

Что такое признаки (features) и для чего они нужны?
Признаки могут быть следующих видов:
- Бинарные, которые принимают только два значения. Например, [true, false], [0,1], [“да”, “нет”].
- Категориальные (или же номинальные). Они имеют конечное количество уровней, например, признак
«день недели»имеет 7 уровней: понедельник, вторник и т. д. до воскресенья.
- Упорядоченные. В некоторой степени похожи на категориальные признаки. Разница между ними в том, что данном случае существует четкое упорядочивание категорий. Например,
«классы в школе»от 1 до 11. Сюда же можно отнести«время суток», которое имеет 24 уровня и является упорядоченным.
- Числовые (количественные). Это значения в диапазоне от минус бесконечности до плюс бесконечности, которые нельзя отнести к предыдущим трем типам признаков.
Стоит отметить, что для задач машинного обучения нужны только те «фичи», которые на самом деле влияют на итоговый результат. Определить и сгенерировать такие признаки вам поможет эта статья.
Что такое построение признаков?
Например, в базе данных интернет-магазина есть таблица «Покупатели», содержащая одну строку для каждого посетившего сайт клиента.
В ней также может быть таблица «Взаимодействия», содержащая строку для каждого взаимодействия (клика или посещения страницы), которое клиент совершил на сайте. Эта таблица также содержит информацию о времени взаимодействия и типе события, которое представляло собой взаимодействие (событие «Покупка», событие «Поиск» или событие «Добавить в корзину»). Эти две таблицы связаны между собой столбцом Customer ID.

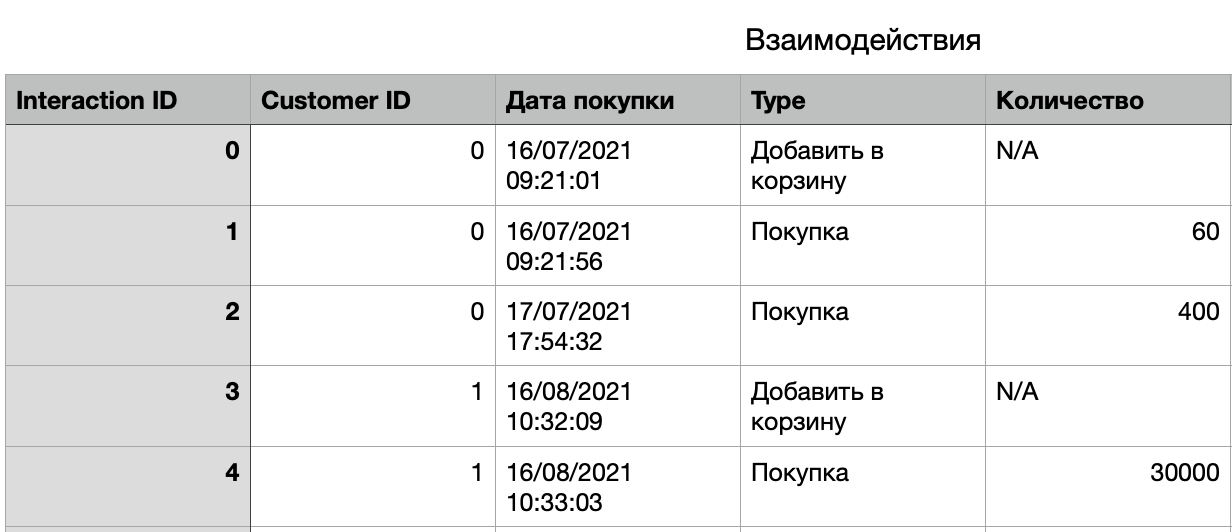
Чтобы повысить предсказательную способность, нам необходимо воспользоваться данными в таблице взаимодействий. Отбор признаков делает это возможным. Мы можем рассчитать статистику для каждого клиента, используя все значения в таблице «Взаимодействия» с идентификатором этого клиента. Вот несколько потенциально полезных признаков, или же «фич», которые помогут нам в решении задачи:
- Среднее время между прошлыми покупками.
- Средняя сумма прошлых покупок.
- Максимальная сумма прошлых покупок.
- Время, прошедшее с момента последней покупки.
- Общее количество покупок в прошлом.
Чтобы построить эти признаки, мы должны найти все связанные с конкретным клиентом взаимодействия. Затем мы проведем фильтрацию тех, чей Тип (Type) не является "Покупкой", и вычислим функцию, которая возвращает одно значение, используя имеющиеся данные.
Следует обратить внимание, что данный процесс уникален для каждого случая использования и набора данных.
Этот тип инжиниринга признаков необходим для эффективного использования алгоритмов машинного обучения и построения прогностических моделей.
Построение признаков на табличных данных
Удаление пропущенных значений
Отсутствующие значения – одна из наиболее распространенных проблем, с которыми вы можете столкнуться при попытке подготовить данные. Этот фактор очень сильно влияет на производительность моделей машинного обучения.
Самое простое решение для пропущенных значений – отбросить строки или весь столбец. Оптимального порога для отбрасывания не существует, но вы можете использовать 70% в качестве значения и отбросить строки со столбцами, в которых отсутствуют значения, превышающие этот порог.
import pandas as pd
import numpy as np
threshold = 0.7
# Удаление столбцов с коэффициентом пропущенных значений выше порога
data = data[data.columns[data.isnull().mean() < threshold]]
# Удаление строк с коэффициентом отсутствия значений выше порога
data = data.loc[data.isnull().mean(axis=1) < threshold]
Заполнение пропущенных значений
Более предпочтительный вариант, чем отбрасывание, потому что он сохраняет размер данных. Очень важно, что именно вы относите к недостающим значениям. Например, если у вас есть столбец, с числами 1 и N/A , то вполне вероятно, что строки N/A соответствуют 0 .
В качестве другого примера: у вас есть столбец, который показывает количество посещений клиентов за последний месяц. Тут отсутствующие значения могут быть заменены на 0.
За исключением вышеперечисленного, лучший способ заполнения пропущенных значений – использовать медианы столбцов. Поскольку средние значения столбцов чувствительны к значениям выбросов, медианы в этом отношении будут более устойчивыми.
import pandas as pd
import numpy as np
# Заполнение всех пропущенных значений 0
data = data.fillna (0)
# Заполнение пропущенных значений медианами столбцов
data = data.fillna (data.median ())
Замена пропущенных значений максимальными
Замена отсутствующих значений на максимальное значение в столбце будет хорошим вариантом для работы только в случае, когда мы разбираемся с категориальными признаками. В других ситуациях настоятельно рекомендуется использовать предыдущий метод.
import pandas as pd
import numpy as np
data['column_name'].fillna(data['column_name'].value_counts() .idxmax(), inplace=True)
Обнаружение выбросов
Что касается обнаружения выбросов: один из лучших способов это сделать – рассчитать стандартное отклонение. Если значение отклоняется больше, чем на x * стандартное отклонение, его можно принять, как выброс. Наиболее используемое значение для x – в пределах [2, 4].
import pandas as pd
import numpy as np
# Удаление неподходящих строк
x = 3
upper_lim = data['column'].mean () + data['column'].std () * x
lower_lim = data['column'].mean () - data['column'].std () * x
data = data[(data['column'] < upper_lim) & (data['column'] > lower_lim)]
Другой математический метод обнаружения выбросов – использование процентилей. Вы принимаете определенный процент значения сверху или снизу за выброс.
Ключевым моментом здесь является повторная установка процентного значения, и это зависит от распределения ваших данных, как упоминалось ранее.
Кроме того, распространенной ошибкой является использование процентилей в соответствии с диапазоном данных. Другими словами, если ваши данные находятся в диапазоне от 0 до 100 , ваши лучшие 5% – это не значения между 96 и 100 . Верхние 5% означают здесь значения, выходящие за пределы 95-го процентиля данных.
import pandas as pd
import numpy as np
# Избавляемся от лишних строк при помощи процентилей
upper_lim = data['column'].quantile(.95)
lower_lim = data['column'].quantile(.05)
data = data[(data['column'] < upper_lim) & (data['column'] > lower_lim)]
Ограничение выбросов
С другой стороны, ограничение может повлиять на распределение данных и качество модели, поэтому лучше придерживаться золотой середины.
import pandas as pd
import numpy as np
upper_lim = data['column'].quantile(.95)
lower_lim = data['column'].quantile(.05)
data.loc[(df[column] > upper_lim),column] = upper_lim
data.loc[(df[column] < lower_lim),column] = lower_lim
Логарифмическое преобразование
- Оно помогает обрабатывать искаженные данные, и после преобразования распределение становится более приближенным к нормальному.
- В большинстве случаев порядок величины данных изменяется в пределах диапазона данных. Например, разница между возрастом от 15 до 20 лет не равна возрасту от 65 до 70 лет, так как по всем остальным аспектам разница в 5 лет в молодом возрасте означает большую разницу в величине. Этот тип данных поступает в результате мультипликативного процесса, и логарифмическое преобразование нормализует подобные различия величин.
- Это также снижает влияние выбросов за счет нормализации разницы величин, и модель становится более надежной.
Важное примечание: данные, которые вы применяете, должны иметь только положительные значения, иначе вы получите ошибку.
import pandas as pd
import numpy as np
# Пример логарифмической трансформации
data = pd.DataFrame({'value':[2,45, -23, 85, 28, 2, 35, -12]})
data['log+1'] = (data['value']+1).transform(np.log)
# Обработка отрицательных значений
# (Обратите внимание, что значения разные)
data['log'] = (data['value']-data['value'].min()+1) .transform(np.log)
Быстрое кодирование (One-Hot encoding)
Этот метод распределяет значения в столбце по нескольким столбцам флагов и присваивает им 0 или 1. Бинарные значения выражают связь между сгруппированным и закодированным столбцом. Этот метод изменяет ваши категориальные данные, которые сложно понять алгоритмам, в числовой формат. Группировка происходит без потери какой-либо информации, например:
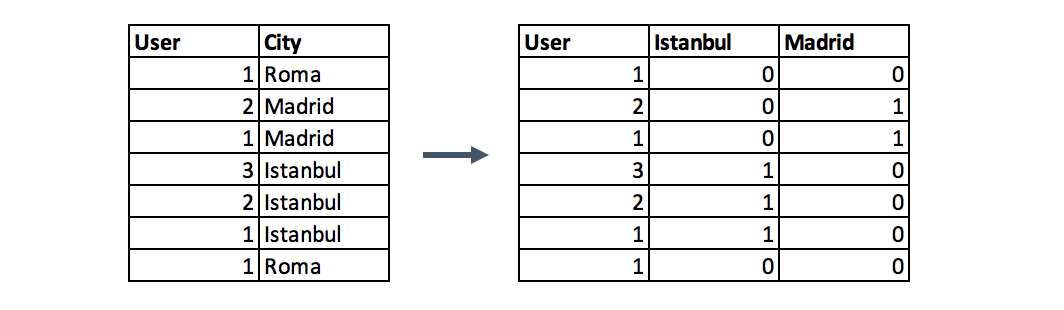
Приведенная ниже функция отражает использование метода быстрого кодирования с вашими данными.
encoded_columns = pd.get_dummies(data['column'])
data = data.join(encoded_columns).drop('column', axis=1)
Масштабирование признаков
В большинстве случаев числовые характеристики набора данных не имеют определенного диапазона и отличаются друг от друга.
Например, столбцы возраста и месячной зарплаты будут иметь совершенно разный диапазон.
Как сравнить эти два столбца, если это необходимо в нашей задаче? Масштабирование решает эту проблему, так как после данной операции элементы становятся идентичными по диапазону.
Существует два распространенных способа масштабирования:
- Нормализация.
В данном случае все значения будут находиться в диапазоне от 0 до 1. Дискретные бинарные значения определяются как 0 и 1.
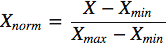
import pandas as pd
import numpy as np
data = pd.DataFrame({'value':[2,45, -23, 85, 28, 2, 35, -12]})
data['normalized'] = (data['value'] - data['value'].min()) / (data['value'].max() - data['value'].min())
- Стандартизация.
Масштабирует значения с учетом стандартного отклонения. Если стандартное отклонение функций другое, их диапазон также будет отличаться друг от друга. Это снижает влияние выбросов в элементах. В следующей формуле стандартизации среднее значение показано как μ, а стандартное отклонение показано как σ.
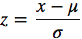
import pandas as pd
import numpy as np
data = pd.DataFrame({'value':[2,45, -23, 85, 28, 2, 35, -12]})
data['standardized'] = (data['value'] - data['value'].mean()) / data['value'].std()
Работа с текстом
Перед тем как работать с текстом, его необходимо разбить на токены – отдельные слова. Однако делая это слишком просто, мы можем потерять часть смысла. Например, «Великие Луки» это не два токена, а один.
После превращения документа в последовательность слов, можно начинать превращать их в векторы. Самый простой метод – Bag of Words. Мы создаем вектор длиной в словарь, для каждого слова считаем количество его вхождений в текст и подставляем это число на соответствующую позицию в векторе.
В коде алгоритм выглядит гораздо проще, чем на словах:
from functools import reduce
import numpy as np
texts = [['i', 'have', 'a', 'cat'],
['he', 'have', 'a', 'dog'],
['he', 'and', 'i', 'have', 'a', 'cat', 'and', 'a', 'dog']]
dictionary = list(enumerate(set(reduce(lambda x, y: x + y, texts))))
def vectorize(text):
vector = np.zeros(len(dictionary))
for i, word in dictionary:
num = 0
for w in text:
if w == word:
num += 1
if num:
vector[i] = num
return vector
for t in texts:
print(vectorize(t))
Работа с изображениями
Часто для задач с изображениями используется определенная сверточная сеть. Необязательно продумывать архитектуру сети и обучать ее с нуля. Можно взять уже обученную нейросеть из открытых источников.
Чтобы адаптировать ее под свою задачу, работающие в области науки о данных инженеры практикуют fine tuning (тонкую настройку). Ликвидируются последние слои нейросети, вместо них добавляются новые, подобранные под нашу конкретную задачу, и сеть дообучается на новых данных.
Пример подобного шаблона:
from keras.applications.resnet50 import ResNet50
from keras.preprocessing import image
from scipy.misc import face
import numpy as np
resnet_settings = {'include_top': False, 'weights': 'imagenet'}
resnet = ResNet50(**resnet_settings)
img = image.array_to_img(face())
img = img.resize((224, 224))
# в реальной жизни может понадобиться внимательнее относиться к ресайзу
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
# нужно дополнительное измерение, т.к. модель рассчитана на работу с массивом изображений
features = resnet.predict(x)
Заключение
На практике процесс построения фич может быть самым разнообразным: решение проблемы пропущенных значений, обнаружение выбросов, превращение текста в вектор (с помощью продвинутой обработки естественного языка, которая отображает слова в векторное пространство) – лишь некоторые примеры из этой области.
Следующая статья будет посвящена отбору признаков.
Комментарии