

Пять самых интересных проектов машинного и глубокого обучения
Включая техническое описание каждого
Время от времени я читаю научные статьи по ML/AI/DL, просто чтобы следить за происходящим в индустрии. Мне кажется, было бы здорово собрать самые интересные идеи в одну статью, добавить несколько ключевых теоретических концепций и поделиться всем этим с вами. Итак, вот несколько исследовательских проектов, которые нравятся лично мне, и, надеюсь, понравятся вам.
1. Toonify Yourself (Сделай из себя мультяшку)

Авторы: Дорон Адлер (Doron Adler) и Джастин Пинкни (Justin Pinkney)
Начнем с чего-нибудь не очень серьезного: этот забавный маленький проект позволяет вам загрузить свое изображение и преобразовать его в мультяшное. Обработка и преобразование изображений в наше время не представляют собой ничего особенно нового, но проект остается очень интересным: сайт даже предоставит вам файл Google Colab, позволяющий превратить себя в мультяшку и пройти этот процесс по шагам, чтобы вы могли воссоздать его самостоятельно.
Несколько ключевых идей и концепций:
Это – проект сетевого осветления/перемены местами слоев (network blending/layer swapping) в StyleGAN, и авторы использовали предварительно обученные модели для передачи обучения (transfer learning). Точнее, они использовали две модели: базовую и созданную на ее основе полностью обученную модель. Чтобы получить такой результат, они меняли слои между двумя моделями. Слои высокого разрешения берутся из базовой модели, а слои низкого разрешения – из полностью обученной. Потом из исходного изображения, которое мы хотим превратить в мультик, выводится скрытый вектор (latent vector): он используется в качестве входа для модели сетевого осветления. Этот скрытый вектор очень похож на исходное изображение, а после его ввода в модель сетевого осветления на выходе создается мультяшное изображение.
Более подробно об этом можно прочитать здесь.
2. Lamphone (Лампофон)

Авторы: Бен Насси, Ярон Пирутин, Ади Шамир, Ювал Еловичи и Борис Задов.
Этот проект немного пугает: Lamphone позволяет наблюдателю восстановить речь и иную информацию, воссоздавая звук из записанных электро-оптическим сенсором вибраций электрической лампы.
Несколько ключевых идей/концепций:
Установка системы включает подзорную трубу со встроенным электро-оптическим сенсором, способным распознавать шаблоны вибрации электрической лампы в комнате жертвы. Точнее, авторы использовали колебания воздушного давления возле лампы (которые и заставляют ее вибрировать). В этом эксперименте авторы сумели успешно определить, какая песня играла в комнате, и кусок записанной речи Трампа с расстояния в 25 метров, используя электро-оптический сенсор за $400. Они утверждают, что дистанция может быть увеличена, если использовать более совершенное оборудование.
Более подробно об этом можно прочитать здесь.
3. GANPaint Studio (Студия авторисования)

Авторы: Дэвид Бау, Хендрик Штробельт, Уильям Пиблс, Джонас Вульфф, Болей Жоу, Юн-Ян Жу, Антонио Торральба.
Именно этот проект особенно взволновал меня. Это – инструмент, позволяющий вам "растворить" объект изображения в выделенной части исходного изображения (вы также решаете, где будет подсветка). Мне всегда нравилась идея о том, что не умеющие рисовать люди все-таки смогут легко создавать новые изображения. Мне кажется, создание новых картин и изображений – истинно творческий процесс, и, возможно, в будущем машина сыграет роль помощника, который стимулирует множество людей попробовать свои способности в искусстве. В данном случае, хотя этот конкретный инструмент и не предназначен для создания предметов искусства, до появления таких инструментов осталось недолго.
Несколько ключевых идей/концепций:
Интересный факт об этом проекте: он синтезирует новый контент, соответствующий как намерениям пользователя, так и статистике исходного изображения. Конвейер по обработке изображений включает трехшаговый процесс: вычисление скрытого вектора исходного изображения, применение операции семантического векторного пространства в скрытом пространстве и, наконец, восстановление изображения из модифицированного на предыдущем шаге. Вот что написали авторы в исходном документе:
Взяв естественную фотографию на входе, мы сначала перерисовываем картинку, используя генератор изображений. Конкретнее, для точного восстановления входного изображения наш метод не только оптимизирует скрытое представление, но также адаптирует генератор. Затем пользователь манипулирует изображением с помощью интерактивного интерфейса: например, добавляя или удаляя определенные объекты, либо меняя их внешний вид. Наш метод обновляет скрытое представление в соответствии с каждым редактированием, и отрисовывает итоговый результат, исходя из измененного представления. Наши результаты выглядят реалистично и визуально похожи на исходную естественную фотографию.
Более подробно об этом можно прочитать здесь.
4. Jukebox (Музыкальный автомат)

Авторы: Прафулла Дхаривал, Хивуу Юн, Кристина Мак-Ливи Пэйн (ВНЕСЛИ РАВНЫЙ ВКЛАД), Йонг Вук Ким, Алек Рэдфорд, Илья Суцкевер.
Если кратко, этот проект использует нейронные сети для генерации музыки. Для заданных на входе жанра, музыканта и текста песни, Jukebox выдаст созданный образчик музыки.
Автоматическая генерация музыки – не такая уж новая технология. Предыдущие подходы включали символическую генерацию музыки. Однако те генераторы зачастую не могли уловить ключевые музыкальные элементы, вроде человеческих голосов, деталей тембра, динамики и выразительности. Прослушав несколько выложенных на странице "Jukebox Sample Explorer" музыкальных треков, можно убедиться — они еще не дошли до уровня, когда слушатель не сможет отличить оригинальный трек от сгенерированного. Однако я считаю несомненно волнующим наблюдать за тем, к чему могут привести проекты вроде этого, и какое влияние они окажут на нашу музыкальную индустрию в ближайшее время.
Несколько ключевых идей/концепций:
Авторы использовали двухшаговый процесс – первый шаг состоит из сжатия музыки в дискретные коды, а второй включает генерацию кодов с помощью трансформеров. У них есть очень красивые диаграммы, поясняющие этот процесс, которые я приведу здесь:
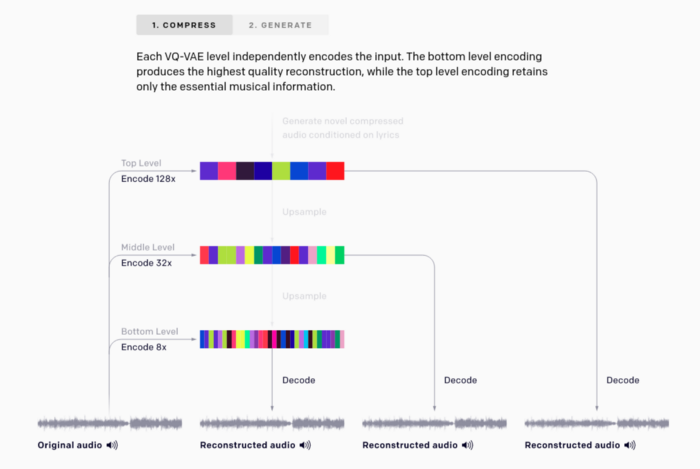
На шаге сжатия авторы используют модифицированную версию Векторного Квантованного Вариационного Автокодировщика (Vector Quantized-Variational AutoEncoder, VQ-VAE-2) и генеративную модель дискретного обучения представлениям. Согласно рисунку А, исходное аудио с частотой 44 кГц сжимается в 8, 32 и 128 раз с использованием кодовой таблицы размером 2048 на каждом уровне. Если пойти на сайт и попробовать нажать каждую пиктограмму, чтобы услышать звучание восстановленного изображения, правая пиктограмма выдаст максимальный уровень шума, поскольку она соответствует сжатию в 128 раз, и в аудио остались только самые значимые особенности (ритм, тембр и уровень громкости).
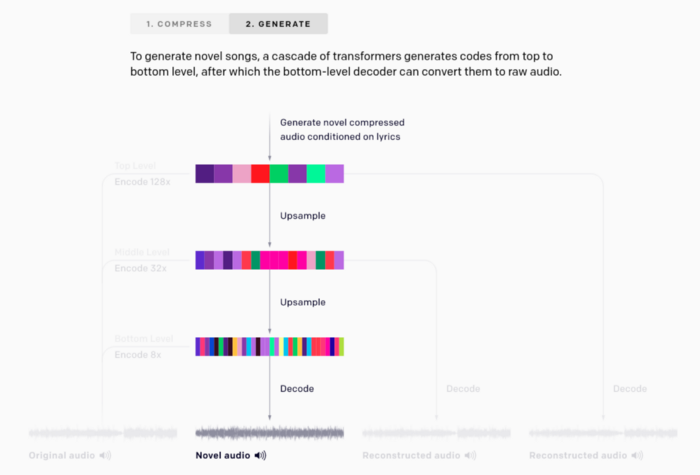
На шаге генерации, как упомянуто в документе по VQ-VAE и документе по VQ-VAE-2, используется мощный авторегрессионный декодер, но в алгоритме Jukebox и отдельные декодеры — входные коды на каждом уровне восстанавливаются независимо, чтобы максимизировать использование верхних. Эта фаза генерации (согласно официальному сайту) состоит в:
(обучении) предыдущих моделей, цель которых заключается в изучении распределения музыкальных кодов, закодированных VQ-VAE, и генерации музыки в этом сжатом дискретном пространстве. [...] Предыдущие модели верхнего уровня моделируют долговременную структуру музыки, и сэмплы, декодированные на этом уровне, имеют худшее качество аудио, но улавливают высокоуровневую семантику вроде пения или музыки. Средняя и нижняя модели повышающей дискретизации добавляют локальные музыкальные структуры вроде тембра, существенно повышая качество аудио [...] Когда все предыдущие модели обучены, мы можем генерировать коды, начиная с верхнего уровня и последовательно повышая дискретизацию с помощью соответствующих моделей. Можно декодировать эти коды обратно в пространство необработанной музыки с помощью VQ-VAE декодера, чтобы получить новые песни.
Более подробно прочитать об этом, а также попробовать демо можно здесь.
5. Engaging Image Captioning via Personality (Вовлекающее именование изображений с помощью личности)

Авторы: Курт Шустер, Самуэль Химео, Хексианг Ху, Антуан Борде, Джейсон Уэстон.
По традиции, задачи именования изображений лишены каких-либо эмоций и описывают только факты (например, метки вроде «Это кот» или «Мальчик играет в футбол с друзьями»). Авторы этого проекта пытаются внести в заголовки эмоции или личные оценки, чтобы сделать их более личными и привлекающими больше внимания. Цитируя их документ, «наша цель – быть настолько же вовлекающими, как живые люди, встраивая управляемый стиль и личные особенности».
Надеюсь, этот проект будет использован только для добрых целей – идея общающихся между собой как люди машинах или ботах меня немного пугает. Тем не менее, это достаточно интересный проект.
Несколько ключевых идей/концепций:
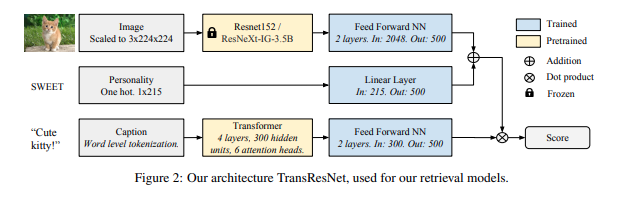
Цитата из документа авторов проекта:
Для представления изображений, мы использовали работу [32] (D. Mahajan, R. B. Girshick, V. Ramanathan, K. He, M. Paluri, Y. Li, A. Bharambe, and L. van der Maaten. Исследование пределов предварительного обучения со слабым привлечением учителя. CoRR, abs/1805.00932, 2018.), которая использует обученную на 3.5 миллиардах изображений из социальных сетей архитектуру ResNeXt. Для текста мы используем трансформерное представление предложений, [36] (P.-E. Mazare, S. Humeau, M. Raison, and A. Bordes. Обучение миллионов персонализированных диалоговых агентов. ArXiv e-prints, Sept. 2018.), обученное на 1.7 миллиардах примеров диалогов. Наша модель устанавливает новый стандарт генерации заголовков COCO, а наша архитектура TransResNet достигла рекордного рейтинга R@1 на наборе данных Flickr30k.
Более подробно об этом можно прочитать здесь.
Бонус. Я приведу ссылки еще на три интересных проекта:
- Искусственный интеллект скопирует ваш голос, прослушав его на протяжении 5 секунд: ссылка.
- Искусственный интеллект, создающий реалистичные сцены из ваших фотографий: ссылка.
- Восстановление старых изображений: ссылка.
Финальные заметки
Читая имеющие отношение к глубокому обучению документы, поневоле начинаешь беспокоиться, насколько легко технологии могут быть использованы во вред или причинить пагубные последствия всему современному обществу. Несмотря на то, что некоторые из них кажутся безвредными, промежуток между невинным игрушечным проектом и мощным инструментом манипуляции чрезвычайно узок. Я очень надеюсь, что появится какая-то концепция или система стандартов, чтобы мы получили контролируемых помощников, а не выпустили на волю монстра.
Спасибо за внимание!
Какие проекты из области AI интересны лично вам и почему?