
Хотите стать мастером в Python? Тогда изучайте язык на практике. В этом материале рассказываем, как создать словарь на Python.
Интернет, с одной стороны, открывает доступ к большому объёму информации, но с другой, тормозит развитие. Согласитесь, изучая что-то новое, допустим, язык программирования Python, поиск ценных ресурсов занимает много сил и времени.
Из-за этого новички часто сдаются, переходят к чему-то более простому. Прежде чем мы пойдём дальше, нужно понять, что это не очередная статья из разряда «Как научиться программированию на Python с нуля», а нечто более ценное. За этим материалом последует ещё несколько, в каждом из которых мы покажем, как создаются Python-приложения, параллельно разбираясь с полезными для разработки и анализа данных навыками и инструментами.

Первое приложение, которое мы сделаем − интерактивный словарь на Python. Кажется, что это просто, но не заблуждайтесь.
Что будет делать наш словарь на Python? Его задача состоит в том, чтобы выводить на экран определение слова, которое задаст пользователь. В дополнение к этому, если пользователь сделает опечатку при вводе слова, программа предложит наиболее близкое слово, как обычно делает Google − «Вы имели в виду это вместо этого?». Ну а если у слова будет несколько определений, то программа выдаст все. Уже не так просто, правда?

Важно! Помимо изучения процесса создания приложения, обратите особое внимание на структуру кода.
Шаг №1 − Данные
Чтобы понимать принцип работы словаря, нужно определить, какие данные он будет использовать для выполнения действий − они представлены в формате JSON. Если вы уже знаете, что такое JSON, не бойтесь пропустить следующие несколько строк. Если же вы впервые услышали это слово или не уверены в своих знаниях, сейчас всё быстро объясним. Рекомендуем взглянуть вот на эти данные, потом мы их и будем использовать − раз и два.
Интересный факт: Каждую секунду генерируется примерно 2 500 000 000 000 000 000 байт данных
JSON, или JavaScript Object Notation, − это формат обмена данными, удобный как компьютерам, так и людям. Обычно он состоит из двух вещей − key и value. Представим, что key − это заброшенная территория, некто вынес постановление о том, что его нельзя использовать для строительства, например, вот это постановление примем за value. Если хотите вникнуть более серьёзно, посмотрите этот материал.
"заброшенный промышленный участок": ["Площадка не может быть использована для строительства".]
Теперь перейдём к коду. Сначала мы импортируем библиотеку JSON, а затем используем метод загрузки этой библиотеки для работы с нашими данными в формате .json. Важно понимать, что мы загружаем данные из .json формата, но храниться они будут в переменной "data" в виде dict — словаря Python. Если вы незнакомы с dict, можете представить их как хранилище данных.
import json
data = json.load(open("data.json"))
def retrive_definition(word):
return data[word]
word_user = input("Enter a word: ")
print(retrive_definition(word_user))
Как только данные будут загружены, создадим функцию, которая будет принимать слово и искать определение этого слова в данных. Достаточно просто.

Шаг №2 − Проверка на существование слова
Использование оператора if-else поможет вам проверить существует слово или нет. Если слово отсутствует в данных, просто сообщите об этом пользователю − в нашем случае, будет напечатано «Такого слова не существует, пожалуйста, проверьте, не ошиблись ли вы при вводе».
import json
data = json.load(open("dictionary.json"))
def retrive_definition(word):
if word in data:
return data[word]
else:
return ("The word doesn't exist, please double check it.")
word_user = input("Enter a word: ")
print(retrive_definition(word_user))

Шаг №3 - Учёт регистра
Каждый пользователь пишет по-своему. Одни пишут только строчными, другие используют ещё и заглавные. Для нас важно сделать так, чтобы результат для всех был одинаковым. Например, результаты по запросам «Rain» и «rain» будут идентичны. Чтобы сделать это, мы собираемся преобразовать слово, введенное пользователем, в строчную запись буквы, потому что наши данные имеют одинаковый формат. Сделать это можно с помощью метода lower() в Python.
Ситуация №1: Чтобы убедиться, что программа возвращает определение слов, начинающихся с заглавной буквы (например, Дели, Техас), мы также проверим наличие заглавных букв в условии else-if.
Ситуация №2: Чтобы убедиться, что программа возвращает определение аббревиатур (например, США, НАТО), мы также проверим прописные буквы.
import json
data = json.load(open("dictionary.json"))
def retrive_definition(word):
word = word.lower()
if word in data:
return data[word]
elif word.title() in data:
return data[word.title()]
elif word.upper() in data:
return data[word.upper()]
word_user = input("Enter a word: ")
print(retrive_definition(word_user))

Теперь словарь на Python может выполнять свою основную функцию − выдавать определение. Идём дальше, поможем пользователю найти слово, если он допустил ошибку при вводе.
Шаг №4 − Поиск близкого слова
Теперь, если пользователь сделал опечатку при вводе слова, вы можете предложить наиболее близкое слово и спросить, имел ли он его в виду. Мы можем сделать это с помощью библиотеки Python difflib. Для этого существует два метода, объясним, как работают оба, а чем пользоваться, выбирайте сами.
Метод 1 − Соответствие последовательности
Сначала мы импортируем библиотеку и извлекаем из нее метод. Функция SequenceMatcher() принимает всего 3 параметра. Первый − junk, что означает, что если в слове есть пробелы или пустые строки, в нашем случае это не так. Второй и третий параметры − это слова, между которыми вы хотите найти сходство. А последний метод выдаст вероятность того, что слово подобрано правильно.
import json
import difflib
from difflib import SequenceMatcher
data = json.load(open("dictionary.json"))
value = SequenceMatcher(None, "rainn", "rain").ratio()
print(value)

Как видите, сходство между словами «rainn» и «rain» составляет 0,89 или 89%. Это один из способов найти нужное слово. Но в той же библиотеке есть другой метод, который выбирает точное совпадение со словом напрямую, без определения вероятности.
Метод 2 − Получение близких совпадений
Метод работает следующим образом: первый параметр − это слово, для которого вы хотите найти близкие совпадения. Второй параметр − это список слов для сравнения. Третий указывает, сколько совпадений вы хотите в качестве вывода. Вы помните, что мы получили вероятность 0,89 в предыдущем методе? Последний метод использует это число, чтобы узнать, когда прекратить рассматривать слово как близкое совпадение (0,99 - самое близкое к слову). Эту цифру, порог, можно установить самостоятельно.
import json
import difflib
from difflib import get_close_matches
data = json.load(open("dictionary.json"))
output = get_close_matches("rain", ["help","mate","rainy"], n=1, cutoff = 0.75)
print(output)

Самое близкое слово из всех трех − rainy [rainy].
Шаг №5 - Возможно, вы имели в виду это?
Для удобства чтения я просто добавил часть кода if-else. Вы знакомы с первыми двумя утверждениями else-if, теперь разберемся с третьим. Сначала проверяется длина полученных близких совпадений. Функция получения близких совпадений принимает слово, введенное пользователем, в качестве первого параметра, и весь наш набор данных сопоставляется с этим словом. Здесь key − это слова в наших данных, а value − это их определение. [0] в операторе указывает на самое близкое среди всех совпадений.
if word in data:
return data[word]
elif word.title() in data:
return data[word.title()]
elif word.upper() in data:
return data[word.upper()]
elif len(get_close_matches(word, data.keys())) > 0:
return ("Did you mean %s instead?" % get_close_matches(word, data.keys())[0])

Да, об этом мы и говорили. Что теперь? Если это то слово, которое имел в виду пользователь, вы должны получить определение этого слова. Об этом далее
Шаг №6 − Получение определения
Ещё один if-else, и вот оно − определение нужного слова.
elif len(get_close_matches(word, data.keys())) > 0:
action = input("Did you mean %s instead? [y or n]: " % get_close_matches(word, data.keys())[0])
if (action == "y"):
return data[get_close_matches(word, data.keys())[0]]
elif (action == "n"):
return ("The word doesn't exist, yet.")
else:
return ("We don't understand your entry. Apologies.")

Шаг №7 − Вишенка на торте
Конечно, это дает нам определение слова «rain», но есть квадратные скобки и выглядит это не очень хорошо. Давайте удалим их и сделаем вид более чистым. Слово «rain» имеет более одного определения, вы заметили? Мы будем повторять вывод таких слов, имеющих более одного определения.
output = retrive_definition(word_user)
if type(output) == list:
for item in output:
print("-",item)
else:
print("-",output)
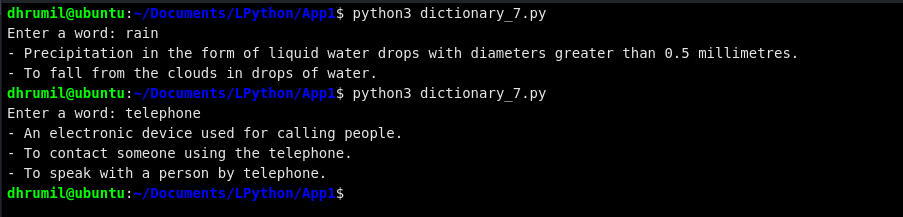
Выглядит намного лучше, не так ли? Ниже прикрепили весь код для справки. Не стесняйтесь изменять и обновлять его по своему усмотрению.
Итого
import json
from difflib import get_close_matches
data = json.load(open("data.json"))
def retrive_definition(word):
word = word.lower()
if word in data:
return data[word]
elif word.title() in data:
return data[word.title()]
elif word.upper() in data:
return data[word.upper()]
elif len(get_close_matches(word, data.keys())) > 0:
action = input("Did you mean %s instead? [y or n]: " % get_close_matches(word, data.keys())[0])
if (action == "y"):
return data[get_close_matches(word, data.keys())[0]]
elif (action == "n"):
return ("The word doesn't exist, yet.")
else:
return ("We don't understand your entry. Apologies.")
word_user = input("Enter a word: ")
output = retrive_definition(word_user)
if type(output) == list:
for item in output:
print("-",item)
else:
print("-",output)
Заключение
Вот мы и закончили создавать словарь на Python. Изучая одно, вы параллельно изучаете другие вещи, о которых даже не думали. Этот материал научил работе с данными JSON, основными функциями Python, библиотекой difflib и тому, как писать чистый код. Теперь попробуйте создать собственное приложение, с опорой на информацию из этого текста. Как закончите, переходите к новому материалу из цикла.
Комментарии