
Знакомьтесь, регулярные выражения! Из статьи вы почерпнёте основные идеи, распространённые шаблоны и функции с примерами.
Регулярные выражения – мощный инструмент таких языков, как Python, R, Java, JavaScript, PHP, Scala и не только.
Уверенное понимание регулярок поможет разработчику производить операции с данными и текстом. Например, в обработке естественного языка.

Не бойтесь этих кракозябр: регулярные выражения принесут вам пользу, как только вы начнёте понимать и применять их.
Что такое регулярные выражения?
Регулярное выражение – это текстовая строка, которая определяет шаблон поиска:
"\w+"
Подобные шаблоны используются для четырёх главных задач:
- Найти текст в большом объёме текстовых данных.
- Проверить строку на совпадения с желаемым форматом.
- Заменить и вставить текст.
- Разделить строки.
Посмотрим на основные шаблоны регулярок.
Основные шаблоны
Вернёмся к примеру:
\w+
Здесь «w» означает слово (от англ. word). «+» означает «ещё одно». Эта регулярка сравнивает символы слов, включая ASCII, цифры и нижнее подчеркивание. Предположим, что нам нужно сравнить первое слово в строке. Сначала импортируем модуль re:
import re
Затем мы определяем шаблон и юзаем функцию re.match() для определения первого слова:
word_regex = '\w+' re.match(word_regex, 'hello world!') # это будет сопоставляться с первым словом в поиске >>><re.Match object; span=(0, 2), match='hi'>
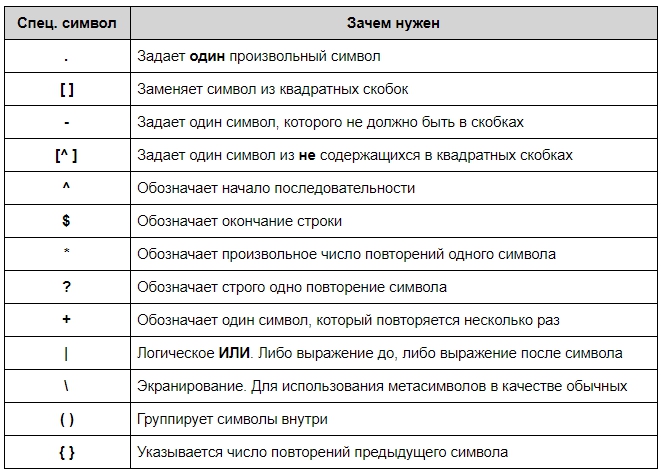
Вот основные символы, которыми вы будете оперировать:
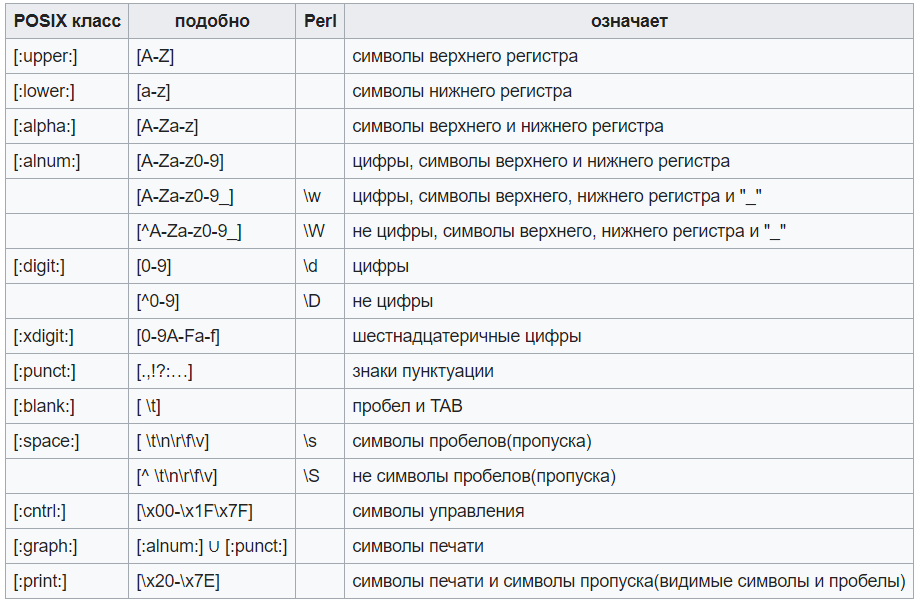
Некоторые распространённые шаблоны:
Что с этим делать? Всё просто! Например, вы можете использовать такие паттерны для проверки вводимых значений в input-поля:
- Full name –
^[A-Z]{1}[A-Za-z 0-9-]{1,12}$ - email –
[\w-]+@([\w-]+\.)+[\w-]+ - Телефон (с буквами, как принято во многих странах) –
^[+]*[(]{0,1}[0-9]{1,4}[)]{0,1}[-\s\./0-9]*[a-z]*$
Теперь у вас есть немного готовых регулярных выражений. Время двигаться к важным функциям.
Функция match()
Эта функция сопоставляет шаблон со строкой. Она возвращает объект match при успехе и None – в случае неудачи:
re.match('\w+', 'hello world!')
>>><re.Match object; span=(0, 5), match='hello'>
Функция findall()
Возвращает список всех экземпляров шаблона в строке. Совпадения возвращаются в порядке слева направо:
re.findall('[A-Z]\w+', 'hello World!')
>>>['World']
Функция search()
Функция search() ищет экземпляры шаблона в строке. Она возвращает объект match при успехе, None – при неудаче. Похожа на функцию match(), но ищет по всей строке:
re.search('ef', 'abcdef')
>>><re.Match object; span=(4, 6), match='ef'>
Функция split()
Разделяет строку по местонахождению шаблона:
re.split('\s+', 'hello world this is andre')
>>>['hello', 'world', 'this', 'is', 'andre']
Некоторые мысли
Несмотря на свою пользу, регулярные выражения – это инструмент, которым легко злоупотребить.
На заметку:
- Начинайте с малого. Используйте регулярные выражения ответственно. Разделите их на более мелкие, если нужно. Вам ни к чему одна огромная регулярка в несколько строк: это существенно снизит читаемость кода.
- Комментируйте регулярки! Никто не хочет тратить время на вашего монстра из 20 строчек, пытаясь понять, что это значит.
Заключение
Регулярные выражения – инструмент, который требует практики. В интернете вы найдёте много ресурсов по регулярным выражениям. Например, официальная документация языка Python.
Комментарии