
Перед тем как начнем изучать алгоритм, давайте разберемся – что же такое кластеризация. Под кластеризацией понимается обнаружение естественных группировок в данных. Обычно, когда нам даны данные, которые мы можем визуализировать (2- или 3-мерные данные), человеческий глаз может легко формировать различные кластеры. Но для машин это делать несколько сложнее. Но тут на помощь и приходят алгоритмы кластеризации, способные находить кластеры в пространстве с ещё большим количеством измерений, чего не может делать даже глаз человека. Теперь, когда мы знаем, что мы хотим сделать, воспользуемся K-means здесь.
Представьте, что у нас есть набор данных из 19 значений, которые выглядят примерно так:
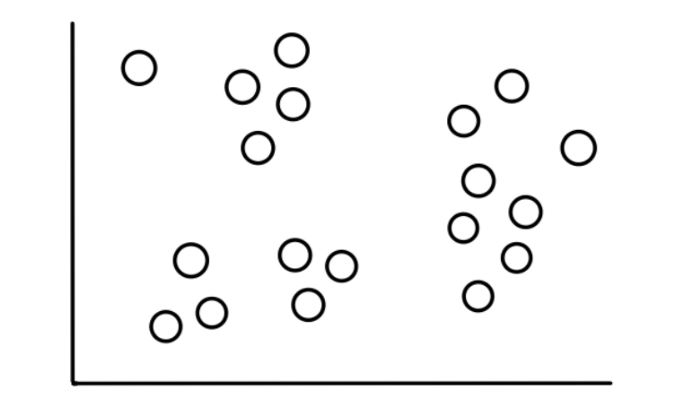
Теперь предположим, что мы знаем, что эти данные разбиваются на 3, относительно очевидные, категории и выглядеть это будет так:

Наша задача – использовать алгоритм кластеризации K-means, чтобы произвести эту категоризацию.
Шаг 1: Выбираем число кластеров, k
Число кластеров, которые мы хотим распознать, это и есть k в K-means. В нашем случае, так как мы предположили, что всего 3 кластера, k = 3.
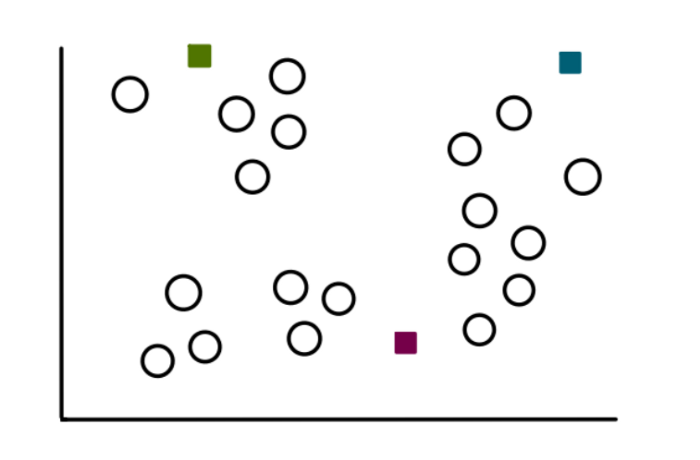
Шаг 2: Выбираем k случайных значений
Процесс обнаружения кластеров мы начинаем с выбора 3 случайно выбранных значений (не обязательно, чтобы они были нашими данными). Эти точки будут сейчас работать как центроиды или центры кластеров, которые мы собираемся сгруппировать:
Шаг 3: Создать k кластеров
Чтобы создать кластеры, мы начнем измерять расстояние между каждым значением наших данных до каждого из трех центроидов, а затем добавляем его к наиболее близкому кластеру. Для значения, взятого в качестве примера, расстояния будут выглядеть примерно так:
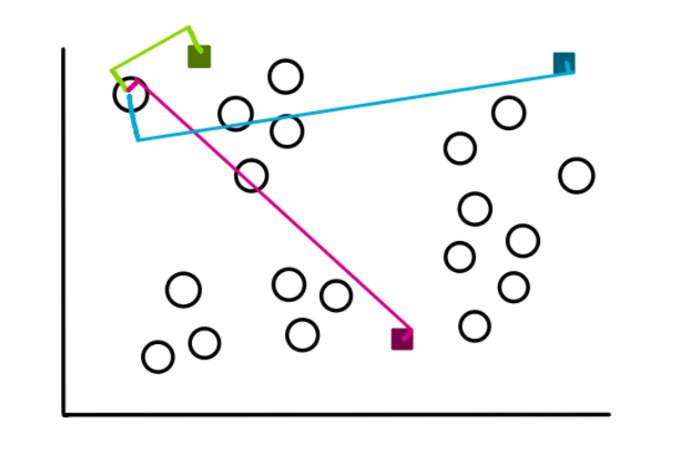
Смотря на рисунок, мы понимаем, что расстояние от значения до зеленого центроида наименьшее, поэтому мы и добавляем значение в зеленый кластер.
В 2-мерном пространстве для нахождения расстояния между двумя точками используется формула:
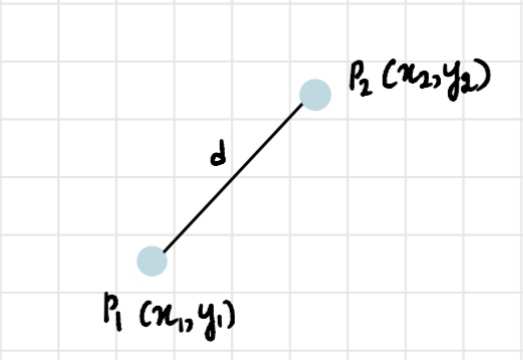
Используя эту формулу, мы повторяем процесс с оставшимися значениями, после этого кластеры будут выглядеть следующим образом:

Шаг 4: Вычисляем новый центроид каждого кластера
Теперь, когда у нас есть все три кластера, мы находим новые центроиды для каждого из них. Например, ниже изображена формула для нахождения координат синего кластера:
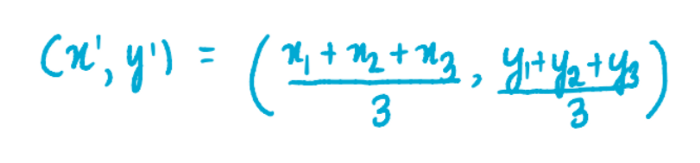
где x1, x2 и x3 – это координаты по оси x каждого из трех значений синего кластера, а y1, y2 и y3 – координаты соответствующих точек по оси y. Мы разделили сумму координат на 3, потому что 3 значения содержится в кластере. Аналогично, координаты центроид розового и зеленого кластеров будут равны:
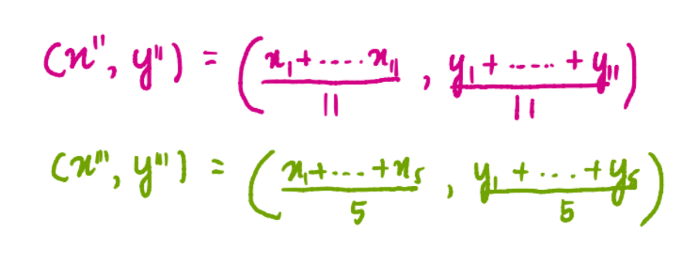
Так, новые центроиды будут иметь вид:

Шаг 5: Оценить качество каждого кластера
Так как k-means не может видеть кластеры так, как это делаем мы, он измеряет качество, находя среднее отклонение внутри всех кластеров. Основная идея, лежащая в основе k-means, заключается в определении таких кластеров, что отклонения внутри каждого кластера минимальны. Чтобы оценить отклонение, мы вычислим такую величину, как WCSS (within-cluster sum of squares) – cумму квадратов внутрикластерных расстояний до центра кластера.
Где С – это кластерные центроиды, а d – значения данных в каждом кластере
Но в целях упрощения, давайте представим, что отклонение визуально выглядит так:

Шаг 6: повторяем шаги 3-5
Итак, мы получили кластеры и отклонение, и … Мы начинаем все сначала.
Но теперь мы используем центроиды, которые были вычислены ранее, чтобы создать 3 новых кластера, пересчитать центры новых кластеров и вычислить сумму расстояний внутри каждого кластера.
Давайте предположим, что следующие 4 итерации будут выглядеть так:
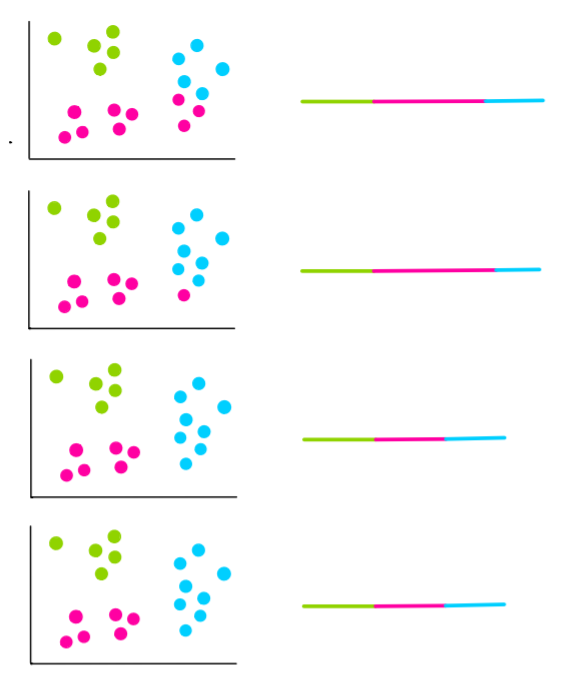
На двух последних итерациях мы видим, что кластеры не меняются. Это значит, что алгоритм сошелся и мы останавливаем процесс. Затем мы выбираем кластеры с наименьшим WCSS. Это будут кластеры на последних 2 итерациях, поэтому они и становятся нашими финальными кластерами.
Как выбирать k?
В нашем примере мы знали, что нам нужно 3 кластера. Но что, если мы не знаем, какое количество кластеров мы имеем, тогда как нам выбрать k?
В этом случае мы пытаемся использовать различные значения k и считать WCSS.
k=1:

k=2:

k=3:
k=4:
Вы можете заметить, что каждый раз, когда мы добавляем новый кластер, общее отклонение внутри каждого кластера становится все меньше и меньше. В конце настанет случай, когда на каждое значение данных будет приходиться отдельный кластер, и тогда отклонение будет равно 0.
Нам нужно использовать подход, называемый «метод локтя», чтобы найти наилучшее значение k. Для этого мы строим график зависимости WCSS от количества кластеров, или k.
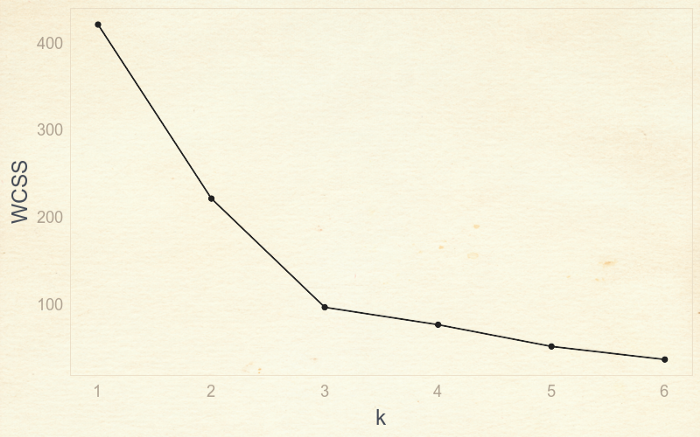
Подход называется «метод локтя», потому что мы можем найти оптимальное значение k, когда найдем «согнутый локоть» графика, что находится в точке с k=3. Вы можете заметить, что до 3 наблюдается быстрое уменьшение отклонения, но потом отклонение перестает падать также быстро.
Что ж, а на этом все. Вот такой он, k-means – простой, но эффективный алгоритм кластеризации! Подведем краткий итог. Сегодня из этой статьи мы узнали, что же такое k-means, как он работает при решении задач кластеризации, а также как находить количество кластеров, когда это неизвестно. Надеюсь, что статья вам понравилось. До новых встреч.
Мне нужно оперативно освоить алгоритмы и структуры данных. Что делать?
Если хотите подтянуть или освежить знания по алгоритмам и структурам данных, загляните на наш курс «Алгоритмы и структуры данных», на котором вы:
- углубитесь в решение практических задач;
- научитесь применять алгоритмы и структуры данных при разработке программ;
- изучите сленг, на котором говорят все разработчики независимо от языка программирования: язык алгоритмов и структур данных;
- узнаете все про сложные алгоритмы, сортировки, сжатие данных и многое другое.
Вы также будете на связи с преподавателем и другими студентами. В итоге будете браться за сложные проекты и повысите чек за свою работу. Курс подходит как junior, так и middle-разработчикам.
Комментарии