
MLlib, PySpark и многоклассовая классификация криминальных сводок с помощью нескольких алгоритмов. Не пропустите! Будет интересно.

Мы обрабатываем так много информации ежедневно, что возможность передавать и анализировать ее в реальном времени стала очень ценной. Apache Spark это умеет, благодаря чему стремительно набирает популярность. Он достаточно быстр для выполнения исследовательских запросов без выборки. Многие эксперты Data Science рекомендуют его.
Мы будем использовать библиотеку машинного обучения Spark (MLlib) для многоклассовой классификации текста c помощью PySpark. Если вы хотите увидеть реализацию со Scikit-Learn, взгляните на этот материал.
Данные
Задача состоит в том, чтобы классифицировать описания преступлений в Сан-Франциско по 33 предопределенным категориям. Исходные данные можно загрузить из Kaggle.
Получая новое описание, мы должны отнести его к одной из этих групп. Предполагается, что каждому тексту присваивается одна и только одна категория. Таким образом, это многоклассовая классификация.
- Входные данные: описание преступления. Например, STOLEN AUTOMOBILE (украденный автомобиль).
- Выходные данные: категория. Например, VEHICLE THEFT (транспортная кража).
Для решения мы будем использовать различные методы извлечения признаков и алгоритмы контролируемого машинного обучения Spark.
Получение и извлечение данных
Загрузить CSV-файл очень просто с помощью csv-пакетов Spark.
from pyspark.sql import SQLContext
from pyspark import SparkContext
sc =SparkContext()
sqlContext = SQLContext(sc)
data = sqlContext.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load('train.csv')
Набор данных загружен, можно начинать анализ. Убираем ненужные столбцы и выводим первые 5 строк:
drop_list = ['Dates', 'DayOfWeek', 'PdDistrict', 'Resolution', 'Address', 'X', 'Y'] data = data.select([column for column in data.columns if column not in drop_list]) data.show(5)

Чтобы распечатать схему в формате дерева, нужно использовать функцию printSchema().
data.printSchema()

Получим самые многочисленные категории преступлений:
from pyspark.sql.functions import col
data.groupBy("Category") \
.count() \
.orderBy(col("count").desc()) \
.show()

А вот ТОП-20 описаний:
data.groupBy("Descript") \
.count() \
.orderBy(col("count").desc()) \
.show()

Классификация по этапам
Spark Machine Learning Pipelines API похож на Scikit-Learn. Наша классификация состоит из трех шагов:
RegexTokenizer– токенизация с использованием регулярного выражения;StopwordsRemover– удаление стоп-слов;CountVectors– расчет векторов (метод «мешок слов»).
from pyspark.ml.feature import RegexTokenizer, StopWordsRemover, CountVectorizer from pyspark.ml.classification import LogisticRegression # токенизация regexTokenizer = RegexTokenizer(inputCol="Descript", outputCol="words", pattern="\\W") # стоп-слова add_stopwords = ["http","https","amp","rt","t","c","the"] stopwordsRemover = StopWordsRemover(inputCol="words", outputCol="filtered").setStopWords(add_stopwords) # мешок слов countVectors = CountVectorizer(inputCol="filtered", outputCol="features", vocabSize=10000, minDF=5)
StringIndexer
StringIndexer кодирует столбец строковых меток в столбец индексов. Они находятся в интервале [0, numLabels) и отсортированы по частоте, поэтому самая частая метка получает индекс 0.
В нашем случае столбец меток (Категории) будет перекодирован в индексы от 0 до 32. Самая популярная метка LARCENY/THEFT (кража).
from pyspark.ml import Pipeline from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler label_stringIdx = StringIndexer(inputCol = "Category", outputCol = "label") pipeline = Pipeline(stages=[regexTokenizer, stopwordsRemover, countVectors, label_stringIdx]) pipelineFit = pipeline.fit(data) dataset = pipelineFit.transform(data) dataset.show(5)

Обучающие и тестовые наборы
# устанавливаем параметр seed для воспроизводимости разделения
(trainingData, testData) = dataset.randomSplit([0.7, 0.3], seed = 100)
print("Training Dataset Count: " + str(trainingData.count()))
print("Test Dataset Count: " + str(testData.count()))
Размер тренировочной выборки: 5185
Размер тестовой выборки: 2104
Обучение и оценка моделей
После проверки модели на тестовом наборе данных мы посмотрим на 10 лучших прогнозов с наибольшей вероятностью.
Логистическая регрессия с использованием векторов слов
lr = LogisticRegression(maxIter=20, regParam=0.3, elasticNetParam=0)
lrModel = lr.fit(trainingData)
predictions = lrModel.transform(testData)
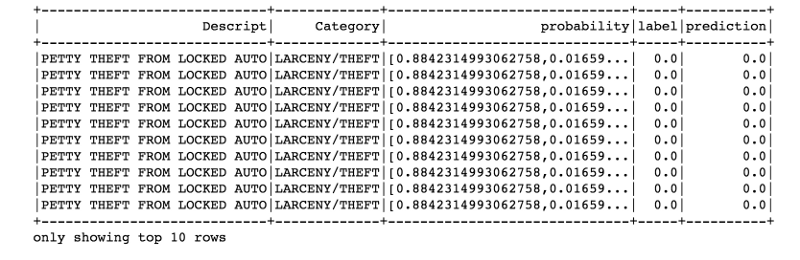
predictions.filter(predictions['prediction'] == 0) \
.select("Descript","Category","probability","label","prediction") \
.orderBy("probability", ascending=False) \
.show(n = 10, truncate = 30)
from pyspark.ml.evaluation import MulticlassClassificationEvaluator evaluator = MulticlassClassificationEvaluator(predictionCol="prediction") evaluator.evaluate(predictions)
0.9610787444388802
Отличный результат!
Логистическая регрессия с использованием метода TF-IDF
from pyspark.ml.feature import HashingTF, IDF
hashingTF = HashingTF(inputCol="filtered", outputCol="rawFeatures", numFeatures=10000)
idf = IDF(inputCol="rawFeatures", outputCol="features", minDocFreq=5) #minDocFreq: remove sparse terms
pipeline = Pipeline(stages=[regexTokenizer, stopwordsRemover, hashingTF, idf, label_stringIdx])
pipelineFit = pipeline.fit(data)
dataset = pipelineFit.transform(data)
(trainingData, testData) = dataset.randomSplit([0.7, 0.3], seed = 100)
lr = LogisticRegression(maxIter=20, regParam=0.3, elasticNetParam=0)
lrModel = lr.fit(trainingData)
predictions = lrModel.transform(testData)
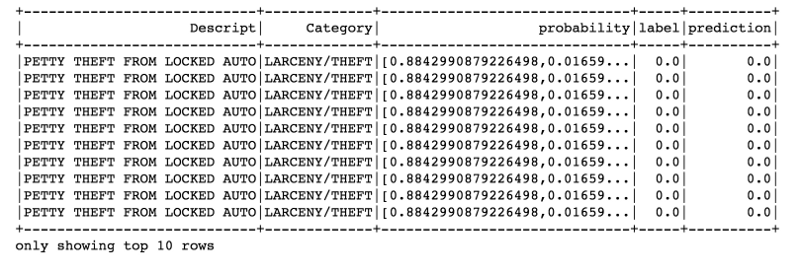
predictions.filter(predictions['prediction'] == 0) \
.select("Descript","Category","probability","label","prediction") \
.orderBy("probability", ascending=False) \
.show(n = 10, truncate = 30)
evaluator = MulticlassClassificationEvaluator(predictionCol="prediction") evaluator.evaluate(predictions)
0.9616202660247297
Результат такой же.
Кросс-валидация
Теперь проведем кросс-валидацию, чтобы настроить гиперпараметры.
pipeline = Pipeline(stages=[regexTokenizer, stopwordsRemover, countVectors, label_stringIdx])
pipelineFit = pipeline.fit(data)
dataset = pipelineFit.transform(data)
(trainingData, testData) = dataset.randomSplit([0.7, 0.3], seed = 100)
lr = LogisticRegression(maxIter=20, regParam=0.3, elasticNetParam=0)
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
# Создание ParamGrid для кросс-валидации
paramGrid = (ParamGridBuilder()
.addGrid(lr.regParam, [0.1, 0.3, 0.5])
.addGrid(lr.elasticNetParam, [0.0, 0.1, 0.2])
# .addGrid(model.maxIter, [10, 20, 50]) #Количество итераций
# .addGrid(idf.numFeatures, [10, 100, 1000]) #Количество признаков
.build())
cv = CrossValidator(estimator=lr, \
estimatorParamMaps=paramGrid, \
evaluator=evaluator, \
numFolds=5)
cvModel = cv.fit(trainingData)
predictions = cvModel.transform(testData)
# Оценка лучшей модели
evaluator = MulticlassClassificationEvaluator(predictionCol="prediction")
evaluator.evaluate(predictions)
0.9851796929217101
Производительность улучшилась.
Наивный Байесовский подход
from pyspark.ml.classification import NaiveBayes
nb = NaiveBayes(smoothing=1)
model = nb.fit(trainingData)
predictions = model.transform(testData)
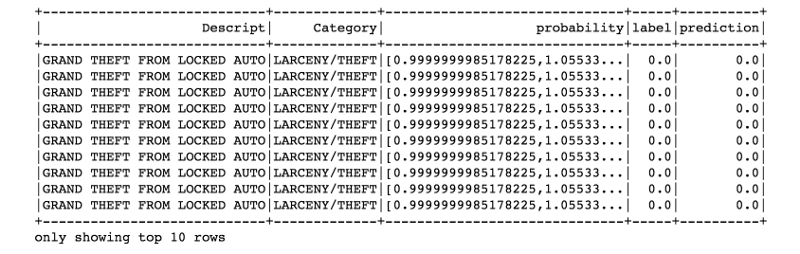
predictions.filter(predictions['prediction'] == 0) \
.select("Descript","Category","probability","label","prediction") \
.orderBy("probability", ascending=False) \
.show(n = 10, truncate = 30)
evaluator = MulticlassClassificationEvaluator(predictionCol="prediction") evaluator.evaluate(predictions)
0.9625414629888848
Случайный лес
from pyspark.ml.classification import RandomForestClassifier
rf = RandomForestClassifier(labelCol="label", \
featuresCol="features", \
numTrees = 100, \
maxDepth = 4, \
maxBins = 32)
rfModel = rf.fit(trainingData)
predictions = rfModel.transform(testData)
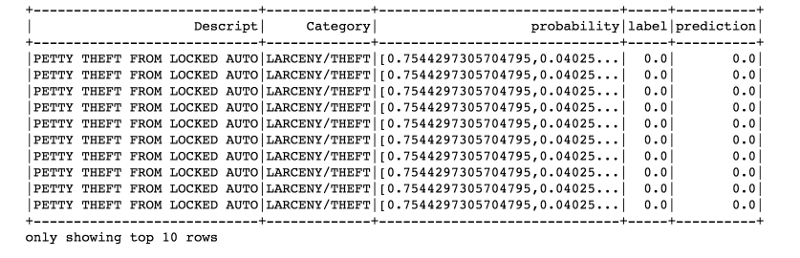
predictions.filter(predictions['prediction'] == 0) \
.select("Descript","Category","probability","label","prediction") \
.orderBy("probability", ascending=False) \
.show(n = 10, truncate = 30)
evaluator = MulticlassClassificationEvaluator(predictionCol="prediction") evaluator.evaluate(predictions)
0.6600326922344301
Random forest – очень хороший, надежный и универсальный метод, однако для многомерных разреженных данных это не лучший выбор.
Очевидно, что для нашей модели следует использовать логистическую регрессию с перекрестной валидацией.
Исходный код проекта можно найти на Github.
Перевод статьи Susan Li: Multi-Class Text Classification with PySpark
Комментарии