

Поговорим о Jupyter
Для создания нового блокнота необходимо нажать на кнопку New в верхнем правом углу экрана.
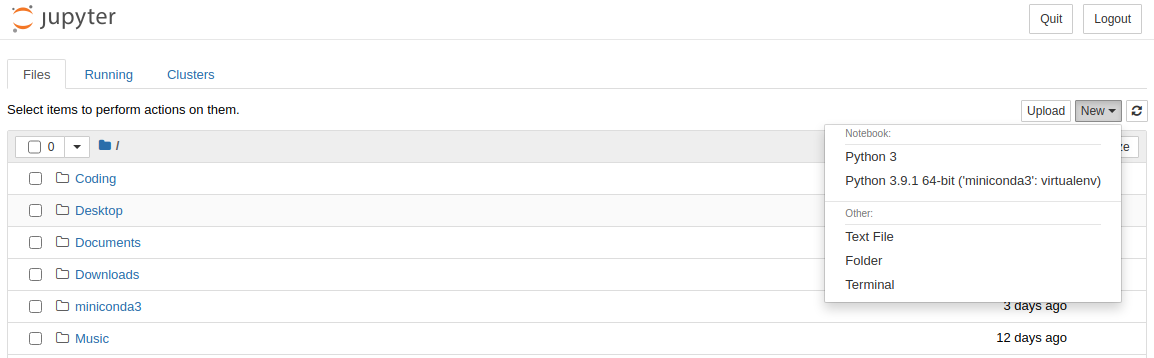
Дальше мы увидим, следующую картину:
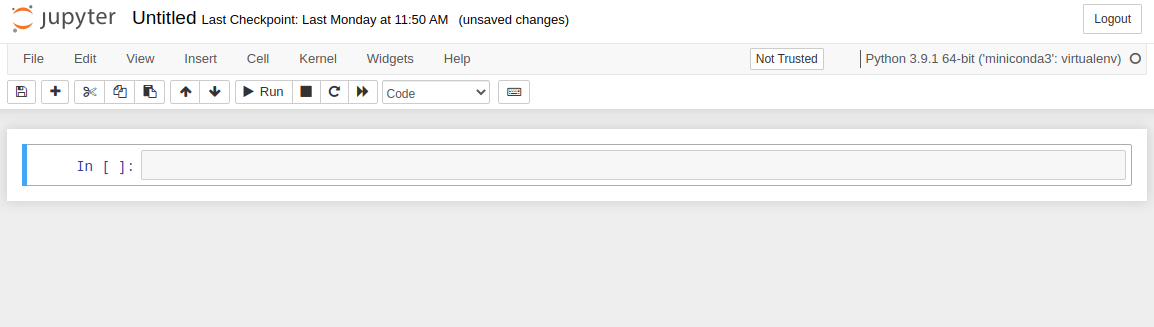
По умолчанию доступна пустая ячейка для вставки кода. Введем в нее print("Hello proglib.io") и нажмём Ctrl+Enter. Это заставить Jupyter выполнить этот участок кода и вывести под ячейкой результат его выполнения.
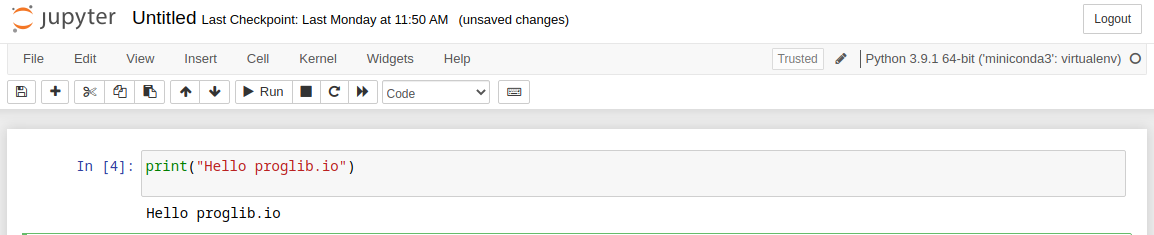
Доступна похожая на предыдущую комбинация клавиш Shift+Enter, которая выполняет код в текущей активной ячейке и добавляет под ней новую.
Второй тип ячеек, поддерживаемый в Jupyter Notebook, позволяет использовать разметку markdown. Чтобы сменить тип ячейки, можно нажать латинскую клавишу M или выбрать тип в выпадающем списке вверху.
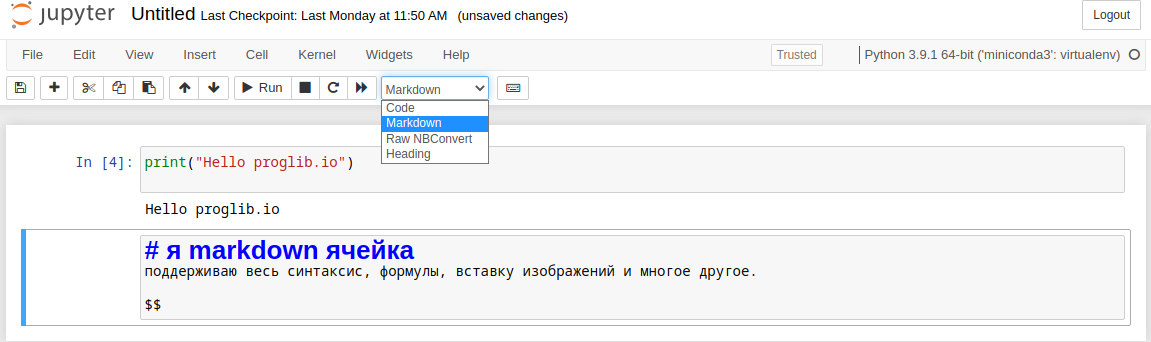
Полное описание синтаксиса этих ячеек можно найти здесь.
Дополнительные материалы:
NumPy. Массивы, базовые операции, индексация
Прежде, чем начать погружение в NumPy, его необходимо установить. Чтобы потом не отвлекаться, поставим и остальные необходимый пакеты. Откроем терминал и выполним:
pip install numpy pandas matplotlib
NumPy предоставляет свой тип данных для работы с многомерными массивами – ndarray. Измерения массива называются осями (axis). Например, матрица 2х2 типа ndarray имеет 2 оси (axis).
Создание массивов NumPy
И первым делом необходимо импортировать numpy в проект. Для этого добавьте в ячейку следующий код и запустите его на выполнение.
import numpy as np
Для получения количества осей в массиве (здесь и далее под словом массив будем подразумевать массив NumPy), необходимо обратиться к свойству ndim:

В приведенном коде, создаем массив a1 из списка чисел. Обращаемся к свойству массива ndim, получаем одномерный массив.
Создадим двумерный массив. Для этого в качестве параметра будем метода array будем использовать не список, а список списков.

Чтобы узнать не только количество осей, но и количество элементов в каждой из них используют свойство shape. Для наших списков оно выглядит следующим образом:

Список а1 представляет собой одну ось из пяти элементов. Список a2 – одна ось из двух элементов, т.е. из двух строк, и вторая ось из пяти элементов, т.е. из пяти столбцов.
NumPy предоставляет довольно много различных функций для построение массивов. Рассмотрим некоторые из них. Мы уже сталкивались с методом array, позволяющим обернуть обычный список python в массив NumPy.
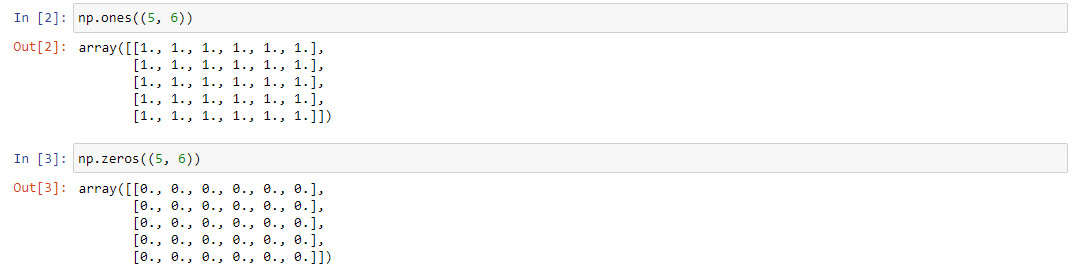
Существует довольно много специальных массивов, применяемых в различных расчетах: единичные, нулевые, пустые и т.д. Чтобы получить массив, состоящий строго из одних единиц, используется метод ones((n,m)).
np.ones((5, 6))
Чтобы получить массив, состоящий строго из одних нулей, используется метод zeros((n,m)). Его синтаксис аналогичен предыдущему.
Квадратная матрица, состоящая из единиц на главной диагонали и остальных нулей, называется единичной и строится с помощью метода identity(n). Единственный входной параметр – количество строк и столбцов.
np.identity(3)
Пустая матрица создается с помощью метода empty((n, m)). Вызов этого метода возвращает матрицу следующего вида:

Обратите внимание, что матрица состоит не из нулей, а из очень маленьких чисел типа float.
В NumPy есть аналог стандартной функции range: np.arange(<start>, stop, <step>). Он возвращает равномерно распределенные значения в заданном интервале и может принимать как целые числа, так и числа с плавающей точкой. Например:
np.arange(3, 22, 3)
np.arange(1.5, 6.7, 0.7)

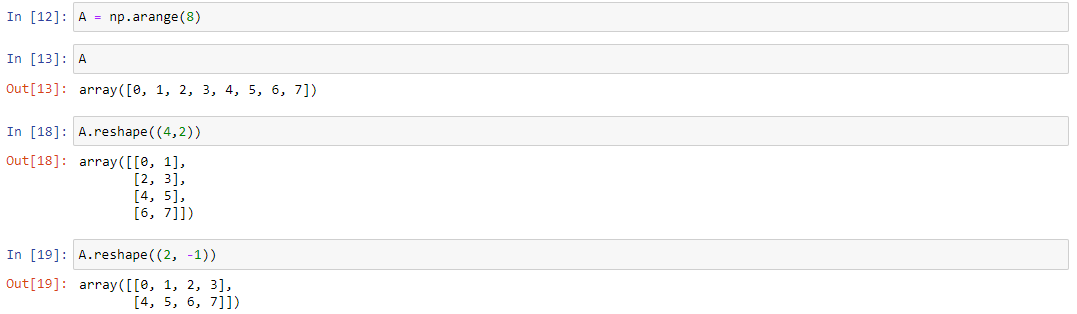
Метод reshape(a, newshape, order='C') позволяет переделать форму (количество осей) существующего массива. Для наглядности будем использовать следующий массив и приведем несколько примеров:
A = np.arange(9) # подопытный одномерный массив
A.reshape((4,2)) # изменяем его форму в матрицу из четырех строк и двух столбцов
A..reshape((2, -1)) # делаем новую форму как матрицу из двух строк
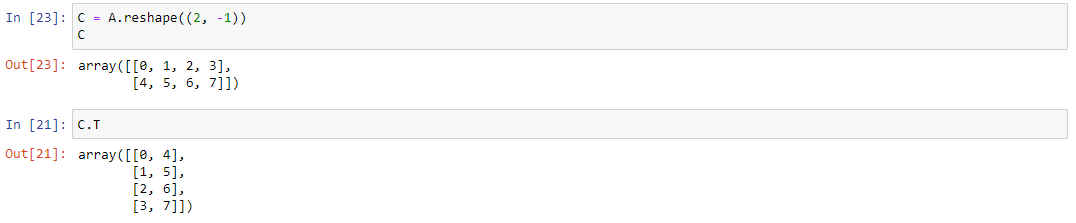
NumPy позволяет транспонировать матрицы. Создадим себе матрицу С следующим образом:
C = A.reshape((2, -1))
Чтобы получить транспонированную матрицу C, нужно просто обратиться к свойству Т следующим образом:
C.T
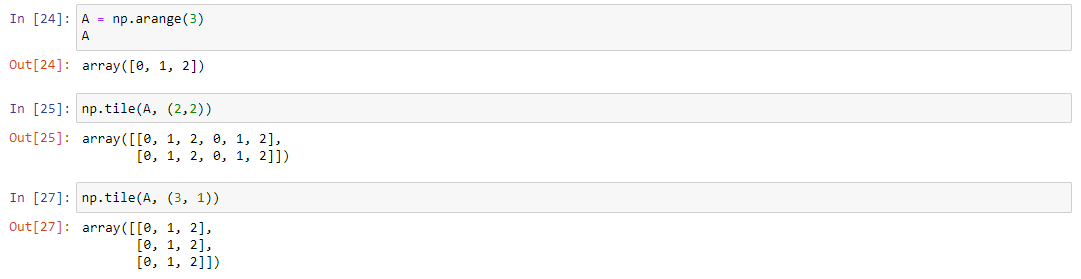
Часто возникает необходимость создать массив, состоящий из повторов другого массива. Для этого существует метод numpy.tile(A, reps), где A – какой-то массив, а resp – шаблон, по которому нужно скопировать массив А. Рассмотрим несколько примеров. Для этого создадим список A следующим образом:
A = np.arange(3)
- Вызов
np.tile(A, (2,2))построит новый массив повторами массива A два раза по-вертикали и два раза по-горизонтали. - Вызов
np.tile(A, (3,1))построит новый массив повторами массива A три раза по-вертикали и один раза по-горизонтали.
Операции с массивами NumPy
Поэлементная операция воздействует на каждый конкретный элемент. Сложение складывает элементы, находящиеся на одинаковых индексах. Аналогично работают вычитание, умножение и деление.
Создадим матрицы D и E размера 3х3. Для примера, сложим обе матрицы, перемножим друг с другом, перемножим матрицу E с числом 10. Остальные операции доступны в блокноте, ссылка на который в конце статьи:
D = np.arange(9).reshape((3,3))
E = np.arange(2, 11).reshape((3,3))
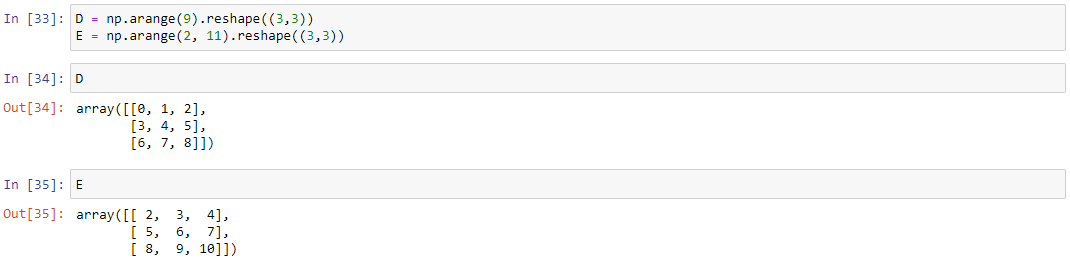
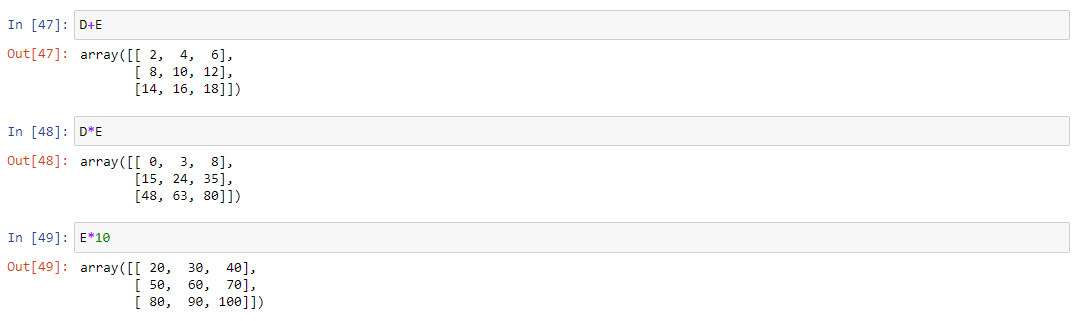
Стоит отдельно отметить, что выбор знака * для поэлементного перемножения матриц выглядит странным. От него, согласно правилам линейной алгебры, интуитивно ожидается другое поведение – перемножение матриц по следующим правилам: каждый элемент результирующей матрицы – сумма произведений каждого элемента соответствующей строки в первой матрице с соответствующим элементом из колонки второй. Но он позволяет поэлементно перемножить две матрицы.
Для классического умножения в NumPy используется метод dot(a, b). Применим его к нашим матрицам D и E.
np.dot(D,E)

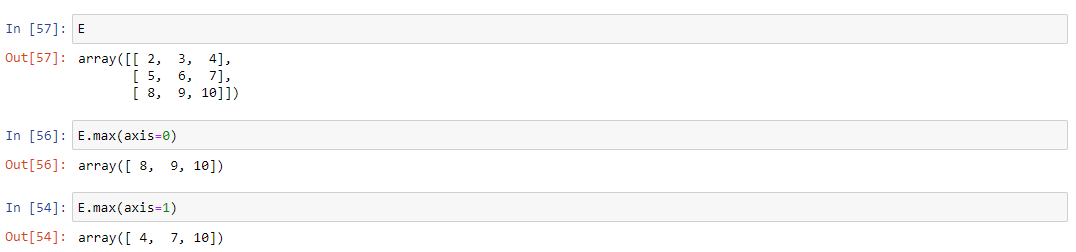
Чтобы найти максимум матрицы, можно использовать метод max().
E.max()

Входным параметром данного метода является axis - возвращение максимум по соответствующему измерению.
E.max(axis=0) # находит максимумы в столбцах
E.max(axis=1) # находит максимумы в строках
Аналогичным образом работает метод sum():
E.sum(axis=0) # находит сумму каждого столбца
E.sum(axis=1) # находит сумму каждой строк

Индексация массивов NumPy
Пакет NumPy поддерживает несколько различных способ индексации массивов. Чтобы их рассмотреть, создадим себе массив A:
A = np.arange(10)
Поддерживаются классические срезы, как одномерных, так и двумерных массивов. Для демонстрации срезов двумерного массива, применим к массиву A метод reshape, чтобы превратить ее в матрицу с пятью строками и двумя столбцами:
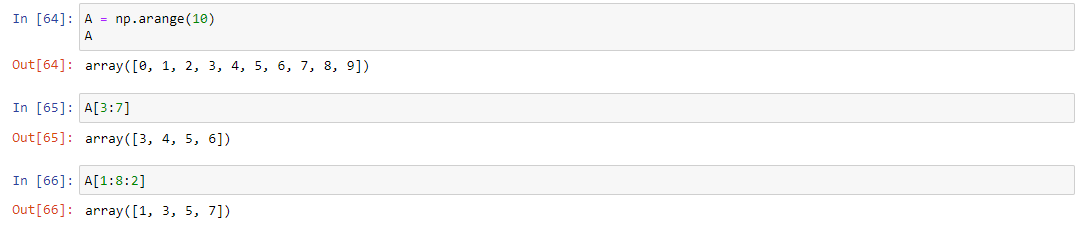
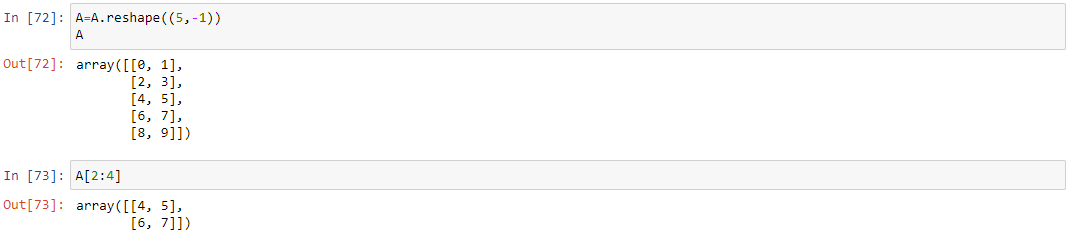
Для сортировки можно использовать логические операции. Выведем четные элементы списка от нуля до девяти. Для этого вместо индексов можно использовать логические выражения. Для связки выражений используются функции np.logical_and() и np.logical_or().
A[A % 2 == 0] # выведет все четные элементы массива A
A[np.logical_and(A != 5, A != 0)] # выведет все элементы массива A, которые не равны нулю и пяти

Pandas
import os
import pandas as pd
И, для интереса, попробуем поработать с pandas на примере классического датасета Titanic из соревнований kaggle. Датасет представляет собой таблицу, поставляемую формате *.csv. Для его чтения pandas предоставляет метод, который преобразует таблицу в формат данных pandas – dataframe.
Загрузим датасет с помощью команды:
os.system('wget -O titanic.csv https://www.dropbox.com/s/1qtgllk0d89bt3d/titanic.csv?dl=1')
Пользователи системы Windows могут просто кликнуть по ссылке и сохранить скачанный файл в папку с рабочим блокнотом.
В результате, в папке с блокнотом будет создан файл titanic.csv. Откроем его с помощью pandas.
data = pd.read_csv('titanic.csv')
Переменная data представляет собой датафрейм pandas и по сути своей является таблицей с данными.
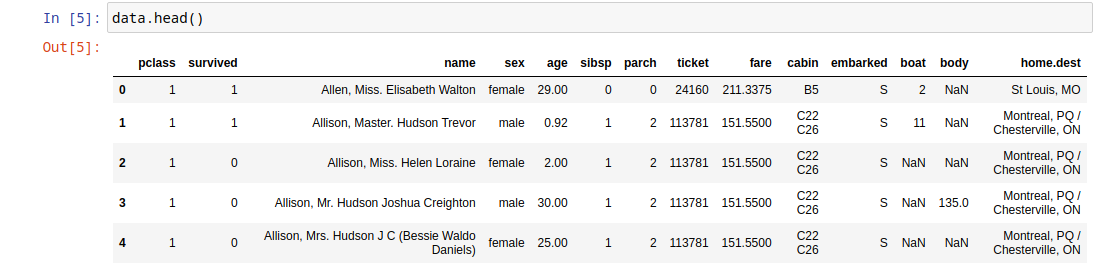
Чтобы оценить таблицу, узнать ее структуру можно использовать метод head(n=5), возвращающий первые n строк датафрейма.
data.head()
Для получения имен колонок существует свойство columns.
data.columns

Индексация датафреймов аналогична стандартной индексации списков в python и индексации numpy.

Помимо такого способа, pandas предоставляет два метода индексации:
- iloc для индексации по номера столбцов и строк
- loc для индексации по строковым значением строк и названиям столбцов.
Например, есть задача получить пол пассажиров для строк с первой по седьмую. Используем loc следующий образом:
data.loc[1:7, 'sex']
Первым параметром передаем идентификаторы строк, у нас это числа, вторым параметром нужный столбец или столбцы. На скриншоте, для примера, приведено получение не только пола, но и возраста пассажиров с необходимыми номерами.l

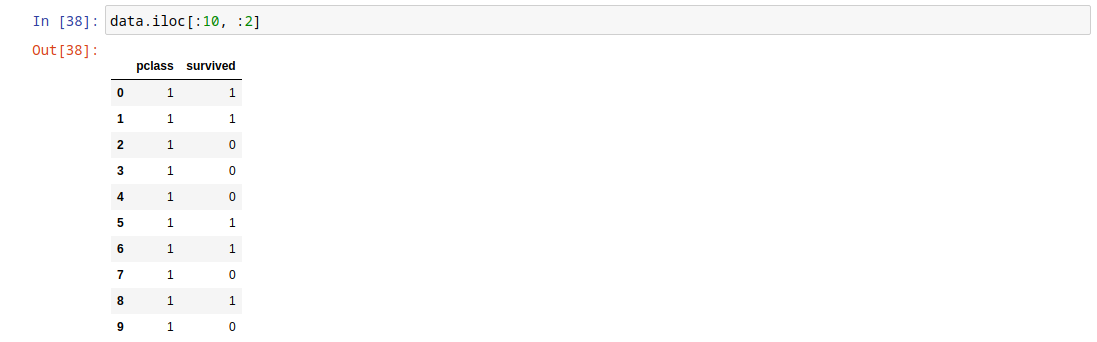
iloc работает аналогичным образом, но только с номерами строк и столбцов, а не с их именами.
Получим для примера первые два столбца первых десяти строк.
data.iloc[:10, :2]
Есть возможность обращаться по имени к каждому конкретному столбцу. Получим первые пять имен пассажиров нашей таблицы:
data['name'].head()

При индексации можно строить логические запросы к данным датафрефма. Для примера выведем пять первых женщин пассажиров.
data[(data['sex'] == 'female')]['name'].head()

Логика работы следующая: получаем строки таблицы, в которых колонка sex = female. Выбираем только колонку name и с помощью метода head() получаем верхние пять строк.
Усложним пример. Получим датафрейм, содержащий первые пять мужчин или женщин старше 50 лет.
data[(data['sex'] == 'women') & (data['age'] > 50) | (data['sex'] == 'male')].head()
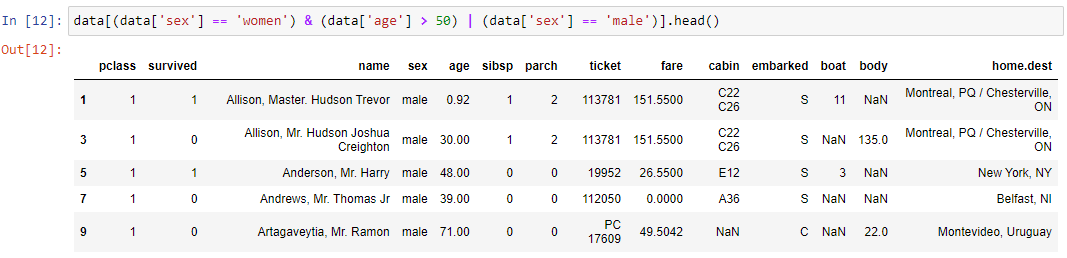
Связка условий происходит с помощью логических операторов И (&) и ИЛИ (|).
Изменение датафреймов Pandas
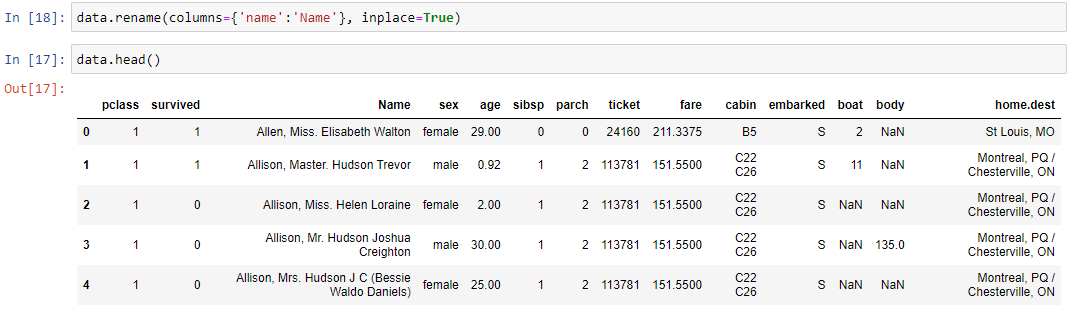
Пусть нам необходимо изменить название колонки. Pandas позволяет сделать это одной левой с помощью метода rename(). Переименуем колонку name в Name. В параметр columns передаем словарь, в котором указываются пары старое_имя:новое_имя колонок. Параметр inplace=True заставляет Pandas менять текущий датафрейм, а не создавать новый.
data.rename(columns={'name':'Name'}, inplace=True)
Возможно применить произвольную пользовательскую функцию к каждому элементу выбранных столбцов. Например, получим фамилии всех людей из колонки Name.
Функция получения фамилии выглядит следующим образом:
def get_last_name(name):
return name.split(',')[0].strip()

Теперь, чтобы применить ее ко всем элементам датафрейма, используется метод apply(), в которую передается объект функции. Например:
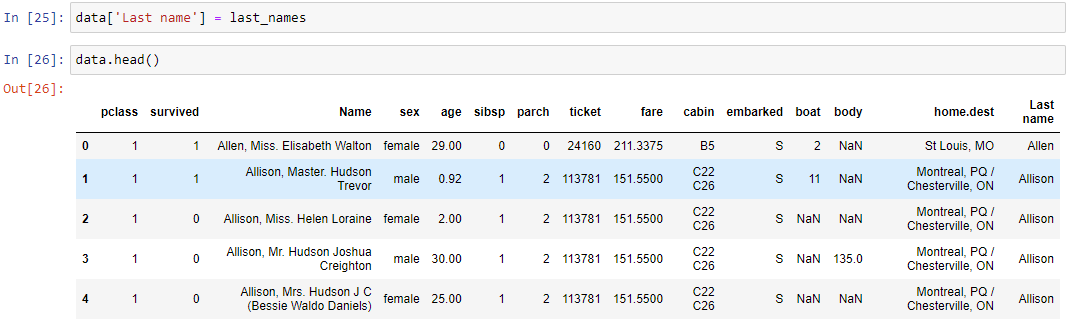
last_names = data['Name'].apply(get_last_name)

А теперь добавим в наш датафрейм столбец фамилий, которые мы сохранили в переменной last_names. Для этого просто в квадратных скобках указывается имя нового столбца:
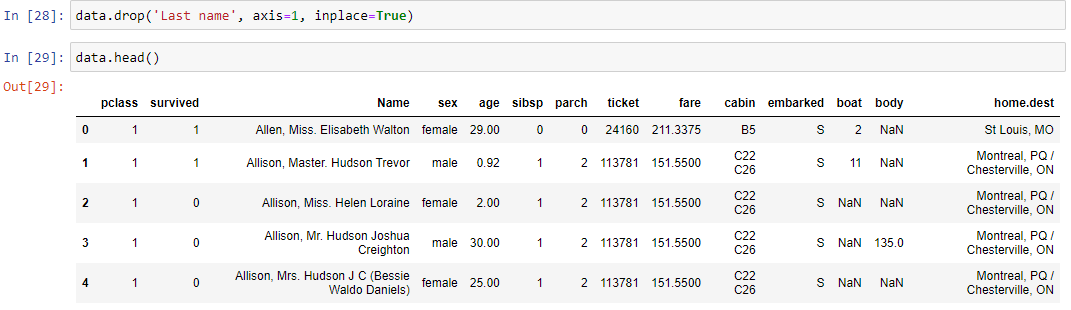
Чтобы удалить столбец, используется метод drop(). Удалим только что добавленный столбец фамилий. Параметр axis необходим, чтобы явно указать pandas работать со столбцами. Попробуйте поменять его на ноль и посмотреть, что произойдет.
data.drop('Last name', axis=1, inplace=True)
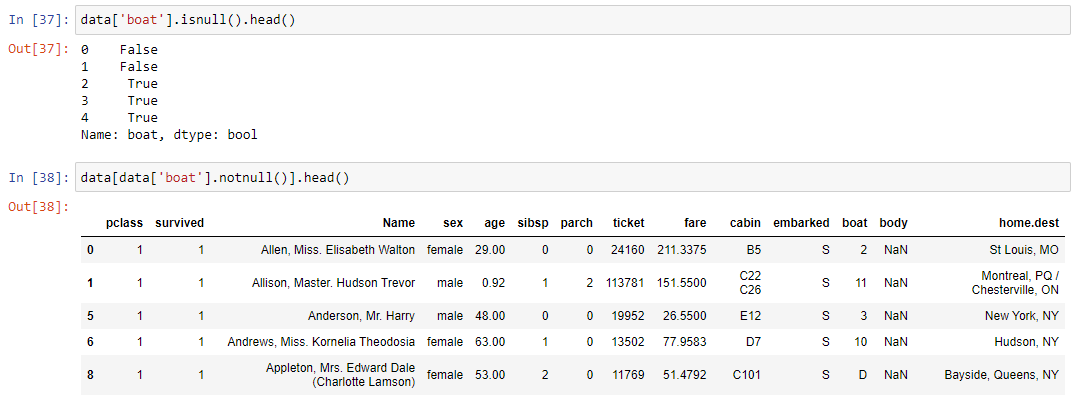
Очень часто датасеты поставляются неполными. Это значит, что в некоторых ячейках таблицы может не быть данных. В машинном обучении стараются или избавиться от таких строк данных, или как-то их заполнить. Для получения пустых строк используется метод isnull(), а для получения непустых строк – метод notnull(). Работает достаточно интуитивно.
data['boat'].isnull().head() # первые пять пустых ячеек столбца boat
data[data['boat'].notnull()].head() # первые пять непустых ячеек столбца boat
Если вы работали с SQL, то вам наверняка знаком метод GROUP BY. Он позволяет группировать данные по какому-то заданному критерию. Pandas обладает такими же возможностями. Для этого используется метод groupby().
Сгруппируем пассажиров по полу в зависимости от класса каюты и посчитаем их количество:
data.groupby('sex')['pclass'].value_counts()

Pandas содержит набор статистических методов, которые позволяют найти среднее значение, максимум, минимум, стандартное отклонение какого-либо набора данных из датафрейма. Кроме того, для быстрой оценки всех популярных параметров используется метод describe(). Рассчитаем все эти показатели для стоимости проезда пассажиров по разным классам:
data.groupby('pclass')['fare'].describe()

В результате, получаем таблицу, содержащую количество пассажиров, среднюю стоимость, ее стандартное отклонение и другие показатели.
Эти же функции доступны отдельно. Например, определим в каком соотношении выжили мужчины и женщины:
data.groupby('sex')['survived'].mean()

После окончания работы с датафремом, его можно сохранить в файлы различных форматов. Например, для сохранения в csv формат используется метод to_csv().
data.to_csv('titanic_2.csv', index=False)
Сохраняем датафрейм в файл csv с именем titanic_2.
Основы matplotlib
Matplotlib – библиотека для визуализации данных. Подключим библиотеку.
%matplotlib inline
import matplotlib.pyplot as plt
Jupyter Notebook поддерживает вывод графиков “на месте”. Для активации этого режима используется магическая команда %matplotlib inline.
Для построение графиков, используется объект plt, который был импортирован из пакета matplotlib.
Первым этапом построения графика является создание холста. Делается это следующим образом. Параметр figsize определяет размер холста в дюймах. Параметры передаются в виде кортежа. Числа могут быть дробными.
fig = plt.figure(figsize=(10, 6))
После этого добавляет оси, строим кривые и наносим легенду на холст.
fig = plt.figure(figsize=(10, 6))
axes = fig.add_axes([0,0,1,1]) # создаем прямоуголник для построение графиков в виде списка [left, bottom, width, height]
axes.plot(x, x**2, 'r') # добавить первую кривую на холст красного цвета
axes.plot(x, x**3, 'b*--') # добавить вторую крикую на холст синего цвета с маркерами другого типа
axes.set_xlabel('x') # добавить название оси Х
axes.set_ylabel('y') # добавить название оси Y
axes.set_title('Hello proglib') # добавить название всего графика
axes.legend([r'$x^2$', r'$x^3$'], loc=0) # добавить легенду
plt.show() # вывести график на экран
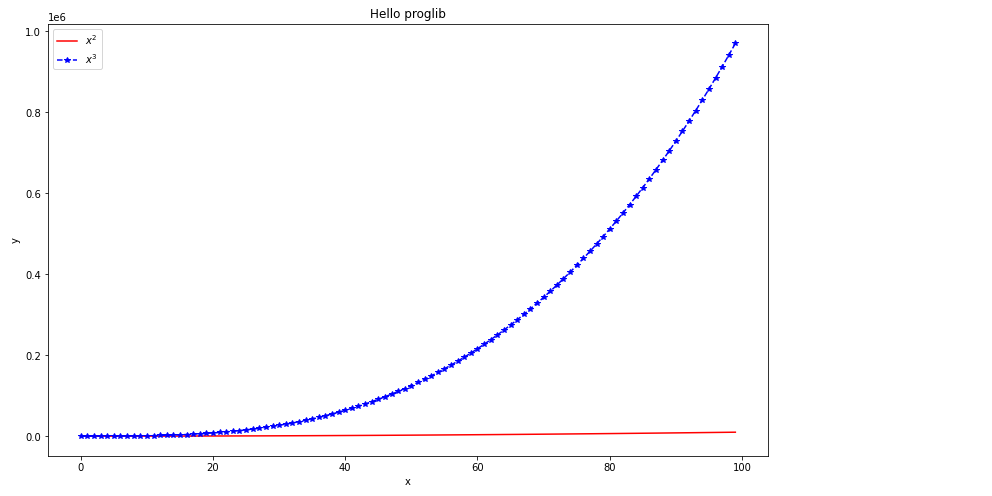
Пакет позволяет строить семейства графиков.
1. График в графике. Схема состроения абсолютно такая же, как в предудыщем примере
fig = plt.figure()
axes1 = fig.add_axes([0.1, 0.1, 0.8, 0.8]) # основной график
axes2 = fig.add_axes([0.2, 0.5, 0.4, 0.3]) # внутренный график. Его размер меньше, цифры показывают долю от figsize
# Основной график
axes1.plot(x, x**2, 'r')
axes1.set_xlabel('x')
axes1.set_ylabel('y')
axes1.set_title('Я внешний график')
# Вложенный график
axes2.plot(x**2, x, 'b')
axes2.set_xlabel('y')
axes2.set_ylabel('x')
axes2.set_title('Я внутренний график')
plt.show()
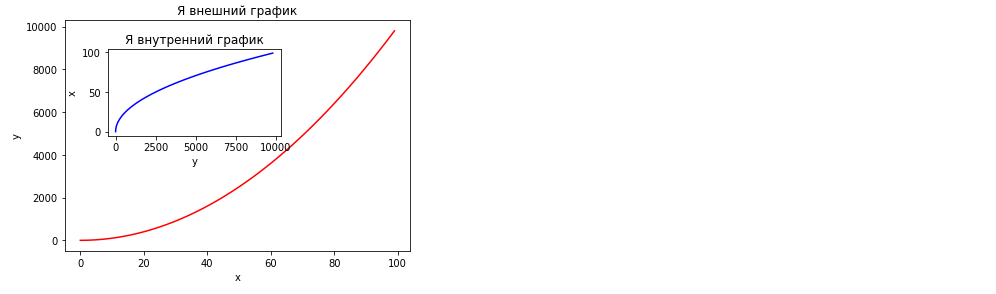
2. Семейство графиков. В этом случае, холст создается методом subplots(), параметром которого является кортеж чисел, сколько графиков по-горизонтали и по-вертикали он включает в себя. Построим одну строку из трех графиков.
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(16, 5))
for pow, ax in enumerate(axes):
ax.plot(x, x**(pow + 1), 'b')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title(f'$y = x^{pow + 1}$', fontsize=18)
fig.tight_layout() # автоматически вписывает все графики в размер холста
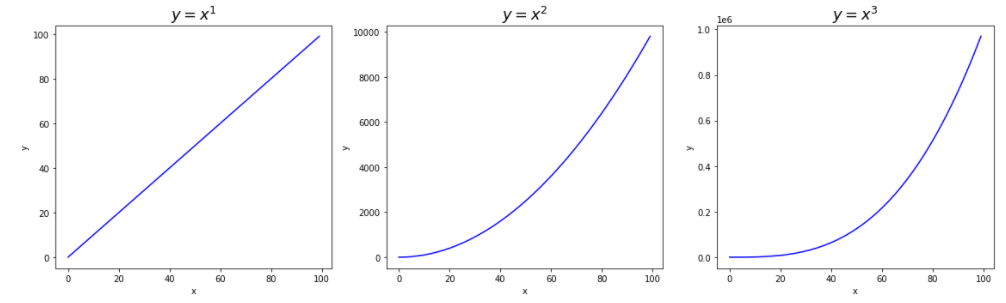
Matplotlib подходит для построения статистических графиков. Это огромная область, но построим гистограмму распределение пассажиров по возрасту для мужчин и женщин. В качестве данных используем тот же датасет titanic.
fig = plt.figure()
axes = fig.add_axes([0.0, 0.0, 1.0, 1.0])
bins = 20 # количество столбцов
index = np.arange(bins) # создаем список от 0 до bins - 1
axes.hist(data[data['sex'] == 'male']['age'].dropna(), bins=bins, alpha=0.6, label='Мужчины') # добавляем на холст гистограмму распределения возрастов среди мужчин
axes.hist(data[data['sex'] == 'female']['age'].dropna(), bins=bins, alpha=0.6, label='Женщины') # добавляем на холст гистограмму распределения возрастов среди женщин
axes.legend() # строим легенду
axes.set_xlabel('Возраст', fontsize=18)
axes.set_ylabel('Количество', fontsize=18)
axes.set_title('Распределение возрастов по полу человека', fontsize=18)
plt.show()
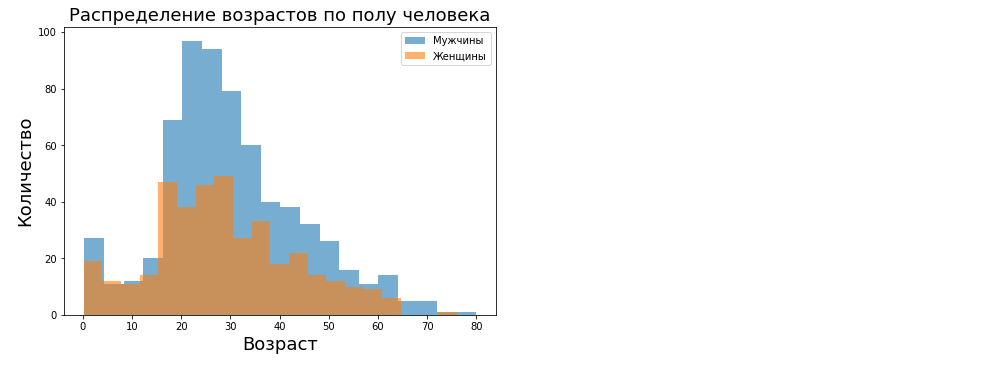
Стоит сказать, что это очень малая часть возможностей данной библиотеки. В качестве дополнительных материалов оставлю ссылки на документацию по всем рассмотренным в статье модулям:
Комментарии