
Что такое A/B-тестирование
A/B-тестирование (также известное как сплит-тестирование) – это метод сравнения двух версий чего-либо для определения, какая из них работает лучше. Обычно одна версия (A) является контрольной, а другая (B) – экспериментальной. A/B тестирование часто применяется:
- В маркетинге – для оптимизации рекламных кампаний и email-рассылок.
- В разработке игр и прикладного ПО – для тестирования новых функций или дизайна.
- В UX/UI дизайне – для улучшения пользовательского опыта.
- В электронной коммерции – для повышения продаж и оптимизации процесса покупки.
Есть два подхода к проведению A/B-тестирования – частотный (традиционный, общепринятый) и байесовский (альтернативный, применяется реже). К байесовскому подходу мы вернемся ниже, а основные этапы частотного тестирования выглядят так:
- Определение цели – что именно нужно улучшить.
- Создание гипотезы – какие изменения могут привести к улучшению.
- Создание вариантов – разработка контрольной (A) и экспериментальной (B) версий.
- Случайное распределение – разделение аудитории на две группы.
- Проведение теста и сбор данных о поведении пользователей.
- Анализ
результатов – статистическая обработка полученных данных.
- Выбор лучшего варианта на основе результатов и внедрение в продакшен.
Несмотря на очевидную простоту, сплит-тестирование поразительно эффективно. Вот несколько реальных кейсов:
1. Заголовки рекламы
В 2012 году сотрудник Microsoft, работающий над поисковой системой Bing, придумал, как изменить способ отображения заголовков рекламы. Идея была простой и требовала всего несколько дней работы программиста. Однако она была лишь одной из сотен предложенных идей, и менеджеры проекта посчитали ее неважной. Из-за этого идея не реализовывалась более полугода.
Затем другой инженер решил провести A/B тест этой идеи, так как это не требовало много усилий. Результаты теста появились очень быстро: новый вариант заголовков рекламы начал приносить необычно высокий доход. Это было настолько неожиданно, что сработала система предупреждения о возможном баге в рекламной системе.
После проверки выяснилось, что это не ошибка: анализ показал, что простое изменение действительно увеличило доходы на целых 12%. В масштабах года это означало более $100 млн дополнительного дохода только в США. При этом важные показатели удовлетворенности пользователей не пострадали. Эта идея оказалась самой прибыльной за всю историю Bing, но до проведения теста никто не понимал, насколько она ценна.
2. Цветовая схема страницы с результатами поиска
В 2013 году команда Bing решила провести эксперимент с цветами текста на странице результатов поиска. Они изменили:
- Цвет заголовков (сделали синий и зеленый чуть темнее).
- Цвет подписей (сделали черный чуть светлее).
Важно отметить, что эти изменения были очень небольшими – настолько, что обычный пользователь мог их даже не заметить.

Результаты этого эксперимента оказались неожиданно положительными:
- Повысилась успешность поиска – пользователи, которые видели страницу с новыми цветами, чаще находили то, что искали.
- Увеличилась скорость поиска – те, кто успешно находил нужную информацию, делали это быстрее, чем раньше.
Дизайнеры отнеслись к результатам теста скептически, и команда провела тестирование повторно – в этот раз на 32 млн пользователей. Результаты оказались такими же: пользователи действительно лучше реагировали на новую цветовую схему. После внесения изменений в продакшен ежегодная прибыль увеличилась более чем на $10 млн.
3. Перемещение рекламы кредиток в Аmazon
Amazon обнаружил, что простое перемещение рекламы кредитных карт с главной страницы на страницу корзины увеличивает прибыль на десятки миллионов долларов в год.

Приглашаем на вебинар «Как меняется математика в разных индустриях: от мобильных игр к фондовым рынкам» 22 августа, 20:00 МСК.
Вы узнаете:
- Влияние математических методов на мобильные игры и фондовые рынки.
- Специфику математических подходов в разных бизнес-сферах.
- Практические примеры применения математики в GameDev и финансах.
- Ключевые математические навыки для успешной карьеры в Data Science.
Различия между частотным и байесовским подходами к A/B тестированию
В статистике есть две основные философские школы: частотная (фреквентистская) и байесовская. Главное различие между ними заключается в подходе к пониманию вероятности и неопределенности:
Частотный подход
- Рассматривает вероятности объективно, как фиксированные, но неизвестные величины.
- Вероятность определяется путем многократных испытаний. Например, чтобы определить, является ли монета «честной», нужно подбросить ее много раз и записать результаты. После, скажем, 100 подбрасываний, можно вычислить вероятность выпадения орла и оценить точность этой вероятности (доверительный интервал).
Байесовский подход
- Рассматривает вероятности субъективно, как меру уверенности.
- Верит в обновление предварительных убеждений при получении новой информации.
- Позволяет включать предварительные знания в оценку вероятностей. Например, если монета выглядит нечестной, можно предположить, что вероятность выпадения орла выше 0,5. Затем, по мере того как вы подбрасываете монету и видите результаты, можно обновлять свои убеждения.
- Вероятность рассматривается как случайная величина.
Традиционное A/B тестирование обычно использует частотный подход, и, как следствие:
- Основано на p-значениях и доверительных интервалах.
- Требует предварительного определения размера выборки.
- Использует нулевую гипотезу (нет разницы между A и B) и альтернативную гипотезу.
- Нуждается в большом объеме данных для достижения статистической значимости.
- Результат – бинарное решение отвергнуть или не отвергать нулевую гипотезу.
Плюсы и минусы частотного подхода к A/B тестированию:
+ Более традиционный и широко используемый.
+ Проще в реализации и интерпретации для неспециалистов.
- Требует использования большой выборки для репрезентативности.
Байесовское A/B тестирование предлагает альтернативный подход
- Использует априорные убеждения и обновляет их по мере поступления данных.
- Позволяет включать предварительные знания в анализ.
- Дает вероятностные оценки превосходства одного варианта над другим.
- Позволяет проводить промежуточные анализы без потери статистической мощности.
- Часто требует меньше данных для принятия решения.
- Результат – это распределение вероятностей, а не бинарное решение.
Плюсы и минусы байесовского подхода
+ Более гибкий и информативный.
+ Учитывает предварительные знания.
+ Позволяет принимать решения на основе меньших выборок.
+ Дает более богатую информацию о вероятностях различных исходов.
+ Можно обновлять вероятности по мере поступления новых данных.
- Может быть сложнее в реализации и интерпретации.
- Априорная информация может быть субъективной.
На первый взгляд, плюсов у байесовского подхода намного больше: он кажется более гибким, надежным и практичным. Но на деле споры о том, какой подход лучше, ведутся с 18-го века – с момента публикации эпохальной работы Байеса «Очерки к решению проблемы доктрины шансов».
Важно отметить, что для большинства стандартных A/B-тестов с высоким трафиком (большой выборкой), которые проводятся до естественного завершения, оба подхода обычно приводят к одинаковым выводам. Разница становится более существенной в специфических ситуациях (небольшая выборка, преждевременная остановка теста). Поэтому есть смысл выбирать подход в зависимости от контекста.
Частотный подход лучше использовать
- Для стандартных A/B-тестов с большим трафиком.
- Когда нужна объективность и опора только на текущие данные.
- Когда необходим консервативный подход, избегающий преждевременных выводов.
- Для выявления долгосрочных изменений.
Байесовский подход предпочтительнее
- При небольшом объеме трафика / выборки.
- Когда нужно принимать решения быстрее, особенно на ранних этапах теста.
- Для тестирования в нишевых сегментах.
- Когда имеются полезные предварительные данные, которые нужно учесть.
- При тестировании радикальных изменений.
Реализация байесовского A/B-тестирования на Python
Для проведения A/B-тестов на Python обычно используют специальные библиотеки. Самая популярная из них – PyMC, ее ближайший конкурент – Pyro, созданная разработчиками Uber. Есть также несколько неплохих библиотек попроще, сделанных специально для байесовского тестирования – bayesian_testing, BayesABTest, bayesian-ab-test. Но можно обойтись и без A/B библиотек, если воспользоваться статистическими возможностями пакета SciPy, что мы и сделаем.
Определение эффективности рекламной кампании
Предположим, в течение некоторого времени мы проводили рекламную кампанию A, но потом у нас появилась идея, что новый вариант рекламы B может работать лучше. Поэтому мы проводим эксперимент, разделив нашу аудиторию пополам: одна часть видит существующую кампанию A, в то время как другая видит новую кампанию B. Наша метрика производительности – конверсия (продажи) на клик (игнорируем проблему атрибуции рекламы на данный момент). Спустя 24 дня с начала эксперимента у нас есть достаточно данных о ежедневных кликах и конверсиях по каждой кампании. Настало время определить, какая кампания приносит нам больше продаж.
Используемые инструменты
Будем использовать только NumPy, pandas, SciPy и matplotlib для визуализации:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import beta
Чтобы датафреймы выводились полностью, без сокращений, можно установить параметры:
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)
pd.set_option('max_colwidth', None)
Генерация синтетических данных
# Генерация синтетических данных для кампаний А и B
def gen_campaigns(p1, p2, nb_days, scaler, seed):
np.random.seed(seed)
ns = np.random.triangular(50, 100, 150, size=nb_days * 2).astype(int)
np.random.seed(seed)
es = np.random.randn(nb_days * 2) / scaler
n1 = ns[:nb_days]
c1 = ((p1 + es[:nb_days]) * n1).astype(int)
n2 = ns[nb_days:]
c2 = ((p2 + es[nb_days:]) * n2).astype(int)
conv_days = pd.DataFrame({
'click_day': range(nb_days),
'click_a': n1,
'conv_a': c1,
'click_b': n2,
'conv_b': c2
})
conv_days['cumu_click_a'] = conv_days.click_a.cumsum()
conv_days['cumu_click_b'] = conv_days.click_b.cumsum()
conv_days['cumu_conv_a'] = conv_days.conv_a.cumsum()
conv_days['cumu_conv_b'] = conv_days.conv_b.cumsum()
conv_days['cumu_rate_a'] = conv_days.cumu_conv_a / conv_days.cumu_click_a
conv_days['cumu_rate_b'] = conv_days.cumu_conv_b / conv_days.cumu_click_b
return conv_days
# Генерация синтетических данных кампании
conv_days = gen_campaigns(p1=0.10, p2=0.105, nb_days=24, scaler=300, seed=1412)
print(conv_days.head())
Полученные синтетические данные:
click_day click_a conv_a click_b conv_b cumu_click_a cumu_click_b cumu_conv_a cumu_conv_b cumu_rate_a cumu_rate_b
0 0 125 12 87 9 125 87 12 9 0.096000 0.103448
1 1 114 11 86 9 239 173 23 18 0.096234 0.104046
2 2 67 6 91 9 306 264 29 27 0.094771 0.102273
3 3 96 9 103 10 402 367 38 37 0.094527 0.100817
4 4 89 9 125 13 491 492 47 50 0.095723 0.101626
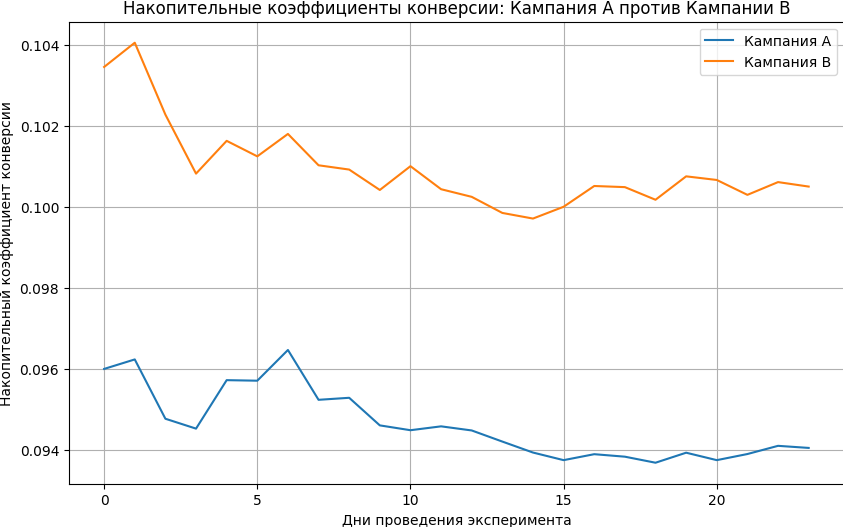
Визуализируем накопительные коэффициенты конверсии:
# Построение графика накопительных коэффициентов конверсии для обеих кампаний
def plot_conversion_rates(conv_days):
plt.figure(figsize=(10, 6))
plt.plot(conv_days['click_day'], conv_days['cumu_rate_a'], label='Кампания A')
plt.plot(conv_days['click_day'], conv_days['cumu_rate_b'], label='Кампания B')
plt.xlabel('Дни проведения эксперимента')
plt.ylabel('Накопительный коэффициент конверсии')
plt.legend()
plt.grid(True)
plt.title('Накопительные коэффициенты конверсии: Кампания A против Кампании B')
plt.show()
plot_conversion_rates(conv_days)
Вычисляем сводные данные о кликах и конверсиях:
# Сводка по конверсиям и количеству кликов после 24 дней
conv_df = pd.DataFrame({
'campaign_id': ['A', 'B'],
'clicks': [conv_days.click_a.sum(), conv_days.click_b.sum()],
'conv_cnt': [conv_days.conv_a.sum(), conv_days.conv_b.sum()]
})
conv_df['conv_per'] = conv_df['conv_cnt'] / conv_df['clicks']
print(conv_df)
По сводке уже видно, что кампания B эффективнее:
campaign_id clicks conv_cnt conv_per
0 A 2488 234 0.094051
1 B 2209 222 0.100498
Суть байесовского подхода
Основная идея байесовского подхода к A/B-тестированию заключается в формулировке апостериорного распределения для каждой вариации. В отличие от частотного подхода, который сначала предполагает нулевую гипотезу о том, что между вариантами нет различий, и затем анализирует данные для определения уровня ложноположительного результата, байесовский подход позволяет прямо работать с гипотезами о истинных значениях, таких как конверсионные ставки для каждой вариации. Однако стоит отметить, что теперь мы не можем использовать центральную предельную теорему для предположения нормального распределения наших гипотез; вместо этого нам нужно самостоятельно строить свои распределения, называемые апостериорными распределениями, используя правило Байеса:
где H — гипотеза или модель, D — данные или свидетельство,
- P(H|D) — вероятность того, что гипотеза верна, учитывая наблюдаемые данные, называемые апостериором. Это распределение используется для оценки истинных значений, например, истинных конверсионных ставок в байесовском подходе.
- P(D|H) — вероятность наблюдения данных, если гипотеза верна, называемая правдоподобностью. Это похоже на p-значение отклонения нулевой гипотезы в частотном подходе.
- P(H) — наша уверенность в гипотезе, называемая априорным распределением. Выбрать подходящее предварительное распределение можно из таблицы сопряженных априорных распределений.
- P(D) — вероятность наличия данных, называемая свидетельством.
В нашем случае, вероятность того, что мы увидим данный набор данных кликов и конверсий, при условии что истинная конверсионная ставка равна p, может быть описана с помощью распределения Бернулли:
где xi— двоичный флаг конверсии, а p — истинная конверсионная ставка по гипотезе H.
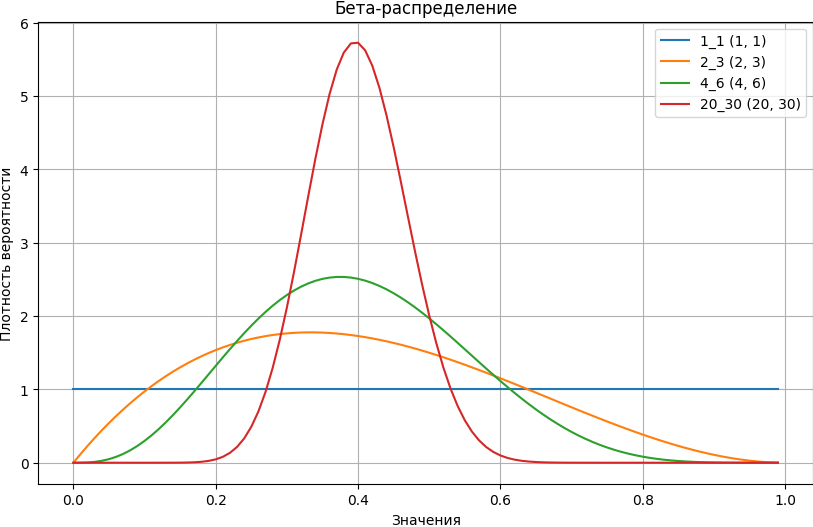
Априорное распределение представляет собой бета-распределение со следующей плотностью вероятности:
где α и β — гиперпараметры, связанные соответственно с количеством успехов и неудач, а B(α, β) — бета-функция, которая нормализует распределение так, чтобы оно находилось между 0 и 1. Интуитивно, форма бета-распределения определяется количеством успехов и неудач, заданных α и β; кроме того, большее число означает, что мы более уверены в своем распределении, что приводит к меньшей дисперсии.
Выполним построение графика бета-распределения:
beta_df = pd.DataFrame({
'x': [i/100 for i in range(100)],
'1_1': [beta.pdf(i/100, a=1, b=1) for i in range(100)],
'2_3': [beta.pdf(i/100, a=2, b=3) for i in range(100)],
'4_6': [beta.pdf(i/100, a=4, b=6) for i in range(100)],
'20_30': [beta.pdf(i/100, a=20, b=30) for i in range(100)]
})
plt.figure(figsize=(10, 6))
for column in beta_df.columns[1:]:
plt.plot(beta_df['x'], beta_df[column], label=f'{column} ({column.replace("_", ", ")})')
plt.title('Бета-распределение')
plt.xlabel('Значения')
plt.ylabel('Плотность вероятности')
plt.legend()
plt.grid(True)
plt.show()
Заметно, что свидетельство P(D) и нормализующий фактор B(α, β) являются константами относительно нашей гипотезы, поэтому при рассмотрении апостериорного распределения мы можем ими пренебречь. Наше апостериорное распределение P(H|D) пропорционально произведению вероятностей успехов и неудач, возведенных в степень соответствующих параметров бета-распределения, увеличенных на количество успехов и неудач соответственно:
После обработки данных и применения формулы для обновления наших убеждений (априорного распределения), мы получаем выражение, которое по своей форме соответствует бета-распределению, но еще не нормализовано. Нормализация выполняется путем деления каждой вероятности на константу, которая равна сумме всех вероятностей в ненормализованном распределении:
Выбор правильного априорного распределения
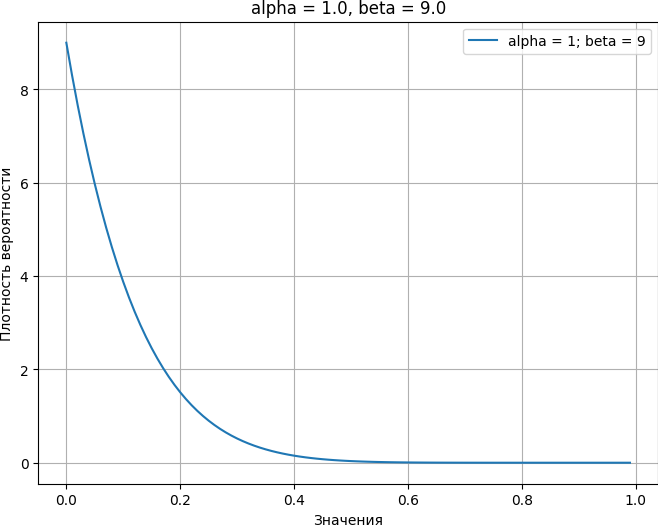
Один из способов выбора априорного распределения — основывать его на результатах предыдущих кампаний. Например, если у нас была кампания с средней конверсией в 10%, мы можем масштабировать априорное распределение в соответствии с нашей уверенностью в этих показателях конверсии.
Важно отметить, что разные априоры могут представлять один и тот же средний уровень конверсии (в данном случае 10%), но с различной степенью уверенности. Например, распределения Beta(1, 9) и Beta(10, 90) оба представляют среднюю конверсию в 10%, но Beta(10, 90) имеет более высокую степень уверенности в этом значении, поскольку оно более «остро» сосредоточено вокруг 10%:
def plot_beta(a=1, b=9, scaler=1):
beta_df = pd.DataFrame({
'x': [i / 100 for i in range(100)],
'value': [beta.pdf(i / 100, a=a * scaler, b=b * scaler) for i in range(100)]
})
plt.figure(figsize=(8, 6))
plt.plot(beta_df['x'], beta_df['value'], label=f'alpha = {a * scaler}; beta = {b * scaler}')
plt.title('alpha = 1.0, beta = 9.0')
plt.xlabel('Значения')
plt.ylabel('Плотность вероятности')
plt.legend()
plt.grid(True)
plt.show()
plot_beta(a=1, b=9, scaler=1)
def plot_beta(a=10, b=90, scaler=1):
beta_df = pd.DataFrame({
'x': [i / 100 for i in range(100)],
'value': [beta.pdf(i / 100, a=a * scaler, b=b * scaler) for i in range(100)]
})
plt.figure(figsize=(8, 6))
plt.plot(beta_df['x'], beta_df['value'], label=f'alpha = {a * scaler}; beta = {b * scaler}')
plt.title('alpha = 10.0, beta = 90.0')
plt.xlabel('Значения')
plt.ylabel('Плотность вероятности')
plt.legend()
plt.grid(True)
plt.show()
plot_beta(a=10, b=90, scaler=1)
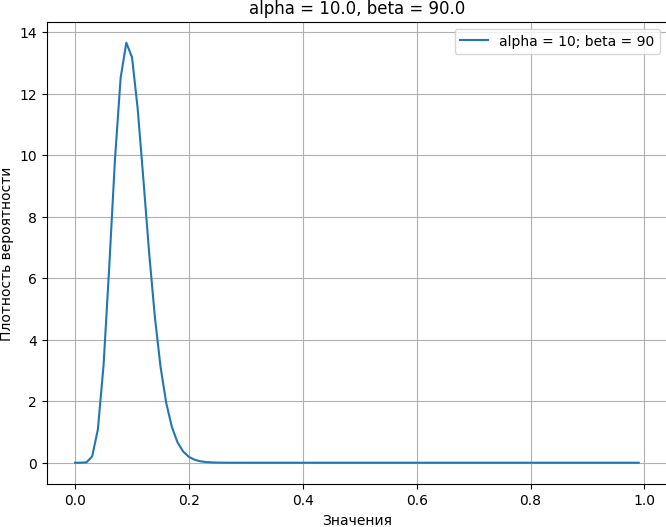
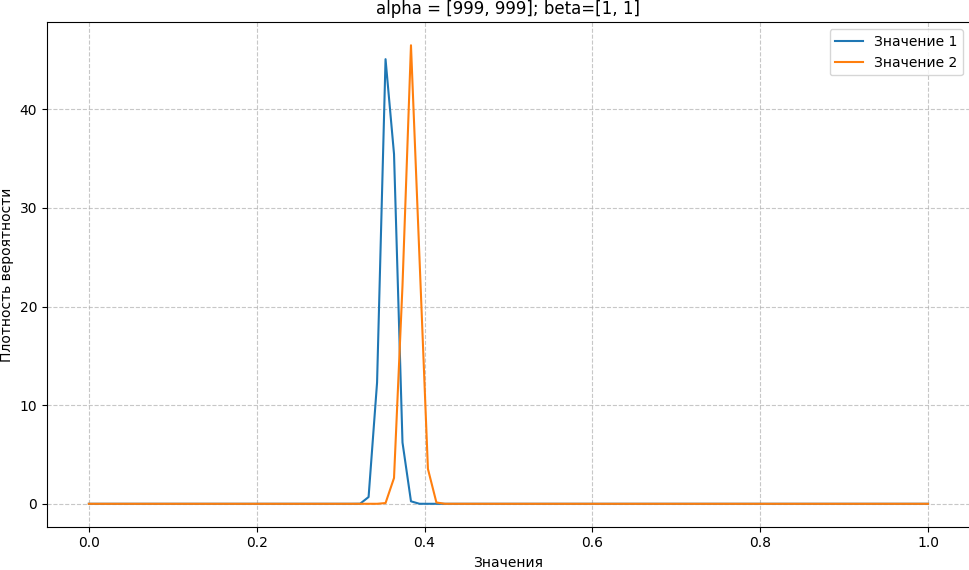
Влияние априорных распределений на точность и ожидаемые значения
Выбор априоров влияет не только на форму апостериорного распределения (насколько оно «острое» или «плоское»), но и на ожидаемые значения этого распределения. «Острота» распределения отражает нашу уверенность в его значениях: чем острее распределение, тем выше наша уверенность в том, что истинное значение находится близко к пикам распределения. Даже если мы используем абсурдно сильный априор Beta(999, 1), подразумевающий конверсию на невозможном уровне 99,9%, наши апостериорные ожидания могут оказаться около 30%. Это происходит потому, что сильный априор тянет апостериорное распределение в сторону своих значений, даже если наблюдаемые данные указывают на другое:
def plot_posterior(clicks, conv_cnt, a=1, b=1, scaler=1):
x = np.linspace(0, 1, 100)
if not isinstance(a, collections.abc.MutableSequence):
a = [a for _ in range(len(clicks))]
b = [b for _ in range(len(clicks))]
plt.figure(figsize=(10, 6))
for v in range(len(clicks)):
y = [beta.pdf(i/100, a=a[v]*scaler + conv_cnt[v], \
b=b[v]*scaler + clicks[v] - conv_cnt[v]) for i in range(100)]
plt.plot(x, y, label=f'Значение {v+1}')
plt.xlabel('Значения')
plt.ylabel('Плотность вероятности')
plt.title(f'alpha = {[i*scaler for i in a]}; beta={[i*scaler for i in b]}')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
Какая кампания эффективнее и насколько
Один из способов определить, какой вариант лучше, — это изучить апостериорные распределения и их ожидания. Однако это не дает нам понимания о разнице между ними. У нас есть апостериорное распределение для каждой вариации, поэтому мы можем вывести то, что иногда путают с частотным p-значением: какова вероятность того, что одна вариация будет лучше другой? Один из способов сделать это — использовать метод Монте-Карло для генерации большого количества выборок из каждого апостериора, а затем рассчитать процентное соотношение побед каждого образца.
Метод Монте-Карло позволяет приближенно оценить сложные статистические свойства систем путем случайного моделирования. В контексте сравнения вариаций, можно использовать этот метод для оценки вероятности того, что одна вариация превзойдет другую, основываясь на их апостериорных распределениях:
# Выборка из бета-распределения и вычисление вероятности того, что кампания A лучше B
def sample_proportion(c, n, a=1, b=1, sim_size=100000):
return np.random.beta(c + a, n - c + b, sim_size)
def proportion_test_b(c1, c2, n1, n2, a1=1, a2=1, b1=9, b2=9, sim_size=100000):
p1 = sample_proportion(c1, n1, a1, b1, sim_size)
p2 = sample_proportion(c2, n2, a2, b2, sim_size)
return (p1 > p2).mean()
def proportion_ratio(c1, c2, n1, n2, a1=1, a2=1, b1=9, b2=9, sim_size=100000):
p1 = sample_proportion(c1, n1, a1, b1, sim_size)
p2 = sample_proportion(c2, n2, a2, b2, sim_size)
return p1 / p2
def proportion_ci_b(c1, c2, n1, n2, p_value=0.05, a1=1, a2=1, b1=9, b2=9, sim_size=100000):
ratios = proportion_ratio(c1, c2, n1, n2, a1, a2, b1, b2, sim_size)
return np.quantile(ratios, [p_value / 2, 1 - p_value / 2])
p_value = proportion_test_b(*conv_df['conv_cnt'], *conv_df['clicks'])
ratios = proportion_ratio(*conv_df['conv_cnt'], *conv_df['clicks'])
credible = proportion_ci_b(*conv_df['conv_cnt'], *conv_df['clicks'], p_value=0.05)
print(f'Вероятность того, что A больше B: {p_value}')
print(f'Среднее отношение A/B: {ratios.mean()}')
print(f'Доверительный интервал отношения A/B: {credible}')
Результат:
Вероятность того, что A лучше B: 0.22743
Среднее отношение A/B: 0.9394908467261973
Доверительный интервал отношения A/B: [0.78622231 1.11331594]
Определение вероятности того, что B лучше A:
def sample_proportion(c, n, a=1, b=1, sim_size=100000):
return np.random.beta(c + a, n - c + b, sim_size)
def proportion_test_b(c1, c2, n1, n2, a1=1, a2=1, b1=9, b2=9, sim_size=100000):
p1 = sample_proportion(c1, n1, a1, b1, sim_size)
p2 = sample_proportion(c2, n2, a2, b2, sim_size)
return (p2 > p1).mean()
def proportion_ratio(c1, c2, n1, n2, a1=1, a2=1, b1=9, b2=9, sim_size=100000):
p1 = sample_proportion(c1, n1, a1, b1, sim_size)
p2 = sample_proportion(c2, n2, a2, b2, sim_size)
return p2 / p1
def proportion_ci_b(c1, c2, n1, n2, p_value=0.05, a1=1, a2=1, b1=9, b2=9, sim_size=100000):
ratios = proportion_ratio(c1, c2, n1, n2, a1, a2, b1, b2, sim_size)
return np.quantile(ratios, [p_value / 2, 1 - p_value / 2])
p_value = proportion_test_b(*conv_df['conv_cnt'], *conv_df['clicks'])
ratios = proportion_ratio(*conv_df['conv_cnt'], *conv_df['clicks'])
credible = proportion_ci_b(*conv_df['conv_cnt'], *conv_df['clicks'], p_value=0.05)
print(f'Вероятность того, что B лучше A: {p_value}')
print(f'Среднее отношение B/A: {ratios.mean()}')
print(f'Доверительный интервал отношения B/A: {credible}')
Результат:
Вероятность того, что B лучше A: 0.77257
Среднее отношение B/A: 1.0728335856593436
Доверительный интервал отношения B/A: [0.89821762 1.27190489]
Построение отношения A к B позволяет нам увидеть степень различия между двумя значениями. Например, ниже мы видим, что примерно в 80% распределения A оказывается хуже, чем B, и в случае, если мы ошиблись, A в лучшем случае будет всего на 20% эффективнее, чем B. И аналогично частотному подходу, мы можем рассчитать диапазон, в который попадают большинство этих отношений (скажем, 95%), называемый доверительным интервалом:
def plot_ab_ratio(ratios, credible):
plt.figure(figsize=(10, 6))
plt.hist(ratios, bins=50, alpha=0.75, color='blue')
plt.axvline(x=1, color='red', linestyle='--', label='Отношение A/B = 1')
plt.axvline(x=credible[0], color='green', linestyle='--', label=f'Нижняя граница = {credible[0]:.2f}')
plt.axvline(x=credible[1], color='green', linestyle='--', label=f'Верхняя граница = {credible[1]:.2f}')
plt.xlabel('Отношение взятых коэффициентов конверсии A / B')
plt.ylabel('Частота')
plt.legend()
plt.grid(True)
plt.title('Распределение отношений A/B')
plt.show()
plot_ab_ratio(ratios, credible)
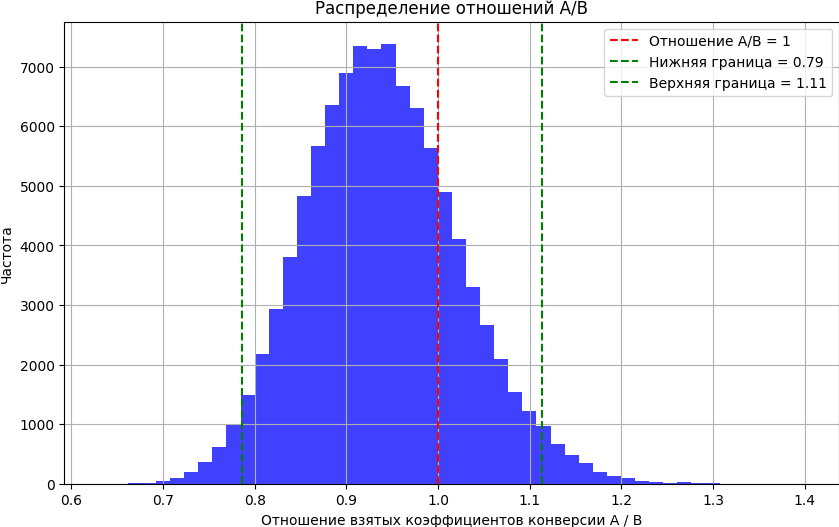
Когда можно остановить тест
Освобождение от частотных p-значений позволяет нам избежать проблемы, когда бесконечное количество выборок всегда дает статистическую значимость — даже тогда, когда истинные значения абсолютно одинаковы. Как видно из приведенного ниже графика, вероятность того, что A превосходит B, остается примерно на уровне 50%, когда нет истинных различий, и постепенно уменьшается, когда они есть:
conv_days2 = gen_campaigns(p1=0.10, p2=0.10, nb_days=60, scaler=300, seed=1412)
conv_days3 = gen_campaigns(p1=0.10, p2=0.11, nb_days=60, scaler=300, seed=1412)
conv_days2['prob_same'] = conv_days2.apply(lambda row: proportion_test_b(row['cumu_conv_a'], row['cumu_conv_b'], row['cumu_click_a'], row['cumu_click_b']), axis=1)
conv_days3['prob_diff'] = conv_days3.apply(lambda row: proportion_test_b(row['cumu_conv_a'], row['cumu_conv_b'], row['cumu_click_a'], row['cumu_click_b']), axis=1)
plt.figure(figsize=(12, 8))
plt.plot(conv_days2['click_day'], conv_days2['prob_same'], label='Вероятность равенства')
plt.plot(conv_days3['click_day'], conv_days3['prob_diff'], label='Вероятность различия')
plt.axhline(y=0.9, color='green', linestyle='--', label='Здесь A лучше B')
plt.axhline(y=0.1, color='red', linestyle='--', label='Здесь B лучше A')
plt.xlabel('Количество временных шагов')
plt.ylabel('Вероятность того, что A побеждает B')
plt.title('Сравнение вероятностей того, что A побеждает B, когда B на самом деле лучше, и когда оба равны')
plt.legend()
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()
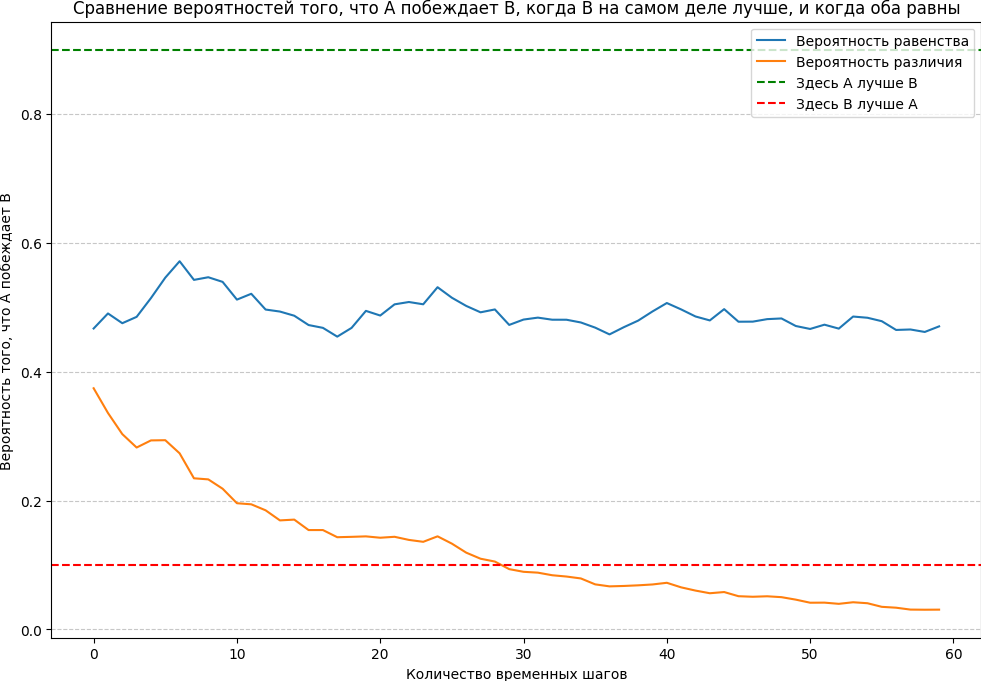
Логичный вопрос, который возникает далее: когда нам следует остановиться и объявить победителя? Технически, когда есть истинное различие, мы можем остановиться в любой момент времени, и получим победителя с различными степенями вероятности (это явный прогресс по сравнению с частотным подходом). Мы также можем использовать простое правило, например, если вероятность того, что A побеждает B, ниже 10% или выше 90%, мы объявляем победителя, как показано на графике выше.
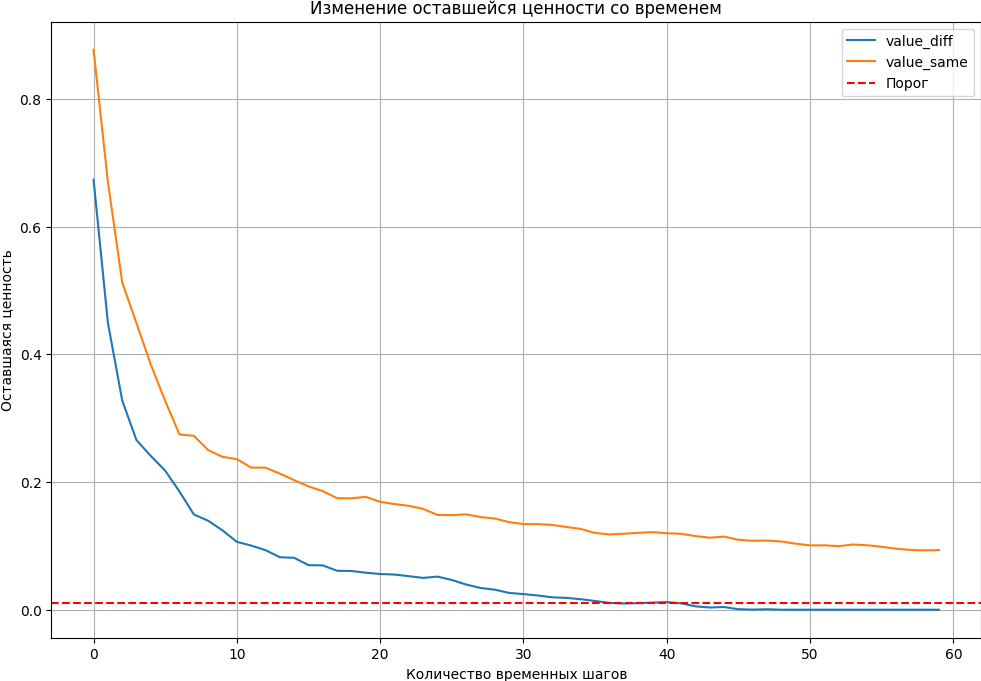
Критерии остановки экспериментов типа ROPE и ожидаемая потеря описаны в Руководстве по байесовскому A/B-тестированию. А здесь мы будем использовать концепцию оставшейся ценности, введенную Google. Оставшаяся ценность за каждый раунд эксперимента определяется так:
По мере продолжения эксперимента мы строим распределение Vt и останавливаемся, когда 1−α процентиль ниже нашего порога. Это означает, что мы уверены на 1−α% что наш лучший вариант может быть побежден с маржой, равной порогу. На практике мы пробуем 95-й процентиль и порог в 1%:
def value_remaining(c1, c2, n1, n2, q=95, sim_size=100000, a1=1, a2=1, b1=9, b2=9):
p1 = sample_proportion(c1, n1, a1, b1, sim_size)[:, None]
p2 = sample_proportion(c2, n2, a2, b2, sim_size)[:, None]
p = np.concatenate([p1, p2], 1)
p_max = p.max(1)
best_idx = np.argmax([p1.mean(), p2.mean()])
p_best = p[:, best_idx]
vs = (p_max - p_best) / p_best
return np.percentile(vs, q)
def proportion_test_b(c1, c2, n1, n2, a1=1, a2=1, b1=9, b2=9, sim_size=100000):
p1 = sample_proportion(c1, n1, a1, b1, sim_size)
p2 = sample_proportion(c2, n2, a2, b2, sim_size)
return (p1 > p2).mean()
conv_days2 = gen_campaigns(p1=0.10, p2=0.10, nb_days=60, scaler=300, seed=1412)
conv_days2['prob_same'] = conv_days2.apply(lambda row: proportion_test_b(row['cumu_conv_a'], row['cumu_conv_b'], row['cumu_click_a'], row['cumu_click_b']), axis=1)
conv_days3 = gen_campaigns(p1=0.10, p2=0.11, nb_days=60, scaler=300, seed=1412)
conv_days3['prob_diff'] = conv_days3.apply(lambda row: proportion_test_b(row['cumu_conv_a'], row['cumu_conv_b'], row['cumu_click_a'], row['cumu_click_b']), axis=1)
conv_days2['value_remaining'] = conv_days2.apply(lambda row: value_remaining(row['cumu_conv_a'], row['cumu_conv_b'], row['cumu_click_a'], row['cumu_click_b']), axis=1)
conv_days3['value_remaining'] = conv_days3.apply(lambda row: value_remaining(row['cumu_conv_a'], row['cumu_conv_b'], row['cumu_click_a'], row['cumu_click_b']), axis=1)
value_df = pd.DataFrame({
'click_day': conv_days2.click_day,
'value_same': conv_days2.value_remaining,
'value_diff': conv_days3.value_remaining
}).melt(id_vars='click_day')
plt.figure(figsize=(12, 8))
for name, group in value_df.groupby('variable'):
plt.plot(group['click_day'], group['value'], label=name)
plt.axhline(y=0.01, color='r', linestyle='--', label='Порог')
plt.xlabel('Количество временных шагов')
plt.ylabel('Оставшаяся ценность')
plt.legend()
plt.title('Изменение оставшейся ценности со временем')
plt.grid(True)
plt.show()
Подведем итоги
A/B-тестирование играет ключевую роль в оптимизации взаимодействия пользователей с продуктами и услугами. Выбор подхода к A/B-тестированию зависит от специфики исследования, целей анализа и доступных данных:
- Частотный подход, основанный на предположении о независимости выборок и использовании p-значений для оценки статистической значимости, является классическим методом и широко применяется в научных исследованиях и бизнес-анализах. Он хорошо подходит для ситуаций, когда можно собрать достаточно большие выборки данных и когда интересуют глобальные тренды и тенденции.
- Байесовский подход позволяет интегрировать предварительные знания и шкалу убеждений в анализ, делая его более адаптивным и гибким к изменениям в данных. Байесовское A/B-тестирование особенно полезно в условиях ограниченных ресурсов, когда важно быстро принимать решения на основе текущих данных, или когда требуется более тонкая настройка стратегии тестирования. Байесовский подход также позволяет более точно оценить вероятностные распределения и интервалы доверия, что может быть критически важно для принятия решений в условиях неопределенности.
Какой опыт у вас есть в применении байесовского A/B-тестирования? Поделитесь своими успехами или трудностями.
Комментарии