

Мощь PostgreSQL сопровождается рядом особенностей, о которых важно знать. Автор публикации, на которой основана эта статья, подробно разобрал ключевые аспекты эффективной работы с PostgreSQL: нормализацию данных, поведение NULL, тонкости JSONB, индексацию, блокировки и улучшение вывода psql.
Нормализация данных
Суть нормализации в том, чтобы избавиться от дублирования и избыточности данных в базе. Представьте сайт, где пользователи могут загружать документы и получать уведомления на почту, когда кто-то просматривает их документы. Как правильно организовать такую базу данных?
Неправильный подход:
- Хранить email пользователя прямо в таблице документов для каждого загруженного файла
- Проблема: если пользователь захочет изменить свой email, придется обновлять его во всех сотнях записей с документами
Правильный подход (нормализованный):
- Создать отдельную таблицу пользователей с их данными (включая email).
- В таблице документов хранить только ID пользователя (внешний ключ).
- При изменении email меняем его только в одном месте.
В некоторых случаях отступить от правила нормализации можно – например, если нужно ускорить чтение часто запрашиваемых данных. Пример – для подсчета отработанных часов сотрудника пекарни за год можно:
- Каждый раз суммировать длительность всех смен (это медленно).
- Или хранить готовую сумму, обновляя ее при изменениях (гораздо быстрее).
Но помните – денормализация всегда имеет свою цену:
- Появляется риск несогласованности данных.
- Усложняется процесс обновления данных.
Не нужно знать наизусть все нормальные формы из учебников, но важно понимать основной принцип: избегайте дублирования данных, если у вас нет веской причины для обратного.
Следуйте рекомендациям разработчиков PostgreSQL
Разработчики PostgreSQL создали список «Не делайте этого» в официальной вики, который содержит важные рекомендации. Не все они будут понятны начинающему разработчику (и это нормально). Вот главные моменты:
- Для хранения текста всегда используйте тип данных text. Это универсальное решение для любого текстового контента. Не нужно беспокоиться о максимальной длине – PostgreSQL эффективно обрабатывает тип text независимо от размера данных.
- Для хранения временных меток используйте timestamptz или time with time zone. Эти типы автоматически учитывают часовые пояса, обеспечивают корректную работу с данными из разных временных зон и помогают избежать проблем с переходом на летнее/зимнее время.
- Называйте таблицы в стиле snake_case – используйте нижний регистр, разделяйте слова подчеркиваниями: user_profiles, payment_transactions, order_items и т. д.
Учитывайте особенности SQL

Регистр запросов
В SQL регистр ключевых слов не имеет значения. То есть, когда вы видите в документации и учебниках SQL-запросы, написанные заглавными буквами, например:
SELECT * FROM my_table WHERE x = 1 AND y > 2 LIMIT 10;
На самом деле вы можете писать то же самое строчными буквами:
select * from my_table where x = 1 and y > 2 limit 10;
Или даже смешанным стилем:
SELECT * from my_table WHERE x = 1 and y > 2 LIMIT 10;
Это справедливо не только для PostgreSQL, но и для других SQL баз данных.
NULL в SQL
NULL в SQL существенно отличается от null/nil в других языках программирования. В SQL NULL лучше понимать как «неизвестное значение». NULL обладает несколькими неожиданными особенностями: например, сравнение NULL = NULL возвращает NULL (а не true, поскольку SQL не может знать, равны ли два неизвестных значения).
Практически все обычные операторы сравнения при работе с NULL возвращают NULL. Чтобы вернуть true/false, используют специальные операторы:
| x IS NULL | вернет true, если x это NULL (false в обратном случае) |
| x IS NOT NULL | вернет true, если x это не NULL (false в обратном случае) |
| x IS NOT DISTINCT FROM y | работает как =, но корректно обрабатывает NULL |
| x IS DISTINCT FROM y | работает как !=, но корректно обрабатывает NULL |
Важнo заметить, что WHERE выбирает только строки, где условие возвращает true. Например, этот запрос НЕ вернет строки, где title равен NULL:
SELECT * FROM users WHERE title != 'manager'
Это происходит потому, что NULL != 'manager' возвращает NULL, а не true или false.
Другая важная функция для работы с NULL – COALESCE. Она принимает несколько аргументов и возвращает первое не-NULL значение из списка:
COALESCE(NULL, 5, 10) = 5
COALESCE(2, NULL, 9) = 2
COALESCE(NULL, NULL) IS NULL
Используйте возможности psql

Как сделать вывод psql более удобным для чтения
Когда вы делаете запрос к таблице со множеством столбцов или длинными значениями, вывод часто становится нечитаемым. Это потому, что вы не используете терминальный пейджер. Пейджер позволяет просматривать текст, прокручивая его в окне терминала. less – стандартный пейджер в Unix-подобных системах. Для использования less как пейджера по умолчанию добавьте в ваш ~/.bashrc или ~/.zshrc:
# Опция -S предотвращает перенос длинных строк
export PAGER='less -S'
Расширенный режим вывода
Таблицы со множеством столбцов неудобно просматривать, даже если данные идеально отформатированы. В этом случае можно включить расширенный режим командой \pset expanded или коротко \x. Чтобы включить этот режим по умолчанию, создайте файл ~/.psqlrc и добавьте туда команду \x. При каждом запуске psql все команды из этого файла будут выполняться автоматически.
Как сделать значения NULL более заметными
Когда в таблице встречается значение NULL, по умолчанию оно отображается просто как пустое место, что может приводить к путанице. Чтобы решить эту проблему, можно настроить специальное отображение NULL-значений. Для этого выполните команду в консоли psql:
\pset null '[NULL]'
При желании можно использовать любую строку, даже эмодзи, например 👻 как индикатор NULL. Чтобы сделать эту настройку постоянной, создайте файл .psqlrc в домашней директории ~/.psqlrc и добавьте в него строку \pset null '[NULL]'.
Автодополнение
psql имеет встроенную функцию автодополнения, которая значительно ускоряет работу. Начните вводить SQL-команду или имя таблицы, нажмите клавишу Tab – psql автоматически дополнит строку:
-- начните печатать "SEL"
SEL
-- ^ нажмите `Tab`
SELECT
Сокращенные команды
В psql есть множество удобных команд, которые начинаются с обратного слэша \. Эти команды помогают быстро находить информацию, редактировать запросы и выполнять другие полезные действия. Вот основные из них:
| \? | Показывает список всех доступных команд. |
| \d | Показывает список объектов (таблиц и последовательностей) вместе с их владельцами. |
| \d+ | То же, что и \d, но дополнительно показывает размер объектов и дополнительную метаинформацию. |
| \d table_name | Показывает структуру таблицы: список столбцов (с их типами, допускаемостью NULL и значениями по умолчанию), а также индексы и внешние ключи. |
| \e | Открывает ваш текстовый редактор (по умолчанию тот, что указан в переменной окружения $EDITOR) для редактирования SQL-запроса. |
| \h SQL_KEYWORD | Показывает синтаксис для указанного SQL-ключевого слова (например, SELECT, INSERT) и ссылку на документацию. |
Эти команды – лишь верхушка айсберга. В psql есть множество других сокращений, которые значительно упрощают работу с базами данных. Попробуйте команду \?, чтобы увидеть полный список.
Запись результата выполнения запроса в CSV
В PostgreSQL можно легко сохранить результат выполнения любого запроса в CSV-файл:
\copy (select * from some_table) to 'my_file.csv' CSV
Если нужно, чтобы в первой строке файла были указаны названия колонок таблицы, добавьте опцию HEADER:
\copy (select * from some_table) to 'my_file.csv' CSV HEADER
Сокращения и псевдонимы
В psql можно использовать сокращения и псевдонимы (алиасы) для упрощения работы с выводом запросов и их организации. Например, с помощью ключевого слова AS можно задать любое название для столбца в выводе:
SELECT vendor, COUNT(*) AS number_of_backpacks FROM backpacks GROUP BY vendor ORDER BY number_of_backpacks DESC;
GROUP BY и ORDER BY позволяют ссылаться на столбцы не только по имени, но и по их порядковому номеру в списке SELECT. Например, тот же запрос можно записать так:
SELECT vendor, COUNT(*) AS number_of_backpacks FROM backpacks GROUP BY 1 ORDER BY 2 DESC;
Однако не рекомендуется использовать эту практику в продакшене.
Почему индексы могут оказаться бесполезными

Индекс – структура данных, которая помогает ускорять поиск данных в таблице. Она действует как быстрый справочник для доступа к строкам таблицы по определенным полям. Наиболее распространенный тип индекса – B-дерево (B-tree), который подходит для:
- Проверки на равенство (WHERE a = 3).
- Поиска в диапазонах (WHERE a > 5).
Однако индекс может оказаться бесполезным по нескольким причинам:
- PostgreSQL сама решает, использовать ли индекс. СУБД анализирует статистику таблицы и определяет, будет ли использование индекса быстрее, чем последовательное сканирование всей таблицы.
- Если индекс создан неправильно или не соответствует условиям запроса, PostgreSQL просто его проигнорирует. Например, индекс на поле a не поможет, если в запросе используется условие WHERE b = 3. К тому же, индексы не эффективны, если запрос фильтрует по слишком большому количеству строк (в этом случае последовательное сканирование может быть быстрее).
- Индекс бесполезен для таблиц с небольшим количеством строк. Если в таблице всего несколько десятков или сотен строк, PostgreSQL часто предпочитает выполнять последовательное сканирование вместо использования индекса. Это объясняется тем, что накладные расходы на использование индекса (например, переход по структуре B-дерева) могут быть больше, чем простое чтение всех строк подряд.
- Порядок столбцов в многоколонных индексах критически важен: первый столбец всегда является основным для поиска. Запросы, фильтрующие, например, только по второму столбцу, могут использовать многоколонный индекс, но его эффективность будет ниже. Для сложных запросов с различными комбинациями условий может потребоваться несколько разных индексов.
- Стандартный индекс типа B-tree, скорее всего, не будет использоваться для запросов на основе совпадения по префиксу LIKE 'prefix%'. Для ускорения запросов с префиксным совпадением создайте индекс с text_pattern_ops:
CREATE INDEX CONCURRENTLY ON directories (path text_pattern_ops);
Долгие блокировки могут навредить вашему приложению
Блокировка (или мьютекс) предотвращает одновременное выполнение опасных операций. Этот механизм нужен для того, чтобы гарантировать, что операция с данными (например, обновление строки, таблицы или представления) либо полностью выполнится, либо полностью откатится. Без блокировки две параллельные операции могут привести к несогласованности данных.
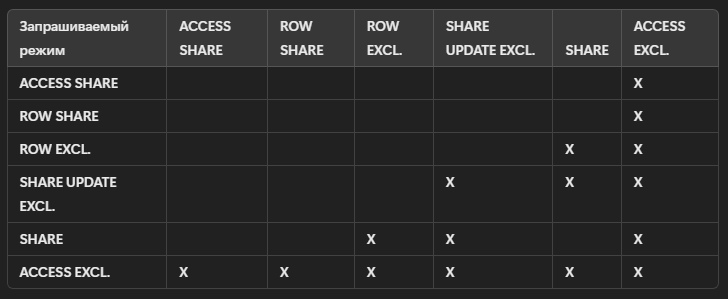
Каждая операция в PostgreSQL требует блокировки соответствующего объекта (таблицы, строки и т. д.) Существует несколько уровней блокировок, от менее до более строгих:
| Режим блокировки | Примеры операторов |
| ACCESS SHARE | SELECT |
| ROW SHARE | SELECT ... FOR UPDATE |
| ROW EXCLUSIVE | UPDATE, DELETE, INSERT |
| SHARE UPDATE EXCLUSIVE | CREATE INDEX CONCURRENTLY |
| SHARE | CREATE INDEX (без CONCURRENTLY) |
| ACCESS EXCLUSIVE | ALTER TABLE, DROP TABLE |
Некоторые блокировки конфликтуют друг с другом (Х означает конфликт)):
Примеры ситуаций для одной таблицы:

Как это может создать проблемы? Если одна операция (например, ALTER TABLE) требует блокировки, она может заблокировать все последующие запросы к таблице. Пример:
- Клиент 1 запускает медленный SELECT (например, внутреннюю панель с отчетами, которая работает долго из-за большого объема данных).
- Клиент 2 запускает ALTER TABLE, чтобы добавить новый столбец. Этот запрос должен дождаться завершения SELECT от клиента 1
- Вся очередь последующих запросов (SELECT, UPDATE и т. д.) будет ждать, пока завершатся операции 1 и 2.
Последствия:
Если ALTER TABLE влияет на часто используемую таблицу (например, users), все запросы к этой таблице временно заблокируются. Это может привести к таймаутам и ошибкам 503 в приложении.
Транзакции тоже могут негативно влиять на производительность
Транзакция – это способ сгруппировать несколько операций с базой данных так, чтобы они выполнялись как единое целое (это делает транзакцию атомарной). Транзакция начинается с команды BEGIN, после чего любые изменения, сделанные в ее рамках, недоступны другим клиентам, пока транзакция не будет завершена с помощью COMMIT.
Если что-то пошло не так, можно отменить изменения, вызвав ROLLBACK. Это особенно полезно в случаях, когда нужно обеспечить целостность данных. Например, при переводе денег между счетами важно, чтобы либо обе операции (списание и зачисление) выполнились, либо не выполнилась ни одна.
Когда транзакция выполняется слишком долго, это может заблокировать доступ других клиентов к данным, которые она изменила или использует. Это связано с тем, что транзакция удерживает блокировки до ее завершения (COMMIT или ROLLBACK). Предположим, клиент 1 работает с базой данных:
BEGIN;
SELECT * FROM backpacks WHERE id = 2;
UPDATE backpacks SET content_count = 3 WHERE id = 2;
SELECT count(*) FROM backpacks;
-- Клиент 1 оставил транзакцию незавершенной
В этой ситуации клиент 1 обновил данные в таблице backpacks, но не завершил транзакцию. Это означает, что строка с id = 2 остается заблокированной. Если клиент 2 попытается удалить эту строку:
DELETE FROM backpacks WHERE id = 2;
Операция зависнет, так как блокировка, удерживаемая клиентом 1, мешает выполнению команды DELETE.
Осторожнее с JSONB

В PostgreSQL можно хранить JSON-данные в формате JSONB, которые эффективно сериализуются и доступны для запросов. Это делает PostgreSQL схожим с документно-ориентированными базами данных (например, MongoDB), но без необходимости запускать дополнительный сервис или управлять несколькими хранилищами данных.
Однако у JSONB есть свои нюансы, которые могут превратиться в серьезную проблему при неправильном использовании.
JSONB медленнее обычных колонок
PostgreSQL не собирает статистику по JSONB-колонкам. Это может привести к тому, что запросы к JSONB будут выполняться значительно медленнее, чем к обычным колонкам. Например, некоторые запросы могут быть медленнее в 2000 раз.
Самодокументированность не предусмотрена
JSONB позволяет хранить произвольные данные, что удобно, но у вас нет гарантий относительно их структуры. При работе с обычной таблицей вы можете посмотреть схему и понять, какие данные вернет запрос. В случае с JSONB такой предсказуемости нет. Например, вам не будет очевидно:
- Используется ли camelCase или snake_case?
- Хранятся ли состояния в виде true/false, или используются строки вроде yes/maybe/no?
Неудобство работы с типами
Запросы к JSONB могут быть непривычными из-за особенностей синтаксиса. К примеру, у нас есть таблица backpacks с колонкой data типа JSONB. Нам нужно найти все рюкзаки бренда JanSport. Интуитивно можно написать такой запрос:
select * from backpacks where data['brand'] = 'JanSport';
Но это вызовет ошибку:
ERROR: invalid input syntax for type json
LINE 1: select * from backpacks where data['brand'] = 'JanSport';
^
DETAIL: Token "JanSport" is invalid.
CONTEXT: JSON data, line 1: JanSport
Причина в том, что PostgreSQL ожидает, что правое значение (JanSport) будет валидным JSON-объектом. Чтобы исправить запрос, нужно либо заключить строку в двойные кавычки:
select * from backpacks where data['brand'] = '"JanSport"';
Или использовать оператор ->> для извлечения значения как текста:
select * from backpacks where data->>'brand' = 'JanSport';
Также стоит отметить эти важные особенности:
- JSONB использует множество своих собственных операторов и функций, которые не так-то просто запомнить.
- В отличие от NULL в SQL, null в контексте JSONB – обычное конкретное значение, подобное числу, строке или булевому значению. Это значение, как и null в других языках программирования, можно сравнивать. Например, в JSONB выражение
'null'::jsonb = 'null'::jsonbвозвращает TRUE, так как оба значения явно равны.
В заключение
PostgreSQL предоставляет разработчикам обширные возможности для работы с данными. Однако эффективность еe использования зависит от понимания ключевых аспектов и нюансов, многие из которых были рассмотрены в этой статье: умелое применение JSONB, нормализация данных, настройка индексов, избегание долгих блокировок и запросов делают приложения на базе PostgreSQL более производительными и стабильными.
Комментарии