

Если вы не знакомы ни с анализом данных, ни с программированием – можете смело пропускать блоки с кодом. Полученная из данных полезная информация сама расскажет историю. Если вы только знакомитесь с Data Science, этот текст даст вам множество примеров того, как можно анализировать данные и как проводить предварительную оценку информации по датасету.
В этой статье мы также проверим данные из СМИ и рассмотрим драматическую историю судна Diamond Princess. В конце публикации сделаем выводы о том, действительно ли стоит бояться нового коронавируса.
Коронавирус COVID-19 🦠
Сообщения о распространении вспышек болезни, даже из официальных правительственных источников, бывают противоречивыми, запоздалыми или просто недостоверными. При этом массовая истерия работает как телескоп: обыватель, находясь вдали от эпицентра заболевания, прислушивается к многочисленным сообщениям СМИ и относится к вирусу, как к непосредственной угрозе жизни. Такая картина складывается сейчас вокруг вспышки коронавируса в Китае.
В то время как алгоритмическое наблюдение за населением внедряется правительством Китая уже длительное время, такие системы не смогли остановить распространение болезни. Да, коронавирус представляет риск для здоровья, и есть причины для беспокойства, если вы живете в пострадавшем регионе или вступили в контакт с кем-то, кто приехал оттуда. Но важно попусту не впадать в панику.
Источники информации 📑
Очевидно, что общедоступные наборы данных не могут содержать точные имена пострадавших, не говоря уже о предполагаемых контактах. Лучшее, на что мы можем рассчитывать, – анализ совокупности агрегированных данных, в том числе метаданных, таких как сообщения в социальных сетях или информация об отмененных рейсах. Чтобы посмотреть последние новости о коронавирусе, приходящие со всего мира, полистайте микроблоги @COVID19Info и @DataCoronavirus.
Ищем открытые данные. Если мы попытаемся найти информацию на популярном сайте открытых данных data.gov, то поисковый запрос вернет шесть наборов данных для запроса «coronavirus». К сожалению, эти результаты соответствуют другому штамму коронавируса, о котором мы были наслышаны ранее – атипичной пневмонии. Они не учитывают штамм 2019 года.
Признанный источник информации. Для нового коронавируса центр системных наук и инженерии (CSSE) при университете Джона Хопкинса создал сайт с анализом авторитетных статистических данных, который называется глобальные случаи Coronavirus COVID-19. Панель построена на основе геоинформационной системы Esri. Вот как выглядел ресурс 26 февраля 2020 года.

Данные о случаях заражения нанесены на карту, видно число заболевших (confirmed), умерших (deaths) и выздоровевших (recovered). Источники данных перечислены на этой странице. Распределение случаев относительно времени приведено на следующем графике.
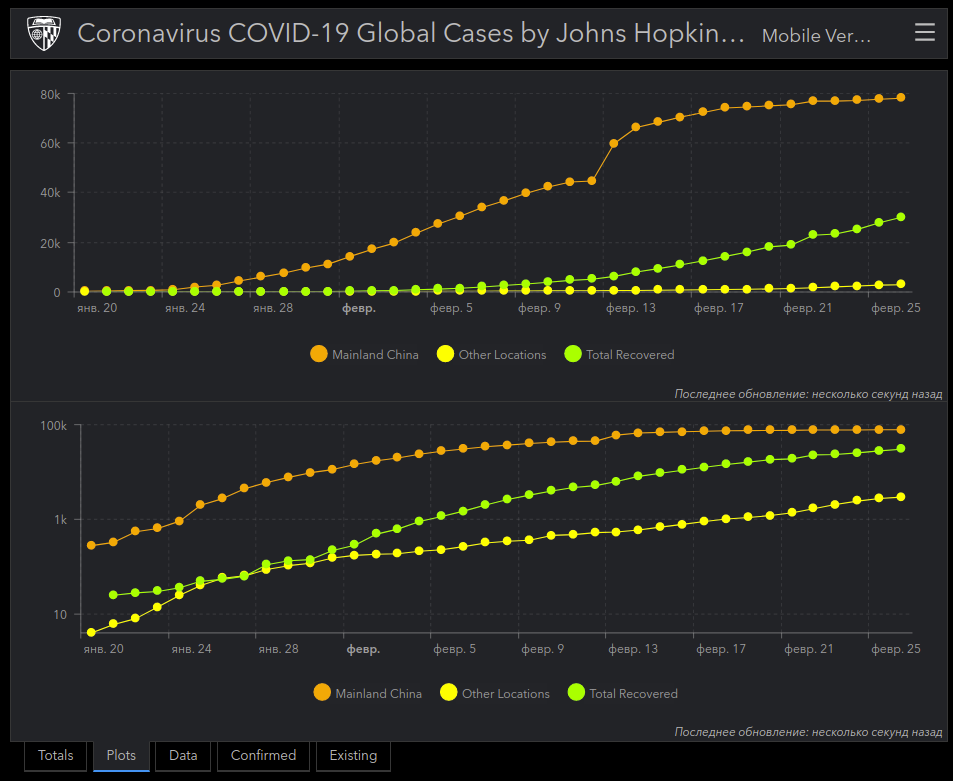
С чем связан скачок? 13 февраля количество зарегистрированных случаев подскочило с 45 тыс. до 60 тыс. из-за изменения методологии подсчёта. Ранее учитывались лишь лабораторно подтвержденные случаи заболевания. Это были точные данные, но приходящие с запаздыванием.
Теперь для подсчёта используется диагноз, основанный на клинических симптомах. В результате за один день было дополнительно зарегистрировано 13322 записей на основе симптомов, и ещё 1820 лабораторно подтвержденных заражений. То есть из 15 152 случаев лишь 12% были подтверждены лабораторно. Впоследствии некоторые из них будут отклонены как ошибочные диагнозы. Но исследователи осмотрительны и предпочитают принять здорового человека за больного, чем пропустить зараженного.
Если коротко. На 26 февраля зарегистрировано 81 тыс. больных, включая неподтвержденные в лаборатории случаи. Из их числа умерло 2762 человека, уже выздоровело 30 тыс. пациентов (37%). Лишь 3% случаев заражения зарегистрированы за пределами Китая.
Что ещё можно извлечь из этих данных 👁
Чтобы посмотреть исходники, мы зашли на страницу GitHub. Данные обновляются ежедневно и представлены в виде трех csv-файлов, соответствующих случаям заражения, смертей и выздоровления:
- time_series_19-covid-Confirmed.csv
- time_series_19-covid-Deaths.csv
- time_series_19-covid-Recovered.csv
Посмотреть структуру файлов можно прямо на GitHub:
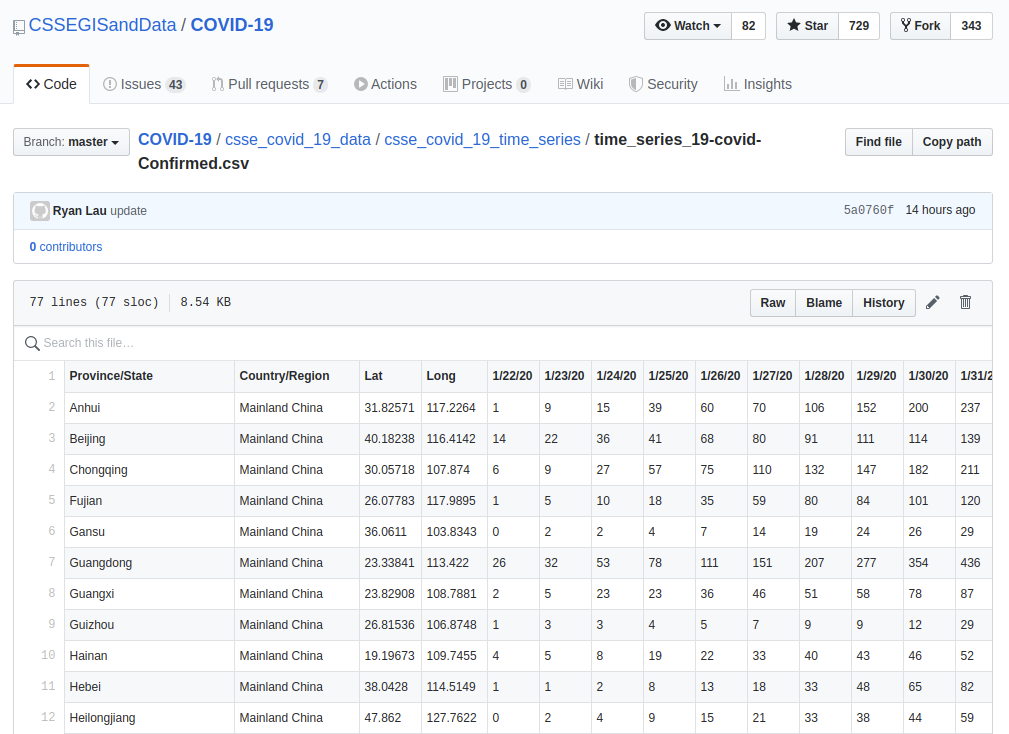
Это простейший формат электронной таблицы, в котором приведены данные за отчетный период в один день из каждого города или региона. К сожалению, отсутствуют метаданные, указывающие, какое смещение часового пояса используется (GMT или стандартное китайское время).
Представление в виде трех отдельных таблиц было преобразовано к более удобному файлу в виде набора данных на Kaggle. В этом файле временным рядам уже соответствуют не строки, а столбцы, и имеется по одному столбцу для каждой из категории заразившихся.
Приведенные данные мы обработали в Jupyter Notebook и выложили на GitHub. Далее статья дублирует файл для тех, кто не занимается анализом данных. Полученный блокнот Jupyter можно использовать для обновленного датасета и чтобы следить за развитием ситуации.
Импортируем библиотеки и изучаем данные🔬
Для обработки данных мы использовали библиотеки NumPy и Pandas, для визуализации – Matplotlib и Seaborn:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# считаем данные из csv файла
data = pd.read_csv("2019_nCoV_data.csv")
# определим размер набора данных
data.shape
На момент написания статьи (19 февраля) набор данных был очень невелик, и состоял всего из 1719 строк и 8 столбцов. Посмотрим на структуру файла, выведем первые 5 строк.
data.head()
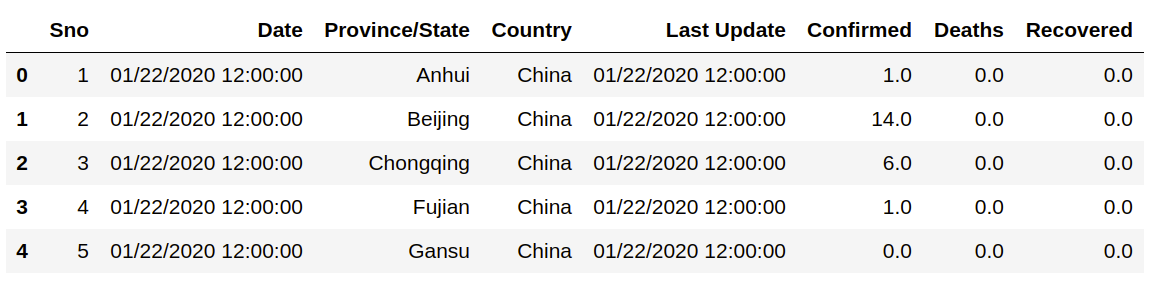
Столбец Sno соответствует номеру строки и не имеет особого значения для анализа. В столбце Last Update отображены те же времена, что и в столбце Date, за исключением нескольких случаев, когда числа обновлялись позже. Удалим Sno и Last Update, посмотрим какие данные хранятся в оставшихся столбцах:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1719 entries, 0 to 1718
Data columns (total 6 columns):
Date 1719 non-null object
Province/State 1257 non-null object
Country 1719 non-null object
Confirmed 1719 non-null float64
Deaths 1719 non-null float64
Recovered 1719 non-null float64
dtypes: float64(3), object(3)
memory usage: 80.7+ KB
Кроме Province/State все столбцы целиком заполнены. Это объясняется тем, что для ряда государств, например, России, указана только страна, без указания области. Информация о провинциях имеет решающее значение пока только для Китая. Большинство заболевших находится в провинции Хубэй.
Перейдем к категориям заболевших. Метод describe описывает общую статистику для каждого числового столбца.
data.describe()
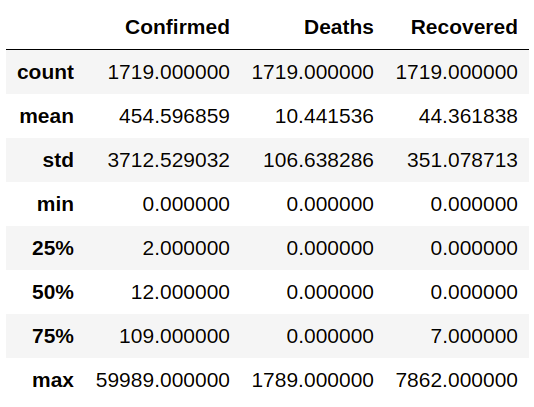
Из значений max следует, что данные в столбцах – кумулятивные. То есть в каждый день дается итог с накоплением. Датасет на Kaggle несколько отстает от данных в исходных CSV-файлах на GitHub (здесь мы видим 60 тыс. общих случаев против 75 тыс. текущих). Но для общего анализа зависимостей это не так важно.
Проверим данные на дубликаты. Метод duplicated() возвращает серию логических значений (равны True, если аналогичная строка уже имеется в наборе данных). Проверим, что никакие две записи не имеют одинаковые страну, область и дату.
>>> sum(data.duplicated(['Country', 'Province/State', 'Date']))
0
Cумма булевых значений может быть равна нулю только если все пункты равны False. Получается, что все строки набора данных уникальны.
Найдем страны, в которых были зарегистрированы случаи обнаружения коронавируса.
При предварительном анализе мы заметили, что в одних сообщениях в качестве страны указан просто Китай (China), в других – Континентальный Китай без Гонконга и Макао (Mainland China). Объединим данные для анализа и выведем общий список.
data.loc[data['Country'] == 'Mainland China', 'Country'] = 'China'
country_list = data['Country'].unique()
print('Коронавирус COVID19 обнаружен в {} странах:'.format(country_list.size))
for country in sorted(country_list):
print('- {}'.format(country))
Коронавирус COVID19 обнаружен в 33 странах:
- Australia
- Belgium
- Brazil
- Cambodia
- Canada
- China
- Egypt
- Finland
- France
- Germany
- Hong Kong
- India
- Italy
- Ivory Coast
- Japan
- Macau
- Malaysia
- Mexico
- Nepal
- Others
- Philippines
- Russia
- Singapore
- South Korea
- Spain
- Sri Lanka
- Sweden
- Taiwan
- Thailand
- UK
- US
- United Arab Emirates
- Vietnam
Можно видеть, что в списке есть Others (другие). Давайте узнаем, почему в каких-то случаях не была указана страна.
data[data['Country'] == 'Others']
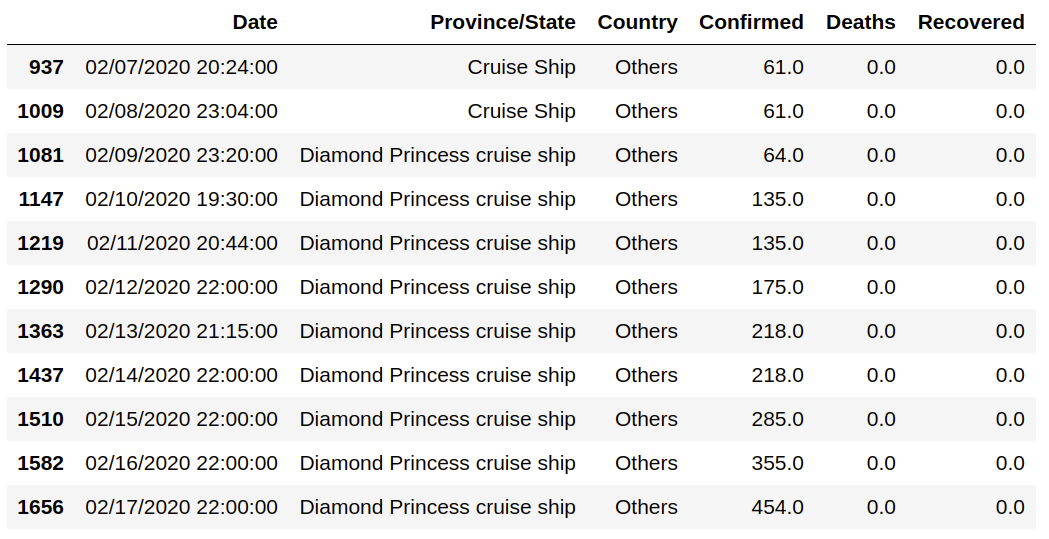
То есть эти случаи произошли не на территории какого-либо государства, а на большом судне, имени которого сначала не знали, а потом было определено, что это круизный лайнер Diamond Princess («Бриллиантовая принцесса»).

Россиянин Аркадий Булгатов вместе с другими пассажирами оказался на этом корабле. Его заметку о том, что проходило на судне, вы можете прочитать онлайн в журнале Esquire. Карантин был снят 19 февраля.
Посмотрим на ситуацию по России, отраженную в агрегированных данных.
data[data['Country'] == 'Russia']
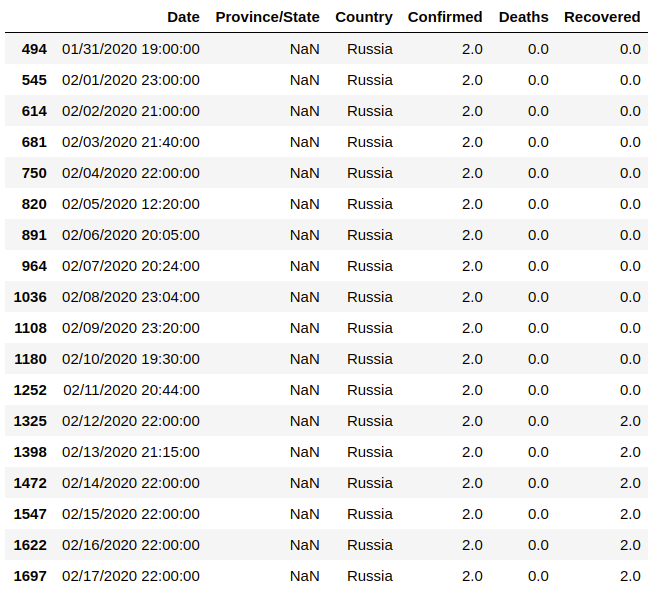
Стабильно указаны 2 пациента, которые по сведениям датасета после 11 февраля были признаны выздоровевшими. Действительно, 12 февраля Газета.ру написала, о том, что в Чите выздоровел второй человек в России, болевший коронавирусом: гражданину КНР Ван Юньбиню вручили документы о выписке.
Это два подтвержденных случая болезни. В то же время в Петербурге из Боткинской больницы постоянно сбегают из-под карантина пациенты, находящиеся под подозрением.
Проанализируем, как часто поступают данные.
>>> print(list(data['Date'].unique()))
['01/22/2020 12:00:00', '01/23/2020 12:00:00', '01/24/2020 12:00:00',
'01/25/2020 22:00:00', '01/26/2020 23:00:00', '01/27/2020 20:30:00',
'01/28/2020 23:00:00', '01/29/2020 21:00:00', '01/30/2020 21:30:00',
'01/31/2020 19:00:00', '02/01/2020 23:00:00', '02/02/2020 21:00:00',
'02/03/2020 21:40:00', '02/04/2020 22:00:00', '02/05/2020 12:20:00',
'02/06/2020 20:05:00', '02/07/2020 20:24:00', '02/08/2020 23:04:00',
'02/09/2020 23:20:00', '02/10/2020 19:30:00', '02/11/2020 20:44:00',
'02/12/2020 22:00:00', '02/13/2020 21:15:00', '02/14/2020 22:00:00',
'02/15/2020 22:00:00', '02/16/2020 22:00:00', '02/17/2020 22:00:00']
Итак, данные ведут отсчет с 22 января. Время дня разнится. Приведем даты к единообразному представлению.
data['Date'] = pd.to_datetime(data['Date'])
data['Date_date'] = data['Date'].apply(lambda x:x.date())
df_by_date=data.groupby(['Date_date']).sum().reset_index(drop=None)
Посмотрим, как повлияла эпидемия на различные страны.
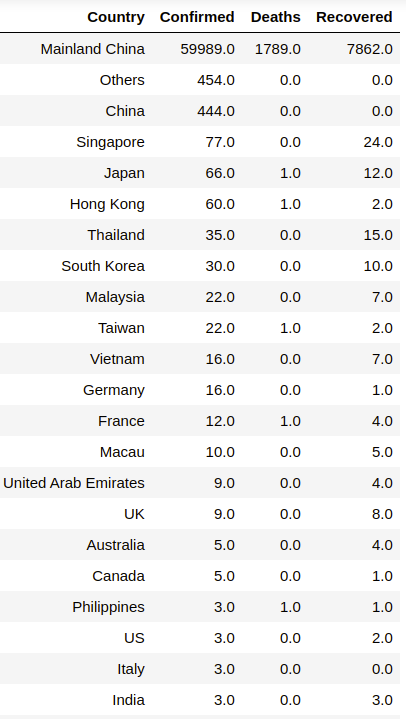
Данные подтверждают, что в Китае зарегистрировано наибольшее количество случаев болезни и основное число смертельных случаев. Кроме Китая очаг незначительно перекинулся на другие страны Восточной Азии. Первая смерть среди стран Европы произошла во Франции (умер турист из Китая).
Визуализируем данные 💁📈
Для визуализации данных мы используем две библиотеки Python – Matplotlib и Seaborn. Matplotlib – библиотека 2D-визуализации, используемая большинством исследователей данных. Seaborn построен поверх matplotlib и помогает создавать более привлекательные и сложные представления информации.
1. Временная зависимость количества подтвержденных случаев
Для начала проверим, что используемые на сайте данные соответствуют тем, которые мы забрали с Kaggle. Проверим, есть ли на данных тот же скачок.
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = [12.0, 5.0]
mpl.rcParams['figure.dpi'] = 100
sns.set()
plt.plot(df_by_date["Date_date"],
df_by_date["Confirmed"]/1000,
'o:')
plt.xlabel('Дата')
plt.ylabel('Число подтвержденных случаев, тыс. чел.')
plt.show()
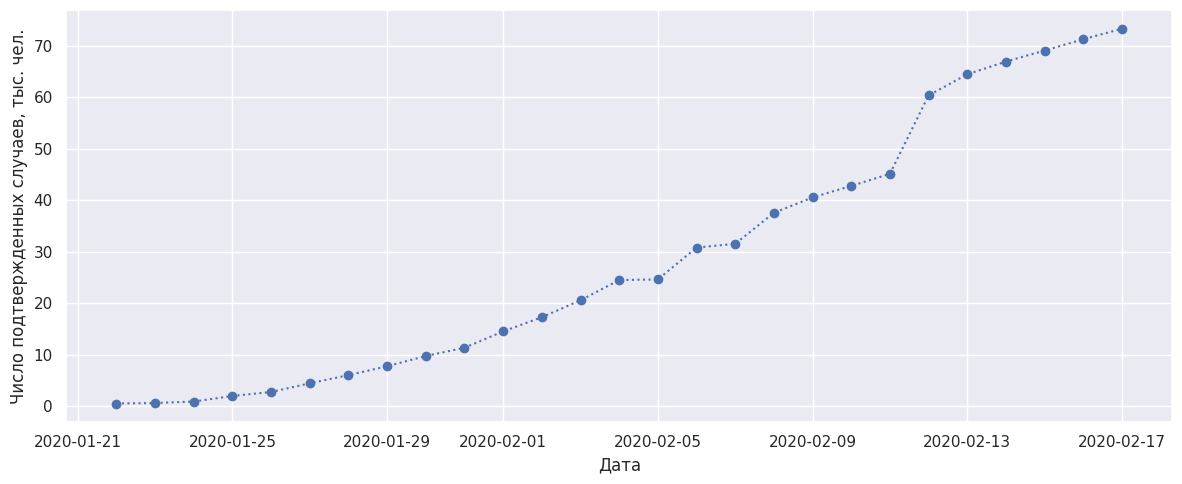
Да, скачок есть, всё соответствует данным с сайта, но теперь мы можем оформлять данные в своем стиле.
2. Число умерших и выздоровевших
Определим, как менялось со временем число людей, которые умерли или выздоровели.
d = {"Deaths":"Умерли", "Recovered":"Выздоровели"}
for label in d:
plt.plot(df_by_date["Date_date"],
df_by_date[label]/1000,
label=d[label])
plt.ylabel('Число случаев, тыс. человек')
plt.xlabel('Дата')
plt.legend()
plt.show()
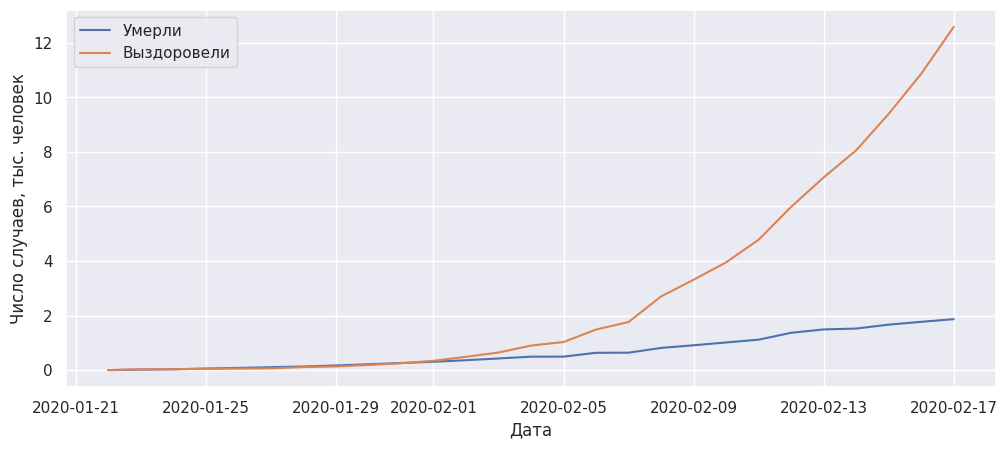
Видно, что сейчас наблюдается рост обеих групп с превалирующим числом выздоровевших пациентов. Так как изменение составляет несколько порядков величины, построим данные в полулогарифмическом масштабе.
plt.yscale('log')
for label in d:
plt.plot(df_by_date["Date_date"],
df_by_date[label]/1000,
label=d[label])
plt.ylabel('Число случаев, тыс. человек')
plt.xlabel('Дата')
plt.legend()
plt.show()
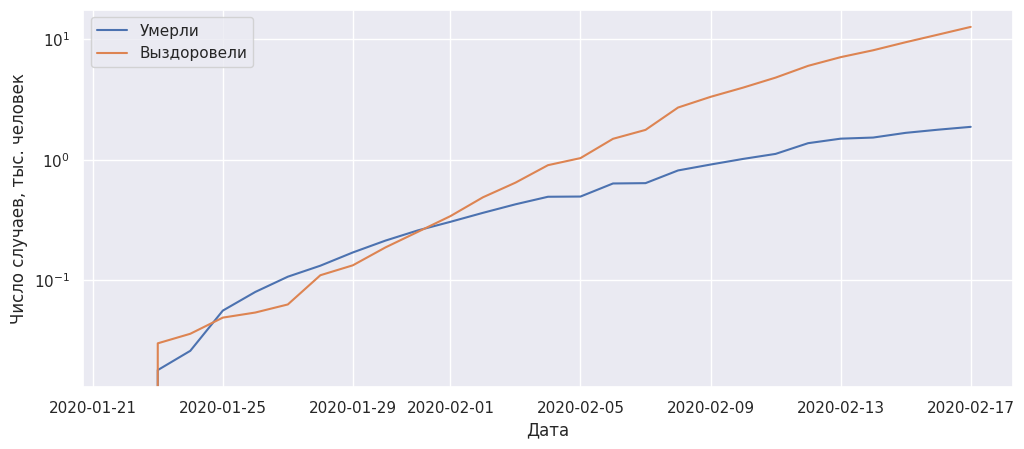
Можно видеть, что число выздоровевших пациентов начало превышать число умирающих в начале февраля.
3. Грубая оценка летальности
Meduza уже писала о том, что для определения смертельности неверно делить число умерших на число заболевших. Подсчитать летальность простым делением можно только для закончившихся эпидемий, а вспышка COVID-19 продолжается. Но данное число можно использовать как грубую оценку.
plt.plot(df_by_date["Date_date"],
df_by_date['Deaths']/df_by_date['Confirmed']*100)
plt.ylabel('Доля умерших среди зараженных, %')
plt.xlabel('Дата')
plt.show()
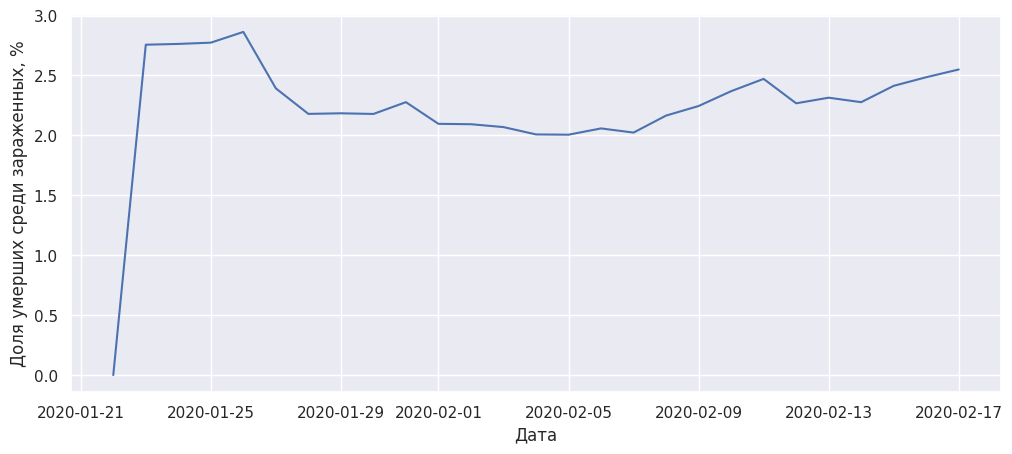
Текущие значения колеблются между 2 и 3 процентами. Сравним рассмотренную динамику летальности с динамикой выздоровления.
for label in d:
plt.plot(df_by_date["Date_date"],
df_by_date[label]/df_by_date['Confirmed']*100,
label=d[label])
plt.ylabel('Доли умерших и выздоровевших зараженных, %')
plt.xlabel('Дата')
plt.legend()
plt.show()
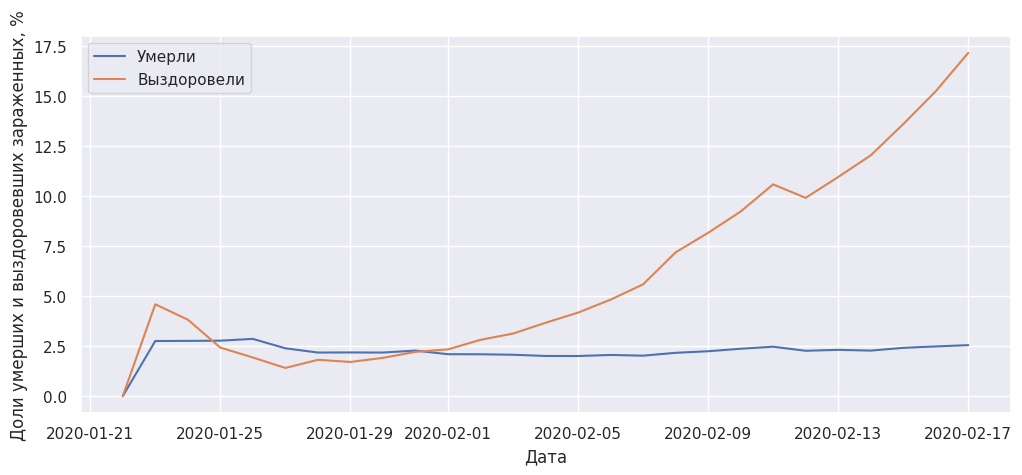
В процентном отношении динамика роста выздоровевших обнадеживает.
4. Лайнер Diamond Princess
Рассмотрим упоминавшийся случай – насколько критично нахождение в замкнутом пространстве круизного лайнера. Сравним, как развивалась ситуация в провинции Хубэй, ставшей очагом распространения болезни с тем, как сложились обстоятельства в случае карантина на лайнере Diamond Princess.
diamond = data[data["Country"]=="Others"]
hubei = data[data["Province/State"]=="Hubei"]
plt.plot(diamond["Date"],
diamond["Confirmed"]/3700,
label='Лайнер "Diamond Princess"')
plt.plot(df_by_date["Date_date"],
df_by_date["Confirmed"]/58e6,
label="Провинция Хубэй")
plt.yscale('log')
plt.xlabel("Дата")
plt.ylabel("Доля зараженных")
plt.legend()
plt.show()
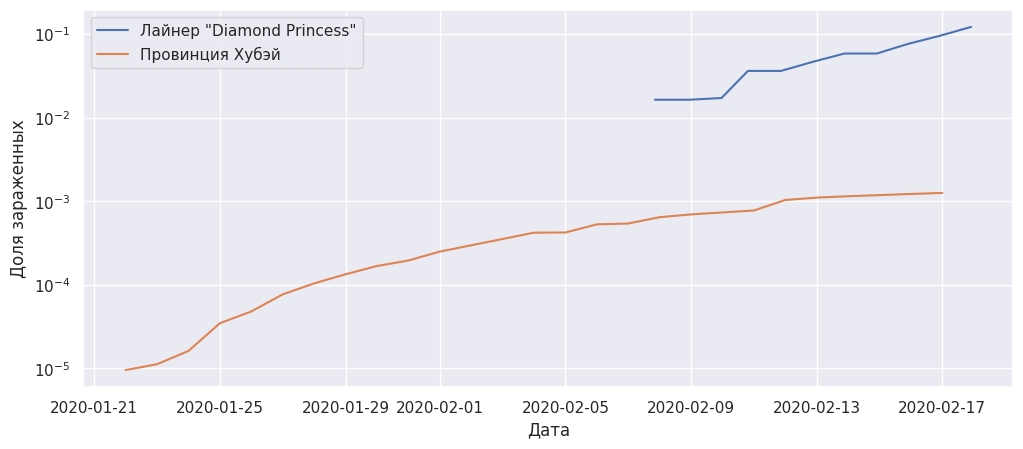
Чтобы сравнить графики, нам пришлось привести ось ординат к логарифмическому масштабу. Доля зараженных людей в случае замкнутого пространства круизного лайнера на 1-2 порядка (в 10-100 раз) превышает долю людей в очаге развития болезни, где люди, несмотря на распространение эпидемии, оказываются в менее тесных условиях и могут меньше контактировать с заболевшими.
Заключение
Итак, число случаев заболевания вирусом COVID-19 стремительно растёт. Однако это не должно вызывать паники:
- Очаг вируса имеет локализованный характер. Большинство заболевших сконцентрированы в провинции Китая Хубей. Примерно половина зараженных за пределами Китая – это пассажиры и члены команды круизного лайнера Diamond Princess.
- Текущая летальность вируса по грубой оценке колеблется в диапазоне 2–3%. Эта оценка также попадает в более строго рассчитанный коридор в 0,4–4%. Для сравнения: летальность другого коронавируса, атипичной пневмонии составляет 9,6%.
- В течение первой недели летальность доминировала над выздоравливаемостью, но сейчас вылечивается всё больше людей.
То есть коронавирус может быть для вас опаснее сезонного гриппа только если вы находитесь в эпицентре событий.
Другие статьи Библиотеки программиста по тематике Data Science:
- Data Science: эффективный учебный план
- 6 шагов, которые помогут стать специалистом по Data Science
- Как изучать Data Science: ответы на частые вопросы
Эти три – для новичков. А если вы уже разбираетесь – просто смотрите, как много всего есть по тегу Data Science.
Источники
- https://towardsdatascience.com/chasing-the-data-coronavirus-802d8a1c4e9a
- https://towardsdatascience.com/a-data-scientists-perspective-on-the-wuhan-coronavirus-4d1110446478
- https://towardsdatascience.com/what-can-data-visualization-help-in-the-battle-against-the-novel-coronavirus-bad9b2c7fb2b
- https://towardsdatascience.com/visualizing-the-progression-of-the-coronavirus-outbreak-a586cf1dc879
Комментарии