
Применяемые в торговле для прогнозирования модели машинного обучения используют не только исторические цены на акции. Значимую информацию можно извлечь из отчётов по форме 10-К – годовых сводок финансовых результатов, подаваемых компаниями США в комиссию по ценным бумагам и биржам. Анализ отчёта и рыночного отклика на его публикацию помогают инвесторам сделать выводы о необходимости вложения средств в развитие компании. Ускорить процесс обработки данных позволяют технологии обработки естественного языка.
Обработка естественного языка

Обработка естественного языка (Natural Language Processing, NLP) – раздел когнитивных технологий, занимающийся обучением компьютеров чтению и извлечению смысла из различных форм речи. Чтобы понять текст, программа должна пройти ряд этапов.
- Сегментация предложений. Текстовый документ разбивается на отдельные предложения.
- Токенизация. Предложения разделяются на отдельные слова, которые называются токенами.
- Частеречная разметка. Каждый токен и несколько слов вокруг него вводятся в предварительно обученную модель классификации, чтобы получить на выходе часть речи.
- Лемматизация. Слова часто появляются в разных формах и контекстах. Чтобы компьютер мог выявлять разные формы одного слова, выполняется лемматизация – процесс группировки различных словоизменений для анализа их как единого элемента (идентифицируемого леммой слова).
- Стоп-слова. Распространенные части речи, такие как предлоги «и», «в», «на», не несут смысловой нагрузки, поэтому они идентифицируются как стоп-слова и исключаются из анализа текста.
- Анализ зависимостей. Назначение синтаксической структуры предложениям и выяснение, как слова в предложении соотносятся друг с другом.
- Субстантивные словосочетания. Группировка словосочетаний для упрощения предложений в тех случаях, когда мы не заботимся о прилагательных.
- Распознавание именованных сущностей. Модель распознавания именованных сущностей может помечать такие объекты, как имена людей, названия компаний и топонимы.
- Разрешение кореферентности. Поскольку модели NLP анализируют отдельные предложения, они «теряются» в местоимениях, относящихся к существительным из других предложений. Чтобы решить эту проблему, используется отслеживающее местоимения в разных предложениях разрешение кореферентности.
Импортируем всё необходимое
Для реализации проекта нам нужно будет использовать Pandas, Numpy и пакет для обработки естественного языка nltk. Попутно будут встречаться и другие библиотеки. Все они легко подключаются через инструмент pip.
# сторонние библиотеки
import nltk
import numpy as np
import pandas as pd
from tqdm import tqdm
# внутренние библиотеки
import pickle
import pprint
# модуль, описанный ниже
import project_helper
Также нам пригодятся специально написанные модули project_helper (нужно будет установить библиотеку ratelimit) и project_tests. Модуль project_helper содержит служебные и графические функции, project_tests – модульные тесты.
import matplotlib.pyplot as plt
import requests
from ratelimit import limits, sleep_and_retry # сторонняя библиотека
class SecAPI(object):
SEC_CALL_LIMIT = {'calls': 10, 'seconds': 1}
@staticmethod
@sleep_and_retry
# Dividing the call limit by half to avoid coming close to the limit
@limits(calls=SEC_CALL_LIMIT['calls'] / 2, period=SEC_CALL_LIMIT['seconds'])
def _call_sec(url):
return requests.get(url)
def get(self, url):
return self._call_sec(url).text
def print_ten_k_data(ten_k_data, fields, field_length_limit=50):
indentation = ' '
print('[')
for ten_k in ten_k_data:
print_statement = '{}{{'.format(indentation)
for field in fields:
value = str(ten_k[field])
# Show return lines in output
if isinstance(value, str):
value_str = '\'{}\''.format(value.replace('\n', '\\n'))
else:
value_str = str(value)
# Cut off the string if it gets too long
if len(value_str) > field_length_limit:
value_str = value_str[:field_length_limit] + '...'
print_statement += '\n{}{}: {}'.format(indentation * 2, field, value_str)
print_statement += '},'
print(print_statement)
print(']')
def plot_similarities(similarities_list, dates, title, labels):
assert len(similarities_list) == len(labels)
plt.figure(1, figsize=(10, 7))
for similarities, label in zip(similarities_list, labels):
plt.title(title)
plt.plot(dates, similarities, label=label)
plt.legend()
plt.xticks(rotation=90)
plt.show()
import numpy as np
import pandas as pd
from collections import OrderedDict
from tests import assert_output, project_test, assert_structure
@project_test
def test_get_documents(fn):
# Test 1
doc = '\nThis is inside the document\n' \
'This is the text that should be copied'
text = 'This is before the test document<DOCUMENT>{}</DOCUMENT>\n' \
'This is after the document\n' \
'This shouldn\t be included.'.format(doc)
fn_inputs = {
'text': text}
fn_correct_outputs = OrderedDict([
(
'extracted_docs', [doc])])
assert_output(fn, fn_inputs, fn_correct_outputs, check_parameter_changes=False)
# Test 2
ten_k_real_compressed_doc = '\n' \
'<TYPE>10-K\n' \
'<SEQUENCE>1\n' \
'<FILENAME>test-20171231x10k.htm\n' \
'<DESCRIPTION>10-K\n' \
'<TEXT>\n' \
'<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">\n' \
'<html>\n' \
' <head>\n' \
' <title>Document</title>\n' \
' </head>\n' \
' <body style="font-family:Times New Roman;font-size:10pt;">\n' \
'...\n' \
'<td><strong> Data Type:</strong></td>\n' \
'<td>xbrli:sharesItemType</td>\n' \
'</tr>\n' \
'<tr>\n' \
'<td><strong> Balance Type:</strong></td>\n' \
'<td>na</td>\n' \
'</tr>\n' \
'<tr>\n' \
'<td><strong> Period Type:</strong></td>\n' \
'<td>duration</td>\n' \
'</tr>\n' \
'</table></div>\n' \
'</div></td></tr>\n' \
'</table>\n' \
'</div>\n' \
'</body>\n' \
'</html>\n' \
'</TEXT>\n'
excel_real_compressed_doc = '\n' \
'<TYPE>EXCEL\n' \
'<SEQUENCE>106\n' \
'<FILENAME>Financial_Report.xlsx\n' \
'<DESCRIPTION>IDEA: XBRL DOCUMENT\n' \
'<TEXT>\n' \
'begin 644 Financial_Report.xlsx\n' \
'M4$L#!!0 ( %"E04P?(\\#P !," + 7W)E;,O+G)E;.MDD^+\n' \
'MPD ,Q;]*F?L:5\#8CUYZ6U9_ )Q)OU#.Y,A$[%^>X>];+=44/ 87O+>CT?V\n' \
'...\n' \
'M,C,Q7V1E9BYX;6Q02P$"% ,4 " !0I4%,>V7[]F0L 0!(@A %0\n' \
'M @ %N9@, 86UZ;BTR,#$W,3(S,5]L86(N>&UL4$L! A0#% @\n' \
'M4*5!3*U*Q:W#O0 U=\) !4 ( !!9,$ &%M>FXM,C Q-S$R\n' \
'@,S%?<)E+GAM;%!+!08 !@ & (H! #[4 4 !\n' \
'\n' \
'end\n' \
'</TEXT>\n'
real_compressed_text = '<SEC-DOCUMENT>0002014754-18-050402.txt : 20180202\n' \
'<SEC-HEADER>00002014754-18-050402.hdr.sgml : 20180202\n' \
'<ACCEPTANCE-DATETIME>20180201204115\n' \
'ACCESSION NUMBER: 0002014754-18-050402\n' \
'CONFORMED SUBMISSION TYPE: 10-K\n' \
'PUBLIC DOCUMENT COUNT: 110\n' \
'CONFORMED PERIOD OF REPORT: 20171231\n' \
'FILED AS OF DATE: 20180202\n' \
'DATE AS OF CHANGE: 20180201\n' \
'\n' \
'FILER:\n' \
'\n' \
' COMPANY DATA: \n' \
' COMPANY CONFORMED NAME: TEST\n' \
' CENTRAL INDEX KEY: 0001018724\n' \
' STANDARD INDUSTRIAL CLASSIFICATION: RANDOM [2357234]\n' \
' IRS NUMBER: 91236464620\n' \
' STATE OF INCORPORATION: DE\n' \
' FISCAL YEAR END: 1231\n' \
'\n' \
' FILING VALUES:\n' \
' FORM TYPE: 10-K\n' \
' SEC ACT: 1934 Act\n' \
' SEC FILE NUMBER: 000-2225413\n' \
' FILM NUMBER: 13822526583969\n' \
'\n' \
' BUSINESS ADDRESS: \n' \
' STREET 1: 422320 PLACE AVENUE\n' \
' CITY: SEATTLE\n' \
' STATE: WA\n' \
' ZIP: 234234\n' \
' BUSINESS PHONE: 306234534246600\n' \
'\n' \
' MAIL ADDRESS: \n' \
' STREET 1: 422320 PLACE AVENUE\n' \
' CITY: SEATTLE\n' \
' STATE: WA\n' \
' ZIP: 234234\n' \
'</SEC-HEADER>\n' \
'<DOCUMENT>{}</DOCUMENT>\n' \
'<DOCUMENT>{}</DOCUMENT>\n' \
'</SEC-DOCUMENT>\n'.format(ten_k_real_compressed_doc, excel_real_compressed_doc)
fn_inputs = {
'text': real_compressed_text}
fn_correct_outputs = OrderedDict([
(
'extracted_docs', [ten_k_real_compressed_doc, excel_real_compressed_doc])])
assert_output(fn, fn_inputs, fn_correct_outputs, check_parameter_changes=False)
@project_test
def test_get_document_type(fn):
doc = '\n' \
'<TYPE>10-K\n' \
'<SEQUENCE>1\n' \
'<FILENAME>test-20171231x10k.htm\n' \
'<DESCRIPTION>10-K\n' \
'<TEXT>\n' \
'<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">\n' \
'...'
fn_inputs = {
'doc': doc}
fn_correct_outputs = OrderedDict([
(
'doc_type', '10-k')])
assert_output(fn, fn_inputs, fn_correct_outputs, check_parameter_changes=False)
@project_test
def test_lemmatize_words(fn):
fn_inputs = {
'words': ['cow', 'running', 'jeep', 'swimmers', 'tackle', 'throw', 'driven']}
fn_correct_outputs = OrderedDict([
(
'lemmatized_words', ['cow', 'run', 'jeep', 'swimmers', 'tackle', 'throw', 'drive'])])
assert_output(fn, fn_inputs, fn_correct_outputs, check_parameter_changes=False)
@project_test
def test_get_bag_of_words(fn):
def sort_ndarray(array):
hashes = [hash(str(x)) for x in array]
sotred_indicies = sorted(range(len(hashes)), key=lambda k: hashes[k])
return array[sotred_indicies]
fn_inputs = {
'sentiment_words': pd.Series(['one', 'last', 'second']),
'docs': [
'this is a document',
'this document is the second document',
'last one']}
fn_correct_outputs = OrderedDict([
(
'bag_of_words', np.array([
[0, 0, 0],
[1, 0, 0],
[0, 1, 1]]))])
fn_out = fn(**fn_inputs)
assert_structure(fn_out, fn_correct_outputs['bag_of_words'], 'bag_of_words')
assert np.array_equal(sort_ndarray(fn_out.T), sort_ndarray(fn_correct_outputs['bag_of_words'].T)), \
'Wrong value for bag_of_words.\n' \
'INPUT docs:\n{}\n\n' \
'OUTPUT bag_of_words:\n{}\n\n' \
'A POSSIBLE CORRECT OUTPUT FOR bag_of_words:\n{}\n'\
.format(fn_inputs['docs'], fn_out, fn_correct_outputs['bag_of_words'])
@project_test
def test_get_jaccard_similarity(fn):
fn_inputs = {
'bag_of_words_matrix': np.array([
[0, 1, 1, 0, 0, 0, 1],
[0, 1, 2, 0, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0]])}
fn_correct_outputs = OrderedDict([
(
'jaccard_similarities', [0.7142857142857143, 0.0])])
assert_output(fn, fn_inputs, fn_correct_outputs, check_parameter_changes=False)
@project_test
def test_get_tfidf(fn):
def sort_ndarray(array):
hashes = [hash(str(x)) for x in array]
sotred_indicies = sorted(range(len(hashes)), key=lambda k: hashes[k])
return array[sotred_indicies]
fn_inputs = {
'sentiment_words': pd.Series(['one', 'last', 'second']),
'docs': [
'this is a document',
'this document is the second document',
'last one']}
fn_correct_outputs = OrderedDict([
(
'tfidf', np.array([
[0.0, 0.0, 0.0],
[1.0, 0.0, 0.0],
[0.0, 0.70710678, 0.70710678]]))])
fn_out = fn(**fn_inputs)
assert_structure(fn_out, fn_correct_outputs['tfidf'], 'tfidf')
assert np.isclose(sort_ndarray(fn_out.T), sort_ndarray(fn_correct_outputs['tfidf'].T)).all(), \
'Wrong value for tfidf.\n' \
'INPUT docs:\n{}\n\n' \
'OUTPUT tfidf:\n{}\n\n' \
'A POSSIBLE CORRECT OUTPUT FOR tfidf:\n{}\n'\
.format(fn_inputs['docs'], fn_out, fn_correct_outputs['tfidf'])
@project_test
def test_get_cosine_similarity(fn):
fn_inputs = {
'tfidf_matrix': np.array([
[0.0, 0.57735027, 0.57735027, 0.0, 0.0, 0.0, 0.57735027],
[0.0, 0.32516555, 0.6503311, 0.0, 0.42755362, 0.42755362, 0.32516555],
[0.70710678, 0.0, 0.0, 0.70710678, 0.0, 0.0, 0.0]])}
fn_correct_outputs = OrderedDict([
(
'cosine_similarities', [0.75093766927060945, 0.0])])
assert_output(fn, fn_inputs, fn_correct_outputs, check_parameter_changes=False)
Затем мы загружаем стоп-слова для их удаления и wordnet для лемматизации.
nltk.download('stopwords')
nltk.download('wordnet')
Всю дальнейшую обработку будем производить в Jupyter Notebook (GitHub-репозиторий).
Получение 10-К
Отчёты 10-K включают описание истории компании, организационной структуры, вознаграждений руководителей, собственного капитала, капитала дочерних компаний и аудиты финансовой отчётности. Для поиска документов можно использовать уникальный для каждой компании CIK (Central Index Key). Перечислим их примеры в виде словаря:
cik_lookup = {
'AMZN': '0001018724',
'BMY': '0000014272',
'CNP': '0001130310',
'CVX': '0000093410',
'FL': '0000850209',
'FRT': '0000034903',
'HON': '0000773840'}
Выведем для примера данные Amazon. Подключение к сайту, где хранятся отчёты, производится с помощью упомянутого выше модуля project_helper:
sec_api = project_helper.SecAPI()
from bs4 import BeautifulSoup
def get_sec_data(cik, doc_type, start=0, count=60):
rss_url = 'https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany' \
'&CIK={}&type={}&start={}&count={}&owner=exclude&output=atom' \
.format(cik, doc_type, start, count)
sec_data = sec_api.get(rss_url)
feed = BeautifulSoup(sec_data.encode('ascii'), 'xml').feed
entries = [
( entry.content.find('filing-href').getText(),
entry.content.find('filing-type').getText(),
entry.content.find('filing-date').getText())
for entry in feed.find_all('entry', recursive=False)]
return entries
example_ticker = 'AMZN'
sec_data = {}
for ticker, cik in cik_lookup.items():
sec_data[ticker] = get_sec_data(cik, '10-K')
pprint.pprint(sec_data[example_ticker][:5])
В результате получаем следующий вывод:
[('https://www.sec.gov/Archives/edgar/data/1018724/000101872420000004/0001018724-20-000004-index.htm',
'10-K',
'2020-01-31'),
('https://www.sec.gov/Archives/edgar/data/1018724/000101872419000004/0001018724-19-000004-index.htm',
'10-K',
'2019-02-01'),
('https://www.sec.gov/Archives/edgar/data/1018724/000101872418000005/0001018724-18-000005-index.htm',
'10-K',
'2018-02-02'),
('https://www.sec.gov/Archives/edgar/data/1018724/000101872417000011/0001018724-17-000011-index.htm',
'10-K',
'2017-02-10'),
('https://www.sec.gov/Archives/edgar/data/1018724/000101872416000172/0001018724-16-000172-index.htm',
'10-K',
'2016-01-29')]
Теперь у нас есть список URL-адресов, указывающих на файлы с метаданными, остаётся только забрать информацию:
raw_fillings_by_ticker = {}
for ticker, data in sec_data.items():
raw_fillings_by_ticker[ticker] = {}
for index_url, file_type, file_date in tqdm(data, desc='Downloading {} Fillings'.format(ticker), unit='filling'):
if (file_type == '10-K'):
file_url = index_url.replace('-index.htm', '.txt').replace('.txtl', '.txt')
raw_fillings_by_ticker[ticker][file_date] = sec_api.get(file_url)
print('Example Document:\n\n{}...'.format(next(iter(raw_fillings_by_ticker[example_ticker].values()))[:1000]))
Downloading AMZN Fillings: 100%|██████████| 25/25 [00:05<00:00, 4.88filling/s]
Downloading BMY Fillings: 100%|██████████| 30/30 [00:12<00:00, 2.49filling/s]
Downloading CNP Fillings: 100%|██████████| 22/22 [00:57<00:00, 2.61s/filling]
Downloading CVX Fillings: 100%|██████████| 28/28 [00:34<00:00, 1.24s/filling]
Downloading FL Fillings: 100%|██████████| 25/25 [00:25<00:00, 1.02s/filling]
Downloading FRT Fillings: 100%|██████████| 32/32 [00:36<00:00, 1.15s/filling]
Downloading HON Fillings: 29%|██▊ | 8/28 [00:10<00:25, 1.30s/filling]
Example Document:
<SEC-DOCUMENT>0001018724-20-000004.txt : 20200131
<SEC-HEADER>0001018724-20-000004.hdr.sgml : 20200131
<ACCEPTANCE-DATETIME>20200130204613
ACCESSION NUMBER: 0001018724-20-000004
CONFORMED SUBMISSION TYPE: 10-K
PUBLIC DOCUMENT COUNT: 109
CONFORMED PERIOD OF REPORT: 20191231
FILED AS OF DATE: 20200131
DATE AS OF CHANGE: 20200130
FILER:
COMPANY DATA:
COMPANY CONFORMED NAME: AMAZON COM INC
CENTRAL INDEX KEY: 0001018724
STANDARD INDUSTRIAL CLASSIFICATION: RETAIL-CATALOG & MAIL-ORDER HOUSES [5961]
IRS NUMBER: 911646860
STATE OF INCORPORATION: DE
FISCAL YEAR END: 1231
FILING VALUES:
FORM TYPE: 10-K
SEC ACT: 1934 Act
SEC FILE NUMBER: 000-22513
FILM NUMBER: 20562951
BUSINESS ADDRESS:
STREET 1: 410 TERRY AVENUE NORTH
CITY: SEATTLE
STATE: WA
ZIP: 98109
BUSINESS PHONE: 2062661000
MAIL ADDRESS:
STREET 1: 410 TERRY AVENUE NORTH
CITY: SEATTLE
STATE: WA
ZIP: 98109
</SEC-HEADER>
<DOCUMENT>
<TYPE>10-K
<SEQUENCE>1
<FILENAM...
Разобьем загруженные
файлы на документы по ограничивающим тегам <DOCUMENT> и </DOCUMENT>:
import re
def get_documents(text):
extracted_docs = []
doc_start_pattern = re.compile(r'<DOCUMENT>')
doc_end_pattern = re.compile(r'</DOCUMENT>')
doc_start_is = [x.end() for x in doc_start_pattern.finditer(text)]
doc_end_is = [x.start() for x in doc_end_pattern.finditer(text)]
for doc_start_i, doc_end_i in zip(doc_start_is, doc_end_is):
extracted_docs.append(text[doc_start_i:doc_end_i])
return extracted_docs
filling_documents_by_ticker = {}
for ticker, raw_fillings in raw_fillings_by_ticker.items():
filling_documents_by_ticker[ticker] = {}
for file_date, filling in tqdm(raw_fillings.items(), desc='Getting Documents from {} Fillings'.format(ticker), unit='filling'):
filling_documents_by_ticker[ticker][file_date] = get_documents(filling)
print('\n\n'.join([
'Document {} Filed on {}:\n{}...'.format(doc_i, file_date, doc[:200])
for file_date, docs in filling_documents_by_ticker[example_ticker].items()
for doc_i, doc in enumerate(docs)][:3]))
Getting Documents from AMZN Fillings: 100%|██████████| 20/20 [00:00<00:00, 71.03filling/s]
Getting Documents from BMY Fillings: 100%|██████████| 26/26 [00:00<00:00, 42.15filling/s]
Getting Documents from CNP Fillings: 100%|██████████| 18/18 [00:00<00:00, 33.56filling/s]
Getting Documents from CVX Fillings: 100%|██████████| 24/24 [00:00<00:00, 36.84filling/s]
Getting Documents from FL Fillings: 100%|██████████| 19/19 [00:00<00:00, 58.05filling/s]
Getting Documents from FRT Fillings: 100%|██████████| 22/22 [00:00<00:00, 58.46filling/s]
Getting Documents from HON Fillings: 100%|██████████| 23/23 [00:00<00:00, 46.45filling/s]
Document 0 Filed on 2020-01-31:
<TYPE>10-K
<SEQUENCE>1
<FILENAME>amzn-20191231x10k.htm
<DESCRIPTION>10-K
<TEXT>
<XBRL>
<?xml version="1.0" encoding="UTF-8"?>
<!--XBRL Document Created with Wdesk from Workiva-->
<!--p:c57a17684e854b...
Document 1 Filed on 2020-01-31:
<TYPE>EX-4.6
<SEQUENCE>2
<FILENAME>amzn-20191231xex46.htm
<DESCRIPTION>EXHIBIT 4.6
<TEXT>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>...
Document 2 Filed on 2020-01-31:
<TYPE>EX-21.1
<SEQUENCE>3
<FILENAME>amzn-20191231xex211.htm
<DESCRIPTION>EXHIBIT 21.1
<TEXT>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<ht...
Определим функцию
get_document_type() для возврата типа документа:
def get_document_type(doc):
type_pattern = re.compile(r'<TYPE>[^\n]+')
doc_type = type_pattern.findall(doc)[0][len('<TYPE>'):]
return doc_type.lower()
Отфильтруем с помощью написанной функции все не являющиеся отчетами документы из вложений:
ten_ks_by_ticker = {}
for ticker, filling_documents in filling_documents_by_ticker.items():
ten_ks_by_ticker[ticker] = []
for file_date, documents in filling_documents.items():
for document in documents:
if get_document_type(document) == '10-k':
ten_ks_by_ticker[ticker].append({
'cik': cik_lookup[ticker],
'file': document,
'file_date': file_date})
project_helper.print_ten_k_data(ten_ks_by_ticker[example_ticker][:5], ['cik', 'file', 'file_date'])
[
{
cik: '0001018724'
file: '\n<TYPE>10-K\n<SEQUENCE>1\n<FILENAME>amzn-2019123...
file_date: '2020-01-31'},
{
cik: '0001018724'
file: '\n<TYPE>10-K\n<SEQUENCE>1\n<FILENAME>amzn-2018123...
file_date: '2019-02-01'},
{
cik: '0001018724'
file: '\n<TYPE>10-K\n<SEQUENCE>1\n<FILENAME>amzn-2017123...
file_date: '2018-02-02'},
{
cik: '0001018724'
file: '\n<TYPE>10-K\n<SEQUENCE>1\n<FILENAME>amzn-2016123...
file_date: '2017-02-10'},
{
cik: '0001018724'
file: '\n<TYPE>10-K\n<SEQUENCE>1\n<FILENAME>amzn-2015123...
file_date: '2016-01-29'},
]
Предобработка данных
Удалим html-код и переведем все символы в строчные:
def remove_html_tags(text):
text = BeautifulSoup(text, 'html.parser').get_text()
return text
def clean_text(text):
text = text.lower()
text = remove_html_tags(text)
return text
Очистим документы с
помощью функции clean_text():
for ticker, ten_ks in ten_ks_by_ticker.items():
for ten_k in tqdm(ten_ks, desc='Cleaning {} 10-Ks'.format(ticker), unit='10-K'):
ten_k['file_clean'] = clean_text(ten_k['file'])
project_helper.print_ten_k_data(ten_ks_by_ticker[example_ticker][:5], ['file_clean'])
Cleaning AMZN 10-Ks: 100%|██████████| 20/20 [00:26<00:00, 1.31s/10-K]
Cleaning BMY 10-Ks: 100%|██████████| 26/26 [00:56<00:00, 2.17s/10-K]
Cleaning CNP 10-Ks: 100%|██████████| 18/18 [00:54<00:00, 3.02s/10-K]
Cleaning CVX 10-Ks: 100%|██████████| 24/24 [01:44<00:00, 4.33s/10-K]
Cleaning FL 10-Ks: 100%|██████████| 19/19 [00:21<00:00, 1.14s/10-K]
Cleaning FRT 10-Ks: 100%|██████████| 22/22 [00:43<00:00, 1.97s/10-K]
Cleaning HON 10-Ks: 100%|██████████| 23/23 [00:46<00:00, 2.02s/10-K]
[
{
file_clean: '\n10-k\n1\namzn-20191231x10k.htm\n10-k\n\n\n\n\n\...},
{
file_clean: '\n10-k\n1\namzn-20181231x10k.htm\n10-k\n\n\n\n\n\...},
{
file_clean: '\n10-k\n1\namzn-20171231x10k.htm\n10-k\n\n\n\n\n\...},
{
file_clean: '\n10-k\n1\namzn-20161231x10k.htm\nform 10-k\n\n\n...},
{
file_clean: '\n10-k\n1\namzn-20151231x10k.htm\nform 10-k\n\n\n...},
]
Лемматизируем данные:
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet
def lemmatize_words(words):
lemmatized_words = [WordNetLemmatizer().lemmatize(word, 'v') for word in words]
return lemmatized_words
word_pattern = re.compile('\w+')
for ticker, ten_ks in ten_ks_by_ticker.items():
for ten_k in tqdm(ten_ks, desc='Lemmatize {} 10-Ks'.format(ticker), unit='10-K'):
ten_k['file_lemma'] = lemmatize_words(word_pattern.findall(ten_k['file_clean']))
project_helper.print_ten_k_data(ten_ks_by_ticker[example_ticker][:5], ['file_lemma'])
Lemmatize AMZN 10-Ks: 100%|██████████| 20/20 [00:03<00:00, 5.4210-K/s]
Lemmatize BMY 10-Ks: 100%|██████████| 26/26 [00:04<00:00, 5.3810-K/s]
Lemmatize CNP 10-Ks: 100%|██████████| 18/18 [00:04<00:00, 3.9610-K/s]
Lemmatize CVX 10-Ks: 100%|██████████| 24/24 [00:04<00:00, 5.0810-K/s]
Lemmatize FL 10-Ks: 100%|██████████| 19/19 [00:02<00:00, 9.2110-K/s]
Lemmatize FRT 10-Ks: 100%|██████████| 22/22 [00:03<00:00, 7.0410-K/s]
Lemmatize HON 10-Ks: 100%|██████████| 23/23 [00:03<00:00, 7.6110-K/s]
[
{
file_lemma: '['10', 'k', '1', 'amzn', '20191231x10k', 'htm', '...},
{
file_lemma: '['10', 'k', '1', 'amzn', '20181231x10k', 'htm', '...},
{
file_lemma: '['10', 'k', '1', 'amzn', '20171231x10k', 'htm', '...},
{
file_lemma: '['10', 'k', '1', 'amzn', '20161231x10k', 'htm', '...},
{
file_lemma: '['10', 'k', '1', 'amzn', '20151231x10k', 'htm', '...},
]
Удаляем стоп-слова:
from nltk.corpus import stopwords
lemma_english_stopwords = lemmatize_words(stopwords.words('english'))
for ticker, ten_ks in ten_ks_by_ticker.items():
for ten_k in tqdm(ten_ks, desc='Remove Stop Words for {} 10-Ks'.format(ticker), unit='10-K'):
ten_k['file_lemma'] = [word for word in ten_k['file_lemma'] if word not in lemma_english_stopwords]
print('Stop Words Removed')
Remove Stop Words for AMZN 10-Ks: 100%|██████████| 20/20 [00:01<00:00, 15.8810-K/s]
Remove Stop Words for BMY 10-Ks: 100%|██████████| 26/26 [00:02<00:00, 9.8610-K/s]
Remove Stop Words for CNP 10-Ks: 100%|██████████| 18/18 [00:02<00:00, 7.5410-K/s]
Remove Stop Words for CVX 10-Ks: 100%|██████████| 24/24 [00:02<00:00, 9.4010-K/s]
Remove Stop Words for FL 10-Ks: 100%|██████████| 19/19 [00:01<00:00, 17.5510-K/s]
Remove Stop Words for FRT 10-Ks: 100%|██████████| 22/22 [00:01<00:00, 13.2810-K/s]
Remove Stop Words for HON 10-Ks: 100%|██████████| 23/23 [00:01<00:00, 15.1510-K/s]
Stop Words Removed
Анализ тональностей 10-К
Воспользуемся списком слов Loughran-McDonald для выполнения анализа тональностей текстов в 10-К. Он был специально разработан для текстового анализа с финансовой составляющей.
sentiments = ['negative', 'positive', 'uncertainty', 'litigious', 'constraining']
sentiment_df = pd.read_csv('loughran_mcdonald_master_dic_2018.csv')
sentiment_df.columns = [column.lower() for column in sentiment_df.columns]
# Удалим неиспользующуюся информацию
sentiment_df = sentiment_df[sentiments + ['word']]
sentiment_df[sentiments] = sentiment_df[sentiments].astype(bool)
sentiment_df = sentiment_df[(sentiment_df[sentiments]).any(1)]
# Применим ту же предобработку данных, что для отчетов 10-K
sentiment_df['word'] = lemmatize_words(sentiment_df['word'].str.lower())
sentiment_df = sentiment_df.drop_duplicates('word')
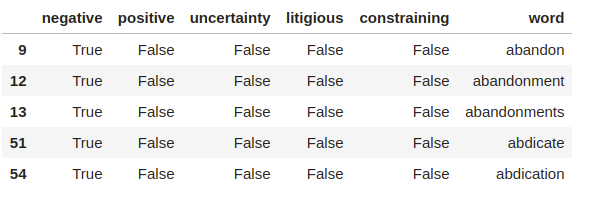
sentiment_df.head()
Создадим набор тональностей слов для документов 10-К, используя списки тональностей. Подсчитаем количество слов с определённой тональностью в каждом документе:
from collections import defaultdict, Counter
from sklearn.feature_extraction.text import CountVectorizer
def get_bag_of_words(sentiment_words, docs):
vec = CountVectorizer(vocabulary=sentiment_words)
vectors = vec.fit_transform(docs)
words_list = vec.get_feature_names()
bag_of_words = np.zeros([len(docs), len(words_list)])
for i in range(len(docs)):
bag_of_words[i] = vectors[i].toarray()[0]
return bag_of_words.astype(int)
sentiment_bow_ten_ks = {}
for ticker, ten_ks in ten_ks_by_ticker.items():
lemma_docs = [' '.join(ten_k['file_lemma']) for ten_k in ten_ks]
sentiment_bow_ten_ks[ticker] = {
sentiment: get_bag_of_words(sentiment_df[sentiment_df[sentiment]]['word'], lemma_docs)
for sentiment in sentiments}
project_helper.print_ten_k_data([sentiment_bow_ten_ks[example_ticker]], sentiments)
[
{
negative: '[[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ....
positive: '[[12 0 0 ... 0 0 0]\n [15 0 0 ... 0 0 0...
uncertainty: '[[0 0 0 ... 1 1 2]\n [0 0 0 ... 1 1 2]\n [0 0 0 ....
litigious: '[[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ....
constraining: '[[0 0 0 ... 0 0 2]\n [0 0 0 ... 0 0 2]\n [0 0 0 ....},
]
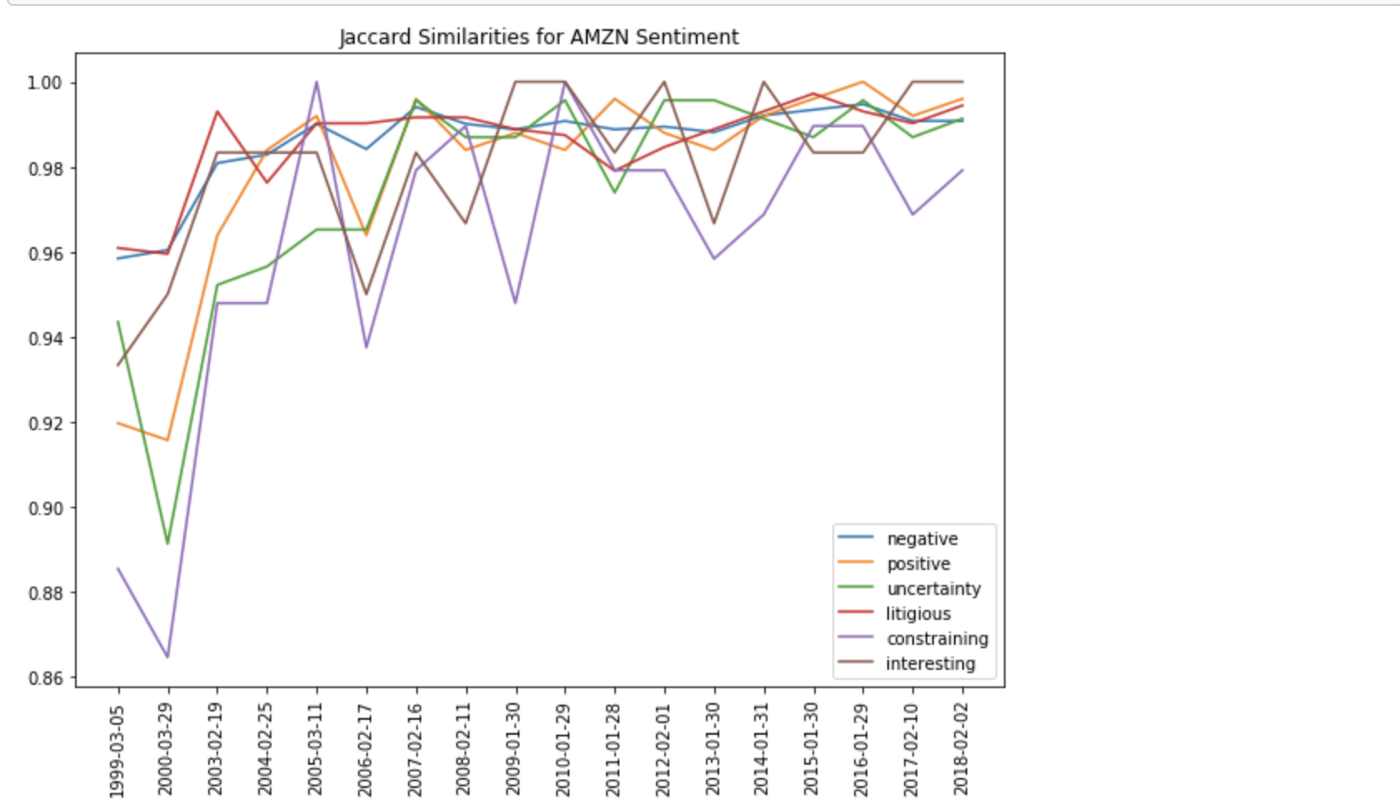
Сходство Жаккара
Когда у нас есть набор слов, мы можем преобразовать его в логический массив и вычислить коэффициент сходства Жаккара. Сходство определяется как размер пересечения множеств, поделенный на размер их объединения.
Например, сходство Жаккара между двумя предложениями – это количество общих слов в двух предложениях, поделенное на общее количество уникальных слов в обоих предложениях. Чем ближе значение сходства к 1, тем более похожи наборы. Для наглядности построим график коэффициента сходства Жаккара.
from sklearn.metrics import jaccard_similarity_score
def get_jaccard_similarity(bag_of_words_matrix):
jaccard_similarities = []
bag_of_words_matrix = np.array(bag_of_words_matrix, dtype=bool)
for i in range(len(bag_of_words_matrix)-1):
u = bag_of_words_matrix[i]
v = bag_of_words_matrix[i+1]
jaccard_similarities.append(jaccard_similarity_score(u,v))
return jaccard_similarities
# Get dates for the universe
file_dates = {
ticker: [ten_k['file_date'] for ten_k in ten_ks]
for ticker, ten_ks in ten_ks_by_ticker.items()}
jaccard_similarities = {
ticker: {
sentiment_name: get_jaccard_similarity(sentiment_values)
for sentiment_name, sentiment_values in ten_k_sentiments.items()}
for ticker, ten_k_sentiments in sentiment_bow_ten_ks.items()}
project_helper.plot_similarities(
[jaccard_similarities[example_ticker][sentiment] for sentiment in sentiments],
file_dates[example_ticker][1:],
'Jaccard Similarities for {} Sentiment'.format(example_ticker),
sentiments)
TF-IDF
Из списков слов тональности создадим term frequency – inverse document frequency (TF-IDF) для документов 10-К. TF-IDF – это метод поиска информации, используемый для выявления частоты появления слова в выбранной коллекции текста. Каждому слову/термину присваивается частота термина (TF) и обратная частота документа (IDF). Произведение этих оценок называется весом TF-IDF данного термина. Высокий вес TF-IDF указывает на редкие термины, а низкий – на более общие.
from sklearn.feature_extraction.text import TfidfVectorizer
def get_tfidf(sentiment_words, docs):
vec = TfidfVectorizer(vocabulary=sentiment_words)
tfidf = vec.fit_transform(docs)
return tfidf.toarray()
sentiment_tfidf_ten_ks = {}
for ticker, ten_ks in ten_ks_by_ticker.items():
lemma_docs = [' '.join(ten_k['file_lemma']) for ten_k in ten_ks]
sentiment_tfidf_ten_ks[ticker] = {
sentiment: get_tfidf(sentiment_df[sentiment_df[sentiment]]['word'], lemma_docs)
for sentiment in sentiments}
project_helper.print_ten_k_data([sentiment_tfidf_ten_ks[example_ticker]], sentiments)

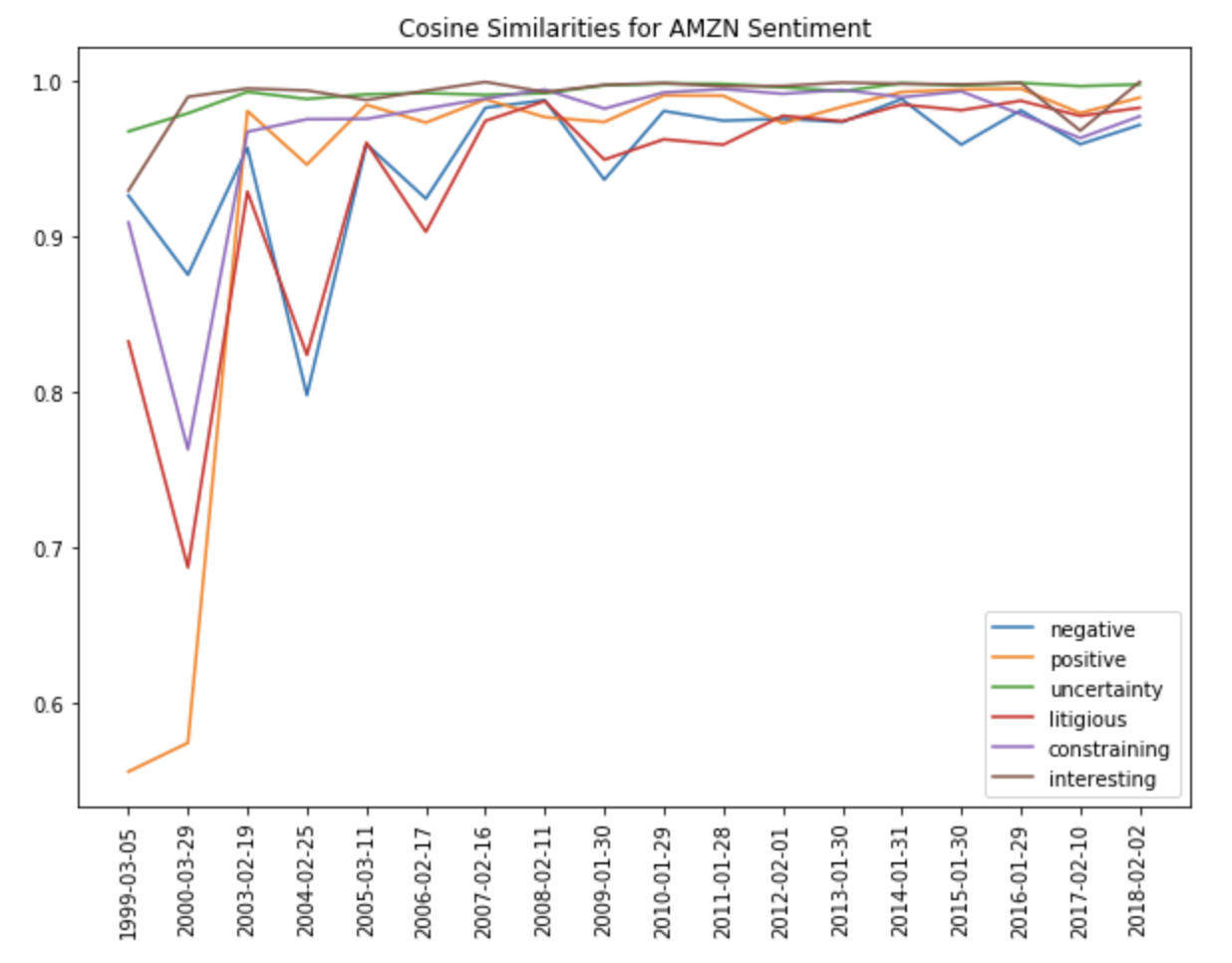
Косинусное сходство
Исходя из значений TF-IDF, мы можем вычислить косинусное сходство и построить его с учетом изменения времени. Подобно сходству Жаккара – это метрика, используемая для определения схожести документов. Косинус схожести вычисляет подобие независимо от размера, измеряя косинус угла между двумя векторами, проецируемыми в многомерном пространстве. Для текстового анализа обычно используются массивы, содержащие количество слов в двух документах.
from sklearn.metrics.pairwise import cosine_similarity
def get_cosine_similarity(tfidf_matrix):
cosine_similarities = []
for i in range(len(tfidf_matrix)-1):
cosine_similarities.append(cosine_similarity(tfidf_matrix[i].reshape(1, -1),tfidf_matrix[i+1].reshape(1, -1))[0,0])
return cosine_similarities
cosine_similarities = {
ticker: {
sentiment_name: get_cosine_similarity(sentiment_values)
for sentiment_name, sentiment_values in ten_k_sentiments.items()}
for ticker, ten_k_sentiments in sentiment_tfidf_ten_ks.items()}
project_helper.plot_similarities(
[cosine_similarities[example_ticker][sentiment] for sentiment in sentiments],
file_dates[example_ticker][1:],
'Cosine Similarities for {} Sentiment'.format(example_ticker),
sentiments)
Ценовые данные
Теперь мы оценим альфа-факторы, сравнив их с годовыми ценами на акции. Мы можем скачать данные о ценах из QuoteMedia.
pricing = pd.read_csv('yr-quotemedia.csv', parse_dates=['date'])
pricing = pricing.pivot(index='date', columns='ticker', values='adj_close')
pricing
Преобразование в датафрейм
Alphalens – использующая датафреймы библиотека Python для анализа производительности альфа-факторов поможет преобразовать наш словарь.
cosine_similarities_df_dict = {'date': [], 'ticker': [], 'sentiment': [], 'value': []}
for ticker, ten_k_sentiments in cosine_similarities.items():
for sentiment_name, sentiment_values in ten_k_sentiments.items():
for sentiment_values, sentiment_value in enumerate(sentiment_values):
cosine_similarities_df_dict['ticker'].append(ticker)
cosine_similarities_df_dict['sentiment'].append(sentiment_name)
cosine_similarities_df_dict['value'].append(sentiment_value)
cosine_similarities_df_dict['date'].append(file_dates[ticker][1:][sentiment_values])
cosine_similarities_df = pd.DataFrame(cosine_similarities_df_dict)
cosine_similarities_df['date'] = pd.DatetimeIndex(cosine_similarities_df['date']).year
cosine_similarities_df['date'] = pd.to_datetime(cosine_similarities_df['date'], format='%Y')
cosine_similarities_df.head()
Перед использованием функции alphalens нужно выровнять индексы и преобразовать
время в unix timestamp:
import alphalens as al
factor_data = {}
skipped_sentiments = []
for sentiment in sentiments:
cs_df = cosine_similarities_df[(cosine_similarities_df['sentiment'] == sentiment)]
cs_df = cs_df.pivot(index='date', columns='ticker', values='value')
try:
data = al.utils.get_clean_factor_and_forward_returns(cs_df.stack(), pricing.loc[cs_df.index], quantiles=5, bins=None, periods=[1])
factor_data[sentiment] = data
except:
skipped_sentiments.append(sentiment)
if skipped_sentiments:
print('\nSkipped the following sentiments:\n{}'.format('\n'.join(skipped_sentiments)))
factor_data[sentiments[0]].head()
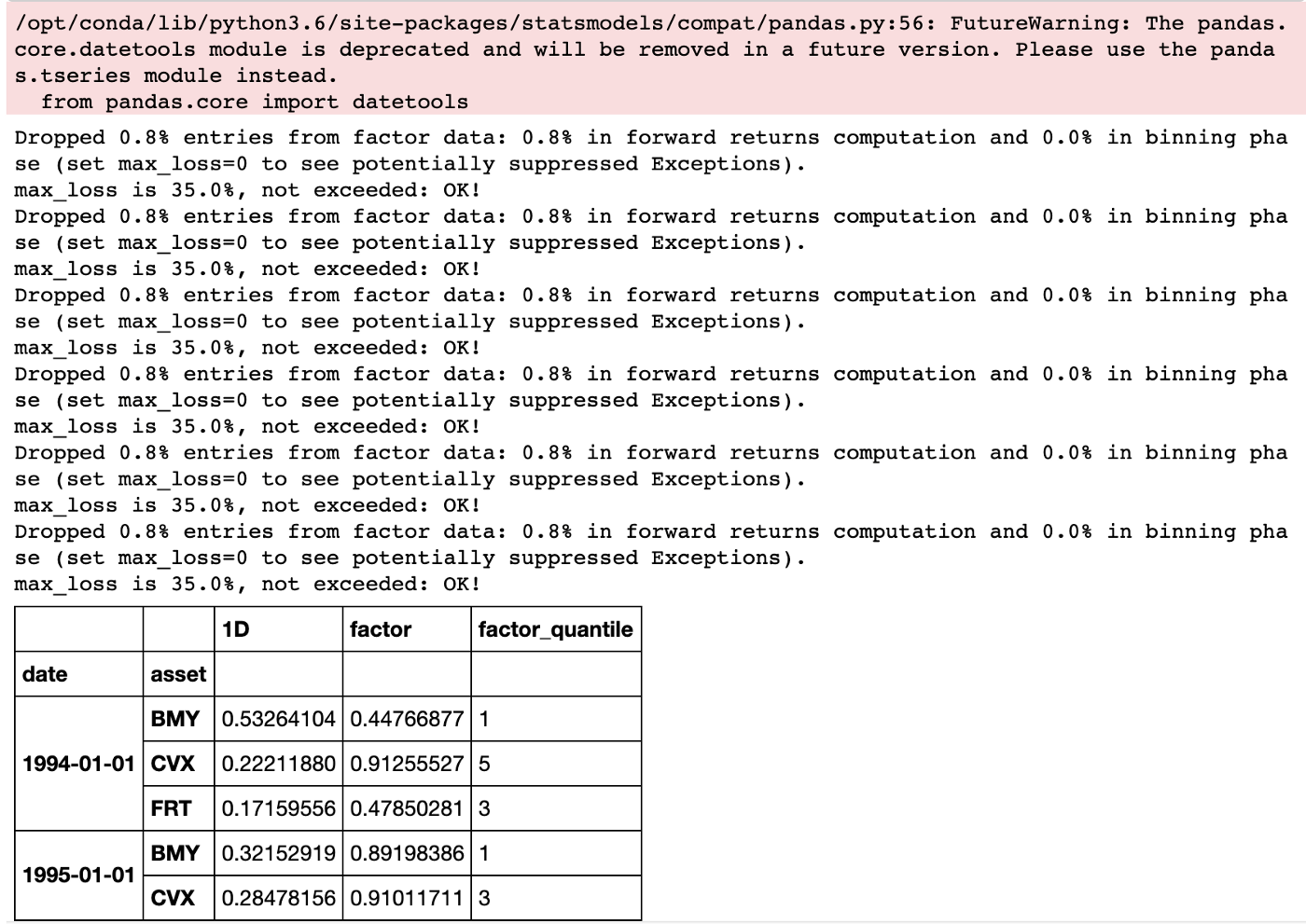
Мы также должны создать
факторные датафреймы с unix-временем для совместимости с alphalen-функциями:
factor_rank_autocorrelation и mean_return_by_quantile:
unixt_factor_data = {
factor: data.set_index(pd.MultiIndex.from_tuples(
[(x.timestamp(), y) for x, y in data.index.values],
names=['date', 'asset']))
for factor, data in factor_data.items()}
Коэффициент отдачи
Посмотрим на коэффициент отдачи с течением времени:
ls_factor_returns = pd.DataFrame()
for factor_name, data in factor_data.items():
ls_factor_returns[factor_name] = al.performance.factor_returns(data).iloc[:, 0]
(1 + ls_factor_returns).cumprod().plot()
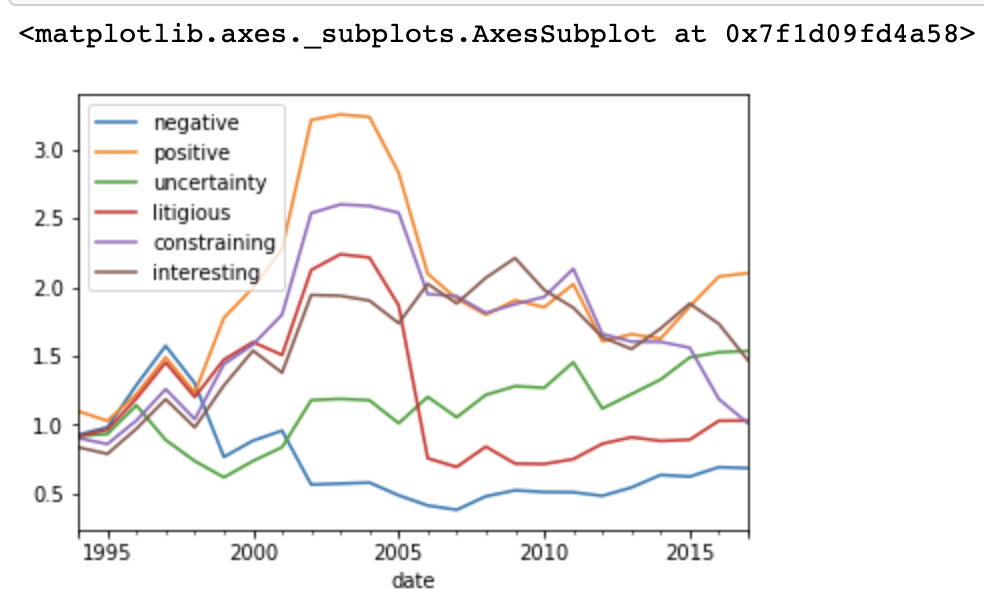
Выражающие позитивную тональность отчеты 10-К свидетельствуют о наибольшей прибыли, а негативные – об убытках.
Анализ оборота
Используя factor_rank_autocorrelation,
мы можем проанализировать, насколько устойчивы альфы с течением времени. Мы хотим, чтобы они оставались относительно одинаковыми от периода к периоду:
ls_FRA = pd.DataFrame()
for factor, data in unixt_factor_data.items():
ls_FRA[factor] = al.performance.factor_rank_autocorrelation(data)
ls_FRA.plot(title="Factor Rank Autocorrelation")

Коэффициент Шарпа
Теперь давайте рассчитаем коэффициент Шарпа, который представляет собой разность между средней доходностью и безрисковой доходностью, поделённой на стандартное отклонение доходности инвестиций.
daily_annualization_factor = np.sqrt(252)
(daily_annualization_factor * ls_factor_returns.mean() / ls_factor_returns.std()).round(2)

Коэффициент Шарпа 1 считается приемлемым, 2 – очень хорошим, а 3 – превосходным. Положительная тональность коррелирует с высоким коэффициентом Шарпа, а отрицательная – с низким. Другие настроения также коррелировали с высокими коэффициентами.
Заключение
В статье мы рассмотрели занимательную тему обработки естественного языка. Этот подход применяется на фондовых рынках, поскольку дает массу информации для понимания процессов и помогает инвесторам принять решение о вложении средств. Тема непростая, но она будет интересна не только работающим в финансовой сфере специалистам, но и Python-разработчикам, желающим окунуться в мир возвратов и оборотов.
Интересна ли вам тематика применения Data Science для анализа фондовых рынков?