

Текст представляет собой сокращенный перевод объемного руководства Дэна Хипшмана Python Microservices With gRPC.
Микросервисная архитектура – способ организации сложных программных систем: приложение разбивается на сервисы, которые развертываются независимо, но взаимодействуют друг с другом. Из этого руководства вы узнаете, как приступить к работе с микросервисами Python с помощью gRPC – одного из самых популярных фреймворков в этой сфере.
К концу прохождения туториала вы сможете:
- реализовать микросервисную архитектуру с помощью Python, gRPC и Docker-контейнеров,
- применить юнит-тестирование и интеграционное тестирование к микросервисной архитектуре.
Исходный код этого туториала доступен в репозитории RealPython.
Чем так хороша микросервисная архитектура?
Представим, что вы работаете в компании, создающей популярный сайт, продающий книги. В компании несколько сотен разработчиков, каждый пишет код для некоторого продукта или внутренней функции. Например, управление корзиной покупок, создание рекомендаций, обработка платежных транзакций и задач логистики.
Хотим ли мы, чтобы весь код был в одном гигантском приложении? Конечно, нет – мы бы предпочли, чтобы код, соответствующий модульным функциям продукта, тоже был модульным: микросервис cart для управления корзиной, микросервис inventory для инвентаризации и складского учета.
Модульность
Изменение кода обычно происходит по пути наименьшего сопротивления. Представим, что генеральный директор хочет добавить новую функцию «при покупке более двух книг одна книга в подарок». Вы – член команды, которую попросили запустить функцию. Посмотрим, что происходит, когда весь код находится в одном приложении.
Вы предлагаете добавить код в логику корзины, чтобы проверить, есть ли в ней более двух книг. Далее вычитаем стоимость самой дешевой книги из общей суммы корзины. Нет проблем – делаем pull request.
Затем продакт-менеджер замечает, что нужно также отслеживать влияние кампании на продажи книг. Это тоже довольно просто. Поскольку логика, реализующая функцию, находится в коде корзины, достаточно добавить строку в поток оформления заказа. Будем обновлять столбец в базе данных транзакций, указав, что продажа была частью рекламной акции: buy_two_get_one_free_promo. Выполнено.
Затем нам напоминают, что акция действует для каждого покупателя только один раз. То есть нужно добавить некоторую логику, чтобы проверить, был ли установлен флаг buy_two_get_one_free_promo для каких-либо предыдущих транзакций. Соответственно нужно скрыть и рекламный баннер на главной странице, поэтому мы также добавляем эту проверку. Так, а ещё нужно отправлять электронные письма тем, кто еще не поучаствовал в промо-акции... Добавим и это.
Спустя несколько лет база данных транзакций оказывается слишком большой, и ее необходимо заменить новой общей базой данных. Все эти ссылки потребуется изменить. Но к сожалению, текущая база данных упоминается по всей кодовой базе.
Размещение всего кода в одном приложении в долгосрочной перспективе может быть опасным. Иногда хорошо расчертить границы ответственности. База данных транзакций должна быть доступна только микросервису транзакций. Другие части кода могут взаимодействовать с сервисом транзакций через абстрактный API, скрывающий внутренние детали реализации.
Гибкость
Разделение кода на микросервисы дает большую гибкость. Можно писать свои микросервисы на разных языках. Например, нередко первое веб-приложение компании пишется на Ruby или PHP. Но это не означает, что все остальное тоже должно работать на этих языках!
Каждый микросервис можно независимо масштабировать. Например, в этом руководстве в качестве рабочего примера мы рассмотрим веб-приложение и микросервис с рекомендациями. Веб-приложение, скорее всего, будет управлять вводом-выводом, извлечением информации из баз данных и, загрузкой шаблонов и других файлов с диска. В то же время микросервис рекомендаций работает иначе – обычно он выполняет множество вычислений на основе машинного обучения и может ограничивать возможности центрального процессора. Поэтому даже имеет смысл запускать эти два микросервиса Python на различном оборудовании.
Если весь ваш код находится в одном приложении, развертывать его придется тоже целиком. Это рискованно – изменение одной небольшой части кода может привести к выходу из строя всего сайта.
Разграничение ответственности
Когда одна кодовая база используется большим количеством людей, часто нет четкого видения архитектуры кода. Особенно это касается крупных компаний, где сотрудники приходят и уходят. Могут быть люди, у которых есть видение того, как должен выглядеть код, но его трудно добиться, когда кодовая база быстро меняется.
Одним из преимуществ микросервисов является то, что команды могут четко разграничивать свой код. Это увеличивает вероятность того, что в каждой команде будет достаточно четкое видение своей части программного обеспечения, код останется чистым и организованным. Это также дает понять, кто несет ответственность за добавление функций в код или внесение изменений, если что-то пойдет не так.
Почему же «микро»? Насколько должен быть мал отдельный сервис?
Насколько маленькими должны быть микросервисы – одна из тех тем, которые могут вызвать жаркие споры среди разработчиков. Вставим свои пару копеек: микро – не совсем подходящая приставка. Проще говорить просто о сервисах.
Слишком маленький размер микросервисов может привести к проблемам. Прежде всего, это фактически противоречит цели создания модульного кода. Приведем аналогию. Файловый объект Python имеет все необходимые методы. Мы можем использовать .read() и .write(), или, если хотим, .readlines(). Нам не нужны отдельные модули или классы FileReader и FileWriter. Возможно, вы знакомы с языками, в которых так делается, и, может быть, вам уже казалось, что это немного громоздко и запутанно. С микросервисами дела обстоят так же.
Микросервисы труднее тестировать, чем монолитный код. Если разработчик хочет протестировать функцию, которая распространяется на множество микросервисов, ему необходимо запустить все это в своей среде разработки. С несколькими микросервисами все не так плохо, но если их десятки, это может стать трудной задачей.
Следует обратить внимание на то, что каждая команда должна работать с вменяемым количеством микросервисов. Команда из пяти человек не может работать над двадцатью сервисами.
Пример того, как можно разбить гипотетический книжный онлайн-магазин на микросервисы:
Marketplaceобслуживает логику навигации пользователя по сайту.Cartотслеживает, что пользователь положил в свою корзину и процесс оформления заказа.Transactionsобрабатывают платежи и отправляют квитанции.Inventoryпредоставляет данные о том, какие книги есть в наличии.User Accountуправляет регистрацией пользователей и данными учетной записи, например, изменением паролей.Reviewsхранит оценки книг и отзывы, введенные пользователями.
Это всего лишь несколько примеров, а не исчерпывающий список. Однако вы можете видеть, что логика каждого из них относительно независима. Кроме того, если микросервис Reviews был развернут с ошибкой, пользователь все равно сможет использовать сайт и совершать покупки, несмотря на то, что отзывы временно не загружаются.
Компромисс между микросервисной и монолитной архитектурами
Микросервисы не всегда лучше монолитов, в которых весь код хранится в одном приложении. Как правило, (и особенно в начале жизненного цикла разработки программного обеспечения) монолитная архитектура позволяет двигаться быстрее. Она упрощает совместное использование кода и добавление новых функций, а необходимость развертывания только одной службы помогает быстро предоставить приложение пользователям.
Компромисс заключается в том, что по мере роста сложности кодовой базы все эти вещи могут постепенно затруднять разработку, замедлять развертывание и делать его более хрупким. То есть монолитная архитектура сэкономит время и усилия на начальном этапе, но в дальнейшем может застопорить развитие. Внедрение микросервисов будет стоить вам времени и усилий в краткосрочной перспективе, но если все сделано правильно, в долгосрочной перспективе вы сможете лучше масштабироваться.
Типичный цикл запуска в Кремниевой долине начинается с монолитной архитектуры, обеспечивающей быстрое итерирование по мере того, как бизнес находит продукт, подходящий клиентам. После того как компания разработала успешный продукт и наняла больше инженеров, пора задуматься о микросервисах. Не внедряйте их слишком рано, но и не затягивайте.
Чтобы узнать больше о различиях между микросервисами и монолитами, обратите внимание на отличное обсуждение Сэма Ньюмана и Мартина Фаулера «Когда использовать микросервисы (а когда нет)».
Пример микросервисной архитектуры
Начнем работу над нашим практическим примером. Шаг за шагом мы создадим два связанных между собой микросервиса и API их взаимодействия:
Marketplace– минималистичное веб-приложение, отображающее полный список книг, продаваемых на сайте.Recommendations– микросервис, предоставляющий список книг, которые могут быть интересны конкретному пользователю.
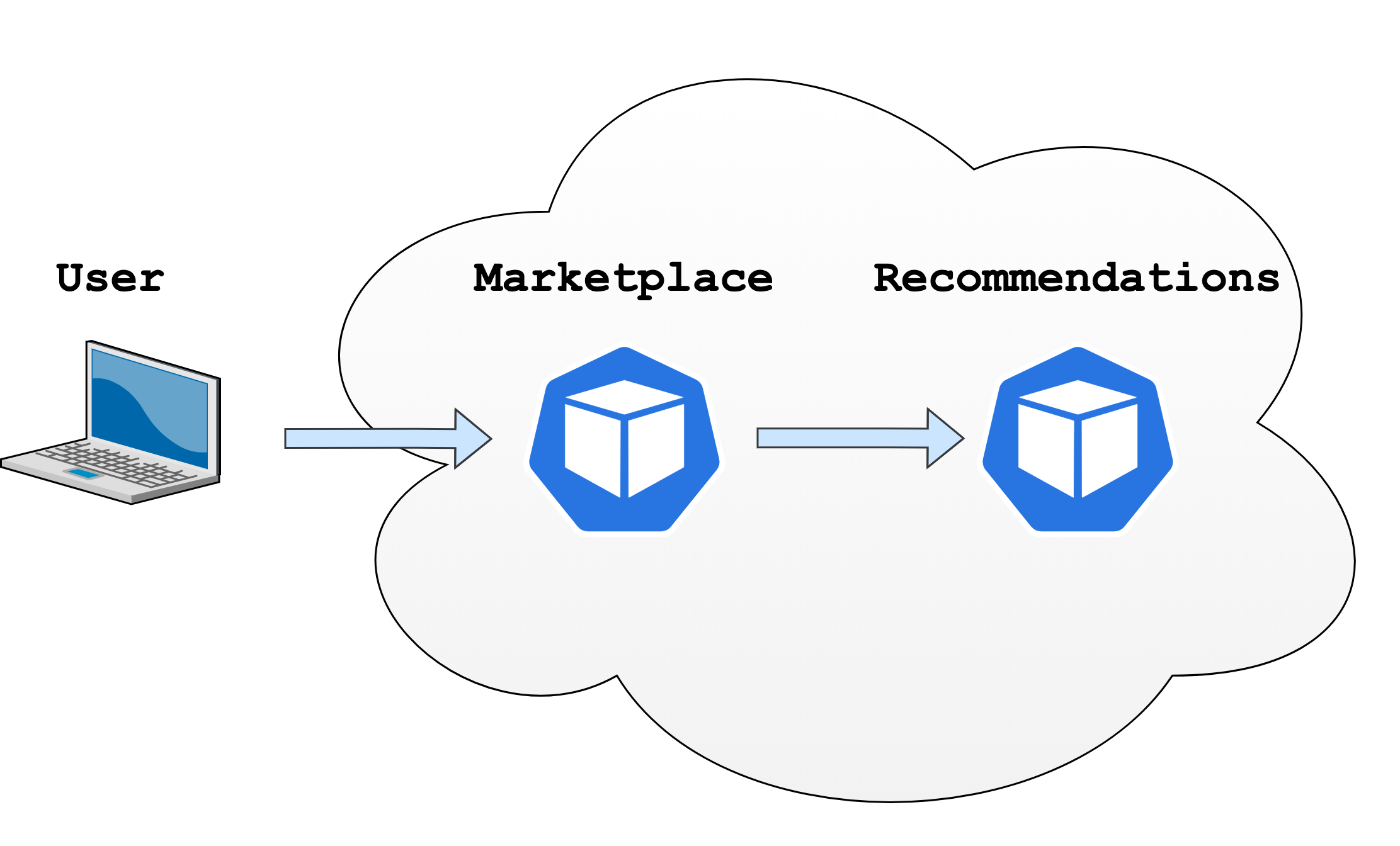
Пользователь взаимодействует с микросервисом Marketplace через свой браузер, а уже микросервис Marketplace взаимодействует с микросервисом Recommendations.
Задумаемся на мгновение об API рекомендаций. Мы хотим, чтобы запрос рекомендаций имел несколько функций:
User ID: мы хотим использовать id пользователя для персонализации рекомендаций.Book category: чтобы сделать API немного более интересным, мы добавим категории книг.Max results: мы не хотим подгружать все книги, имеющиеся в наличии, поэтому добавим ограничение на запрос.
Для каждой книги будут предоставлены следующие данные:
Book ID: уникальный числовой идентификатор книги.Book title: название, которое мы показываем пользователю.
Теперь мы можем определить API более формально, с помощью синтаксиса Protocol Buffers (Protobuf):
syntax = "proto3";
enum BookCategory {
MYSTERY = 0;
SCIENCE_FICTION = 1;
SELF_HELP = 2;
}
message RecommendationRequest {
int32 user_id = 1;
BookCategory category = 2;
int32 max_results = 3;
}
message BookRecommendation {
int32 id = 1;
string title = 2;
}
message RecommendationResponse {
repeated BookRecommendation recommendations = 1;
}
service Recommendations {
rpc Recommend (RecommendationRequest) returns (RecommendationResponse);
}
Протокол Protobuf разработан в Google и позволяет формально определять API. Пока в общих чертах поясним, что здесь происходит:
- Указываем, что файл использует синтаксис
proto3. - Определяем категории книг (
MYSTERY,SCIENCE_FICTION,SELF_HELP), каждой категории присваиваем числовой идентификатор. - Определяем API-запросы. Используем 32-битное целое число (
int32) для полейuser_IDиmax_results. Указываем также определенное выше перечислениеBookCategory. Кроме имени каждому полю назначается числовой идентификатор поля. - Определяем новый тип
BookRecommendationдля рекомендации книги. Он имеет 32-битный целочисленный идентификатор и строковый заголовок. - Описываем отклик микросервиса
Recommendations. - Последние строки определяют API-метод, которые принимает
RecommendationRequestи возвращаетRecommendationResponse. Ключевое словоrpcобозначает удаленный вызов процедуры.
Зачем использовать RPC и Protocol Buffers?
Итак, почему мы должны использовать этот синтаксис для определения API? Разве нельзя просто сделать HTTP-запрос и получить JSON? Можно сделать и так, но у Protobuf есть свои преимущества.
Документация
Первое преимущество использования Protocol Buffers заключается в том, что они дают API четко определенную и самодокументированную схему. Используя JSON, мы должны задокументировать содержащиеся в нем поля и их типы. Как и в случае с любой другой документацией, мы рискуем, что она окажется неточной, неполной или устаревшей. Когда же мы пишем API на Protobuf, мы можем сгенерировать из него код Python. То есть код никогда не будет рассинхронизирован с документацией. Документация – хорошо, но самодокументируемый код – еще лучше.
Валидация
Второе преимущество заключается в том, что при генерации кода Python из кода Protobuf вы заодно получаете некоторую базовую проверку. Например, сгенерированный код не принимает поля неправильного типа
Если для API вы используете HTTP и JSON, вам приходится писать код, который создает запрос, отправляет его, ожидает ответа, проверяет код состояния, а также анализирует и проверяет ответ. С помощью Protobuf можно генерировать код, который выглядит так же, как обычный вызов функции, но выполняет под капотом сетевой запрос.
Производительность
Платформа gRPC более эффективна, чем использование обычных HTTP-запросов. gRPC построен на основе HTTP/2, позволяющем выполнять несколько запросов параллельно поточно-безопасным способом. Сообщения gRPC хранятся в бинарном виде и весят меньше, чем JSON. Кроме того, HTTP/2 имеет встроенное сжатие заголовков, а gRPC – встроенную поддержку потоковой передачи запросов и ответов. В общем, попутно мы получаем отличную инфраструктуру.
Удобство для разработчиков
Вероятно, самая важная причина, по которой многие предпочитают gRPC, заключается в том, что мы можем определять свой API в терминах функций, а не HTTP-команд и ресурсов. В REST API мы должны решить, какие у нас есть ресурсы, как строить пути, как называть команды. Часто эти задачи могут быть решены множеством разных способов, в итоге обсуждение REST нередко превращается в дискуссию о предпочтениях. Protobuf сродни JSON или XML в том, что все они являются способами форматирования данных. В отличие от JSON, Protocol Buffers имеют строгую схему и более компактны при передаче по сети.
Пример реализации
После всех этих разговоров о Protocol Buffers пора посмотреть, чем они могут нам помочь. Сначала определим структуру каталогов:
.
├── protobufs/
│ └── recommendations.proto
|
└── recommendations/
Каталог protobufs/ будет содержать файл с именем recommendations.proto. Содержимым этого файла является приведенный выше код.
Cгенерируем код Python для взаимодействия с ним в каталоге recommendations/. Во-первых, мы должны установить grpcio-tools. Создадим файл recommendations/requirements.txt и добавим следующее:
grpcio-tools ~= 1.30
Чтобы запустить код локально, активируем новую виртуальную среду и установим в нее зависимости. Пример для Windows:
C:\ python -m venv venv
C:\ venv\Scripts\activate.bat
(venv) C:\ python -m pip install -r requirements.txt
В Linux и macOS используйте следующие команды:
python3 -m venv venv
source venv/bin/activate # Linux/macOS only
(venv) python -m pip install -r requirements.txt
Чтобы сгенерировать код Python из protobufs, выполним следующую команду:
cd recommendations
python -m grpc_tools.protoc -I ../protobufs --python_out=. \
--grpc_python_out=. ../protobufs/recommendations.proto
python -m grpc_tools.protocзапускает компилятор, который генерирует код Python из кода Protobuf,-I ../protobufsсообщает компилятору, где найти файлы, которые импортирует код Protobuf. Фактически мы не используем функцию импорта, но тем не менее флаг-Iнеобходим,--python_out =. --grpc_python_out =.сообщает компилятору, куда выводить файлы Python,../protobufs/recommendations.proto– это путь к файлу protobuf, который будет использоваться для генерации кода Python.
Если вы посмотрите, что сгенерировано, вы увидите два файла:
ls
recommendations_pb2.py recommendations_pb2_grpc.py
Эти файлы включают типы и функции Python для взаимодействия с нашим API. Компилятор сгенерирует клиентский код для вызова RPC и серверный код для реализации RPC. Сначала рассмотрим, что происходит на стороне клиента.
Клиент RPC
Сгенерированный на самом деле он не предназначен для чтения людьми. Запустим интерактивную оболочку Python, чтобы узнать, как взаимодействовать с этим кодом:
>>> from recommendations_pb2 import BookCategory, RecommendationRequest
>>> request = RecommendationRequest(
... user_id=1, category=BookCategory.SCIENCE_FICTION, max_results=3
... )
>>> request.category
1
Компилятор Protobuf сгенерировал проверку типов в Python, соответствующую типам в коде Protobuf. Проверим, что есть проверка типов:
>>> request = RecommendationRequest(
... user_id="oops", category=BookCategory.SCIENCE_FICTION, max_results=3
... )
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'oops' has type str, but expected one of: int, long
Важное замечание: все поля в proto3 являются необязательными. Поэтому нужно убедиться, что они все настроены. Если вы не укажете какое-то значение, по умолчанию оно будет равно нулю для числовых типов и пустой строке для строк:
>>> request = RecommendationRequest(
... user_id=1, category=BookCategory.SCIENCE_FICTION
... )
>>> request.max_results
0
Созданный файл recommendations_pb2.py содержит определения типов. Файл recommendations_pb2_grpc.py содержит структуру для клиента и сервера. Инструкции импорта, необходимые для создания клиента:
>>> import grpc
>>> from recommendations_pb2_grpc import RecommendationsStub
Здесь мы импортируем модуль grpc, предоставляющий функции для настройки подключений к удаленным серверам. Затем импортируем заглушку (stub) для клиента. Это заглушка, потому как сам клиент не имеет никаких функций – он лишь обращается к удаленному серверу и возвращает результат.
Вернувшись к коду Protobuf, в конце мы увидим раздел service Recommendations {...}. Компилятор Protobuf берет имя микросервиса Recommendations, и добавляет к нему Stub, чтобы сформировать имя клиента RecommendationsStub.
Теперь мы можем сделать RPC-запрос:
>>> channel = grpc.insecure_channel("localhost:50051")
>>> client = RecommendationsStub(channel)
>>> request = RecommendationRequest(
... user_id=1, category=BookCategory.SCIENCE_FICTION, max_results=3
... )
>>> client.Recommend(request)
Traceback (most recent call last):
...
grpc._channel._InactiveRpcError: <_InactiveRpcError of RPC that terminated with:
status = StatusCode.UNAVAILABLE
details = "failed to connect to all addresses"
...
На порту 50051 мы создали соединение с localhost, то есть вашей собственной машиной. Порт 50051 является стандартным портом для gRPC, при желании вы можете его изменить. Затем мы передаем канал RecommendationsStub, чтобы создать экземпляр клиента.
Теперь мы можем вызвать метод Recommend, который мы определили в микросервисе Recommendations. Однако мы получаем исключение, поскольку микросервис пока еще не работает на localhost: 50051. Пора приняться за серверную часть.
Сервер RPC
Начнем с инструкций импорта и добавления некоторых образцов данных:
# recommendations/recommendations.py
from concurrent import futures
import random
import grpc
from recommendations_pb2 import (
BookCategory,
BookRecommendation,
RecommendationResponse,
)
import recommendations_pb2_grpc
books_by_category = {
BookCategory.MYSTERY: [
BookRecommendation(id=1, title="The Maltese Falcon"),
BookRecommendation(id=2, title="Murder on the Orient Express"),
BookRecommendation(id=3, title="The Hound of the Baskervilles"),
],
BookCategory.SCIENCE_FICTION: [
BookRecommendation(
id=4, title="The Hitchhiker's Guide to the Galaxy"
),
BookRecommendation(id=5, title="Ender's Game"),
BookRecommendation(id=6, title="The Dune Chronicles"),
],
BookCategory.SELF_HELP: [
BookRecommendation(
id=7, title="The 7 Habits of Highly Effective People"
),
BookRecommendation(
id=8, title="How to Win Friends and Influence People"
),
BookRecommendation(id=9, title="Man's Search for Meaning"),
],
}
Далее создадим класс, реализующий функции микросервиса:
class RecommendationService(
recommendations_pb2_grpc.RecommendationsServicer
):
def Recommend(self, request, context):
if request.category not in books_by_category:
context.abort(grpc.StatusCode.NOT_FOUND, "Category not found")
books_for_category = books_by_category[request.category]
num_results = min(request.max_results, len(books_for_category))
books_to_recommend = random.sample(
books_for_category, num_results
)
return RecommendationResponse(recommendations=books_to_recommend)
Класс RecommendationService – это реализация нашего микросервиса. Обратите внимание, что класс наследуется от подкласса RecommendationServicer. Это часть интеграции с gRPC.
Далее мы определяем метод Recommend. Он должен иметь то же имя, что и RPC, который мы определяем в своем файле Protobuf. Метод также принимает Request и возвращает RecommendationResponse, как и в определении Protobuf. Параметр context позволяет установить код состояния для response.
Метод abort() для завершения запроса и устанавливается код состояния NOT_FOUND, если вы получаете неожиданную категорию. Поскольку gRPC построен поверх HTTP/2, код состояния аналогичен стандартному коду состояния HTTP. Его установка позволяет клиенту выполнять различные действия в зависимости от полученного кода. Это также помогает промежуточному программному обеспечению (например, системам мониторинга), регистрировать, какое число запросов содержит ошибки.
В следующих строчках случайным образом выбираются книги из выбранной категории, которые можно рекомендовать. Количество рекомендаций ограничено max_results.
В последней строке возвращается RecommendationResponse со списком рекомендаций книг.
Обратите внимание, что было бы логично при возникновении ошибки вызывать исключение, чем использовать abort(), как в этом примере. Однако тогда ответ не установит код состояния правильно.
Класс RecommendationService уже определяет реализацию микросервиса, но нам как-то нужно запустить сам сервис. Для этого мы определим функцию serve():
def serve():
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
recommendations_pb2_grpc.add_RecommendationsServicer_to_server(
RecommendationService(), server
)
server.add_insecure_port("[::]:50051")
server.start()
server.wait_for_termination()
if __name__ == "__main__":
serve()
serve() запускает сетевой сервер и использует класс микросервиса для обработки запросов. В приведенном коде сначала создается сервер gRPC, которому мы указываем использовать 10 потоков для обслуживания запросов, что совершенно излишне для демонстрационного примера, но является хорошим дефолтным значением для реального микросервиса Python. Далее мы связываем класс с сервером. Это похоже на добавление обработчика запросов. Потом мы указываем серверу работать на порту 50051. Далее мы запускаем микросервис и ждем, пока он не остановится. Единственный способ остановить его в этом случае – нажать в терминале комбинацию [Ctrl + C].
Не закрывая терминал, который мы использовали для тестирования клиента, откроем новый терминал и выполним следующую команду:
python recommendations.py
Эта команда запустит микросервис Recommendations, так что мы сможем протестировать клиента на некоторых реальных данных. Теперь вернемся к терминалу, который мы использовали для тестирования клиента, чтобы создать заглушку канала. Если вы оставили консоль открытой, вы можете пропустить инструкции импорта:
>>> import grpc
>>> from recommendations_pb2_grpc import RecommendationsStub
>>> channel = grpc.insecure_channel("localhost:50051")
>>> client = RecommendationsStub(channel)
Теперь, когда у нас есть клиентский объект, мы можем сделать запрос:
>>> request = RecommendationRequest(
... user_id=1, category=BookCategory.SCIENCE_FICTION, max_results=3)
>>> client.Recommend(request)
recommendations {
id: 6
title: "The Dune Chronicles"
}
recommendations {
id: 4
title: "The Hitchhiker\'s Guide To The Galaxy"
}
recommendations {
id: 5
title: "Ender\'s Game"
}
Работает! Мы сделали RPC-запрос к микросервису и получили ответ. Обратите внимание, что ваш результат будет отличаться, потому что рекомендации выбираются случайным образом.
Теперь, когда у нас есть сервер, мы можем реализовать микросервис Marketplace и заставить его вызывать микросервис рекомендаций. Можно закрыть консоль Python, но оставьте включенным микросервис Recommendations.
Связываем микросервисы вместе
Создайте новый каталог marketplace/ и поместите в него файл marketplace.py для своего микросервиса Marketplace. Дерево каталогов должно теперь выглядеть так:
.
├── marketplace/
│ ├── marketplace.py
│ ├── requirements.txt
│ └── templates/
│ └── homepage.html
|
├── protobufs/
│ └── recommendations.proto
|
└── recommendations/
├── recommendations.py
├── recommendations_pb2.py
├── recommendations_pb2_grpc.py
└── requirements.txt
Обратите внимание на новый каталог marketplace/ для кода микросервиса, requirements.txt и homepage.html для домашней страницы. Всё это будет описано ниже. Пока для них можно создать пустые файлы.
Микросервис Marketplace будет приложением Flask для отображения пользователю веб-страницы. Он будет вызывать микросервис Recommendations, чтобы получить рекомендации по книгам. Откроем файл marketplace/marketplace.py и добавим следующее:
# marketplace/marketplace.py
import os
from flask import Flask, render_template
import grpc
from recommendations_pb2 import BookCategory, RecommendationRequest
from recommendations_pb2_grpc import RecommendationsStub
app = Flask(__name__)
recommendations_host = os.getenv("RECOMMENDATIONS_HOST", "localhost")
recommendations_channel = grpc.insecure_channel(
f"{recommendations_host}:50051"
)
recommendations_client = RecommendationsStub(recommendations_channel)
@app.route("/")
def render_homepage():
recommendations_request = RecommendationRequest(
user_id=1, category=BookCategory.MYSTERY, max_results=3
)
recommendations_response = recommendations_client.Recommend(
recommendations_request
)
return render_template(
"homepage.html",
recommendations=recommendations_response.recommendations,
)
Здесь мы настраиваем Flask, создаем клиент gRPC и добавляем функцию для рендеринга домашней страницы.
Откроем файл homepage.html в каталоге marketplace/templates/ и добавим следующий HTML-код:
<!-- homepage.html -->
<!doctype html>
<html lang="en">
<head>
<title>Online Books For You</title>
</head>
<body>
<h1>Mystery books you may like</h1>
<ul>
{% for book in recommendations %}
<li>{{ book.title }}</li>
{% endfor %}
</ul>
</body>
Это демо нашей домашней страницы. Когда мы закончим, она должна отображать список рекомендуемых книг.
Для запуска кода потребуются следующие зависимости, которые мы можем добавить в marketplace/requirements.txt:
flask ~= 1.1
grpcio-tools ~= 1.30
Jinja2 ~= 2.11
pytest ~= 5.4
Каждый микросервис будут иметь свой файл requirements.txt, но при желании вы можете использовать одну и ту же виртуальную среду для обоих. Выполним следующее, чтобы обновить виртуальную среду:
python -m pip install -r marketplace/requirements.txt
Теперь, когда мы установили зависимости, нужно также сгенерировать код для protobufs в каталоге marketplace/. Для этого мы запустим в консоли следующее:
cd marketplace
python -m grpc_tools.protoc -I ../protobufs --python_out=. \
--grpc_python_out=. ../protobufs/recommendations.proto
Это та же команда, которую мы запускали раньше, так что здесь нет ничего нового. Может показаться странным иметь одни и те же файлы в каталогах Marketplace/ и Recommendations, но позже вы увидите, как автоматически создавать их в рамках развертывания. То есть обычно нет необходимости хранить их в системе контроля версий.
Чтобы запустить микросервис Marketplace, введем в консоль следующее:
FLASK_APP=marketplace.py flask run
Теперь у нас должны быть микросервисы Recommendations и Marketplace, работающие в двух отдельных терминалах. Если вы завершили работу микросервиса Recommendations, перезапустите его:
cd recommendations
python recommendations.py
В результате наших действий запущено приложение Flask, которое по умолчанию работает на порту 5000. Проверьте результат в браузере:
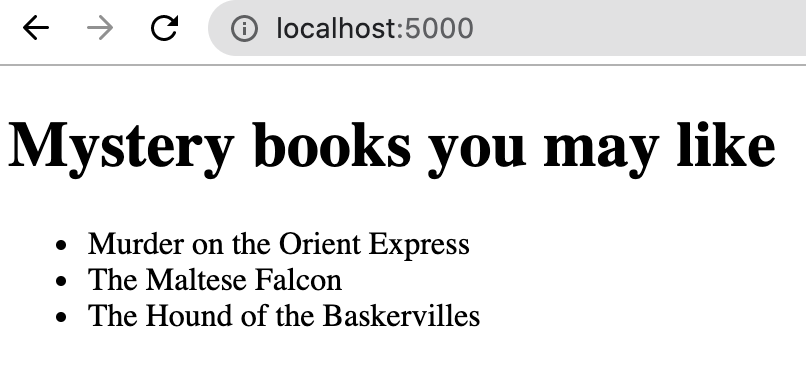
Итак, у нас есть два микросервиса, которые общаются друг с другом. Но они все еще находятся на нашем компьютере. Далее мы рассмотрим, как внедрить их в производственную среду.
Можно остановить микросервисы Python, нажав в терминале Ctrl + C. Далее мы будем запускать микросервисы в Docker.
Микросервисы Python в Docker
Docker – это технология, которая позволяет на одном компьютере изолировать одни процессы от других. Docker идеально подходит для развертывания микросервисов Python, поскольку вы можете упаковать все зависимости и запустить микросервис в изолированной среде.
Мы создадим два образа Docker: по одному для каждого из микросервисов. Образ – это по сути файловая система плюс некоторые метаданные. Каждый микросервис может записывать файлы, не затрагивая файловой системы, на которой запущен Docker, и открывать порты без конфликтов с другими процессами.
Образцы создаются с помощью описания в виде Dockerfile. Весь процесс всегда строится от некоторого базового образа. В нашем случае базовый образ будет включать интерпретатор Python. Далее мы скопируем файлы из своей файловой системы в образ Docker и запустим команду для установки зависимостей.
Dockerfile для сервиса Recommendations
Начнем с создания образа Docker для микросервиса рекомендаций. Создадим файл Recommendations/Dockerfile и добавим в него следующее:
FROM python
RUN mkdir /service
COPY protobufs/ /service/protobufs/
COPY recommendations/ /service/recommendations/
WORKDIR /service/recommendations
RUN python -m pip install --upgrade pip
RUN python -m pip install -r requirements.txt
RUN python -m grpc_tools.protoc -I ../protobufs --python_out=. \
--grpc_python_out=. ../protobufs/recommendations.proto
EXPOSE 50051
ENTRYPOINT [ "python", "recommendations.py" ]
В первой строчке мы инициализируем образ с помощью базовой среды Linux и последней версии Python. Образ на этот момент имеет типичную структуру файловой системы Linux. Далее создается новый каталог в /service для хранения кода микросервиса. Потом мы копируем каталоги protobufs/ и recommendations в /service.
Затем мы создаем каталог /service/recommendations и делаем его текущей рабочей директорией. После этого мы устанавливаем зависимости для библиотек Python и генерируем Python-файлы из кода Protobuf.
В итоге папка /service/ внутри Docker-образа будет иметь следующую структуру:
/service/
|
├── protobufs/
│ └── recommendations.proto
|
└── recommendations/
├── recommendations.py
├── recommendations_pb2.py
├── recommendations_pb2_grpc.py
└── requirements.txt
Наконец, мы открываем микросервис наружу Docker-образа на порте 50051 и говорим Docker запустить наш микросервис в Python, передав название файла для запуска.
Мы описали всю процедуру в Dockerfile. Чтобы сгенерировать Docker-образ, перейдем на уровень выше относительно Dockerfile и запустим команду build:
docker build . -f recommendations/Dockerfile -t recommendations
Когда Docker создаст образ, мы сможем его запустить:
docker run -p 127.0.0.1:50051:50051/tcp recommendations
Вы не увидите никаких дополнительных сообщения, но микросервис рекомендаций теперь работает в Docker-контейнере. Когда мы запускаем образ, на его основе создается контейнер. Мы можем запустить образ несколько раз, чтобы развернуть несколько контейнеров.
Параметр -p 127.0.0.1:50051:50051/tcp указывает Docker перенаправлять TCP-соединения с порта 50051 на вашем компьютере на порт 50051 внутри контейнера.
Dockerfile для Marketplace
Теперь создадим образ Marketplace. Напишем аналогичный файл Marketplace/Dockerfile:
FROM python
RUN mkdir /service
COPY protobufs/ /service/protobufs/
COPY marketplace/ /service/marketplace/
WORKDIR /service/marketplace
RUN python -m pip install --upgrade pip
RUN python -m pip install -r requirements.txt
RUN python -m grpc_tools.protoc -I ../protobufs --python_out=. \
--grpc_python_out=. ../protobufs/recommendations.proto
EXPOSE 5000
ENV FLASK_APP=marketplace.py
ENTRYPOINT [ "flask", "run", "--host=0.0.0.0"]
Этот Dockerfile очень похож на тот, что мы подготовили для микросервиса Recommendations, лишь с некоторыми отличиями в конце: ENV FLASK_APP=marketplace.py устанавливает значение переменной FLASK_APP внутри образа, это необходимо для корректной работы Flask. Параметр --host=0.0.0.0 позволяет Flask принимать соединения не только от localhost внутри образа.
Собираем образ и запускаем контейнер:
docker build . -f marketplace/Dockerfile -t marketplace
docker run -p 127.0.0.1:5000:5000/tcp marketplace
Настройка сети
Хотя контейнеры Recommendations и Marketplace уже работают, если мы сейчас перейдем в браузере по адресу http://localhost:5000, мы получим сообщение об ошибке. Дело в том, что контейнеры изолированы.
К счастью, Docker предлагает решение этой проблемы. Мы можем создать виртуальную сеть и добавить в нее оба контейнера, а также назначить им DNS-имена, чтобы они могли найти друг друга.
Ниже мы создаем сеть под названием microservices и запускаем в ней микросервис рекомендаций. Сначала остановите запущенные в данный момент контейнеры с помощью Ctrl + C. Затем запустите следующее:
docker network create microservices
docker run -p 127.0.0.1:50051:50051/tcp --network microservices \
--name recommendations recommendations
Команда docker network create создает сеть. Достаточно это сделать только один раз – далее к этой сети можно подключить несколько контейнеров. Далее мы добавляем сеть микросервисов в команду docker run, чтобы запустить контейнер в этой сети. Параметр ‑‑name recommendations указывает имя контейнера в сети.
Перед перезапуском контейнера Marketplace нам необходимо скорректировать код. Следующую строчку в marketplace.py
recommendations_channel = grpc.insecure_channel("localhost:50051")
нужно изменить так, чтобы мы могли подключаться к контейнеру recommendations:50051. Для удобства последующей работы мы укажем имя в переменной среды. Заменим строку выше двумя следующими:
recommendations_host = os.getenv("RECOMMENDATIONS_HOST", "localhost")
recommendations_channel = grpc.insecure_channel(
f"{recommendations_host}:50051"
)
Эти строчки позволяют загружать имя хоста микросервиса рекомендаций в переменную среды RECOMMENDATIONS_HOST. Если переменная среды отсутствует, то по умолчанию будет использоваться значение localhost. Это помогает запускать один и тот же код и непосредственно на компьютере, и внутри контейнера.
Мы изменили код, нужно пересобрать образ marketplace. Запустим его внутри сети:
docker build . -f marketplace/Dockerfile -t marketplace
docker run -p 127.0.0.1:5000:5000/tcp --network microservices \
-e RECOMMENDATIONS_HOST=recommendations marketplace
На этом этапе вы можете снова попробовать открыть localhost:5000 в браузере, и теперь уже страница должна загрузиться.
Docker Compose
Несмотря на преимущества, такая работа с Docker выглядит немного утомительно. Было бы неплохо иметь одну команду, которая бы выполнила все необходимое для запуска всех контейнеров. Соответствующее решение называется docker-compose и является частью проекта Docker.
Вместо того, чтобы запускать кучу команд для создания образов, создания сетей и запуска контейнеров, мы можем объявить микросервисы в одном YAML-файле docker-compose.yaml, который обращается к отдельным докерфайлам в соответствюущих папках:
version: "3.8"
services:
marketplace:
build:
context: .
dockerfile: marketplace/Dockerfile
environment:
RECOMMENDATIONS_HOST: recommendations
image: marketplace
networks:
- microservices
ports:
- 5000:5000
recommendations:
build:
context: .
dockerfile: recommendations/Dockerfile
image: recommendations
networks:
- microservices
networks:
microservices:
Этот файл расположен в корне проекта, а сам проект сейчас имеет следующую структуру:
.
├── marketplace/
│ ├── marketplace.py
│ ├── requirements.txt
│ └── templates/
│ └── homepage.html
|
├── protobufs/
│ └── recommendations.proto
|
├── recommendations/
│ ├── recommendations.py
│ ├── recommendations_pb2.py
│ ├── recommendations_pb2_grpc.py
│ └── requirements.txt
│
└── docker-compose.yaml
В этом руководстве мы не будем подробно вдаваться в синтаксис, поскольку он хорошо документирован и в действительности делает то же самое, что мы уже делали вручную. Но теперь для запуска достаточно набрать лишь одну команду:
docker-compose up
Тестирование
Для модульного тестирования микросервиса Python можно создать экземпляр класса микросервиса и вызвать его методы. Вот базовый пример теста для RecommendationService:
# recommendations/recommendations_test.py
from recommendations import RecommendationService
from recommendations_pb2 import BookCategory, RecommendationRequest
def test_recommendations():
service = RecommendationService()
request = RecommendationRequest(
user_id=1, category=BookCategory.MYSTERY, max_results=1
)
response = service.Recommend(request, None)
assert len(response.recommendations) == 1
Интеграционное тестирование включает в себя выполнение автоматизированных тестов с множеством неимитируемых микросервисов. Так что это немного сложнее, но не слишком сложно. Добавим файл marketplace/marketplace_integration_test.py
from urllib.request import urlopen
def test_render_homepage():
homepage_html = urlopen("http://localhost:5000").read().decode("utf-8")
assert "<title>Online Books For You</title>" in homepage_html
assert homepage_html.count("<li>") == 3
Данный тест делает HTTP-запрос к URL-адресу домашней страницы и проверяет, что он возвращает некоторый HTML-код с заголовком и тремя маркерами <li>. Это не самый полезный тест, но достаточный для демонстрации идеи. Тест будет выполнен только, если микросервис Recommendations запущен и работает. Даже можно протестировать микросервис Marketplace, отправив ему HTTP-запрос.
Запустив микросервисы Python с помощью docker-compose, мы можем запускать внутри них команды с помощью docker-compose exec. Например, чтобы запустить интеграционный тест внутри контейнера Marketplace, можно выполнить следующий набор команд:
docker-compose build
docker-compose up
docker-compose exec marketplace pytest marketplace_integration_test.py
Это запустит команду pytest внутри контейнера marketplace. Поскольку интеграционный тест подключается к localhost, необходимо запустить тест в том же контейнере, что и микросервис.
Развертывание на Kubernetes
Теперь на вашем компьютере запущено несколько микросервисов. Вы можете быстро вызвать их и запустить интеграционные тесты. Мы считаем, что этого достаточно для базового знакомства. Но если вы хотите двинуться дальше и попробовать перенести результат в производственную среду на кластере Kubernetes, мы отсылаем вас к оригинальной публикации Дэна Хипшмана. Там же вы можете узнать о процессе мониторинга микросервисов и лучших практиках работы с gRPC.
Дополнительные материалы по теме:
Комментарии