

Паттерны проектирования в библиотеках и коде
Паттерн «фабрика»
Паттерн «фабрика» отделяет объекты, такие, как обучающие данные, от того, как они создаются. Создание этих объектов иногда может быть сложным (например, распределенные загрузчики данных), но использование данного паттерна помогает пользователям, упрощая создание объектов и обеспечивая соблюдение ограничений, которые помогают предотвращать ошибки.
Базовая фабрика может быть определена через интерфейс или абстрактный класс. Затем, чтобы создать новую фабрику, мы можем создать ее подкласс и предоставить детали собственной реализации.
PyTorch Dataset — хороший пример. Чтобы создать наши собственные наборы данных, мы должны создать подкласс Dataset и переопределить методы __len__и __getitem__. Первый возвращает размер набора данных, а второй поддерживает индексирование для получения i-го примера. Вот пример создания пользовательского набора данных.
from torch.utils.data import Dataset
class SequencesDataset(Dataset):
def __init__(self, sequences: Sequences, neg_sample_size=5):
self.sequences = sequences
self.neg_sample_size = neg_sample_size
def __len__(self):
return self.sequences.n_sequences
def __getitem__(self, idx):
pairs = self.sequences.get_pairs(idx)
neg_samples = []
for center, context in pairs:
neg_samples.append(self.sequences.get_negative_samples(context))
return pairs, neg_samples
Gensim textcorpus — еще один пример, упрощающий чтение текстовых файлов для последующего языкового моделирования. Пользователям необходимо переопределить get_texts() – метод для чтения и обработки одной строки (или документа) и возврата ее в виде последовательности слов.
from gensim.corpora.textcorpus import TextCorpus
from gensim.test.utils import datapath
from gensim import utils
class CorpusMiislita(TextCorpus):
stopwords = set('for a of the and to in on'.split())
def get_texts(self):
for doc in self.getstream():
yield [word for word in utils.to_unicode(doc).lower().split() if word not in self.stopwords]
def __len__(self):
self.length = sum(1 for _ in self.get_texts())
return self.length
corpus = CorpusMiislita(datapath('head500.noblanks.cor.bz2'))
>>> len(corpus)
250
document = next(iter(corpus.get_texts()))
Последний пример — Hugging Face Dataset, не требующий подкласса. Он предоставляет пользователям простой способ загрузки данных в Apache Arrow, который обеспечивает быстрый поиск с низкими требованиями к памяти. Он также включает методы потоковой передачи, чередования, перемешивания и т. д.
from datasets import load_dataset
from datasets import interleave_datasets
# Load as streaming = True
en_dataset = load_dataset('oscar', "unshuffled_deduplicated_en", split='train', streaming=True)
fr_dataset = load_dataset('oscar', "unshuffled_deduplicated_fr", split='train', streaming=True)
# Interleave
multilingual_dataset = interleave_datasets([en_dataset, fr_dataset])
# Shuffle
shuffled_dataset = multilingual_dataset.shuffle(seed=42, buffer_size=10_000)
Паттерн «адаптер»
Паттерн «адаптер» повышает совместимость между интерфейсами, такими форматы данных как CSV, Parquet, JSON и т.д. Это позволяет объектам (например, сохраненным данным) с несовместимыми интерфейсами взаимодействовать. В конкретных конвейерах обработки данных адаптеры часто используются для чтения данных, хранящихся в различных форматах, в стандартный объект данных, такой как Dataframe.
Например, у Pandas есть почти 20 адаптеров для чтения большинства типов файловых хранилищ в pandas Dataframe.
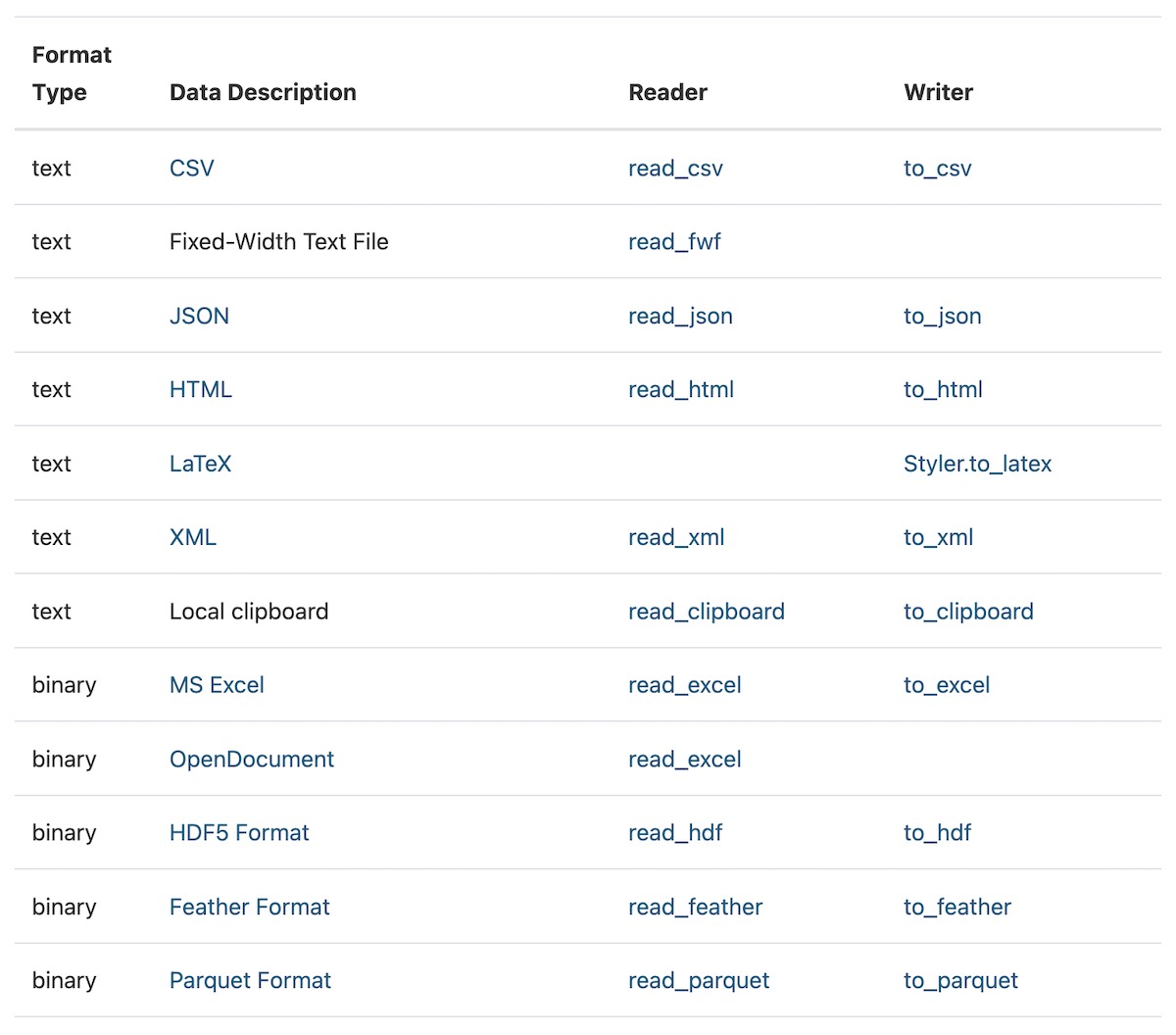
Точно так же Spark имеет адаптеры для чтения из различных форматов данных, таких как Parquet, JSON, CSV, Hive и текстовые файлы.
val parquetDf = spark.read.parquet("people.parquet")
val jsonDf = spark.read.json("examples/src/main/resources/people.json")
val hiveDF = sql("SELECT name, job_family FROM people WHERE age < 60 ORDER BY age")
val csvDf = spark.read.csv("examples/src/main/resources/people.csv")
val textDf = spark.read.text("examples/src/main/resources/people.txt")
Другим примером является Apache Arrow, который предоставляет стандартный формат столбцов для нескольких платформ данных, таких как Pandas, Spark, Parquet, Cassandra и других. (Набор данных Hugging Face использует Arrow для своей локальной системы кэширования.)

Паттерн «декоратор»
Паттерн «декоратор» позволяет пользователям легко добавлять функциональные возможности в свой существующий код. Объекты можно «декорировать» (т. е. добавлять функциональные возможности) во время выполнения без необходимости обновления структуры или поведения других объектов того же класса.
В Python методы декорирования легко реализуются с помощью @синтаксиса. Использование @decorator эквивалентно вызову method() — method = decorator(method).
Удобным примером встроенного оператора является оператор functool lru_cache(). Он сохраняет самые последние вызовы x в словаре, который сопоставляет входные аргументы с возвращаемыми результатами. Вот пример использования кэша для эффективного вычисления чисел Фибоначчи.
from functools import lru_cache
@lru_cache(maxsize=None)
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)
>>> [fib(n) for n in range(16)]
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610]
>>> fib.cache_info()
CacheInfo(hits=28, misses=16, maxsize=None, currsize=16)
Другой пример — декораторы Pytest для определения фикстур. Затем на эти фикстуры можно ссылаться в последующих тестах. Думайте о фикстурах как о методах, которые генерируют данные для тестирования ожидаемого поведения. Эти фикстуры вызываются перед запуском любых тестов и совместно используются тестами. Вот несколько примеров фикстур для загрузки демонстрационных данных и обученных моделей.
import pytest
import numpy as np
from src.data_prep.prep_titanic import load_df, prep_df, split_df, get_feats_and_labels
from src.tree.decision_tree import DecisionTree
from src.tree.random_forest import RandomForest
# Returns data for training and evaluating our models
@pytest.fixture
def dummy_dataset():
df = load_df()
df = prep_df(df)
train, test = split_df(df)
X_train, y_train = get_feats_and_labels(train)
X_test, y_test = get_feats_and_labels(test)
return X_train, y_train, X_test, y_test
# Returns a trained DecisionTree that is evaluated on implementation and behavior
@pytest.fixture
def dummy_decision_tree(dummy_dataset):
X_train, y_train, _, _ = dummy_dataset
dt = DecisionTree(depth_limit=5)
dt.fit(X_train, y_train)
return dt
# Returns a trained RandomForest that is evaluated on implementation and behavior
@pytest.fixture
def dummy_random_forest(dummy_dataset):
X_train, y_train, _, _ = dummy_dataset
rf = RandomForest(num_trees=8, depth_limit=5, col_subsampling=0.8, row_subsampling=0.8)
rf.fit(X_train, y_train)
return rf
Простой декоратор, который я часто использую — это таймер, который измеряет, сколько времени занимает вызов метода, и возвращает результаты. Это полезно при создании прототипов, которые вызывают разные модели — с разной задержкой — для проверки времени, затрачиваемого на каждый вызов.
from functools import wraps
from time import perf_counter
from typing import Callable
from typing import Tuple
def timer(func: Callable) -> Callable:
@wraps(func)
def wrapper(*args, **kwargs):
start = perf_counter()
results = func(*args, **kwargs)
end = perf_counter()
run_time = end - start
return results, run_time
return wrapper
@timer
def predict_with_time(model, X_test: np.array) -> Tuple[np.array]:
return model.predict(X_test)
Паттерн «стратегия»
Паттерн «стратегия» позволяет пользователям изменять предполагаемое поведение объекта или алгоритм. Пользователи могут создавать новые объекты для каждой стратегии (или алгоритма), и в зависимости от используемого объекта стратегии поведение контекста может меняться во время выполнения. Это отделяет алгоритмы от клиентов, добавляя гибкости и возможности повторного использования кода.
Большинство библиотек машинного обучения имеют встроенные алгоритмы и настройки. Тем не менее, они также предоставляют пользователям возможность добавлять свои собственные алгоритмы, если они соответствуют интерфейсу стратегии.
Например, XGBoost предоставляет различные методы построения деревьев (например, точное, приблизительное, гистологическое, gpu_hist) и несколько целевых функций, таких как квадрат ошибки, логистическое и попарное ранжирование. Тем не менее, мы также можем предоставить пользовательскую целевую функцию, если захотим, например, приведенный ниже пример ошибки квадратного журнала.
import numpy as np
import xgboost as xgb
from typing import Tuple
def gradient(predt: np.ndarray, dtrain: xgb.DMatrix) -> np.ndarray:
y = dtrain.get_label()
return (np.log1p(predt) - np.log1p(y)) / (predt + 1)
def hessian(predt: np.ndarray, dtrain: xgb.DMatrix) -> np.ndarray:
y = dtrain.get_label()
return ((-np.log1p(predt) + np.log1p(y) + 1) / np.power(predt + 1, 2))
def squared_log(predt: np.ndarray, dtrain: xgb.DMatrix) -> Tuple[np.ndarray, np.ndarray]:
predt[predt < -1] = -1 + 1e-6
grad = gradient(predt, dtrain)
hess = hessian(predt, dtrain)
return grad, hess
xgb.train({'tree_method': 'hist', 'seed': 1994},
dtrain=dtrain,
num_boost_round=10,
obj=squared_log) # Using the custom objective function
Точно так же конвейер Hugging Face позволяет легко использовать различные стратегии (также известные как языковые модели) для логического вывода. Pipelines поддерживает такие задачи, как анализ настроений, перевод, ответы на вопросы и многое другое.
from transformers import pipeline
pipe = pipeline("sentiment-analysis")
>>> pipe(["This restaurant is awesome", "This restaurant is aweful"])
[{'label': 'POSITIVE', 'score': 0.9998743534088135},
{'label': 'NEGATIVE', 'score': 0.9996669292449951}]
en_fr_translator = pipeline("translation_en_to_fr")
>>> en_fr_translator("How old are you?")
[{'translation_text': ' quel âge êtes-vous?'}]
qa_model = pipeline("question-answering")
question = "Where do I live?"
context = "My name is Merve and I live in İstanbul."
>>> qa_model(question = question, context = context)
{'answer': 'İstanbul', 'end': 39, 'score': 0.953, 'start': 31}
Паттерн «итератор»
Паттерн «итератор» обеспечивает способ просмотра объектов в коллекции объектов. Это отделяет алгоритм обхода от контейнера данных, и пользователи могут задать свой собственный алгоритм. Например, если у нас есть данные в дереве, мы можем захотеть переключаться между обходом в ширину и обходом в глубину.
Примером может служить DataLoader из PyTorch, который позволяет пользователям определять размер пакета, перетасовку, число работников и даже предоставлять пользовательские функции сортировки.
from torch.utils.data import DataLoader
dataset = SequencesDataset(sequences)
def collate(batches):
batch_list = []
for batch in batches:
pairs = np.array(batch[0])
negs = np.array(batch[1])
negs = np.vstack((pairs[:, 0].repeat(negs.shape[1]), negs.ravel())).T
pairs_arr = np.ones((pairs.shape[0], pairs.shape[1] + 1), dtype=int)
pairs_arr[:, :-1] = pairs
negs_arr = np.zeros((negs.shape[0], negs.shape[1] + 1), dtype=int)
negs_arr[:, :-1] = negs
all_arr = np.vstack((pairs_arr, negs_arr))
batch_list.append(all_arr)
batch_array = np.vstack(batch_list)
# Return item1, item2, label
return (torch.LongTensor(batch_array[:, 0]), torch.LongTensor(batch_array[:, 1]),
torch.FloatTensor(batch_array[:, 2]))
# We can customize the batch size, number of works, shuffle, etc.
train_dataloader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=8, collate_fn=collate)
Паттерн «конвейер»
Паттерн «конвейер» («pipeline») позволяет пользователям связывать последовательность преобразований. Преобразования — это этапы обработки данных, такие как очистка данных, разработка функций, уменьшение размерности и т. д. В конец конвейера можно добавить блок оценки (также известный как модель машинного обучения). Таким образом, конвейер принимает данные в качестве входных данных, преобразует их и в конце обучает модель.
ИМХО, в конвейерах ML все, от подготовки данных до разработки функций и гиперпараметров модели, является параметром для настройки. Возможность связывать и варьировать преобразования и блоки оценки обеспечивает удобную настройку параметров конвейера. Как изменятся показатели модели, если мы будем использовать непрерывные переменные или добавим триграммы к нашим текстовым функциям?
При использовании конвейера мы должны знать, что ввод и вывод каждого шага преобразования должны иметь стандартизированный формат, такой как кадр данных Pandas. Кроме того, каждое преобразование должно иметь необходимые методы, такие как .fit() и .transform().
Pipeline из Sklearn позволяет пользователям предоставлять список преобразований и окончательную оценку. Мы также можем использовать TransformerMixin для создания пользовательских преобразований.
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
X, y = make_classification(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# Create and train pipeline
pipe = Pipeline([('imputer', SimpleImputer(strategy="median")),
('scaler', StandardScaler()),
('svc', SVC())])
pipe.fit(X_train, y_train)
# Evaluate the pipeline
>>> pipe.score(X_test, y_test)
0.88
MLlib из Spark также использует концепцию конвейеров, построенных на основе фреймов данных, преобразователей и блоков оценки.
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
// Prepare training documents from a list of (id, text, label) tuples.
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")
// Configure an ML pipeline, which consists of three stages: tokenizer, hashingTF, and lr.
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.001)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
// Fit the pipeline to training documents.
val model = pipeline.fit(training)
// Now we can optionally save the fitted pipeline to disk
model.write.overwrite().save("/tmp/spark-logistic-regression-model")
Паттерны проектирования в системах
Думаю, паттерны проектирования применяются не только в коде и библиотеках, но и в системах. Вот два паттерна, обычно наблюдаемые в системах машинного обучения.
Паттерн «Заместитель»
Паттерн «заместитель» («proxy») позволяет нам заменить рабочую базу данных или службу. Затем прокси-сервер может выполнять задачи от имени конечной точки.
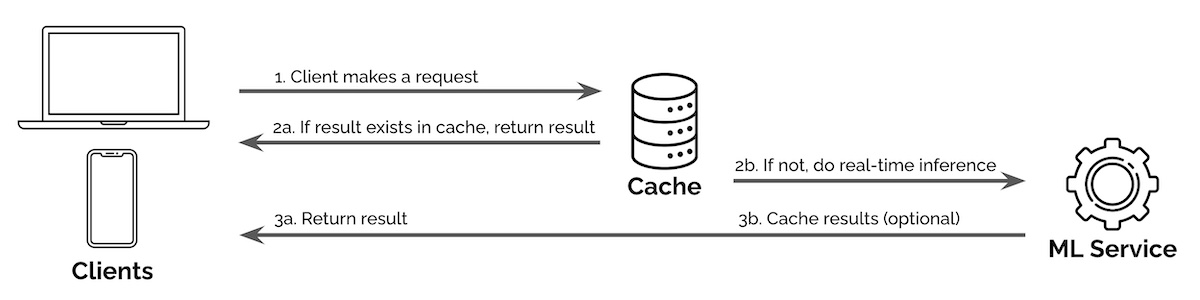
Одним из примеров является использование кеша прокси-сервера для обслуживания поисковых запросов. Поисковые запросы следуют принципу Парето, когда на долю запросов приходится важная часть запросов. Таким образом, путем кэширования результатов самых популярных запросов (например, предложение запроса, классификация запроса, извлечение и ранжирование) мы можем уменьшить объем вычислений, необходимых для логического вывода в реальном времени.
На изображении ниже при исполнении запроса наш сервис сначала проверяет, доступен ли результат в кэше. Если это так, он возвращает результат из кеша; если нет, запрос передается для логического вывода в реальном времени.
Другой пример — использование обратного прокси для обслуживания моделей. Один из способов масштабирования — обслуживание через несколько машин (т. е. горизонтальное масштабирование). Тем не менее, мы по-прежнему хотим предоставить единый адрес для доступа. Обратный прокси может принимать входящие запросы через один адрес и распределять их по нескольким серверам, чтобы распределить нагрузку и обеспечить низкую задержку.
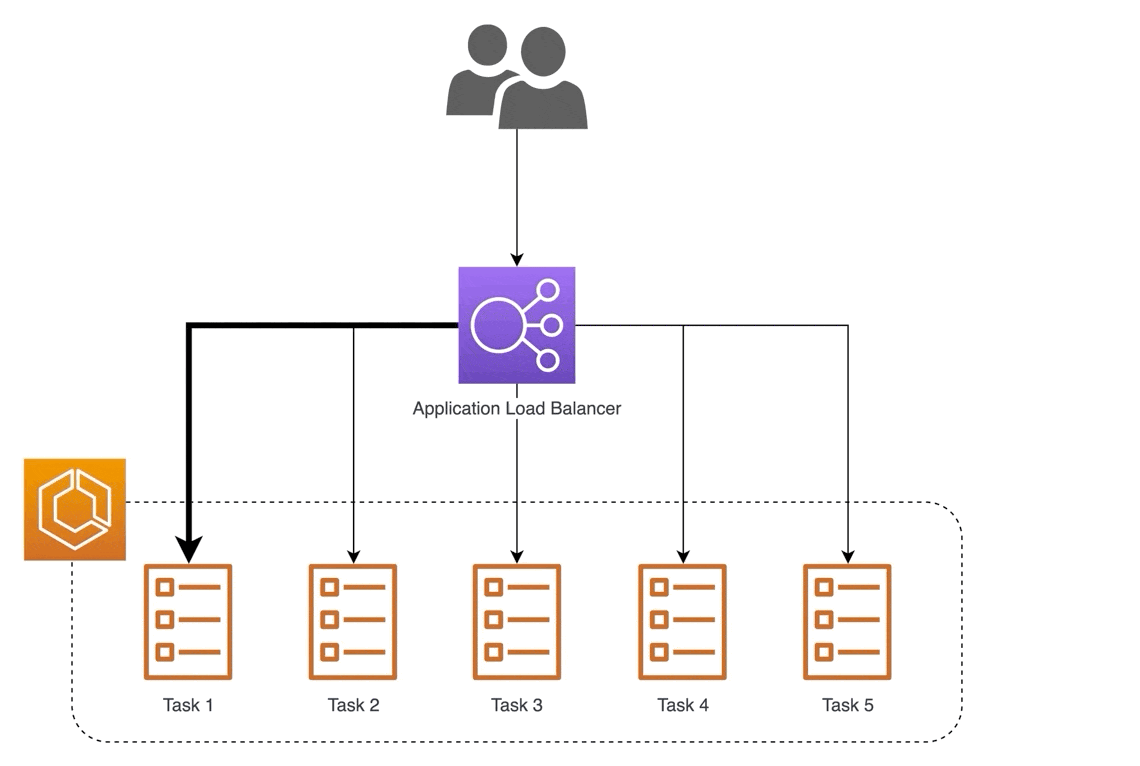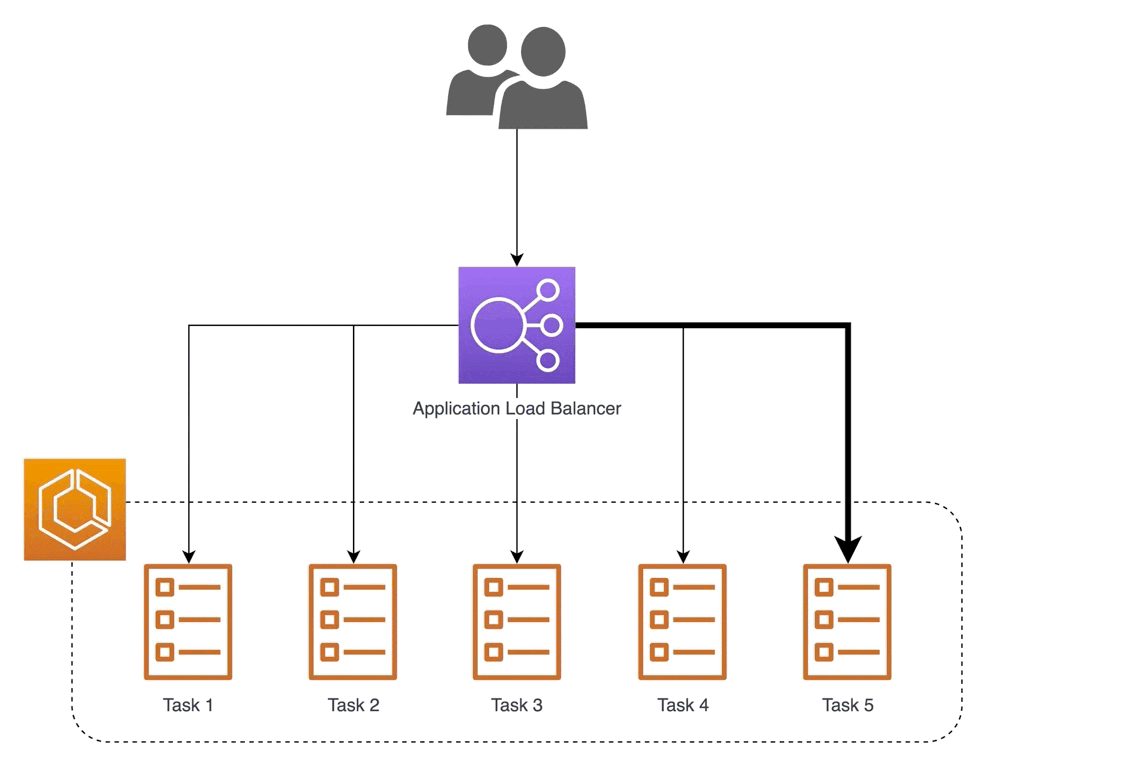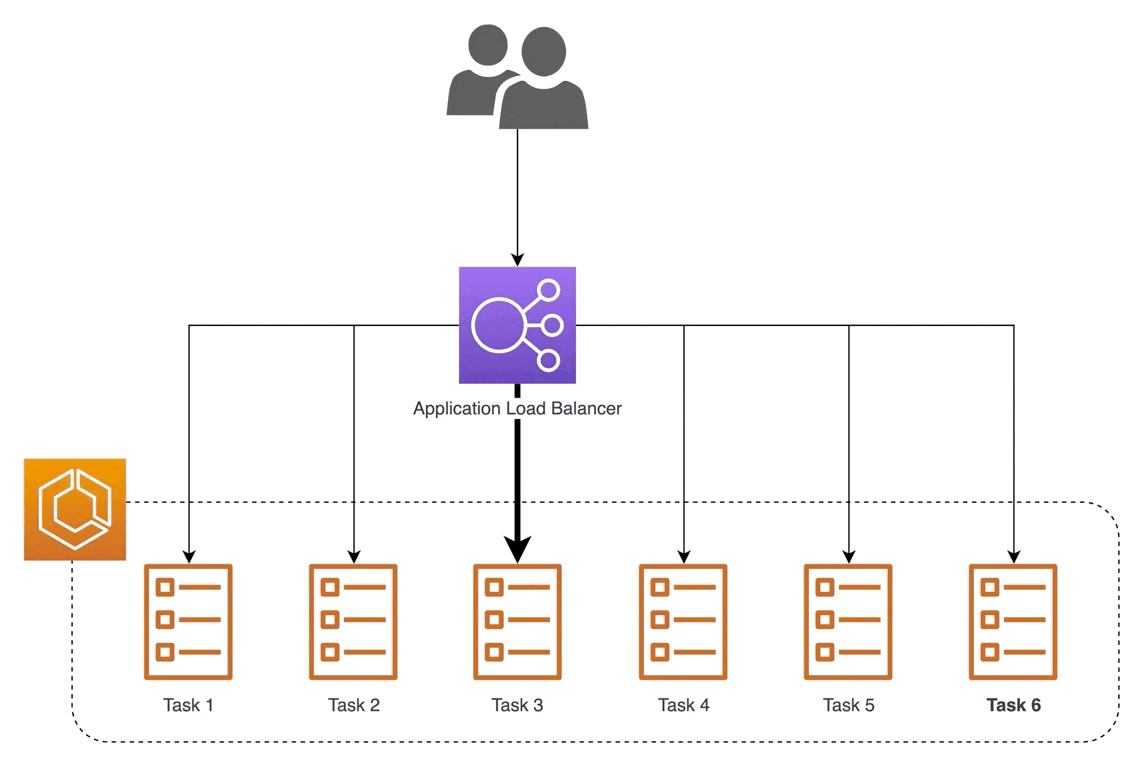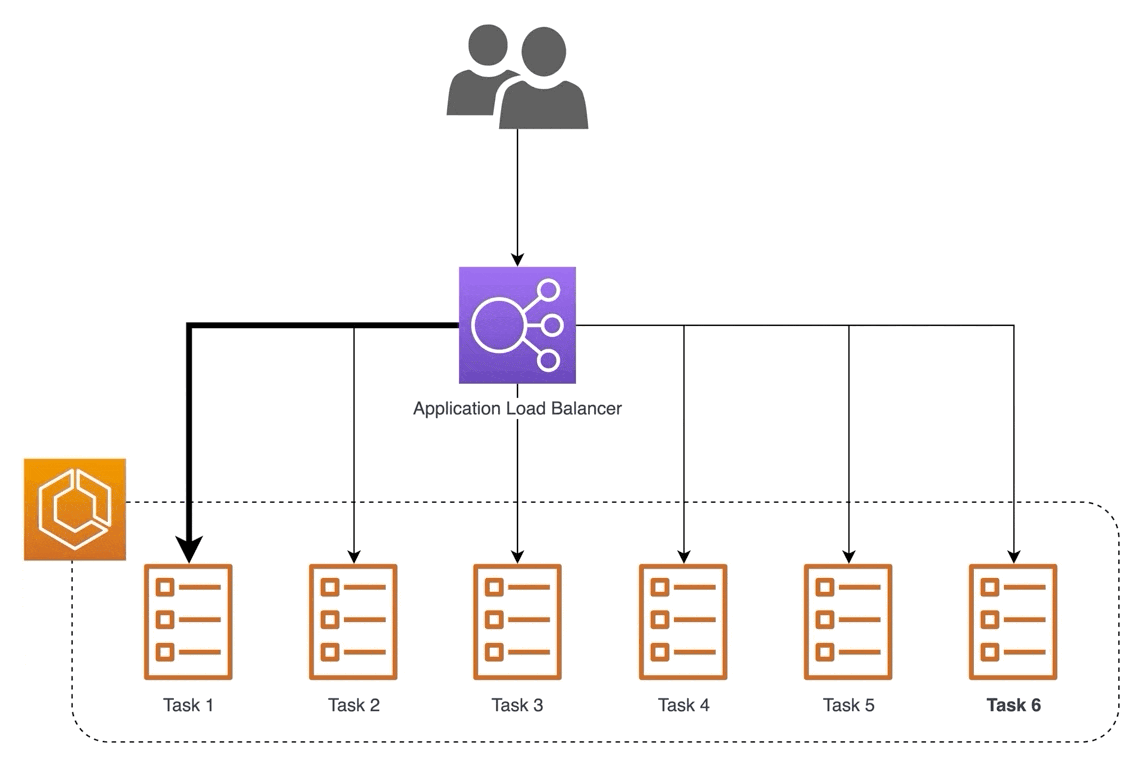
В чем разница между балансировщиком нагрузки и обратным прокси-сервером?
«Когда мы говорим о балансировщике нагрузки, мы имеем в виду очень конкретную вещь – сервер, который балансирует входящие запросы между двумя или более веб-серверами для распределения нагрузки.
Однако обратный прокси-сервер, как правило, имеет ряд функций:
- Балансировка нагрузки: как обсуждалось выше.
- Кэширование: он может кэшировать содержимое веб-сервера (серверов), расположенного за ним, и тем самым снижать нагрузку на веб-сервер (серверы) и возвращать статическое содержимое обратно запрашивающему без необходимости получать данные с веб-сервера (серверов).
- Безопасность: он может защитить веб-сервер(ы), предотвращая прямой доступ из интернета; он может сделать это простыми средствами, просто скрыв веб-сервер(ы), или он может использовать активные компоненты, которые фактически просматривают входящие запросы в поисках вредоносного кода.
Ускорение SSL: при использовании SSL, он может служить точкой завершения для этих SSL-сессий, чтобы снять нагрузку по шифрованию с веб-сервера(ов)». (источник)
Паттерн «посредник»
Паттерн «посредник» предоставляет посредника, который ограничивает прямую связь между службами, заставляя службы сотрудничать — косвенно — через посредника. Это способствует слабой связи, не позволяя службам явно ссылаться друг на друга и реализовывать интерфейс других служб.
Если в наших существующих системах есть посредники, мы должны ожидать предоставления услуг машинного обучения через них, а не напрямую для нижестоящих приложений (например, сайтов электронной коммерции, торговых заказов). Посредники обычно имеют стандартные требования (например, схемы запросов) и ограничения (например, задержку, ограничение скорости), которых необходимо придерживаться.
Например, у нас может быть несколько виджетов рекомендаций для отображения на домашней странице Netflix. Вместо того, чтобы позволять виджетам решать, как они будут показаны пользователям, мы можем потребовать, чтобы каждый виджет проходил через посредника, который ранжирует виджеты. Посредник также может выполнять проверки (например, исключать виджеты с менее чем x элементами) или обновлять виджеты (например, выполнять дедупликацию элементов в нескольких виджетах).
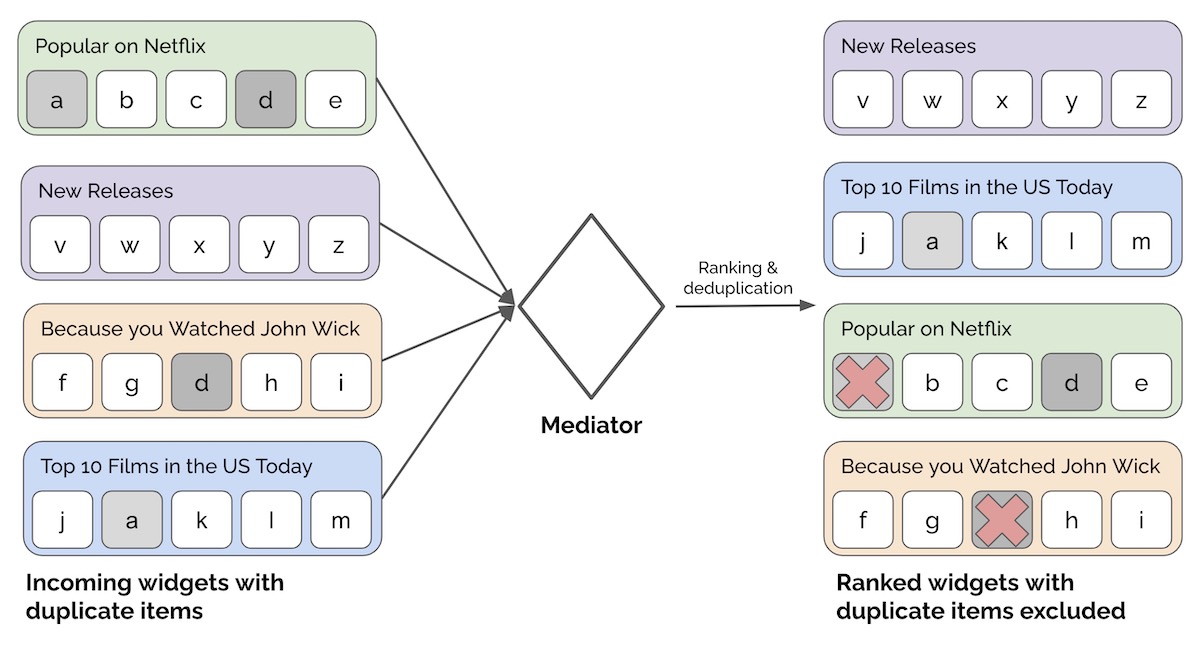
Хочу подтянуть знания по математике, но не знаю, с чего начать. Что делать?
Если базовые концепции языка программирования можно достаточно быстро освоить самостоятельно, то с математикой могут возникнуть сложности. Чтобы помочь освоить математический инструментарий, «Библиотека программиста» совместно с преподавателями ВМК МГУ разработала курс по математике для Data Science, на котором вы:
- подготовитесь к сдаче вступительных экзаменов в Школу анализа данных Яндекса;
- углубитесь в математический анализ, линейную алгебру, комбинаторику, теорию вероятностей и математическую статистику;
- узнаете роль чисел, формул и функций в разработке алгоритмов машинного обучения.
- освоите специальную терминологию и сможете читать статьи по Data Science без постоянных обращений к поисковику.
Курс подойдет как начинающим специалистам, так и действующим программистам и аналитикам, которые хотят повысить свой уровень или перейти в новую область.
Комментарии