

Большинство туториалов по парсингу становятся неактуальными через несколько месяцев, так как код сайта меняется и парсер нужно переписывать. Специально для этой публикации на основе датасета Google trends сгенерирована HTML-страница со всеми данными из датасета. Мы научимся создавать HTML-страницу, напишем парсер, соберем всю информацию со странички в датафрейм и проверим, совпадает ли он с оригинальным датафреймом. После этого займемся визуализацией данных с помощью библиотек pandas, matplotlib, plotly, seaborn, bokeh и altair. Ссылку на блокнот Jupyter вы найдете в конце статьи.
1. Генерация HTML-страницы
Для генерации HTML-страницы воспользуемся библиотекой yattag. Установим библиотеки pandas и yattag:
!pip install pandas
!pip install yattag
1.1. Библиотека yattag
Разберемся как библиотека yattag генерирует HTML-код. Если инструкции with записываются последовательно, то теги вкладываются друг в друга:
from yattag import Doc
doc, tag, text = Doc().tagtext()
with tag('h1'):
text('Заголовок первого уровня')
with tag('h2'):
text('Заголовок второго уровня')
print(doc.getvalue())
#<h1>Заголовок первого уровня<h2>Заголовок второго уровня</h2></h1>
Если инструкции with записываются параллельно/на одном уровне, то теги следуют друг за другом:
doc, tag, text = Doc().tagtext()
with tag('h1'):
text('Заголовок первого уровня')
with tag('h2'):
text('Заголовок второго уровня')
print(doc.getvalue())
#<h1>Заголовок первого уровня</h1><h2>Заголовок второго уровня</h2>
Здесь:
tag() – создает тег.text() – создает текстовую запись.h1 и h2 – теги заголовков первого и второго уровня соответственно.doc.getvalue() – выдает результат.
1.2. Структура HTML-страницы
Откроем датафрейм, чтобы узнать названия столбцов, которые станут полями нашей странички:
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
df.head(1)

Нам нужно создать пять полей: location, year, category, rank и query. Стили возьмем из CSS-фреймворка Bootstrap:
<!DOCTYPE html>
<html>
<head>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta3/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-eOJMYsd53ii+scO/bJGFsiCZc+5NDVN2yr8+0RDqr0Ql0h+rP48ckxlpbzKgwra6" crossorigin="anonymous" />
</head>
<body>
<div class="container py-5" id="featured-3">
<h2 class="pb-2 border-bottom">Google trends</h2>
<div class="row g-5 py-5">
<!-- Начало блока. Мы напишем цикл и повторим этот блок со всеми значениями из датафрейма. -->
<div class="feature col-md-4">
<h1 class="display-6">#1 in Global</h1>
<ul class="list-group">
<li class="list-group-item list-group-item-info">Query: Nokia</li>
<li class="list-group-item list-group-item-primary">Category: Consumer Brands</li>
</ul>
<span class="badge bg-primary rounded-pill">2001</span>
</div>
<!-- Конец блока. -->
</div>
</div>
</body>
</html>
Здесь:
<!DOCTYPE html> – указание типа текущего документа, то есть HTML.<html> – контейнер для всего содержимого веб-страницы.<head> – контейнер для заголовка и технической информации. В него мы запишем ссылку на Bootstrap.<link href= /> – ссылка на CSS-файл.<body> – содержит контент веб-страницы. В нашем случае – значения из датафрейма.<h2> – заголовок второго уровня со значением поля rank и location.<li> – два элемента списка: значения столбцов query и category.<span> – строковый контейнер со значением из столбца year.
1.3. Создаем HTML-страницу
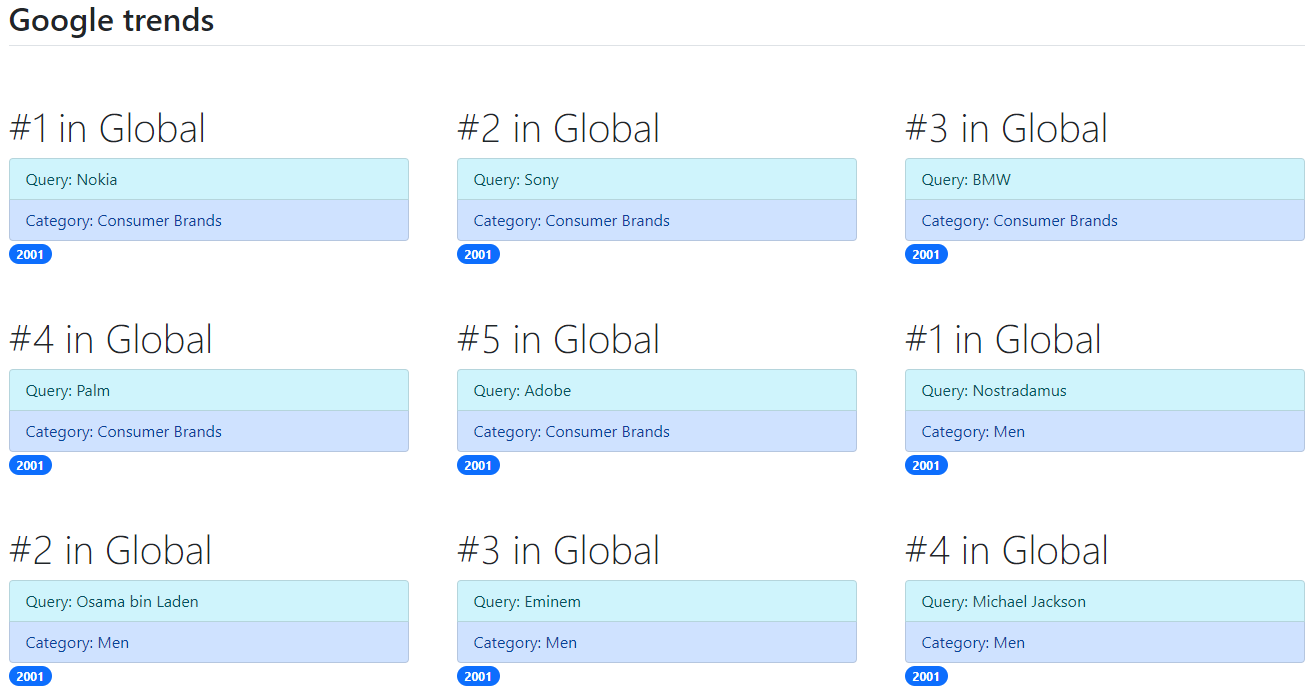
Сгенерируем из датафрейма HTML-страничку:
from yattag import Doc
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part1/trends.csv')
doc, tag, text, line = Doc().ttl()
#объявление типа документа
doc.asis('<!DOCTYPE html>')
#создание тега html
with tag('html'):
#создание тега head
with tag('head'):
doc.stag("link href='https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta3/dist/css/bootstrap.min.css' rel='stylesheet' integrity='sha384-eOJMYsd53ii+scO/bJGFsiCZc+5NDVN2yr8+0RDqr0Ql0h+rP48ckxlpbzKgwra6' crossorigin='anonymous'")
#создание тега body
with tag('body'):
#создание блочного элемента
with tag('div', klass = 'container py-5', id = 'featured-3'):
line('h2', 'Google trends', klass = 'pb-2 border-bottom')
#создание блочного элемента
with tag('div', klass = 'row g-5 py-5'):
#создание блоков с данными из столбцов датафрейма
for i in range(len(df.index)):
with tag('div', klass = 'feature col-md-4'):
# создание тега со значениями rank и location
elements = ['#', df['rank'][i].astype(str), ' in ', df['location'][i]]
rank_and_location_line = ''.join(elements)
line('h1', rank_and_location_line, klass = 'display-6')
# создание маркированного списка со значениями query и category
with tag('ul', klass = 'list-group'):
query_line = 'Query: ' + df['query'][i]
category_line = 'Category: ' + df['category'][i]
line('li', query_line, klass='list-group-item list-group-item-info')
line('li', category_line, klass = 'list-group-item list-group-item-primary')
# создание тега со значением year
with tag('span', klass = 'badge bg-primary rounded-pill'):
text(df['year'][i].astype(str))
# создание файла googletrends.html, запись в него HTML-кода, сохранение изменений
with open('googletrends.html', 'w', encoding='utf-8') as file:
file.write(doc.getvalue())
Сгенерированная страничка доступна на Гитхабе.
Здесь:
doc.asis() – метод asis() не экранирует символы, без него мы получим <<!DOCTYPE html> />.tag(html) – создает тег <html></html>.doc.stag("link href=...") – создает самозакрывающийся тег <link href= ... />.line('h2') – создает тег <h2></h2> после инструкции with tag():.klass = '' – класс CSS. Классы берутся из Bootstrap.for i in range(len(df.index)) – цикл, создающий HTML-блоки с содержимым из датафрейма.rank_and_location_line, query_line, category_line – создают строчки со значениями из столбцов датафрейма rank, location, query, category.df['rank'][i].astype(str) – тип переменной меняется с числового на строчный для конкатенации с другими строчками.with open("googletrends.html", "w", encoding='utf-8') – создает файл googletrends.html и записывает в него в режиме w HTML-код. Кодировка utf-8, чтобы избежать ошибки UnicodeEncodeError.
Теперь напишем парсер для этой странички.
2. Пишем парсер
2.1. Библиотека BeautifulSoup

Для получения HTML-кода воспользуемся библиотекой requests, а для парсинга разметки HTML библиотекой beautifulsoup4.
Установим библиотеки:
!pip install beautifulsoup4
!pip install requests
Напишем парсер:
from bs4 import BeautifulSoup
import requests
r = requests.get('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/html/googletrends.html')
soup = BeautifulSoup(r.text, 'html.parser')
year_parsed = soup.find_all('span', {'class': 'rounded-pill'})
category_parsed = soup.find_all('li', {'class': 'list-group-item-primary'})
rank_and_location_parsed = soup.find_all('h1')
query_parsed = soup.find_all('li', {'class': 'list-group-item-info'})
locations = []
years = []
categories = []
ranks = []
queries = []
for a, b, c, d in zip(rank_and_location_parsed, year_parsed, category_parsed, query_parsed):
locations.append(a.getText()[6:])
years.append(b.getText())
categories.append(c.getText()[10:])
ranks.append(a.getText()[1])
queries.append(d.getText()[7:])
Здесь:
r = requests.get() – отправляет GET-запрос сгенерированной в предыдущей главе веб-странице и извлекает из нее код. soup = BeautifulSoup(r.text, 'html.parser') – создает объект BeautifulSoup из полученных данных. С помощью этого объекта можно найти разные элементы страницы. Например, содержимое тега <head> через soup.head и так далее.soup.find_all('span', {'class': 'rounded-pill'}) – метод find_all ищет содержимое в указанном теге с заданным классом и возвращает все совпадения в виде списка. В нашем случае – содержимое в теге span, который имеет класс rounded-pill.
locations, years, categories, ranks, queries – списки, в которые добавляются соответствующее содержимое тегов.
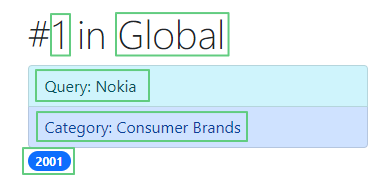
Значение rank и location находятся на одной строчке. Мы точно знаем, что rank – всегда второй символ, а location – все символы, начиная с седьмого. Воспользуемся индексами и срезами, чтобы получить нужные значения из строчки: [1] для rank и [6:] для location. Значения query и category так же получаем через срезы, а year берем как есть.
Cоздадим пустой датафрейм со столбцами locations, years, categories, ranks, queries:
df = pd.DataFrame(columns=['location','year','category','rank','query'])
df

и заполним столбцы значениями из соответствующих списков:
df = pd.DataFrame({'location': locations,'year': years,'category': categories,'rank': ranks,'query': queries})
df
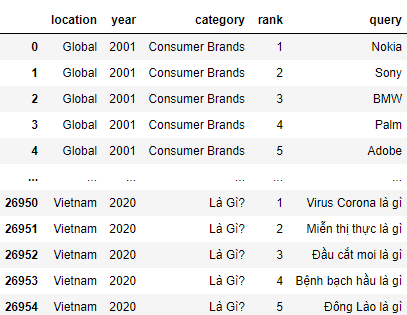
Узнаем количество строк и столбцов:
df.shape
# (26955, 5)
и типы данных в столбцах:
df.dtypes
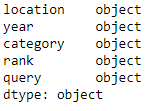
Значения в столбцах year и rank имеют тип object, а должны иметь тип целое число int. Изменим их тип на int64, как в оригинальном датасете:
df['year'] = df['year'].astype('int64')
df['rank'] = df['rank'].astype('int64')
df.dtypes

Сравним полученный нами датасет с оригинальным методом equals():
df_original = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/trends_original.csv')
df.equals(df_original)
# True
Мы получили True – датасеты совпадают. Переходим к визуализации данных.
3. Визуализация данных
3.1. Библиотека Pandas
В библиотеке pandas есть встроенные методы визуализации данных. Они не такие продвинутые как в matplotlib и других библиотеках, но тоже могут пригодиться.
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/trends_original.csv')
def highlight_max(v):
is_max = v == v.max()
return ['background-color: yellow' if x else '' for x in is_max]
def highlight_min(v):
is_max = v == v.min()
return ['background-color: green' if x else '' for x in is_max]
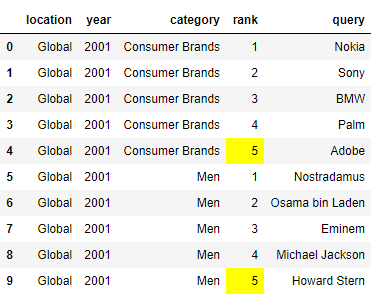
Выделим цветом максимальные значения в столбце rank:
df[:10].style.apply(highlight_max, subset=['rank'])
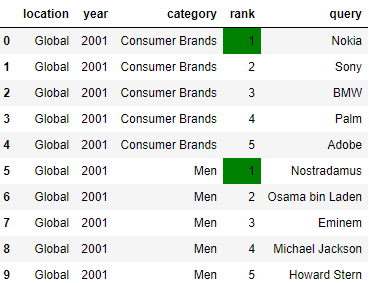
и минимальные значения:
df[:10].style.apply(highlight_min, subset=['rank'])
Здесь:
highlight_max, highlight_min – функции, принимающие значение из столбца rank. Если значение максимальное, то ячейка выделяется желтым цветом. В противном случае цвет не меняется.df.style.apply() – изменяет визуальное оформление значений в столбце/строке/всей таблице.
df[:10].style.bar(subset=['rank'], color='#d65f5f')
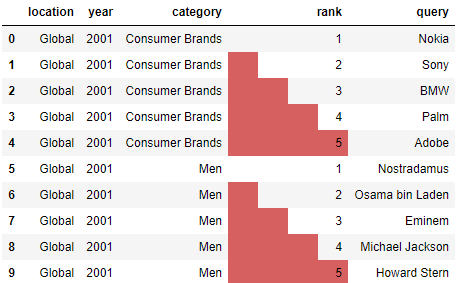
Здесь:
df.style.bar() – создает столбиковую диаграмму.
3.2. Библиотека Matplotlib
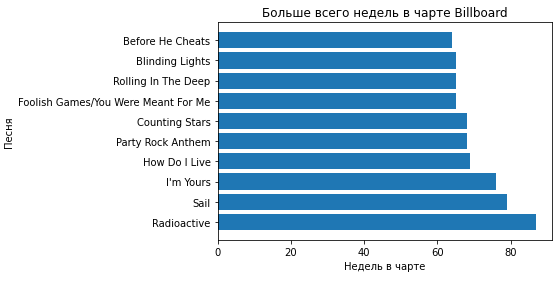
Библиотеке matplotlib больше десяти лет и она до сих пор развивается. Построим с ее помощью столбиковую диаграмму, на которой отобразим ТОП-10 песен, продержавшихся в чарте The Billboard Hot 100 максимальное количество недель. Оригинал датасета доступен здесь.
Установим matplotlib:
!pip install matplotlib
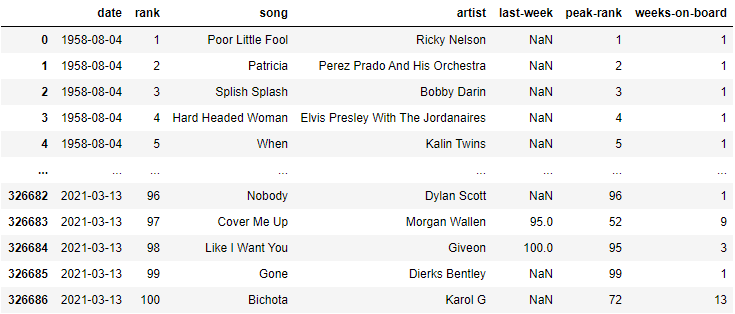
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/charts.csv')
df
Создадим датафрейм df_wob и запишем в него ТОП-10 песен с максимальным значением weeks-on-board (количество недель в чарте):
df_wob = df.nlargest(80, ['weeks-on-board']).drop_duplicates(subset=['song']).copy()
df_wob
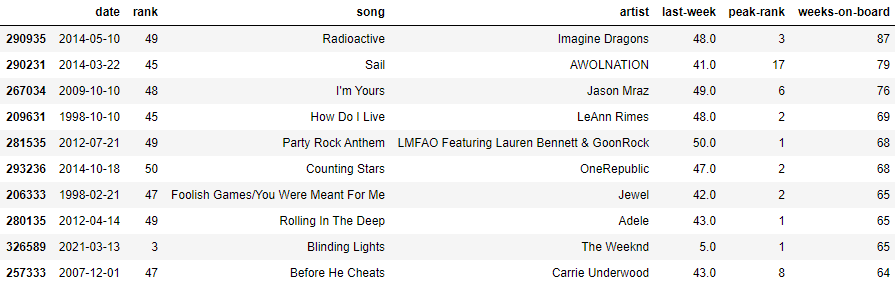
Здесь:
nlargest(80, ['weeks-on-board']) – возвращает 80 максимальных значений в столбце weeks-on-board.
drop_duplicates(subset=['song']) – убирает все дубликаты в столбце song.
import numpy as np
import matplotlib.pyplot as plt
song = list(df_wob['song'])
weeks_on_board = list(df_wob['weeks-on-board'])
fig, ax = plt.subplots()
ax.set(xlabel='Недель в чарте', ylabel='Песня',
title='Больше всего недель в чарте Billboard')
ax.barh(song, weeks_on_board)
Здесь:
list(df_wob['song']) – создает список из элементов столбца song.
list(df_wob['weeks-on-board']) – создает список из элементов столбца weeks-on-board.
fig – создает контейнер для визуальных объектов.ax – объявляет визуальные объекты.xlabel, ylabel, title – метки на осях x, y и название диаграммы соответственно.barh(song, weeks_on_board) – создает диаграмму со значениями из столбцов song и weeks_on_board.
3.3. Библиотека Plotly
Установим библиотеку Plotly:
!pip install plotly
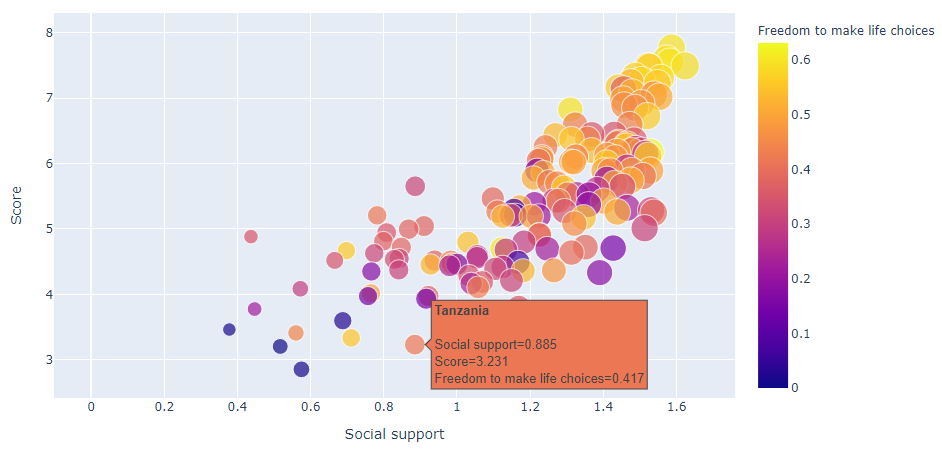
На основе датасета «Отчет по уровню счастья в мире» (оригинал) построим график зависимости уровня счастья в разных странах от качества социальной поддержки.
import plotly.express as px
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/happiness_2019.csv')
fig = px.scatter(df, x="Social support", y="Score", color="Freedom to make life choices", hover_name="Country or region", size="Social support")
fig.show()
Здесь:
px – модуль plotly.express является частью библиотеки plotly. Он ускоряет создание графиков за счет своего лаконичного синтаксиса.scatter() – инициирует создание пузырьковой диаграммы.x='', y='' – значения по оси x, и y соответственно.color – добавляет градацию по цвету в зависимости от значения Freedom to make life choices.hover_name – добавляет всплывающее окно при наведении на метку.size – задает размер круга в зависимости от значения Social support.
Размер круга определяется величиной социальной поддержки. Цветом выделен уровень свободы в принятии решений: желтый цвет – максимум свободы. В лидерах Финляндия, Дания, Норвегия и Исландия.
3.4. Библиотека Seaborn
Seaborn – обертка над библиотекой matplotlib. Она представляет высокоуровневый интерфейс для рисования красивых и информативных графиков.
Установим библиотеку seaborn:
!pip install seaborn
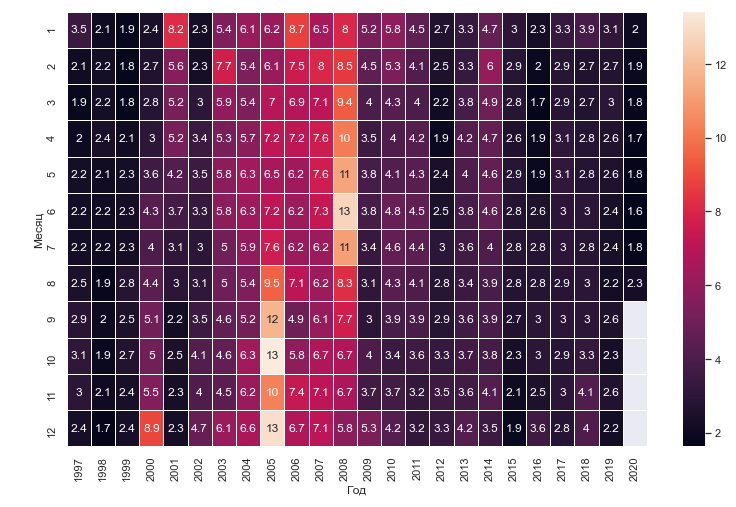
Построим тепловую карту цен на газ в зависимости от года и месяца. На тепловой карте значения выделяются цветом, но мы так же подключим численное отображение:
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/gas_monthly.csv')
df
Посмотрим какие у нас типы в столбцах:
df.dtypes

Столбец Month имеет тип object. Чтобы получить значения года и месяца преобразуем его тип в datetime:
df['Month'] = pd.to_datetime(df['Month'])
df.dtypes

Создадим из столбца Month отдельные столбцы с годом Год и месяцем Месяц:
df['Год'] = df['Month'].dt.year
df['Месяц'] = df['Month'].dt.month
df
Нарисуем тепловую карту:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme()
Gas_price = df.pivot("Месяц", "Год", "Price")
f = plt.subplots(figsize=(13, 8))
sns.heatmap(Gas_price, annot=True, linewidths=.5)
Здесь:
set_theme() – устанавливает стиль диаграмм.
df.pivot() – создает сводную таблицу.
figsize=(x, y) – задает размеры ячейки: x – ширина, y – высота.
heatmap() – создает тепловую карту.
annot=True – добавляет численные значения к каждой ячейке.
linewidths – задает толщину разделительных линий.
3.5. Библиотека Bokeh
Библиотека Bokeh помогает создавать графику, начиная с простых графиков и заканчивая сложными инструментальными панелями с большими наборами данных.
Установим библиотеку Bokeh:
!pip install bokeh
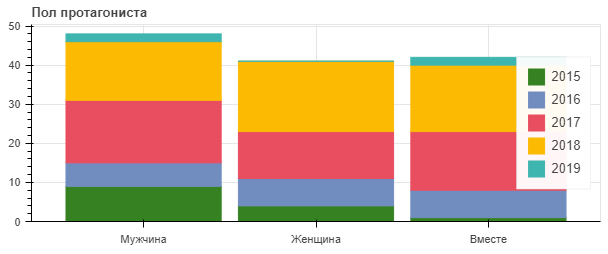
Построим диаграммы по гендерному распределению главных ролей в фильмах и сериалах Netflix за последние пять лет. За основу возьмем датасет «Оригинальный датасет Нетфликса».
df = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/netflix_original_content_dataset.csv')
df
Нарисуем график:
from bokeh.io import show, output_notebook, reset_output
from bokeh.plotting import figure
#reset_output()
output_notebook()
sex = ['Мужчина', 'Женщина', 'Вместе']
years = ["2015", "2016", "2017", "2018", "2019"]
colors = ["#368223", "#718dbf", "#e84d60", "#fcba03", "#3fb5af"]
data = {'sex' : sex,
'2015' : [df.loc[(df['Year Released'] == 2015) & (df['Main Actor'] == 'Male')]['Main Actor'].count(),
df.loc[(df['Year Released'] == 2015) & (df['Main Actor'] == 'Female')]['Main Actor'].count(),
df.loc[(df['Year Released'] == 2015) & (df['Main Actor'] == 'Both')]['Main Actor'].count()],
'2016' : [df.loc[(df['Year Released'] == 2016) & (df['Main Actor'] == 'Male')]['Main Actor'].count(),
df.loc[(df['Year Released'] == 2016) & (df['Main Actor'] == 'Female')]['Main Actor'].count(),
df.loc[(df['Year Released'] == 2016) & (df['Main Actor'] == 'Both')]['Main Actor'].count()],
'2017' : [df.loc[(df['Year Released'] == 2017) & (df['Main Actor'] == 'Male')]['Main Actor'].count(),
df.loc[(df['Year Released'] == 2017) & (df['Main Actor'] == 'Female')]['Main Actor'].count(),
df.loc[(df['Year Released'] == 2017) & (df['Main Actor'] == 'Both')]['Main Actor'].count()],
'2018' : [df.loc[(df['Year Released'] == 2018) & (df['Main Actor'] == 'Male')]['Main Actor'].count(),
df.loc[(df['Year Released'] == 2018) & (df['Main Actor'] == 'Female')]['Main Actor'].count(),
df.loc[(df['Year Released'] == 2018) & (df['Main Actor'] == 'Both')]['Main Actor'].count()],
'2019' : [df.loc[(df['Year Released'] == 2019) & (df['Main Actor'] == 'Male')]['Main Actor'].count(),
df.loc[(df['Year Released'] == 2019) & (df['Main Actor'] == 'Female')]['Main Actor'].count(),
df.loc[(df['Year Released'] == 2019) & (df['Main Actor'] == 'Both')]['Main Actor'].count()]}
p = figure(x_range=sex, plot_height=250, title="Пол протагониста",
toolbar_location=None, tools="hover", tooltips="$name год, @sex: @$name")
p.vbar_stack(years, x='sex', width=0.9, color=colors, source=data,
legend_label=years)
p.y_range.start = 0
p.x_range.range_padding = 0.1
p.legend.location = "right"
p.legend.orientation = "vertical"
show(p)
Здесь:
sex – пол протагониста: мужской, женский, вместе (главные герои мужчина и женщина).data – словарь со значением пола, и количеством протагонистов у каждого пола с 2015 по 2019 годы .df.loc[(df['Year Released'] == 2017) & (df['Main Actor'] == 'Male')]['Main Actor'].count() – фильтрация датасета по 2017 году и мужскому полу; count() – подсчет сколько раз мужчины были протагонистами.x_range – определяет значение метки деления.toolbar_location=None – скрывает панель инструментов.tools="hover" – включает подсказку при наведении на диаграмму.tooltips="" – данные подсказки.vbar_stack() – генерирует снизу наверх несколько уровней/контейнеров в диаграмме.y_range.start – определяет с какого уровня по оси y строить диаграмму.x_range.range_padding – задает начальное смещение диаграмм вправо по оси x.legend.locationс и legend.orientation – определяют место и ориентацию описания диаграмм соответственно.
3.6. Библиотека Altair
Altair – это библиотека визуализации для Python, основанная на инструментах визуализации Vega и Vega-Lite.
Установим Altair:
!pip install altair
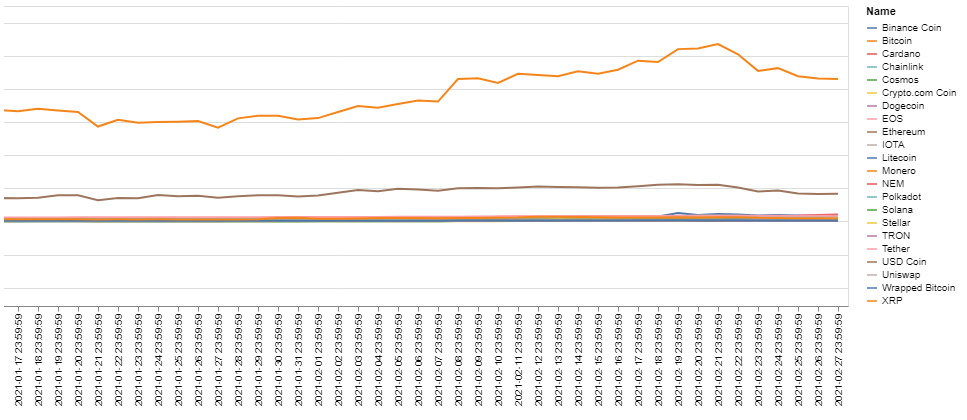
Построим графики изменения цен криптовалют за последние семь лет. Импортируем датасеты (оригиналы):
df1 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Aave.csv')
df2 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_BinanceCoin.csv')
df3 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Bitcoin.csv')
df4 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Cardano.csv')
df5 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_ChainLink.csv')
df6 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Cosmos.csv')
df7 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_CryptocomCoin.csv')
df8 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Dogecoin.csv')
df9 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_EOS.csv')
df10 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Ethereum.csv')
df11 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Iota.csv')
df12 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Litecoin.csv')
df13 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Monero.csv')
df14 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_NEM.csv')
df15 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Polkadot.csv')
df16 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Solana.csv')
df17 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Stellar.csv')
df18 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Tether.csv')
df19 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Tron.csv')
df20 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_USDCoin.csv')
df21 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_Uniswap.csv')
df22 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_WrappedBitcoin.csv')
df23 = pd.read_csv('https://raw.githubusercontent.com/tttdddnet/Python-Data-Journalism/main/part2/data/coin_XRP.csv')
Объединим датафреймы:
df1 = pd.DataFrame()
df1 = pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9, df10, df11, df12,
df13, df14, df15, df16, df17, df18, df19, df20, df21, df22, df23], axis=0)
Здесь:
concat([df1, df2, ... ], axis=0) – метод concat() добавляет к датафрейму df1 строчки из других датафреймов.
MaxRowsError: The number of rows in your dataset is greater than the maximum allowed (5000). For information on how to plot larger datasets in Altair, see the documentation.У нас получилось 33969 строк. По умолчанию altair визуализирует датасеты максимум с 5000 строк. Чтобы обойти это ограничение добавим следующую запись в код: alt.data_transformers.disable_max_rows().Нарисуем графики:
import altair as alt
alt.data_transformers.disable_max_rows()
alt.Chart(df1).mark_line().encode(
x='Date',
y='Marketcap',
color='Name',
).interactive()
Здесь:
Chart(df1).mark_line() – создает график из линий на основе датасета df1. Если поставить mark_circle(), то график строится из кружков. Больше вариантов в документации.
x='Date' и y='Marketcap' – значения на осях x и y из столбоцов Date и Markercap соответственно.interactive() – добавляет возможность передвигать графики курсором мыши и изменять масштаб колесиком мыши.
Блокнот Jupyter
Блокнот лежит на Гитхабе. Первая часть цикла доступна по ссылке.
Мы научились:
- генерировать из датафрейма HTML-страницу;
- парсить данные с веб-страницы;
- визуализировать данные с помощью библиотек
pandas,matplotlib,plotly,seaborn,bokehиaltair.
Надеемся, полученные знания помогут вам в проведении журналистских исследований.
Комментарии