

Для эффективной работы с большими массивами данных требуются инструменты, обеспечивающие высокую скорость вычислений и оптимизацию операций. Именно здесь на помощь приходит Polars. Polars – это многофункциональная библиотека с открытым исходным кодом, специально разработанная для высокопроизводительного управления данными и их анализа на языке Python.
Особенности Polars
Polars – это библиотека, полностью написанная на языке Rust и созданная с целью предоставления разработчикам на Python масштабируемого и эффективного фреймворка для работы с данными, и рассматривается как альтернатива популярной библиотеке Pandas. Она предоставляет широкий спектр функциональных возможностей, которые облегчают выполнение различных задач по обработке и анализу данных. Некоторые из ключевых особенностей и преимуществ использования Polars состоят в следующем:
Скорость и производительность
Polars разработан с учетом требований к производительности. Он использует технологии параллельной обработки и оптимизации памяти, что позволяет ему обрабатывать большие массивы данных гораздо быстрее, по сравнению с традиционными методами.
Возможности для работы с данными
Polars предоставляет универсальный набор инструментов для работы с данными, включающий такие необходимые операции, как фильтрация, сортировка, группировка, объединение и обобщение данных. Несмотря на то что Polars не обладает такой же широкой функциональностью, как Pandas (в силу своей относительной новизны) – он охватывает порядка 80% типовых операций, встречающихся в Pandas.
Выразительный синтаксис
В Polars используется лаконичный и интуитивно понятный синтаксис, что делает его простым в освоении и использовании. По своей структуре синтаксис напоминает популярные библиотеки Python, такие как Pandas, что позволяет пользователям быстро адаптироваться к Polars и использовать уже имеющиеся в их арсенале знания.
DataFrame и объекты Series
В основе Polars лежат конструкции DataFrame и Series, которые обеспечивают хорошо известную и мощную систему для работы с табличными данными. Операции с DataFrame в Polars можно объединять в последовательности, что позволяет эффективно и лаконично обрабатывать данные.
Polars поддерживает ленивую оценку
В Polars реализована функция ленивой оценки, которая заключается в изучении и оптимизации результатов запросов, с целью повышения их производительности и минимизации потребления памяти. Библиотека Polars анализирует ваши запросы и ищет способы ускорить процесс их выполнения или уменьшить потребление памяти. В то же время, Pandas поддерживает только «активную» оценку, при которой вычисления оперативно обрабатываются сразу после их появления.
Зачем выбирать Polars, если есть Pandas?

Pandas – одна из наиболее распространенных библиотек, известна своей универсальностью и простотой использования. Однако при работе с большими наборами данных, Pandas может испытывать проблемы с производительностью из-за своей ориентированности на однопотоковый процесс работы. При увеличении размера массива данных время обработки может стать чрезмерно продолжительным, что ограничивает производительность.
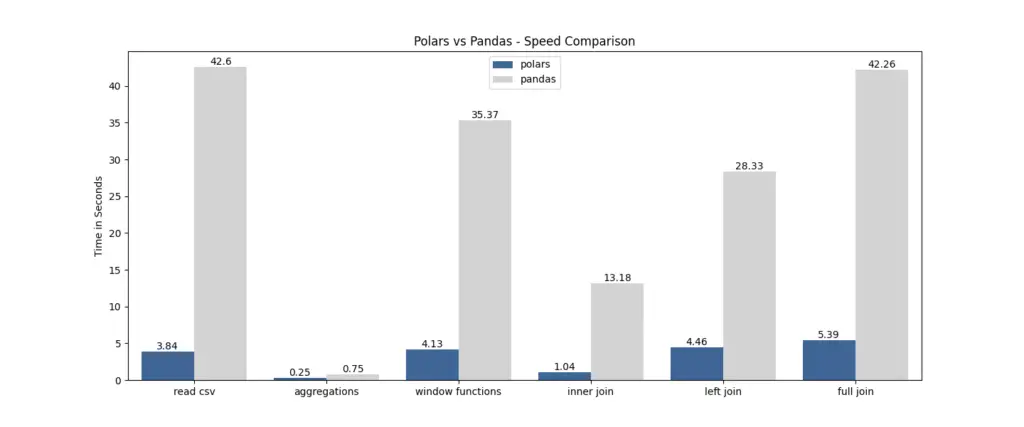
Polars был специально разработан для эффективной работы с большими базами данных. Благодаря стратегии «ленивой» оценки и возможности параллельного выполнения, Polars отлично справляется с задачей оперативной обработки значительных объемов данных. Распределяя вычисления между несколькими ядрами процессора, Polars использует принцип параллелизма для достижения впечатляющих результатов. Сравнительный тест скорости между Pandas и Polars от Yuki представлен на диаграмме ниже:
Установка Polars
Polars можно установить с помощью pip, менеджера пакетов Python. Откройте интерфейс командной строки и выполните следующую команду:
pip install polars
Загрузка базы данных в Polars
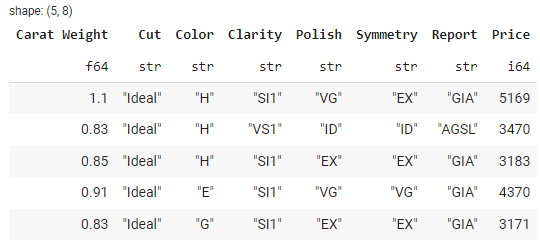
Polars предоставляет удобные методы для загрузки данных из различных источников, включая CSV-файлы, файлы Parquet и Pandas DataFrames. Методы для чтения CSV- или parquet-файлов аналогичны методам из библиотеки Pandas.
# read csv file
import polars as pl
data = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# check the head
data.head()
Результат:
Тип данных – polars.DataFrame:
type(data)
>>> polars.dataframe.frame.DataFrame
Результат:
Общие операции с данными в Polars
Polars предоставляет полный набор функций для работы с данными, позволяя вам с легкостью выбирать, фильтровать, сортировать, преобразовывать и обрабатывать данные. Давайте рассмотрим некоторые общие операции с данными и способы их реализации с помощью Polars:
1. Выборка и фильтрация данных
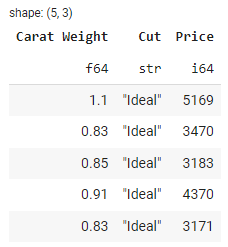
Чтобы выбрать определенные столбцы из DataFrame, вы можете использовать метод select(). Приведем пример:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# Select specific columns: carat, cut, and price
selected_df = df.select(['Carat Weight', 'Cut', 'Price'])
# show selected_df head
selected_df.head()
Результат:
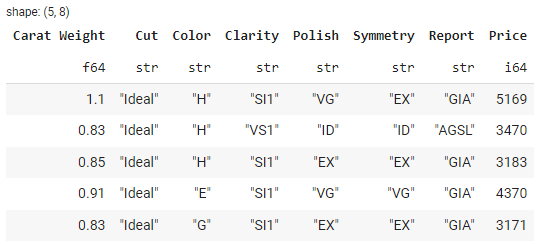
Фильтрация строк по определенным параметрам может быть выполнена с помощью метода filter(). Например, чтобы отфильтровать строки, в которых значение карата больше единицы, вы можете воспользоваться следующим методом:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# filter the df with condition
filtered_df = df.filter(pl.col('Carat Weight') > 2.0)
# show filtered_df head
filtered_df.head()
Результат:
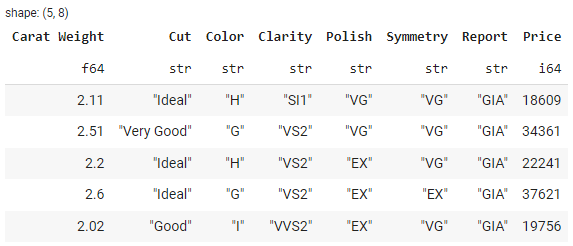
2. Сортировка и упорядочивание данных
Polars использует метод sort() для сортировки DataFrame на базе одного или нескольких столбцов. Например:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# sort the df by price
sorted_df = df.sort(by='Price')
# show sorted_df head
sorted_df.head()
Результат:
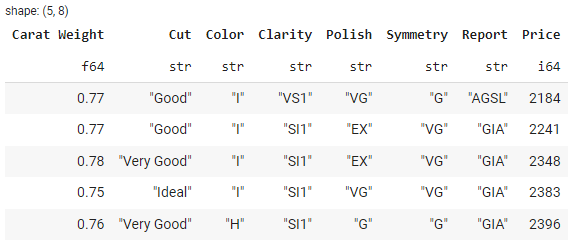
3. Обработка недостающих значений
Polars предоставляет удобные методы для обработки отсутствующих данных. Метод drop_nulls() позволяет исключить строки, содержащие пропущенные значения:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# drop missing values
cleaned_df = df.drop_nulls()
# show cleaned_df head
cleaned_df.head()
Результат:
В качестве альтернативного варианта можно использовать метод fill_nulls(), чтобы заменить отсутствующие значения заданной величиной по умолчанию или с помощью заполнения.
4. Группировка данных по определенным столбцам
Чтобы сгруппировать данные по определенным столбцам, можно использовать метод groupby(). Вот пример, в котором данные группируются по столбцу Cut и вычисляется средняя цена для каждой отдельной группы:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# group by cut and calc mean of price
grouped_df = df.groupby(by='Cut').agg(pl.col('Price').mean())
# show grouped_df head
grouped_df.head()
Результат:
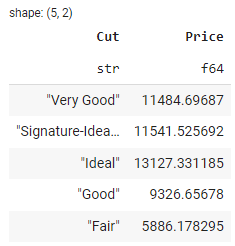
На изображении выше вы можете проследить среднюю цену бриллиантов по размеру огранки.
5. Объединение и комбинирование DataFrames
Polars предоставляет широкие возможности для объединения и комбинирования DataFrames, позволяя вам группировать и компоновать данные из различных источников. Чтобы выполнить операцию объединения, вы можете использовать метод join(). Вот один из примеров, демонстрирующий внутреннее объединение двух DataFrames на базе общего ключевого столбца:
import polars as pl
# Create the first DataFrame
df1 = pl.DataFrame({
'id': [1, 2, 3, 4],
'name': ['Alice', 'Bob', 'Charlie', 'David']
})
# Create the second DataFrame
df2 = pl.DataFrame({
'id': [2, 3, 5],
'age': [25, 30, 35]
})
# Perform an inner join on the 'id' column
joined_df = df1.join(df2, on='id')
# Display the joined DataFrame
joined_df
Результат:

На этом примере мы создадим два датафрейма (df1 и df2) с помощью конструктора pl.DataFrame. Первый датафрейм df1 содержит столбцы id и name, а второй датафрейм df2 – столбцы id и age. Затем мы выполним объединение по столбцу id с помощью метода join(), указав столбец id в качестве ключа объединения.
Интеграция и взаимодействие
Polars предлагает удобную интеграцию с другими популярными библиотеками Python, позволяя аналитикам данных использовать широкий спектр инструментов и функциональных возможностей. Давайте рассмотрим два ключевых аспекта интеграции: работу с другими библиотеками и взаимодействие с Pandas.
Интеграция Polars с другими библиотеками Python
Polars успешно взаимодействует с такими библиотеками, как NumPy и PyArrow, позволяя пользователям объединить сильные стороны нескольких инструментов в процессе анализа данных. Благодаря интеграции с NumPy, Polars легко конвертирует данные между Polars DataFrames и массивами NumPy, используя мощные возможности NumPy для научных вычислений. Такая интеграция обеспечивает плавный обмен данными и позволяет аналитикам напрямую применять функции NumPy к вычислениям в Polars.
Аналогичным образом, используя PyArrow, Polars оптимизирует передачу данных между Polars и системами на базе Arrow. Такая интеграция обеспечивает беспрепятственную работу с данными, хранящимися в формате Arrow и использует высокопроизводительные возможности Polars по обработке данных.
Преобразование данных Polars DataFrames в Pandas DataFrames
Polars обеспечивает плавное преобразование Polars DataFrames в Pandas DataFrames. Вот пример, иллюстрирующий преобразование из Polars в Pandas.
import polars as pl
import pandas as pd
# Create a Polars DataFrame
df_polars = pl.DataFrame({
'column_A': [1, 2, 3],
'column_B': ['apple', 'banana', 'orange']
})
# Convert Polars DataFrame to Pandas DataFrame
df_pandas = df_polars.to_pandas()
# Display the Pandas DataFrame
df_pandas
Результат:
Заключение
Polars – это функциональная библиотека для высокоэффективной работы с данными и их анализа на Python. Благодаря выразительному синтаксису и структурам DataFrame, Polars предлагает привычный и интуитивно понятный интерфейс для работы с данными. Кроме того, Polars легко интегрируется с другими библиотеками Python, такими как NumPy и PyArrow, расширяя поле своих возможностей и позволяя пользователям задействовать разнообразную экосистему инструментов. Возможность конвертации Polars DataFrames в Pandas DataFrames обеспечивает совместимость и облегчает интеграцию Polars в существующие рабочие процессы.
Комментарии