

Сможете ли вы ответить на все?
Вот еще 26 вопросов с собеседований по Data Science и ответов на эти вопросы (первые 26 можно найти здесь). Вопросы упорядочены по темам от математики и статистики к алгоритмам и далее к глубокому обучению и NLP, а вопросы по организации данных разбросаны между ними. Я рекомендую читать вопросы и пытаться ответить на них самостоятельно, прежде чем переходить к проверке своего ответа.
Будь вы студентом вуза или опытным профессионалом, любой может проверить (или освежить) свои навыки, потратив совсем немного времени.
Сможете ли вы правильно ответить на все вопросы? Поехали!
1). Какие формы ошибок выборки (selection bias) можно встретить в данных?
- Ошибка отбора (sampling bias)- систематическая ошибка, возникающая из-за неслучайного отбора участников выборки, что приводит к тому, что некоторые категории популяции встречаются в выборках реже, чем другие. Например, онлайн-опросы могут исключать бедные семьи или включать их реже, чем они реально встречаются.
- Ошибка временного интервала (time interval bias) - прерывание испытания при достижении желаемого результата или экстремального результата (обычно по этическим причинам). Ошибка в том, что преждевременное достижение результата характерно для переменных с высокой дисперсией, даже если среднее значение всех переменных одинаково.
- Ошибка выбора данных (data bias) – выбор подмножеств данных для доказательства или опровержения гипотез не соответствует предварительно объявленным или согласованным критериям.
- Наконец, ошибка выжившего (attrition bias) – ошибка, вызванная потерей значительной доли участников, поскольку те участники, которые не дошли до конца испытаний, не учитываются.
2). Определите Процент ошибок (Error Rate), Достоверность (Accuracy), Чувствительность/Полноту (Sensitivity/Recall), Специфичность (Specificity), Точность (Precision) и F-меру (F-Score)
Рассмотрим матрицу ошибок, где T – это истинный результат (True), F – ложный результат (False), P – позитивный результат (Positive), а N – негативный (Negative):
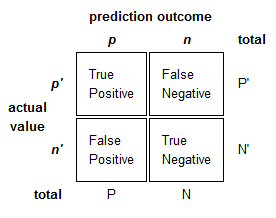
- Error Rate: (FP + FN) / (P + N). Это доля ошибочных предсказаний из всех.
- Accuracy: (TP + TN) / (P + N). Это доля истинных предсказаний из всех.
- Sensitivity/Recall: TP / P. Это доля истинно предсказанных позитивных.
- Specificity: TN / N. Это доля истинных предсказаний из негативных.
- Precision: TP / (TP + FP). Доля истинных позитивных из предсказанных позитивных.
- F-Score: гармоническое среднее между Precision и Recall.
3). Чем корреляция отличается от ковариации?
Корреляция считается лучшей техникой для измерения и количественной оценки соотношения между двумя переменными, и измеряет, насколько сильна зависимость между ними.
Ковариация измеряет степень, в которой две случайные переменные изменяются в цикле. Иначе говоря, она измеряет систематическую зависимость переменных друг от друга, при которой изменение одной переменной приводит к соответствующим изменениям второй.
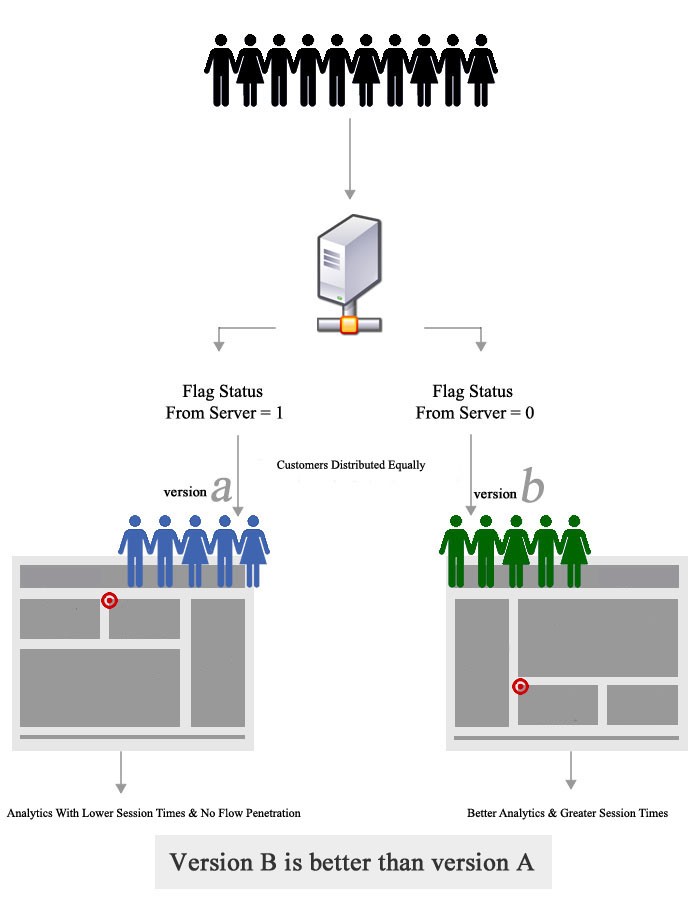
4). Почему A/B тестирование эффективно?
A/B тестирование – это тестирование гипотезы для рандомизированного эксперимента с двумя переменными A и B. Его цель – идентифицировать любые изменения, например, на web-странице, на которой клиенты из группы A получают приветствие «Добрый день», а клиенты из группы B – «Добро пожаловать». A/B тестирование эффективно, поскольку оно минимизирует сознательное предубеждение – люди из группы А не знают, что они из группы А, что существует группа B и наоборот. Это хороший способ получить данные о честной переменной. Однако A/B тестирование трудно проводить для любого контекста, кроме Интернет-бизнесов.
5). Как бы вы сгенерировали случайное число от 1 до 7, имея всего один шестигранный кубик?
Одно из решений – это бросить кубик два раза. При этом количество возможных комбинаций равно 6*6 = 36. Если исключить одну комбинацию (например, 6 и 6), останется 35 возможных комбинаций. Если мы назначим по 5 комбинаций (порядок имеет значение!) каждому из 7 возможных результатов, мы получим случайное число от 1 до 7.
Например, мы выбросили (1, 2). Поскольку мы, гипотетически, назначили комбинации бросков (1, 1), (1, 2), (1, 3), (1, 4) и (1, 5) результату 1, то наше случайно сгенерированное число будет равно 1.
6). В чем разница между унивариационным, бивариационным и мультивариационным анализом?
Унивариационный анализ – это методы статистического анализа, требующие только одной переменной. Он включает диаграммы, гистограммы и «ящики с усами» (boxplots).
Бивариационный анализ пытается понять соотношение между двумя переменными. Это может включать диаграммы рассеяния (scatter plot), контурные диаграммы и анализ временных рядов.
Мультивариационный анализ имеет дело с несколькими переменными, чтобы понять влияние этих переменных на целевую переменную. Он может включать обучение нейронных сетей для предсказаний или получение SHAP-графиков важности значений/комбинаций для нахождения самого важного признака. Он также может включать диаграммы рассеяния с третьим параметром в виде цвета или размера точек.
7). Что такое кросс-валидация? Какие проблемы она пытается решить? Почему она эффективна?
Кросс-валидация – это метод определения, насколько хорошо модель обобщается на весь набор данных. Традиционное разделение данных на тестовые и тренировочные, при котором часть данных случайно выбирается для обучения модели, а остальные данные – для тестирования, может привести к тому, что модель будет хорошо работать на одних случайно выбранных фрагментах тестовых данных и плохо работать на других фрагментах. Иными словами, метрики будут соответствовать не качеству модели, а случайному выбору тестовых данных.
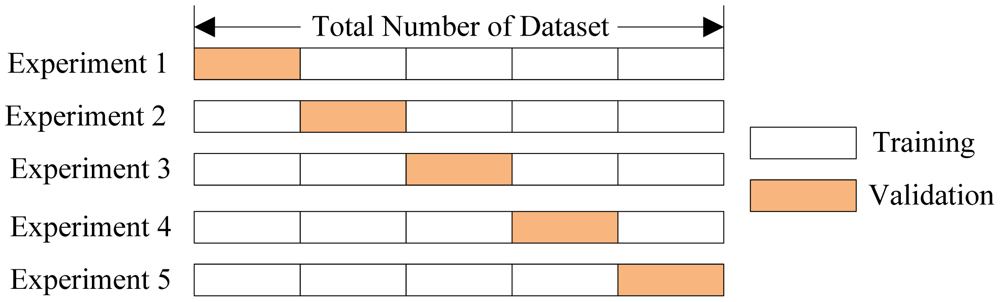
Кросс-валидация делит данные на n сегментов. Модель обучается на n-1 сегментах и тестируется на оставшемся сегменте. Затем модель заново инициализируется и обучается на другом наборе из n-1 сегментов. Этот процесс повторяется, пока модель не предскажет значения для всех данных (результаты предсказаний усредняются). Кросс-валидация полезна, поскольку она предоставляет более полное представление о качестве модели на всем наборе данных.
8). Что означает слово «наивный» в «Наивном Байесовском классификаторе»?
Наивный Байесовский алгоритм основан на теореме Байеса, которая описывает вероятность события, основываясь на предыдущем знании условий, которые могут иметь отношение к этому событию. Алгоритм считается «наивным», поскольку делает ряд предположений, которые могут быть или не быть верными. Вот почему этот алгоритм может быть очень мощным, если он используется правильно – он может пропустить поиск знания, которое другие алгоритмы должны искать, просто принимая на веру его истинность.
9). Какие ядра используются в SVM?
Есть четыре вида ядер SVM:
- Линейное ядро.
- Полиномиальное ядро.
- Ядро радиального базиса.
- Сигмоидное ядро.
10). Как справиться с переобучением Деревьев Решений?
Деревья Решений часто имеют высокое смещение (bias), поскольку суть алгоритма включает нахождение нишевых паттернов данных и создании новых узлов дерева специально для таких ниш. Если это не контролировать, дерево решений создаст такое огромное количество узлов, что будет отлично работать на тренировочных данных, но очень плохо на тестовых. Один из методов борьбы с переобучением деревьев решений называется подрезкой (pruning).
Обрезка – это метод сокращения деревьев решений посредством удаления тех секций дерева, которые мало помогают классификации. Это позволяет обобщить дерево решений и заставляет алгоритм создавать только узлы, важные для структуры данных, а не просто шум.
11. Объясните и дайте примеры коллаборативной фильтрации, фильтрации контента и гибридной фильтрации
Коллаборативная фильтрация – это форма рекомендательной системы, которая определяет то, что может понравиться пользователю, исключительно по его рейтингам. Все атрибуты товара изучаются посредством взаимодействия с пользователем или отбрасываются. Один из примеров коллаборативной фильтрации – это факторизация матриц.
Фильтрация контента – другая форма рекомендательной системы, выдающая рекомендации исключительно исходя из внутренних атрибутов товаров и клиентов, таких, как цена товара, возраст клиента и т.п. Один из способов добиться фильтрации контента – найти сходство между вектором профиля и вектором товара, например, косинусную меру сходства.
Гибридная фильтрация берет лучшее из обоих подходов, комбинируя коллаборативную фильтрацию и фильтрацию контента для получения лучших рекомендаций. Однако выбор метода фильтрации зависит от контекста из реального мира, и гибридная фильтрация не всегда будет лучшим методом.
12). В чем разница между bagging и boosting для ансамблей?
Bagging – это метод обучения ансамблей, при котором готовятся несколько поднаборов данных случайным выбором из всего набора данных (они могут перекрываться). После этого все модели обучаются на одном поднаборе, и их решения собираются вместе с помощью какой-либо функции.
Boosting – это итеративная техника, которая изменяет вес наблюдения в зависимости от последней классификации. Если наблюдение было классифицировано правильно, его вес увеличивается, и наоборот. Бустинг уменьшает ошибку смещения и строит сильные предсказательные модели.
13). В чем разница между жестким и мягким голосованием в ансамблях?
При жестком голосовании финальная классификация каждой модели ансамбля (например, 0 или 1) аггрегируется – возможно, с помощью среднего значения или моды.
Мягкое голосование – это когда аггрегируются итоговые вероятности (например, 85% вероятность классификации 1), обычно с помощью среднего значения.
Мягкое голосование может в некоторых случаях принести преимущества, но может привести к переобучению и недостаточному обобщению модели.

14). В вашем компьютере 5Гб ОЗУ, а вам нужно обучить модель на 10-гигабайтовом наборе данных. Как вы это сделаете?
Для SVM может сработать частичное обучение. Набор данных можно разбить на несколько наборов меньшего размера. Поскольку SVM – это алгоритм с низкими вычислительными требованиями, в данном сценарии это может быть лучшим выбором.
Если данные не подходят для SVM, можно обучить нейронную сеть с достаточно малым размером пакета (batch size) на сжатом массиве NumPy. В NumPy есть несколько инструментов для сжатия больших наборов данных, которые интегрированы в широко распространенные пакеты нейронных сетей вроде Keras/Tensorflow и PyTorch.
15). Теория глубокого обучения известна довольно давно, но лишь недавно получила большую популярность. Как вы думаете, почему глубокое обучение так поднялось за последние годы?
Глубокое обучение растет очень быстро, поскольку лишь недавно оно стало необходимым. Недавно усовершенствованные методы сдвига от физических экспериментов к онлайновым означают, что можно собрать намного больше данных. Вследствие перехода покупок в онлайн глубокое обучение получило больше возможностей повысить доход и вероятность возврата покупателей, чем, допустим, в физических бакалейных лавках. Стоит отметить, что две крупнейших модели машинного обучения на PyTorch (Tensorflow и PyTorch) были созданы крупными корпоративными компаниями Google и Facebook. Кроме того, развитие GPU позволило обучать модели быстрее.
(Хотя этот вопрос и не связан напрямую с теорией, способность ответить на него означает, что вы следите за картиной в целом и имеете представление о том, как ваш анализ может быть полезен с корпоративной точки зрения)
16). Как бы вы инициализировали веса нейронной сети?
Самый широко встречающийся метод – инициализировать веса случайно, близкими к нулю значениями. Затем правильно выбранный оптимизатор может сдвинуть веса в нужном направлении. Если пространство ошибок слишком крутое, оптимизатору может быть сложно избежать локального минимума. В этом случае может быть хорошей идеей инициализировать несколько нейронных сетей в различных локациях пространства ошибок, чтобы повысить шанс нахождения глобального минимума хотя бы одной из моделей.
17). Каковы последствия установки неправильной скорости обучения?
Если скорость обучения слишком мала, обучение модели будет слишком медленным, поскольку веса будут изменяться ненамного. Однако, если скорость обучения слишком велика, это может привести к тому, что функция потерь будет беспорядочно прыгать вследствие сильных изменений весов. Модель может не сойтись в какой-то одной точке или даже отклониться от минимума, если данные слишком хаотичны для обучения нейронной сети.
18). Объясните разницу между эпохой, пакетом (batch) и итерацией.
- Эпоха – один проход по всему набору данных, предназначенному для обучения.
- Пакет. Поскольку передача сразу всего набора данных в нейронную сеть требует слишком много вычислительной мощности, набор данных делится на пакеты.
- Итерация – количество запусков пакетов в каждой эпохе. Если у нас 50.000 строк данных, а размер пакета составляет 1000 строк, в каждой эпохе будет запущено 50 итераций.
19). Какие три основных вида слоев обычно используются в сверточных нейронных сетях? Как они обычно сочетаются?
Три основных вида слоев, используемых в сверточных нейронных сетях – это:
- Сверточный слой: слой, выполняющий операцию свертки, которая создает несколько окон-картинок, обобщая изображение.
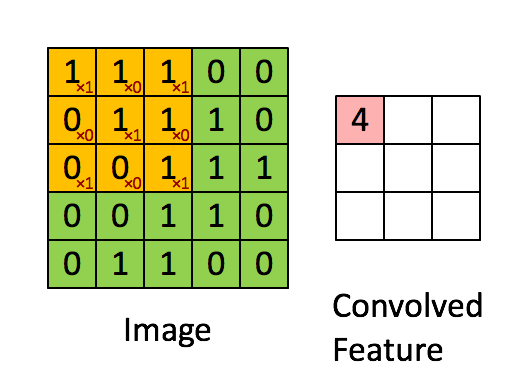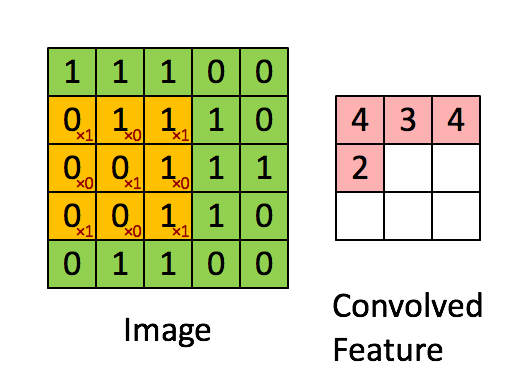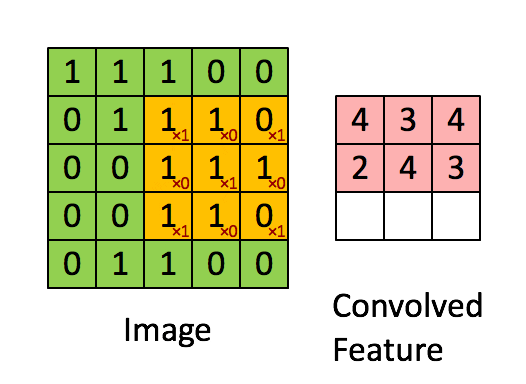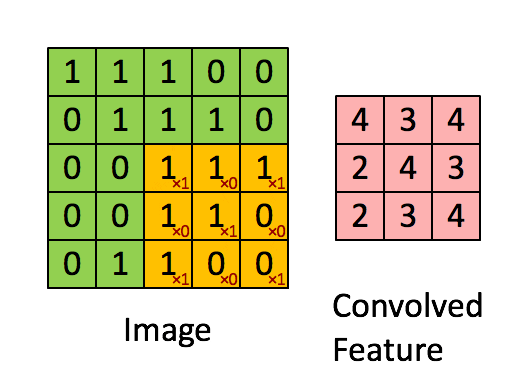
- Слой активации (обычно ReLU): привносит в сеть нелинейность и приводит все негативные пиксели к нулю. Вывод превращается в исправленную карту признаков.
- Слой группировки (pooling): операция сокращения, которая сокращает размерность карты признаков.
Сверточная нейронная сеть обычно состоит из нескольких последовательностей сверточного, активационного и группирующего слоев. За всем этим могут следовать один или два полносвязных слоя или слоя исключения (dropout) для дальнейшего обобщения, и последним идет полносвязный слой.
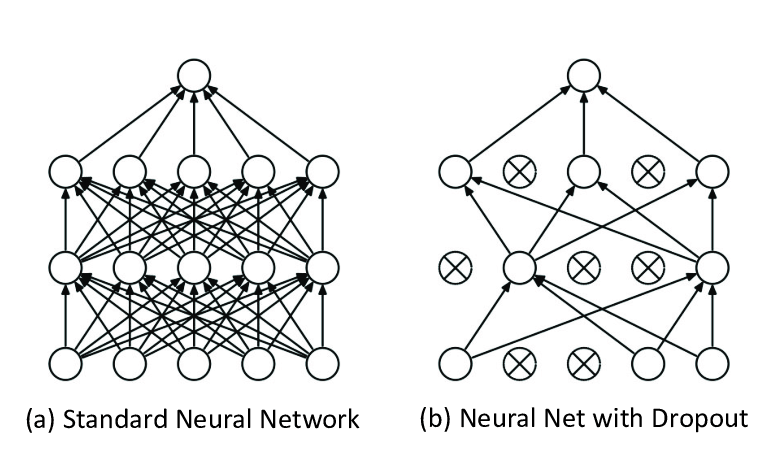
20). Что такое слой исключения (dropout), и чем он может помочь?
Слой исключения сокращает переобучение нейронной сети, предотвращая комплексную со-адаптацию к тренировочным данным. Слой исключения служит маской, случайным образом предотвращая связи с некоторыми узлами. Иными словами, в процессе обучения примерно половина нейронов слоя исключения будет деактивирована, что заставляет нейроны нести больше информации, чем оставалось после деактивированных нейронов. Иногда слои исключения используются после слоев максимальной группировки (max-pooling).
21). Если говорить упрощенно и на фундаментальном уровне, что делает недавно разработанный BERT лучше, чем традиционные модели NLP?
Традиционные модели NLP, чтобы познакомиться с текстом, получают задачу предсказания следующего слова в предложении (например, слово "dogs" в предложении "It's raining cats and ___"). Другие модели могут дополнительно обучаться предсказывать предыдущее слово в предложении по контексту после него. BERT случайным образом маскирует слово в предложении и заставляет модель предсказывать это слово, исходя из контекста до и после него – например, слово "raining" в предложении "It's _____ cats and dogs".

Это значит, что BERT может усвоить более сложные зависимости между словами, которые нельзя предсказать только по предыдущему (или только по следующему) контексту. Конечно, BERT имеет множество других улучшений, таких, как различные слои кодирования, но на фундаментальном уровне его успех обусловлен способом чтения текста.
22). Что такое «Распознавание Именованных Сущностей» (Named Entity Recognition, NER)?
NER, также известная как идентификация сущностей, выделение сущностей или извлечение сущностей – это подзадача извлечения информации, направленная на нахождение и классификацию именованных сущностей в неструктурированном тексте по категориям – таким, как имена, организации, локации, суммы денег, время и т.д. NER пытается разделить слова, которые пишутся одинаково, но означают разные вещи, и корректно идентифицировать сущности, содержащие под-сущности, например, "America" и "Bank of America".
23). Вам дали большой набор данных твитов, и ваша задача – предсказать их тональность (положительная или отрицательная). Объясните, как бы вы проводили предварительную обработку данных.
Поскольку твиты наполнены хэштегами, которые могут представлять важную информацию, и, возможно, создать набор признаков, закодированных унитарным кодом (one-hot encoding), в котором '1' будет означать наличие хэштега, а '0' – его отсутствие. То же самое можно сделать с символами '@' (может быть важно, какому аккаунту адресован твит). В твитах особенно часто встречаются сокращения (поскольку есть лимит количества символов), так что в текстах наверняка будет много намеренно неправильно записанных слов, которые придется восстанавливать. Возможно, само количество неправильно написанных слов также представляет полезную информацию: разозленные люди обычно пишут больше неправильных слов.
Удаление пунктуации, хоть оно и является стандартным для NLP, в данном случае можно пропустить, поскольку восклицательные знаки, вопросы, точки и пр. могут нести важную информацию, в сочетании с текстом, в котором они применяются. Можно создать три или большее количество столбцов, в которых будет указано количество восклицательных знаков, вопросительных знаков и точек. Однако перед передачей данных в модель пунктуацию следует убрать из текста.
Затем нужно провести лемматизацию и токенизацию текста. В модель следует передать не только чистый текст, но и информацию о хэштегах, '@', неправильно написанных словах и пунктуации. Все это, вероятно, повысит точность предсказаний.
24). Как можно определить сходство двух абзацев текста?
Первый шаг – это перевести абзацы в числовую форму с помощью векторизатора – например, "мешка слов" (bag of words) или TF/IDF. В данном случае "мешок слов" может быть лучше, поскольку набор текстов совсем невелик. Кроме того, он может дать лучшее представление о тексте, ведь TF/IDF предназначен преимущественно для моделей.
После этого для измерения сходства между двумя векторами можно использовать косинусную меру или Евклидово расстояние между ними.
25). В наборе из N документов один случайный документ содержит T терминов. Термин 'hello' встречается в этом документе K раз. Чему равно произведение TF (Term Frequency) и IDF (Inverted Document Frequency), если термин 'hello' встречается примерно в трети всех документов?
Формула для Term Frequency = K/T, а формула для IDF – это логарифм отношения количества всех документов к количеству документов, содержащих термин (то есть, log(1/(1/3)) = log(3). Поэтому значение TF/IDF для слова 'hello' будет равно K * log(3) / T.
26). Существует ли универсальный набор стоп-слов? В каких случаях вы бы расширили набор стоп-слов, и в каких, наоборот, уменьшили его?
В библиотеке NLTK на Python'е задан общепринятый набор стоп-слов (для английского языка), но в некоторых случаях список стоп-слов нужно расширить или сократить, в зависимости от контекста. Например, для твитов набор стоп-слов придется сократить, поскольку у нас не так много текста. Следовательно, важная информация может быть выражена небольшим количеством символов, и удаление того, что мы посчитаем стоп-словами, может привести к потере этой информации.
С другой стороны, если мы имеем дело с тысячей коротких рассказов, мы можем захотеть удалять больше стоп-слов, не только для экономии машинного времени, но и для упрощения нахождения разницы между этими рассказами, каждый из которых, вероятно, будет содержать множество стоп-слов.
На сколько вопросов вам удалось ответить правильно? Эти вопросы касаются статистики, алгоритмов, глубокого обучения, NLP, организации и понимания данных – так что они должны послужить хорошим показателем вашего знакомства с концепциями Data Science.
Если вы еще не сделали этого, проверьте себя на первых 26 вопросах с собеседований.
Комментарии