

Современные рекомендательные системы
Не далее чем в мае 2019 Facebook выложил в открытый доступ исходный код некоторых своих подходов к рекомендациям и представил DLRM (Deep-Learning Recommendation Model – рекомендательную модель глубокого обучения). Эта статья попробует объяснить, как и почему DLRM и другие современные подходы к рекомендациям работают настолько хорошо, посредством анализа их происхождения от прежних результатов в данной области и детального объяснения внутренних деталей их работы и заложенных в них идей.

Персонализированная реклама, основанная на ИИ, сегодня царствует в онлайн-маркетинге, и такие компании, как Facebook, Google, Amazon, Netflix и прочие – короли джунглей этого онлайн-маркетинга, поскольку они не просто усвоили этот тренд, а фактически сами воплотили его в жизнь и построили на нем всю свою бизнес-стратегию. Netflix'овские "другие фильмы, которые могут вам понравиться" и Amazon'овские "люди, купившие это, купили также..." – всего лишь несколько примеров из реального мира.
Само собой, будучи постоянным пользователем Facebook и Google, в какой-то момент я спросил себя:
КАК ИМЕННО ЭТА ШТУКА РАБОТАЕТ?
И, разумеется, мы все уже видели базовый пример рекомендации фильмов, объясняющий, как работают коллаборативная фильтрация и факторизация матриц. Я также не говорю о подходе обучения простого классификатора для каждого пользователя, который будет выдавать вероятность того, что этому пользователю понравится тот или иной продукт. Эти два подхода, называемые коллаборативной фильтрацией и рекомендацией, основанной на контексте, наверняка более-менее эффективны и выдают предсказания, которые можно использовать, но у Google, Facebook и прочих наверняка должно быть что-нибудь получше, какой-нибудь "туз в рукаве", иначе они бы не были там, где они находятся сейчас.
Чтобы понять, откуда происходят современные передовые рекомендательные системы, нам придется взглянуть на два основных подхода к задаче
предсказания, насколько данному пользователю понравится данный продукт,
которая в мире онлайнового маркетинга складывается в предсказание показателя кликабельности (click-through rate, CTR) для возможных рекламных объявлений, основанное как на явной обратной связи (рейтинги, лайки и т.п.), так и на неявной (клики, истории поиска, комментарии или посещения веб-сайтов).
Коллаборативная фильтрация против фильтрации на основе содержимого
1. Фильтрация на основе содержимого (content-based filtering)
Грубо говоря, рекомендация на основе содержимого пытается предсказать, понравится ли пользователю некоторый продукт, используя его онлайновую историю. Это включает, помимо всего прочего, поставленные пользователем лайки (например, на Facebook), ключевые слова, которые он искал (например, в Google), а также простые клики и посещения определенных веб-сайтов. В конечном счете она концентрируется на собственных предпочтениях каждого пользователя. Мы можем, например, построить простой бинарный классификатор (или регрессор), предсказывающий ожидаемый уровень кликабельности (или рейтинг) определенной группы рекламных объявлений для данного пользователя.
2. Коллаборативная фильтрация
Коллаборативная фильтрация пытается предсказать, может ли пользователю понравиться определенный продукт, путем анализа предпочтений похожих пользователей. Здесь мы можем подумать об уже привычном для нас (по примеру рекомендации фильмов) подходе факторизации матриц (matrix factorization – MF), при котором матрица рейтингов приводится к одной матрице, описывающей пользователей и другой, описывающей фильмы.
Недостаток классической MF в том, что мы не можем использовать никакие признаки, кроме пользовательских оценок – например, жанр фильма, год выхода и т.д. – MF приходится догадываться обо всем этом из имеющихся оценок. Кроме того, MF страдает от так называемой "проблемы холодного старта": новый фильм, который еще никто не оценил, не может быть рекомендован. Фильтрация на основе содержимого справляется с этими двумя проблемами, но ей не хватает предсказательной мощности просмотра предпочтений других пользователей.
Преимущества и недостатки этих двух различных подходов очень ясно демонстрируют необходимость комбинированного подхода, в котором обе идеи каким-то образом будут использованы в одной и той же модели. Поэтому далее в этой статье будут рассмотрены гибридные модели рекомендации.
1. Машина Факторизации (Factorization Machine)
Одна из идей гибридной модели, предложенная Стеффеном Рендлом в 2010-м – это Машина Факторизации. Она придерживается базового математического подхода, комбинируя факторизацию матриц с регрессией:
Здесь <vi, vj> – произведение векторов, которые можно рассматривать как строки матрицы V.
Понять смысл этого уравнения довольно просто, если посмотреть на пример представления данных x, попадающих в эту модель. Давайте рассмотрим пример, представленный Стеффеном в его статье о Машине Факторизации.
Предположим, у нас есть следующие данные об обзорах фильмов, где пользователи ставят фильмам оценки в определенное время:
- пользователь u из множества U = {Alice (A), Bob (B),...}
- фильм i из множества I = {"Титаник" (TN), "Ноттинг Хилл" (NH), "Звездные Войны" (SW), "Стар Трек" (ST),...}
- оценка r из {1, 2, 3, 4, 5}, поставленная во время t.

Посмотрев на приведенный выше рисунок, мы увидим представление данных в гибридной рекомендательной модели. Как разреженные признаки, представляющие пользователя и оцениваемый объект, так и любая другая дополнительная информация об объекте или мета-информация (в этом примере – Time и Last Movie Rated) попадают в вектор признаков x, который соответствует значению целевой переменной y. Теперь главное – то, как они обрабатываются моделью.
- Регрессионая часть FM обрабатывает и разреженные, и плотные данные (например, Time), как обычная задача линейной регрессии, и, таким образом, может считаться подходом фильтрации на основе содержимого в составе FM.
- Часть MF отвечает за взаимодействие между блоками признаков (например, взаимодействие между "Пользователем" и "Фильмом"), где матрицу V можно рассматривать как встроенную матрицу, используемую в подходах коллаборативной фильтрации. Эти отношения пользователь-фильм предоставляют нам догадки вроде:
Пользователю i, которому соответствует вектор vi (представляющий его предпочтения к параметрам фильмов), похожий на вектор vj пользователя j, скорее всего, понравятся те же фильмы, что и пользователю j.
Сложение вместе предсказаний регрессионной части и части MF и одновременное обучение их параметров в одной функции потерь приводит к гибридной модели FM, которая теперь использует подход "лучшее из обоих миров" для выдачи рекомендации пользователю.
Однако, несмотря на то, что подход Машины Факторизации с первого взгляда кажется "лучшей моделью из обоих миров", многие области ИИ, такие, как обработка естественного языка или машинное зрение, давно доказали, что
если взять нейронную сеть, то будет еще лучше!
2. Широкие и глубокие: нейронная коллаборативная фильтрация (NCF) и Глубокие Машины Факторизации (DeepFM)
Для начала бросим взгляд на то, как можно реализовать коллаборативную фильтрацию с помощью нейронных сетей, просмотрев статью об NCF. В конце концов это приведет нас к Глубоким Машинам Факторизации (DeepFM), представляющим собой нейросетевую версию машин факторизации. Мы увидим, почему они превосходят обычные машины факторизации, и как можно интерпретировать архитектуру этих нейронных сетей. Мы увидим, что DeepFM была разработана как улучшение вышедшей до этого модели Wide&Deep от Google, которая была одним из первых крупных прорывов в области глубокого обучения рекомендательных систем. В конце концов это приведет нас к упомянутой выше статье по DLRM, опубликованной Facebook'ом в 2019-м, которую можно считать упрощением и небольшим усовершенствованием DeepFM.
NCF
В 2017-м группа исследователей опубликовала свою работу о Нейронной Коллаборативной Фильтрации (NCF). Она содержит обобщенный фреймворк для изучения нейронных зависимостей, моделируемых факторизацией матриц при коллаборативной фильтрации с помощью нейронной сети. Авторы также объяснили, как получить зависимости высшего порядка (MF имеет порядок всего лишь 2), и как объединить оба эти подхода.
Общая идея заключается в том, что нейронная сеть может (теоретически) усвоить любую функциональную зависимость. Это значит, что зависимость, которую модель коллаборативной фильтрации выражает матричной факторизацией, может быть усвоена нейронной сетью. NCF предлагает простой слой представления сразу для пользователей и объектов (похожий на классическую факторизацию матриц), за которым следует простая нейронная сеть вроде многослойного перцептрона, которая должна усвоить зависимость между представлениями пользователя и объекта, аналогичную произведению факторизованных матриц.
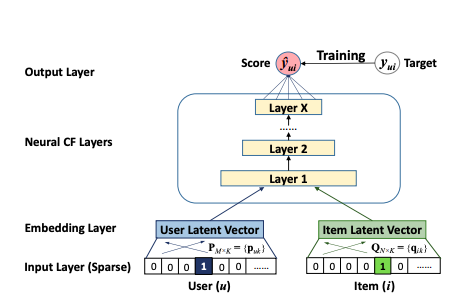
Преимущество этого подхода заключается в нелинейности многослойного перцептрона. Простое произведение матриц, используемое при матричной факторизации, всегда будет ограничивать модель взаимодействиями 2-й степени, тогда как нейронная сеть с X слоями в теории может усвоить взаимодействия гораздо более высоких степеней. Представьте себе, например, три качественные переменные, все имеющие взаимодействия друг с другом – например, мужской пол, подростковый возраст и ролевые компьютерные игры.
В реальных задачах мы не просто используем двоичные векторы, соответствующие пользователю и объекту в качестве необработанных данных для их представления, но, очевидно, включаем и прочую дополнительную или мета-информацию, которая может представлять ценность (например, возраст, страну, аудио- и текстовые записи, метки времени,...), так что в реальности у нас получается набор данных очень высокой размерности, сильно разреженный и содержащий смесь качественных переменных с количественными. К этому моменту представленную на рис. 2 нейронную сеть можно считать и рекомендацией на основе содержимого в виде простого нейронного бинарного классификатора прямого прохода. И эта интерпретация – ключевая для понимания того, почему этот подход в конце концов оказывается гибридным между коллаборативной фильтрацией и рекомендациями на основе содержимого. Эта нейронная сеть может усвоить любые функциональные зависимости – например, взаимодействия 3-й степени и выше, вроде x1 * x2 * x3, или любые нелинейные трансформации в классическом понимании, используемом в нейронных классификаторах – в виде sigma(.. sigma(w1x1+w2x2+w3x3+b)).
Вооружившись мощью изучения зависимостей высшего порядка, мы можем использовать простой способ изучения зависимостей 1-го и 2-го порядков, скомбинировав нейронную сеть с широко известной моделью для их изучения, Машиной Факторизации. Именно это авторы DeepFM предложили в своей статье. Идея этой комбинации – параллельно изучать зависимости между признаками низких и высоких порядков – ключевая часть многих современных рекомендательных систем, и в том или ином виде ее можно найти почти в каждой архитектуре нейронной сети, предлагаемой в этой области.
DeepFM
DeepFM – это смешанный подход, включающий факторизацию матриц и глубокую нейронную сеть, причем оба используют один и тот же входной слой представления (embedding). Необработанные признаки трансформируются, чтобы закодировать категориальные признаки унитарным кодом (one-hot encoding). Итоговое предсказание (показатель кликабельности), выдаваемое последним словом нейронной сети, определяется так:
То есть, это сумма предсказаний матричной факторизации и нейронной сети, пропущенная через сигмоидную функцию активации.
Компонент факторизации матриц – это обычная Машина Факторизации, оформленная в стиле архитектуры нейронной сети:
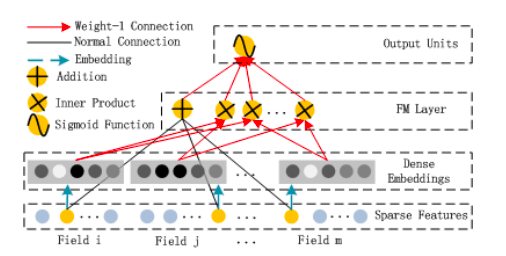
Часть сложения (Addition) этого слоя матричной факторизации получает вектор входных данных x от слоя разреженных признаков (Sparse Features) и умножает каждый элемент на его вес (Normal Connection) перед суммированием. Часть перемножения векторов (Inner Product) также получает вектор x, но только после его прохождения через слой представления и просто перемножает представленные векторы без весов ("Weight-1 Connection"). Сложение обеих частей вместе приводит к вышеупомянутому уравнению для Машины Факторизации:
В этом уравнении перемножение xixj нужно только для записи суммы от 1 до n. Оно не является частью вычислений нейронной сети. Нейронная сеть автоматически знает, произведение каких векторов vi и vj потребуется, благодаря архитектуре слоя представления.
Архитектура слоя представления выглядит следующим образом:
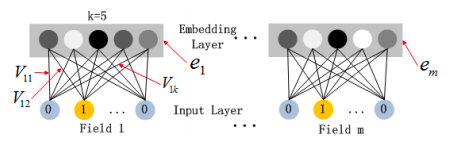
Здесь Vp – матрица представлений для каждого поля p={1,2...,m} c k столбцами и количеством строк, соответствующим количеству элементов поля, закодированных двоичным образом. Выход этого слоя представления определяется как
и важно отметить, что этот слой не полносвязный, а именно – нет связей между необработанным входом любого поля и представлением любого другого поля. Представьте это следующим образом: вектор значений для пола (например, (0, 1)), закодированный унитарным кодом, не может иметь ничего общего с вектором представлений для дня недели (например, вектором (0, 1, 0, 0, 0, 0, 0), закодированный "Вторник", или его вектором представления, например, для k=4, (12, 4, 5, 9).
Компонент FM – это Машина Факторизации, отражающая высокую важность взаимодействий 1 и 2 порядка, которые прямо складываются с выходом глубокого компонента и передаются в сигмоидную функцию активации последнего слоя.
Глубоким компонентом, как предполагается, теоретически может быть нейронная сеть любой архитектуры. Авторы рассмотрели стандартный многоуровневый перцептрон прямого прохода (а также так называемую PNN). Стандартный многоуровневый перцептрон изображен на следующем рисунке:
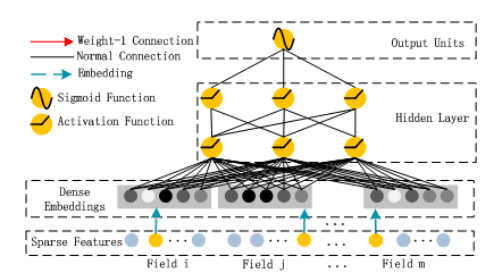
Нейронная сеть на основе стандартного многослойного перцептрона со слоем представления между необработанными данными (сильно разреженными после унитарного кодирования категориальных переменных) и следующими слоями нейронной сети описывается следующей формулой:
где sigma – функция активации, W – матрица весов, a – результат функции активации предыдущего слоя, а b – порог.
Это приводит к общей архитектуре нейронной сети DeepFM:
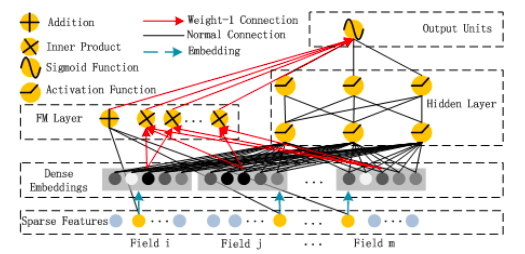
со следующими параметрами:
- Скрытый вектор Vi для измерения влияния взаимодействий признака i с другими признаками (слой представления).
- Vi передается в компонент FM для моделирования взаимодействий 2 порядка (компонент FM).
- wi взвешивает важность необработанного признака i 1-го порядка (компонент FM).
- Vi также передается в Глубокий компонент для моделирования всех взаимодействий высших порядков (>2)(Глубокий компонент).
- WI и bI – веса и пороги нейронной сети (Глубокий компонент).
Ключ к одновременному получению взаимодействий высших и низших порядков – это одновременное обучение всех параметров под одной функцией потерь, используя один и тот же слой представления как для компонента FM, так и для Глубокого компонента.
Сравнение с Wide&Deep и NeuMF
Есть много вариаций, о которых можно задуматься, чтобы "отполировать" эту архитектуру и сделать ее еще лучше. Однако в основном все они сходятся в своем гибридном подходе, заключающемся в одновременной обработке взаимодействий высших и низших порядков. Авторы DeepFM также предложили замену многоуровневого перцептрона на так называемую PNN, глубокую нейронную сеть, получающую в качестве входных данных выводы FM и слоя представления.
Авторы статьи про NCF также предложили похожую архитектуру, которую они назвали NeuMF (Neural Matrix Factorization – нейронная факторизация матриц). Вместо использования FM в качестве компонента низшего порядка они используют обычную факторизацию матриц, результаты которой передаются в функцию активации. Этому подходу, однако, не хватает взаимодействий 1 порядка, моделируемых линейной частью FM. Авторы также указали, что модель имеет различные представления пользователя и объекта для матричной факторизации и многослойного перцептрона.
Как упомянуто выше, команда исследователей Google была одной из первых, предложивших нейронные сети для гибридного подхода к рекомендации. DeepFM можно рассматривать как дальнейшеее развитие алгоритма Wide&Deep от Google, который выглядит примерно так:
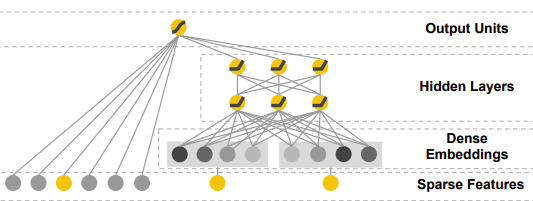
На правой стороне находится уже хорошо известный нам многоуровневый перцептрон со слоем представления, но на левой стороне находятся иные, сконструированные вручную входные параметры, которые напрямую направляются к конечному выходному слою. Взаимодействия низкого порядка в виде операций произведения векторов скрыты в этих сконструированных вручную параметрах, которые, по словам авторов, могут быть многими различными вещами, например:
Это выражает взаимодействие между d признаками (с предшествующим представлением признаков или без него), умножая их друг на друга (показатель степени равен 1, если xi является частью k-й трансформации).
Легко видеть, что DeepFM является развитием этой модели, поскольку она не требует никакого предварительного конструирования признаков и может обучиться взаимодействиям низкого и высокого порядка на основе одних и тех же входных данных, разделяющих один и тот же слой представления. DeepFM действительно содержит Машину Факторизации как часть основной сети, тогда как Wide&Deep не выполняет произведение векторов в какой-либо части сети, а делает это предварительно на шаге конструирования признаков.
3. DLRM – рекомендационная модель глубокого обучения
Ну что ж, рассмотрев различные варианты от Google, Huawei (команда исследователей, стоящая за архитектурой DeepFM) и прочих, давайте познакомимся с видением исследователей Facebook. Они опубликовали свою статью о DLRM в 2019-м, и она в основном фокусируется на практической реализации этих моделей. Решения с параллельным обучением, переложение расчетов на GPU, а также различная обработка постоянных и категориальных признаков.
Архитектура DLRM описана на следующем рисунке и работает следующим образом: каждый категориальный признак представлен вектором представления, а постоянные признаки обрабатываются многослойным перцептроном таким образом, чтобы на выходе получались векторы такого же размера, как и векторы представления. На второй стадии рассчитываются взаимные произведения всех векторов представления и выходных векторов перцептрона. После этого произведения соединяются вместе и передаются в другой многослойный перцептрон, а в конце концов – в функцию сигмоиды, выдающую вероятность.
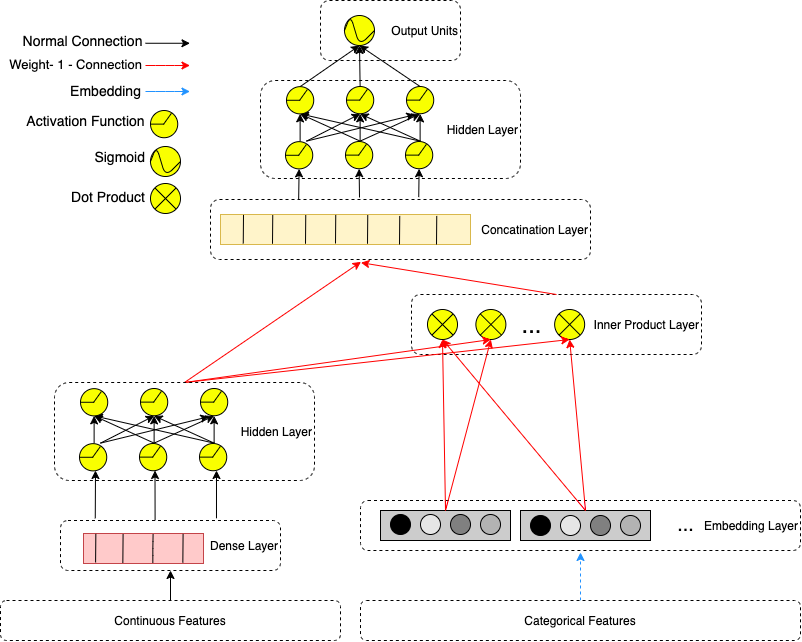
Предложение DLRM – это нечто вроде упрощенной и модифицированной версии DeepFM в том смысле, что оно также использует произведение векторов, но намеренно пытается держаться подальше от взаимодействий высших порядков, не обязательно прогоняя представленные категориальные признаки через многослойный перцептрон. Такой дизайн предназначен для копирования подхода, используемого в Машине Факторизации, когда она рассчитывает взаимодействия второго порядка между представлениями. Мы можем рассматривать всю DLRM как отдельную часть DeepFM, компонент FM. Можно считать, что классический Глубокий компонент DeepFM, вывод которого складывается с выводом компонента FM в финальном слое DeepFM (а потом передается в функцию сигмоиды) в DLRM полностью отсутствует. Теоретические преимущества DeepFM очевидны, поскольку ее дизайн намного лучше приспособлен для изучения взаимодействий высших порядков, однако, по мнению специалистов Facebook:
"взаимодействия выше второго порядка, используемые в других сетях, не обязательно стоят дополнительных затрат вычислительной мощности и памяти".
4. Обзор и кодирование
Представив различные подходы к глубокой рекомендации, их теоретические основы, преимущества и недостатки, я был просто вынужден взглянуть на предлагаемую реализацию DLRM на PyTorch на GitHub-странице Facebook.
Я изучил детали реализации и протестировал предлагаемые специальные API наборов данных, которые авторы создали для прямой обработки различных наборов данных. Как соревнование по рекламе дисплеев на Kaggle от Criteo, так и их набор данных Terabyte имеют готовые реализации API, их можно загрузить и впоследствии использовать для обучения полной DLRM всего одной командой bash (инструкции см. в репозитории DLRM). Затем я расширил API модели DLRM от Facebook, добавив шаги загрузки и предварительной обработки для другого набора данных, "Предсказание показателя кликабельности для рекламы DIGIX в 2020". Результат можно найти здесь.
Примерно так же, как и для приведенных авторами примеров, после загрузки и распаковки данных DIGIX, вы также сможете обучить модель на этом наборе данных одной командой bash. Все шаги предварительной обработки, размеры представлений и параметры архитектуры нейронной сети были настроены на обработку набора данных DIGIX. Блокнот, который проведет вас по этим шагам, можно найти здесь. Эта модель выдает приличные результаты, и я продолжаю над ней работать с целью улучшения производительности посредством лучшего понимания необработанных данных и процесса работы с рекламными объявлениями, используемого в DIGIX. Специализированная очистка данных, настройка гиперпараметров и конструирование признаков – все это вещи, над которыми я хотел бы еще поработать, и они упомянуты в блокноте. Моей первой целью было технически рациональное расширение API модели DLRM, способное использовать необработанные данные DIGIX в качестве входных данных.
В конечном счете, я верю, что гибридные глубокие модели – один из самых мощных инструментов для решения задач рекомендации. Однако недавно появилось и несколько действительно интересных и креативных подходов к решению задач коллаборативной фильтрации с помощью автоэнкодеров. Поэтому на данный момент я могу только гадать, что же софтверные гиганты используют сегодня, чтобы скармливать нам рекламу, на которой мы щелкнем мышью с максимальной вероятностью. Полагаю, это вполне может быть комбинация вышеупомянутого подхода автоэнкодеров и какой-то формой глубокой гибридной модели, представленной в этой статье.
Ссылки
Стеффен Рендл, "Машины факторизации", Международная конференция IEEE по Data Mining, стр. 995-1000, 2010.
Ксианьян Хе, Лизи Ляо, Ханванг Жанг, Ликианг Ли, Ксиа Ху и Тат-Сенг Чуа. "Нейронная коллаборативная фильтрация", Материалы 26-й международной конференции по World-Wide Web, стр. 173-182, 2017.
Хуифенг Гуо, Руиминг Тэнг, Юнминь Е, Женгуо Ли и Ксиукианг Хе. "DeepFM: нейронная сеть для предсказания показателя кликабельности, основанная на машине факторизации", препринт arXiv:1703.04247, 2017.
Джианксун Лиан, Ксиаохуан Жоу, Фуженг Жанг, Жонгксиа Чен, Ксинг Кси и Гуангжонг Сун. "xDeepFM: комбинируем явные и неявные взаимодействия признаков для рекомендательных систем", в Материалах 24-й международной конференции ACM SIGKDD по исследованию знаний и Data Mining, стр. 1754–1763. ACM, 2018.
Хенг-Це Ченг, Левент Коц, Джеремия Хармсен, Тал Шакед, Тушар Чандра, Хриши Арадхье, Глен Андерсон, Грег Коррадо, Вей Чай, Мустафа Испир, Рохан Анил, Закария Хак, Личан Хонг, Вихан Джайн, Ксяобинг Лю и Хемаль Шах. "Широкое и глубокое обучение для рекомендательных систем", в материалах 1-го семинара по глубокому обучению рекомендательных систем", стр. 7-10, 2016.
М. Наумов, Д. Мудигер, Х.М. Ши, Дж. Хуанг, Н. Сундараман, Дж. Парк, Кс. Ванг, У. Гупта, Ц. Ву, А.Г. Аццолини, Д. Джулгаков, А. Малевич, И. Чернавский, Ю. Лю, Р. Кришнамурти, А. Ю, В. Кондратенко, С. Перейра, Кс. Чен, В. Чен, В. Рао, Б. Джиа, Л. Ксионг и М. Смелянский "Рекомендационная модель глубокого обучения для систем персонализации и рекомендации", CoRR, vol. abs/1906.00091, 2019. [Онлайн]. Доступна здесь.
Комментарии