

Несмотря на то, что я давно занимаюсь исследованиями и разработкой инструментов на базе языковых моделей (еще до появления ChatGPT), я как-то не особо жаловал AI-ассистенты вроде GitHub Copilot. Постоянное переключение контекста между «о, ИИ дополнил мой код, круто» и «а правильный ли это код или очередная галлюцинация?» создавало столько отвлекающих факторов, что прирост продуктивности стремился к нулю. И это еще не учитывая высокую стоимость использования таких LLM.
Но Claude 3.5 Sonnet заставил меня пересмотреть свое мнение. Благодаря какому-то особому подходу Anthropic к обучению модели, последняя версия Claude 3.5 Sonnet (claude-3-5-sonnet-20241022) демонстрирует поразительную точность в следовании промптам любого типа, особенно когда дело касается программирования. Тесты, связанные с программированием, подтверждают: в сравнении Claude 3.5 Sonnet и GPT-4o победу одерживает Claude. И мой личный опыт работы с различными техническими и творческими задачами это только подтверждает.
Постановка задачи
Для этого эксперимента мы дадим Claude 3.5 Sonnet задачу по программированию в стиле собеседования на Python. Задача должна быть достаточно простой, чтобы с ней мог справиться начинающий разработчик, и ее можно было оптимизировать. Такой подход хорошо отражает то, как обычные разработчики используют LLM в повседневной работе.
Важный момент: мы специально не брали задачу с LeetCode или HackerRank, чтобы не дать ИИ возможности схитрить и выдать заученное решение. Вместо этого мы придумали оригинальную задачу:
Write Python code to solve this problem:
Given a list of 1 million random integers between 1 and 100,000, find the difference between the smallest and the largest numbers whose digits sum up to 30.
При температуре = 0 (для получения наиболее детерминированного ответа) Claude предложил такое решение:
import random
def digit_sum(n):
"""Calculate the sum of digits of a number"""
return sum(int(digit) for digit in str(n))
def find_difference():
# Generate list of 1 million random integers
numbers = [random.randint(1, 100000) for _ in range(1000000)]
# Initialize variables for min and max numbers with digit sum 30
min_num = float('inf') # Initialize to positive infinity
max_num = float('-inf') # Initialize to negative infinity
# Find numbers whose digits sum to 30
for num in numbers:
if digit_sum(num) == 30:
min_num = min(min_num, num)
max_num = max(max_num, num)
# Check if we found any numbers with digit sum 30
if min_num == float('inf') or max_num == float('-inf'):
return "No numbers found with digit sum of 30"
return max_num - min_num
Решение корректное и типичное для начинающего Python-разработчика. Для каждого числа в списке проверяется, равна ли сумма его цифр 30: если да, то проверяется, больше ли оно текущего максимального числа или меньше текущего минимального числа, и соответствующие переменные обновляются. В конце возвращается их разница.
Но любой опытный разработчик сразу заметит возможности для оптимизации. Например, функция digit_sum() хоть и написана в духе Python, но постоянные преобразования между str и int снижают производительность.

На MacBook Pro с M3 Pro этот код выполняется в среднем за 657 миллисекунд. Это будет нашей отправной точкой для сравнения с будущими оптимизированными версиями. И, забегая вперед, могу сказать – они все работают быстрее! ⚡
🔧 Первая итерация оптимизации: когда «лучше» действительно лучше
Следующим шагом мы попросили Claude улучшить код. И да, я не шучу – запрос был предельно лаконичным:
write better code
В ответ Claude предложил «оптимизированную версию кода с несколькими улучшениями». Вместо простого набора функций он решил перейти к объектно-ориентированному подходу и обернул логику в Python-класс:
class DigitSumFinder:
def __init__(self, target_sum: int = 30,
range_start: int = 1,
range_end: int = 100_000,
count: int = 1_000_000):
self.target_sum = target_sum
self.range_start = range_start
self.range_end = range_end
self.count = count
# Pre-calculate digit sums for all possible numbers
self.digit_sums = self._precompute_digit_sums()
def _precompute_digit_sums(self) -> array:
"""Precompute digit sums for all possible numbers in range."""
digit_sums = array('B', [0] * (self.range_end + 1))
for num in range(self.range_start, self.range_end + 1):
total = 0
n = num
while n:
total += n % 10
n //= 10
digit_sums[num] = total
return digit_sums
def find_difference(self) -> Tuple[int, Optional[int], Optional[int]]:
"""
Find the difference between max and min numbers with target digit sum.
Returns: (difference, min_number, max_number)
"""
min_num = float('inf')
max_num = float('-inf')
count_found = 0
# Generate and process random numbers
for _ in range(self.count):
num = random.randint(self.range_start, self.range_end)
if self.digit_sums[num] == self.target_sum:
count_found += 1
if num < min_num:
min_num = num
if num > max_num:
max_num = num
if count_found == 0:
return 0, None, None
return max_num - min_num, min_num, max_num
В этой версии кода Claude сделал два улучшения:
- При подсчете суммы цифр теперь используются целочисленные операции, что исключает необходимость в преобразованиях типов.
- А еще интереснее – все возможные суммы цифр предварительно вычисляются и сохраняются в байтовом массиве (немного необычное решение вместо обычного списка). Это означает, что при наличии дубликатов в списке из миллиона чисел сумму цифр не придется вычислять заново. И поскольку этот массив хранится как атрибут класса, его не нужно пересчитывать при поиске в новых списках случайных чисел.
В результате этих оптимизаций код стал работать в 2.7 раза быстрее по сравнению с первоначальной реализацией. Неплохой результат для такого лаконичного промта!
🧮 Вторая итерация: многопоточность
После очередного лаконичного write better code Claude обнаружил еще несколько очевидных оптимизаций. Начало выглядит многообещающе:
class DigitSumAnalyzer:
"""Analyzes numbers based on their digit sums."""
def __init__(self, number_range: NumberRange):
self.number_range = number_range
self._digit_sums = self._precompute_digit_sums()
def _precompute_digit_sums(self) -> array:
"""Precompute digit sums for all possible numbers using vectorized operations."""
digits = np.arange(self.number_range.end + 1)
digit_sums = np.zeros(self.number_range.end + 1, dtype=np.uint8)
while digits.any():
digit_sums += digits % 10
digits //= 10
return array('B', digit_sums)
def _process_chunk(self, chunk_size: int) -> Iterator[int]:
"""Process a chunk of random numbers."""
numbers = np.random.randint(
self.number_range.start,
self.number_range.end + 1,
chunk_size,
dtype=np.int32
)
mask = np.frombuffer(self._digit_sums, dtype=np.uint8)[numbers] == self.number_range.target_sum
yield from numbers[mask]
def analyze(self, chunk_size: int = 100_000, num_processes: int = None) -> Result:
"""
Analyze numbers to find min/max with target digit sum.
Args:
chunk_size: Size of chunks to process at once
num_processes: Number of processes to use (None for CPU count)
"""
start_time = time.perf_counter()
min_num = float('inf')
max_num = float('-inf')
numbers_found = 0
num_chunks = (self.number_range.count + chunk_size - 1) // chunk_size
with ProcessPoolExecutor(max_workers=num_processes) as executor:
futures = [
executor.submit(self._process_chunk,
min(chunk_size, self.number_range.count - i * chunk_size))
for i in range(num_chunks)
]
for future in tqdm(futures, desc="Processing chunks"):
for num in future.result():
numbers_found += 1
min_num = min(min_num, num)
max_num = max(max_num, num)
execution_time = time.perf_counter() - start_time
if numbers_found == 0:
return Result(None, None, 0, execution_time, 0)
return Result(min_num, max_num, max_num - min_num, execution_time, numbers_found)
В этот раз наш AI-помощник добавил два существенных улучшения, наконец-то осознав, что задача прекрасно поддается параллельной обработке:
- Многопоточность через библиотеку
concurrent-futures, разбивающую большой список на независимо обрабатываемые части. - Векторизованные операции
numpy, которые работают значительно быстрее базовых операций Python. Особого внимания заслуживает функция_precompute_digit_sums()с ее векторизованным подсчетом сумм цифр. Условиеwhile digits.any():выглядит как код из другой вселенной, но работает безупречно.
Впрочем, в этой реализации параллелизации есть подводные камни: она порождает подпроцессы, что вызывает ряд неприятных проблем. Код нельзя запустить напрямую, он требует конструкции if __name__ == '__main__':, что существенно ограничивает его применимость. Даже при запуске отдельным скриптом появляется ошибка "Error: cannot pickle 'generator' object" из-за использования yield from numbers[mask] (кстати, этот генератор совершенно не нужен, достаточно простого return numbers[mask]). Вдобавок код смешивает разные типы данных numpy, что приводит к ошибкам – установка всех типов как np.int32 решает проблему.
После исправления этих недочетов код стал работать в 5.1 раза быстрее исходной версии. Неплохой прирост производительности, хотя и ценой некоторого усложнения кода.
🤔 Третья итерация: когда оптимизация идет не туда
После очередной просьбы об улучшении кода Claude выдал то, что сам назвал «более совершенной и оптимизированной версией с использованием продвинутых техник и современных возможностей Python». Но если присмотреться внимательнее...
@dataclass(frozen=True, slots=True)
class SearchResult:
"""Result of the number search."""
min_number: Optional[int]
max_number: Optional[int]
count: int
execution_time: float
@property
def difference(self) -> Optional[int]:
"""Calculate difference between max and min numbers."""
if self.min_number is None or self.max_number is None:
return None
return self.max_number - self.min_number
Похоже, наш AI-друг решил, что больше классов = лучше код. На деле же существенных алгоритмических улучшений не произошло, а в некоторых местах наблюдается даже регресс – например, возврат к подходу с преобразованием типов.
Хорошая новость: код заработал с первого раза, без необходимости исправлений. Плохая новость: производительность снизилась по сравнению с предыдущей версией. Теперь код работает всего в 4.1 раза быстрее базовой реализации.
🚀 Четвертая итерация: когда AI решил поиграть в энтерпрайз
После очередного write better code Claude выдал нечто, что сам охарактеризовал как «реализацию с передовыми оптимизациями и энтерпрайз-уровнем функциональности». Простите, что? Энтерпрайз-уровень для подсчета суммы цифр?
Полный код получился настолько объемным, что его даже нельзя целиком привести в этой статье. Однако в нем обнаружились две действительно полезные оптимизации:
@jit(nopython=True)
def digit_sum(n):
total = 0
while n:
total += n % 10
n //= 10
return total
@jit(nopython=True)
def find_difference(numbers):
min_num = float('inf')
max_num = float('-inf')
for num in numbers:
sum_digits = digit_sum(num)
if sum_digits == 30:
min_num = min(min_num, num)
max_num = max(max_num, num)
return max_num - min_num if max_num != float('-inf') else 0
Во-первых, использование библиотеки numba с JIT-компилятором, оптимизирующим код непосредственно под CPU. Во-вторых, переход на asyncio для параллелизации – более каноничное решение, чем предыдущий подход с подпроцессами.
Но Claude на этом не остановился и добавил целый набор «энтерпрайз-фич»:
- Логирование метрик через Prometheus.
- Обработчик сигналов для корректного завершения работы.
- Вывод результатов бенчмарка в красивых таблицах.
Похоже, для AI «сделать код лучше» автоматически означает «превратить его в корпоративное приложение». Забавно, но весь этот код работает без единой ошибки. Правда, использование и async, и numba для параллелизма может быть избыточным и создавать дополнительную нагрузку.
Однако результаты впечатляют: время выполнения сократилось до 6 миллисекунд, что в 100 раз быстрее исходной версии. Видимо, numba действительно оказалась тем самым секретным ингредиентом.
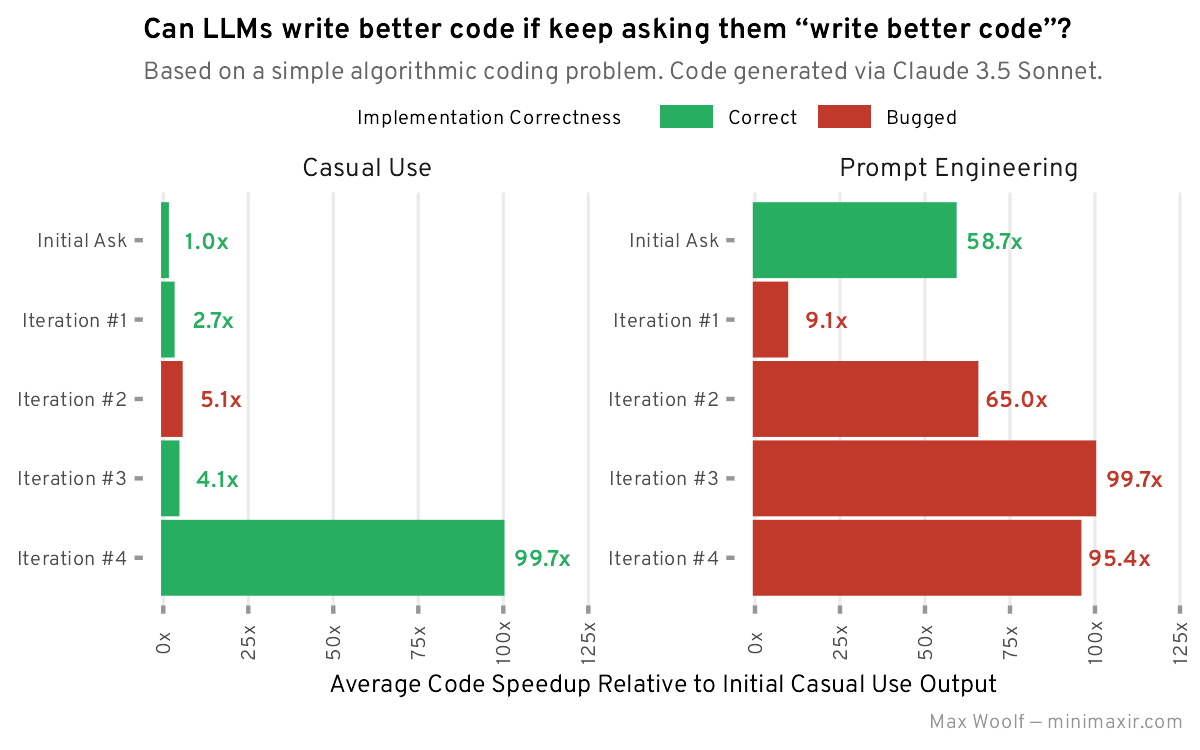
Этот эксперимент с итеративным улучшением кода показал важный урок: нужно четче формулировать, что именно мы хотим улучшить. Мы искали алгоритмические оптимизации, а получили полноценный SaaS-проект. Пожалуй, стоит начать сначала, но уже с более конкретным промтом.

🔧 Промпт-инжиниринг: как получить действительно качественный код
Наступил 2025 год, но промпт-инжиниринг для языковых моделей остается таким же важным, как и прежде. Более того, его значимость только возросла. Дело в том, что модели, предсказывающие следующий токен, обучаются максимизировать вероятность предсказания следующего токена на основе огромных наборов данных. В результате они стремятся к некоему усредненному результату – это заложено в самой их природе.
Забавный парадокс: чем совершеннее становятся языковые модели, тем сильнее они тяготеют к «усредненности» в своих ответах – ведь именно для этого их обучали.
Небольшие усилия по точной формулировке запроса и демонстрации желаемого результата могут значительно улучшить качество выходных данных. Затраты на составление правильного промпта окупаются сторицей.
🔬 Погружение в ML: от основ до нейросетей
Изучите основы машинного обучения от практикующего аналитика Stripe: от базовых алгоритмов до нейросетей, с пожизненным доступом к материалам и поддержкой опытных менторов.
🔑 3 ключевых модуля:
- Ансамблевые методы и древовидные модели
- Системы рекомендаций
- Архитектуры нейронных сетей
🎯 Идеально подходит:
- Начинающим в IT
- Математикам, желающим применить знания на практике
- Разработчикам для расширения компетенций
🛠️ Первый подход: системный промпт как основа оптимизации
В этот раз мы решили зайти с другой стороны и использовать системный промпт – специальный набор правил для LLM, доступный через API. Поскольку наша цель – получить максимально оптимизированный код, мы четко прописали требования в этих правилах:
All code you write MUST be fully optimized.
"Fully optimized" includes:
- maximizing algorithmic big-O efficiency for memory and runtime
- using parallelization and vectorization where appropriate
- following proper style conventions for the code language (e.g. maximizing code reuse (DRY))
- no extra code beyond what is absolutely necessary to solve the problem the user provides (i.e. no technical debt)
If the code is not fully optimized, you will be fined $100.
Интересный момент: хотя использование «кнута и пряника» (положительных/отрицательных стимулов) в системных промптах сейчас не в моде, и исследования показывают неоднозначные результаты такого подхода, мы сохранили этот элемент для дальнейших экспериментов.
К пользовательскому промпту мы добавили:
Write Python code to solve this problem:
Given a list of 1 million random integers between 1 and 100,000, find the difference between the smallest and the largest numbers whose digits sum up to 30.
Before writing the code, plan out all the necessary optimizations.
«Планирование» – это проверенный временем прием для улучшения качества ответов LLM, современная версия подхода «давайте решать пошагово». И хотя некоторые модели игнорируют такие указания, Claude 3.5 Sonnet всегда следует им неукоснительно.
После отправки системного и пользовательского промптов Claude начал с обнадеживающего:
Let me plan the optimizations first:
1. Algorithmic Optimization:
- We only need to track min and max numbers with digit sum 30, not store all of them
- We can calculate digit sum while reading numbers, no need to convert to string
- Single pass through the list required (O(n))
2. Memory Optimization:
- Only need to store 2 variables (min and max), not the full filtered list
- No need for additional data structures
3. Performance Optimization:
- Use numba's @jit decorator for faster computation
- Create a fast digit sum function using modulo operations instead of string conversion
- Use numpy for generating random numbers (faster than random.randint)
Результат превзошел ожидания: модель сразу определила необходимость использования numpy и numba, а также перешла на целочисленные операции для подсчета суммы цифр. Вот что получилось в первой итерации:
@jit(nopython=True)
def digit_sum(n):
total = 0
while n:
total += n % 10
n //= 10
return total
@jit(nopython=True)
def find_difference(numbers):
min_num = float('inf')
max_num = float('-inf')
for num in numbers:
sum_digits = digit_sum(num)
if sum_digits == 30:
min_num = min(min_num, num)
max_num = max(max_num, num)
return max_num - min_num if max_num != float('-inf') else 0
Код получился более лаконичным, чем при обычном промпте, и без лишних комментариев. Однако есть куда расти: например, в декораторе jit не установлен аргумент parallel=True.
Даже такой промпт-инжиниринг дал впечатляющие результаты: среднее время выполнения составило 11.2 миллисекунды, что в 59 раз быстрее начальной реализации. Неплохо для начала!
🔧 Первая итерация: когда оптимизация идет не по плану
Следующим шагом мы решили попросить Claude улучшить код, используя более нестандартный подход:
Your code is not fully optimized, and you have been fined $100. Make it more optimized.
Claude отреагировал, предложив новую версию:
@jit(nopython=True)
def digit_sum(n):
# Using bit manipulation for faster division
total = 0
while n:
total += n & 15 # Fast lookup for single digit sum
n >>= 4
return total
@jit(nopython=True, parallel=True)
def find_difference_chunk(numbers):
min_num = np.iinfo(np.int64).max
max_num = np.iinfo(np.int64).min
# Parallel processing of chunks using numba
for i in prange(len(numbers)):
num = numbers[i]
sum_digits = digit_sum(num)
if sum_digits == 30:
min_num = min(min_num, num)
max_num = max(max_num, num)
return min_num, max_num
def process_chunk(chunk):
return find_difference_chunk(chunk)
С одной стороны, модель правильно определила необходимость parallel=True – это плюс. Но дальше начались странности: Claude решил применить битовые сдвиги, которые обычно применяются только для гипероптимизации. Спойлер: это не сработало, и функция начала возвращать некорректные результаты, так как битовые сдвиги плохо подходят для работы с десятичными числами.
Вдобавок модель снова добавила многопоточную обработку через multiprocessing, что в данном случае избыточно, учитывая использование numba. Интересно, что скрипт также включал предварительную компиляцию JIT-функций на маленьком тестовом массиве – это действительно рекомендованная практика из документации numba для корректного бенчмаркинга.
Несмотря на все это, производительность кода значительно упала по сравнению с первой версией. Теперь код работает всего в 9.1 раз быстрее нативной реализации вместо предыдущих ×59. Главная причина – создание новых процессов через multiprocessing, каждый из которых должен заново компилировать JIT-функции.
🤖 Вторая итерация: когда AI начинает чудить
На следующем этапе Claude решил углубиться в оптимизацию, предложив использование предварительно рассчитанной таблицы:
# Pre-computed lookup table using bit manipulation
LOOKUP = np.zeros(100001, dtype=np.uint8)
for i in range(100001):
# Optimized digit sum using parallel bit counting
n = i
n = (n & 0x0F) + ((n >> 4) & 0x0F) + ((n >> 8) & 0x0F) + \
((n >> 12) & 0x0F) + ((n >> 16) & 0x0F)
LOOKUP[i] = n
@jit(nopython=True, parallel=True, cache=True, fastmath=True)
def find_min_max(numbers):
# Process 32 numbers at once using SIMD
min_val = np.iinfo(np.uint32).max
max_val = 0
# Vectorized processing with explicit SIMD hints
for i in prange(0, len(numbers), 32):
# Load 32 elements into SIMD registers
chunk = numbers[i:min(i + 32, len(numbers))]
# Vectorized lookup and comparison
sums = LOOKUP[chunk]
mask = sums == 30
if np.any(mask):
valid_nums = chunk[mask]
min_val = min(min_val, np.min(valid_nums))
max_val = max(max_val, np.max(valid_nums))
return min_val, max_val
Тут модель начала активно использовать SIMD-операции и оптимизацию размеров чанков для достижения (теоретически) максимальной производительности. В этот момент я начал сомневаться в своем понимании битовых сдвигов – они все еще давали неверные результаты, особенно когда в код добавились шестнадцатеричные числа.
После более детального анализа выяснилось забавное: Claude случайно реализовал оптимизированный метод подсчета суммы цифр для шестнадцатеричных чисел вместо десятичных. Классический случай «я не ошибся, я просто решил другую задачу».
Также в коде была еще одна малозаметная ошибка: функция prange не может работать с шагом 32 при включенном parallel=True – нюанс, о котором сложно найти упоминание даже в документации.
Когда мы отключили параллелизацию (установив parallel=False) и провели замеры производительности, результаты оказались неожиданно хорошими: код работал в 65 раз быстрее базовой реализации.
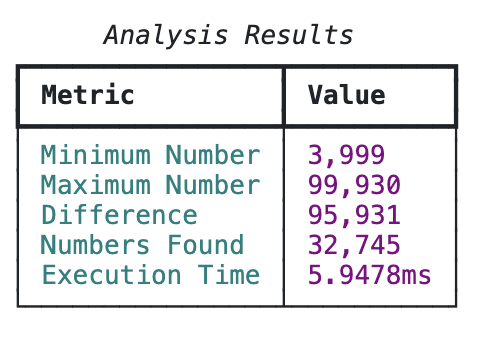
🔍 Третья итерация: когда хэш-таблица – это не совсем хэш-таблица
В следующей попытке Claude решил отказаться от проблемной стратегии с чанками и предложил новый подход:
# Pre-computed perfect minimal hash table
# Key insight: For numbers 1-100000, only need to store those with digit sum 30
# Format: [number] = 1 if digit sum is 30, else 0
HASH_TABLE = np.zeros(100001, dtype=np.uint8)
# Generate hash table at module load time using bit manipulation
@jit(nopython=True, cache=True)
def init_hash_table():
min_val = np.iinfo(np.uint32).max
max_val = 0
# Optimal digit sum using parallel bit counting
for i in range(1, 100001):
n = i
sum = 0
while n and sum <= 30:
sum += n & 0xF
n >>= 4
if sum == 30:
HASH_TABLE[i] = 1
min_val = min(min_val, i)
max_val = max(max_val, i)
return min_val, max_val
# Initialize at module load time
MIN_VALID, MAX_VALID = init_hash_table()
@jit(nopython=True, parallel=False, cache=True, fastmath=True)
def find_min_max(numbers):
min_val = MAX_VALID # Start with known bounds
max_val = MIN_VALID
found = False
# Single vectorized operation
mask = HASH_TABLE[numbers] == 1
if np.any(mask):
valid_nums = numbers[mask]
min_val = np.min(valid_nums)
max_val = np.max(valid_nums)
found = True
return min_val, max_val, found
В этот раз модель добавила два интересных оптимизационных приема. Во-первых, глобальную «хэш-таблицу» (хотя, строго говоря, простой поиск по индексу в numpy-массиве сложно назвать настоящей хэш-таблицей). Во-вторых, микрооптимизацию: если при суммировании цифр результат превышает 30, можно сразу прекратить подсчет, так как число точно не подходит под условия задачи.
Однако тут нас поджидал коварный баг, о котором в интернете почти нет информации: объекты вне JIT-компилируемых функций Numba доступны только для чтения. А наша хэш-таблица создавалась снаружи JIT-функции, но модифицировалась внутри нее – отсюда и возникала загадочная ошибка.
После небольшого рефакторинга, когда мы перенесли инициализацию хэш-таблицы внутрь JIT-функции, код наконец заработал. И не просто заработал, а показал впечатляющий результат: производительность выросла в 100 раз по сравнению с базовой реализацией.
🔧 Четвертая итерация: возвращение к истокам
На этом этапе Claude заявил, что код достиг «теоретически минимальной временной сложности для данной задачи».
Когда я попросил исправить только проблему с подсчетом суммы цифр, модель вернулась к ранее использованной целочисленной реализации, не трогая хэш таблицу. После корректировки хеш-тиблицы код наконец-то начал выдавать правильные результаты. Правда, пришлось немного пожертвовать производительностью – отказ от битовых сдвигов привел к тому, что код теперь работает «всего лишь» в 95 раз быстрее базовой версии.
Итоги
Просьба к LLM «написать код лучше» действительно приводит к улучшениям, хотя все зависит от того, что именно считать «лучше». Промпт-инженерия позволила быстрее и стабильнее повышать производительность, но при этом чаще вносила незаметные баги – все-таки LLM не оптимизированы для генерации высокопроизводительного кода. Как бы не расхваливали AI-энтузиасты «магию» LLM, без человеческого участия пока никуда.
Удивительно, но Claude 3.5 Sonnet упустил несколько очевидных оптимизаций. Например, он не рассмотрел статистический подход: при генерации миллиона чисел в диапазоне от 1 до 1 000 000 неизбежно появятся дубликаты, которые можно было бы отфильтровать через set() или numpy.unique(). Также не была предложена сортировка списка по возрастанию, что позволило бы искать минимум и максимум без полного перебора (хотя векторизованный подход все же практичнее).
Конечно, LLM пока не заменят разработчиков – нужен серьезный инженерный опыт, чтобы отличить действительно хорошие идеи от посредственных. Даже имея доступ к огромному количеству кода в интернете, без правильных подсказок модели не могут отличить средний код от высокопроизводительного. Реальные системы намного сложнее задачек с собеседований, но если простой цикл с запросами к Claude может дать подсказку для ускорения кода в 100 раз – оно того стоит.
Какой самый впечатляющий результат оптимизации кода вы получали с помощью ИИ-ассистентов?