

Ранее с помощью нейросетей мы генерировали лица персонажей манги и аниме. Теперь научим генеративно-состязательную сеть раскрашивать черно-белые контурные наброски.
Введение
Генеративно-состязательные сети (GAN) представляют собой результат переноса идей парадигмы генеративного моделирования на методы глубокого обучения.
Генеративное моделирование представляет пример задачи машинного обучения «без учителя», Изучение шаблонов во входных данных происходит таким образом, что модель может создавать новые примеры, схожие по характеристикам с экземплярами оригинального датасета.
Архитектура модели GAN включает две подмодели:
- Генератор, создающий новые примеры.
- Дискриминатор для классификации того, являются ли сгенерированные примеры «реальными» или поддельными, созданными генератором (фактически задача состоит в том, чтобы обучить генератор создавать примеры, которые дискриминатор не сможет отличить от оригинальных).
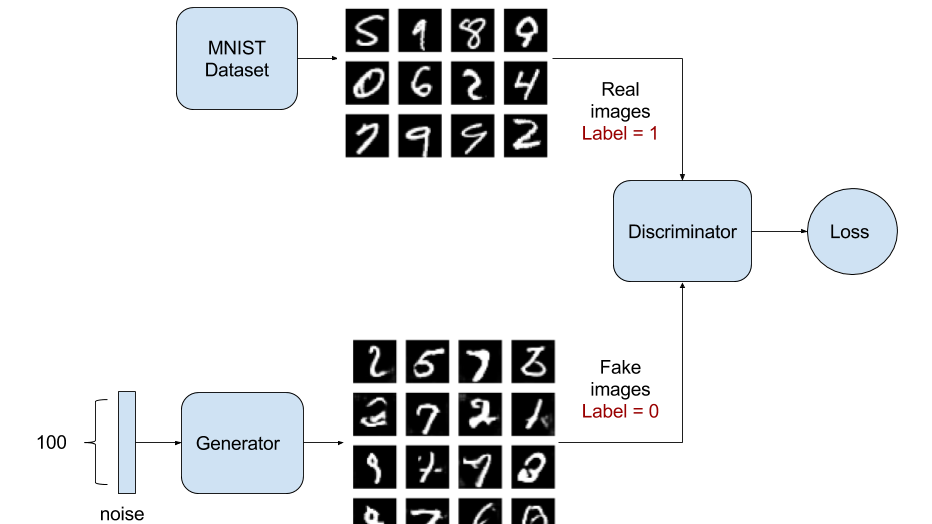
В терминах теории игр идея генеративно-состязательной нейросети базируется на идее игры с нулевой суммой: если один выигрывает, соперник проигрывает. В теории игр модель GAN сходится, когда дискриминатор и генератор достигают равновесия Нэша. Это оптимальная точка для следующего минимаксного уравнения:
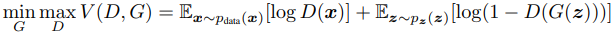
Если вы хотите углубиться в математику, ознакомьтесь с вышеупомянутой статьей Яна Гудфеллоу.
Генеративно-состязательные сети используются в задачах перевода изображения в изображение (летние фотографии в зимние, день в ночь) и для создания неотличимых от реальности изображений никогда не существовавших объектов, сцен и людей. В этой статье мы тоже преобразуем одно изображение, черно-белое, в цветное, как если бы набросок раскрашивал художник.
1. Получение и предварительная обработка данных
Набор данных для раскрашивания аниме-эскизов, используемый для обучения генеративно-состязательной нейросети, можно загрузить с Kaggle. После загрузки и распаковки набора данных его нужно предварительно обработать, так как эскиз и цветное изображение были на одном изображении.
# импортируем необходимые библиотеки
import matplotlib.pyplot as plt
from PIL import Image
from tqdm import tqdm
import numpy as np
import glob
# отображение образцов эскизмо и цветных изображений
for file in glob.glob('train\*.png')[:5]:
f, a = plt.subplots(1,2, figsize=(10,5))
a = a.flatten()
img = Image.open(file).convert('RGB')
a[0].imshow(img.crop((0, 0, 512,512))); a[0].axis('off');
a[1].imshow(img.crop((512, 0, 1024, 512))); a[1].axis('off');
plt.show()
print(file)
# создадим директорию с данными для обучения
get_ipython().system('mkdir trainData')
# предобработка и сохранение данных
for idx, file in tqdm(enumerate(glob.glob('train\*.png')[:23])):
img = Image.open(file).convert('RGB')
img.crop((0, 0, 512,512)).save('./trainData/Images/{}.png'.format(idx))
img.crop((512, 0, 1024, 512)).save('./trainData/Sketches/{}.png'.format(idx))
# директория для валидации и теста
get_ipython().system('mkdir valData')
# предобработка и сохранение данных валидации и теста
for idx, file in tqdm(enumerate(glob.glob('val\*.png')[:23])):
img = Image.open(file).convert('RGB')
img.crop((0, 0, 512,512)).save('./valData/Images/{}.png'.format(idx))
img.crop((512, 0, 1024, 512)).save('./valData/Sketches/{}.png'.format(idx))
После сохранения эскизов и цветных изображений в отдельных каталогах мы нормализуем их так, чтобы все значения, что находились в диапазоне [0, 255] перешли в диапазон [- 1, 1].
def generate_samples(sketch_paths, image_paths, n_samples):
""" Загружает черно-белые наброски и цветные изображения
из переданных путей для обучения GAN.
Параметры:
sketch_paths(numpy.array): пути к черно-белым наброскам т.е. входные изображения
image_paths(numpy.array): пути к цветным изображениям, т.е. целевые изображения
n_samples(int): число образцов для обучения
Возвращает:
X_sketches(numpy.array): загруженные наброски
X_images(numpy.array): загруженные цветные изображения
"""
idxs = np.random.randint(0, TOTAL_IMAGES, n_samples)
X_sketches = []
X_images = []
for sket, img in zip(sketch_paths[idxs], image_paths[idxs]):
X_sketches.append(np.array(Image.open(sket).convert('RGB')))
X_images.append(np.array(Image.open(img).convert('RGB')))
# нормализация значения до диапазона [-1, 1].
X_sketches = (np.array(X_sketches, dtype='float32')-127.5)/127.5
X_images = (np.array(X_images, dtype='float32')-127.5)/127.5
return X_sketches, X_images
Нормализация цветовой шкалы необходима для эффективной работы функции активации выходного слоя. Пока лучшей функцией активации для GAN считается гиперболический тангенс.
2. Архитектура генератора
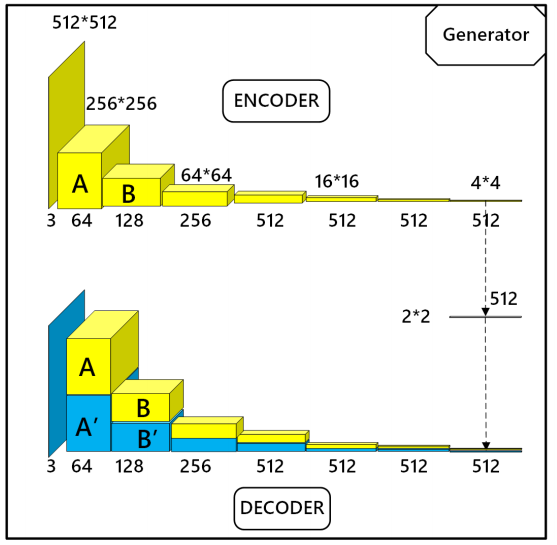
Архитектура генератора, который используется для раскраски эскиза представляет вариант архитектуры U-Net – полносвязной сверточной нейросети, разработанной в 2015 году для сегментации биомедицинских изображений.
def generator(drop_rate, alpha, inp_shape=(512, 512, 3)):
"""
Создает модель генератора, используя
Convolution и Convolution Transpose Blocks, определенные ранее.
Принимает входной эскиз со значениями в диапазоне [-1, 1] и генерирует
цветное изображение.
Параметры:
drop_rate (float): коэффициент отсева для регуляризации.
alpha (float): альфа-значение для активации LeakyReLu.
inp_shape (tuple): форма ввода для инициализации генератора.
Возвращает:
tenorflow.keras.Model: модель генератора, инициализированная структурой U-Net.
"""
n_filters = 16
inp = Input(inp_shape)
print('Encoder:')
conv1 = convBlock(inp, n_filters, BN=False, alpha=alpha)# 256x256
conv2 = convBlock(conv1, n_filters*2, alpha=alpha) # 128x128
conv3 = convBlock(conv2, n_filters*4, alpha=alpha) # 64x64
conv4 = convBlock(conv3, n_filters*8, alpha=alpha) # 32x32
conv5 = convBlock(conv4, n_filters*8, alpha=alpha) # 16x16
conv6 = convBlock(conv5, n_filters*8, alpha=alpha) # 8x8
conv7 = convBlock(conv6, n_filters*8, alpha=alpha) # 4x4
conv8 = convBlock(conv7, n_filters*8, alpha=alpha) # 2x2x512
print('Decoder:')
deconv1 = convTransBlock(conv8, n_filters*8, alpha=alpha) # 4x4
deconv2 = convTransBlock(deconv1, n_filters*8, convOut=conv7, dropout=drop_rate, alpha=alpha) # 8x8
deconv3 = convTransBlock(deconv2, n_filters*8, convOut=conv6, dropout=drop_rate, alpha=alpha) # 16x16
deconv4 = convTransBlock(deconv3, n_filters*8, convOut=conv5, dropout=drop_rate, alpha=alpha) # 32x32
deconv5 = convTransBlock(deconv4, n_filters*4, convOut=conv4, alpha=alpha) # 64x64
deconv6 = convTransBlock(deconv5, n_filters*2, convOut=conv3, alpha=alpha) # 128x128
deconv7 = convTransBlock(deconv6, n_filters, convOut=conv2, alpha=alpha) # 256x256
deconv8 = convTransBlock(deconv7, 3, convOut=conv1, activation=False, BN=False) # 512x512
outp = tanh(deconv8)
model = Model(inputs=inp, outputs=outp)
return model
Вместо использования полносвязных слоев в кодирующих-декодирующих блоках здесь чтобы не потерять информации используется свертка и деконволюция. В сравнении с другими задачами трансформации изображения Sketch2Color критически важно сохранить информацию о ребрах, образующих набросок. U-net архитектура используется для объединения слоев и декодера.
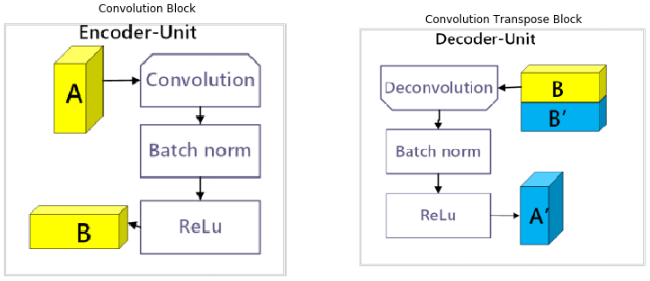
Как показано на изображении выше, на каждом слое декодирования (синие блоки) соответствующие слои кодера (желтые блоки) объединяются с текущим слоем для декодирования следующего слоя.
3. Архитектура дискриминатора
В отличие от генератора дискриминатор имеет только блоки кодера. Дискриминатор предназначен для классификации того, является ли входная пара «эскиз-цветное изображение» «реальными» или «поддельными». То есть получено ли цветное изображение из фактических данных или от генератора.

На вход дискриминатора поступает либо пара эскиза (на рисунке выше обозначен желтым цветом) и реального целевого изображения (красный), либо пара эскиза (желтый) и сгенерированного изображение (синий). Сеть дискриминатора обучена максимизировать точность классификации.
def discriminator(alpha, learning_rate, inp_shape=(512, 512, 3), target_shape=(512, 512, 3)):
"""
Функция для создания модели дискриминатора.
Эта функция определяет дискриминаторную часть GAN с заданным входом
shape & target shape с использованием определенных ранее сверточных блоков.
Принимает эскиз и целевое изображение / сгенерированное цветное изображение из генератора.
со значениями в диапазоне [-1, 1] и выводит вероятность того, что
реал / фейк в диапазоне [0, 1].
Параметры:
alpha (float): альфа-значение для активации LeakyReLu.
learning_rate (float): значение скорости обучения для оптимизатора дискриминатора.
inp_shape (tuple): форма ввода для инициализации генератора.
target_shape (tuple): форма целевого выходного изображения.
Возвращает:
tenorflow.keras.Model: инициализированная модель дискриминатора.
"""
n_filters = 16
inp1 = Input(inp_shape) # sketch input
inp2 = Input(target_shape) # colored input
inp = concatenate([inp1, inp2]) # 512x512
conv1 = convBlock(inp, n_filters, BN=False, alpha=alpha) # 256x256
conv2 = convBlock(conv1, n_filters*2, alpha=alpha) # 128x128
conv3 = convBlock(conv2, n_filters*4, alpha=alpha) # 64x64
conv4 = convBlock(conv3, n_filters*8, alpha=alpha) # 32x32
conv5 = convBlock(conv4, n_filters*8, filter_size=2, stride=1,\
padding='valid', alpha=alpha) # 31x31x512
conv6 = convBlock(conv5, n_filters=1, filter_size=2, stride=1,\
activation=False, BN=False, padding='valid') # 30x30x1
sigmoid_outp = sigmoid(conv6)
outp = GlobalAveragePooling2D()(sigmoid_outp)
model = Model(inputs=[inp1, inp2], outputs=outp)
opt = Adam(lr=learning_rate, beta_1=.5)
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy'])
return model
Выходные данные дискриминатора представляют собой матрицу вероятностей формы 30x30x1. В этой матрице каждый элемент соответствует вероятности того, что пара изображений это реальная пара эскиза и цветного аниме-изображения.
Здесь мы также избегаем использования полносвязных слоев здесь, чтобы избежать потери информации. Для получения единственного значения используем агрегацию посредством пулинга по среднему значению (global average pooling). Сверточные слои между входом и выходом извлекают высокоуровневые характеристики.
4. Функции потерь генератора и дискриминатора
Создать цветное изображение из черно-белого эскиза сложнее, чем из изображения в градациях серого, ведь такой рисунок содержит меньше полезной информации. Для создания дополнительных ограничений мы будем использовать условные порождающие состязательные сети (conditional GAN). Функция потерь для условных GAN в общем случае выглядит следующим образом:
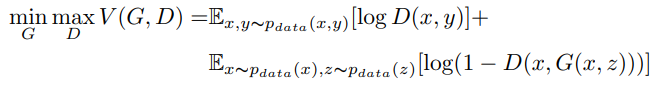
В этом выражении x – входной эскиз, y – цель (цветное мультипликационное изображение), G(x, z) – сгенерированное цветное изображение.
Условные GAN изучают отображение из вектора случайных чисел z в выходное изображение y по условиям, которые заданы эскизами x. В то время как генератор пытается минимизировать потери, дискриминатор пытается их максимизировать. Действуя совместно, они достигают равновесия.
Генератор минимизирует потери во время обучения, так что получаются правдоподобные цветные изображения. Вот его функция потерь:
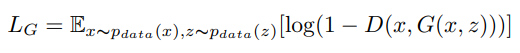
Одновременное обучение дискриминатора стимулирует вариативность в генерации цветных изображений. Однако получить реалистичные картинки удается, если сочетать потери GAN с традиционными функциями потерь.
Первая из таких функций потерь – PixelLevel, т.е. L1-расстояние между каждым пикселем целевого цветного изображения и сгенерированного аналога:

def pixelLevel_loss(y, g):
"""
Потеря для получения правильных изображений при сравнении пикселей.
Нестандартная функция потерь для перевода Pixel2Pixel, чтобы цвета не
вышли края сгенерированных изображений.
Параметры:
y (тензор): реальные целевые изображения для генерации.
g (тензор): вывод изображений генератором.
Возвращает:
функция: ссылка на функцию потерь прототипа, что требует Keras.
"""
import tensorflow.keras.backend as K
def finalPLLoss(y_true, y_pred):
return K.mean( K.abs( y - g ) )
return finalPLLoss
Вторая функция потерь FeatureLevel – L2-расстояние между активацией φj 4-го слоя 16-слойной VGG-сети, предварительно обученной на наборе данных ImageNet. Предобучение используется для сохранения высокоуровневых функций, таких как цвет и форма объектов. Соответствующая функция потерь:
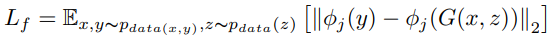
def pixelLevel_loss(y, g):
"""
Функция потерь для фич, извлеченных из 4-го слоя VGG16.
Пользовательские потери для извлечения высокоуровневых объектов целевых
цветных и сгенерированных цветных изображений.
Параметры:
y (Тензор): целевые изображения, которые будут созданы.
g (Тензор): вывод изображений генератором.
Возвращает:
функция: ссылка на функцию потерь прототипа,
который требует Keras.
"""
import tensorflow.keras.backend as K
def finalPLLoss(y_true, y_pred):
return K.mean( K.abs( y - g ) )
return finalPLLoss
Последняя из используемых функций потерь – TotalVariation. Эта функция необходима для того, чтобы GAN использовала палитры цветов, аналогичные данным обучающей выборки. Это действует как форма регуляризации и способствует плавности контуров изображений.
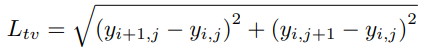
def totalVariation_loss(y, g):
"""
Функция потеря для гладкости и удаления шума из выходного изображения.
Нестандартная функция потерь для получения цветов как в обучающих данных.
Параметры:
y (тензор): выходные изображения.
g (тензор): вывод изображений генератора.
Возвращает:
функция: ссылка на функцию потерь прототипа,
геобходимая для Keras.
"""
import tensorflow.keras.backend as K
def finalTVLoss(y_true, y_pred):
return K.abs( K.sqrt( K.sum(K.square(g[:, 1:, :, :] - g[:, :-1, :, :])) +\
K.sum(K.square(g[:, :, 1:, :] - g[:, :, :-1, :])) ) )
return finalTVLoss
Функция потерь GAN представляет собой взвешенную комбинацию всех вышеуказанных потерь:
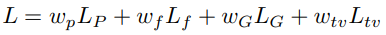
Веса Wp, Wf, Wg и Wtv учитывают важность каждого из видов потерь. Минимизируя функцию потерь L, GAN находит лучшие образцы пар эскиза и цветного изображения.
def define_gan(g_model, d_model, vgg_net1, vgg_net2, learning_rate, pixelLevelLoss_weight=100,\
totalVariationLoss_weight=.0001,featureLevelLoss_weight=.01, inp_shape=(512, 512, 3)):
"""
Эта функция определяет модель GAN, используя генератор и дискриминатор с
обновлением весов дискриминатора, замораживаемых во время обучения, так что градиенты
изменяются только у генератора.
Таким образом, дискриминатор не доминирует над генератором, а генератор никогда
не фиксирует распределение вероятностей для цветных изображений.
Параметры:
g_model (keras.Model): модель генератора, инициализированная ранее.
d_model (keras.Model): модель дискриминатора, инициализированная ранее.
vgg_net1 (keras.Model): модель VGG16 с выходом 4 слоя, инициализированная для
целевых изображений.
vgg_net2 (keras.Model): модель VGG16 с выходом 4 слоя, инициализированная для
сгенерированных изображений.
learning_rate (float): скорость обучения для оптимизатора модели.
pixelLevelLoss_weight (float): вес потери LevelLoss.
totalVariationLoss_weight (float): вес потери VariationLoss.
featureLevelLoss_weight (float): вес потери featureLevelLoss.
inp_shape (tuple): форма входа для инициализации модели GAN.
Возвращает:
tenorflow.keras.Model: Инициализированная модель GAN.
"""
d_model.trainable = False
# ======= Генератор ======= #
sketch_inp = Input(inp_shape)
gen_color_output = g_model([sketch_inp])
# ======= Дискриминатор ======= #
disc_outputs = d_model([sketch_inp, gen_color_output])
color_inp = Input(inp_shape)
# =================== Функция потерь PixelLevel =================== #
pixelLevelLoss = pixelLevel_loss(color_inp, gen_color_output)
# =================== Функция потерь TotalVariation=================== #
totalVariationLoss = totalVariation_loss(color_inp, gen_color_output)
# =================== Функция потерь FeatureLevel =================== #
net1_outp = vgg_net1([tf.image.resize(color_inp, (224, 224), tf.image.ResizeMethod.BILINEAR)])
net2_outp = vgg_net2([tf.image.resize(gen_color_output, (224, 224), tf.image.ResizeMethod.BILINEAR)])
featureLevelLoss = featureLevel_loss(net1_outp, net2_outp)
# =================== Конечная модель =================== #
model = Model(inputs=[sketch_inp, color_inp], outputs=disc_outputs)
opt = Adam(lr=learning_rate, beta_1=.5)
# Single output multiple loss functions in keras : https://stackoverflow.com/a/51705573/9079093
model.compile(loss=lambda y_true, y_pred : tf.keras.losses.binary_crossentropy(y_true, y_pred) + \
pixelLevelLoss_weight * pixelLevelLoss(y_true, y_pred) + \
totalVariationLoss_weight * totalVariationLoss(y_true, y_pred) + \
featureLevelLoss_weight * featureLevelLoss(y_true, y_pred),\
optimizer=opt)
return model
"""
Создание генератора, дискриминатора и GAN, которая использует их.
"""
vgg_net1 = Model(inputs=vgg.input, outputs=ReLU()(vgg.get_layer('block2_conv2').output))
vgg_net2 = Model(inputs=vgg.input, outputs=ReLU()(vgg.get_layer('block2_conv2').output))
g_model = generator(alpha=.2, drop_rate=.5)
d_model = discriminator(alpha=.2, learning_rate=.0002)
gan_model = define_gan(g_model, d_model, vgg_net1, vgg_net2, learning_rate=.0002,\
pixelLevelLoss_weight=100, totalVariationLoss_weight=.0001,\
featureLevelLoss_weight=.01)
5. Обучение генератора и дискриминатора
Генеративно-состязательная сеть была обучена за 43 эпохи с размером батча 8. В процессе обучения использовалось сглаживание меток, т.е. более «мягкие» метки (0,9 вместо 1).
Дискриминатор обучался меньше в случае четных батчей, так как когда генератор узнает больше о реальных и сгенерированных цветных изображениях, он начинает доминировать над генератором. Тогда генератор становится слабым и не обучается, лишь фиксируя распределение реальных целевых изображений.
def train(g_model, d_model, gan_model, sketch_paths, image_paths, latent_dim, seed_skets, seed_imgs, output_frequency, n_epochs=100, n_batch=128, init_epoch=0):
"""
Функция для процесса обучения GAN.
Определяет обучение дискриминатора и генератора поочередно
так что градиенты изменяются только в оном из них.
Также выводит потерю реальных и сгенерированных изображений дискриминатора для n-го батча.
Параметры:
g_model (keras.model): модель генератора для окрашивания.
d_model (keras.model): модель дискриминатора для обучения.
gan_model (keras.model): модель GAN для обучения.
sketch_paths (numpy.array): пути к черно-белым наброскам, т.е. входным изображениям.
image_paths (numpy.array): пути к цветным изображениям, то есть целевым изображениям.
latent_dim (int): размерности вектора z.
seed_skets (numpy.array): фиксированные черно-белые эскизы для проверки выходных сигналов генератора после каждой эпохи.
seed_imgs (numpy.array): фиксированные цветные изображения для проверки выходного сигнала генератора после каждой эпохи.
output_frequency (int): частота, с которой следует печатать значения потерь в консоли.
n_epochs (int): число эпох для обучения дискриминатора и GAN.
n_batch (int): размер пакета для каждой эпохи обучения.
init_epoch (int): начальная эпоха, с которой стартует процесс обучения,
полезно для возобновления тренировочного процесса с определенной эпохи.
"""
bat_per_epo = int(TOTAL_IMAGES / n_batch)
half_batch = int(n_batch / 2)
for i in range(init_epoch, n_epochs):
start = datetime.now()
gen_losses = []
dis_losses = []
for j in range(bat_per_epo):
# ======================== Обучаем дискриминатор на реальных изображениях ========================= #
if not j%2:
X_real_skets, X_real_imgs, y_real = generate_real_samples(sketch_paths, image_paths, half_batch)
d_loss1, _ = d_model.train_on_batch([X_real_skets, X_real_imgs], y_real * .9)
# ======================== Обучаем дискриминатор на сгенерированных изображениях ========================= #
X_fake_skets, X_fake_imgs, y_fake = generate_fake_samples(g_model, sketch_paths, image_paths,\
latent_dim, half_batch)
d_loss2, _ = d_model.train_on_batch([X_fake_skets, X_fake_imgs], y_fake)
d_loss = .5 * (d_loss1 + d_loss2)
# ======================== Обучаем генератор ========================= #
X_gan_skets, X_gan_imgs, _ = generate_fake_samples(None, sketch_paths, image_paths, latent_dim, n_batch)
y_gan = np.ones((n_batch, 1))
g_loss = gan_model.train_on_batch([X_gan_skets, X_gan_imgs], y_gan)
dis_losses.append(d_loss)
gen_losses.append(g_loss)
if not j % output_frequency:
print('>%d, %d/%d, d1=%.3f, d2=%.3f g=%.3f' %(i+1, j+1, bat_per_epo, d_loss1, d_loss2, g_loss))
# Сохранить потери в Tensorboard после каждой эпохи
write_log(tensorboard_disc_callback, 'discriminator_loss', np.mean(dis_losses), i+1, (i+1)%3==0)
write_log(tensorboard_gen_callback, 'generator_loss', np.mean(gen_losses), i+1, (i+1)%3==0)
# Показывает итог после каждой эпохи.
display.clear_output(True)
print('Time for epoch {} : {}'.format(i+1, datetime.now()-start))
print('>%d, %d/%d, d1=%.3f, d2=%.3f g=%.3f' %(i+1, j+1, bat_per_epo, d_loss1, d_loss2, g_loss))
summarize_performance(i, g_model, d_model, sketch_paths, image_paths, latent_dim, seed_skets, seed_imgs, seed_skets.shape[0])
display.clear_output(True)
print('>%d, %d/%d, d1=%.3f, d2=%.3f g=%.3f' %(i+1, j+1, bat_per_epo, d_loss1, d_loss2, g_loss))
summarize_performance(i, g_model, d_model, sketch_paths, image_paths, latent_dim, seed_skets, seed_imgs, seed_skets.shape[0])
Для обучения использовался оптимизатор Adam с learning rate = 0.0002 и beta_1 = 0.5.
Дискриминатор и генератор обучались поочередно в цикле: сначала дискриминатор, затем генератор, затем снова дискриминатор и т. д.
6. Работа с TensorBoard
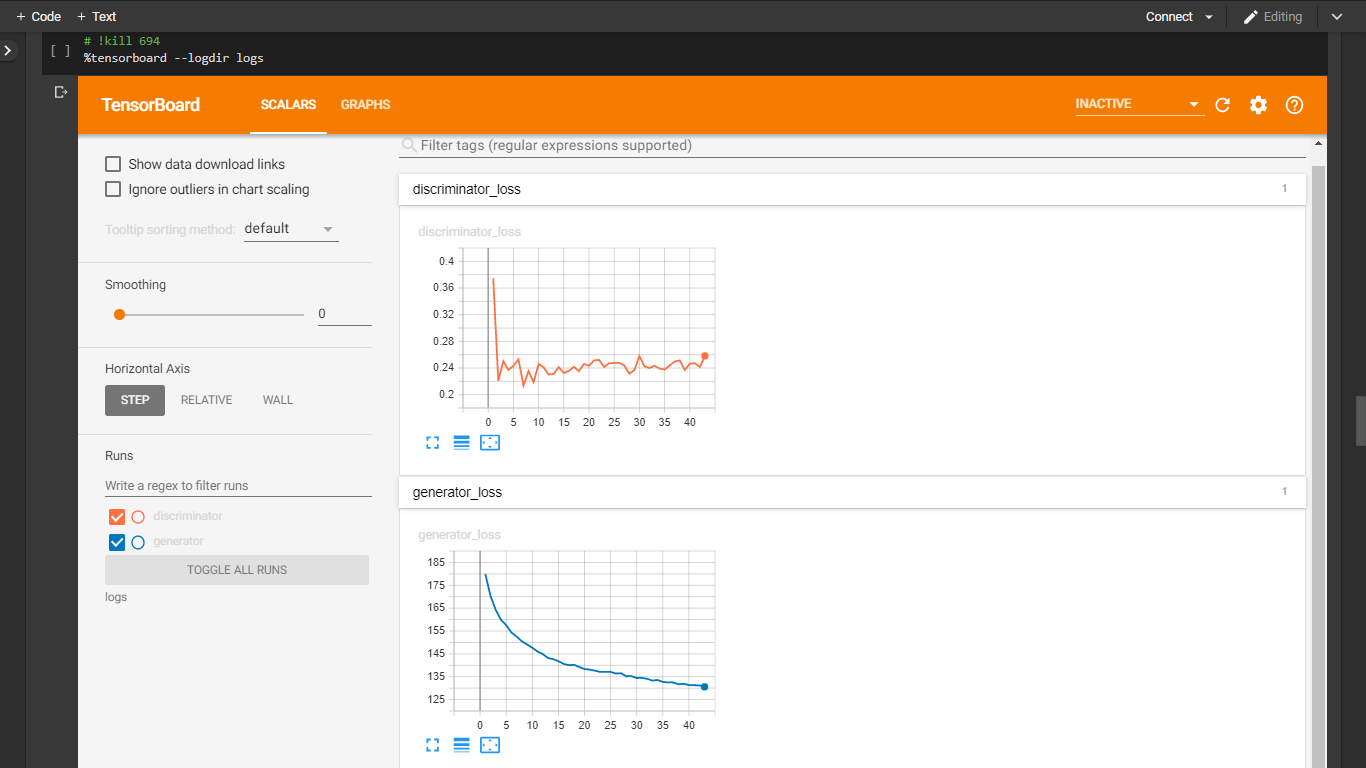
В каждом батче после обучения рассчитывались потери дискриминатора (или генератора) на парах изображений. Средние потери дискриминатора и генератора регистрировались после каждой эпохи, чтобы отслеживать их прогресс с помощью обратных вызовов TensorBoard.
Запускаем расширение блокнота для TensorBoard.
%load_ext tensorboard
# Колбэки TensorBoard для логгирования потерь генератора и дискриминатора.
tensorboard_gen_callback = TensorBoard(log_dir="logs/generator/")
tensorboard_gen_callback.set_model(g_model)
tensorboard_disc_callback = TensorBoard(log_dir="logs/discriminator/")
tensorboard_disc_callback.set_model(d_model)
# Запускаем TensorBoard.
%tensorboard --logdir logs
В соответствии с ожиданиями потери дискриминатора колеблются между 0.23 и 0.35, а потери генератора стабильно уменьшаются. То есть генератор фиксирует распределение реальных целевых изображений.
7. Результаты обучения
После каждой эпохи генератор проверялся на прогнозирование цветов для фиксированных эскизов, чтобы проверить, узнает ли он корреляции между эскизом и связанным с ним цветным изображением.
def save_plot(predictions, epoch, n=3):
"""
Функция сохранения промежуточных прогнозов.
Функция сохраняет график созданных генератором цветных изображений
для начальных / фиксированных эскизов, которые загружаются перед началом обучения.
Параметры:
predictions (numpy.array): цветные изображения от генератора.
epoch (int): эпоха, в которую генерируются цветные изображения.
n (int): количество созданных цветных изображений.
"""
n = int(math.sqrt(n))
plt.figure(figsize=(6, 6))
# Масштабируемся обратно к [0, 255] от [-1, 1].
predictions = (predictions + 1) / 2.0
for i in range(n * n):
plt.subplot(n, n, 1 + i)
plt.axis('off')
plt.imshow(predictions[i])
filename = './Sketch2Image/generated_plot_e%03d.png' % (epoch+1)
plt.savefig(filename)
plt.show()
Ниже представлены примеры результатов для 30-й, 40-й и 43-й эпох обучения.


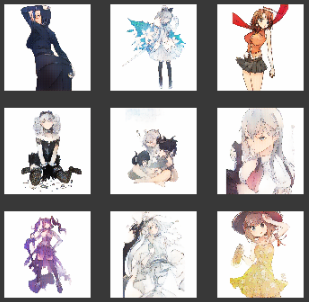
По мере обучения цвета становятся более правдоподобными, не выходят за границы и распределяются немонотонно.
8. Вывод результатов
Наконец, обучение завершено. Сделаем вывод генератора для эскизов образцов.
# Число скетчей для обработки
k = 10
test_skets = []
idxs = np.random.randint(2335, TOTAL_IMAGES - 2335, k)
for sket, img in zip(sketch_paths[idxs], img_paths[idxs]):
test_skets.append(np.array(Image.open(sket).convert('RGB')))
# Масштабируемся так, чтобы все значения находились в диапазоне [-1, 1].
test_skets = np.array(temp_skets, dtype='float32')/127.5 - 1
# Предсказываем цвета для скетчей
pred = g_model.predict(test_skets)
# Масштабируемся обратно к [0, 255]
pred = (pred+1)/2.0
test_skets = (test_skets+1)/2.0
# Строим сгенерированные цветные изображения.
f, a = plt.subplots(k, 2, figsize=(12,60)); a = a.flatten()
idx = 0
for sket, pic in zip(temp_skets, pred):
a[idx].imshow(sket); a[idx].axis('off')
a[idx+1].imshow(pic); a[idx+1].axis('off')
idx += 2
plt.subplots_adjust(wspace=.1, hspace=.1)
plt.show()


Генератор выдает разумные цвета для заданных простых набросков. Генеративно-состязательная сеть обучилась на 13 тысячах пар эскизов и цветных изображений. Результат можно улучшить, собирая и добавляя дополнительные пары изображений в обучающие данные.
Полный код в формате Jupyter-блокнота находится в репозитории GitHub.
Комментарии