

Эта публикация – выполненный с небольшими сокращениями перевод статьи Дуга Фаррелла Data Management With Python, SQLite, and SQLAlchemy. Полный программный код пособия доступен в GitHub-репозитории. Все упоминаемые примеры подпрограмм отсылают к соответствующим файлам.
Все программы в той или иной форме занимаются обработкой информации. Многим из них необходимо сохранять эти данные и впоследствии извлекать. В небольших проектах хранить информацию можно в одном файле без необходимости использования сервера баз данных. С такими задачами вполне можно справиться средствами Python, SQLite и SQLAlchemy.
Аналогичных результатов можно добиться, используя форматы CSV, JSON, XML или даже кастомные решения. Преимуществом таких текстовых хранилищ является легкий для восприятия формат данных – обычно структура понятна с первого взгляда. Ниже мы сравним такой способ хранения и обработки данных с применением реляционных баз данных и языка SQL, а также разберемся, какой метод лучше подходит для вашей программы. В общих чертах мы рассмотрим следующие вопросы:
- как использовать плоские файлы и SQLite для хранения данных;
- как SQL позволяет облегчить доступ к данным;
- как применять SQLAlchemy для работы с данными в форме объектов Python.
В практическом отношении основной акцент в статье делается на SQLAlchemy.
🧾 Плоские базы данных
Под плоской базой данных (плоской таблицей) будем понимать файл, содержащий данные без внутренней иерархии и ссылок на внешние файлы. Это объясняет ряд особенностей: в таких базах данных нет необходимости использовать фиксированную ширину полей, а csv-файлы (англ. comma separated values) представляют собой строки простого текста, в которых элементы данных разделены запятыми. Каждая строка текста представляет собой строку данных, а каждое значение в строке, отделенное от остальных запятой соответствует одному из полей таблицы.
first_name,last_name,title,publisher
Isaac,Asimov,Foundation,Random House
Pearl,Buck,The Good Earth,Random House
Pearl,Buck,The Good Earth,Simon & Schuster
Tom,Clancy,The Hunt For Red October,Berkley
Tom,Clancy,Patriot Games,Simon & Schuster
Stephen,King,It,Random House
Stephen,King,It,Penguin Random House
Stephen,King,Dead Zone,Random House
Stephen,King,The Shining,Penguin Random House
John,Le Carre,"Tinker, Tailor, Solider, Spy: A George Smiley Novel",Berkley
Alex,Michaelides,The Silent Patient,Simon & Schuster
Carol,Shaben,Into The Abyss,Simon & Schuster
В первой строке представленного примера находится список полей – имена столбцов данных. Каждая следующая строка соответствует одной записи.
➕ Преимущества плоских баз данных
Небольшие плоские базы данных легко создавать и корректировать с помощью текстового редактора, не составляет трудностей найти несоответствие или иную проблему. Многие приложения умеют их импортировать и экспортировать. В Excel можно превратить csv-файл в электронную таблицу и обратно.
Ещё одно преимущество плоских файлов – они автономны, данными в такой форме легко поделиться. Практически в любом языке программирования есть инструменты и библиотеки для работы с csv-файлами. Python имеет встроенный модуль csv и мощную стороннюю библиотеку pandas.
➖ Недостатки плоских баз данных
Преимущества плоских баз данных меркнут по мере увеличения объема информации. Файлы остаются читаемыми, но редактирование и поиск отдельных записей вызывают трудности. И не только для человека – файл разрастается, и его обработка требует вычислительных ресурсов.
Другая трудность, связанная с применением плоских файлов – нужно явно создавать и поддерживать отношения между компонентами данных в рамках одного файла. Чтобы описать новые отношения, приходится писать дополнительный текст, создавать новые поля.
Ещё одна сложность – люди, с которыми мы хотим поделиться файлом данных, также должны знать о структурах и отношениях, которые в этих данных отразили. Чтобы получить доступ к информации, пользователи нередко должны понимать не только структуру данных, но и сопровождающие инструменты программирования.
📇 Пример работы с плоской базой данных
В качестве примера рассмотрим описанный выше файл author_book_publisher.csv, содержащий список авторов, опубликованных ими книг и издателей. Для простоты будем считать, что все авторы, книги и издательства уникальны, и все книги пишутся автором без соавторов.
Рассмотрим функцию main() программы, находящейся в упомянутом репозитории по относительному адресу examples/example_1/main.py.
def main():
"""Основная точка входа в программу"""
# Получим ресурсы для программы
with resources.path(
"project.data", "author_book_publisher.csv"
) as filepath:
data = get_data(filepath)
# Узнаем количество книг, напечатанных каждым издателем
books_by_publisher = get_books_by_publisher(data, ascending=False)
for publisher, total_books in books_by_publisher.items():
print(f"Publisher: {publisher}, total books: {total_books}")
print()
# Узнаем число авторов у каждого из издателей
authors_by_publisher = get_authors_by_publisher(data, ascending=False)
for publisher, total_authors in authors_by_publisher.items():
print(f"Publisher: {publisher}, total authors: {total_authors}")
print()
# Вывод иерархических данных об авторах
output_author_hierarchy(data)
# Добавим новую книгу в структуру данных
data = add_new_book(
data,
author_name="Stephen King",
book_title="The Stand",
publisher_name="Random House",
)
# Выводим обновленные данные в иерархическом виде
output_author_hierarchy(data)
При запуске программы для обновленного csv-файла выводится следующий результат:
$ python main.py
Publisher: Simon & Schuster, total books: 4
Publisher: Random House, total books: 4
Publisher: Penguin Random House, total books: 2
Publisher: Berkley, total books: 2
Publisher: Simon & Schuster, total authors: 4
Publisher: Random House, total authors: 3
Publisher: Berkley, total authors: 2
Publisher: Penguin Random House, total authors: 1
Authors
├── Alex Michaelides
│ └── The Silent Patient
│ └── Simon & Schuster
├── Carol Shaben
│ └── Into The Abyss
│ └── Simon & Schuster
├── Isaac Asimov
│ └── Foundation
│ └── Random House
├── John Le Carre
│ └── Tinker, Tailor, Solider, Spy: A George Smiley Novel
│ └── Berkley
├── Pearl Buck
│ └── The Good Earth
│ ├── Random House
│ └── Simon & Schuster
├── Stephen King
│ ├── Dead Zone
│ │ └── Random House
│ ├── It
│ │ ├── Penguin Random House
│ │ └── Random House
│ └── The Shining
│ └── Penguin Random House
└── Tom Clancy
├── Patriot Games
│ └── Simon & Schuster
└── The Hunt For Red October
└── Berkley
Для выполнения основной части работы main() вызывает другие функции, с которыми можно ознакомиться в файле. Само приложение работает корректно и демонстрирует возможности библиотеки pandas.
Мы показали этот пример, чтобы далее создать программу с идентичной функциональностью, используя базу данных SQLite и библиотеку SQLAlchemy для манипуляции этими данными.
🦋 Использование SQLite для хранения данных
Как мы упомянули выше в примечании, в файле author_book_publisher.csv в некоторых данных есть повторы. Например, роман Перл Бак The Good Earth опубликовали два разных издателя.
Pearl,Buck,The Good Earth,Random House
Pearl,Buck,The Good Earth,Simon & Schuster
Представьте, что было бы, если файл содержал больше связанных данных, например, сведения об авторе, дату публикации, ISBN книги, адрес и телефонный номер издательства. Подобные сведения будут дублироваться для каждого корневого элемента: автора, книги, издательства. Такое построение не только избыточно, но и усложняет процедуры 1) изменения полей, связанных с отдельным объектом и 2) добавления новых свойств.
Перечисленные причины обуславливают использование баз данных, учитывающих отношения между скрытыми в них структурами – реляционных баз данных. Важной темой в этом плане является нормализация базы данных – приведение структуры к виду, обеспечивающему минимальную логическую избыточность. Когда структура базы данных расширяется новыми типами данных, предварительная нормализация сводит к минимуму изменения существующей структуры.
SQLite является системой управления реляционными базами данных, доступной в стандартной библиотеке Python. Для работы с ней не требуется отдельный сервер, формат файла является кросс-платформенным и доступен в других языках программирования, поддерживающих SQLite.
🏗️ Создаем структуру базы данных
Реляционные базы данных позволяют хранить структурированные данные в виде связанных друг с другом таблиц. В качестве основного способа взаимодействия с данными используется язык запросов SQL.
SQL – это декларативный язык, используемый для создания, управления и поиска данных, содержащихся в базе. Декларативный язык описывает, что должно быть выполнено, а не то, как это нужно сделать. Мы увидим примеры операторов SQL позже, когда перейдем к созданию таблиц базы данных.
Чтобы воспользоваться преимуществами SQL, нам нужно провести нормализацию базы данных из файла author_book_publisher.csv. Для этого мы перенесем авторов, книги и издателей в отдельные таблицы базы данных.
Данные в этом формате хранятся в виде двумерных табличных структур. Данные, содержащиеся в полях таблицы, относятся к заранее определенным типам: текст, целые числа, числа с плавающей запятой и т. д. Это отличает базы данных от csv-файлов, где все поля исходно являются текстовыми и для распознавания типа должны быть проанализированы программно.
Каждая запись в таблице имеет первичный ключ (англ. primary key), определенный для присвоения записи уникального идентификатора. Первичный ключ похож на ключ в словаре Python. Движок базы данных обычно сам генерирует целочисленный первичный ключ, увеличивая значение на единицу для каждой новой записи. Если данные, хранящиеся в поле, уникальны среди всех других данных в этом поле, это значение также может использоваться, как первичный ключ. Например, в таблице, содержащей данные о книгах, в качестве первичного ключа может использоваться уникальный по своей природе ISBN.
🏢 Создание таблиц базы данных
Ниже представлен пример, как с помощью операторов SQL можно создать три таблицы, представляющие авторов, книги и издательства:
CREATE TABLE author (
author_id INTEGER NOT NULL PRIMARY KEY,
first_name VARCHAR,
last_name VARCHAR
);
CREATE TABLE book (
book_id INTEGER NOT NULL PRIMARY KEY,
author_id INTEGER REFERENCES author,
title VARCHAR
);
CREATE TABLE publisher (
publisher_id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR
);
Обратите внимание, что здесь нет ни файловых операций, ни переменных, ни структур для их хранения. Описывается только желаемый результат: создание таблицы с определенными атрибутами. Механизм базы данных определяет, как это сделать.
Представим, что далее мы сделали SQL-запросы, чтобы заполнить таблицы базы данных информацией. Следующий оператор использует знак *, чтобы получить и вывести все данные в таблице авторов:
SELECT * FROM author;
Вы можете использовать инструмент командной строки sqlite3 для взаимодействия с файлом базы данных author_book_publisher.db:
sqlite3 author_book_publisher.db
Ниже показан результат работы указанной команды SQL и ее вывод, за которой следует команда .q для выхода из программы:
sqlite> SELECT * FROM author;
1|Isaac|Asimov
2|Pearl|Buck
3|Tom|Clancy
4|Stephen|King
5|John|Le Carre
6|Alex|Michaelides
7|Carol|Shaben
sqlite> .q
Обратите внимание, что в отличие от csv-файла каждый автор присутствует в таблице только один раз.
🕹️ Манипуляции данными с помощью SQL
SQL предоставляет различные способы работы с базами данных и таблицами, добавление новых данных, обновление и удаление уже существующих. Пример оператора SQL для вставки нового автора в таблицу author:
INSERT INTO author
(first_name, last_name)
VALUES ('Paul', 'Mendez');
Оператор INSERT вставляет строковые значения Paul и Mendez в соответствующие столбцы first_name и last_name таблицы author.
Обратите внимание, что столбец author_id не указан. Поскольку этот столбец является первичным ключом, механизм базы данных сам генерирует и добавляет значение.
Обновление записей в таблице базы данных – также несложный процесс. Например, предположим, что Стивен Кинг хотел, чтобы его знали под псевдонимом Ричард Бахман:
UPDATE author
SET first_name = 'Richard', last_name = 'Bachman'
WHERE first_name = 'Stephen' AND last_name = 'King';
Оператор SQL находит запись с помощью условного оператора WHERE, а затем обновляет поля first_name и last_name свежими значениями. Знак равенства (=) в SQL используется и для сравнения, и для присваивания.
Пример оператора SQL для удаления записи из таблицы авторов:
DELETE FROM author
WHERE first_name = 'Paul'
AND last_name = 'Mendez';
first_name = 'Paul', то были бы удалены все авторы с именем Paul.🤝 Строим отношения: «один ко многим»
Данные в файле author_book_publisher.csv отображают данные и связи путем дублирования данных. База данных SQLite разбивает данные на три таблицы (author, book, and publisher) и устанавливает между ними отношения.
Связь «один ко многим» похоже на связь покупателя с заказываемыми товарами в Интернете. У одного покупателя может быть много заказов, но каждый заказ принадлежит одному покупателю. В базе данных author_book_publisher.db связь «один ко многим» представлена отношением авторов и книг. Каждый автор может написать много книг, но каждая художественная книга написана одним автором (в рамках рассматриваемого примера).
Как реализовать связь «один ко многим» между двумя таблицами? Каждая таблица в базе данных имеет поле первичного ключа, обычно названное по шаблону <имя таблицы>_id.
Кроме того, таблица book содержит поле author_id, которое ссылается на таблицу author (см. выше SQL-запрос для создания таблиц). Таким образом, поле author_id устанавливает связь «один ко многим» между авторами и книгами, которая выглядит следующим образом.

author и bookПриведенная выше диаграмма представляет собой простую диаграмму отношений сущностей (ERD), созданную с помощью приложения JetBrains DataGrip. Два графических элемента добавляют информацию о связях:
- Значки ключей обозначают первичный (желтый цвет) и внешний (голубой цвет) ключи.
- Стрелка указывает на связь между таблицами на основе внешнего ключа
author_id.
Чтобы вывести две таблицы вместе, используем SQL-оператор JOIN:
sqlite> SELECT
...> a.first_name || ' ' || a.last_name AS author_name,
...> b.title AS book_title
...> FROM author a
...> JOIN book b ON b.author_id = a.author_id
...> ORDER BY a.last_name ASC;
Isaac Asimov|Foundation
Pearl Buck|The Good Earth
Tom Clancy|The Hunt For Red October
Tom Clancy|Patriot Games
Stephen King|It
Stephen King|Dead Zone
Stephen King|The Shining
John Le Carre|Tinker, Tailor, Solider, Spy: A George Smiley Novel
Alex Michaelides|The Silent Patient
Carol Shaben|Into The Abyss
Приведенный SQL-запрос собирает информацию из author и book, используя установленную между ними связь. Конкатенация строк SQL позволяет присвоить author_name полное имя автора. Данные, собранные запросом, сортируются в порядке возрастания по полю last_name.
Создав отдельные таблицы для авторов и книг и установив между ними связь, мы уменьшили избыточность данных. Теперь данные об авторе редактируются в одном месте, данные о книгах – в другом.
🌉 Добавляем связи: «многие ко многим»
Автор может работать со многими издателями, а издатель – со многими авторами. Книга может быть опубликована в нескольких издательствах, а издатель может опубликовать множество разных книг. То есть в базе данных author_book_publisher.db отношение «многие ко многим» существует между авторами и издателями, а также между издателями и книгами.
Такой тип связи являются двусторонним и создается с помощью свящующей таблицы. Такая таблица содержит как минимум два поля внешних ключей, которые являются первичными ключами для каждой из двух связанных таблиц:
CREATE TABLE author_publisher (
author_id INTEGER REFERENCES author,
publisher_id INTEGER REFERENCES publisher
);
В этом примере создается новая таблица author_publisher, которая ссылается на первичные ключи уже существующих таблиц author и publisher. То есть таблица author_publisher устанавливает отношения между автором и издателем. Аналогично создается таблица book_publisher.
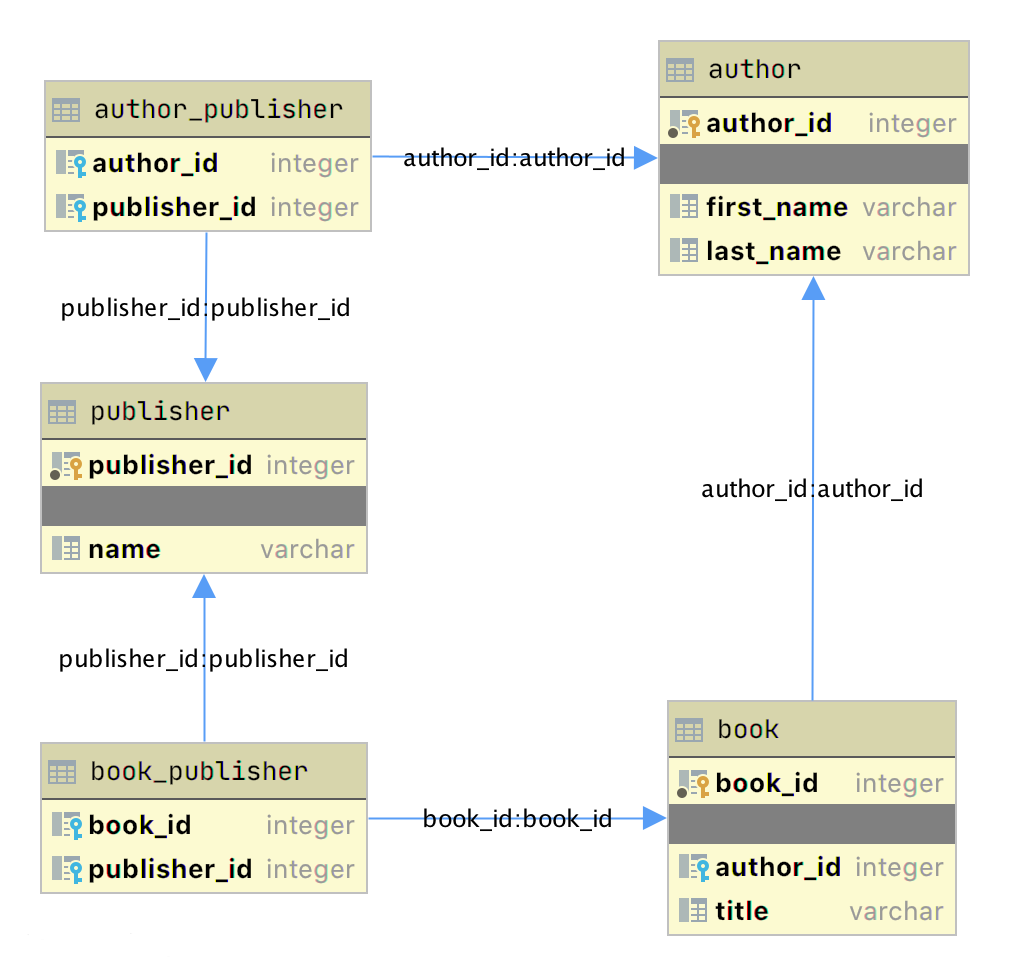
Поскольку связь устанавливается между двумя первичными ключами, нет необходимости создавать первичный ключ для самой таблицы связей. Комбинация двух связанных ключей создает уникальный идентификатор.
Объединить таблицы можно с помощью оператора JOIN, но в случае связи многие-ко-многим требуется использовать оператор дважды:
- Соединяя таблицы
authorиauthor_publisher - Соединяя таблицы
author_publisherиpublisher
Пример SQL-запроса, возвращающего список авторов и издателей, публикующих их книги:
sqlite> SELECT
...> a.first_name || ' ' || a.last_name AS author_name,
...> p.name AS publisher_name
...> FROM author a
...> JOIN author_publisher ap ON ap.author_id = a.author_id
...> JOIN publisher p ON p.publisher_id = ap.publisher_id
...> ORDER BY a.last_name ASC;
Isaac Asimov|Random House
Pearl Buck|Random House
Pearl Buck|Simon & Schuster
Tom Clancy|Berkley
Tom Clancy|Simon & Schuster
Stephen King|Random House
Stephen King|Penguin Random House
John Le Carre|Berkley
Alex Michaelides|Simon & Schuster
Carol Shaben|Simon & Schuster
Приведем пример еще одного запроса, отражающего некоторые возможности SQL:
sqlite> SELECT
...> a.first_name || ' ' || a.last_name AS author_name,
...> COUNT(b.title) AS total_books
...> FROM author a
...> JOIN book b ON b.author_id = a.author_id
...> GROUP BY author_name
...> ORDER BY total_books DESC, a.last_name ASC;
Stephen King|3
Tom Clancy|2
Isaac Asimov|1
Pearl Buck|1
John Le Carre|1
Alex Michaelides|1
Carol Shaben|1
Этот запрос возвращает список авторов и количество написанных ими книг. Список сортируется сначала по количеству книг в порядке убывания, а затем по имени автора в алфавитном порядке.
То есть здесь мы используем SQL одновременно для агрегирования и сортировки результатов. Выполнение вычислений в базе данных на основе встроенных возможностей систем управления базами данных обычно происходит быстрее, чем выполнение тех же вычислений с необработанными наборами данных в Python.
🧰 Работа с SQLAlchemy и объектами Python
SQLAlchemy – это мощный набор Python-инструментов для доступа к базам данных. Когда мы программируем на объектно-ориентированном языке, полезно мыслить в категориях объектов. Но между объектно-ориентированной и реляционной моделями существует концептуальный разрыв. Этот зазор покрывает объектно-реляционное отображение (ORM), предоставляемое SQLAlchemy. Между базой данных и программой Python появляется модель, преобразующая информацию из потока базы данных в объекты Python и обратно. Таким образом, SQLAlchemy позволяет мыслить в терминах объектов, при этом сохраняя мощные механизмы базы данных.
Модель. Для подключения SQLAlchemy к базе данных создается модель – класс Python, унаследованный от класса SQLAlchemy Base , определяющий отображение данных между объектами Python, возвращаемыми в результате запроса, и самими таблицами базы данных.
Представленный ниже файл models.py создает модели для представления базы данных author_book_publisher.db:
# импортируем классы, используемые для определения атрибутов модели
from sqlalchemy import Column, Integer, String, ForeignKey, Table
# импортируем объекты для создания отношения между объектами
from sqlalchemy.orm import relationship, backref
# объект для подключения ядро базы данных
from sqlalchemy.ext.declarative import declarative_base
# создаем класс, от которого будут наследоваться модели
Base = declarative_base()
# создаем модель таблицы связей таблиц author и publisher
author_publisher = Table(
"author_publisher",
Base.metadata,
Column("author_id", Integer, ForeignKey("author.author_id")),
Column("publisher_id", Integer, ForeignKey("publisher.publisher_id")),
)
# создаем модель таблицы связей таблиц book и publisher
book_publisher = Table(
"book_publisher",
Base.metadata,
Column("book_id", Integer, ForeignKey("book.book_id")),
Column("publisher_id", Integer, ForeignKey("publisher.publisher_id")),
)
# определяем модельи классов для автора, книги и издательства
class Author(Base):
__tablename__ = "author"
author_id = Column(Integer, primary_key=True)
first_name = Column(String)
last_name = Column(String)
books = relationship("Book", backref=backref("author"))
publishers = relationship(
"Publisher", secondary=author_publisher, back_populates="authors"
)
class Book(Base):
__tablename__ = "book"
book_id = Column(Integer, primary_key=True)
author_id = Column(Integer, ForeignKey("author.author_id"))
title = Column(String)
publishers = relationship(
"Publisher", secondary=book_publisher, back_populates="books"
)
class Publisher(Base):
__tablename__ = "publisher"
publisher_id = Column(Integer, primary_key=True)
name = Column(String)
authors = relationship(
"Author", secondary=author_publisher, back_populates="publishers"
)
books = relationship(
"Book", secondary=book_publisher, back_populates="publishers"
)
В приведенных в коде комментариях модели сопоставлены пяти показанным выше таблицам базы данных author_book_publisher.db.
Класс Table служит для создания связующей таблицы, то есть для создания отношений многие-ко-многим. Первый параметр – имя таблицы, определенное в базе данных, второй (Base.metadata) обеспечивает связь между функциональностью SQLAlchemy и механизмами базы данных. Остальные параметры являются экземплярами класса Column, определяющего поле таблицы по имени, типу, а также соответствие внешнему ключу.
Класс ForeignKey определяет взаимосвязь между двумя полями Column в разных таблицах. Например, следующая строка в определении таблицы author_publisher сообщает SQLAlchemy, что в таблице author_publisher есть поле с именем author_id, тип этого поля – Integer, и он является внешним ключом, связанным с первичным ключом в таблице author.
Column("author_id", Integer, ForeignKey("author.author_id"))
Функция relationship определяет отношение один-ко-многим.
books = relationship("Book", backref=backref("author"))
Первый параметр функции relationship – имя класса Book (не путайте с именем таблицы book) – это класс, к которому относится атрибут books. Это отношение сообщает SQLAlchemy, что существует связь между классами Author и Book. SQLAlchemy найдет связь в определении класса Book:
author_id = Column(Integer, ForeignKey("author.author_id"))
SQLAlchemy распознает, что это точка соединения ForeignKey между двумя классами.
Параметр backref создает атрибут author для каждого экземпляра Book. Этот атрибут ссылается на Author, с которым связан экземпляр Book.
Например, если выполнить следующий код Python, то в результате запроса будет возвращен экземпляр Book, имеющий атрибуты, которые можно использовать для вывода информации о книге:
book = session.query(Book).filter_by(Book.title == "The Stand").one_or_none()
print(f"Authors name: {book.author.first_name} {book.author.last_name}")
Наличие атрибута author в book связано с определением backref. Обратная ссылка очень удобна, когда нам нужно обратиться к родительскому объекту, а все, что у нас есть, – это дочерний экземпляр.
Другая связь у Author с классом Publisher:
publishers = relationship(
"Publisher", secondary=author_publisher, back_populates="authors"
)
# для сравнения
books = relationship("Book", backref=backref("author"))
Как и книги, атрибут publishers обозначает совокупность издателей, связанных с автором. Первый параметр, "Publisher", сообщает SQLAlchemy, что это за класс. Второй параметр secondary сообщает SQLAlchemy, что связь с классом Publisher осуществляется через «вторичную» таблицу – таблицу author_publisher. Третий параметр back_populate сообщает SQLAlchemy о наличии дополнительной коллекции в классе Publisher, называемой authors.
💬 Запросы к базе данных
Стандартный запрос наподобие SELECT * FROM author в SQLAlchemy можно сделать вот так:
results = session.query(Author).all()
Здесь session – объект SQLAlchemy, используемый для связи с SQLite в программах Python. Здесь мы сообщаем, что хотим выполнить запрос к модели Author и вернуть все записи.
На этом этапе преимущества использования SQLAlchemy вместо простого SQL могут быть неочевидны, особенно с учетом необходимости создания моделей. Однако оказывается, что вместо списка скалярных данных, теперь мы получаем список экземпляров объектов Author с атрибутами, соответствующими заданным именам столбцов.
Коллекции книг и издателей, поддерживаемая SQLAlchemy, создает иерархический список авторов и написанных ими книг, а также издателей, которые эти книги опубликовали. За кулисами SQLAlchemy превращает вызовы объектов и методов в операторы SQL для выполнения в системе управления базами данных SQLite. И наоборот, SQLAlchemy преобразует данные, возвращаемые запросами SQL, в объекты Python.
С помощью SQLAlchemy мы можем выполнить запрос агрегирования, показанный ранее для списка авторов и количества написанных книг, следующим образом:
author_book_totals = (
session.query(
Author.first_name,
Author.last_name,
func.count(Book.title).label("book_total")
)
.join(Book)
.group_by(Author.last_name)
.order_by(desc("book_total"))
.all()
)
Запрос session.query возвращает имя и фамилию автора, а также количество книг, написанных автором. Агрегирующий счетчик в инструкции group_by производит подсчет по фамилии автора. Результаты сортируются в порядке убывания на основе расчетной переменной с псевдонимом book_total.
👨💻 Пример программы
Пример программы examples/example_2/main.py содержит те же функции, что и первый программный пример, но использует SQLAlchemy исключительно для взаимодействия с базой данных SQLite author_book_publisher.db. Приведем здесь функцию main():
def main():
"""Main entry point of program"""
# Подключение к базе данных через SQLAlchemy
with resources.path(
"project.data", "author_book_publisher.db"
) as sqlite_filepath:
engine = create_engine(f"sqlite:///{sqlite_filepath}")
Session = sessionmaker()
Session.configure(bind=engine)
session = Session()
# Определяем число книг, изданных каждым издательством
books_by_publisher = get_books_by_publishers(session, ascending=False)
for row in books_by_publisher:
print(f"Publisher: {row.name}, total books: {row.total_books}")
print()
# Определяем число авторов у каждого издательства
authors_by_publisher = get_authors_by_publishers(session)
for row in authors_by_publisher:
print(f"Publisher: {row.name}, total authors: {row.total_authors}")
print()
# Иерархический вывод данных
authors = get_authors(session)
output_author_hierarchy(authors)
# Добавляем новую книгу
add_new_book(
session,
author_name="Stephen King",
book_title="The Stand",
publisher_name="Random House",
)
# Вывод обновленных сведений
authors = get_authors(session)
output_author_hierarchy(authors)
В сравнении с изначальным кодом теперь весь код в файле выражает, что нужно получить или сделать, а не то, как это нужно сделать. И в отличие от второй части нашего рассказа теперь вместо использования SQL мы применяем объекты и методы Python.
👥 Предоставление доступа к данным нескольким пользователям
К этому моменту мы узнали, как для доступа к одним и тем же данным могут использоваться pandas, SQLite и SQLAlchemy. Одним из решающих факторов при выборе между использованием плоского файла или базы данных является объем данных и количество связей между различными структурами данных. Еще один фактор, который следует учитывать, – с каким количеством пользователей мы делимся данными и вопрос критичности их рассинхронизации.
Проблема обеспечения единообразия данных обычно возникает, когда множество пользователей взаимодействуют с данными удаленно через сеть. Предоставление данных через серверное приложение и пользовательский интерфейс решает проблему целостности данных. В этом случае сервер – единственное приложение, имеющее доступ к базе данных на уровне файлов.
Последний пример – законченное веб-приложение и пользовательский интерфейс для образца существенно более крупной учебной базы данных SQLite Chinook, содержащей информацию о музыкальных исполнителях, альбомах, треках, жанрах и т. п. (11 связанных таблиц).
🌐 Использование Flask с SQLite и SQLAlchemy
Программа examples/example_3/chinook_server.py создает приложение Flask, с которым можно взаимодействовать с помощью браузера. В приложении используются следующие технологии:
- Flask Blueprint – часть Flask для делегирования задач отдельным модулям с заранее определенной функциональностью;
- Flask SQLAlchemy – расширение Flask, добавляющее в веб-приложения поддержку SQLAlchemy;
- Flask_Bootstrap4 упаковывает набор интерфейсных инструментов Bootstrap, интегрируя его с веб-приложениями Flask;
- Flask_WTF расширяет Flask с помощью WTForms, предоставляя вашим веб-приложениям удобный способ создания и проверки веб-форм;
- python_dotenv – модуль Python, используемый приложением для чтения переменных среды из файла и сохранения конфиденциальной информации за пределами программного кода.
Пример приложения довольно большой, и лишь некоторая его часть имеет отношение к руководству. По этой причине изучение кода оставлено в качестве упражнения для читателя. Тем не менее вы можете посмотреть представленный ниже скринкаст, за которой следует HTML-код шаблона домашней страницы и Python-скрипт, который динамически предоставляет данные.
HTML-шаблон Jinja2, который создает домашнюю страницу приложения:
{% extends "base.html" %}
{% block content %}
<div class="container-fluid">
<div class="m-4">
<div class="card" style="width: 18rem;">
<div class="card-header">Create New Artist</div>
<div class="card-body">
<form method="POST" action="{{url_for('artists_bp.artists')}}">
{{ form.csrf_token }}
{{ render_field(form.name, placeholder=form.name.label.text) }}
<button type="submit" class="btn btn-primary">Create</button>
</form>
</div>
</div>
<table class="table table-striped table-bordered table-hover table-sm">
<caption>List of Artists</caption>
<thead>
<tr>
<th>Artist Name</th>
</tr>
</thead>
<tbody>
{% for artist in artists %}
<tr>
<td>
<a href="{{url_for('albums_bp.albums', artist_id=artist.artist_id)}}">
{{ artist.name }}
</a>
</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
</div>
{% endblock %}
Файл Python, ответственный за отображение страницы:
from flask import Blueprint, render_template, redirect, url_for
from flask_wtf import FlaskForm
from wtforms import StringField
from wtforms.validators import InputRequired, ValidationError
from app import db
from app.models import Artist
# Настраиваем blueprint
artists_bp = Blueprint(
"artists_bp", __name__, template_folder="templates", static_folder="static"
)
def does_artist_exist(form, field):
artist = (
db.session.query(Artist)
.filter(Artist.name == field.data)
.one_or_none()
)
if artist is not None:
raise ValidationError("Artist already exists", field.data)
class CreateArtistForm(FlaskForm):
name = StringField(
label="Artist's Name", validators=[InputRequired(), does_artist_exist]
)
@artists_bp.route("/")
@artists_bp.route("/artists", methods=["GET", "POST"])
def artists():
form = CreateArtistForm()
# Проверяем валидность формы
if form.validate_on_submit():
# "Создаем" нового артиста
artist = Artist(name=form.name.data)
db.session.add(artist)
db.session.commit()
return redirect(url_for("artists_bp.artists"))
artists = db.session.query(Artist).order_by(Artist.name).all()
return render_template("artists.html", artists=artists, form=form,)
Заключение
Разумно задаться вопросом: является ли SQLite правильным выбором в качестве серверной части базы данных для веб-приложения. На веб-сайте SQLite указано, что SQLite – хороший выбор для сайтов, обслуживающих около 100 тыс. обращений в день. Если на вашем сайт посещений больше, в первую очередь вас стоит поздравить 🎉
Если вы реализовали веб-сайт с помощью SQLAlchemy, то можно перенести данные из SQLite в другую базу данных, такую как MySQL или PostgreSQL. Описательные модели данных SQLAlchemy останутся прежними.
Комментарии