

Matplotlib – наиболее широко используемый инструмент на Python. Он имеет отличную поддержку множеством сред, таких, как веб-серверы приложений, графические библиотеки пользовательского интерфейса, Jupiter Notebook, iPython Notebook и оболочка iPython.
Архитектура Matplotlib
Matplotlib имеет три основных слоя: слой нижнего уровня (backend), слой рисунков и слой скриптов. Слой нижнего уровня содержит три интерфейсных класса: канва рисунка (figure canvas), определяющая область рисунка, прорисовщик (renderer), умеющий рисовать на этой канве, и событие (event), обрабатывающее ввод пользователя вроде щелчков мыши. Слой рисунков знает, как рисовать с помощью Renderer'а и рисовать на канве. Все, что находится на рисунке Matplotlib, является экземпляром слоя рисунка (artist). Засечки, заголовок, метки – все это индивидуальные объекты слоя рисунков. Слой скриптов – это облегченный интерфейс, который очень полезен для ежедневного применения. Все примеры, приведенные в этой статье, используют слой скриптов и среду Jupiter Notebook.
Если вы используете эту статью для обучения, я рекомендую вам запускать каждый пример кода.
Подготовка данных
Подготовка данных – часто выполняемая задача перед любым проектом по визуализации данных или анализа данных, поскольку данные никогда не приходят в том виде, в котором они нам нужны. Я использую набор данных об иммиграции в Канаду. Сначала импортируем необходимые пакеты и набор данных.
import numpy as np
import pandas as pd
df = pd.read_excel('https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DV0101EN/labs/Data_Files/Canada.xlsx',
sheet_name='Canada by Citizenship',
skiprows=range(20),
skipfooter=2)
df.head()
Я пропускаю первые 20 строк и последние две строки, потому что это текст, а не данные с табуляцией. Набор данных слишком велик, так что я не могу показать его целиком. Чтобы получить представление о наборе, давайте посмотрим на имена столбцов:
df.columns
# Вывод:
# Index([ 'Type', 'Coverage', 'OdName', 'AREA', 'AreaName', 'REG',
# 'RegName', 'DEV', 'DevName', 1980, 1981, 1982,
# 1983, 1984, 1985, 1986, 1987, 1988,
# 1989, 1990, 1991, 1992, 1993, 1994,
# 1995, 1996, 1997, 1998, 1999, 2000,
# 2001, 2002, 2003, 2004, 2005, 2006,
# 2007, 2008, 2009, 2010, 2011, 2012,
# 2013],
# dtype='object')
Мы не собираемся использовать все эти столбцы в нашей статье. Поэтому давайте избавимся от столбцов, которые мы не будем использовать, чтобы сделать набор данных меньшим и лучше управляемым.
df.drop(['AREA','REG','DEV','Type','Coverage'], axis=1, inplace=True)
df.head()
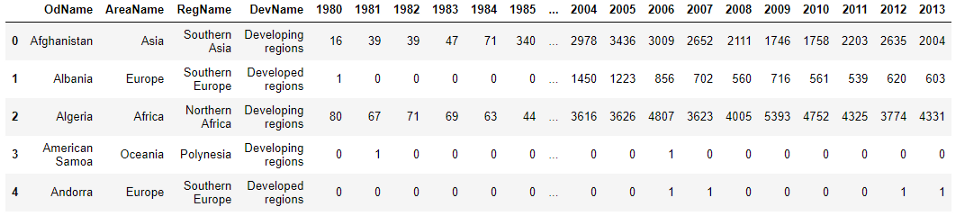
Посмотрите на эти столбцы. Столбец 'OdName' – на самом деле название страны, 'AreaName' – континент, а 'RegName' – регион на этом континенте. Переименуем эти столбцы, чтобы их имена стали более понятными.
df.rename(columns={'OdName':'Country', 'AreaName':'Continent', 'RegName':'Region'}, inplace=True)
df.columns
# Вывод:
# Index([ 'Country', 'Continent', 'Region', 'DevName', 1980,
# 1981, 1982, 1983, 1984, 1985,
# 1986, 1987, 1988, 1989, 1990,
# 1991, 1992, 1993, 1994, 1995,
# 1996, 1997, 1998, 1999, 2000,
# 2001, 2002, 2003, 2004, 2005,
# 2006, 2007, 2008, 2009, 2010,
# 2011, 2012, 2013],
# dtype='object')
Теперь наш набор данных стал более простым для понимания. У нас есть Country, Continent, Region, а DevName указывает, является ли страна развитой или развивающейся. Все столбцы с годами содержат количество иммигрантов в Канаду из соответствующей страны за указанный год. Теперь добавим столбец 'Total' ('Всего'), в котором будет содержаться общее количество иммигрантов из этой страны с 1980-го до 2013-го.
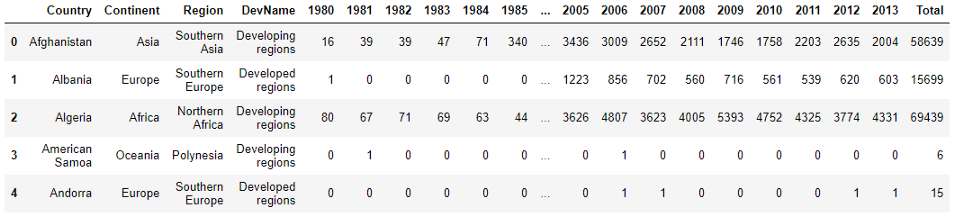
Проверим, есть ли в наборе какие-либо значения null.
df.isnull().sum()
Результат показывает 0 во всех столбцах, то есть в наборе нет пропусков. Я люблю задавать в качестве индекса значащий столбец, а не какие-то цифры, поэтому установим столбец 'Country' в качестве индекса.
df = df.set_index('Country')
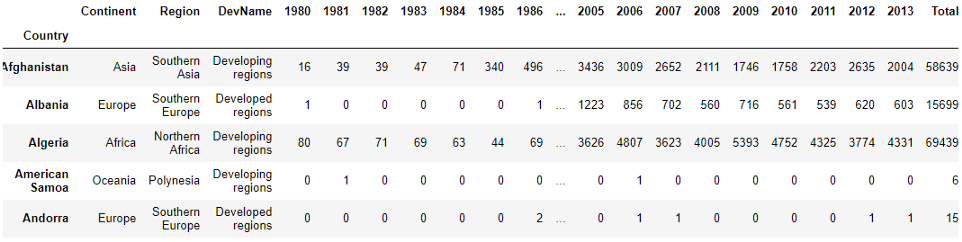
Теперь набор данных достаточно чист и красив, чтобы начать работать с ним, поэтому больше чистить мы не станем. Если нам потребуется что-то еще, мы сделаем это по мере необходимости.
Упражнения по рисованию диаграмм
В этой статье мы попробуем несколько различных типов диаграмм – таких, как линейная диаграмма (line plot), диаграмма с областями (area plot), секторная диаграмма (pie plot), диаграмма рассеяния (scatter plot), гистограмма, столбчатая диаграмма (bar graph). Сначала импортируем необходимые пакеты.
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib as mpl
Выберем стиль, чтобы нам не пришлось слишком утруждаться установкой стиля диаграммы. Вот список доступных стилей:
plt.style.available
# Вывод:
# ['bmh',
# 'classic',
# 'dark_background',
# 'fast',
# 'fivethirtyeight',
# 'ggplot',
# 'grayscale',
# 'seaborn-bright',
# 'seaborn-colorblind',
# 'seaborn-dark-palette',
# 'seaborn-dark',
# 'seaborn-darkgrid',
# 'seaborn-deep',
# 'seaborn-muted',
# 'seaborn-notebook',
# 'seaborn-paper',
# 'seaborn-pastel',
# 'seaborn-poster',
# 'seaborn-talk',
# 'seaborn-ticks',
# 'seaborn-white',
# 'seaborn-whitegrid',
# 'seaborn',
# 'Solarize_Light2',
# 'tableau-colorblind10',
# '_classic_test']
Я буду использовать стиль 'ggplot'. Вы можете взять любой другой стиль по своему вкусу.
mpl.style.use(['ggplot'])
Линейная диаграмма
Будет полезным увидеть график изменений иммиграции в Канаду для одной страны. Создадим список лет с 1980-го до 2013-го:
years = list(range(1980, 2014))
Я выбрала для этой демонстрации Швейцарию. Приготовим иммиграционные данные по нашим годам для этой страны.
df.loc['Switzerland', years]
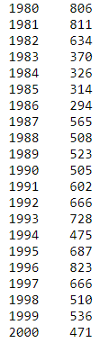
Настало время нарисовать диаграмму. Это очень просто: достаточно вызвать функцию plot для приготовленных нами данных. Затем добавим заголовок и метки для осей x и y.
df.loc['Switzerland', years].plot()
plt.title('Immigration from Switzerland')
plt.ylabel('Number of immigrants')
plt.xlabel('Years')
plt.show()
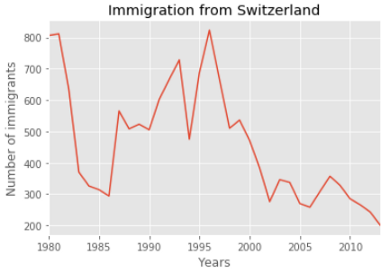
Что, если мы хотим вывести графики иммиграции для нескольких стран сразу, чтобы сравнить тенденции иммиграции из этих стран в Канаду? Это делается почти так же, как и в прошлом примере. Нарисуем диаграмму иммиграции из трех южно-азиатских стран: Индии, Пакистана и Бангладеш по годам.
ind_pak_ban = df.loc[['India', 'Pakistan', 'Bangladesh'], years]
ind_pak_ban.head()

Посмотрите на формат этих данных – он отличается от данных по Швейцарии, использованных прежде. Если мы вызовем функцию plot для этого DataFrame (ind_pak_ban), она выведет количество иммигрантов в каждой стране по оси x и годы по оси y. Нам нужно изменить формат данных:
ind_pak_ban.T
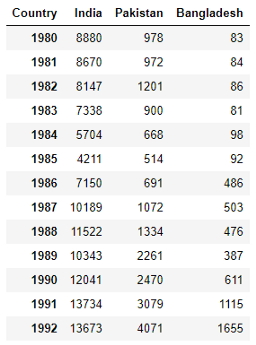
Это не весь набор данных, а только его часть. Видите, теперь формат данных изменился. Теперь годы будут выводиться по оси x, а количество иммигрантов из каждой страны по оси y.
ind_pak_ban.T.plot()
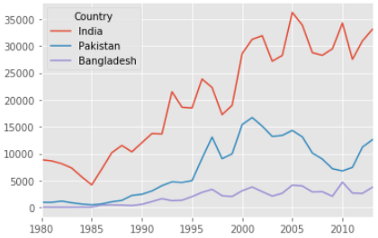
Нам не пришлось задавать тип диаграммы, потому что линейная диаграмма рисуется по умолчанию.
Секторная диаграмма
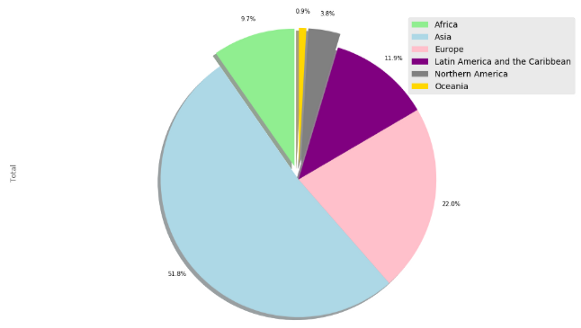
Чтобы продемонстрировать секторную диаграмму, построим диаграмму общего количества иммигрантов для каждого континента. У нас есть данные по каждой стране. Давайте сгруппируем данные по континентам, чтобы просуммировать количество иммигрантов для каждого континента.
cont = df.groupby('Continent', axis=0).sum()
Теперь у нас есть данные, показывающие общее количество иммигрантов для каждого континента. Если хотите, можете вывести этот DataFrame, чтобы увидеть результат. Я не привожу его потому, что он занимает слишком много места по горизонтали. Давайте нарисуем эту диаграмму.
cont['Total'].plot(kind='pie', figsize=(7,7),
autopct='%1.1f%%',
shadow=True)
# plt.title('Immigration By Continenets')
plt.axis('equal')
plt.show()
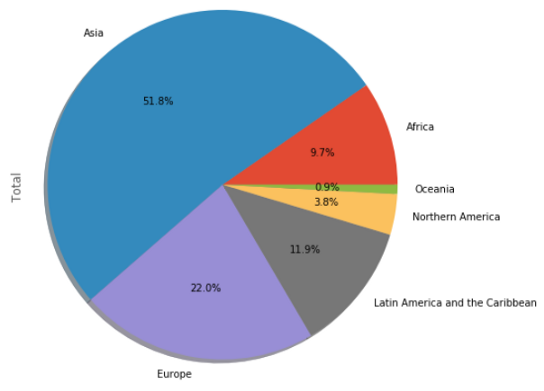
Заметьте, что мне пришлось использовать параметр 'kind'. Все виды диаграмм, кроме линейной, в функции plot нужно указывать явно. Я ввожу новый параметр 'figsize', определяющий размеры диаграммы.
Эта секторная диаграмма достаточно понятна, но мы можем сделать ее еще лучшей. На этот раз я установлю собственные цвета и начальный угол.
colors = ['lightgreen', 'lightblue', 'pink', 'purple', 'grey', 'gold']
explode=[0.1, 0, 0, 0, 0.1, 0.1]
cont['Total'].plot(kind='pie', figsize=(17, 10),
autopct = '%1.1f%%', startangle=90,
shadow=True, labels=None, pctdistance=1.12, colors=colors, explode = explode)
plt.axis('equal')
plt.legend(labels=cont.index, loc='upper right', fontsize=14)
plt.show()
Ящик с усами (boxplot)
Сначала мы построим "ящик с усами" для количества иммигрантов из Китая.
china = df.loc[['China'], years].T
Вот наши данные. А вот диаграмма, построенная по этим данным.
china.plot(kind='box', figsize=(8, 6))
plt.title('Box plot of Chinese Immigrants')
plt.ylabel('Number of Immigrants')
plt.show()
Если вам нужно освежить свои знания про "ящики с усами", пожалуйста, обратитесь к статье "Пример понимания данных с помощью гистограммы и ящика с усами".
Мы можем нарисовать несколько ящиков с усами в одной диаграмме. Используем DataFrame ind_pak_ban и нарисуем ящики для количества иммигрантов из Индии, Пакистана и Бангладеш.
ind_pak_ban.T.plot(kind='box', figsize=(8, 7))
plt.title('Box plots of Inian, Pakistan and Bangladesh Immigrants')
plt.ylabel('Number of Immigrants')
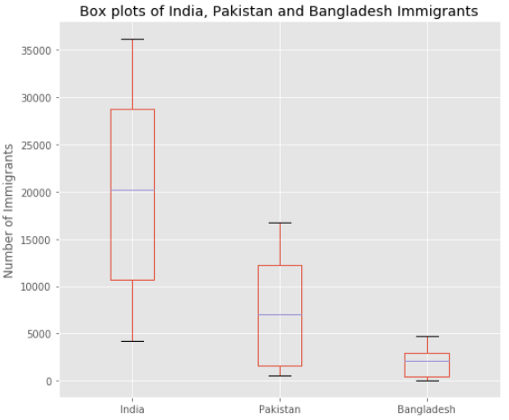
Диаграмма рассеяния
Диаграммы рассеяния лучше всего подходят для исследования зависимости между переменными. Построим диаграмму рассеяния, чтобы увидеть тренд количества иммигрантов в Канаду за годы.
Для этого упражнения мы создадим новый DataFrame, содержащий годы в качестве индекса и общее количество иммигрантов за каждый год.
totalPerYear = pd.DataFrame(df[years].sum(axis=0))
totalPerYear.head()
Нам нужно преобразовать годы в целые числа. Я также хочу немного причесать DataFrame, чтобы сделать его более презентабельным.
totalPerYear.index = map(int, totalPerYear.index)
totalPerYear.reset_index(inplace=True)
totalPerYear.columns = ['year', 'total']
totalPerYear.head()
Осталось задать параметры осей x и y для диаграммы рассеяния.
totalPerYear.plot(kind='scatter', x = 'year', y='total', figsize=(10, 6), color='darkred')
plt.title('Total Immigration from 1980 - 2013')
plt.xlabel('Year')
plt.ylabel('Number of Immigrants')
plt.show()
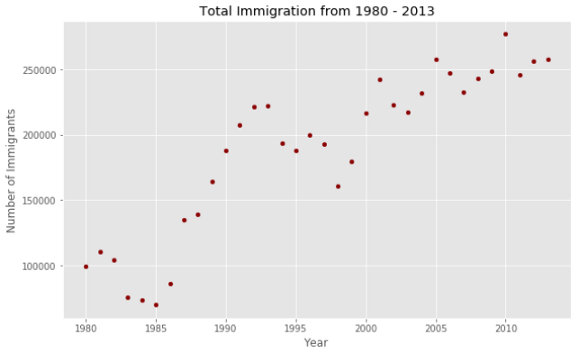
Похоже, здесь есть линейная зависимость между годом и количеством иммигрантов. С течением лет количество иммигрантов показывает явно растущий тренд.
Диаграмма с областями
Диаграмма с областями показывает область под линейным графиком. Для этой диаграммы я хочу создать DataFrame, содержащий информацию по Индии, Китаю, Пакистану и Франции.
top = df.loc[['India', 'China', 'Pakistan', 'France'], years]
top = top.T
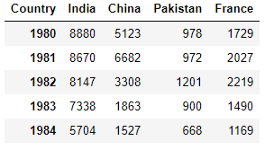
Набор данных готов. Пора сделать из него диаграмму.
colors = ['black', 'green', 'blue', 'red']
top.plot(kind='area', stacked=False, figsize=(20, 10), color=colors)
plt.title('Immigration trend from Europe')
plt.ylabel('Number of Immigrants')
plt.xlabel('Years')
plt.show()
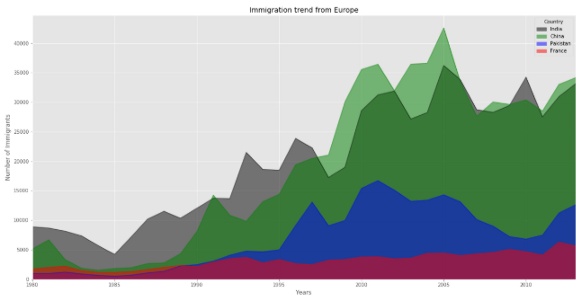
Не забудьте использовать параметр 'stacked', если хотите увидеть области для каждой отдельной страны. Если не установить stacked = False, диаграмма будет выглядеть примерно так:

Гистограмма
Гистограмма показывает распределение переменной. Вот ее пример:
df[2005].plot(kind='hist', figsize=(8,5))
plt.title('Histogram of Immigration from 195 Countries in 2005') # заголовок гистограммы
plt.ylabel('Number of Countries') # y-метка
plt.xlabel('Number of Immigrants') # x-метка
plt.show()
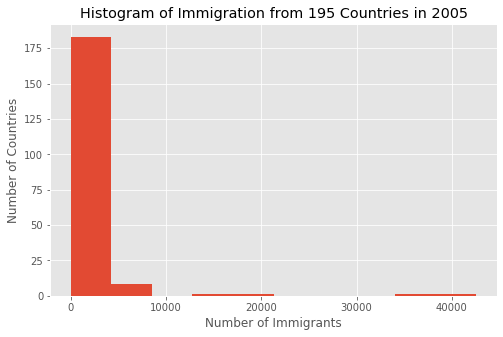
Мы построили гистограмму, показывающую распределение иммиграции за 2005 год. Гистограмма показывает, что из большинства стран приехало от 0 до 5000 иммигрантов. Только несколько стран прислали 20 тысяч, и еще пара стран прислала по 40 тысяч иммигрантов.
Давайте используем DataFrame top из предыдущего примера и нарисуем распределение количества иммигрантов из каждой страны в одной и той же гистограмме.
top.plot.hist()
plt.title('Histogram of Immigration from Some Populous Countries')
plt.ylabel('Number of Years')
plt.xlabel('Number of Immigrants')
plt.show()
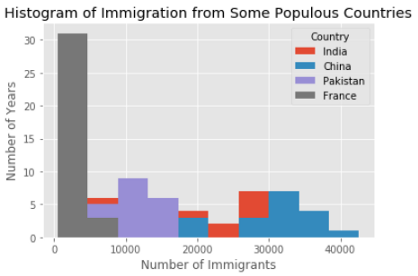
На предыдущей гистограмме мы видели, что из нескольких стран приехало 20 и 40 тысяч иммигрантов. Похоже, что Китай и Индия среди этих "нескольких". На этой гистограмме мы не можем четко увидеть границы между столбцами. Давайте улучшим ее.
Задаем количество столбцов и показываем их границы.
Я использую 15 столбцов. Здесь я ввожу новый параметр под названием 'alpha' – он определяет прозрачность цветов. Для таких перекрывающихся диаграмм, как наша, прозрачность важна, чтобы увидеть картину каждого распределения.
count, bin_edges = np.histogram(top, 15)
top.plot(kind = 'hist', figsize=(14, 6), bins=15, alpha=0.6,
xticks=bin_edges, color=colors)
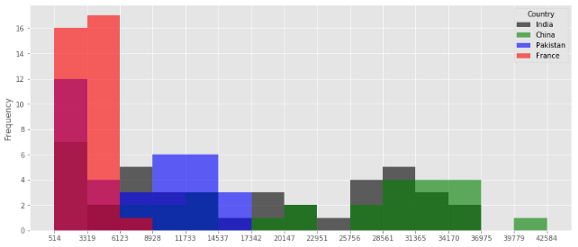
Как и для диаграммы с областями, мы можем использовать параметр 'stacked', но для гистограмм он по умолчанию выключен.
top.plot(kind='hist',
figsize=(12, 6),
bins=15,
xticks=bin_edges,
color=colors,
stacked=True,
)
plt.title('Histogram of Immigration from Some Populous Countries')
plt.ylabel('Number of Years')
plt.xlabel('Number of Immigrants')
plt.show()
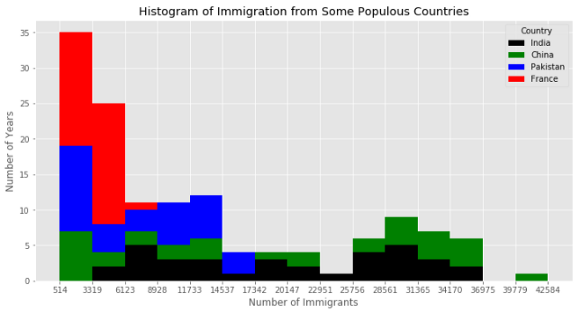
Столбчатая диаграмма
Для столбчатой диаграммы я использую количество иммигрантов из Франции за каждый год.
france = df.loc['France', years]
france.plot(kind='bar', figsize = (10, 6))
plt.xlabel('Year')
plt.ylabel('Number of immigrants')
plt.title('Immigrants From France')
plt.show()
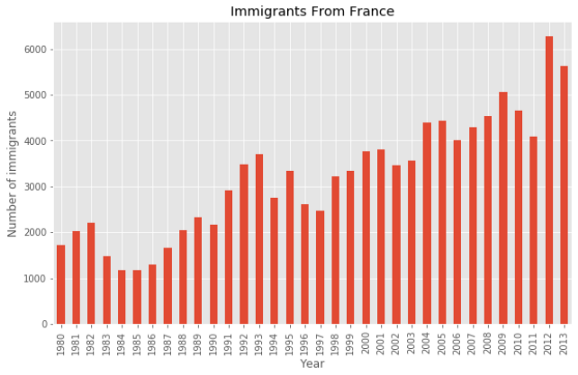
Вы можете добавить к столбчатой диаграмме дополнительную информацию. Эта диаграмма показывает растущий тренд с 1997 года примерно на декаду, который стоит отметить. Это можно сделать с помощью функции annotate.
france.plot(kind='bar', figsize = (10, 6))
plt.xlabel('Year')
plt.ylabel('Number of immigrants')
plt.title('Immigrants From France')
plt.annotate('Increasing Trend',
xy = (19, 4500),
rotation= 23,
va = 'bottom',
ha = 'left')
plt.annotate('',
xy=(29, 5500),
xytext=(17, 3800),
xycoords='data',
arrowprops=dict(arrowstyle='->', connectionstyle='arc3', color='black', lw=1.5))
plt.show()
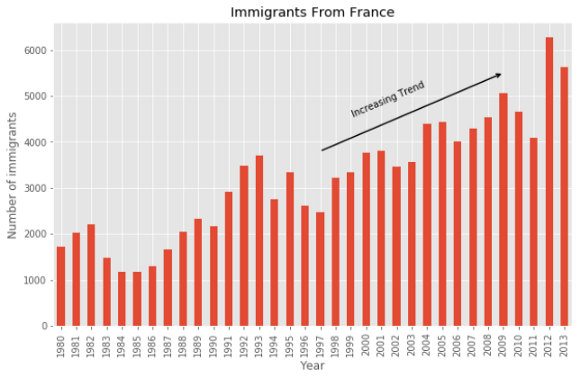
Иногда горизонтальное расположение столбцов делает диаграмму более понятной. Еще лучше, если метки рисуются прямо на столбцах. Давайте сделаем это.
france.plot(kind='barh', figsize=(12, 16), color='steelblue')
plt.xlabel('Year') # add to x-label to the plot
plt.ylabel('Number of immigrants') # add y-label to the plot
plt.title('Immigrants From France') # add title to the plot
for index, value in enumerate(france):
label = format(int(value), ',')
plt.annotate(label, xy=(value-300, index-0.1), color='white')
plt.show()
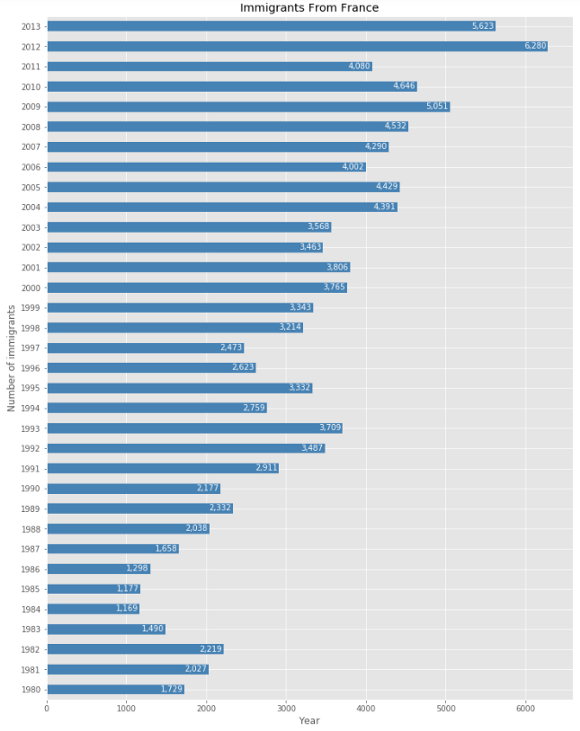
Разве эта диаграмма выглядит не лучше, чем предыдущая?
В этой статье мы изучили основы Matplotlib. Теперь у вас достаточно знаний, чтобы начать самостоятельное использование Matplotlib прямо сегодня.
Расширенные методы визуализации описаны в следующих статьях:
- "Интерактивная фоновая картограмма на Python"
- "Создаем "облака слов" любой формы на Python"
- "Интерактивная визуализация географических данных на Python"
- "Вафельные графики" с помощью Matplotlib на Python"
- "Пузырьковые диаграммы с помощью Matplotlib"
- "Исследовательский анализ данных для моделирования данных"
- "Сортируем и сегментируем данные с помощью методов Cut или Qcut из Pandas"
Комментарии