

Установка необходимых библиотек
Для работы понадобится установить следующие пакеты:
OpenCV – cамая популярная библиотека компьютерного зрения – её мы будем использовать для
чтения и записи видеофайлов. Пример использования недавно публиковался в Библиотеке программиста. Чтобы установить OpenCV, используйте pip:
pip3 install opencv-python
FFmpeg – кроссплатформенное ПО для записи, конвертации и стриминга аудио и видео. Мы будем использовать FFmpeg для объединения нескольких видеофайлов. Страница загрузки.
Импорт библиотек в Python
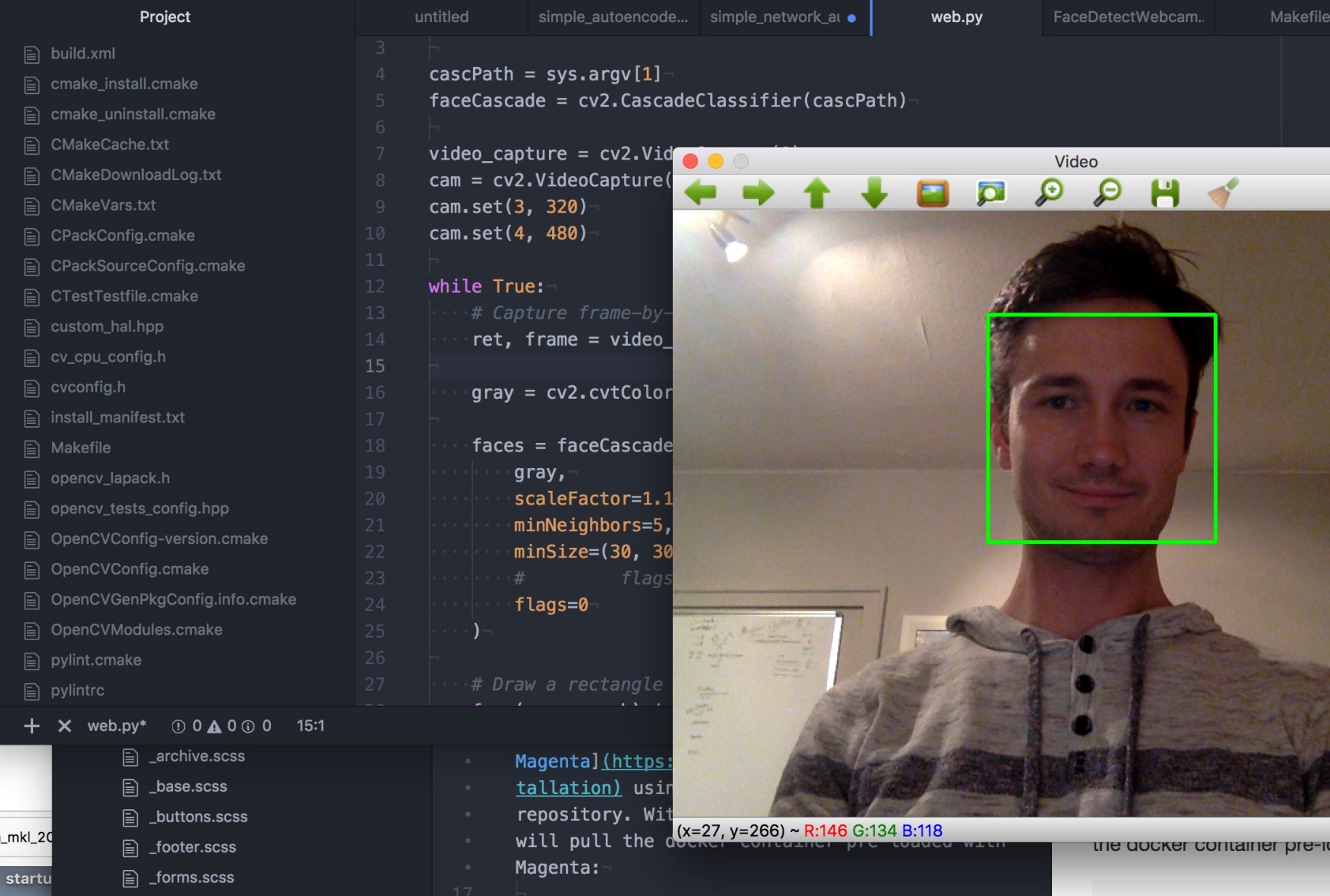
Давайте импортируем необходимые библиотеки:
import cv2 as cv
import time
import subprocess as sp
import multiprocessing as mp
from os import remove
from xailient import dnn
Подробная информация об используемых библиотеках:
- cv2: библиотека OpenCV, чтобы читать и писать видеофайлы;
- time: получаем текущее время для расчета времени выполнения кода;
- subprocess: запускаем новые процессы, подключаемся к их каналам input/output/error и забираем их коды возврата.
- multiprocessing: распараллеливаем выполнение функции для нескольких входных значений и распределяем входные данные между процессами;
- xailient: библиотека для распознавания лиц. Вы можете использовать для этой цели любую библиотеку, например face_recognition, но в нашем примере используется эта.
Конвейер обработки видео в одном процессе
Начнем с метода обработки видео в одном процессе. Именно так мы обычно читаем видеофайл, обрабатываем каждый кадр и записываем выходные кадры обратно на диск.
def process_video():
# Читаем файл с видео
cap = cv.VideoCapture(file_name)
# Получаем высоту, ширину и количество кадров в видео
width, height = (
int(cap.get(cv.CAP_PROP_FRAME_WIDTH)),
int(cap.get(cv.CAP_PROP_FRAME_HEIGHT))
)
fps = int(cap.get(cv.CAP_PROP_FPS))
# Определяем кодек и создаем объект VideoWriter
fourcc = cv.VideoWriter_fourcc('m', 'p', '4', 'v')
out = cv.VideoWriter()
output_file_name = "output_single.mp4"
out.open(output_file_name, fourcc, fps, (width, height), True)
try:
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
im = frame
# Выполняем распознавание лиц в кадре
_, bboxes = detectum.process_frame(im, THRESHOLD)
# Цикл по списку (если он пуст, то это пропускаем) и наложение зеленых полей for i in bboxes:
cv.rectangle(im, (i[0], i[1]), (i[2], i[3]), (0, 255, 0), 3)
# Рисуем рамку
out.write(im)
except:
# Высвобождаем ресурсы
cap.release()
out.release()
# Высвобождаем ресурсы
cap.release()
out.release()
Давайте создадим еще одну функцию, которая вызывает видеопроцессор, фиксирует время начала и конца, вычисляет время, необходимое для выполнения обработки и количество обработанных кадров в секунду.
def single_process():
print("Обработка видео с использованием одного процесса...")
start_time = time.time()
process_video()
end_time = time.time()
total_processing_time = end_time - start_time
print("Время: {}".format(total_processing_time))
print("FPS : {}".format(frame_count/total_processing_time))
file_name = "input_video.mp4"
output_file_name = "output.mp4"
width, height, frame_count = get_video_frame_details(file_name)
print("Количество кадров = {}".format(frame_count))
print("Ширина = {}, Длина = {}".format(width, height))
single_process()
Обработка видео с использованием нескольких процессов
Теперь определим другую функцию, использующую многопроцессорную обработку:
def process_video_multiprocessing(group_number):
# Читаем файл с видео
cap = cv.VideoCapture(file_name)
cap.set(cv.CAP_PROP_POS_FRAMES, frame_jump_unit * group_number)
# Получаем высоту, ширину и количество кадров в видео
width, height = (
int(cap.get(cv.CAP_PROP_FRAME_WIDTH)),
int(cap.get(cv.CAP_PROP_FRAME_HEIGHT))
)
no_of_frames = int(cap.get(cv.CAP_PROP_FRAME_COUNT))
fps = int(cap.get(cv.CAP_PROP_FPS))
proc_frames = 0
# Определяем кодек и создаем объект VideoWriter
fourcc = cv.VideoWriter_fourcc('m', 'p', '4', 'v')
out = cv.VideoWriter()
output_file_name = "output_multi.mp4"
out.open("output_{}.mp4".format(group_number), fourcc, fps, (width, height), True)
try:
while proc_frames < frame_jump_unit:
ret, frame = cap.read()
if not ret:
break
im = frame
# Выполняем распознавание лиц в каждом кадре
_, bboxes = detectum.process_frame(im, THRESHOLD)
# Цикл по списку (если он пуст, то это пропускаем) и наложение зеленых полей
for i in bboxes:
cv.rectangle(im, (i[0], i[1]), (i[2], i[3]), (0, 255, 0), 3)
# Рисуем рамку
out.write(im)
proc_frames += 1
except:
# Высвобождаем ресурсы
cap.release()
out.release()
# Высвобождаем ресурсы
cap.release()
out.release()
В приведенной функции описана обработка, которая обычно выполняется с помощью одного процесса, но теперь она делится поровну между общим количеством процессоров, доступных на исполняющем устройстве.
Если существует 4 процесса, а общее количество кадров в обрабатываемом видео равно 1000, то каждый процесс получает 250 кадров для обработки, которые выполняются параллельно. В итоге каждый процесс создаст отдельный выходной файл с видео. Чтобы объединить эти файлики мы будем использовать ffmpeg.
def combine_output_files(num_processes):
# Создаем список выходных файлов и складываем имена файлов в текстовый файл
list_of_output_files = ["output_{}.mp4".format(i) for i in range(num_processes)]
with open("list_of_output_files.txt", "w") as f:
for t in list_of_output_files:
f.write("file {} \n".format(t))
# Используем ffmpeg для объединения выходных видеофайлов
ffmpeg_cmd = "ffmpeg -y -loglevel error -f concat -safe 0 -i list_of_output_files.txt -vcodec copy " + output_file_name
sp.Popen(ffmpeg_cmd, shell=True).wait()
# Удаляем временные файлы
for f in list_of_output_files:
remove(f)
remove("list_of_output_files.txt")
Теперь создаем конвейер для запуска многопроцессорной обработки видео, расчета времени выполнения и кадров, обрабатываемых в секунду.
def multi_process():
print("Обработка видео с использованием {} процессов...".format(num_processes))
start_time = time.time()
# Параллельное выполнение функции с несколькими входными значениями
p = mp.Pool(num_processes)
p.map(process_video_multiprocessing, range(num_processes))
combine_output_files(num_processes)
end_time = time.time()
total_processing_time = end_time - start_time
print("Время: {}".format(total_processing_time))
print("FPS : {}".format(frame_count/total_processing_time))
file_name = "input.mp4"
output_file_name = "output.mp4"
width, height, frame_count = get_video_frame_details(file_name)
print("Количество кадров = {}".format(frame_count))
print("Ширина= {}, Высота = {}".format(width, height))
num_processes = mp.cpu_count()
print("Количество процессоров: " + str(num_processes))
frame_jump_unit = frame_count// num_processes
multi_process()
Результаты
Эксперимент проводился на Lenovo Yoga 920 с Ubuntu18.04. Количество доступных на устройстве логических процессоров – 8шт.
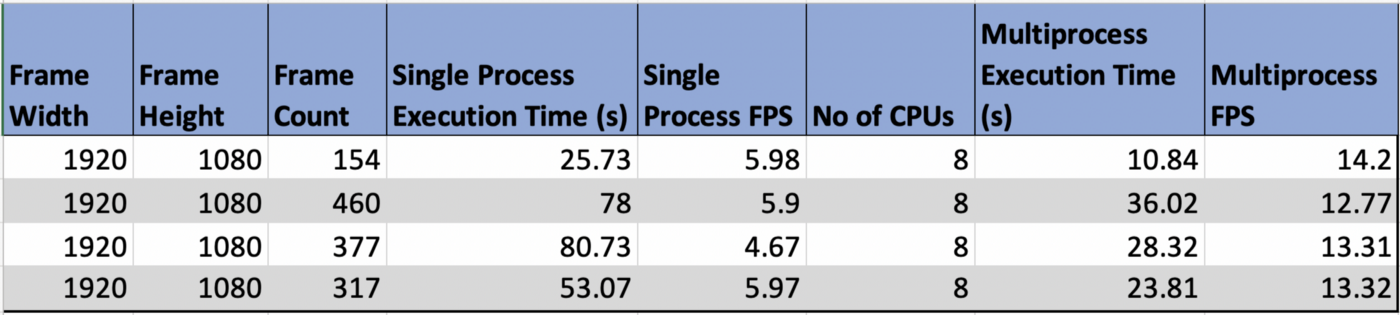
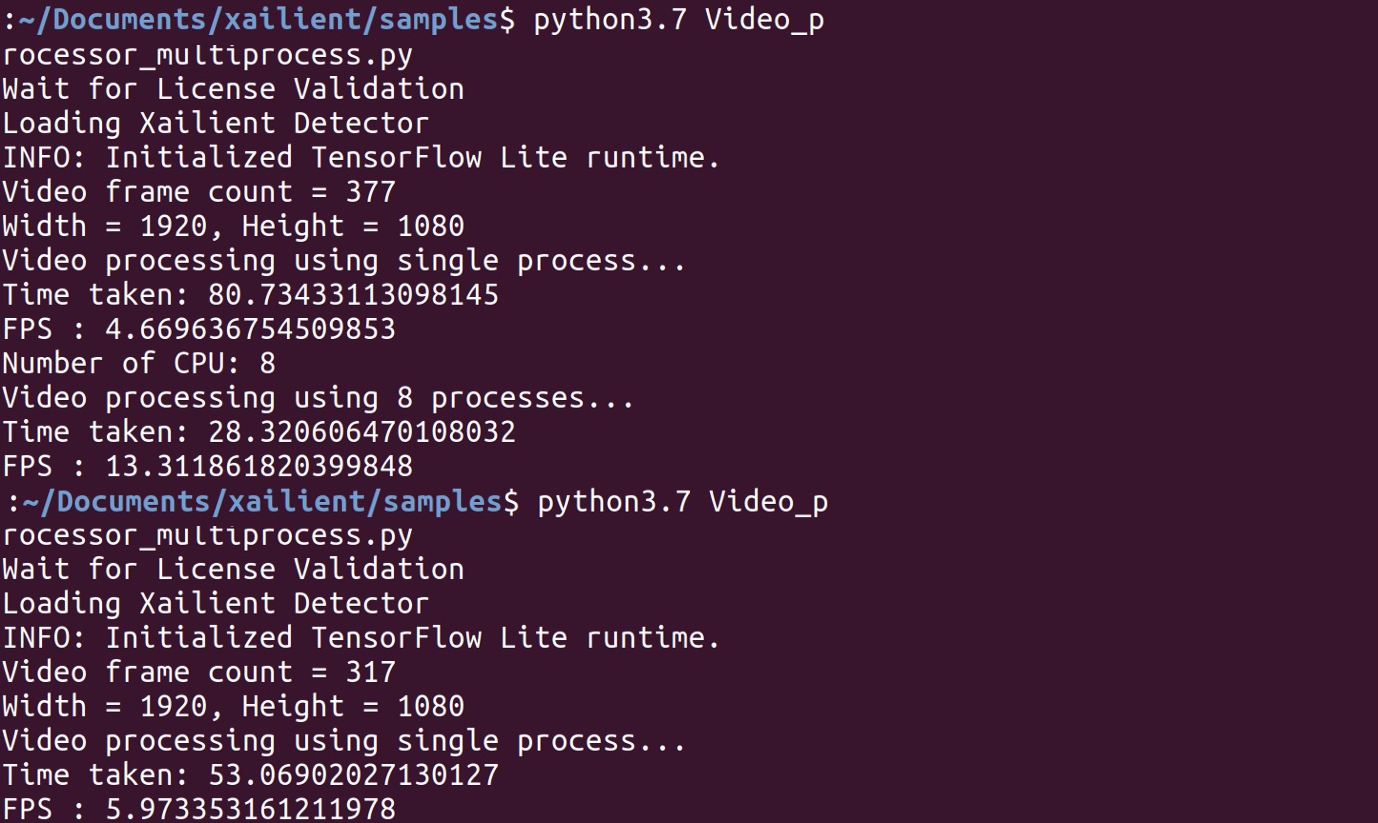
Из этого эксперимента
мы можем сделать вывод, что при использовании всех ядер обрабатывается в 2 раза
больше кадров в секунду. Чем больше процессоров на тестовой машине, тем больше можно реализовать процессов, и тем быстрее пройдет процесс обработки.
Комментарии