

Что такое хэш-карта?
Чтобы сформулировать понятие хэш-карты, для начала необходимо понять, что такое хэширование. Хеширование – это процесс преобразования любого заданного ключа или строки символов в другое значение. В результате обычно получается более короткое значение фиксированной длины, с которым гораздо проще работать, чем с исходным ключом.
Хэш-карты, также известные как хэш-таблицы, представляют собой одну из наиболее распространенных реализаций хэширования. Хэш-карты хранят пары ключ-значение (например, идентификатор сотрудника и его имя) в списке, доступ к которому осуществляется через его индекс.
Идея хэш-карт заключается в распределении записей (пар ключ/значение) по массиву блоков. Учитывая ключ, функция хеширования вычисляет отдельный индекс, который подсказывает, где можно найти нужную запись. Использование индекса вместо исходного ключа делает хэш-карты особенно удобными для различных операций с данными, включая их добавление, удаление и поиск.
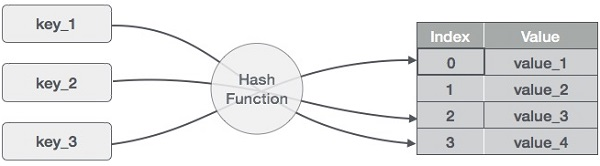
Для вычисления хэш-значения, или просто хэша, хэш-функция генерирует новые значения в соответствии с математическим алгоритмом хэширования. Поскольку пары ключ-значение теоретически неограничены, то хэш-функция сопоставляет ключи в соответствии с заданным размером таблицы.
Существует множество хэш-функций, каждая из которых имеет свои плюсы и минусы. Основная цель хэш-функции – всегда возвращать одно и то же значение на один и тот же запрос.
Наиболее распространенными являются следующие:
- Метод деления. Это самый простой и самый быстрый способ вычисления хэш-значений. Для этого нужно разделить ключ на размер таблицы, а затем использовать остаток в качестве хэша.
- Метод среднего квадрата. Находит квадрат заданного ключа, затем берет средние цифры и использует их в качестве индекса элемента.
- Метод умножения. Определяет хэш-индекс из дробной части умножения ключа на большое вещественное число.
- Метод складывания. Ключ сначала делится на равные по размеру части, итоги складываются, а результат делится на размер таблицы. В результате получается хэш.
Хэш-карты в Python
В Python хеш-карты реализуются через встроенный тип данных словаря. Как и хеш-карты, словари хранят данные в парах {ключ:значение}. Как только вы создадите словарь (смотрите следующий раздел), Python применит подходящую хэш-функцию для вычисления хэша каждого ключа.
Словари Python обладают следующими свойствами:
- Словари можно изменять. Это означает, что мы можем изменять, добавлять или удалять элементы после создания словаря.
- Элементы упорядочены. В Python 3.6 и более ранних версиях словари были неупорядоченными, то есть их элементы не имели определенного порядка. Однако после выхода Python 3.7 словари стали поддерживать порядок. Теперь, когда вы создаете словарь Python, ключи будут следовать порядку, указанному в исходном коде.
- Ключи являются неизменяемыми. Это означает, что ключи – это всегда типы данных, которые не могут быть изменены. Другими словами, словари допускают только хешируемые типы данных, такие как строки, числа и кортежи. И наоборот, ключи никогда не могут быть изменяемыми типами данных, такими как список.
- Ключи уникальны. Ключи уникальны в пределах словаря и не могут быть продублированы внутри него. Если он используется более одного раза, последующие записи будут перезаписывать предыдущее значение.
Итак, если вы когда-либо задавались вопросом о различиях между хеш-картами и словарями – ответ прост. Словарь – это просто собственная реализация хэш-карт в Python. В то время как хеш-карта – это структура данных, которая может быть создана с использованием различных методов хеширования, где словарь – это конкретная хеш-карта, основанная на Python, дизайн и поведение которой определяется классом dict в Python.
Как использовать словари Python
Давайте рассмотрим некоторые из наиболее распространенных операций со словарями. Чтобы узнать больше о том, как использовать словари, ознакомьтесь с нашим учебником по словарям Python: 🐍 Самоучитель по Python для начинающих. Часть 6: Методы работы со словарями и генераторами словарей.
Создание словаря
Создавать словари в Python довольно просто. Нужно просто использовать фигурные скобки и вставить пары ключ-значение, разделенные запятыми. В качестве альтернативы можно использовать встроенную функцию dict(). Давайте создадим словарь, который сопоставляет столицы и страны:
dictionary_capitals = {'Madrid": 'Spain", 'Lisboa': 'Portugal', 'London': 'United Kingdom'}
Чтобы вывести на экран содержимое словаря:
print(dictionary_capitals)
{'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}
Важно не забывать, что ключ должен быть уникальным в словаре – дубликаты не допускаются. Впрочем, в случае дублирования ключей Python не выдаст ошибку, а примет за действительный последний экземпляр ключа и просто проигнорирует первую пару ключ-значение. Убедитесь в этом сами:
dictionary_capitals = {'Madrid': 'China', 'Lisboa': 'Portugal',
'London': 'United Kingdom','Madrid':'Spain'}
print(dictionary_capitals)
{'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}
Поиск в словаре
Чтобы найти информацию в словаре, нам нужно указать ключ в скобках, и Python вернет связанное с ним значение, как показано ниже:
dictionary_capitals['Madrid']
'Spain'
Если вы попытаетесь получить доступ к ключу, которого нет в словаре, Python выдаст ошибку. Чтобы предотвратить это, вы можете альтернативно получить доступ к ключам с помощью метода .get(). В случае несуществующего ключа он просто вернет значение None:
print(dictionary_capitals.get('Prague'))
None
Добавление и удаление значений в словаре
Давайте добавим новую пару столица-страна:
dictionary_capitals['Berlin'] = 'Italy'
Тот же синтаксис можно использовать для обновления значения, связанного с ключом. Давайте исправим значение, связанное с Берлином:
dictionary_capitals['Berlin'] = 'Germany'
Теперь давайте удалим одну из пар в нашем словаре:
del dictionary_capitals['Lisboa']
print(dictionary_capitals)
{'Madrid': 'Spain', 'London': 'United Kingdom', 'Berlin': 'Germany'}
Или, если вам нужно удалить все пары ключ-значение в словаре, вы можете воспользоваться методом .clear():
dictionary_capitals.clear()
Выборка словарей
Если вы хотите получить все пары ключ-значение, используйте метод .items(), и Python получит итерируемый список кортежей:
dictionary_capitals.items()
dict_items([('Madrid', 'Spain'), ('London', 'United Kingdom'), ('Berlin', 'Germany')])
for key, value in dictionary_capitals.items():
print('the capital of {} is {}'.format(value, key))
the capital of Spain is Madrid
the capital of United Kingdom is London
the capital of Germany is Berlin
Аналогично, если вы хотите получить итерируемый список с ключами и значениями, вы можете использовать методы .keys() и .values() соответственно:
dictionary_capitals.keys()
dict_keys(['Madrid', 'London', 'Berlin'])
for key in dictionary_capitals.keys():
print(key.upper())
MADRID
LONDON
BERLIN
dictionary_capitals.values()
dict_values(['Spain', 'United Kingdom', 'Germany'])
for value in dictionary_capitals.values():
print(value.upper())
SPAIN
UNITED KINGDOM
GERMANY
Области применения хэш-карт
Хэш-карты – это мощные структуры данных, которые используются практически повсеместно в цифровом мире. Ниже приведен список применений хэш-карт:
- Индексирование баз данных. Хэш-карты часто используются для индексирования и поиска огромных объемов данных. Обычные веб-браузеры используют хэш-карты для хранения проиндексированных веб-страниц.
- Управление кэшем. Современные операционные системы используют хэш-карты для упорядочивания кэш-памяти, чтобы обеспечить быстрый доступ к часто используемой информации.
- Криптография. Хэш-карты играют важную роль в области криптографии. Криптографические алгоритмы используют хэш-карты для обеспечения целостности данных, их проверки и безопасных транзакций в сетях.
- Блокчейн. Хэш-карты лежат в основе блокчейна. Когда в сети осуществляется транзакция, данные о ней поступают на вход хэш-функции, которая затем выдает уникальный результат. Каждый блок в блокчейне содержит хэш предыдущего блока, образуя цепочку блоков.
Лучшие практики работы с хэш-картами и распространенные ошибки
Хэш-карты – универсальные и эффективные структуры данных. Однако они также не лишены проблем и ограничений. Чтобы решить общие проблемы, связанные с хэш-картами, важно помнить о некоторых рекомендациях и лучших практиках.
Ключи должны быть неизменяемыми
Это логично: если содержимое ключа изменится, то хэш-функция вернет другой результат, и Python не сможет найти значение, связанное с ключом.
Устранение коллизий хэш-карты
Хеширование работает только в том случае, если каждый элемент сопоставляется с уникальным местоположением в хеш-таблице. Но иногда хэш-функции могут возвращать один и тот же результат для разных исходных данных. К примеру, если вы используете хэш-функцию деления, разные целые числа могут иметь одну и ту же хэш-функцию (они могут возвращать один и тот же остаток при применении модуля деления), что создает проблему, называемую коллизией. Коллизии необходимо разрешать, и для этого существует несколько методов. К счастью, в случае со словарями, Python справляется с потенциальными коллизиями «изнутри».
Понимание коэффициента загрузки
Коэффициент загрузки определяется как отношение количества элементов в таблице к общему количеству блоков. Это показатель, позволяющий оценить, насколько хорошо распределены данные. Как правило, чем равномернее данные расположены, тем меньше вероятность столкновений. Опять же, в случае со словарями, Python автоматически адаптирует размер таблицы при добавлении или удалении новых пар ключ-значение.
Помните о производительности
Хорошая хэш-функция должна минимизировать количество коллизий, быть простой в вычислении и равномерно распределять элементы в хэш-таблице. Этого можно добиться, увеличив размер таблицы или сложность хэш-функции. Хотя это практично для небольшого количества элементов, при большом объеме возможных объектов это нецелесообразно, так как приведет к тому, что хэш-таблицы будут занимать много памяти и будут менее эффективными.
Словари – это то, что вам нужно?
Словари – это здорово, но другие структуры данных могут оказаться более подходящими для ваших конкретных данных и потребностей. В конце концов, словари не поддерживают такие распространенные операции, как индексирование, срез и объединение, что делает их менее гибкими и более сложными для работы в определенных условиях.
Альтернативные реализации хеш-карт в Python
Как уже упоминалось, в Python хеш-карты реализуются через встроенные словари. Однако важно отметить, что существуют и другие внутренние инструменты Python, а также сторонние библиотеки, позволяющие использовать возможности хеш-карт.
Давайте рассмотрим некоторые из наиболее популярных примеров.
Defaultdict
Каждый раз, когда вы пытаетесь получить доступ к ключу, которого нет в вашем словаре, Python возвращает ошибку KeyError. Предотвратить это можно, выполнив поиск информации с помощью метода .get(). Однако более оптимальным способом является использование Defaultdict, доступного в модуле collections. Defaultdict и словари – это почти одно и то же. Единственное отличие заключается в том, что Defaultdict никогда не вызывает ошибку, поскольку предоставляет значение по умолчанию для несуществующих ключей.
from collections import defaultdict
# Defining the dict
capitals = defaultdict(lambda: "The key doesn't exist")
capitals['Madrid'] = 'Spain'
capitals['Lisboa'] = 'Portugal'
print(capitals['Madrid'])
print(capitals['Lisboa'])
print(capitals['Ankara'])
Spain
Portugal
The key doesn't exist
Counter (счетчик)
Counter – это подкласс словаря Python, который специально разработан для подсчета хэшируемых объектов. Это словарь, в котором элементы хранятся как ключи, а их количество – как значения.
Существует несколько способов инициализации счетчика:
- Последовательностью элементов.
- Ключами и значениями в словаре.
- С помощью сопоставления имя:значение.
from collections import Counter
c1 = Counter(['aaa','bbb','aaa','ccc','ccc','aaa'])
c2 = Counter({'red': 4, 'blue': 2})
c3 = Counter(cats=4, dogs=8)
print(c1)
print(c2)
print(c3)
Counter({'aaa': 3, 'ccc': 2, 'bbb': 1})
Counter({'red': 4, 'blue': 2})
Counter({'dogs': 8, 'cats': 4})
Класс counter включает в себя ряд удобных методов для выполнения стандартных вычислений.
print('keys of the counter: ', c3.keys())
print('values of the counter: ',c3.values())
print('list with all elements: ', list(c3.elements()))
print('number of elements: ', c3.total()) # number elements
print('2 most common occurrences: ', c3.most_common(2)) # 2 most common occurrences
dict_keys(['cats', 'dogs'])
dict_values([4, 8])
['cats', 'cats', 'cats', 'cats', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs']
12
[('dogs', 8), ('cats', 4)]
Методы хеширования в Scikit-learn
Scikit-learn, также известная как sklearn, – это надежная библиотека машинного обучения на Python с открытым исходным кодом. Она была создана, чтобы помочь упростить процесс реализации машинного обучения и статистических моделей на Python.
Sklearn включает в себя различные методы хеширования, которые могут быть очень полезны в процессе разработки функций.
Один из самых распространенных – метод CountVectorizer. Он используется для преобразования заданного текста в вектор на основе частоты встречаемости каждого слова во всем тексте. CountVectorized особенно полезен в контексте анализа текста.
from sklearn.feature_extraction.text import CountVectorizer
documents = ["Welcome to this new DataCamp Python course",
"Welcome to this new DataCamp R skill track",
"Welcome to this new DataCamp Data Analyst career track"]
# Create a Vectorizer Object
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# print unique values
print('unique words: ', vectorizer.get_feature_names_out())
#print sparse matrix with word frequency
pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names_out())
unique words: ['analyst' 'career' 'course' 'data' 'datacamp' 'new' 'python' 'skill' 'this' 'to' 'track' 'welcome']

В sklearn есть и другие методы хеширования, включая FeatureHasher и DictVectorizer.
Заключение
Поздравляем вас с завершением этого руководства по хеш-картам. Мы надеемся, что теперь вы лучше понимаете, что такое хеш-карты и словари Python. Если вы хотите узнать больше о словарях и о том, как использовать их в реальных условиях, мы настоятельно рекомендуем вам прочитать наш специальный учебник по словарям Python:
И решить несколько задач:
Комментарии