
Рассказываем, на какие вопросы отвечают на собеседованиях Data Scientists и какие знания стоит освежить перед грядущим интервью.
Зачем использовать Feature selection?
Feature selection (выбор классификационных признаков) – простой и эффективный способ улучшения алгоритмов классификации. Этот метод позволяет при построении модели выбрать только самые показательные признаки (например, слова) и отсеять остальные.
Методы фильтрации
Методы фильтрации основаны на статистических методах и, как правило, рассматривают каждую функцию независимо. Они позволяют оценить и ранжировать функции по значимости, за которую принимается степень корреляции этой функции с целевой переменной.
Встроенные методы
Встроенные методы позволяют не разделять отбор фич и обучение классификатора: они производят отбор внутри процесса расчета модели.
Misleading
Включение избыточных атрибутов может вводить в заблуждение при моделировании алгоритмов. Методы на основе экземпляров, такие как k-ближайший сосед, используют ближайших соседей в пространстве атрибутов для определения прогнозов классификации и регрессии. Эти предсказания могут быть сильно искажены избыточными атрибутами.
Overfitting
Overfitting в машинном обучении – это когда построенная Data Scientist's модель хорошо объясняет примеры из обучающей выборки, но относительно плохо работает на примерах, не участвовавших в обучении (из тестовой выборки).
Связано это с тем, что при построении модели в обучающей выборке обнаруживаются случайные закономерности, которые отсутствуют в общей совокупности.
Даже тогда, когда обученная модель не имеет большого количества параметров, можно ожидать, что эффективность её на новых данных будет ниже, чем на данных, которые использовались для обучения.
Что такое регуляризация и чем она полезна?
Регуляризация – это метод добавления дополнительной информации к условию для решения некорректно поставленных задач или для предотвращения переобучения. Под регуляризацией часто понимается «штраф» за сложность модели. Например, это может быть ограничение гладкости результирующей функции или ограничение по норме векторного пространства. Обычно выделяют L1 и L2 регуляризации.
В чем разница между регуляцией L1 и L2?
Разница между L1 (Lasso) и L2 (Ridge) заключается только в том, что L2 – это сумма квадрата весов, тогда как L1 является просто суммой абсолютных весов в MSE или другой функцией потерь. Таким образом:
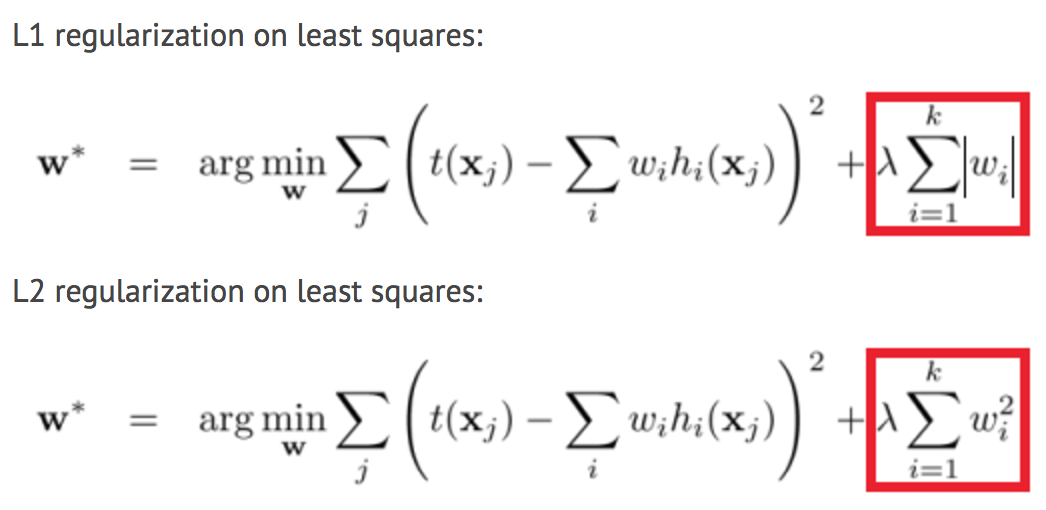
А разницу между их свойствами можно оперативно суммировать:
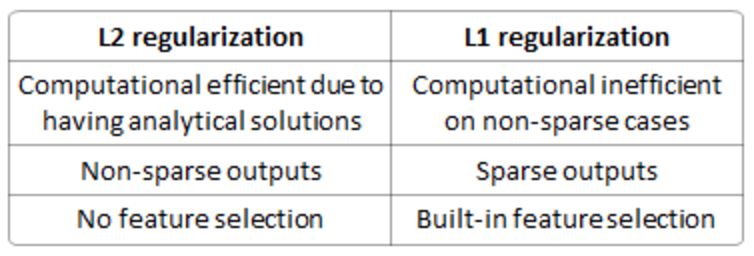
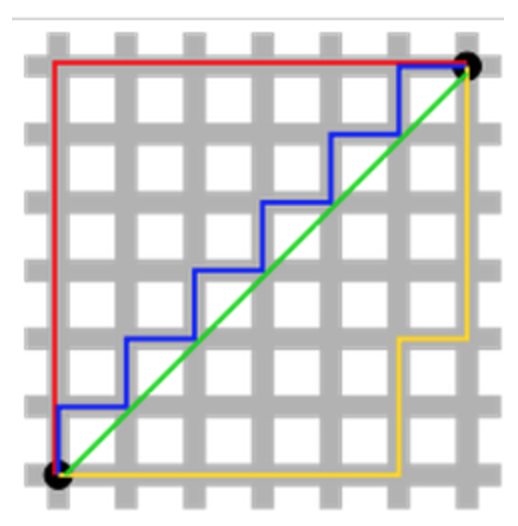
Единственность решения - более простой случай, но требует от Data Scientists немного воображения:
Как проверить модель, созданную для генерации предсказательной модели количественной переменной результата, используя множественную регрессию?
Предлагаемые методы проверки модели:
- Если значения, предсказанные моделью, находятся далеко за пределами диапазона переменных ответа, это указывает на неверную оценку или неточность модели.
- Если значения кажутся разумными, проверим параметры. Любое из следующего будет указывать на плохую оценку или многоколониальность: противоположные признаки ожиданий, необычно большие или малые значения или наблюдаемая несогласованность, при получении моделью новых данных.
- Data Scientists могут использовать модель для прогнозирования, подав новые данные, и применив коэффициент определения (квадрат R) в качестве меры обоснования модели.
- Можно использовать разбиение данных, чтобы сформировать отдельный набор данных для оценки параметров модели, и еще один – для проверки прогнозов.
- Поможет использование Jackknife-передискретизации, если набор данных содержит небольшое количество экземпляров и проверяет достоверность по квадрату R и среднеквадратичной ошибке (MSE).
Что такое precision и recall?
Precision можно интерпретировать как долю объектов, названных классификатором положительными и при этом действительно являющимися положительными, а recall показывает, какую долю положительного класса из всех объектов нашел алгоритм.
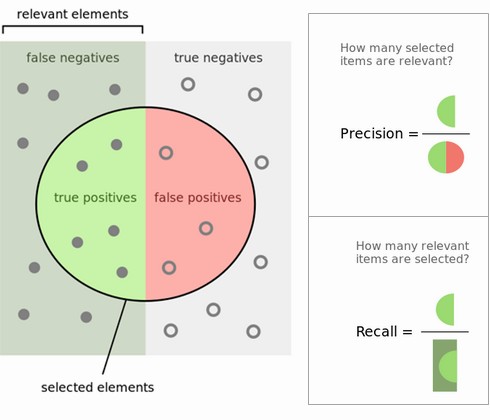
Введение precision не позволяет записывать все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive. Recall демонстрирует способность алгоритма обнаруживать данный класс в принципе, а precision — способность отличать этот класс от других классов.
Лучше ли иметь слишком много false positive или false negative?
Зависит как от вопроса, так и от той области, для которой мы пытаемся решить вопрос.
При медицинском тестировании false negative будет давать ложно обнадеживающее сообщение пациентам и врачам о том, что болезнь отсутствует, когда в действительности она присутствует. Это иногда приводит к неуместному или неадекватному лечению. Таким образом, в этом случае лучше false positive.
Для фильтрации спама false positive возникает, когда фильтры спама или методы блокировки спама ошибочно классифицируют порядочное письмо как спам и, как следствие, препятствуют его прочтению, попаданию во «Входящие». В то время как большинство антиспамовых методов умеют блокировать или фильтровать высокий процент нежелательных писем, делать это, не создавая значительных ложноположительных результатов, будет гораздо более сложной задачей. Таким образом, false negative здесь будет уместней чем false positive.
Что такое статистическая мощность для Data Scientists?
Статистическая мощность в математической статистике — вероятность отклонения основной (или нулевой) гипотезы при проверке статистических гипотез в случае, когда конкурирующая (или альтернативная) гипотеза верна. Чем выше мощность статистического теста, тем меньше вероятность совершить ошибку второго рода. Величина мощности также используется для вычисления размера выборки, необходимой для подтверждения гипотезы с необходимой силой эффекта.

Data Scientists: ошибка первого типа и ошибка второго типа
Что такое смещение и дисперсия, и каковы их отношения в моделировании данных?
Смещение – это то, насколько далеки предсказания модели от правды, а дисперсия – степень, в которой эти предсказания различаются между итерациями модели.
Ошибка из-за смещения: происходит из-за случайности в базовых наборах данных, полученные модели будут иметь ряд прогнозов. Смещение измеряет, насколько прогнозы этих моделей соответствуют правильному значению. Смещение – это ошибка предположений в алгоритме обучения. Высокое смещение может привести к тому, что алгоритм пропустит соответствующие отношения между функциями и целевыми выходами (не обучится должным образом).
Ошибка из-за дисперсии: ошибка из-за дисперсии принимается за изменчивость предсказания модели для данной точки данных. Дисперсия – это ошибка от чувствительности к небольшим колебаниям в тренировочном наборе.
Высокая дисперсия может привести к тому, что алгоритм моделирует случайный шум в данных для обучения, а не предполагаемые выходы (происходит переобучение).
Большой набор данных -> низкая дисперсия
Малый набор данных -> высокая дисперсия
Мало функций -> высокое смещение, низкая дисперсия
Много функции -> низкое смещение, высокая дисперсия
Сложная модель -> низкое смещение
Упрощенная модель -> высокое смещение
Уменьшение λ -> низкое смещение
Увеличение λ -> низкая дисперсия
Что делать, если классы не сбалансированы? Что делать, если групп больше двух?
Двоичная классификация включает классификацию данных в две группы. Например, независимо от того, покупает ли клиент определенный продукт (Да / Нет), модель строится на основе независимых переменных, таких как пол, возраст, местоположение и т. д.
Поскольку целевая переменная не является непрерывной, двоичная модель классификации предсказывает вероятность того, что целевая переменная будет Да / Нет. Для оценки такой модели используется метрика, называемая матрицей путаницы, также называемая классификацией или матрицей совпадений. С помощью матрицы путаницы мы можем вычислить важные показатели эффективности:
- True Positive Rate (TPR) or Recall or Sensitivity = TP / (TP + FN)
- Precision = TP / (TP + FP)
- False Positive Rate(FPR) or False Alarm Rate = 1 - Specificity = 1 - (TN / (TN + FP))
- Accuracy = (TP + TN) / (TP + TN + FP + FN)
- Error Rate = 1 – Accuracy
- F-measure = 2 / ((1 / Precision) + (1 / Recall)) = 2 * (precision * recall) / (precision + recall)
- ROC (Receiver Operating Characteristics) = plot of FPR vs TPR
- AUC (Area Under the Curve)
Какими способами можно сделать модель более устойчивой к выбросам?
Выбросы обычно определяются по отношению к распределению. Они могут быть удалены на этапе предварительной обработки (до любого этапа обучения), с использованием стандартных отклонений (Mean +/- 2*SD). Межквартильные диапазоны Q1 - Q3, Q1 – это «среднее» (Mean) значение в первой половине упорядоченного набора данных, Q3 – это «среднее» значение во второй половине упорядоченного по рангу набора данных. Оно может использоваться для не нормальных/неизвестных, как пороговые уровни.
Более того, преобразование данных (например, преобразование логов) может помочь, если данные имеют заметный хвост. Когда выбросы, связанные с чувствительностью собирающего инструмента, неточно записывают небольшие значения, может быть полезен Winsorization. Этот тип преобразования (названный в честь Чарльза П. Винзора) имеет тот же эффект, что и отсекающие сигналы (то есть заменяет экстремальные значения данных менее экстремальными значениями). Другим вариантом снижения влияния выбросов является использование средней абсолютной разности.
Больше вопросов на собеседованиях Data Scientists.


Комментарии