
Как работает фреймворк Apache Spark? В статье рассмотрим, что прячется под капотом этого инструмента для кластерных вычислений.

В предыдущей статье познакомились с проблемой – обильные, бесконечные потоки данных – и её решением: фреймворк Apache Spark. Здесь, во второй части, сосредоточимся на внутренней архитектуре Spark и структурах данных.
"Первооткрыватели использовали волов для перевозки тяжёлых грузов. И когда вол не мог сдвинуть бревно с места, они не пытались вырастить вола покрупнее. Нам стоит стремиться не к повышению мощности одного компьютера, а к увеличению количества компьютерных систем." – Грейс Хоппер
Поскольку масштабы данных росли стремительными и зловещими темпами, понадобился способ быстрой обработки вероятных петабайт данных. И невозможно было добиться, чтобы один компьютер обрабатывал такой объём с разумной скоростью. Эта проблема решается путём создания кластера машин для выполнения работы. Но как эти машины работают вместе для решения общей проблемы?
Встречайте фреймворк Spark

Spark – фреймворк для кластерных вычислений и крупномасштабной обработки данных. Spark предлагает набор библиотек на 3 языках (Java, Scala, Python) для унифицированного вычислительного движка. Что на самом деле это означает?
Унифицированный: в Spark нет необходимости собирать приложение из нескольких API или систем. Spark предоставляет встроенные API для выполнения работы.
Вычислительный движок: Spark поддерживает загрузку данных из различных файловых систем и выполняет в них вычисления, но сам не хранит никаких данных постоянно. Spark работает исключительно в памяти, что даёт беспрецедентную производительность и скорость.
Библиотеки: фреймворк Spark состоит из ряда библиотек, которые созданы для решения задач Data Science. Spark включает библиотеки для SQL (SparkSQL), машинного обучения (MLlib), обработки потоковых данных (Spark Streaming и Structured Streaming) и обработки графов (GraphX).
Приложение Spark
Каждое Spark-приложение состоит из управляющего процесса – драйвера (Driver) – и набора распределённых рабочих процессов – исполнителей (Executors).
Spark Driver
Driver запускает метод main() нашего приложения. Здесь создаётся SparkContext. Обязанности Spark Driver:
- Запускает задание на узле в нашем кластере или на клиенте и планирует его выполнение с помощью менеджера кластера
- Отвечает на пользовательскую программу или ввод
- Анализирует, планирует и распределяет работу между исполнителями
- Хранит метаданные о запущенном приложении и отображает в веб-интерфейсе
Spark Executors
Исполнитель (Executor) – распределённый процесс, который отвечает за выполнение задач. У каждого приложения Spark собственный набор исполнителей. Они работают в течение жизненного цикла отдельного приложения Spark.
- Исполнители делают всю обработку данных задания Spark.
- Сохраняют результаты в памяти, а на диске – только тогда, когда это специально указывается в программе-драйвере (Driver Program).
- Возвращает результаты драйверу после их завершения.
- Каждый узел может иметь от 1 исполнителя на узел до 1 исполнителя на ядро.
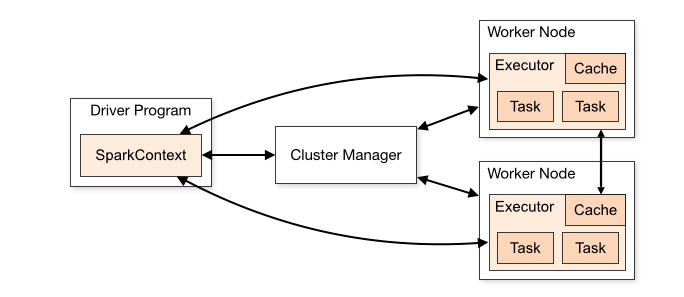
Workflow приложения Spark
Когда отправляем задание в Spark для обработки, многое остаётся за кулисами.
- Наше автономное приложение запускается и инициализирует SparkContext. Только при наличии SparkContext приложение называется драйвером.
- Наша программа-драйвер (Driver program) запрашивает у менеджера кластеров (Cluster Manager) ресурсы для запуска исполнителей.
- Менеджер кластеров запускает исполнителей.
- Наш драйвер запускает собственно код Spark.
- Исполнители запускают задания и отправляют результаты драйверу.
- SparkContext останавливается, а исполнители закрываются и возвращают ресурсы обратно в кластер.
Пересмотр MaxTemperature
Присмотритесь к заданию Spark, которое писали в первой части, для поиска максимальной температуры по стране. Эта абстракция скрывает много кода настройки, включая инициализацию SparkContext, заполним пробелы:
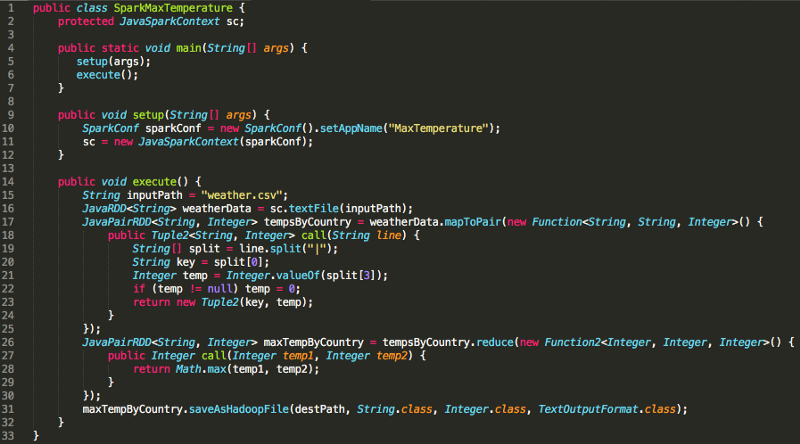
Помните, что Spark – фреймворк, в этом случае реализованный на Java. И до строки 16 Spark не должен ничего делать. Конечно, до этого мы инициализировали SparkContext, однако загрузка данных в RDD – первый фрагмент кода, который требует отправки работы нашим исполнителям.
К этому времени термин «RDD» встречался многократно, пора дать ему определение.
Обзор архитектуры Spark
Чёткая многоуровневая архитектура Spark со слабосвязанными компонентами основывается на двух главных абстракциях:
- Устойчивые распределённые наборы данных (RDD – Resilient Distributed Datasets)
- Направленный ациклический граф (DAG – Directed Acyclic Graph)
Устойчивые распределённые наборы данных
RDD – строительные блоки Spark: всё состоит из них. Даже высокоуровневые Spark API (DataFrames, Datasets) состоят из RDD под капотом. Что значит быть устойчивым распределённым набором данных?
Resilient– Устойчивый: поскольку Spark работает на кластере компьютеров, потеря данных из-за аппаратного сбоя представляет собой серьёзную проблему, поэтому RDD отказоустойчивые и восстанавливаются в случае сбоя.Distributed– Распределённый: один RDD хранится на нескольких узлах кластера, которые не принадлежат одному источнику (и одной точке отказа). Таким образом, кластер оперирует RDD параллельно.Dataset– Набор данных: коллекция значений – вы наверняка уже знали это.
Данные, с которыми мы работаем в Spark, хранятся в той или иной форме в RDD, поэтому понимать их – необходимость.
Spark предлагает API «высшего уровня», разработанные на основе RDD для абстрагирования сложности: DataFrame и Dataset. Если сосредоточиться на циклах «чтение – вычисление – вывод» (REPL), Spark-Submit и Spark-Shell в Scala и Python ориентируются на экспертов по аналитическим данным, которым часто требуется повторный анализ набора данных. Без понимания RDD по-прежнему не обойтись, так как это базовая структура всех данных в Spark.
Разговорный эквивалент RDD: «Распределённая структура данных». JavaRDD<String> – это, по сути, List<String>, рассредоточенный по узлам в нашем кластере, причём каждый узел получает разные порции списка. Фреймворк Spark побуждает мыслить в распределённом контексте, постоянно.
RDD работают путём разделения данных на несколько разделов (Partition), которые хранятся на каждом узле-исполнителе. Каждый узел выполняет работу только на собственных разделах. В этом и заключается мощь Spark: если исполнитель выходит из строя, или не удаётся выполнить задачу, Spark восстанавливает только необходимые разделы из источника и повторно отправляет задачу для завершения.
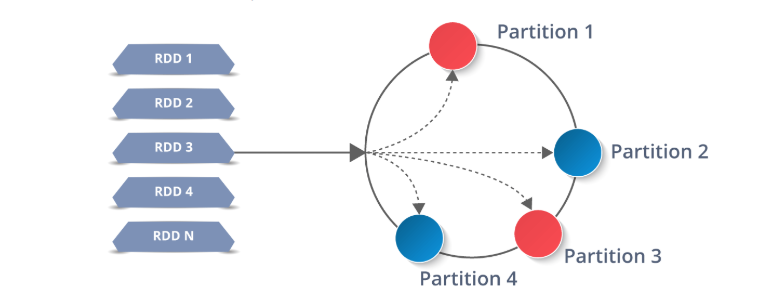
Операции с RDD
RDD Immutable, это означает, что после создания эти наборы никак не изменяются, а только трансформируются (transformed). Идея трансформации RDD лежит в основе Spark, и задания Spark рассматриваются как комбинация этих шагов:
- Загрузка данных в RDD
- Трансформация RDD
- Выполнение действия над RDD
Spark определяет набор API для работы с RDD, которые разбиты на две большие группы: Трансформации и Действия .
Трансформации создают новый RDD из существующего.
Действия возвращают значение или значения программе-драйверу после выполнения вычисления над RDD.
Например, map-функция weatherData.map() – это трансформация, которая передаёт каждый элемент RDD в функцию.
Reduce – это действие RDD, которое объединяет все элементы RDD с использованием некоторой функции и возвращает конечный результат в программу-драйвер.
Ленивые вычисления
«Я выбираю ленивого человека для выполнения трудной работы. Потому что ленивый человек найдёт простой способ решения задачи.» – Билл Гейтс
Трансформации в Spark «ленивые». Это означает, что когда сообщаем Spark о создании RDD с помощью трансформаций существующего RDD, он не будет генерировать этот набор данных, пока не выполнится действие над ним или его дочерним элементом. Затем Spark выполнит трансформацию и действие, которое её запустило. Поэтому Spark работает намного эффективнее.
Ещё раз рассмотрим объявления функций из нашего предыдущего примера Spark, чтобы определить, какие функции – действия, а какие – трансформации:
16: JavaRDD<String> weatherData = sc.textFile(inputPath);
Строка 16 – не действие и не трансформация; это функция sc, нашего JavaSparkContext.
17: JavaPairRDD<String, Integer> tempsByCountry = weatherData.mapToPair(new Func.....
Строка 17 – трансформация RDD WeatherData, в которой преобразовываем каждую строку WeatherData в пару (Город, Температура)
26: JavaPairRDD<String, Integer> maxTempByCountry = tempsByCountry.reduce(new Func....
Строка 26 – также трансформация, потому что перебираем пары ключ-значение. Это трансформация tempsByCountry, в которой происходит свёртка данных каждого города до его наивысшей зарегистрированной температуры.
31: maxTempByCountry.saveAsHadoopFile(destPath, String.class, Integer.class, TextOutputFormat.class);
Наконец, в строке 31 запускаем действие Spark: сохраняем RDD в файловой системе. Поскольку у Spark ленивая модель выполнения, только после этой строки Spark генерирует weatherData, tempsByCountry и maxTempsByCountry, прежде чем окончательно сохранить результат.
Направленный ациклический граф
Каждый раз, когда выполняется действие над RDD, Spark создает DAG, конечный граф без направленных циклов (в противном случае наше задание будет выполняться вечно). Помните, что граф – набор связанных вершин и рёбер, и этот граф ничем не отличается. Каждая вершина в DAG – функция Spark, некоторая операция, которая выполняется над RDD (map, mapToPair, reduByKey и т. д.).
В MapReduce DAG состоит из двух вершин: Map → Reduce.
В приведённом выше примере с MaxTemperatureByCountry граф посложнее:
parallelize → map → mapToPair → reduce → saveAsHadoopFile
С помощью DAG Spark оптимизирует план выполнения и минимизирует перемешивание. Рассмотрение DAG выходит за рамки этого обзора Spark.
Циклы выполнения
Используя наш новый словарь, ещё раз рассмотрим определение проблемы с MapReduce, данное в первой части и приведенное ниже:
«MapReduce справляется с пакетной обработкой данных. Однако отстаёт, когда дело доходит до повторного анализа и небольших циклов обратной связи. Единственный способ повторно использовать данные между вычислениями – записать их во внешнюю систему хранения (например, HDFS).»
«Повторно использовать данные между вычислениями»? Звучит так, будто над RDD совершается несколько действий! Предположим, хотим выполнить два вычисления над фалом «data.txt»:
- Общая длина всех строк в файле
- Длина самой длинной строки в файле
В MapReduce каждая задача требует отдельного задания или мудрёной реализации MulitpleOutputFormat. Spark превращает это в пустяк с четырьма лёгкими шагами:
- Загружаем содержимое
data.txtв RDD
JavaRDD<String> lines = sc.textFile("data.txt");
2. Применяем функцию вычисления длины к каждой строке из lines с помощью map (лямбда-функции используются для краткости)
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
3. Для определения общей длины выполним reduce для lineLengths, чтобы найти сумму длин строк, в нашем случае сумму всех элементов в RDD.
int totalLength = lineLengths.reduce((a, b) -> a + b);
4. Чтобы вычислить наибольшую длину, применяем reduce к lineLengths
int maxLength = lineLengths.reduce((a, b) -> Math.max(a,b));
Обратите внимание, что шаги 3 и 4 – действия RDD, поэтому они возвращают результат программе-драйверу, в данном случае Java int. Также помните, что Spark ленив и отказывается выполнять работу, пока не увидит действие. В этом случае он не начнёт ничего делать до шага 3.
Заключение
К этому моменту мы представили проблему с данными и её решение: фреймворк Apache Spark. Теперь рассмотрели архитектуру и workflow Spark, его главную внутреннюю абстракцию (RDD) и модель выполнения.
Комментарии