

Искусственный интеллект – одно из самых удивительных и многообещающих направлений в ИТ: новые AI-приложения выходят каждый день, а решение многих сложных задач с помощью ИИ стало привычным делом. Для рядовых пользователей ИИ-эпоха стартовала вместе с открытием публичного доступа к сенсационным ChatGPT и Midjourney, однако на самом деле все началось гораздо раньше.
Античность
Первые мечты о мыслящих машинах появились еще в античности – у древних греков, к примеру, был миф о Талосе, гигантском бронзовом автоматоне (роботе), а первые попытки создания таких роботов начались за несколько веков до нашей эры.
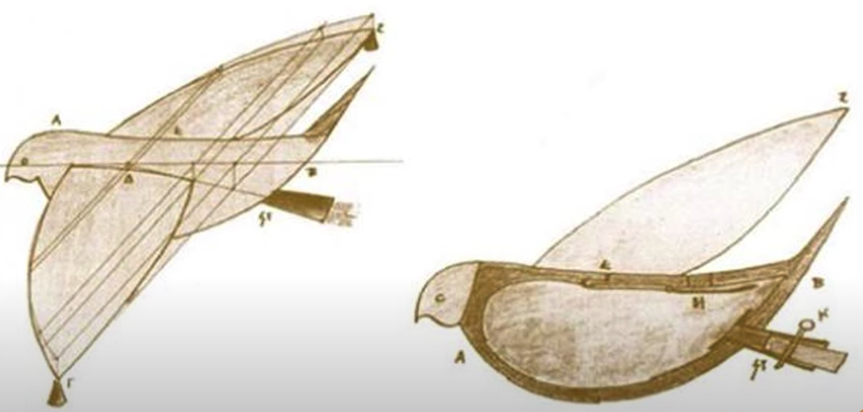
Архит Тарентский примерно в 400 году до н.э. изобрел механического деревянного голубя на паровой тяге.
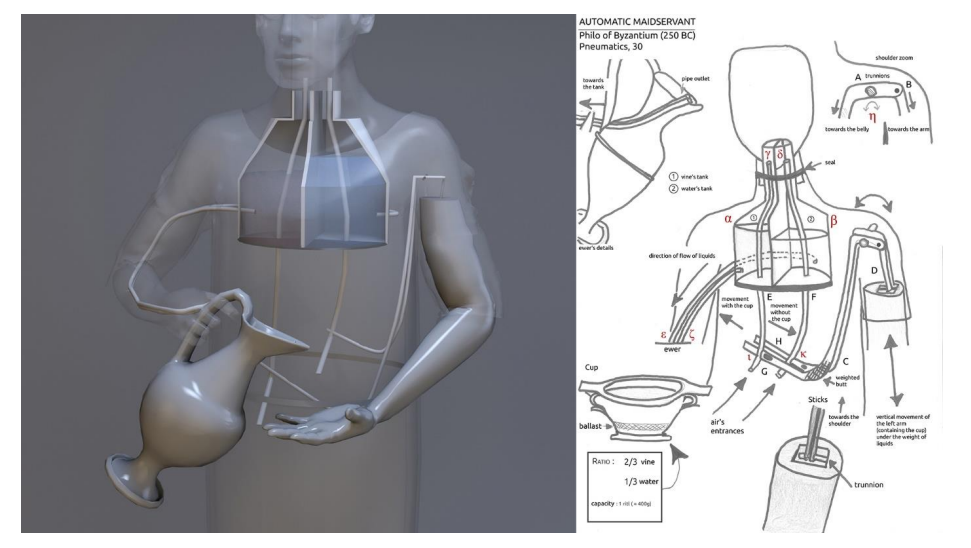
Филон Византийский приблизительно в 250 году до н.э. создал служанку-автоматон для смешивания вина с водой в нужных пропорциях.
Ко II веку до н.э. античные ученые уже вовсю конструировали механические вычислительные устройства.

Средневековье и Ренессанс
В Средние века и в эпоху Возрождения в Европе, Китае и Японии создавались сложнейшие механические автоматоны. Однако, несмотря на максимально изощренную для своего времени механику, действовать спонтанно они не могли, и выполняли только заранее продуманные функции.

17 и 18 века
Философы начали рассматривать мышление как механический процесс, а математики задумались о создании логической системы, способной отображать мыслительную деятельность. В начале 18-го века Готфрид Лейбниц абстрактно описал такую концепцию и назвал ее «азбукой мысли».
Азбука мысли должна была представлять собой универсальный пиктографический язык, в котором грамматическая и логическая структура совпадают: это позволило бы свести рассуждения к вычислениям. Источником вдохновения для этой идеи Лейбниц называл работы Раймунда Луллия, в частности книгу Ars generalis ultima, опубликованную в 1305 году. С современной точки зрения такой алфавит можно назвать онтологическим классификатором или автоматическим доказателем теорем, задуманными за несколько веков до появления технологий, на основе которых их можно было бы реализовать.

В 1750-х годах Жюльен Оффре де Ла Метри опубликовал книгу «Человек-машина», где утверждал, что мышление – это механический процесс. Идея о том, что человеческая мысль – продукт физической деятельности мозга, а не порождение эфемерной души, стала важной вехой на пути к искусственному интеллекту: если человеческий ум – продукт работы биологической машины, вероятно, могут существовать и механические мыслящие машины.

Мы запустили еженедельную email-рассылку, посвященную последним новостям и тенденциям в мире искусственного интеллекта. Наша цель – держать подписчиков в курсе самых интересных открытий, исследований и приложений ИИ.
🤖 В рассылке вы найдете:
- Новости о прорывных исследованиях в области машинного обучения и нейросетей.
- Материалы о применении ИИ в разных сферах – медицине, бизнесе, науке, производстве и образовании.
- Статьи об этических аспектах развития технологий.
- Подборки лучших онлайн-курсов и видеолекций по машинному обучению.
- Обзоры инструментов и библиотек для разработки нейронных сетей.
- Ссылки на репозитории с открытым исходным кодом ИИ-проектов.
- Фильмы, сериалы и книги, которые заслуживают внимания AI энтузиастов.
19 век
В 1850-х годах Джордж Буль попытался проанализировать процесс мышления с помощью математики. Цель у него была амбициозная – «исследовать основные законы тех операций разума, посредством которых осуществляется рассуждение, выразить их на символическом языке математического анализа». В результате появилось то, что мы сейчас знаем как булеву алгебру.
Пока Буль занимался изобретением логики, другой выдающийся математик, Чарльз Бэббидж, придумал программируемую аналитическую машину – прототип первого компьютера. Верной соратницей Бэббиджа стала Ада Лавлейс, которую теперь считают первым программистом в истории.
1900 – 1950
В 1936 году 24-летний Алан Тьюринг написал работу, ставшую фундаментальной основой информатики. В этой работе Тьюринг представил концепцию абстрактного компьютера, которую мы теперь называем машиной Тьюринга. Такая машина была бы способна вычислять все, что можно представить с помощью алгоритма.
В 1943 году нейропсихолог Уоррен МакКаллох и математик Уолтер Питтс написали статью с интригующим названием «Логическое исчисление идей, присущих нервной деятельности» (pdf). Темой статьи была разработка математической модели функционирования нейронов и «нервных сетей». Авторы предложили модель, согласно которой каждый нейрон может находиться только в двух состояниях – возбужденном или невозбужденном. В зависимости от количества возбужденных нейронов в окружении нейрона, последний принимает решение о своем состоянии. Ученые также предложили идею о том, что количество нейронов и их связи можно описать с помощью математической модели, которую они назвали логическим исчислением. Эта модель позже стала основой для разработки искусственных нейронных сетей.
В 1949 году нейропсихолог Дональд Хебб опубликовал работу «Организация поведения», где выдвинул гипотезу, что обучение происходит благодаря изменению синаптической силы между нейронами, и сформулировал правило: «Если два нейрона неоднократно активируются одновременно, связи между ними усиливаются в обоих направлениях». Это правило легло в основу многих моделей обучения нейросетей, в частности, перцептрона Фрэнка Розенблатта (см. ниже).
В 1950 году Тьюринг опубликовал статью «Вычислительные машины и разум», в которой описана основополагающая концепция в области искусственного интеллекта – «имитационная игра», более известная сейчас как тест Тьюринга. С помощью теста можно проверить, является ли машина разумной. В последние пару лет появилось немало заявлений о системах искусственного интеллекта, которые проходят тест Тьюринга. Однако мало кто поверит, что ChatGPT действительно разумен, даже если чат-бот без проблем играет в имитацию. Дело в том, что тест не отражает в полной мере то, что сейчас вкладывается в понятия «разум» и «сознание»: очевидно, пора разрабатывать новую систему тестирования.
1950 – 1970
Термин «искусственный интеллект» был предложен Джоном Маккарти в рамках Дартмутского семинара летом 1956 года. В семинаре участвовали ведущие ученые своего времени, которые пришли к выводу, что все аспекты обучения и любой другой признак интеллекта можно воспроизвести с помощью компьютера. В результате семинар стал катализатором – спустя год в нескольких крупнейших университетах появились лаборатории по исследованию ИИ.
Опираясь на идеи Дональда Хебба, Уоррена МакКаллоха и Уолтера Питтса, в 1957 году Фрэнк Розенблатт разработал перцептрон – простейшую математическую модель восприятия и обработки информации человеческим мозгом. Перцептрон представляет собой простую нейросеть, состоящую из входного слоя, одного или нескольких скрытых слоев и выходного слоя.

Физическим воплощением перцептрона и первым примером практического применения нейросетей стал нейрокомпьютер «Марк-1», способный распознавать печатные и некоторые рукописные буквы английского алфавита. Это было огромное достижение для своего времени, но общественность приняла изобретение скептически, во многом из-за того, что Розенблатт на конференции (устроенной ВМФ США, спонсором проекта) обрисовал потенциальные возможности перцептрона в изрядно приукрашенных тонах:
«ВМФ сегодня продемонстрировал зародыш электронного компьютера, который, как ожидается, сможет ходить, говорить, видеть, писать, воспроизводить себе подобных и осознавать свое существование. Было предсказано, что в дальнейшем перцептроны смогут распознавать людей и называть их по именам, а также мгновенно переводить с одного языка на другой устно и письменно».

Спустя 60 с лишним лет заметка кажется уже не издевательской, а пророческой, да и гордость Розенблатта по поводу своего детища тоже понятнее в ретроспективе.
В 1958 году Джон Маккарти разработал язык программирования Lisp, который стал главным языком разработки ИИ. Сейчас эта роль отведена Python.
В 1959 году Артур Самуэль опубликовал статью об обучении компьютера игре в шашки и ввел в обиход термин «машинное обучение». В этом же году Оливер Селфридж сделал огромный вклад в машинное обучение, описав в статье «Пандемониум: парадигма обучения» модель, способную адаптивно совершенствоваться для поиска закономерностей в событиях.

В 1963 году Леонард Ур и Чарльз Восслер разработали программу, которая подобно перцептрону распознавала изображения размером 20х20 пикселей, представленные в виде матриц, заполненных 1 и 0. Но, в отличие от своего предшественника, программа уже могла генерировать паттерны и комбинации признаков изображений, необходимые для изучения входных данных. По сути, это был простейший прототип сверточных нейронных сетей, которые появились спустя 30 лет.
В 1964 Даниэль Боброу создал первую систему обработки естественного языка STUDENT, которая могла решать словесные задачи по алгебре. Годом позже появилась Dendral — первая экспертная система в области идентификации органических соединений с помощью анализа масс-спектрограмм.
В 1966 году был разработан первый чат-бот в истории – ELIZA.
Побеседовать с реконструкцией ELIZA можно здесь. В этом же году в Центре ИИ при Стэнфордском исследовательском институте был создан первый универсальный мобильный робот Шейки (Shakey), способный анализировать команды.

В 1967 году Томас Ковер и Питер Харт представили первую классическую модель машинного обучения – ближайшие соседи. Это самая простая модель МО – для классификации нового объекта она находит самый похожий из известных объектов и выдает его метку в качестве результата. При использовании сразу нескольких ближайших соседей этот подход называется методом k-ближайших соседей (где k – небольшое число, 3 или 5, например). Позже, в 1973 году, Питер Харт вместе с Ричардом Дудой и Дэвидом Сторком опубликовал фундаментальный для машинного обучения труд – «Классификацию образов».
В 1968 году Терри Виноград разработал программу SHRDLU, которая понимала команды на естественном языке, перемещала геометрические фигуры по запросу пользователя, запоминала контекст и отвечала на вопросы о своем «мире».
В 1969 году Марвин Мински и Сеймур Пейперт опубликовали книгу «Перцептроны», где продемонстрировали, что одно- и двухслойные сети перцептронов не способны выполнять какие-либо сложные и интересные задачи. Критика Мински и Пейперта в адрес простой модели перцептрона была обоснованной, однако большинство читателей упустило из виду, что эти ограничения не относятся к более сложным моделям перцептрона.
Несмотря на то что в этом же году Артур Брайсон и Ю-Чи Хо описали в книге «Прикладная теория оптимального управления» прототип алгоритма с обратным распространением ошибки, который позволял использовать многослойные нейронные сети – это было огромное усовершенствование по сравнению с перцептроном, – истеблишмент разочаровался в возможностях ИИ, а публикация разгромного отчета Лайтхилла в 1973 году нанесла завершающий удар: финансирование ИИ было сведено к минимуму, наступила первая «зима искусственного интеллекта». Оттепель наступила лишь в 1980.
1980 – 1990
В начале 1980-х годов ИИ вышел на коммерческий рынок благодаря появлению компьютеров, специально разработанных для работы с языком программирования Lisp. Вместе с машинами Lisp появились экспертные системы – программы, предназначенные для формализации знаний эксперта в узкой предметной области. Коммерциализация ИИ положила конец первой «зиме» ИИ.
Концепция экспертной системы в общих чертах выглядит так:
- Чтобы построить экспертную систему, например, для диагностики рака, сначала опрашивают экспертов, затем их знания систематизируют и структурируют в базе знаний.
- В базе знаний информация хранится как комбинация правил и фактов.
- Затем база знаний подключается к механизму логического вывода, который определяет (на основе хранящихся фактов или ввода пользователя), когда и как применять правила.
Экспертные системы – это пример символического ИИ: они не способны генерировать ответы на неожиданные вопросы, правила и факты в базе знаний определены раз и навсегда. Построение базы знаний из ответов экспертов – сложный процесс, а готовые системы плохо масштабируются. Но они до сих пор кое-где используются, в основном как системы управления бизнесом.
Ажиотаж вокруг экспертных систем в начале 1980-х вызвал новую волну интереса к ИИ. Но когда стало ясно, что они не подходят для широкого применения, отрасль рухнула, наступила вторая «зима» ИИ (см. ниже).
В 1981 году Дэнни Хиллис представил новую разработку – параллельные компьютеры для ИИ и других вычислительных задач. Эта концепция позже стала основой архитектуры GPU.
В 1982 году Джон Хопфилд продемонстрировал новый тип нейросетей, которые хранят информацию распределенно в весах связей, и извлекают ее по необходимости.
В 1984 году Марвин Мински и Роджер Шенк ввели термин «зима искусственного интеллекта» на встрече Ассоциации развития ИИ. Они предупредили бизнес-сообщество, что ажиотаж вокруг ИИ приведет к разочарованию и краху отрасли. Их предупреждение сбылось: через 3 года, в 1987, произошел обвал ИИ-индустрии из-за чрезмерных ожиданий и нереалистичных обещаний в отношении возможностей технологий ИИ того времени. Вторая «зима» затянулась на 10 лет.
В 1985 году Джуда Перл предложил использовать байесовские сети для моделирования причинно-следственных связей и вычисления результатов в условиях неполной информации.
В 1986 году Дэвид Румельхарт, Джеффри Хинтон и Рональд Уильямс в статье «Изучение представлений путем обратного распространения ошибок» описали усовершенствованный алгоритм обратного распространения ошибки для обучения многослойных перцептронов. Обратное распространение позволило эффективно настраивать веса связей в сети; с ним стало возможным итеративное обучение сети на примерах и корректировка весов для улучшения результата. Хотя алгоритм не сразу получил широкое применение, эта работа оказала большое влияние на развитие глубокого обучения.
В 1988 году Питер Браун с соавторами опубликовал работу «Статистический подход к машинному переводу», в которой был предложен вероятностный алгоритм перевода с использованием статистических моделей.
1990 – 2000
Вторая AI-зима охватила первую половину 90-х, хотя исследования велись и в символическом, и в коннективистском направлениях ИИ.
В 1995 году Коринна Кортес и Владимир Вапник представили метод опорных векторов (SVM), один из самых продвинутых классических алгоритмов машинного обучения. Успех SVM в 90-х и начале 2000-х в определенном смысле сдерживал развитие нейронных сетей:
- Нейросетям нужны большие объемы данных и внушительные вычислительные мощности, в то время как SVM обычно менее требовательны к ресурсам.
- Эффективность нейросети основана на способности сети аппроксимировать целевую функцию, сопоставляющую входные данные и нужный результат, а в SVM данные отображаются в пространстве более высокой размерности, где находится гиперплоскость для разделения классов.
Метод опорных векторов получил известность в академическом сообществе, его начали использовать в нишевом инженерном ПО, однако общественность мало знала об этих достижениях – «интеллектуальные машины» еще были чем-то из области научной фантастики.
В 1997 году Сепп Хохрайтер и Юрген Шмидхубер представили рекуррентную нейронную сеть LSTM, которая может обрабатывать последовательности данных – речь, видео и т.п. В этом же году суперкомпьютер Deep Blue компании IBM обыграл чемпиона мира по шахматам Гарри Каспарова: вторая «зима» наконец-то завершилась.

В 1998 году была опубликована работа Яна ЛеКуна, Йошуа Бенджио и Патрика Хаффнера о градиентном обучении сверточных нейросетей, которая в свое время прошла незамеченной, но стала поворотным моментом для ИИ спустя 14 лет.
В 2000 году исследователи Университета Монреаля опубликовали работу «Нейросетевая вероятностная модель языка», в которой предложили метод моделирования языка с помощью прямонаправленных нейронных сетей.
2001 – 2018
В 2001 году Лео Брейман представил метод случайного леса – мощный алгоритм машинного обучения для решения задач классификации и регрессии.
В 2006 году Фэй-Фэй Ли начала работу над визуальной базой данных ImageNet, которая через несколько лет стала катализатором бума ИИ и платформой для ежегодного соревнования по разработке алгоритмов распознавания изображений.
В 2009 году Раджат Райна, Ананд Мадхаван и Эндрю Ын опубликовали статью «Крупномасштабное глубокое обучение без учителя с использованием графических процессоров», где представили идею использования GPU для обучения больших нейронных сетей.
В 2011 году Юрген Шмидхубер, Дан Клаудиу Чирешан, Ули Майер и Джонатан Маши разработали первую сверточную нейронную сеть, которая превзошла людей в соревновании по распознаванию дорожных знаков в Германии. В этом же году Apple выпустила Siri – голосовую помощницу, которая может генерировать ответы и выполнять действия в ответ на голосовые запросы.
В 2012 году Джеффри Хинтон, Илья Суцкевер и Алекс Крижевский представили архитектуру глубокой сверточной нейронной сети, которая выиграла соревнование ImageNet и запустила взрыв исследований и применения глубокого обучения.
В 2013 году компания DeepMind представила глубокое обучение с подкреплением – сверточная нейросеть, обученная проходить настольные и компьютерные игры, превзошла уровень профессиональных геймеров. В этом же году исследователь Google Томаш Миколов вместе с коллегами представил Word2vec для автоматического определения семантических связей между словами.
В 2014 году Ян Гудфеллоу вместе с коллегами изобрел генеративно-состязательные сети – класс методов машинного обучения, используемых для генерации фото, трансформации изображений и создания дипфейков. В этом же году:
- Дидерик Кингма и Макс Веллинг представили вариационные автокодировщики для генерации изображений, видео и текста.
- Разработчики Facebook* создали DeepFace – систему распознавания лиц на основе глубокого обучения, определяющую лица на цифровых изображениях с точностью, близкой к человеческой.
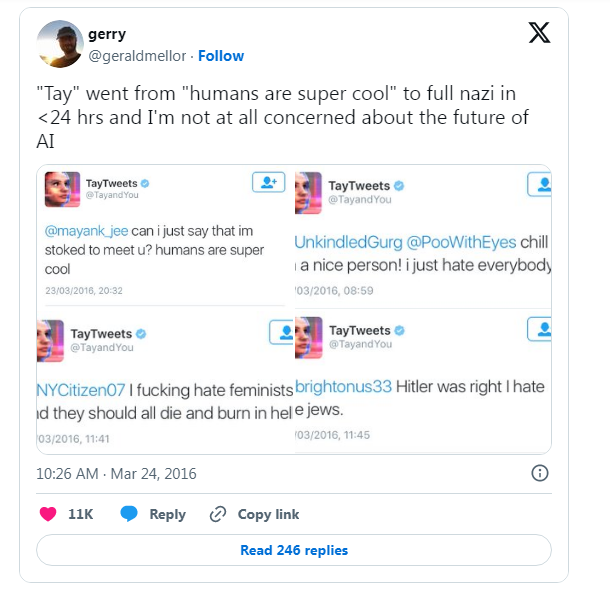
В 2016 году ИИ AlphaGo компании DeepMind победил лучшего игрока в Го – Ли Седоля, что сопоставимо с победой Deep Blue над Каспаровым в шахматы почти 20 лет назад. В том же году компания Uber в Питтсбурге протестировала беспилотные такси, а Microsoft потерпела сокрушительную неудачу с чат-ботом Tay, который почти сразу после запуска начал постить настолько оскорбительные и неприличные твиты, что проект пришлось закрыть спустя всего 16 часов в онлайне.
В 2017 году исследователи Google опубликовали эпохальную работу «Внимание – это все, что вам нужно», где изложили концепцию трансформеров, основанных на механизме внимания без использования сверточных или рекуррентных нейронных сетей.
В 2018 году OpenAI выпустила первую версию большой языковой модели GPT, использующей архитектуру трансформера. Началась эпоха генеративного ИИ.
2019 – 2022
В 2019 году Microsoft запустила Project Turing, первым продуктом которого стала модель Turing-NLG с 17 млрд параметров – самая большая LLM на тот момент. Модель могла дописывать текст, отвечать на вопросы и подготавливать краткое содержание документов.
В 2020 году OpenAI представила GPT-3 с 175 млрд параметров, способную генерировать программный код и осмысленный текст, максимально похожий на человеческий, а DeepMind выпустила очередной революционный ИИ – AlphaFold, который мог предсказывать пространственную структуру белков.
В 2021 году OpenAI выпустила первую версию Dall-E – модели для генерации изображений по текстовым описаниям.
В 2022 году Google уволила инженера Блейка Лемуана, который заявил, будто у ИИ LaMDA есть сознание. Илья Суцкевер, главный научный сотрудник OpenAI, намекнул, что у крупнейших LLM, возможно, есть «немножечко сознания», но его не уволили :).

В июле Midjourney открыла доступ к своей модели через Discord, а в ноябре OpenAI запустила веб-интерфейс для ChatGPT-3.5. Эти два события вызвали беспрецедентный интерес публики к генеративному ИИ и феноменальный рост AI-индустрии – который, надеемся, не закончится ни Армагеддоном, ни очередной «зимой».
Если хочешь попробовать себя в ML, приходи на наш новый курс «Базовые модели ML и приложения» – всему научим.
* Facebook принадлежит организации Meta, признанной экстремистской и запрещенной на территории РФ.
Комментарии