

Серия «Инстурменты дата-журналиста» состоит из двух публикаций. В первой мы будем фильтровать, сортировать и очищать датасеты, используя библиотеку pandas в Jupyter Notebook. Ссылки на блокнот и шпаргалку вы найдете в конце статьи. Во второй части напишем парсер и создадим с его помощью собственный датасет, а также научимся визуализировать данные.
Вместо содержания ловите шпаргалку по статье:
# Импорт данных
df = pd.read_csv('file') – импорт файла
df = pd.read_csv('file', sep=",") – импорт файла с разделителем «запятая»
# Экспорт данных
save_file.to_csv('file.csv', encoding='utf8') – сохранение датафрейма в csv-файл с кодировкой utf8
# Вывод на экран
df – вывести весь датафрейм
df.info – информация о датафрейме
df.head(5) – первые пять строчек
df.tail(5) – последние пять строчек
df.sample(5) – случайные пять строчек
df.shape – количество строк и столбцов
df.dtypes – типы данных в столбцах
df.columns – названия столбцов
f['col1'] – значения столбца col1
df['col1'][0:20] – срез столбца col1
df[['col1', 'col2']] – значения нескольких столбцов
df.loc['index_name'] – строки и/или столбцы по нечисловому значению индекса
df.iloc[0] – строки и/или столбцы по числовому индексу
df.iloc[2,4] – значение ячейки в третьей строчке и пятом столбце
# Объединение датафреймов
df1 = pd.concat([df1, df2], axis=0) – к df1 добавляем строчки df2
df1 = pd.concat([df1, df2], axis=1) – к df1 добавляем столбцы df2
df1 = df1.append(df2) – к df1 добавляем строчки df2
# Копирование датафрейма
df2 = df1.copy – создает глубокую копию датафрейма
# Добавление строчек и столбцов
new_row = {'col1': 'Hello', 'col2': 123}
df = df.append(new_row, ignore_index=True) – добавляет в конец df строчку new_row
df.loc[2] = ['Hello', 123] – добвляет строчку на третье место с начала фрейма
df['new_column'] = 'abcd' – создает столбец со значениями abcd
# Удаление строчек и столбцов
df.drop(26954, 0) – удаляет строчку номер 26954
df.drop('col', 1) – удаляет столбец col
# Переименование столбцов
df.rename(columns={'col1': 'new_col1'}) – меняет имя столбца с col1 на new_col1
# Изменение значения в ячейке
df['col'] = df['col'].replace(to_replace=2020, value=2021) – меняем все значения с 2020 на 2021
df['col'] = df['col'].mask(df['col'] == 2001, 2021) – аналогично, меняем все значения с 2020 на 2021
# Сортировка
df.sort_values('col', ascending=False) – сортировка в обратном алфавитном порядке
df.sort_values(['col1', 'col2']) – сортировка по двум столбцам. col1 – в приоритете, так как первый
# Изменение типов
df['col'] = df['col'].astype(str) – меняет тип переменных на str
df['col'] = df['col'].astype(float) – на float
df['col'] = df['col'].astype('int32') – на int32
df['col'] = df['col'].astype('int64') – на int64
df['col'] = pd.to_numeric(df['col1']) – на int64
# Удаление и замена NaN-значений
df.dropna() – удаляет строчки с отсутствующими значениями
df.dropna(axis=1) – удаляет столбцы с отсутствующими значениями
df.fillna('abcd') – меняет NaN на abcd
# Удаление лишних пробелов
df['col'] = df['col'].map(str.strip) – удаляет пробелы слева и справа
# Обработка дат
df['col'] = pd.to_datetime(df['col']) – меняет тип на datetime64[ns]
df['col'].dt.day – вытаскивает из столбца col только значение дня
df['col'].dt.month – только месяц
df['col'].dt.year – только год
# Фильтрация и поиск
df['col'].str.startswith('a') – ищет совпадение по первому символу строки, не поддерживает regex
df['col'].str.endswith('a') – ищет совпадение по последнему символу строки, не поддерживает regex
df['col'].str.match('a') – определяет, начинается ли каждая строка с шаблона
df['col'].str.findall('a') – возвращает совпадения шаблонов
df['col'].str.contains('a') – в результате поиска возвращает булево значение
df['col'].str.extractall('a') – вернет столбец с поисковым шаблоном
df.loc[df['col'].isin(['a', 'b'])] – ищет совпадения в столбцах
# Статистические данные
df.describe() – статистическая сводка по численным значениями
# Подсчет количества повторов
df['col'].value_counts() – показывает сколько раз значения повторяются в столбце
df['col_result'] = df.groupby('col')['col'].transform('count') – создает столбец с количеством повторов значений
Установка pandas
Установим библиотеку pandas в Jupyter Notebook:
!pip install pandas
и импортируем ее:
import pandas as pd
1. Объекты Series и DataFrame
Объект Series – одномерные массив, состоящий из элементов и их индексов:
series_example = pd.Series(['a', 48, 'd', 'hello115'])
series_example
# 0 a
# 1 48
# 2 d
# 3 hello115
# dtype: object
Здесь: 0, 1, 2, 3 – индексы. a, 48, d, hello115 – элементы.
Объект DataFrame – многомерный массив, как таблица в Excel.
df = pd.DataFrame({
'telephone number': [123456789, 123679, 15645445, 564645546],
'name': ['John', 'Jim', 'Kotowski', 'Lebowski'],
})
df
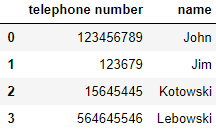
Здесь: telephone number, name – названия столбцов с соответствующими значениями 123456789 ..., John ....
2.Импорт файлов и просмотр содержимого
Импортируем датасет (оригинал) с популярными поисковыми запросами в Google с 2000 по 2020 год. При импорте csv-файла все данные сохраняются в датафрейм df:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
Аналогично есть команды для импорта других файлов: read_excel() – импорт excel-файла.read_sql() – импорт базы данных SQL.read_json() – импорт json-файла.read_html() – создает из HTML-таблицы список объектов DataFrame.
Выведем содержимое датафрейма на экран:
print(df)
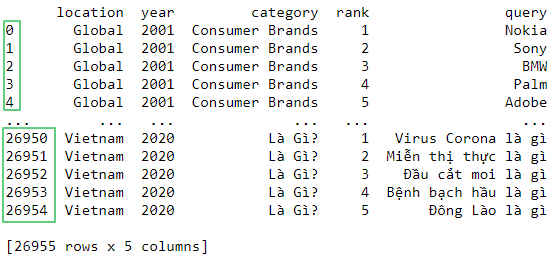
Отображаются первые и последние пять строчек.
Чаще всего значения в датасетах разделяются запятой. Чтобы задать другой разделитель добавим параметр sep="". По умолчанию разделитель между столбцами – запятая.
В нашем случае получаем:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv', sep=",")
df
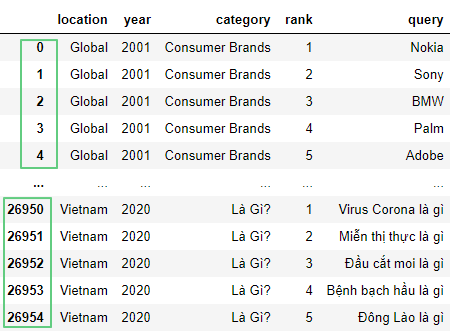
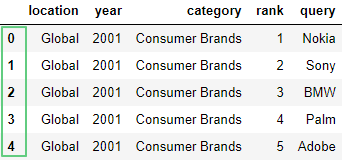
Посмотрим первые пять строчек датафрейма с помощью df.head(5):
df.head(5)
последние 5 строчек:
df.tail(5)
и пять случайных строчек:
df.sample(5)

Узнаем количество строчек и столбцов:
df.shape
# (26955, 5)
Здесь: 26955 – количество строчек. 5 – количество столбцов.
Выведем на экран содержимое датафрейма:
df.info

и использованной памяти:
df.info(memory_usage=True)
Иногда при импорте данных числа принимают тип объект и при обработке данных возникает ошибка. Поэтому проверим какие типы данных находятся в каждом столбце:
df.dtypes

Здесь: object – строчка.int64 – целое число.
Часто встречаемые типы данных:float64 – число с плавающей точкой.datetime64 – дата и время.bool – значения True или False.
Узнаем названия всех столбцов:
df.columns
# Index(['location', 'year', 'category', 'rank', 'query'], dtype='object')
Выведем значения только столбца query:
df['query']

и значения нескольких столбцов:
df[['location', 'category']]
Через срез отобразим первые двадцать значений столбца query:
df['query'][0:20]
В нашем датасете индексы являются числами. Это не очень удобно для понимания, как работает loc и iloc, поэтому создадим небольшой датафрейм с элементами типа object в виде индексов:
df = pd.DataFrame([[1, 2], [3, 4], [5, 6]],
index=['phone', 'telegram', 'letter'],
columns=['max_speed', 'cost'])
df
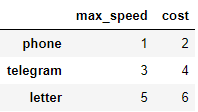
loc выдает строки и/или столбцы по нечисловому значению индекса:
df.loc['phone']

iloc получает строки и/или столбцы по числовому индексу:
df.iloc[0]

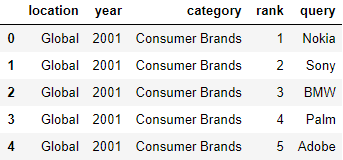
Вернемся к основному датафрейму:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
Выведем первые пять строчек с помощью iloc:
df.iloc[0:5]
Узнаем какой элемент записан в третьей строчке и пятом столбце:
df.iloc[2,4]
# 'BMW'
Выведем значения всех строчек с помощью метода iterrows():
for index, row in df.iterrows():
print(row)
и с помощью iloc():
for i in range(len(df.index)):
print(df.iloc[i])

Отобразим все элементы столбца query:
for index, row in df.iterrows():
print(row['query'])

иначе:
for i in range(len(df.index)):
print(df.iloc[i]['query'])

Выведем строчки со значением Consumer Brands в столбце Сategory:
df.loc[df['category'] == "Consumer Brands"]
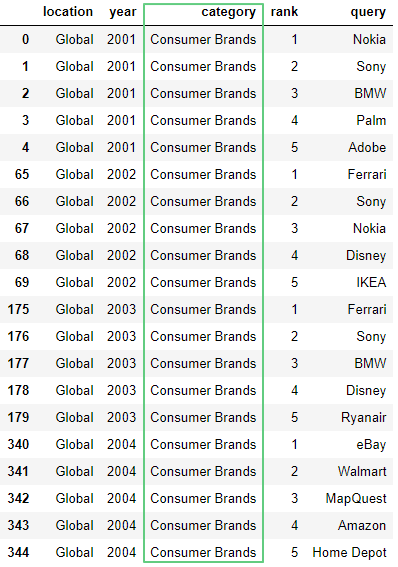
3. Операции над строчками и столбцами
3.1. Объединение датафреймов
Создадим два датафрейма df1 и df2 и добавим столбцы из второго датафрейма в первый с помощью concat(). При этом индексы должны совпадать, иначе мы получим NaN:
df1 = pd.DataFrame([[1, 2], [3, 4], [5, 6]],
index=['phone', 'telegram', 'letter'],
columns=['max_speed', 'cost'])
df2 = pd.DataFrame([[7, 8], [9, 10], [11, 12]],
index=['phone', 'telegram', 'letter'],
columns=['average speed', 'min_speed'])
df1 = pd.concat([df1, df2], axis=1)
df1
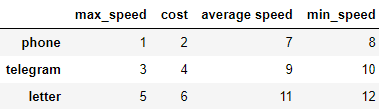
Здесь: df1 и df2 – первый и второй датафрейм соответственно.
Добавим строчки датафрейма df2 к df1. Названия столбцов должны совпадать, иначе получим NaN:
df1 = pd.DataFrame([[1, 2], [3, 4], [5, 6]],
index=['phone', 'telegram', 'letter'],
columns=['max_speed', 'cost'])
df2 = pd.DataFrame([[7, 8], [9, 10], [11, 12]],
index=['smartphone', 'birdmail', 'email'],
columns=['max_speed', 'cost'])
df1 = pd.concat([df1, df2], axis=0)
df1
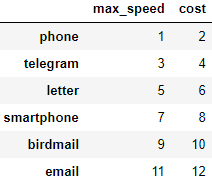
Добавим строчки методом append():
df1 = pd.DataFrame([[1, 2], [3, 4], [5, 6]],
index=['phone', 'telegram', 'letter'],
columns=['max_speed', 'cost'])
df2 = pd.DataFrame([[7, 8], [9, 10], [11, 12]],
index=['smartphone', 'birdmail', 'email'],
columns=['max_speed', 'cost'])
df1 = df1.append(df2)
df1
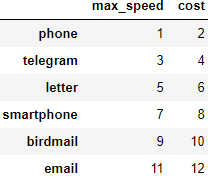
3.2. Добавление строчек и столбцов
Для добавления строчки создадим словарь new_row с названиям столбцов ввиде ключей:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
new_row = {'location': 'Russia', 'year': 2021, 'category': 'Music', 'rank': 1, 'query': 'Artist Name'}
df = df.append(new_row, ignore_index=True)
df.tail(5)
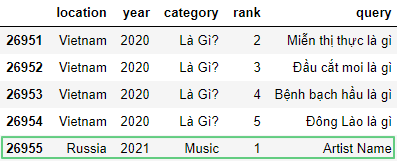
Чтобы добавить строчку в определенную позицию используем метод loc:
df.loc[2] = ['Russia', 2021, 'Music', 1, 'Artist Name']
df.head(5)
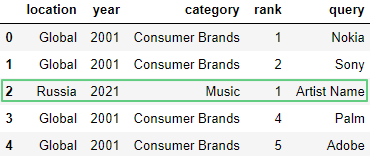
Здесь:loc[2] – вставляем строчку на место третьей строчки.
Следующая запись добавит новый столбец new_column справа и установит все строки на значение new:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df['new_column'] = 'new'
df.tail(5)
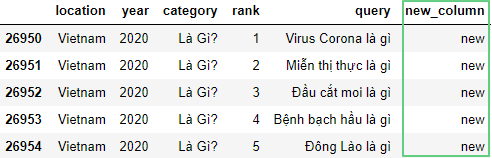
Можно использовать метод insert(), чтобы указать, где должен быть новый столбец. У первого столбца индекс 0:
df.insert(0, 'new_qwerty_column', 'qwerty')
df.head(5)
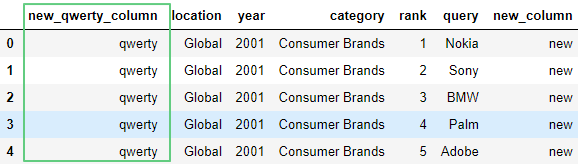
3.3. Удаление строчек и столбцов
Удалим последнюю строчку под номером 26954 c помощью drop():
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df.tail(7)
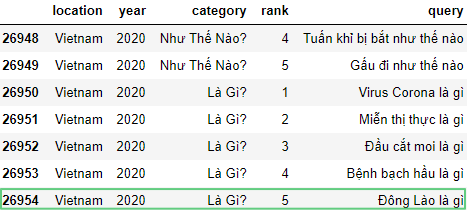
df = df.drop(26954, 0)
df.tail(7)
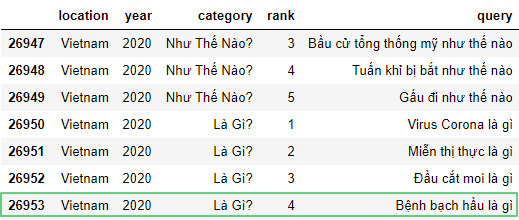
Здесь : year – название столбца 0 – в датафрейме строчка имеет ось = 0, столбец – 1.
Удалим столбец year:
df = df.drop('year', 1)
df.tail(5)
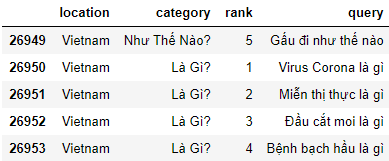
3.4. Переименование столбцов
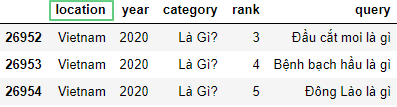
Чтобы переименовать столбец используем rename():
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df.tail(3)
df = df.rename(columns={'location': 'new_location'})
df.tail(3)
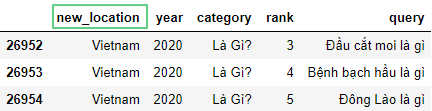
Здесь: location – текущее название столбца.new_location – новое название столбца.
3.5. Замена символов в строке
С помощью replace() заменим в столбце year значения c 2020 на 2021:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df.tail(10)
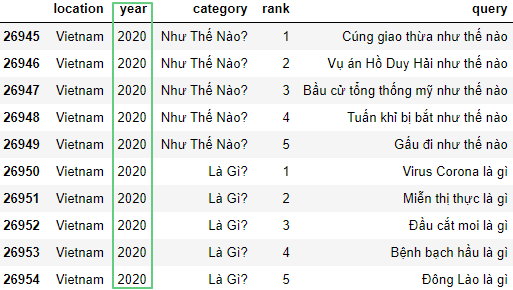
df['year'] = df['year'].replace(to_replace=2020, value=2021)
# сокращенная запись без to_replace и value:
# df['year'] = df['year'].replace(2020, 2021)
df['category'] = df['category'].replace(to_replace='Là Gì?', value='Hello, World.')
df.tail(10)
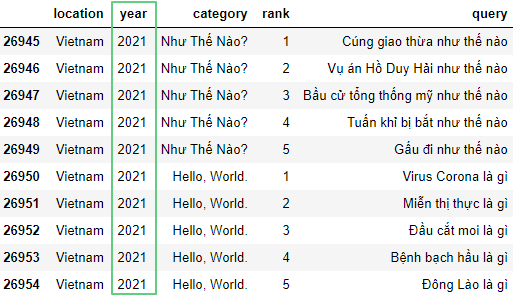
Здесь:replace() – заменяет значения.to_replace=2020– значение, подлежащее замене.value=2021– то, на что меняем.
Метод replace() выполнит замену в результате полного совпадения значения, то есть знак вопроса ? просто так не удалить – нужно писать регулярное выражение (regex). Быстрее воспользоваться методом str.replace(), который выполняет замену подстроки без regex. Заменим знак вопроса обоими методами.
Замена с помощью метода replace() и регулярных выражений:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df['category'] = df['category'].replace(r'[?]', '', regex=True)
df.tail(5)
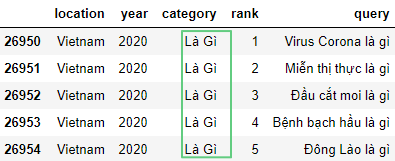
Здесь:r'' – обозначение регулярного выражения.[] – поиск только символа в скобках.? – поиск знака вопроса.
Замена, используя метод str.replace():
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df['category'] = df['category'].str.replace('?', '', regex=False)
df.tail(5)
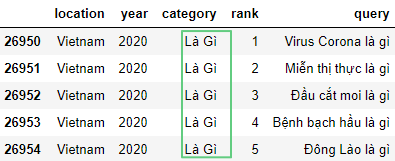
Здесь:regex=False – знак вопроса ? используется в регулярных выражениях, поэтому их нужно отключить, присвоив параметру regex значение False. По умолчанию True.
Также можно заменить значения, используя метод mask():
df['year'] = df['year'].mask(df['year'] == 2001, 2051)
df.head(3)
3.6. Суммирование элементов
Просуммируем элементы в столбце year с помощью sum():
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df['year'].sum()
# 54320885
3.7. Копирование датафрейма
Создадим глубокую копию (изменение в оригинале не влияют на копию и наоборот) датафрейма с помощью copy():
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df2 = df.copy
Здесь:df.copy – создает независимую копию датафрейма. Если нужна зависимая копия, то параметру deep присвоим значение False: df.copy(deep=False). По умолчанию True.
4. Сортировка
Сейчас массив отсортирован по году, давайте отсортируем его по стране (location) в прямом алфавитном порядке с помощью sort_values():
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df.sort_values('location')
и в обратном алфавитном порядке:
df.sort_values('location', ascending=False)
Здесь:ascending=False – сортировка в обратном алфавитном порядке. По умолчанию True.
Отсортируем по двум столбцам: rank и category:
df.sort_values(['rank', 'category'])
В этом случаем приоритет отдается столбцу rank, так как он записан первым.
df.sort_values(['rank', 'category'], ascending=[False, False])
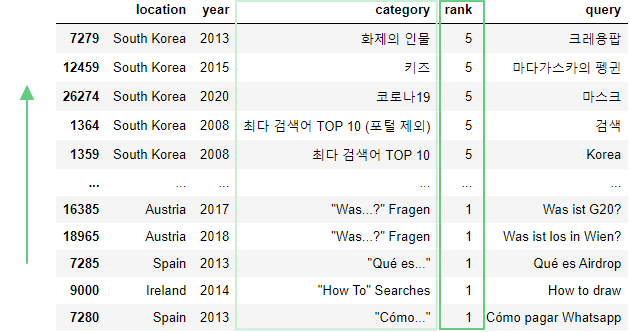
Здесь:ascending=[False, False] – сортировка в обратном порядке по обоим столбцам.
5. Очистка данных.
5.1. Изменение типа данных
Чтобы изменить тип данных воспользуемся методом astype():
f = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df.year.dtype # dtype('int64')
df['year'] = df['year'].astype(str)
df.year.dtype # dtype('O')
df['year'] = df['year'].astype(float)
df.year.dtype # dtype('float64')
df['year'] = df['year'].astype('int32')
df.year.dtype # dtype('int32')
df['year'] = df['year'].astype('int64')
df.year.dtype # dtype('int64')
df['year'] = pd.to_numeric(df['year'])
df.year.dtype # dtype('int64')
Здесь:astype() – меняет тип переменной на строчный Object; на число с плавающей точкой float; на целые числа int32 и int64.to_numeric()– меняет типа переменной наint64.
5.2. Удаление и замена NaN-значений
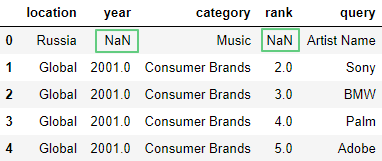
Добавим в начало датафрейма строчку с отсутствующими значениями NaN:
import numpy as np
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df.loc[0] = ['Russia', np.nan, 'Music', np.nan, 'Artist Name']
df = df.append(new_row, ignore_index=True)
df.head(5)
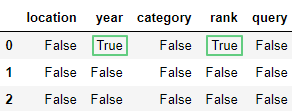
Узнаем, какие элементы имеют значение NaN с помощью метода isnull():
df.isnull().head(3)
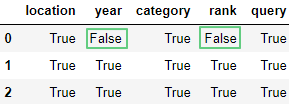
и наоборот методом notnull():
df.notnull().head(3)
Удалим строчки с отсутствующими значениями, используя dropna():
df.dropna().head(3)
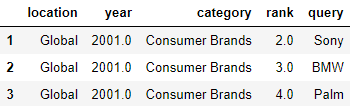
Удалим столбцы с отсутствующими значениями:
df = df.append(new_row, ignore_index=True)
df.dropna(axis=1).head(3)

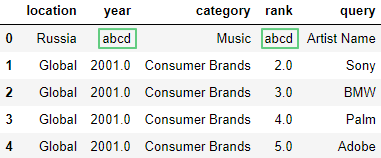
Заменим NaN на abcd методом fillna():
df = df.append(new_row, ignore_index=True)
df.fillna('abcd').head(5)
5.3. Удаление лишних пробелов
Добавим строчку, в которой есть дефектные элементы с лишними пробелами в конце и в начале:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
new_row = {'location': ' Russia ', 'year': 2021, 'category': 'Music', 'rank': 1, 'query': ' Artist Name '}
df = df.append(new_row, ignore_index=True)
print(df.tail(2))

Применим метод strip(), который удаляет символы (по умолчанию – пробел) с левого и правого края строки.
df['location'] = df['location'].map(str.strip)
df['query'] = df['query'].map(str.strip)
print(df.tail(2))

Здесь: map() – применяет к каждому элементу столбцов location и query метод strip().
Напишем цикл, который проходится по всем элементам датафрейма и удаляет у строчек лишние пробелы слева и справа:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
new_row1 = {'location': ' Russia ', 'year': 2021, 'category': 'Music', 'rank': 1, 'query': ' Artist Name '}
new_row2 = {'location': ' Russia ', 'year': 2021, 'category': 'Music ', 'rank': 1, 'query': ' Artist Name '}
df = df.append(new_row1, ignore_index=True)
df = df.append(new_row2, ignore_index=True)
print(df.tail(3))

for column in df.columns:
if df[column].dtype == object:
df[column] = df[column].map(str.strip)
print(df.tail(3))

Здесь:new_row1 и new_row2 – добавляемые строчки. if df[column].dtype == object – проверяем, является ли переменная объектом.
Проверить тип можно также через модуль is_string_dtype:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
new_row1 = {'location': ' Russia ', 'year': 2021, 'category': 'Music', 'rank': 1, 'query': ' Artist Name '}
new_row2 = {'location': ' Russia ', 'year': 2021, 'category': 'Music ', 'rank': 1, 'query': ' Artist Name '}
df = df.append(new_row1, ignore_index=True)
df = df.append(new_row2, ignore_index=True)
print(df.tail(3))

from pandas.api.types import is_string_dtype
for column in df.columns:
if is_string_dtype(df[column].dtype):
df[column] = df[column].map(str.strip)
print(df.tail(3))

Здесь:
is_string_dtype() – проверяет, является ли элемент строкой и возвращает True или False. Проверить на наличие числа можно через is_numeric_dtype().
5.4. Обработка дат
Откроем сокращенный датасет (оригинал) c данными о погоде в Австралии:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/weatherAUS.csv')
df
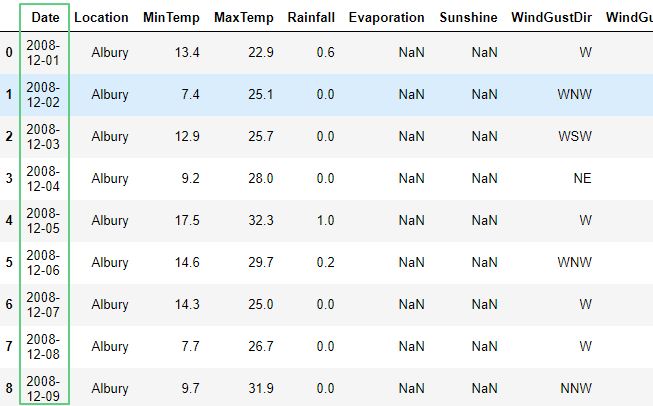
Узнаем типы данных:
df.dtypes
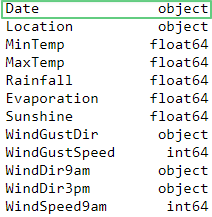
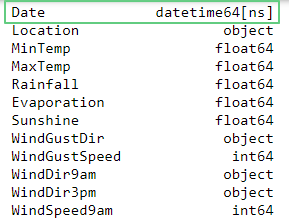
Как видно, элементы столбца Date – строчки. Поменяем их тип на дату методом to_datetime():
df['Date'] = pd.to_datetime(df['Date'])
df.dtypes
Добавим отдельно столбцы год, месяц, день из столбца Date методом DatetimeIndex():
df['Year'] = pd.DatetimeIndex(df['Date']).year
df['Month'] = pd.DatetimeIndex(df['Date']).month
df['Day'] = pd.DatetimeIndex(df['Date']).weekday
df.head(10)
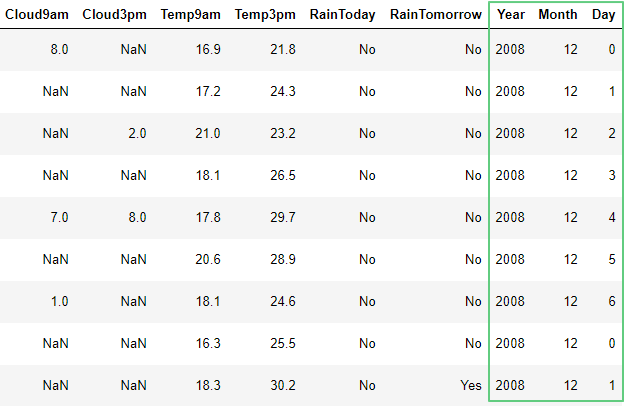
Обратим внимание, что DatetimeIndex.weekday записывает не дату а индексы дней от 0 до 6: понедельник имеет значение 0, воскресенье – 6.
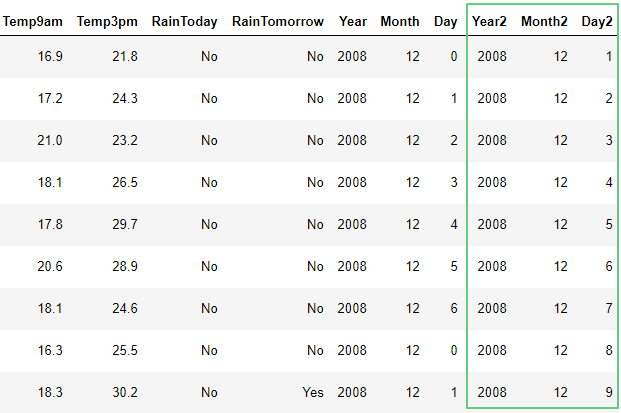
Другой способ записи:
df['Year2'] = df['Date'].dt.year
df['Month2'] = df['Date'].dt.month
df['Day2'] = df['Date'].dt.day
df.head(10)
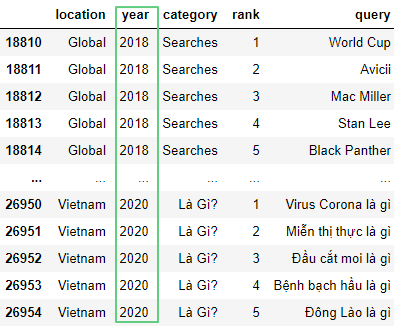
6. Фильтрация и поиск
С помощью оператора сравнения >= получим все поисковые запросы c 2018 года включительно до 2020 года:
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df[df['year'] >= 2018 ]
Более сложные выражения записываются с побитовыми операторами. В данном случае с оператором & (И, AND):
df.loc[(df['year'] >= 2015) & (df['year'] < 2017) & (df['location'] == 'Global')]
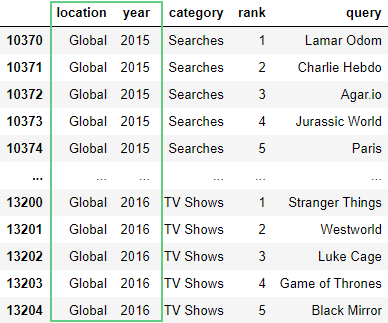
6.1. Метод startswith()
Проверим, совпадает ли начало каждого элемента строки с шаблоном G, используя метод startwith():
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df['location_startswith'] = df['location'].str.startswith('G')
df.head(3)
6.2. Метод endswith()
Метод endswith() проверяет совпадает ли конец каждого элемента строки с шаблоном a:
df['location_endswith'] = df['location'].str.endswith('a')
df.head(3)

Методы startwith() и endswith() не поддерживают регулярные выражения. Для более точного поиска рассмотрим следующие методы.
6.3. Метод match()
Метод match() определяет, начинается ли каждая строка с шаблона, возвращая булево значение. Выведем все запросы о моделях Nokia:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df['query'].str.match('Nokia', case=True)
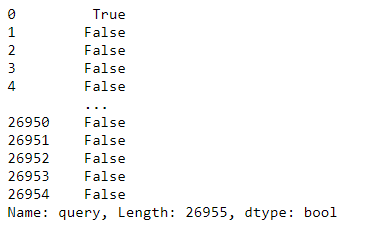
Чтобы вывести больше информации заключим предыдущую запись в df[]:
df[df['query'].str.match('Nokia', case=True)]
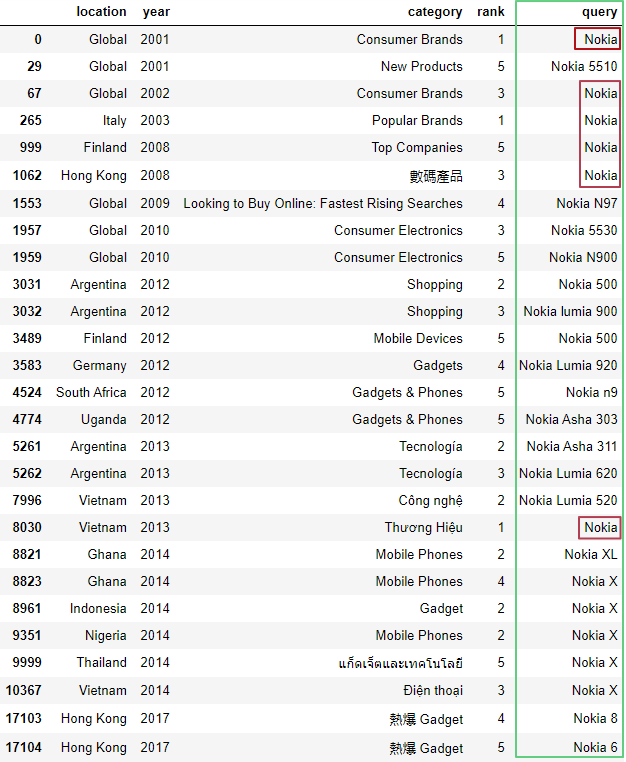
В запросах попадается название компании Nokia без модели, например, Nokia 8. Уточним запрос, воспользовавшись регулярным выражением:
import re
df[df['query'].str.match(r'\b..[k][i][a]\s.', case=True)]
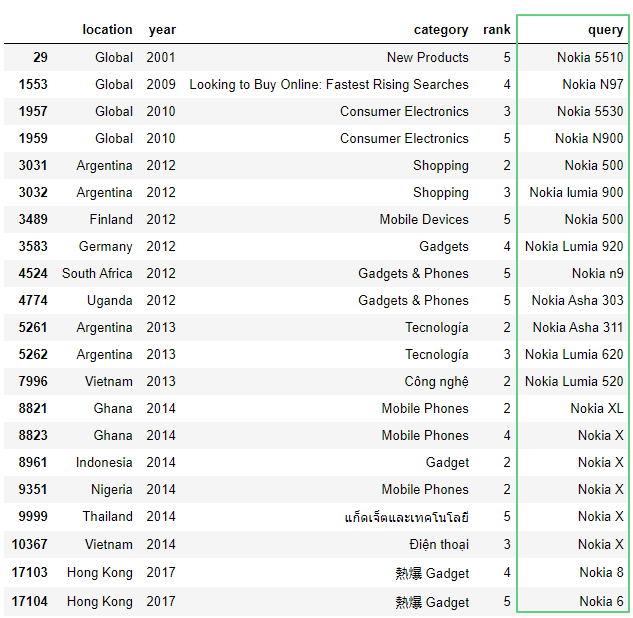
Здесь:import re – импорт библиотеки регулярных выражений.match() – ищет совпадение в начале строки.\b – обозначает границу слова. В нашем случае: слева – ничего, справа – буква.. – любой один символ, кроме символа переноса строки.[k][i][a] – только символы k, i и a соответственно.\s – любой пробельный символ.case=True – чувствителен к регистру.
6.4. Метод findall()
Метод findall возвращает совпадения шаблонов:
df['findall'] = df['query'].str.findall(r'\b..[k][i][a]\s.', flags=re.IGNORECASE).transform(''.join)
df.loc[df['findall'] != '']
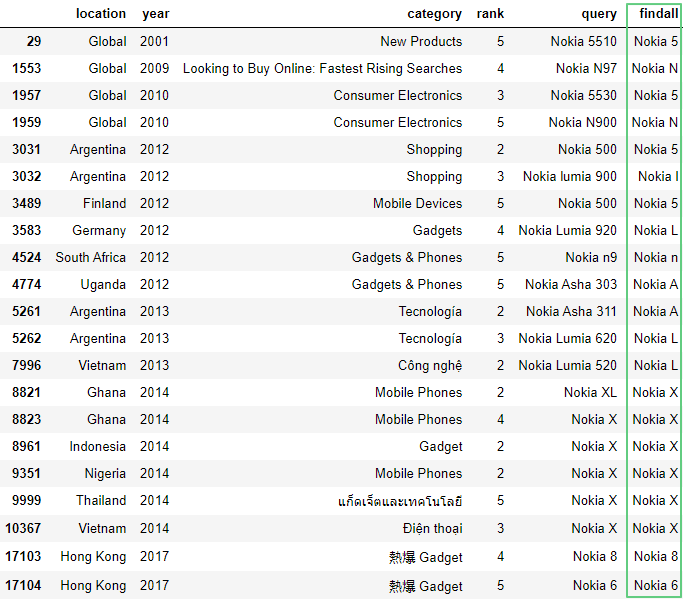
Здесь:df['findall'] != ''] – отбирает все значения, за исключением пустой строчки.flags=re.IGNORECASE – игнорирует регистр при поиске.transform(''.join) – по умолчанию findall() заключает все запросы в квадратные скобки [], что не очень удобно для последующей обработки. Поэтому мы заменили скобки на пустое место ''.
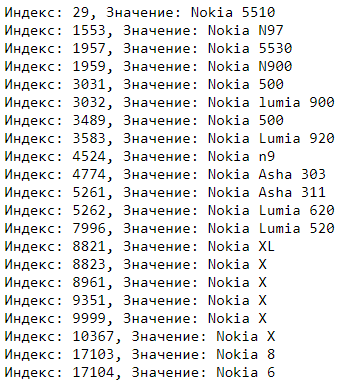
Напишем цикл, который выводит отфильтрованные запросы:
for index, value in df['findall'].items():
if value != '':
print(f"Индекс: {index}, Значение: {df.iloc[index].query}")
6.5. Метод str.contains()
Метод str.contains() в результате поиска возвращает булево значение:
df = pd.read_csv('https://media.githubusercontent.com/media//data/main/trends_saved.csv')
df['query'].str.contains(r'\b..[k][i][a]\s.', regex=True)
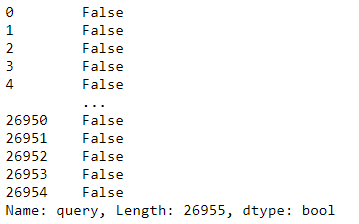
df[df['query'].str.contains(r'\b..[k][i][a]\s.', regex=True)]
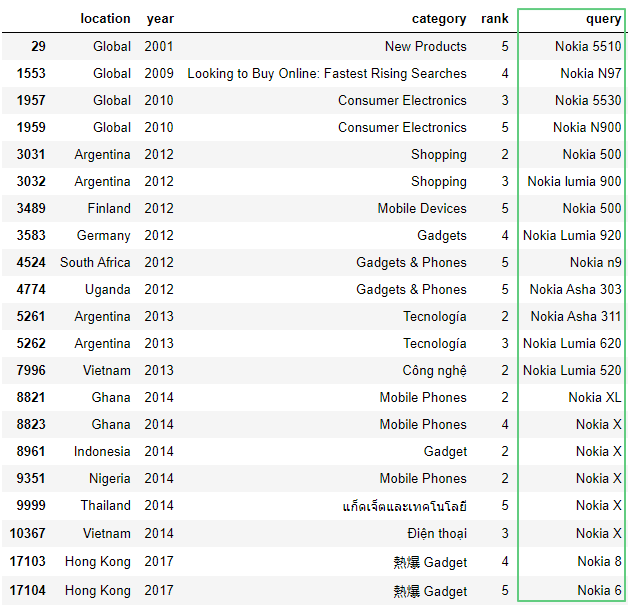
6.6. Метод extractall()
Метод extraclall() вернет столбец с поисковым шаблоном. Результаты, не имеющие совпадений, отображаться не будут:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df['query'].str.extractall(r"(\b..[k][i][a]\s.)")
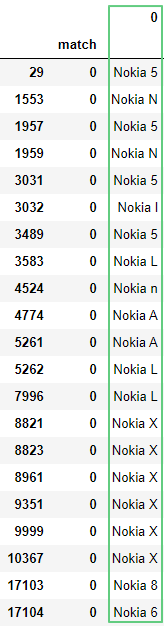
Присвоить название столбцу с результатами можно через следующую запись: ?P<название столбца>.
df['query'].str.extractall(r'(?P<model>\b..[k][i][a]\s.)')
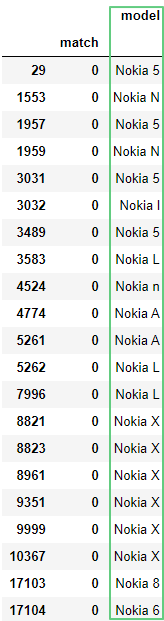
Несколько фильтров в одном запросе:
df['query'].str.extractall(r'(?P<model>\b..[k][i][a]\s.)(?P<number>[5])')
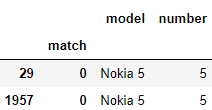
6.7. Метод isin()
Узнаем, содержатся ли искомые значения в столбце методом isin() :
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
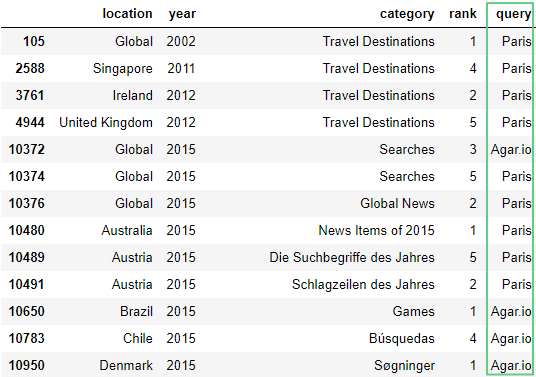
df['query'].isin(['Agar.io', 'Paris'])
df.loc[df['query'].isin(['Agar.io', 'Paris'])]
7. Фильтрация по языку
7.1. Декодер
В датасете могут оказаться кракозябры: ЧЎЧЁЧЧ™Чќ. Для борьбы с ними есть отличная библиотека ftfy (англ. fixes text for you – исправляет текст для тебя), которая также имеет веб-реализацию. Установим ftfy:
!pip install ftfy
from ftfy import fix_encoding
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/decode.csv')
df['decode'] = df['encode'].apply(fix_encoding)
df

Здесь:
apply(fix_encoding) – метод apply() применяет к каждому элементу столбца encode функцию fix_encoding.
7.2. Определение языка
Библиотека google_trans оказалась с багами, поэтому воспользуемся ее работоспособным форком – google_trans_new. Установим google_trans_new:
!pip install requests
!pip install google_trans_new
from google_trans_new import google_translator
import requests
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends_lang.csv')
df['category']= df['category'].apply(fix_encoding)
detector = google_translator()
for index, row in df['category'].items():
try:
df.loc[index, 'category language'] = detector.detect(row)[1]
print(detector.detect(row)[1])
except:
df.loc[index, 'category language'] = 'Error'
print('Error')
Здесь:for index, row ... – цикл по индексу и значению в столбце category.try .... detector.detect(row)[1] – определение языка. 0 – сокращенный вариант en, 1– полный вариант english.except ... 'Error' – если по какой-то причине нам не удастся определить язык, в ячейку запишется значение Error.
df
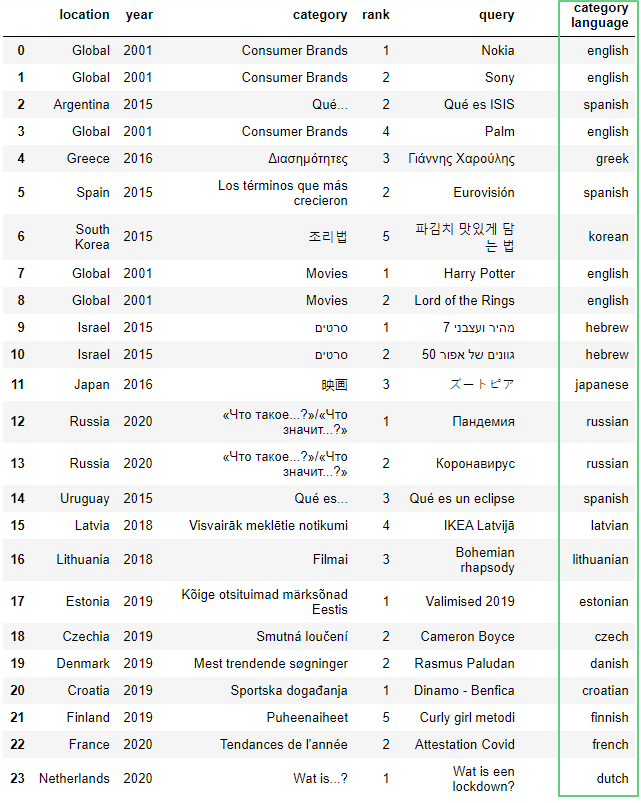
Получим строки, содержащие язык russian:
df.loc[df['category language'] == "russian"]

8. Статистические данные
8.1. Метод describe()
Для просмотра статистической сводки столбцов, содержащих численные значения, введем df.describe().
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df.describe()
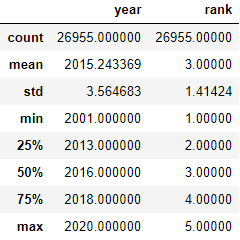
Здесь:count – считает количество записей в столбце без значения NaN. Отдельно можно вызвать через df.count().mean – среднее значение df.mean().std – стандартное отклонение df.std().min – минимальное число в столбце df.min().25% – 25-й процентиль.50%– 50-й процентиль.75%– 75-й процентиль.max – максимальное число в столбцеdf.max().
8.2. Подсчет повторяющихся значений
Подсчитаем количество элементов в столбце query методом count():
df = pd.read_csv('hhttps://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df['query'].count() # 26955
С помощью метода value_counts узнаем сколько раз значения повторяются в столбце:
df['query'].value_counts()

По умолчанию из результата исключаются NaN-значения. Чтобы отобразить их, поставим параметру dropna значение False.
df['query'].value_counts(dropna=False)
Создадим столбец query_count, в который запишем количество упоминаний элемента:
df['query_count'] = df.groupby('query')['query'].transform('count')
df.sample(5)
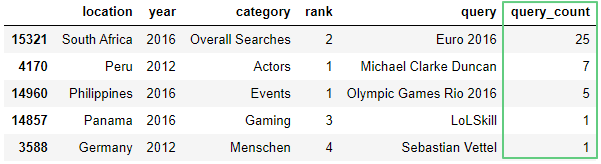
Здесь:groupby() – используется для разделения данных на группы по критериям. Подробнее в документации.transform('count')– считает сколько раз повторяется значение в столбцеquery.
Выведем уникальные значения в столбце location через метод unique():
df['location'].unique()

9. Сохранение датафрейма
Сохраним датафрейм в csv-файл:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
save_file = df[['location', 'year', 'category', 'rank', 'query']]
save_file.to_csv('trends_saved.csv', encoding='utf8')
Здесь:save_file – столбцы датафрейма.to_csv() – сохранить датафрейм в файл формата .csv.
Откроем сохраненный файл:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends_saved.csv')
df.head(3)
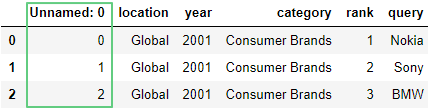
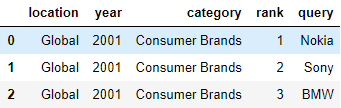
После сохранения файла у нас повявился столбец Unnamed: 0. Он нам не нужен, потому удалим его:
df = df.drop('Unnamed: 0', 1)
df.head(3)
Блокнот Jupyter и шпаргалка
Блокнот и шпаргалка доступны в репозитории Python-Data-Journalism на Гитхабе. Читайте также продолжение статьи.
Мы познакомились с библиотекой pandas и научились:
- делать импорт и экспорт файлов;
- объединять и делать глубокие копии датафреймов;
- проводить базовые операции над строчками и столбцами;
- сортировать данные;
- фильтровать с помощью семи разных методов и регулярных выражений;
- чистить датафрейм от NaN-значений и очищать строчки от лишних пробелов;
- обрабатывать даты;
- декодировать текст и определять его язык;
- получать статистическую сводку.
Комментарии