

Фильтрация данных с помощью операторов WHERE и HAVING
Скорее всего, вы уже знакомы с оператором для фильтрации данных WHERE и, возможно, слышали об операторе HAVING. Но чем же конкретно они отличаются? Давайте сделаем несколько запросов к таблице успеваемости (grades), чтобы в этом разобраться. Воспользуемся оператором ORDER BY RANDOM(), чтобы выбрать произвольные данные, затем LIMIT 5, чтобы запрос выдал только 5 записей. Упорядочивать все строки только ради примера достаточно неэффективно, но если таблица небольшая – это допустимо.
SELECT
*
FROM
grades
ORDER BY
RANDOM()
LIMIT
5;
/*
id | assignment_id | score | student_id
-- | ------------- | ----- | ----------
14 | 4 | 100 | 3
22 | 2 | 91 | 5
23 | 3 | 85 | 5
16 | 1 | 81 | 4
9 | 4 | 64 | 2
*/
Каждая строка отображает оценку ученика по определенному предмету. Давайте узнаем средний балл каждого ученика. Для этого нам понадобится:
GROUP BY– для группировки по ученикам.AVG(score)– для вычисления среднего значения.ROUND– для округления полученных значений.
SELECT
student_id,
ROUND(AVG(score),1) AS avg_score
FROM
grades
GROUP BY
student_id
ORDER BY
student_id;
/*
student_id | avg_score
---------- | ---------
1 | 80.8
2 | 70.4
3 | 94.6
4 | 79.6
5 | 83.4
*/
Теперь давайте представим, что из предыдущего запроса, нам нужны только те строки, где средний балл (avg_score) больше, чем 50 и меньше, чем 75. То есть запрос должен отобразить только ученика со student_id=2. Что произойдет при использовании оператора WHERE?
SELECT
student_id,
ROUND(AVG(score),1) AS avg_score
FROM
grades
WHERE
score BETWEEN 50 AND 75
GROUP BY
student_id
ORDER BY
student_id;
/*
student_id | avg_score
---------- | ---------
1 | 75.0
2 | 70.4
3 | 64.0
4 | 67.0
*/
Результаты выглядят совершенно неверными. Ученик с id=5 не отображается в результате запроса, а ученики с id 1, 3 и 4 на месте. К тому же их средний балл (avg_score) изменился. А что если бы это были данные какого-нибудь важного отчета? Есть вероятность как минимум растеряться.
Давайте вспомним, что оператор HAVING является агрегирующей функцией. Такие функции обрабатывают набор строк для подсчета и возвращения одного значения.
Теперь посмотрим, что изменится при использовании оператора HAVING.
SELECT
student_id,
ROUND(AVG(score),1) AS avg_score
FROM
grades
GROUP BY
student_id
HAVING
ROUND(AVG(score),1) BETWEEN 50 AND 75
ORDER BY
student_id;
/*
student_id | avg_score
---------- | ---------
2 | 70.4
*/
Эти два запроса выдают совершенно разные результаты, потому что операторы WHERE и HAVING фильтруют данные на разных этапах агрегации. WHERE обрабатывает данные перед агрегацией, а HAVING после, и фильтрует уже результаты.
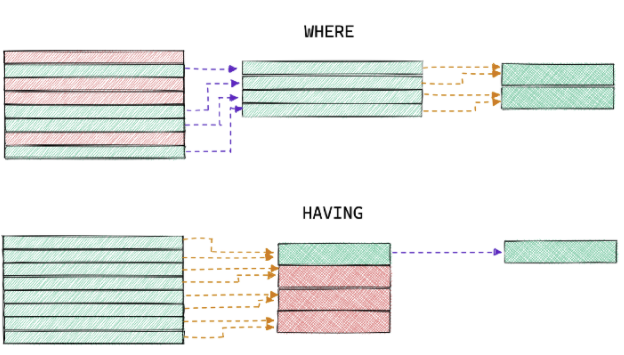
Результат агрегации в запросе с оператором WHERE изменился, потому что мы изменили входные данные для подсчета среднего балла каждого ученика. У ученика с id=5 нет оценок в диапазоне с 50 по 75, поэтому он был исключен из запроса. В то время как оператор HAVING отфильтровал результаты уже после подсчета.
Когда вы освоите применение операторов WHERE и HAVING по отдельности, можете попробовать использовать их вместе. Например: мы хотим отобразить учеников, чей средний балл только по домашним работам не меньше 50 и не больше 75 баллов.
SELECT
student_id,
ROUND(AVG(score),1) AS avg_score
FROM
grades AS g
INNER JOIN
assignments AS a
ON a.id = g.assignment_id
WHERE
a.category = 'homework'
GROUP BY
student_id
HAVING
ROUND(AVG(score),1) BETWEEN 50 AND 75;
/*
student_id | avg_score
---------- | ---------
2 | 74.5
*/
Условные операторы: CASE WHEN и COALESCE
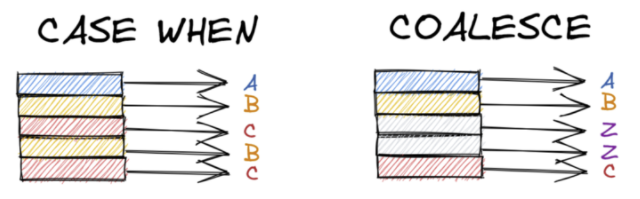
Иногда, к данным в колонке нужно применить некое условие наподобие if-else. Возможно у вас есть таблица для прогнозирования поведения модели и вам нужно вывести данные в виде положительных и отрицательных значений, основываясь на каком-то условии.
На примере нашей базы данных давайте представим, что нам нужно вывести оценки не в виде цифр, а в виде букв. Это легко делается с помощью оператора CASE WHEN.
SELECT
score,
CASE
WHEN score < 60 THEN 'F'
WHEN score < 70 THEN 'D'
WHEN score < 80 THEN 'C'
WHEN score < 90 THEN 'B'
ELSE 'A'
END AS letter
FROM
grades;
/*
score | letter
----- | ------
82 | B
82 | B
80 | B
75 | C
... | ...
*/
Логика, которую мы передаем в блок CASE WHEN может охватывать сразу несколько колонок. Давайте выведем в результат запроса колонку instructor, за основу возьмем таблицу students. Например, если ученику назначен учитель, то в эту колонку запишем имя учителя, если нет, то имя ученика.
SELECT
name,
teacher,
CASE
WHEN teacher IS NOT NULL THEN teacher
ELSE name
END AS instructor
FROM
students AS s
LEFT JOIN
classrooms AS c
ON c.id = s.classroom_id;
/*
name | teacher | instructor
-------- | ------- | ----------
Adam | Mary | Mary
Betty | Mary | Mary
Caroline | Jonah | Jonah
Dina | [null] | Dina
Evan | [null] | Evan
*/
Если мы работаем с данными, которые могут не иметь значения, то есть являются null, оператор COALESCE – лучший выбор. COALESCE – проверка на null, то есть при передаче в него параметров null, он вернет первое значение, не являющееся null. Перепишем предыдущий запрос.
SELECT
name,
teacher,
COALESCE(teacher, name)
FROM
students AS s
LEFT JOIN
classrooms AS c
ON c.id = s.classroom_id;
/*
name | teacher | instructor
-------- | ------- | ----------
Adam | Mary | Mary
Betty | Mary | Mary
Caroline | Jonah | Jonah
Dina | [null] | Dina
Evan | [null] | Evan
*/
Четвертая строка в этом запросе, делает то же самое, что и строки с четвертой по седьмую в предыдущем. То есть, если значение в колонке teacher не null, возвращаем имя учителя, если null, возвращаем имя ученика.
COALESCE будет пропускать все переданные ему аргументы, пока не дойдет до элемента со значением не null. Если же все аргументы имеют значение null, то в возвращаемом значении тоже будет null.
SELECT
COALESCE(NULL, NULL, NULL, 4);
/*
coalesce
--------
4
*/
SELECT
COALESCE(NULL);
/*
coalesce
--------
[null]
*/
И наконец, в Postgres есть еще оператор условия IF , однако он используется для управления несколькими запросами сразу, но не одним. Даже если вы data scientist или data engineer маловероятно, что вы будете им пользоваться. Если вы хотите освоить работу с данным оператором, попробуйте воспользоваться платформой Airflow.
Операции над множествами: UNION, INTERSECT, и EXCEPT
При использовании оператора JOIN мы к одной таблице горизонтально присоединяем другую таблицу. В запросе ниже видно, мы получили данные об ученике с именем Adam из трех таблиц students, grades и assignments. В качестве ключа для связки таблиц использовали поле id.
SELECT
s.name,
g.score,
a.category
FROM
students AS s
INNER JOIN
grades AS g
ON s.id = g.student_id
INNER JOIN
assignments AS a
ON a.id = g.assignment_id
WHERE
s.name = 'Adam';
/*
name | score | category
---- | ----- | --------
Adam | 82 | homework
Adam | 82 | homework
Adam | 80 | exam
Adam | 75 | project
Adam | 85 | exam
*/
В большинстве случаев использование оператора JOIN полностью покрывает наши потребности. Но что если мы захотим объединить таблицы вертикально. Например, у нас есть таблица и снизу к ней мы хотим добавить другую таблицу.
Давайте представим, что с системой успеваемости в нашей школе произошли очень странные изменения. Теперь для определения того, сдал ученик экзамен или нет используются не оценки. Ученик сдаст экзамен если: его имя начинается с буквы А или В или же в его имени только 5 букв. Мы можем написать 2 запроса, которые покажут нам всех учеников, подходящих под каждое условие, а затем используем оператор UNION ALL, чтобы объединить результаты в одну таблицу.
SELECT
*
FROM (
SELECT
name,
'Name starts with A/B' as reason
FROM
students
WHERE
LEFT(name,1) IN ('A', 'B')
) AS x
UNION ALL
SELECT
*
FROM (
SELECT
name,
'Name is 5 letters long' AS reason
FROM
students
WHERE
LENGTH(name) = 5
) AS y;
/*
name | reason
---- | ------
Adam | Name starts with A/B
Betty | Name starts with A/B
Betty | Name is 5 letters long
*/
Здесь, на строках с 4 по 11 и с 18 по 24 мы впервые увидели вложенные запросы (или подзапросы). Обратите внимание, что таким запросам необходимо присваивать имена (в нашем случае x и y) чтобы работал оператор UNION ALL.
Также вы могли обратить внимание, что мы использовали оператор UNION ALL, а не просто UNION. Дело в том, что UNION ALL возвращает все строки, в то время как UNION убирает дубли. То есть если в двух подзапросах будут две одинаковые строки, UNION покажет в результатах только одну. Именно для этого запроса ничего не изменится, потому что ученик Betty удовлетворяет обоим условиям, а вот если не выводить колонку reason в результате мы увидим имя Betty только один раз.
SELECT
*
FROM (
SELECT
name -- <- нет колонки `reason`
FROM
students
WHERE
LEFT(name,1) IN ('A', 'B')
) AS x
UNION -- <- UNION, а не UNION ALL
SELECT
*
FROM (
SELECT
name -- <- нет колонки `reason`
FROM
students
WHERE
LENGTH(name) = 5
) AS y;
/*
name
-----
Adam
Betty <- Только одна запись, потому что использовали оператор UNION
*/
При выборе UNION или UNION ALL подумайте, нужны ли вам повторяющиеся значения. При написании сложных запросов я предпочитаю использовать UNION ALL, чтобы убедиться, что в результирующей таблице то количество строк, которое нужно, и, если есть дубли, значит, где-то раньше я, скорее, всего ошибся с соединениями таблиц (JOIN). Чем раньше вы будете фильтровать данные в запросе, тем эффективнее он будет работать.
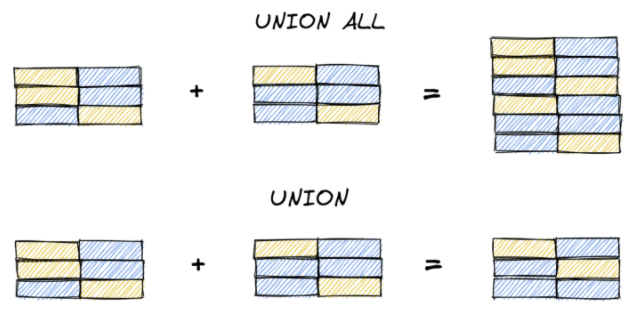
Операторы UNION и UNION ALL возвращают все строки из подзапросов (в случае с UNION без дублей). Два других оператора INTERSECT и EXCEPT, позволяют нам вернуть только те строки, которые соответствуют определенным критериям. INTERSECT (пересечение) вернет только те строки, которые присутствуют в обоих запросах, а EXCEPT (исключение) вернет строки из подзапроса А, которых нет в подзапросе Б.
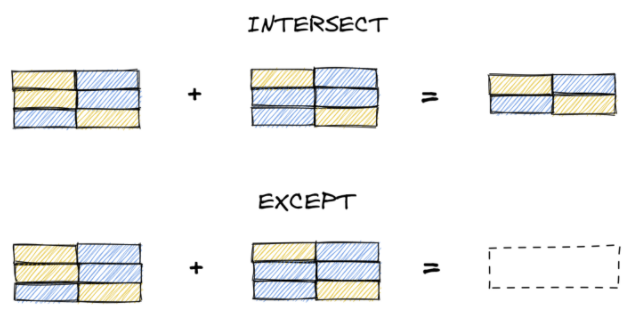
В следующем запросе попробуем работу оператора INTERSECT, который отобразит строки, присутствующие в обоих подзапросах (id 2 и id 3). В отличие от UNION нам не нужно присваивать имена вложенным запросам.
SELECT
*
FROM
students
WHERE
id IN (1,2,3)
INTERSECT
SELECT
*
FROM
students
WHERE
id IN (2,3,4);
/*
id | name | classroom_id
-- | -------- | ------------
2 | Betty | 1
3 | Caroline | 2
*/
А теперь изменим запрос и применим оператор EXCEPT, который выведет строки из подзапроса А, которых нет в подзапросе Б (в нашем случае строка с id=1).
SELECT
*
FROM
students
WHERE
id IN (1,2,3)
EXCEPT
SELECT
*
FROM
students
WHERE
id IN (2,3,4);
/*
id | name | classroom_id
-- | -------- | ------------
1 | Adam | 1
*/
Операции над множествами дают нам возможность комбинировать результаты запросов (UNION), просматривать пересекающиеся записи (INTERSECT) и извлекать отличающиеся данные (EXCEPT). Больше не нужно сравнивать результаты запросов вручную.
Функции для работы с массивами
Данные в реляционных базах обычно являются атомарными, то есть одна ячейка содержит только одно значение (например, только одна оценка в строке таблицы grades). Но иногда, может быть полезно хранить данные в виде массива. Для таких случаев Postgres предоставляет большой набор функций, которые позволяют управлять массивами.
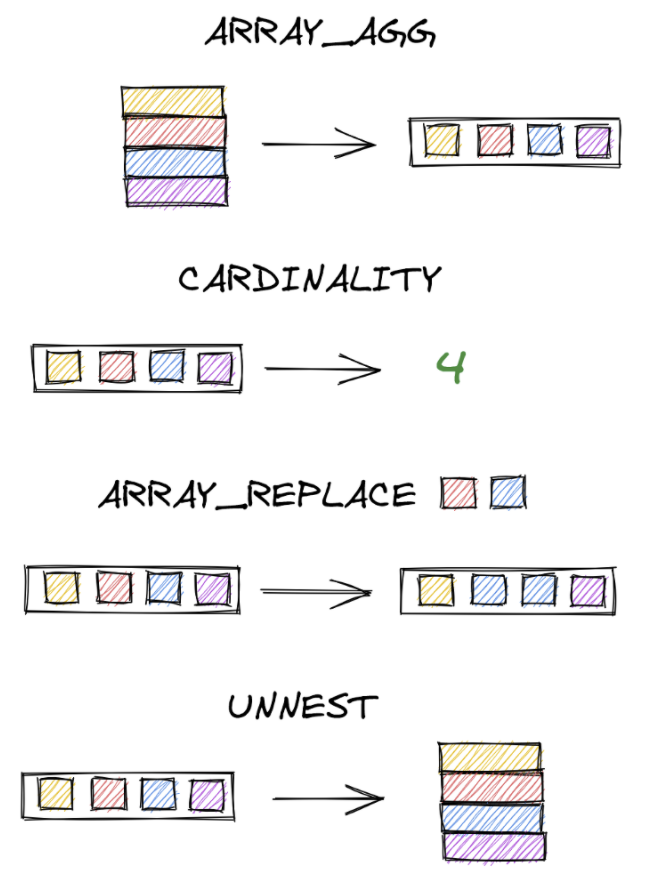
Одна из полезных функций ARRAY_AGG позволяет преобразовать строки в массив. В следующем запросе мы написали ARRAY_AGG(score) и использовали группировку по имени (GROUP BY name) чтобы отобразить массив, включающий в себя все оценки каждого ученика.
SELECT
name,
ARRAY_AGG(score) AS scores
FROM
students AS s
INNER JOIN
grades AS g
ON s.id = g.student_id
GROUP BY
name
ORDER BY
name;
/*
name | scores
-------- | ------
Adam | {82,82,80,75,85}
Betty | {74,75,70,64,69}
Caroline | {96,92,90,100,95}
Dina | {81,80,84,64,89}
Evan | {67,91,85,93,81}
*/
Также в нашем арсенале есть следующие функции:
CARDINALITY– выводит количество элементов в массиве.ARRAY_REPLACE- заменяет указанные элементы.ARRAY_REMOVE- удаляет указанные элемент.
SELECT
name,
ARRAY_AGG(score) AS scores,
CARDINALITY(ARRAY_AGG(score)) AS length,
ARRAY_REPLACE(ARRAY_AGG(score), 82, NULL) AS replaced
FROM
students AS s
INNER JOIN
grades AS g
ON s.id = g.student_id
GROUP BY
name
ORDER BY
name;
/*
name | scores | length | replaced
-------- | ----------------- | ------ | --------------------
Adam | {82,82,80,75,85} | 5 | {NULL,NULL,80,75,85}
Betty | {74,75,70,64,69} | 5 | {74,75,70,64,69}
Caroline | {96,92,90,100,95} | 5 | {96,92,90,100,95}
Dina | {81,80,84,64,89} | 5 | {81,80,84,64,89}
Evan | {67,91,85,93,81} | 5 | {67,91,85,93,81}
*/
UNNEST – еще одна функция, которая может вам пригодиться. Её действие противоположно функции ARRAY_AGG, то есть она позволяет разделить массив на отдельные строки.
SELECT
'name' AS name,
UNNEST(ARRAY[1, 2, 3]);
/*
name | unnest
---- | ------
name | 1
name | 2
name | 3
*/
В этой части статьи мы с вами разобрали:
- фильтрацию данных с помощью операторов
WHEREиHAVING; - условные операторы
CASE WHENиCOALESCE; - операции над множествами;
- функции для работы с массивами.
В финальной части статьи разберем:
- присоединение таблицы к самой себе (
self join); - оконные функции (
window function); - посмотрим вглубь запросов (
explain).
Комментарии