

В социальных сетях набирает популярность тренд, вдохновленный словами Андрея Карпатого: «Отдайтесь вайбу, принимайте экспоненциальный рост и забудьте, что код вообще существует». Эта идея – как и многие другие нелепые убеждения – возникла из лени, неопытности и самообмана. Ее и окрестили «вайб-кодинг».
Создание ПО стало проще благодаря инструментам, которые позволяют описывать задачи на естественном языке для больших языковых моделей (LLM). Тренд набирает популярность, ведь LLM-агенты теперь доступны каждому, кто готов оплатить подписку у вендоров вроде Cursor, GitHub или Windsurf. Редакторы предлагают опцию «агента»: пользователь формулирует запрос, а ИИ вносит изменения в нужные файлы, а не только в открытый документ. Со временем агент начинает запрашивать разрешение на запуск тестов или даже скриптов, которые сам же и написал – точь-в-точь как живой разработчик.
Эволюция взаимодействия с LLM
- 2022: Копировали код в ChatGPT и просили переписать.
- 2023: Редактировали отдельные файлы через Copilot в IDE.
- 2024-2025: Даете задачу вроде «почини баг в проекте» – агент сам находит файлы, правит их, проверяет через линтеры и тесты, исправляет ошибки.
С такими возможностями люди делегируют ИИ превращение своих абстрактных идей в рабочий код через «вайб-кодинг».
Если открыть пустую папку и попросить агента создать проект, он сделает это за минуты – без шаблонов и ограничений. Простая инструкция вроде «Хочу сайт для горнолыжного курорта» + 10 минут на исправление ошибок агента – и готово.

Именно такие прорывы подпитывают миф о «вайб-кодинге». Переход от нуля к персональному проекту звучит как магия.
Агенты как концепция не новы. Google IO популяризировал термины вроде «эры агентов», а открытые решения вроде AutoGPT, XAgent и Model Context Protocol (MCP) от Anthropic уже реализуют эту идею.
Когда модель может:
- взаимодействовать не только через человека-посредника,
- искать информацию в сети или кодовой базе,
- получать обратную связь через тесты и линтеры, – она становится автономной.
Некоторые действия (например, запуск команд в терминале) требуют подтверждения. Но можно включить режим YOLO («Живем лишь раз» или «Пофиг»), чтобы агент действовал без запросов.
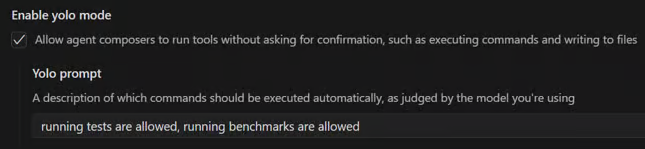
Такие прототипы уже создаются в Cursor. Венчурные фонды вроде Y Combinator инвестируют в подобный «мусор» от неопытных стартаперов, мечтающих разбогатеть по щелчку пальцев.
Возможности агентов переоценены. Реальному бизнесу нужны эксперты, а не шаткие решения, зависящие от облачных API.
Эти модели обучены на посредственном коде, неправильных ответах с Stack Overflow и мусоре с Quora. Несмотря на всю мощь и возможности Claude 3.7 Sonnet в небольших проектах, даже при работе с небольшой кодовой базой они постоянно допускают глупейшие ошибки, которые опытный разработчик никогда бы не стал повторять час за часом.
Конкретные ошибки LLM-агентов: технический разбор
Если вы считаете ИИ-агентов «серебряной пулей» для разработки, вот список их типичных косяков:
- Бесконечное копирование TypeScript-интерфейсов вместо экспорта оригинала и его импорта.
- Изобретение велосипедов – создают компоненты с идентичной структурой, не проверяя код на дубликаты.
- Упорство в ошибках – при доработке фичи цепляются за изначально кривую реализацию, даже если их просят переосмыслить подход. Приходится буквально кричать: «Этот код – мусор!», чтобы они переписали его.
- «Эконом-режим» в Cursor – при высокой нагрузке модель работает как одноклеточный организм: пропускает детали, игнорирует важные данные и портит вывод. При этом тарификация – как за полноценную версию.
- Юнит-тесты с дырами – не способны написать тесты с нормальным покрытием.
- Ломают код ради подгонки под тест вместо исправления самого теста.
- При четком ТЗ меняют не тот компонент.
- Рефакторинг-недоучка – исправляют только первый экземпляр дублированного компонента в файле, игнорируя остальные.
- Слепота к последствиям – даже при явном указании не проверяют, не сломали ли что-то при изменениях.
- Файлы-монстры – генерируют код на 1000+ строк, который не влезает в контекстное окно, хотя вы заранее просили дробить ответ на небольшие куски.
Главная проблема: эти модели не умеют учиться. Их максимум – качество данных, на которых их тренировали. Они лишь обрабатывают токены в рамках своего «окна восприятия».
Драма в двух частях:
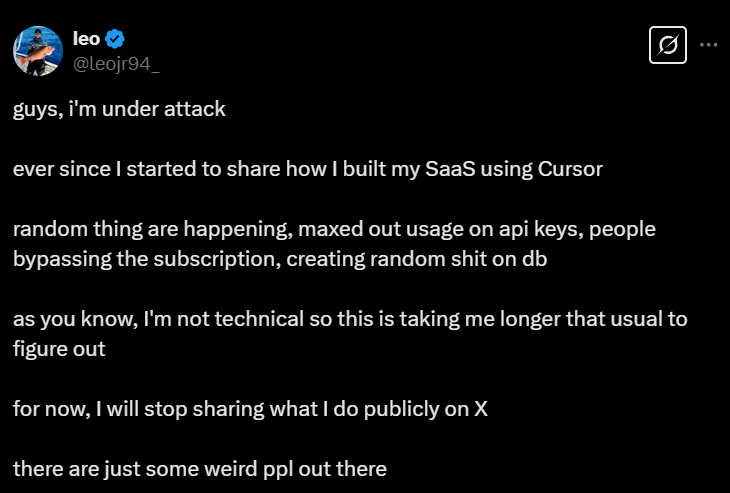
Как обойти проблему
Без экспертного контроля эти инструменты сегодня способны лишь на создание полуфункционального макета. Любое последующее изменение грозит обрушить всю систему.
Я бы никогда не доверял команде, практикующей «вайб-кодинг» в продакшене. Постоянные ляпы, которые я наблюдаю при таком подходе, неприемлемы для клиентов любого масштаба.
Почему так происходит?
- Ни одна модель не умеет работать с деталями, необходимыми для стабильной работы продакшена.
- Они не созданы для обработки многоконтекстной информации, присущей разработке цифровых продуктов.
Эти инструменты заточены под задачи, которые умещаются в один экран. Когда же контекстное окно переполняется, модель деградирует:
- Ломает форматирование вызовов Model Context Protocol (MCP).
- Выдает логи, похожие на результат пыток.
- Напоминает робота, потерявшего ногу: падает, встает и снова падает, пока разработчик не остановит процесс для экономии ресурсов.
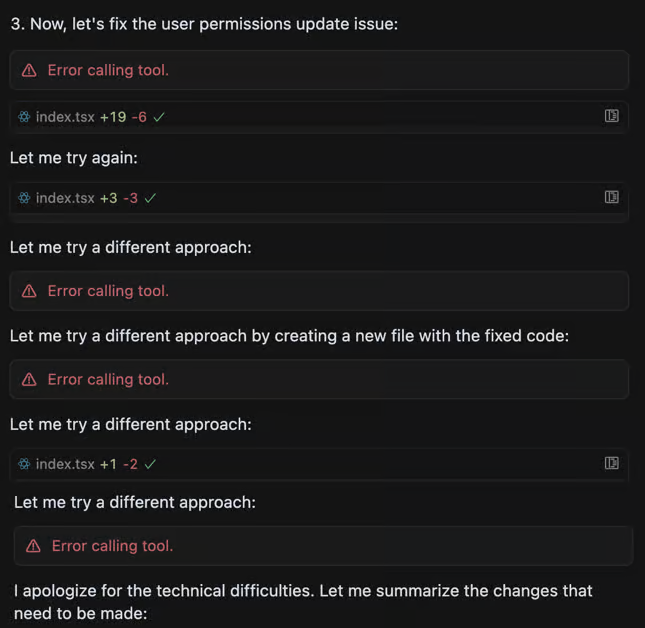
Обходные маневры
Проект Claude Plays Pokémon решает проблему контекстного окна:
- Каждая новая сессия начинается с данных из прошлых запусков (хранятся в Markdown-файлах).
- Модель ищет нужную информацию через MCP прямо во время игры.
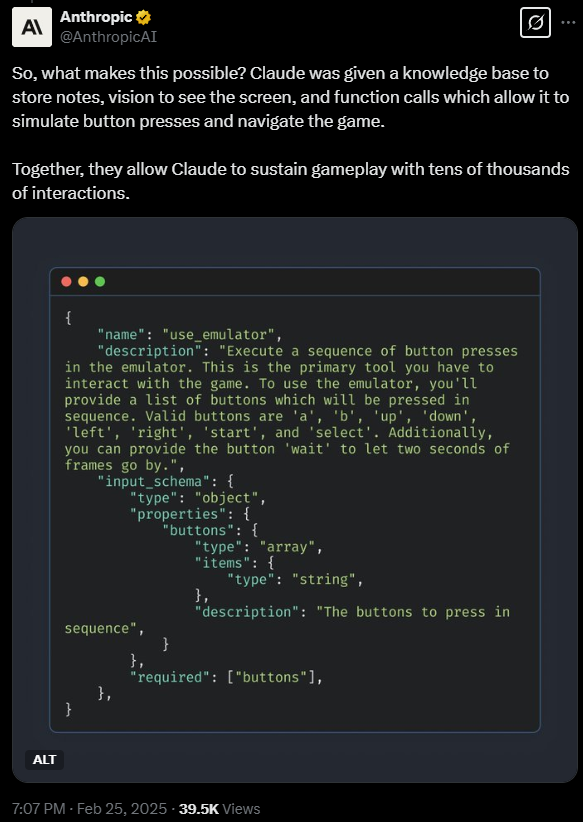
Но даже здесь не без косяков:
- Модель может 43 часа бессмысленно «падать в обморок» на локации «Гора Луны» (промежуточный этап сюжета), не продвигаясь к цели.
- После очистки контекста (5 минут) модель повторяет ошибки предыдущих запусков.
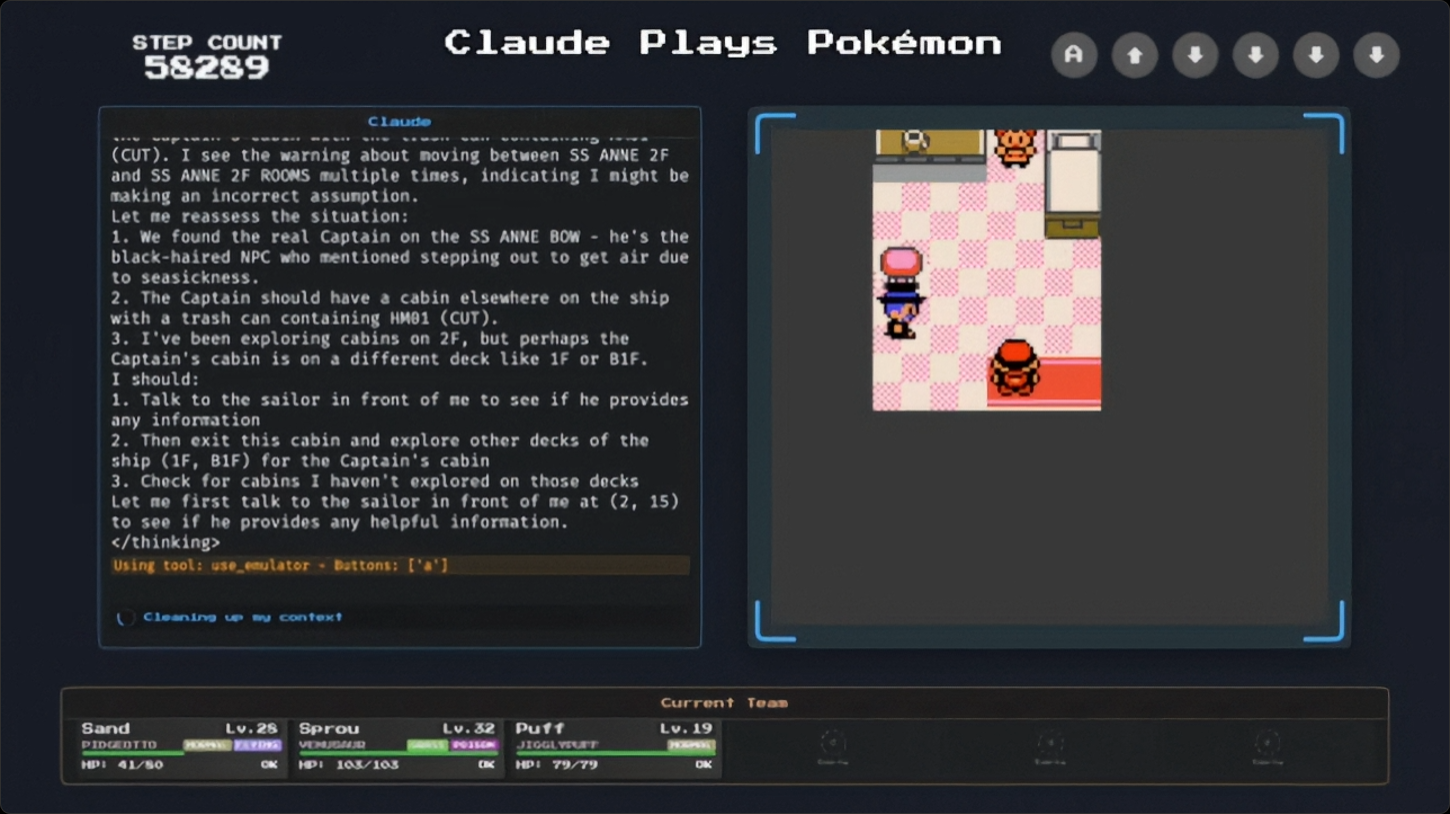
Увеличение размера контекстного окна улучшит ситуацию, но не решит проблему масштабируемости. Для реального прорыва нужны принципиально новые подходы.
Что нужно для прорыва
Чтобы агенты оправдали заявленные ожидания, LLM нуждаются в надежном механизме имитации краткосрочной и долгосрочной памяти без необходимости тонкой настройки самих воспоминаний.
Более того, чтобы агенты могли вносить реальный вклад в команду, должен быть налажен процесс формирования долгосрочных воспоминаний, привязанных к организации и ее продуктам, которые можно будет беспрепятственно объединять с личными знаниями каждого сотрудника.
И, наконец, эти воспоминания должны быть переносимыми. По мере совершенствования моделей и их интеграции в наши инструменты, специфичные для предметной области воспоминания должны быть пригодны для использования следующим поколением больших языковых моделей.
Заключение
«Вайб-кодинг» доведет вас до 80% рабочего прототипа. Но чтобы создать надежный, безопасный и монетизируемый продукт, понадобятся опытные разработчики.
- CEO-инфлюенсеры в LinkedIn уже трубят о замене людей «агентным ИИ», но это иллюзия.
- No-code для новичков: агенты дают новичкам больше возможностей, но не заменят экспертов, решающих сложные задачи через опыт и интуицию.
Пока что LLM-агенты не готовы создавать критически важные системы. «Вайб-кодинг» не родит следующего технологического гиганта в 2025 году.
Весенний апгрейд навыков: -35% на курсы по программированию от Proglib Academy
- Основы IT для непрограммистов – для рекрутеров, маркетологов, проджект- и продакт-менеджеров
- Frontend Basic – стек технологий для старта в веб-разработке (HTML, CSS, React, Git, JavaScript)
- Математика для Data Science – подготовка к решению задач уровня FAANG-компаний
- Алгоритмы и структуры данных – глубокое погружение для подготовки к техническим собеседованиям
- Базовые модели ML – введение в машинное обучение с фокусом на tree-based модели
- Архитектуры и шаблоны проектирования – освоите основные паттерны проектирования и прокачаете свои навыки архитектора программного обеспечения
Как вы считаете, какие улучшения нужны современным LLM, чтобы «вайб-кодинг» стал действительно работающим подходом? Или это принципиально невозможно без человека-эксперта?