
Начинающие аналитики данных уже на ранних этапах задумываются о вариантах приложения недавно приобретенных знаний или участвуют в соревнованиях Kaggle. Однако творческие силы можно и сразу направить на полезный замысел, нацеленный на улучшение мира, уменьшение количества рутинных действий и решение конкретных практических задач. Подходящими площадками для проявления талантов специалистов Data Science являются open source проекты. Ниже мы рассмотрим шесть репозиториев программ с открытым исходным кодом, участие в которых разнообразит ваше резюме или усилит разрабатываемые аналитические решения.
1. Синтез сложных видео из простых моделей
Идея vid2vid состоит в преобразовании семантически простой входной модели (обычно в форме видеоролика) в ультра-реалистичное выходное видео. Это не совсем то же, что DeepFake, хотя и предполагает перенос особенностей одной модели на механику другой системы. Наглядно разнообразные примеры использования представлены в следующем YouTube-ролике.
В настоящее время есть два существенных ограничения моделей vid2vid:
- Огромное количество данных, необходимых для обучения.
- Модели стремятся к обобщению обучающих данных.
Репозиторий GitHub представляет собой реализацию Few-Shot vid2vid на фреймворке PyTorch. Имеется также научная статья, описывающая результат.
2. Сверхлегкий и быстрый детектор лиц
Второй пункт в нашей подборке – удивительный опенсорс-релиз ультралегкой модели распознавания лиц. Не бойтесь, что описание дано на китайском языке – страница легко переводится с помощью Google Translate. Куда важнее, что размер модели составляет всего лишь 1 Мб!

Для детектирования лиц используется архитектура, основанная на библиотеке libfacedetection. Существуют две версии модели:
- slim-версия (немного более простая, но быстрая)
- RFB-версия (модель с лучшей точностью)
Такая легковесная библиотека – блестящая возможность для создания более сложных моделей компьютерного зрения на компактных системах. Если вы новичок в мире распознавания лиц и computer vision, у нас имеется учебный план освоения компьютерного зрения.
3. Точный и быстрый детектор объектов для автономного вождения
В основе идеи автономного управления транспортными средствами лежат алгоритмы обнаружения объектов. Высокие точность обнаружения и скорость вывода данных жизненно важны для обеспечения безопасности жизни. Архитектура библиотеки Gaussian YOLOv3 повышает точность обнаружения и поддерживает работу в режиме реального времени, что является критическим аспектом для построения автопилотов.

В сравнении с обычным YOLOv3 данная модификация имеет лучшие показатели на датасетах, напрямую связанных с вождением транспорта – KITTI и Berkeley deep drive.
4. Преобразование текста от Google Research
Как Google может остаться вне списка «последних достижений»? Компания выделила огромные средства на машинное обучение, глубокое обучение, обучение с подкреплением. К счастью, время от времени они открывают свои проекты с открытым исходным кодом, и у них есть чему поучиться.
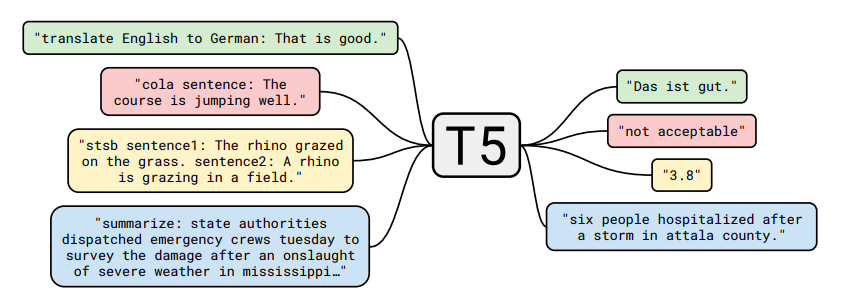
Одним из таких решений является T5 (сокращение от Text-to-Text Transfer Transformer). Идея основана на концепции переноса обучения при обработке естественного языка. Разработанная структура позволяет получать современные результаты в различных задачах, связанных с текстом: обобщение, поиск ответа на заданный вопрос, классификация текста и многое другое.
Установить T5 для Python можно с помощью pip:
pip install t5[gcp]
5. Крупнейшая карта знаний
В теории Data Science существуют определенные примеры использования теории графов. Не совсем привычными в этом плане являются тематические карты, диаграммы связей и карты концептов. Следующий проект является своеобразным монстром среди подобных систем. Это самая большая карта знаний, сделанная в Китае и состоящая из более, чем 140 млн узлов.

Набор данных организован в виде троек (сущность, атрибут, значение) и (сущность, отношение, сущность). Данные хранятся в формате csv. Простота и величина проекта дают возможность вдоволь поиграть с различными алгоритмами теории графов и обработки больших объемов данных.
6. Библиотека визуализации данных в JavaScript
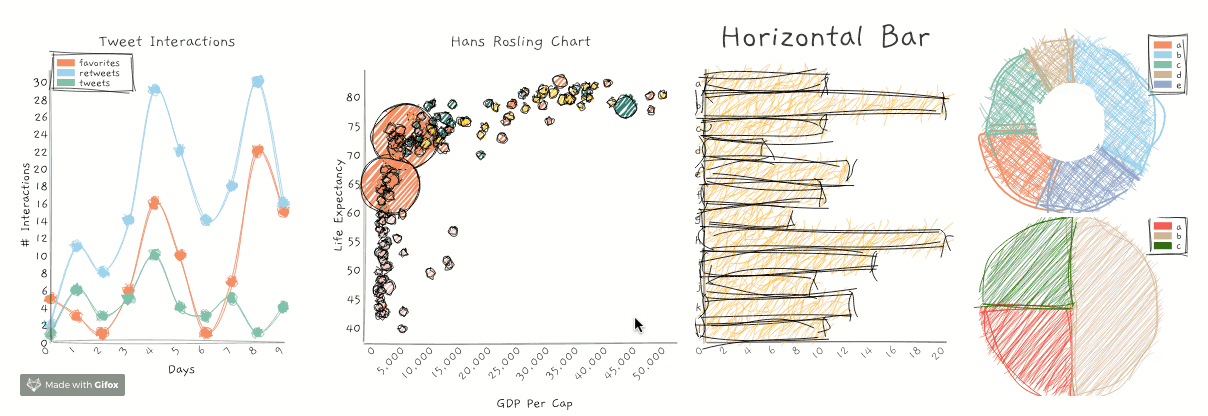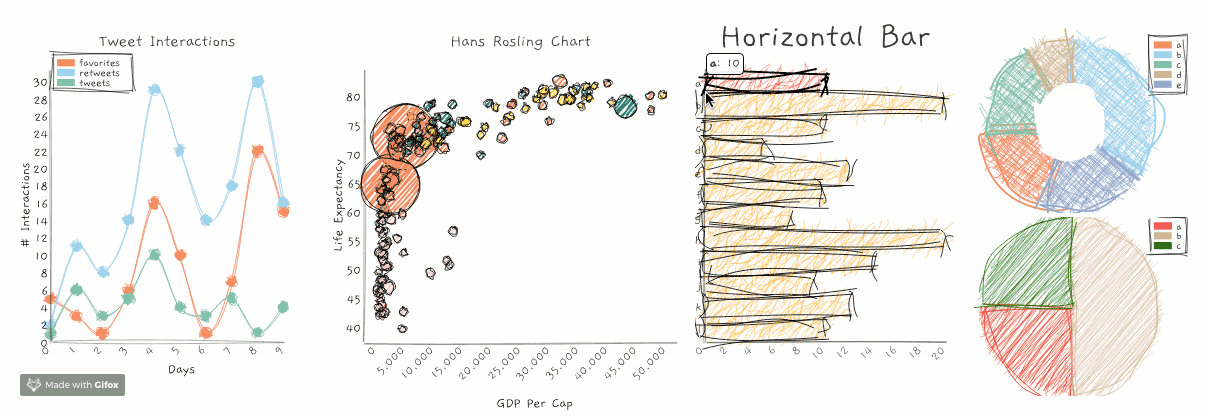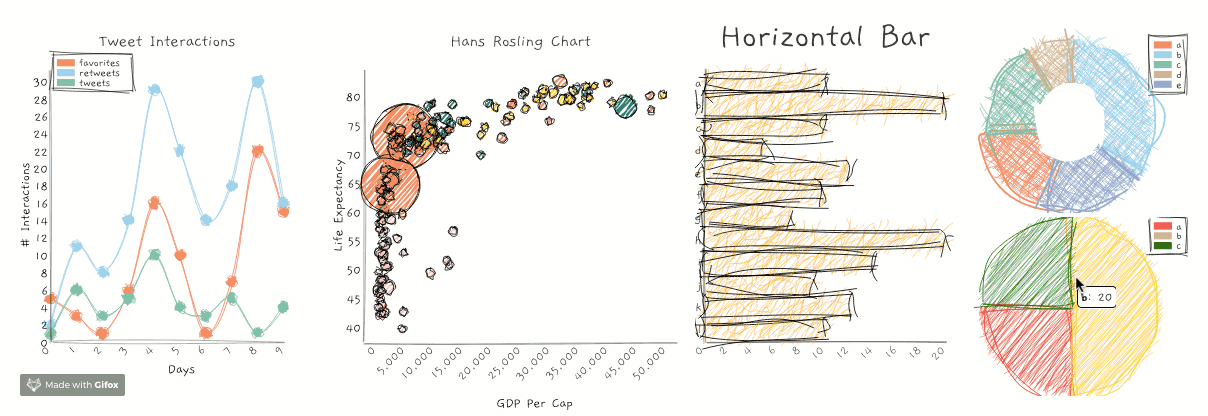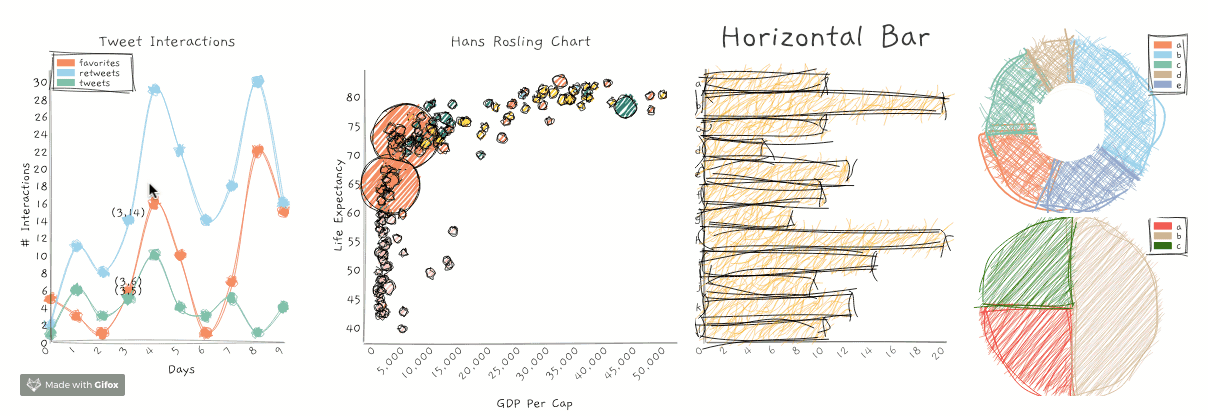
RoughViz – библиотека JavaScript для визуализации данных в стиле нарисованных от руки изображений.
Вы можете установить RoughViz, используя следующую команду:
npm install rough-viz
Репозиторий GitHub содержит подробные примеры и код о том, как использовать RoughViz. Вот различные диаграммы, которые вы можете сгенерировать:
- Гистограмма
- Кольцевая диаграмма
- Линейный график
- Круговая диаграмма
- Точечная диаграмма
Если вы удивлены, что JavaScript может использоваться в Data Science, почитайте нашу публикацию о JavaScript-версии TensorFlow.
Комментарии