

Термину Big Data более десяти лет, но вокруг него до сих пор много путаницы. Доступно рассказываем, что же такое «большие данные», откуда эти данные берутся и где используются, кто такие аналитики данных и чем они занимаются.
Три признака больших данных
Традиционно большие данные характеризуют тремя признаками (так называемым правилом VVV):
- Большой объем (Volume). Термин Big Data предполагает большой информационный объем (терабайты и петабайты информации). Важно понимать, что для решения определенного бизнес-кейса ценность обычно имеет не весь объем, а лишь незначительная часть. Однако заранее эту ценную составляющую без анализа определить невозможно.
- Большая скорость обновлений (Velocity). Данные регулярно обновляются и требуют постоянной обработки. Обновление чаще всего подразумевает рост объема.
- Многообразие (Variety). Данные могут иметь различные форматы и быть структурированы лишь частично или быть вовсе сырыми, неоднородными. Необходимо учитывать, что часть данных почти всегда недостоверна или неактуальна на момент проведения исследования.
В качестве простейшего примера можно представить таблицу с миллионами строк клиентов крупной компании. Столбцы – это характеристики пользователей (Ф.И.О., пол, дата, адрес, телефон и т. д.), один клиент – одна строка. Информация обновляется постоянно: клиенты приходят и уходят, данные корректируются.
Но таблицы – это лишь одна из простейших форм отображения информации. Обычно представление больших данных имеет куда более витиеватый и менее структурированный характер. Так, ниже показана схема базы данных проекта MediaWiki:

Большой объем предполагает особую инфраструктуру хранения данных – распределенные файловые системы. Для работы с ними используются реляционные системы управления базами данных. Это требует от аналитика уметь составлять соответствующие запросы к базам данных.
Где живут большие данные?
Инструменты Big Data используются во многих сферах жизни современного человека. Перечислим некоторые из наиболее популярных областей с примерами бизнес-задач:
- Поисковая выдача (оптимизация отображаемых ссылок с учетом сведений о пользователе, его местоположении, предыдущих поисковых запросах).
- Интернет-магазины (повышение конверсии).
- Рекомендательные системы (жанровая классификация фильмов и музыки).
- Голосовые помощники (распознавание голоса, реакция на запрос).
- Цифровые сервисы (фильтрация спама в электронной почте, индивидуальная новостная лента).
- Социальные сети (персонализированная реклама).
- Игры (внутриигровые покупки, игровое обучение).
- Финансы (принятие банком решений о кредитовании, трейдинг).
- Продажи (прогнозирование остатков на складе для снижения издержек).
- Системы безопасности (распознавание объектов с видеокамер).
- Автопилотируемый транспорт (машинное зрение).
- Медицина (диагностика заболеваний на ранних стадиях).
- Городская инфраструктура (предотвращение пробок на дорогах, предсказание пассажиропотока в общественном транспорте).
- Метеорология (прогнозирование погоды).
- Промышленное производство товаров (оптимизация конвейера, снижение рисков).
- Научные задачи (расшифровка геномов, обработка астрономических данных, космических снимков).
- Обработка информации с фискальных накопителей (прогнозирование стоимости товаров).
Для каждой из перечисленных задач можно найти примеры решений с помощью технологий, входящих в сферу Data Science и Machine Learning. Объем используемых данных определяет стратегию и точность решения.
Чем занимаются люди в Big Data?
Анализ Big Data находится на стыке трех областей:
- Computer Science/IT
- Математика и статистика
- Специальные знания анализируемой области
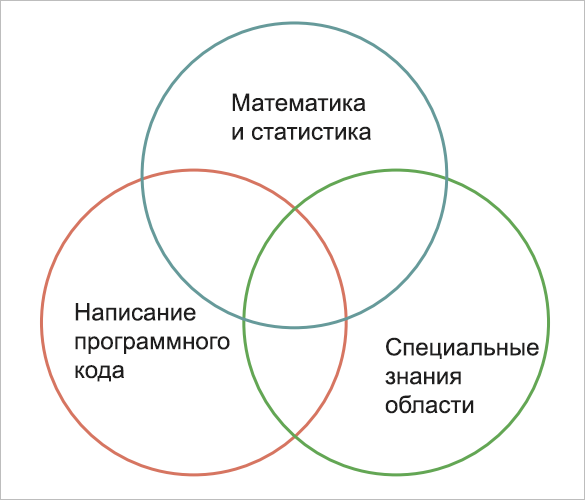
Поэтому аналитик данных – междисциплинарный специалист, обладающий знаниями и в математике, и в программировании, и в базах данных. Вышеперечисленные примеры задач предполагают, что человек должен быстро разбираться в новой предметной области, иметь коммуникативные навыки. Особенно важно уметь находить аналитически обоснованный и полезный для бизнеса результат. Немаловажно грамотно эти выводы визуализировать и презентовать.
Очередность действий в проводимом исследовании примерно сводится к следующему:
- Работа с базами (структурирование, логика).
- Извлечение необходимой информации (написание SQL-запросов).
- Предобработка данных.
- Преобразование данных.
- Применение статистических методов.
- Поиск паттернов.
- Визуализация данных (выявление аномалий, наглядное представление для бизнеса).
- Поиск ответа, формулировка и проверка гипотезы.
- Внедрение в процесс.
Итог работы представляет сжатый отчет с визуализацией результата либо интерактивную панель (dashboard). На такой панели обновляемые данные после обработки предстают в удобной для восприятия форме.
Ключевые навыки и инструменты аналитика
Навыки и соответствующие инструменты, применяемые аналитиками, обычно следующие:
- Извлечение данных из источников данных (MS SQL, MySQL, NoSQL, Hadoop, Spark).
- Обработка данных (Python, R, Scala, Java).
- Визуализация (Plotly, Tableau, Qlik).
- Исследование по критериям бизнес-задачи.
- Формулировка гипотез.
Выбор языка программирования диктуется имеющимися наработками и необходимой скоростью конечного решения. Язык определяет среду разработки и инструменты анализа данных.
Большинство аналитиков используют в качестве языка программирования Python. В этом случае для анализа больших обычно применяется Pandas. При работе в команде общепринятым стандартом документов для хранения и обмена гипотезами являются ipynb-блокноты, обычно обрабатываемые в Jupyter. Этот формат представления данных позволяет совмещать ячейки с программным кодом, текстовые описания, формулы и изображения.
Выбор инструментария для решения задачи зависит от кейса и требований заказчика к точности, надежности и скорости выполнения алгоритма решения. Также важна возможность объяснить составляющие алгоритма от этапа ввода данных до вывода результата.
Так, для задач, связанных с обработкой изображений, чаще применяются нейросетевые инструменты, такие как TensorFlow или один из десятка других фреймворков глубокого обучения. Но, к примеру, при разработке финансовых инструментов нейросетевые решения могут выглядеть «опасными», ведь проследить путь нахождения результата оказывается затруднительно.
Выбор модели анализа и ее архитектуры не менее тривиален, чем вычислительный процесс. Из-за этого в последнее время развивается направление автоматического машинного обучения. Данный подход вряд ли сократит потребность в аналитиках данных, но уменьшит число рутинных операций.
Как разобраться в Big Data?
Как можно понять из приведенного обзора, большие данные предполагают от аналитика и большой объем знаний их различных областей. Разобраться с основами поможет наш учебный план. Если захочется углубиться и попытаться последовательно охватить все аспекты вопроса, изучите roadmap Data Science:
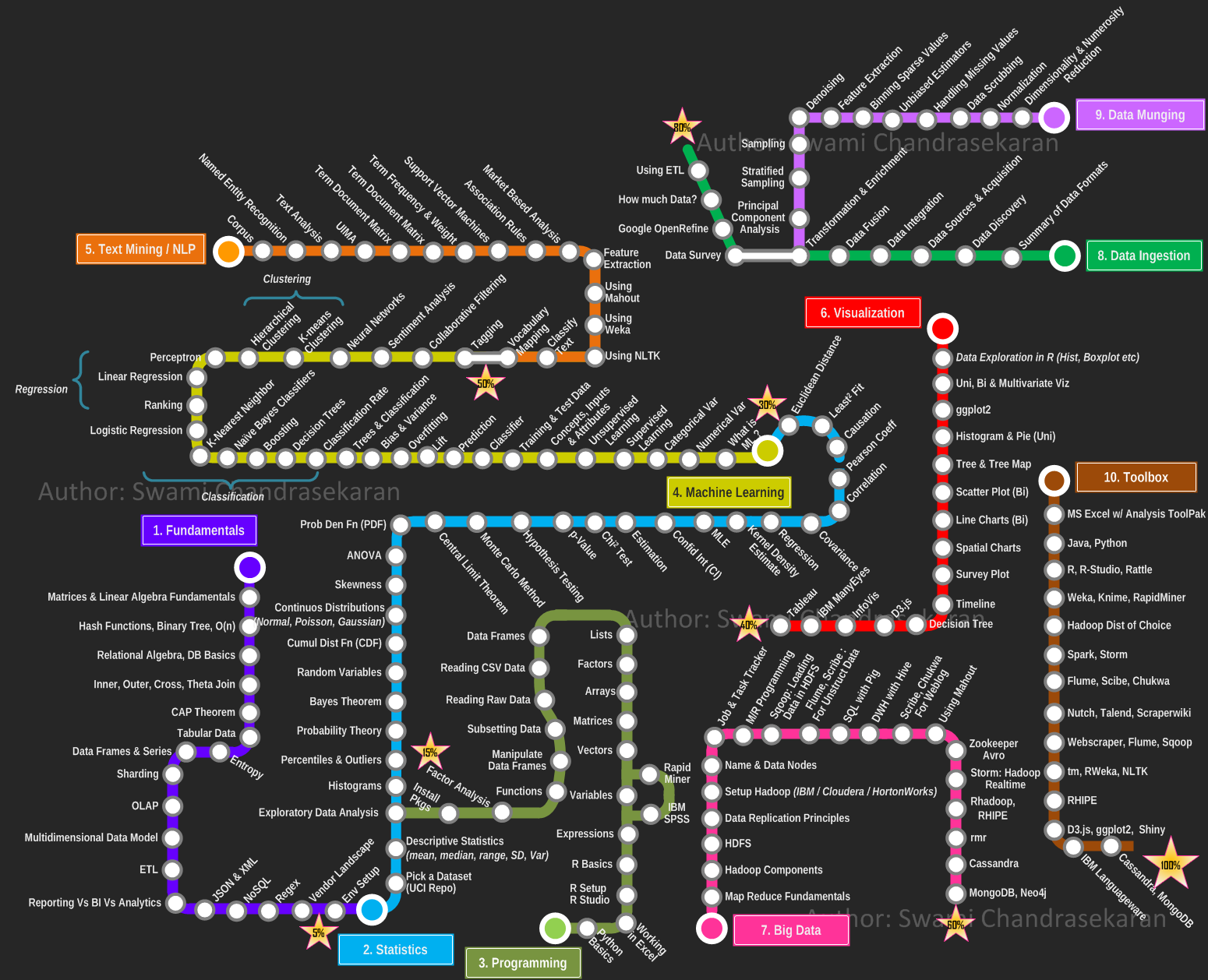
В упомянутом репозитории вы также найдете краткие описания и ссылки к некоторым из компонентов карты.
С чего начать, если хочется попробовать прямо сейчас, но нет данных?
Опытные аналитики советуют пораньше знакомиться с Kaggle. Это популярная платформа для организации конкурсов по анализу больших объемов данных. Здесь найдутся не только соревнования с денежными призами за первые места, но и ipynb-блокноты с идеями и решениями, а также интересные датасеты (наборы данных) различного объема.
Комментарии