
Сделать анализ данных Python быстрее и лучше – мечта каждого разработчика. Вот наглядные примеры: узнайте, как добавить чуточку магии в код.
В этой статье собраны лучшие советы и приёмы. Некоторые из них распространённые, а некоторые новые, но обязательно пригодятся в будущем.
1. Профилирование pandas DataFrame
Профилирование – процесс, который помогает понять наши данные, а Pandas Profiling – Python библиотека, которая делает это. Простой и быстрый способ выполнить предварительный анализ данных Python Pandas DataFrame.
Функции pandas df.describe() и df.info(), как правило, становятся первым шагом в автоматизации проектирования электронных устройств. Но это даёт лишь базовое представление о данных и мало помогает при больших наборах. Зато функция Pandas Profiling отображает много информации с помощью одной строки кода и в интерактивном HTML-отчёте.
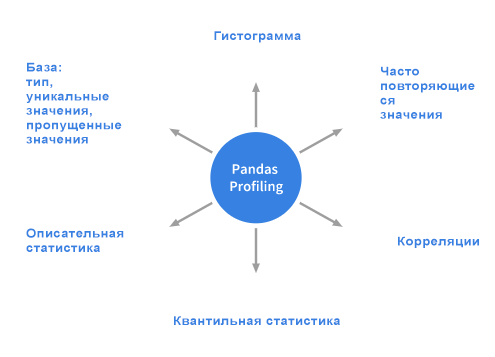
Для представленного набора данных пакет Pandas Profiling вычисляет следующую статистику:
Анализ данных Python: установка
pip install pandas-profiling
или же
conda install -c anaconda pandas-profiling
Применение
Используем испытанный временем набор данных Титаника, чтобы продемонстрировать потенциал универсального профилировщика языка программирования Python:
# импорт необходимых пакетов
import pandas as pd
import pandas_profiling
df = pd.read_csv('titanic/train.csv')
pandas_profiling.ProfileReport(df)
Эта единственная строка кода – всё, что нужно для отображения отчёта о профилировании данных в Jupyter Notebook. Отчёт подробный, включает графики, где это требуется.
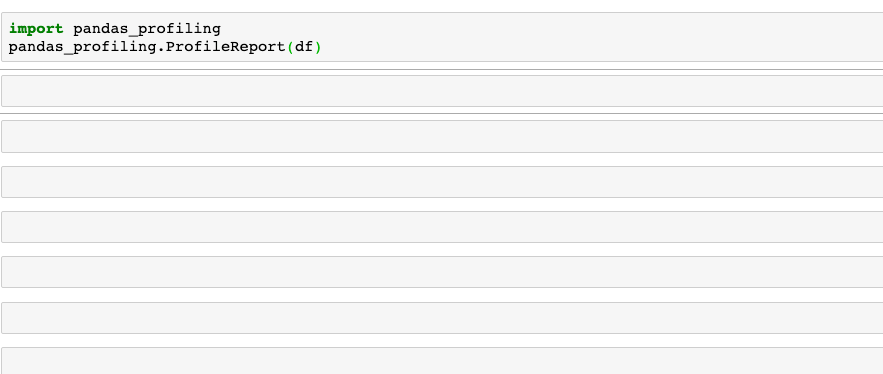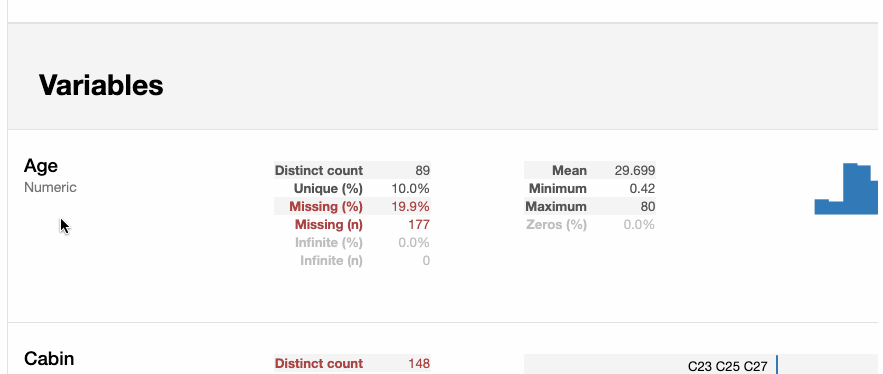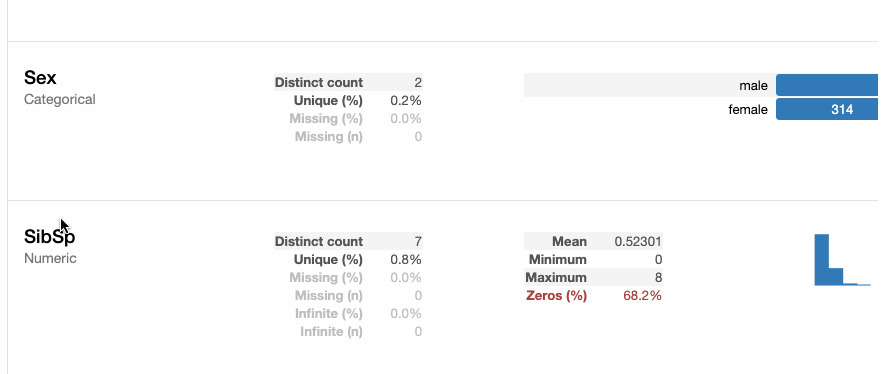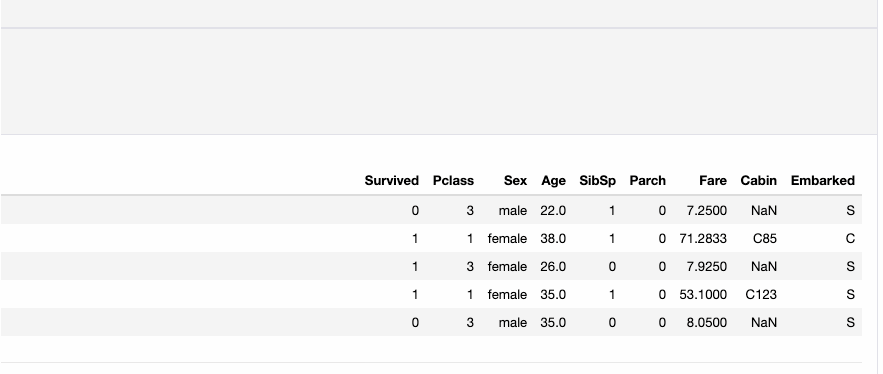
Отчёт также экспортируем в интерактивный HTML-файл с помощью следующего кода:
profile = pandas_profiling.ProfileReport(df) profile.to_file(outputfile="Titanic data profiling.html")
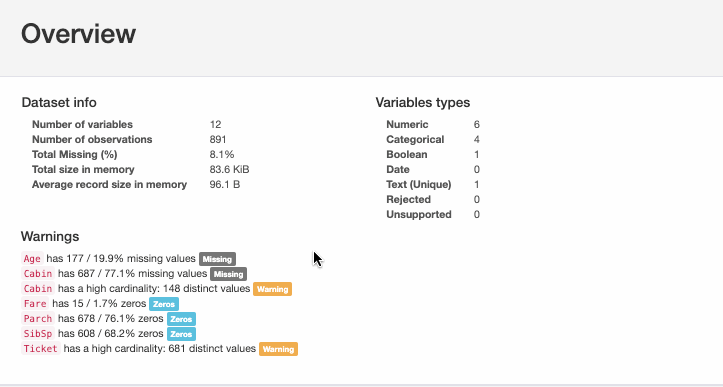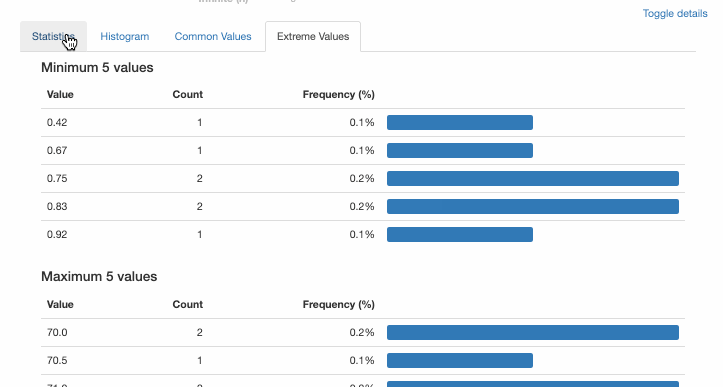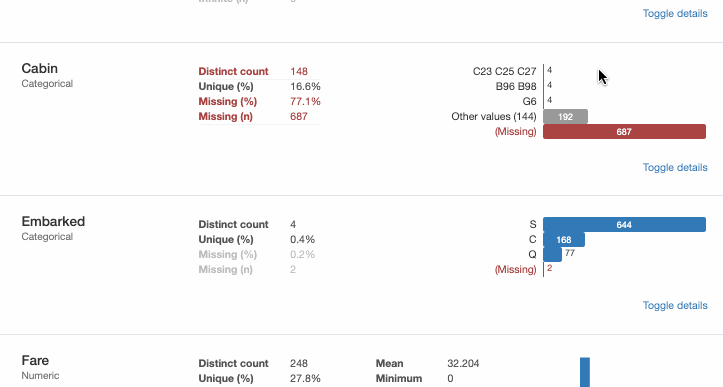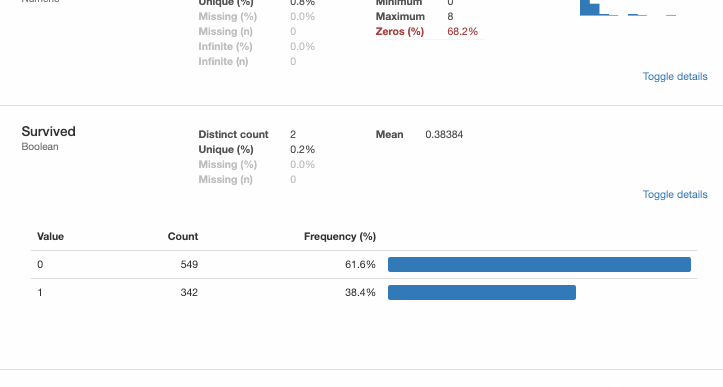
2. Привнесите интерактивность в графики Pandas
В Pandas встроена функция .plot() как часть класса DataFrame. Однако визуализации, которые представляются с помощью этой функции, не интерактивные, что снижает привлекательность. Напротив, нельзя исключать лёгкость построения графиков с использованием функции pandas.DataFrame.plot().
Что, если бы мы создавали интерактивные графики, как диаграммы с pandas без внесения больших изменений в код? К слову, это делается с помощью библиотеки Cufflinks.
Библиотека Cufflinks связывает силу plotly с гибкостью pandas для лёгкого построения графиков. Теперь посмотрим, как установить библиотеку и заставить работать в pandas.
Установка
pip install plotly # Plotly – обязательное условие перед установкой cufflinks pip install cufflinks
Использование
# импорт Pandas import pandas as pd # импорт plotly и cufflinks в автономном режиме import cufflinks as cf import plotly.offline cf.go_offline() cf.set_config_file(offline=False, world_readable=True)
Время увидеть магию, разворачивающуюся с набором данных Титаника.
df.iplot()
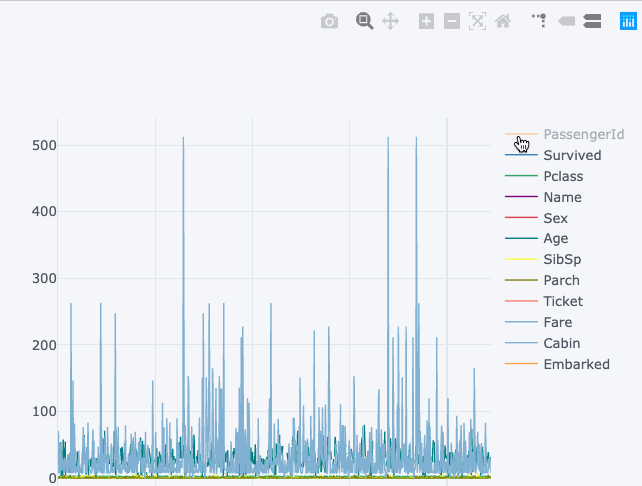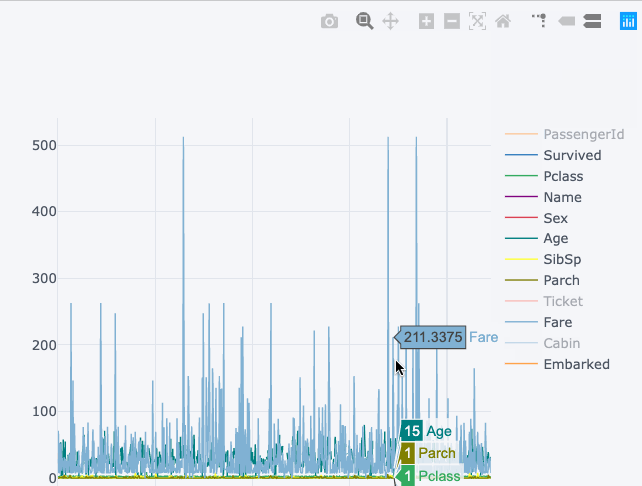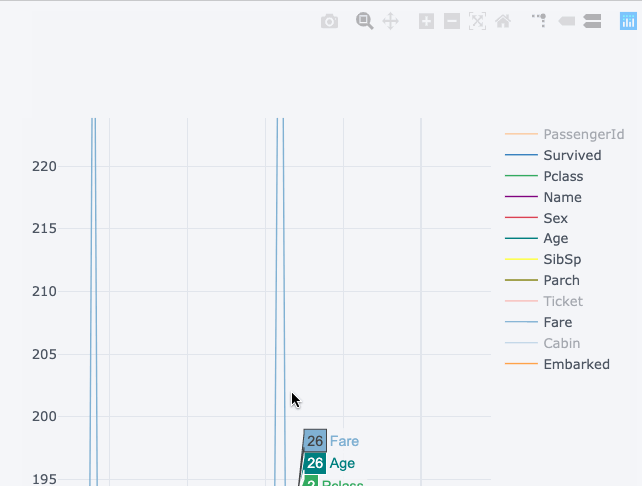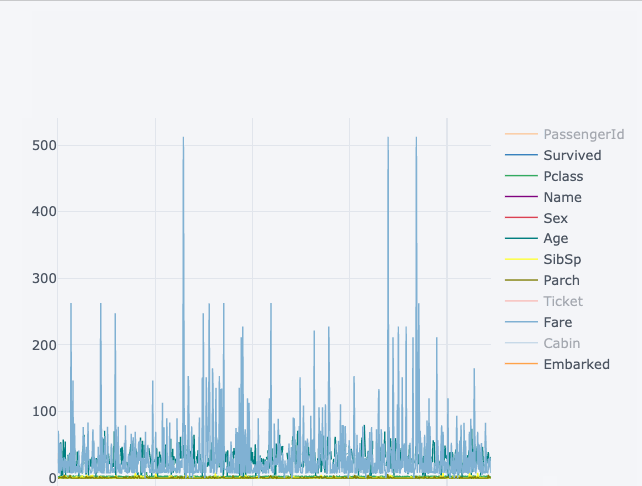
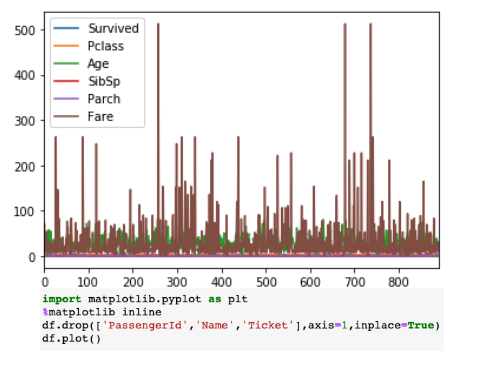
Визуализация снизу показывает статическую диаграмму, в то время как верхняя диаграмма – интерактивная и более подробная. И это без серьёзных изменений в синтаксисе.
3. Добавление Магии в анализ данных Python
Магические команды (magics) – набор удобных функций в Jupyter Notebook, которые предназначены для решения распространённых проблем анализа данных. Посмотрите доступные magics с помощью %lsmagic.
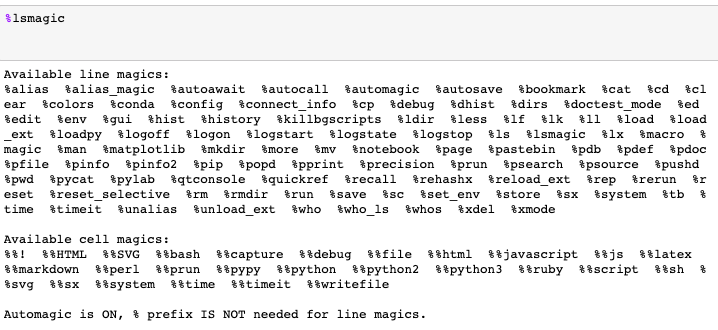
Магические команды делятся на два вида:
- линейные magics, которые начинаются с одного символа
%и работают с одной строкой ввода; - ячеечные magics, связанные с двойным префиксом
%%и работающие с несколькими строками ввода.
Магические функции вызываются без ввода начального %, если установлено значение 1. Вот из них, которые пригодятся в общих задачах анализа данных:
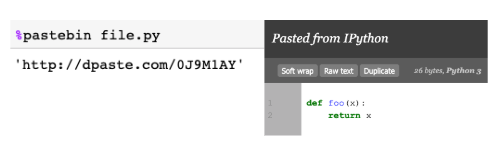
%pastebin
%pastebin загружает код в Pastebin и возвращает URL. Pastebin – онлайн-хостинг, где сохраняем простой текст, такой как фрагменты исходного кода, а затем предоставляем URL-адрес другим пользователям. На самом деле, Github Gist также похож на Pastebin, хотя и с контролем версий.
Python-скрипт file.py с таким содержимым:
#file.py
def foo(x):
return x
Использование %pastebin в Jupyter Notebook генерирует URL-адрес pastebin.
-
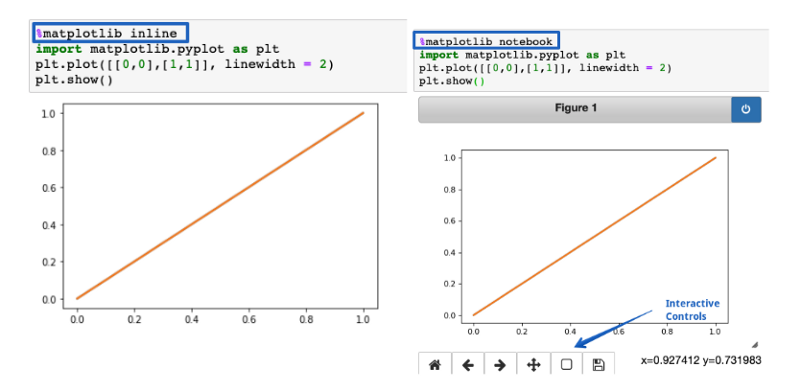
%matplotlib notebook
Функция %matplotlib inline используется для визуализации статических графиков matplotlib в блокноте Jupyter Notebook. Замените inline на notebook, чтобы легко получить масштабирование и изменение размеров графиков. Убедитесь, что функция вызывается перед импортом библиотеки matplotlib.
%run
Функция %run запускает Python-скрипт внутри Notebook.
%run file.py
%%writefile
%%writefile записывает содержимое ячейки в файл. Здесь код будет записан в файл с именем foo.py и сохранён в текущем каталоге.

-
%%latex
Функция %%latex превращает содержимое ячейки в LaTeX. Это полезно для написания математических формул и уравнений в ячейке.

4. Поиск и устранение ошибок
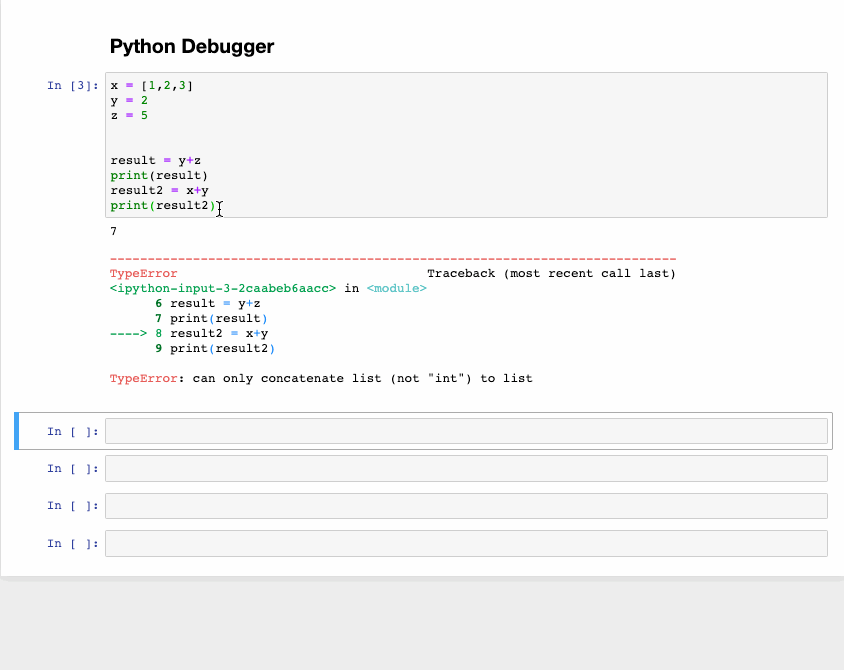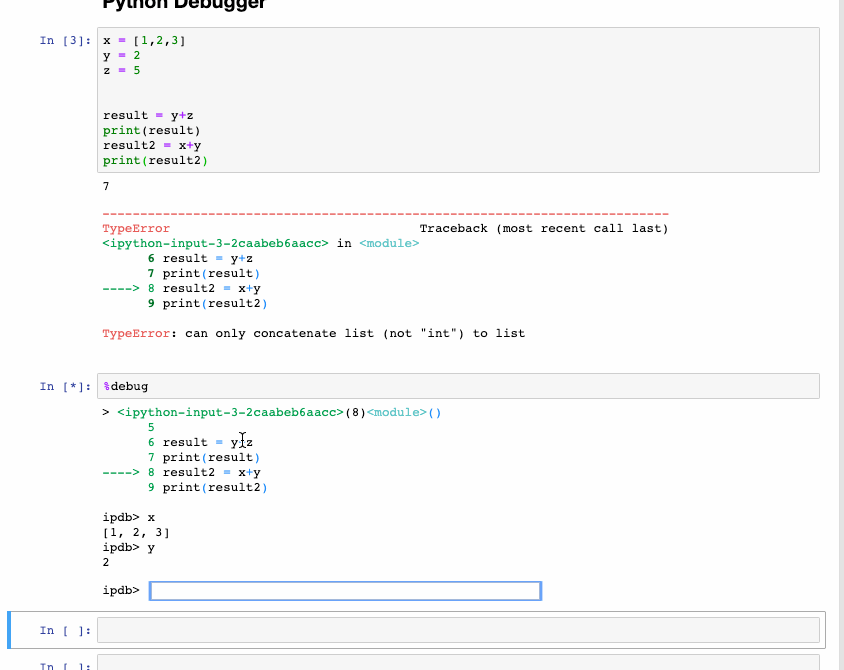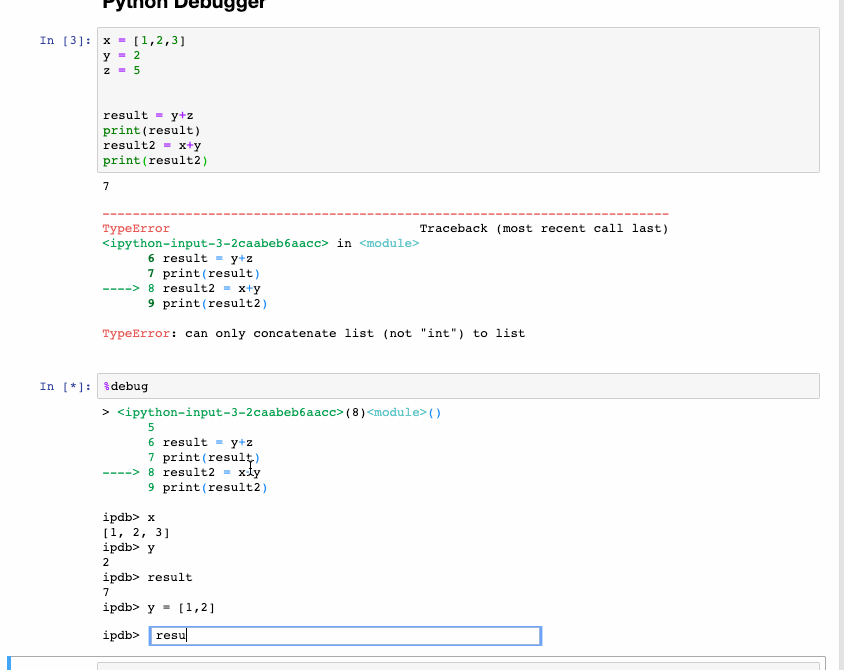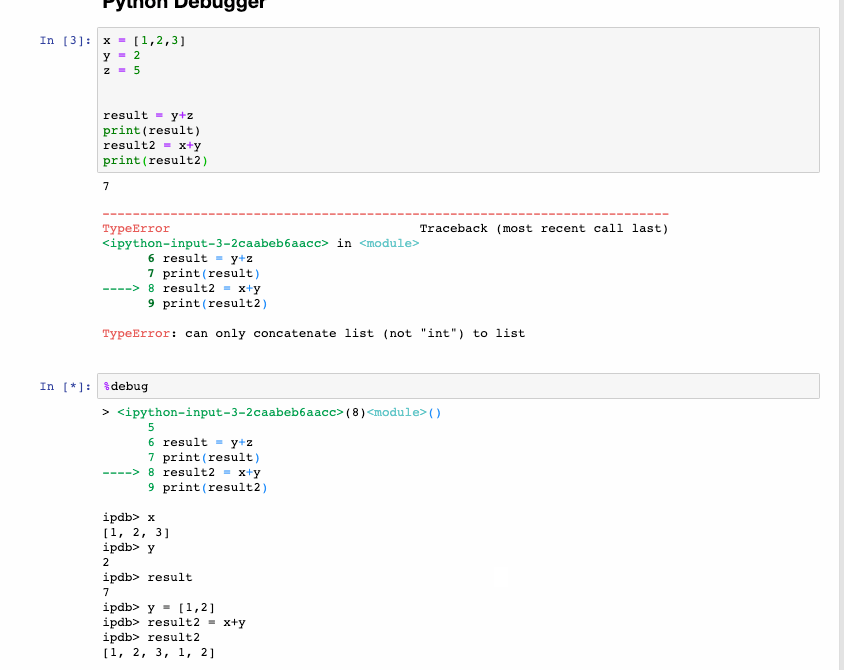
Интерактивный отладчик также относится к магическим функциям, но программист Python выделил для него отдельную категорию. Если получаете исключение при выполнении ячейки кода, введите %debug в новой строке и запустите. Это открывает интерактивную среду отладки, которая приводит к месту, где произошло исключение. Также здесь проверяем значения переменных, которые задали в программе, и выполняем операции. Для выхода из отладчика нажмите q.
5. Отображение тоже будет симпатичным
Хотите создать эстетически приятное представление структур данных? Модуль pprint – ваша палочка-выручалочка. В особенности полезен при отображении словарей или данных JSON. Смотрите пример, где используются print и pprint для печати вывода:


6. Анализ данных Python с выделением заметок
Используйте окна предупреждений или заметок в Jupyter Notebook, чтобы выделить важное. Цвет заметки зависит от типа оповещения. Добавьте один или все представленные блоки кода в ячейку, которую хотите выделить.
- Голубое окно: информация
<div class="alert alert-block alert-info"> <b>Совет:</b> Используйте голубые окна (alert-info) для советов и заметок. Если это заметка, не добавляйте слово «Заметка». </div>

- Жёлтое окно: предупреждение
<div class="alert alert-block alert-warning"> <b>Пример:</b> Жёлтые окна используются для включения дополнительных примеров или математических формул. </div>

- Зелёное окно: успех
<div class="alert alert-block alert-success"> Используйте зелёное поле только при необходимости, например, для отображения ссылок на связанный контент. </div>

- Красное окно: опасность
<div class="alert alert-block alert-danger"> Лучше избегать красных полей, но допускается использовать их для предупреждения пользователей о том, что не стоит удалять некоторые важные части кода и т. д. </div>

7. Печать всех выходных данных ячейки
Посмотрите на ячейку Jupyter Notebook, которая содержит следующие строки кода:
In [1]: 10+5
11+6
Out [1]: 17
Это нормальное свойство ячейки, когда печатается только последний вывод, а для остальных добавляем функцию print(). Что же, получается, чтобы напечатать все выходные данные, добавьте следующий фрагмент вверху Notebook.
from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = "all"
Теперь все выходные данные печатаются друг за другом.
In [1]: 10+5
11+6
12+7
Out [1]: 15
Out [1]: 17
Out [1]: 19
Чтобы вернуться к исходным настройкам:
InteractiveShell.ast_node_interactivity = "last_expr"
8. Запуск скриптов Python с опцией «i»
Типичный способ запуска скрипта Python из командной строки: python hello.py. Однако, если добавите дополнительный -i при запуске того же скрипта, например, python -i hello.py, это даст больше преимуществ. Посмотрим каких.
- Во-первых, после достижения конца программы Python не завершает работу интерпретатора. Таким образом, доступна проверка значений переменных и правильности функций, которые определены в нашей программе.

- Во-вторых, легко вызвать отладчик Python, так как мы до сих пор в интерпретаторе:
import pdb pdb.pm()
Это приведёт нас к месту, где произошло исключение, и позволит дальше работать c кодом.
My-Mac:Desktop parul$ python -i sum.py
Traceback (most recent call last):
File "sum.py", line 3, in <module>
sum = x+v
NameError: name 'v' is not defined
>>> import pdb
>>> pdb.pm()
> /Users/parul/Desktop/sum.py(3)<module>()
-> sum = x+v
(Pdb)
Первоначальный источник хака.
9. Автоматическое комментирование кода
Ctrl/Cmd + / автоматически закомментирует выделенные строки в ячейке. Повторное нажатие комбинации раскомментирует ту же строку кода.
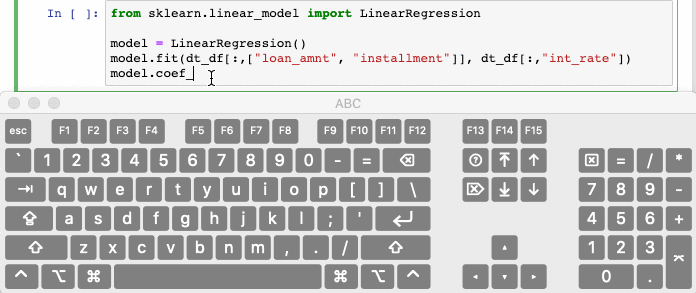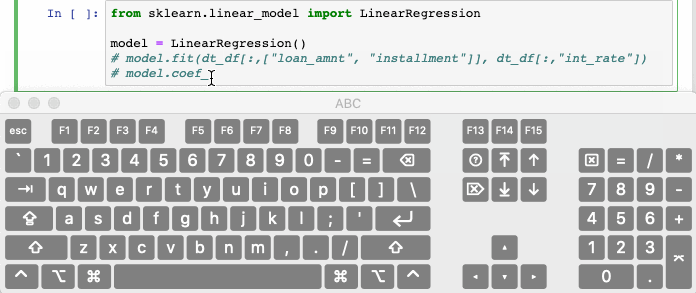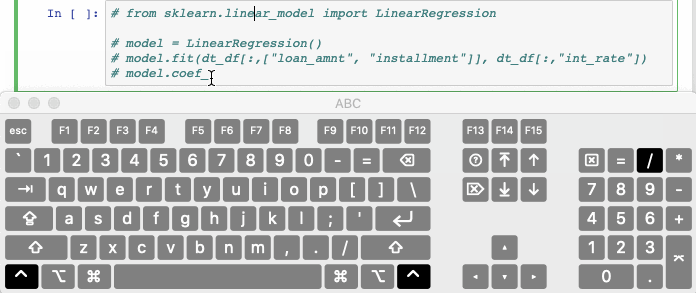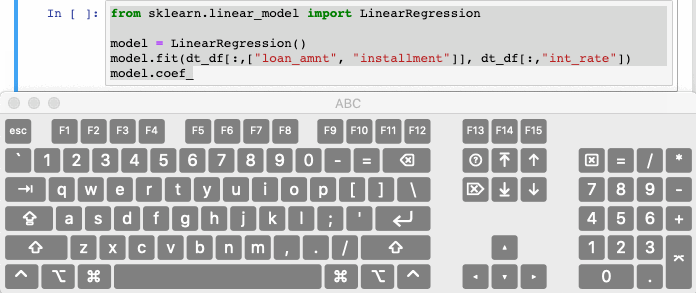
10. Чуть божественного в анализ данных Python – восстановление
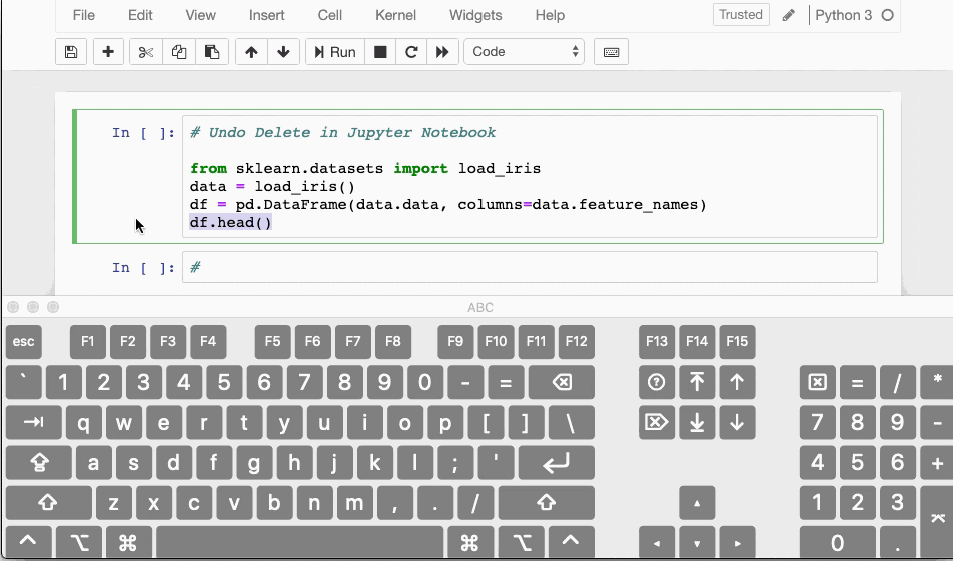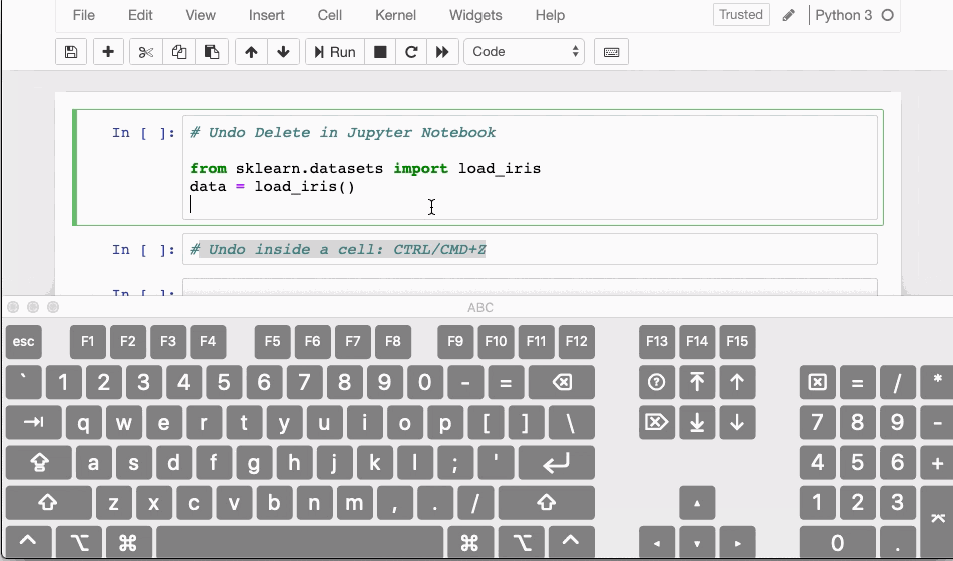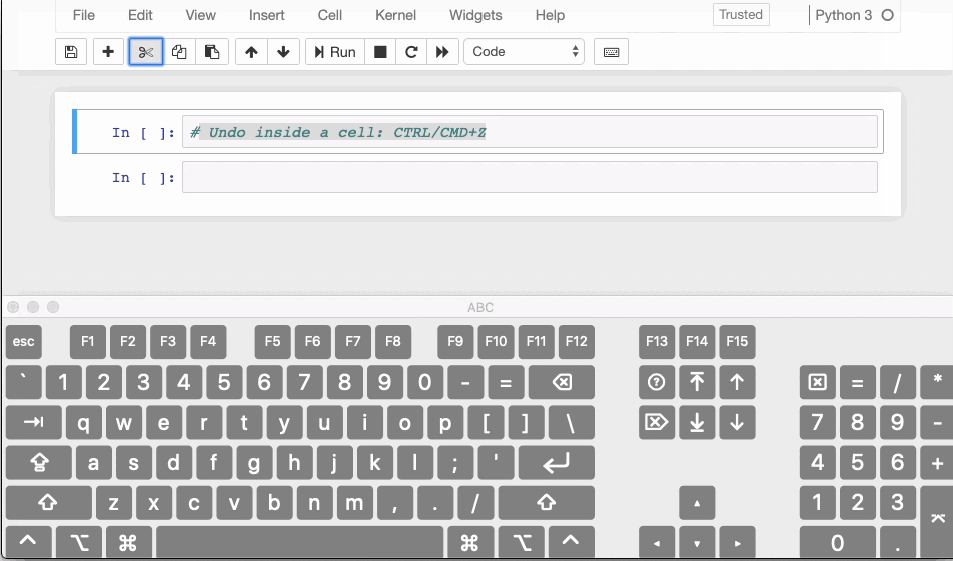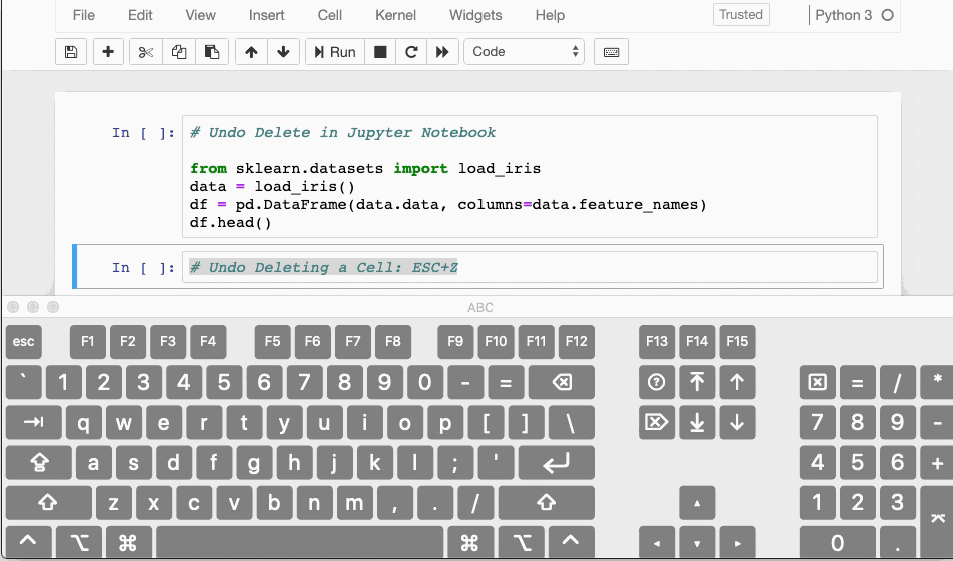
Вы когда-нибудь случайно удаляли ячейку в Jupyter Notebook? Если да, то здесь доступно сокращение, которое отменяет действие удаления.
- В случае, если удалили содержимое ячейки, вы можете легко восстановить его, нажав
CTRL/CMD+Z - Для восстановления полностью удалённой ячейки нажмите
ESC+ZилиEDIT > Undo Delete Cells
Заключение
Эта статья вобрала базовые советы, которые облегчат программирование на Python и работу с Jupyter Notebook. Уверены, что эти фишки будут вам полезны. Удачного Кодинга!



Комментарии