

Сложные (и многочисленные) операции в базе данных требуют солидного объема оперативной памяти – например, для создания набора результатов PostgreSQL обычно приходится:
- Выполнить поиск по индексу.
- Извлечь связанные строки из одной или нескольких таблиц.
- Объединить, отфильтровать, агрегировать и отсортировать кортежи в пригодный для использования результат.
Каждый из этих шагов требует памяти, и PostgreSQL может обрабатывать тысячи таких запросов одновременно. Так что рано или поздно перед разработчиками любого серьезного проекта встает необходимость решения нескольких сложных вопросов:
- Как грамотно оптимизировать использование доступной памяти?
- В каком соотношении распределить ОЗУ между несколькими типами памяти, которые необходимы PostgreSQL для эффективной работы?
- Как предотвратить защитное завершение операционной системой процесса PostgreSQL, который использует слишком много памяти?
Для ответов на все эти вопросы нужно определить, сколько именно памяти использует PostgreSQL для основных процессов – а это сама по себе нетривиальная задача. Советы по настройке памяти так многочисленны и разнообразны, что в них сложно сориентироваться. Поэтому в этой статье мы сведем всю мудрость экспертов к конкретным шагам, которые помогут максимально эффективно распорядиться доступной памятью.
Общие буферы
Первый и самый большой сегмент оперативной памяти, связанный с сервисом PostgreSQL, называется общими буферами. Он представляет собой наиболее часто извлекаемые строки из всех таблиц и индексов (частота использования определяется эвристическим методом). Чем чаще ссылаются на страницу, тем больше вероятность того, что она уже находится в общих буферах и ее не нужно запрашивать у операционной системы. Если вы интересуетесь тонкостями внутреннего устройства общих буферов, отличное объяснение есть здесь.
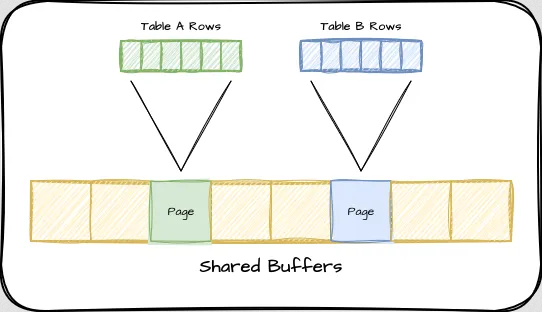
Общие буферы имеют статический объем, который должен быть выделен при запуске PostgreSQL, и он не будет увеличиваться, поэтому нам не нужно беспокоиться о том, что это может привести к неожиданным проблемам с памятью. Важно правильно определить его размер, поскольку он может быть изменен только при запуске или перезапуске PostgreSQL.
Размер страницы PostgreSQL по умолчанию составляет 8 Кб, и каждая страница представляет собой несколько записей индекса или строк таблицы. Прежде чем PostgreSQL сможет использовать индекс или строку, он должен сначала получить соответствующую страницу в оперативной памяти. Если эти страницы находятся в общих буферах, их «рейтинг» увеличивается, и вероятность того, что они будут вытеснены позже, снижается. Учитывая, что мы хотим, чтобы PostgreSQL кэшировал как можно больше данных, этой области следует выделить не менее 25% доступного объема памяти (по умолчанию PostgreSQLвыделяет буферам 128 Мб). Такой объем для буферов называется в большинстве рекомендаций, и опыт показывает, что он подходит для большинства систем.
Но что, если нам нужно более точное значение, чтобы не резервировать слишком много? Постоянное выделение больших объемов оперативной памяти неоправданно увеличивает накладные расходы системы и, в конце концов, может привести к проблемам с очисткой диска. Как найти объем оперативной памяти, используемый наиболее активными таблицами и индексами? Здесь на помощь приходит расширение pg_buffercache. Оно предоставляет представление об общих буферах, чтобы мы могли узнать, какие именно таблицы и индексы выделены, включая относительную оценку каждой страницы. Для целей настройки shared_buffers нам достаточно узнать, насколько заполнен буфер, с помощью такого запроса:
WITH state AS (
SELECT count(*) FILTER (WHERE relfilenode IS NOT NULL) AS used,
count(*) FILTER (WHERE relfilenode IS NULL) AS empty,
count(*) AS total
FROM pg_buffercache
)
SELECT *, round(used * 1.0 / total * 100, 1) AS percent
FROM state;
Этот запрос показывает, сколько страниц буфера используется из общего количества. Если база данных работает уже некоторое время, а буферный кэш не используется на 100%, текущие настройки могут быть слишком высокими, и мы можем уменьшить размер экземпляра или значение shared_buffers, чтобы компенсировать расхождение. Если кэш используется на 100% и кэшируются только небольшие части многих таблиц, может быть полезно последовательно устанавливать более высокие значения, пока мы не увидим уменьшающуюся отдачу. Эту настройку можно выполнить и без помощи pg_buffercache, но она заметно облегчает процесс.
Другой запрос, который может дать представление о настройках shared_buffers, использует представление
pg_stat_ioдля определения отношения количества попаданий в кэш (hits) к общему количеству обращений к диску (reads + hits):
SELECT (hits / (reads + hits)::float) AS hit_ratio,
reads, writes
FROM pg_stat_io
WHERE backend_type = 'client backend'
AND context = 'normal'
AND object = 'relation';
Соотношение, близкое к 1, может указывать на то, что PostgreSQL постоянно циклически загружает и выгружает одни и те же страницы из shared_buffers. Для уменьшения такой пробуксовки нужно увеличить объем shared_buffers.
Рабочая память
Рабочая память используется для временного хранения данных во время выполнения запросов, что позволяет ускорить обработку за счет меньшего использования диска. Параметр контролируется настройкой work_mem, и по умолчанию равен 4 Мб. Это первое значение, которое обычно изменяют в
попытке ускорить выполнение запросов.
work_mem, если операционная система завершает работу PostgreSQL из-за сообщения «закончилась память», но это только усугубит проблему, поскольку увеличит общее потребление памяти сервером PostgreSQL, и повысит вероятность таких завершений. Многие разработчики считают, что рабочая память — это один большой блок памяти, который PostgreSQL использует для всех своих операций во время обработки запроса. Однако это не так. На самом деле, PostgreSQL выделяет отдельные блоки рабочей памяти для каждой отдельной операции или «узла» в процессе выполнения запроса. Рассмотрим упрощенную схему выполнения довольно простого запроса, который извлекает все товары, когда-либо заказанные определенным пользователем, а затем сортирует результаты по элементам заказа:
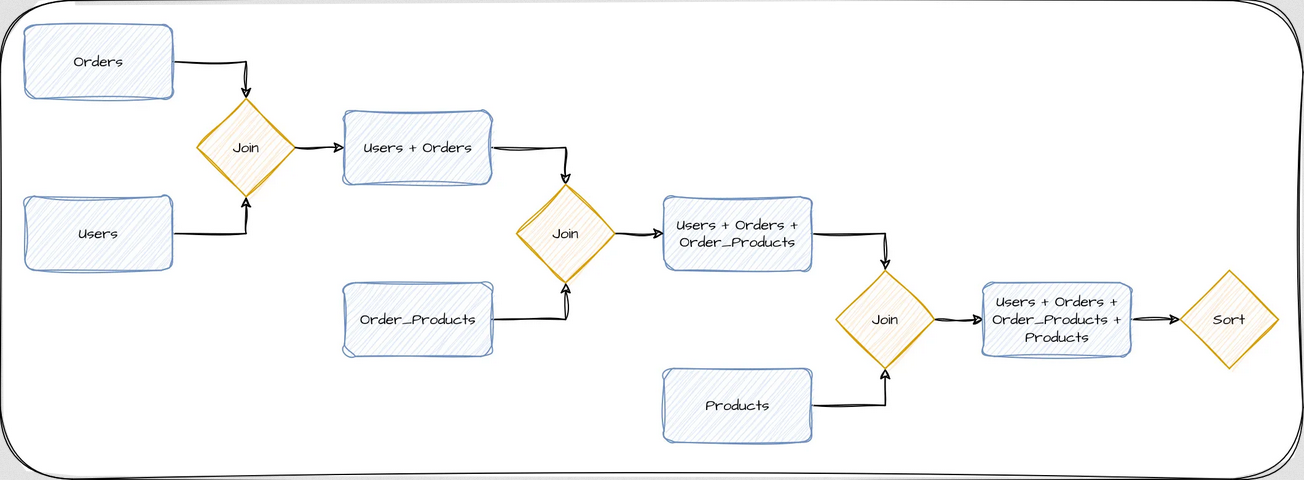
На каждом этапе требуется объединить только два элемента, а результат объединения отправляется на следующие этапы. В большинстве баз данных каждый из этих этапов называется узлом, а запросы обычно состоят из нескольких узлов. В частности, в данном примере для получения конечного результата требуется четыре узла. При рассмотрении вопроса об использовании памяти на сервере PostgreSQL очень важно понимать, что каждому узлу выделяется отдельный экземпляр work_mem. Так что при использовании work_mem по умолчанию в 4 Мб, этот запрос может потребовать до 16 Мб оперативной памяти. Если сервер выполняет одновременно 100 таких запросов, только для подсчета результатов будет задействовано до 1,6 Гб оперативной памяти. Более сложные запросы потребуют еще больше оперативной памяти в зависимости от того, сколько узлов необходимо для выполнения запроса. Параметр max_connections также играет здесь роль, поскольку он определяет, сколько одновременных сессий может выполнять запрос.
Такое высокое потребление памяти work_mem – одна из основных причин, по которой рекомендуется 25% для shared_buffers. Пока база данных не будет тщательно профилирована на предмет параллелизма и сложности запросов, выделять большее значение может быть небезопасно: это может привести к тому, что операционная система будет отклонять запросы на память или завершит работу PostgreSQL.
И наоборот, если значение work_mem слишком мало, все строки или промежуточные результаты, которые не помещаются в оперативной памяти, будут выводиться на диск, что на порядки медленнее. К счастью, это легко обнаружить, проверив представление pg_stat_database с помощью такого запроса:
SELECT datname, pg_size_pretty(temp_bytes / temp_files) AS overflow
FROM pg_stat_database
WHERE temp_files > 0;
datname | overflow
----------+----------
mytestdb | 6017 kB
PostgreSQL отслеживает суммарный размер и количество всех временных файлов, записанных на диск. Можно использовать этот факт, чтобы найти приближенное среднее значение, и если размер будет приемлемым, – увеличить work_mem на этот показатель. После этого
большинство запросов больше не будут использовать диск в
качестве временного рабочего пространства. Нередки случаи, когда work_mem не
хватает всего 2-4 Мб для выполнения в оперативной памяти, в результате чего
запросы выполняются гораздо медленнее, чем могли бы.
Текущее обслуживание
Последний из
параметров настройки использования оперативной памяти PostgreSQL похож на
work_mem, но связан именно с обслуживанием и называется maintenance_work_mem. Этот параметр задает объем
оперативной памяти, выделенный для выполнения таких операций, как VACUUM,
CREATE INDEX и ALTER TABLE ADD FOREIGN KEY, и по умолчанию установлен на 64 Мб.
Поскольку обслуживание ограничено одной операцией за сеанс, и маловероятно, что будет происходить много одновременных действий, считается достаточно безопасным использовать более высокие значения. Очень часто это значение достигает 1 или даже 2 Гб, так как эти операции обслуживания очень требовательны к памяти и выполняются гораздо быстрее, если могут работать полностью в оперативной памяти.
Важным нюансом здесь является процесс автоочистки. Эта функция автоматически запускает процессы в фоновом режиме для очистки мертвых кортежей — это строки данных, которые были удалены или обновлены и теперь не используются, но все еще занимают место в базе данных. Процессы очистки запускаются до определенного лимита, установленного параметром autovacuum_max_workers. Каждый из этих рабочих процессов может использовать полный экземпляр maintenance_work_mem. Большинство серверов с достаточным количеством оперативной памяти могут безопасно использовать 1 Гб для maintenance_work_mem: это позволяет автоочистке эффективно работать без значительного влияния на другие процессы. Но если оперативная память на сервере ограничена, следует уменьшить объем памяти, используемый процессами автоочистки, с помощью параметра autovacuum_work_mem.
Пул соединений
PostgreSQL является процессно-ориентированной системой управления базами данных: это означает, что каждая пользовательская сессия назначается отдельному физическому процессу, а не потоку. Каждое соединение с базой данных требует определенного количества оперативной памяти и способствует переключению контекста между активными сессиями, что может снижать производительность сервера.
Один из эффективных способов управления потреблением памяти и производительностью в PostgreSQL заключается в установке параметра max_connections на значение, которое не превышает количество доступных потоков процессора, умноженное на 4. Это минимизирует время, затрачиваемое на переключение между активными сессиями, и естественным образом ограничивает объем памяти, который могут совместно использовать все сессии.
Помните, что если каждая сессия выполняет запрос, а каждый узел представляет собой одно распределение рабочей памяти, то теоретический максимум использования рабочей памяти составляет: соединения * узлы * рабочая память.
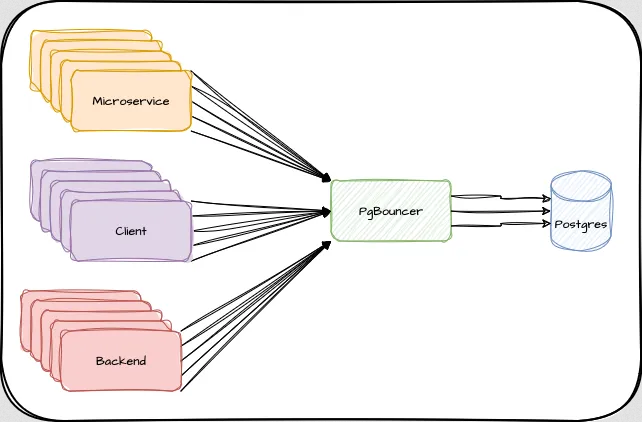
Не всегда удается снизить сложность запросов, но обычно мы можем уменьшить количество соединений. Хотя в случаях, когда приложения всегда открывают определенное количество сессий, или несколько отдельных микросервисов полагаются на PostgreSQL, это может быть очень сложной задачей, которую должен решать специализированный инструмент. Это означает, что следующим шагом будет внедрение пула соединений, такого как PgBouncer. Такой инструмент позволит отделить клиентские соединения от базы данных и повторно использовать дорогостоящие сессии PostgreSQL между ними. При правильной настройке несколько сотен клиентов могут совместно использовать несколько десятков соединений PostgreSQL без ущерба для приложения:
Уменьшение раздутости
Возможно, самый
сложный для отслеживания аспект использования памяти – это «раздувание»
таблиц. PostgreSQL
использует Multi-Version Concurrency Control (MVCC) для представления данных в
своей системе хранения. Это означает, что каждый раз, когда строка таблицы
изменяется, PostgreSQL создает еще одну копию этой строки где-то в таблице, помеченную
новым номером версии. Процесс VACUUM помечает старые версии строк
как неиспользуемое пространство, чтобы туда можно было поместить новые версии
строк.
В PostgreSQL есть автоматический фоновый процесс очистки, который постоянно находит эти неиспользуемые пространства и старается ограничить рост таблиц. Однако иногда стандартной конфигурации недостаточно для систем с особенно большим объемом данных, и автоочистка может не справляться со своими обязанностями. В результате в таблицах постепенно появляется больше мертвых строк, чем живых, что приводит к «раздуванию» таблиц, заполненных старыми данными.
Помните наше предыдущее изображение общих буферов? Что произойдет, если каждая страница будет содержать только одну живую строку и несколько мертвых строк? В итоге мы окажемся в такой ситуации:
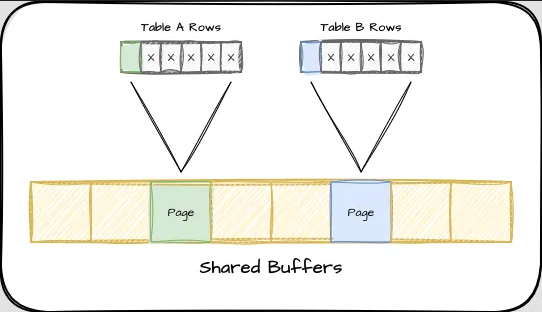
Если в подобной ситуации определенный запрос потребует 10 строк, нам придется получить 10 страниц в общие буферы и в итоге потратить много памяти, которую можно было бы использовать для чего-то другого. А если эти строки особенно востребованы, подсчет использования будет держать их в общих буферах и сделает кэш неэффективным. Существует множество запросов, позволяющих оценить раздутость таблицы, но единственный способ получить конкретное представление о том, как выглядят страницы в таблице, – это использовать расширение pgstattuple. Установив это расширение, мы сможем увидеть, насколько раздутой может быть конкретная таблица, с помощью такого запроса:
SELECT tuple_percent, free_percent
FROM pgstattuple('my_table');
Если free_percent больше 30%, следует сделать настройки автоочистки более агрессивными. Если он значительно превышает 30%, то, вероятно, стоит полностью удалить раздутый массив. К сожалению, в настоящее время нет простого способа сделать это. Единственным поддерживаемым методом является, по сути, перестройка таблицы с помощью этой команды:
VACUUM FULL my_table;
VACUUM FULL переписывает всю таблицу, перемещая все живые строки в новое место, и удаляет старую раздутую копию. На время выполнения этого процесса назначается эксклюзивная блокировка доступа, поэтому почти во всех случаях требуется некоторое время простоя.
Альтернативой VACUUM FULL является расширение pg_repack.
Этот CLI-инструмент тоже
может реорганизовать таблицу для устранения раздутости, но делает это без
эксклюзивной блокировки и полностью в режиме онлайн. Поскольку pg_repack существует
вне ядра PostgreSQL и изменяет хранилище таблиц и индексов, его часто относят к
продвинутым. Перед его использованием в продакшене следует провести многочисленные проверки в тестовой среде.
Стратегия балансировки для проектов с ограниченным объемом ОЗУ
Правильная настройка всех перечисленных выше параметров – это и искусство, и наука. В некоторых ситуациях, когда памяти не хватает, может потребоваться немного уменьшить shared_buffers, чтобы освободить место для work_mem. А возможно, придется уменьшить и то, и другое. Если приложение требует большого количества сеансов, возможно, имеет смысл уменьшить work_mem или ввести пул соединений, чтобы предотвратить выделение большого количества оперативной памяти для параллельных сеансов. Возможно, имеет смысл уменьшить maintenance_work_mem, если в прошлом мы увеличивали его, полагая, что оперативной памяти хватит на все. Есть над чем подумать!
Если приведенных выше настроек оказалось недостаточно для оптимизации работы приложения, советуем выполнить следующие шаги:
- Если вы еще не используете пул соединений – установите его и уменьшите max_connections. Это часто самый быстрый и простой способ сократить максимальное потребление ресурсов.
- Используйте
EXPLAINдля наиболее частых запросов, о которых сообщает pg_stat_statements, чтобы найти максимальное количество узлов в запросах, а не среднее. Затем установите значение work_mem не выше (80% от общего объема оперативной памяти – shared_buffers) / (max_connections * max plan nodes). Накопительный эффект work_mem мультипликативен, поэтому контроль над ним – один из самых простых способов предотвратить перепотребление. - Верните параметры maintenance_work_mem и autovacuum_work_mem к значению по умолчанию 64 Мб. Рассмотрите возможность увеличения на 8 Мб, если задачи обслуживания выполняются слишком медленно и есть доступная оперативная память. Эти параметры не требуют перезапуска, и с ними проще экспериментировать.
- Используйте расширение pg_buffercache, чтобы узнать, какая часть таблиц хранится в shared_buffers. Внимательно изучите каждую таблицу и индекс и посмотрите, есть ли способ уменьшить это количество путем архивирования данных, пересмотра запросов для использования меньшего количества информации и так далее. Примените
VACUUM FULLили pg_repack для уплотнения страниц, используемых активными раздутыми таблицами. Это позволит вам соответствующим образом уменьшить shared_buffers, поскольку активный набор данных станет меньше. - Если pg_buffercache показывает, что shared_buffers переполнен и не может быть уменьшен без вытеснения активных страниц, используйте столбец usagecount для определения приоритета наиболее активных страниц. Значение этого столбца варьируется от 1 до 5, поэтому если мы сосредоточимся на страницах, используемых 3-5 раз, можно будет уменьшить объем shared_buffers без существенного влияния на производительность. Помните, что общие буферы работают вместе с кэшами операционной системы и файловой системы, но не могут быть очищены таким же образом при высоком уровне нагрузки на память. Вместо того, чтобы PostgreSQL напрямую знал о кэшированных страницах, небольшие общие буферы полагаются на операционную систему для кэширования часто используемых данных. Поэтому они могут быть хорошим вариантом, когда оперативной памяти особенно мало.
Если же все эти шаги не помогли, значит, приложению действительно нужен больший объем ОЗУ. Так что остается последняя мера – апгрейд железа или переход на другой облачный тариф.
Подведем итоги
Обновление оборудования или переход на более продвинутый тариф — не первое и тем более не единственное решение проблемы нехватки ОЗУ: прежде всего стоит попробовать оптимизировать использование доступной памяти. Это сложная задача, которая требует понимания того, как и для чего PostgreSQL использует память, но в эти нюансы действительно стоит вникнуть: с помощью продуманной настройки параметров можно достичь значительных улучшений производительности в большинстве случаев.
Комментарии