими инженерами до тех пор, пока вы не достигнете согласия и одобрения того, что ваш подход может быть широко использован, и что они помогут вам способствовать его внедрению в организацию.
Лучше ничего не делать, чем делать что-то неправильно
Многие организации становятся одержимыми скоростью и используют методологии Agile, такие как Scrum, чтобы «максимизировать поток» и пропускную способность команд. Во многих случаях бизнес не знает точно, что ему нужно сделать, поэтому он просто пытается сделать так, чтобы инженеры были заняты, чтобы они оставались в постоянном режиме быстрого выполнения.
Проблема с этим подходом заключается в том, что часто создаются вещи, которые не нужны, но вместо того, чтобы их выбрасывать, они рассматриваются как действующее предприятие, требующее поддержки и постоянных инвестиций. Причина этого в том, что большинство инженеров гордятся своей работой и не хотят работать над «одноразовым» программным обеспечением.
Когда неясно, что нужно сделать, используйте это время, чтобы дать возможность инженерам поэкспериментировать, «обновить» навыки или сотрудничать с менеджерами по продукту и другим руководством, чтобы определить, что следует делать дальше. Это предотвратит создание «мусора» и увеличит право собственности, когда вы поймете, что именно надо строить.
Отложите оптимизацию до тех пор, пока она не понадобится
Всегда лучше проявлять инициативу и решать проблемы с производительностью и доступностью до того, как они повлияют на бизнес. Может показаться заманчивым агрессивно использовать решения, ориентированные на будущее, заставляя их поддерживать массовое масштабирование до того, как это потребуется, но обычно это ошибка.
Вместо этого сделайте определение SLI, мониторинг и планирование мощностей частью предоставления услуг. Когда команда отвечает за то, чтобы показатели уровня обслуживания были четко определены и соответствовали поставленным целям, оптимизация становится частью контракта. Если модели использования услуги существенно изменятся в связи с запуском какого-либо нового продукта или партнерством, необходимо проконсультироваться с владельцами услуг. Им будет разрешено учитывать это в своем планировании и гарантировать, что они смогут поддерживать показатели в надлежащих диапазонах при увеличении трафика. Если команда сохраняет согласованность SLO, получая гораздо больше трафика, вознаграждайте их (финансово), потому что больший объем должен означать больший доход.
Убедитесь, что инженерный успех и успех компании тесно связаны
Слишком часто инженеров вознаграждают за создание технически впечатляющих решений, и это «поднятие планки» — то, как они могут оправдать продвижение по службе в организации. Это часто называют «построением резюме», когда инженеры могут показать будущим работодателям впечатляющие системы, над которыми они работали, в качестве средства для продвижения по службе. Это печально, потому что ваш предметный эксперт покидает здание, превознося достоинства чего-то, что они построили, что вам, возможно, не нужно. Теперь вы должны принять решение о поддержке этого творения дополнительным персоналом или списании его из-за отсутствия внутренних знаний.
Вместо этого поощряйте инженеров ставить потребности бизнеса выше технически впечатляющих решений, гарантируя, что они всегда работают лучше, когда компания работает лучше.
Я посвящу этой теме еще одну статью, но TL;DR заключается в том, чтобы убедиться, что вы (финансово) вознаграждаете техническое поведение, которое вам действительно необходимо для роста и улучшения бизнеса.
Комментарии