

Для начала необходимо ознакомиться с целью соревнования, правилами и данными. Также стоит вспомнить основы работы с Kaggle из первой статьи.
Перед нами стоит задача предсказания стоимости дома на основе множества признаков (фич), вроде расположения, площади, количества комнат, наличия гаража и т.д.
Это состязание по решению задачи регрессии, исходя из чего мы и будем действовать.
Данные состоят из четырех файлов:
- train.csv – обучающая (тренировочная) выборка.
- test.csv – тестовые данные, на основе которых мы будем делать предсказания.
- data_description.txt – полное описание каждого столбца.
- sample_submission.csv – пример того, как должен выглядеть наш ответ (сабмит).

Весь код воспроизводится в ячейках jupyter notebook.
Для начала, загружаем тестовую и тренировочную выборки.
import numpy as np
import pandas as pd
df_train = pd.read_csv('../input/train.csv')
df_test = pd.read_csv('../input/test.csv')
# Просматриваем данные
train_df.head()
Определим размеры датасета. Для анализа будем использовать тренировочную часть.
train_df.shape
Обзор данных – целевая переменная
Первое, что мы должны сделать – посмотреть на нашу целевую переменную SalePrice.
train_df['SalePrice'].describe()

Создается впечатление, что цена дома существенно отклоняется от нормального распределения:
- Стандартное отклонение слишком велико.
- Минимум больше 0 (что логично для цен на недвижимость).
- Существует большая разница между минимальным значением и 25-м процентилем.
- Разница между 75-м процентилем и максимумом больше, чем 25-й процентиль и максимум.
Нам стоит создать гистограмму, чтобы окончательно убедиться в том, с каким распределением мы имеем дело.
# Импортируем необходимые библиотеки для визуализации
import matplotlib.pyplot as plt
import seaborn as sns
# гистограмма
f, ax = plt.subplots(figsize=(8, 6))
sns.distplot(train_df['SalePrice'])
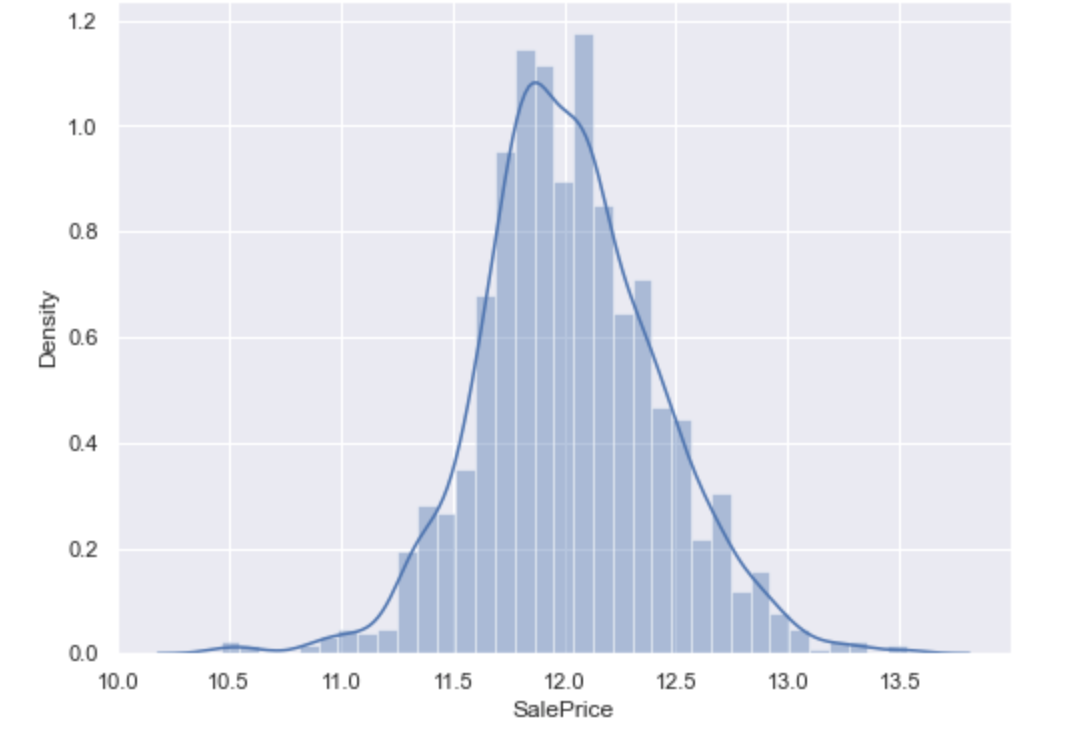
Как мы и полагали, распределение далеко от идеального. Проведем больше наблюдений:
# Рассчитываем асимметрию и эксцесс
print("Ассиметрия: %f" % train_df['SalePrice'].skew())
print("Эксцесс: %f" % train_df['SalePrice'].kurt())
- Ассиметрия: 1.882876.
- Эксцесс: 6.536282.
С этим нужно что-то делать. Возможно, нам поможет логарифмическое преобразование целевой переменной? Создадим два графика: один с исходными данными, другой с применением упомянутой выше техники:
from scipy import stats
fig = plt.figure(figsize = (14,8))
# Распределение на необработанных данных
fig.add_subplot(1,2,1)
res = stats.probplot(train_df['SalePrice'], plot=plt)
# Распределение при условии, что мы прологарифмировали 'SalePrice'
fig.add_subplot(1,2,2)
res = stats.probplot(np.log1p(train_df['SalePrice']), plot=plt)
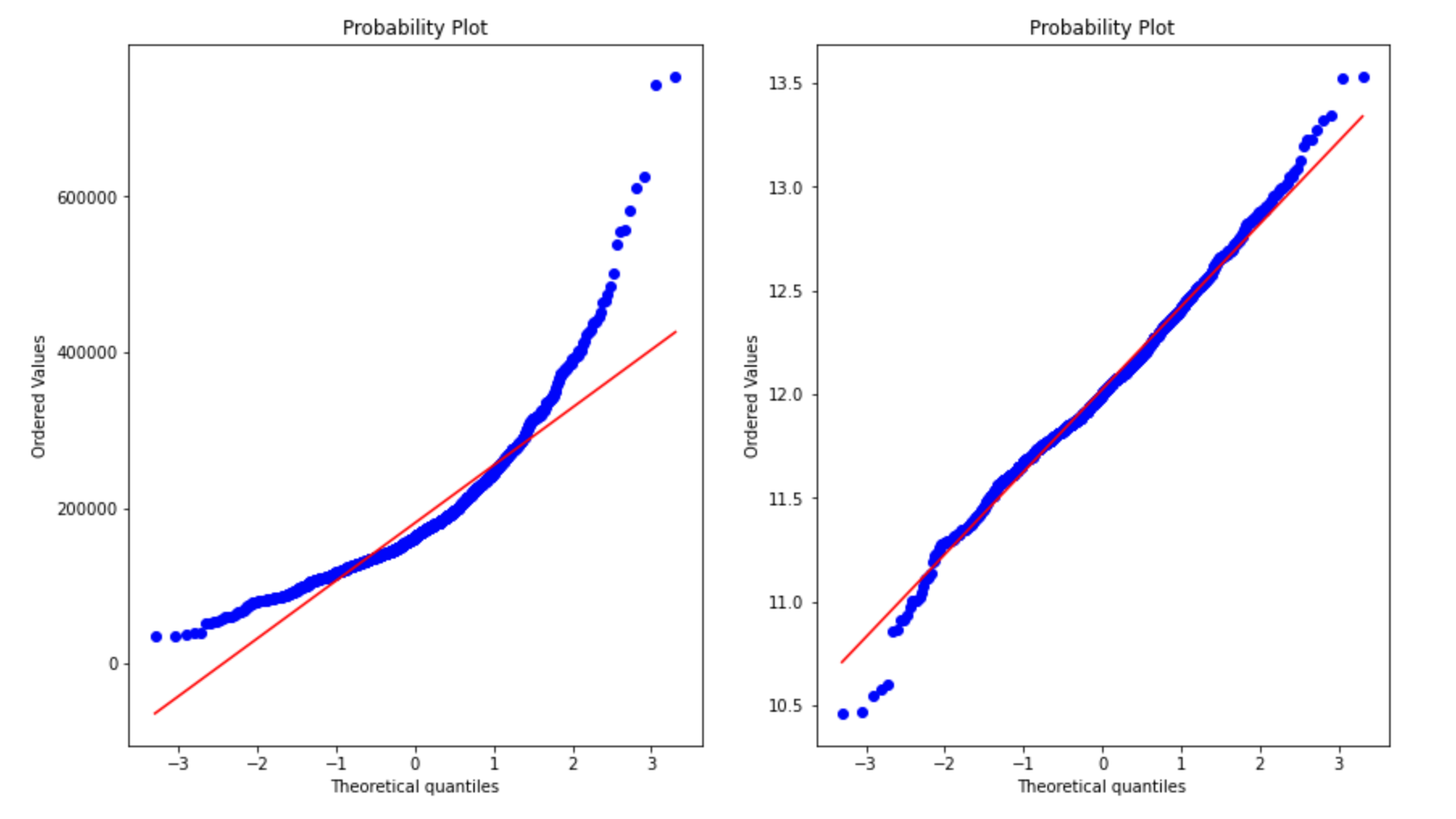
Этот метод построения признаков исправил ситуацию. Теперь наша задача – совершить логарифмирование не просто испытательным путем на графике, а применить данный метод ко всей тренировочной выборке:
train_df['SalePrice'] = np.log1p(train_df['SalePrice'])
Обзор данных – корреляция
Теперь посмотрим, с какими признаками коррелирует целевая переменная SalePrice:
# Матрица корреляции
corrmat = train_df.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True);
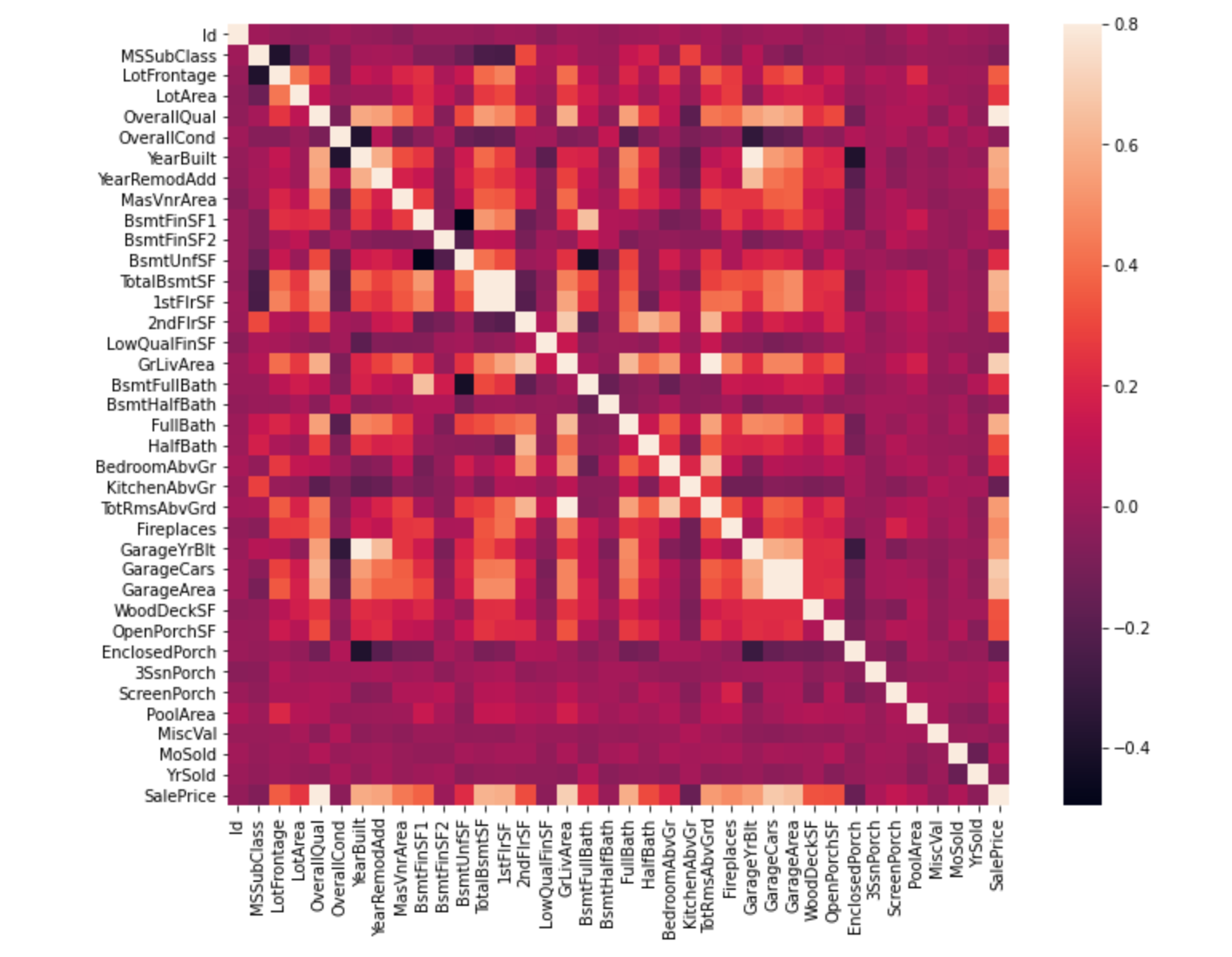
Попробуем усеченный вариант и сократим количество коррелирующих признаков до 10:
k = 10 # количество коррелирующих признаков, которое мы хотим увидеть
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(train_df[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True,
fmt='.2f', annot_kws={'size': 10},
yticklabels=cols.values, xticklabels=cols.values)
plt.show()
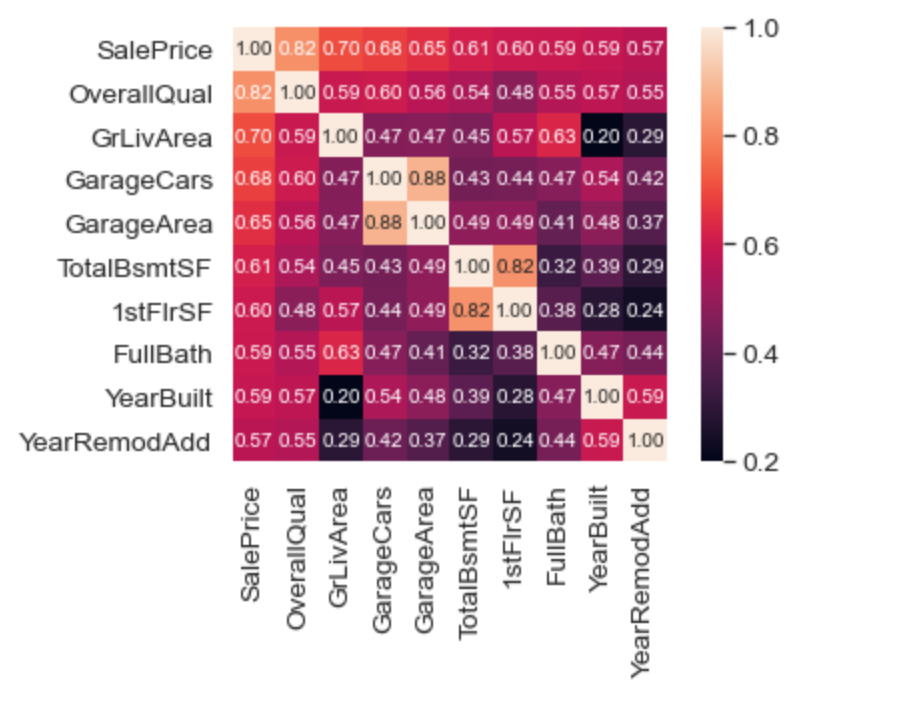
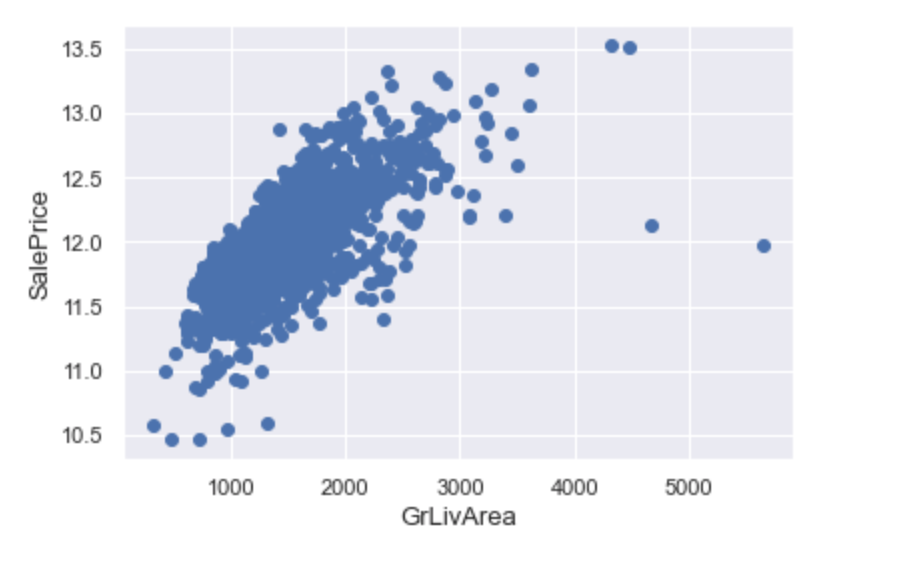
Теперь мы видим, что лучше всего SalePrice коррелирует с GrLivArea и OverallQual. Проверим эти два признака на наличие выбросов:
fig, ax = plt.subplots()
ax.scatter(x = train_df['GrLivArea'], y = train_df['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('GrLivArea', fontsize=13)
plt.show()
fig, ax = plt.subplots()
ax.scatter(x = train_df['OverallQual'], y = train_df['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('OverallQual', fontsize=13)
plt.show()
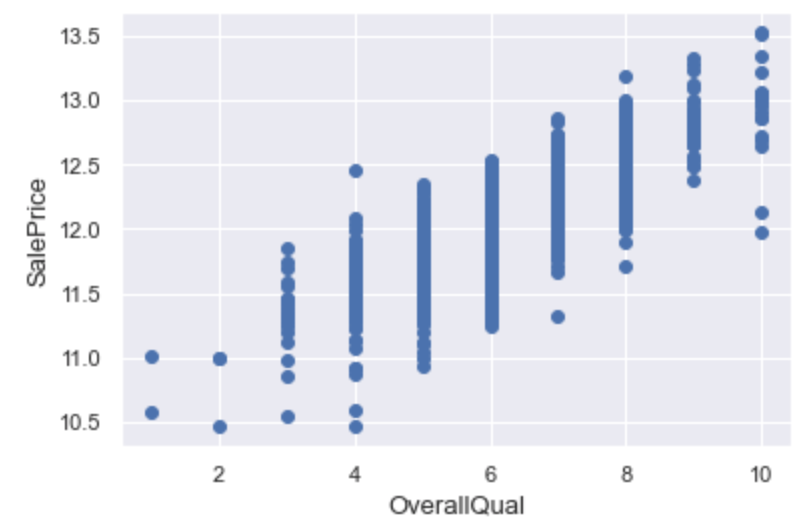
Выбросы незначительны. Однако если мы удалим несколько самых выделяющихся значений, то результат модели улучшится.
# Ликвидируем
# Только эти 2 удаления помогут нам улучшить наш показатель на таблице лидеров
train_df = train_df.drop(train[(train['OverallQual'] > 9) & (train['SalePrice'] < 220000)].index)
train_df = train_df.drop(train[(train['GrLivArea'] > 4000) & (train['SalePrice'] < 300000)].index)
Очистка данных и отбор признаков
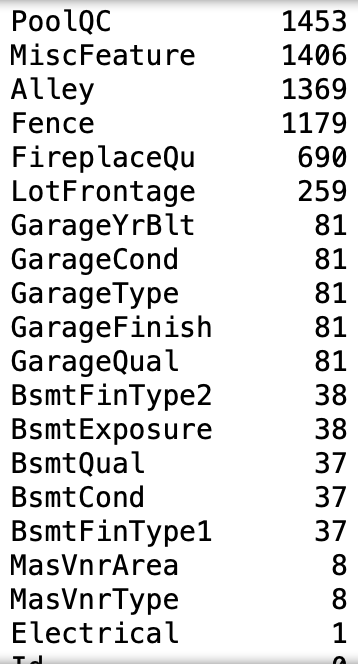
Эта строчка кода выведет топ-20 пропущенных значений:
# Пропущенные значения
train_df.isnull().sum().sort_values(ascending=False).head(20)
На диаграмме масштаб пропущенных значений будет виден лучше:
# Визуализируем
total = train_df.isnull().sum().sort_values(ascending=False)
percent = (train_df.isnull().sum() / train_df.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
# Гистограмма
percent_data = percent.head(20)
percent_data.plot(kind="bar", figsize = (8,6), fontsize = 10)
plt.xlabel("Столбцы", fontsize = 20)
plt.ylabel("Count", fontsize = 20)
plt.title("Общее количество недостающих значений (%)", fontsize = 20)
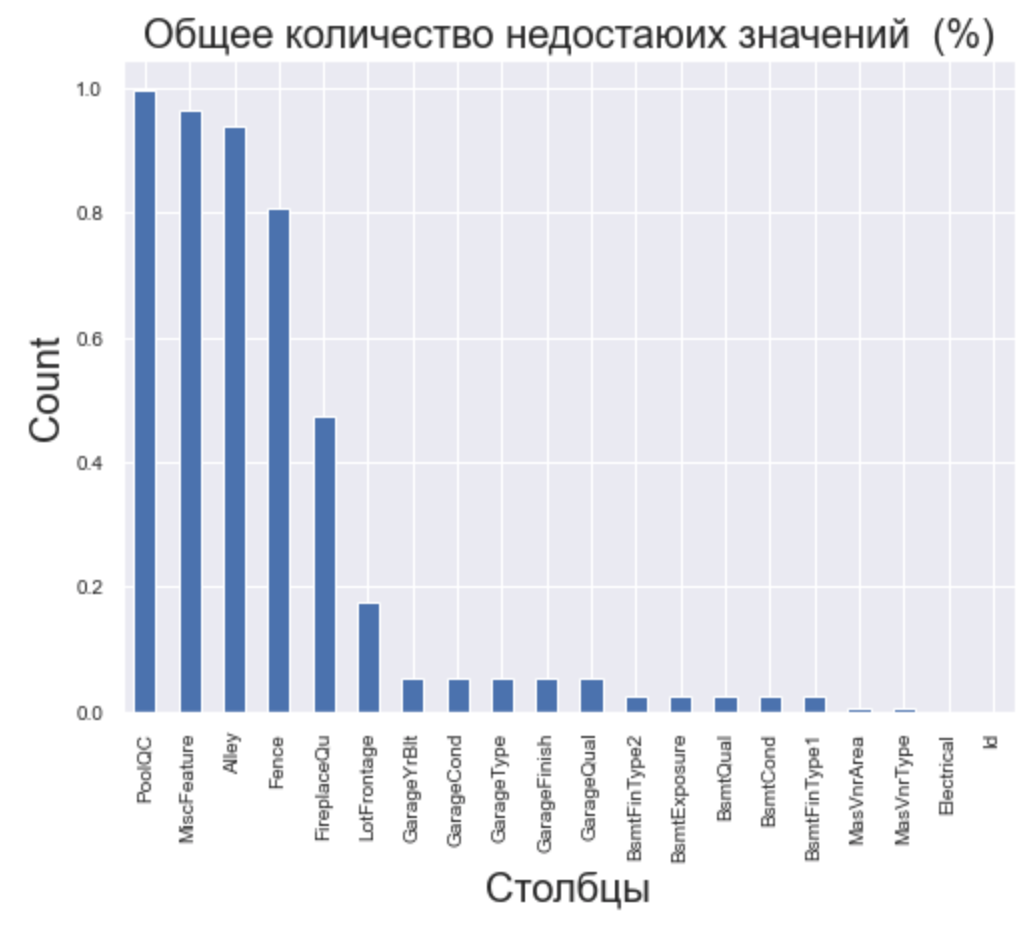
С этим необходимо разобраться. Большой количество пропущенных данных как в тренировочном, так и в тестовом датасете очень сильно ударит по качеству модели, а это прямая дорога на дно таблицы лидеров в соревновании.
Исправим проблему на объединенных данных.
# Удаляем строки, где целевое значение (target) пропущено
Target = 'SalePrice'
train_df.dropna(axis=0, subset=[Target], inplace=True)
# Соединяем тренировочный и тестовый датасеты, чтобы провести наши преобразования на всех данных
all_data = pd.concat([train_df.iloc[:,:-1], test_df],axis=0)
print('У тренировочного датасета {} рядов и {} признаков'.format(train_df.shape[0], train_df.shape[1]))
print('У тестового датасета {} рядов и {} признаков'.format(test_df.shape[0], test_df.shape[1]))
print('Объединённый датасет содержит в себе {} рядов и {} признаков'.format(all_data.shape[0], all_data.shape[1]))
# Удаляем бесполезный столбец
all_data = all_data.drop(columns=['Id'], axis=1)
Теперь мы можем полноценно разобраться с пропущенными данными.
# Функция для просмотра пропущенных данных
# При желании вместо 'train_df' вы можете забить 'all_data'
def missingValuesInfo(df):
total = df.isnull().sum().sort_values(ascending = False)
percent = round(df.isnull().sum().sort_values(ascending = False) / len(df)*100, 2)
temp = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
return temp.loc[(temp['Total'] > 0)]
missingValuesInfo(train_df)
# Разбираемся с пропущенными данными
# Числовые значения отбираем через принадлежность к формату ['int64', 'float64']
# Категориальные значения отбираем через принадлежность к формату ["object"]
def HandleMissingValues(df):
num_cols = [cname for cname in df.columns if df[cname].dtype in ['int64', 'float64']]
cat_cols = [cname for cname in df.columns if df[cname].dtype == "object"]
values = {}
for a in cat_cols:
values[a] = 'UNKNOWN'
for a in num_cols:
values[a] = df[a].median()
df.fillna(value=values, inplace=True)
HandleMissingValues(all_data)
all_data.head()
# Проверим
all_data.isnull().sum().sum()
Результат – 0.
Отлично, мы справились с основной проблемой. Не стоит также забывать о категориальных признаках.
# Разбираемся с категориальными признаками
def getObjectColumnsList(df):
return [cname for cname in df.columns if df[cname].dtype == "object"]
def PerformOneHotEncoding(df, columnsToEncode):
return pd.get_dummies(df, columns=columnsToEncode)
cat_cols = getObjectColumnsList(all_data)
all_data = PerformOneHotEncoding(all_data, cat_cols)
all_data.head()
Наша задача по базовой очистке данных и отбору признаков решена. Теперь мы можем снова разбить данные на тренировочный и тестовый датасеты. Это необходимо, так как предсказывать поведение будущей модели мы будем на тестовой выборке.
train_data = all_data.iloc[:1460, :]
test_data = all_data.iloc[1460:, :]
print(train_df.shape)
print(test_df.shape)
Моделирование
Так как в соревновании House Prices перед участниками стоит задача регрессии, использовать мы будем соответствующие модели.
from sklearn.linear_model import RidgeCV
ridge_cv = RidgeCV(alphas = (0.01, 0.05, 0.1, 0.3, 1, 3, 5, 10))
ridge_cv.fit(X, y)
ridge_cv_preds = ridge_cv.predict(test_data)
И также XGBRegressor
import xgboost as xgb
model_xgb = xgb.XGBRegressor(n_estimators=340, max_depth=2, learning_rate=0.2)
model_xgb.fit(X, y)
xgb_preds = model_xgb.predict(test_data)
Возьмем усредненное значение от обеих моделей:
predictions = (ridge_cv_preds + xgb_preds) / 2
Создадим датафрейм, чтобы выложить наше решение.
submission = {
'Id': test_df.Id.values,
'SalePrice': predictions
}
solution = pd.DataFrame(submission)
solution.to_csv('submission.csv',index=False)
Заключение
Цель этой статьи – предоставить вам базовое понимание “пайплайна”, который необходим для успешного покорения Kaggle. Сюда входят:
- Загрузка данных, их тщательное изучение и последующая очистка.
- Отбор признаков, при необходимости – создание новых.
- Выбор правильной модели (в продвинутых случаях – ансамбль нескольких моделей), подбор приемлемых параметров.
- Предсказание и успешный сабмит.
Поиск лучшего решения на соревновании Kaggle – это целое искусство, освоить которое вы сможете, комбинируя самые разнообразные техники с нестандартными методами.
Если вы только начинаете путь в профессию и еще не определились со специализацией, подумайте о применении методов науки о данных в медицинской отрасли: сейчас это одно из самых перспективных направлений. Образовательная онлайн-платформа GeekBrains проводит набор на факультет Data Science в медицине, на котором студенты научатся с нуля решать задачи в области медицины. Обучение длится 18 месяцев, плюс 6 месяцев занимает практика по медицинской специализации. По итогам получите 15 проектов в портфолио и гарантию трудоустройства.
Комментарии