
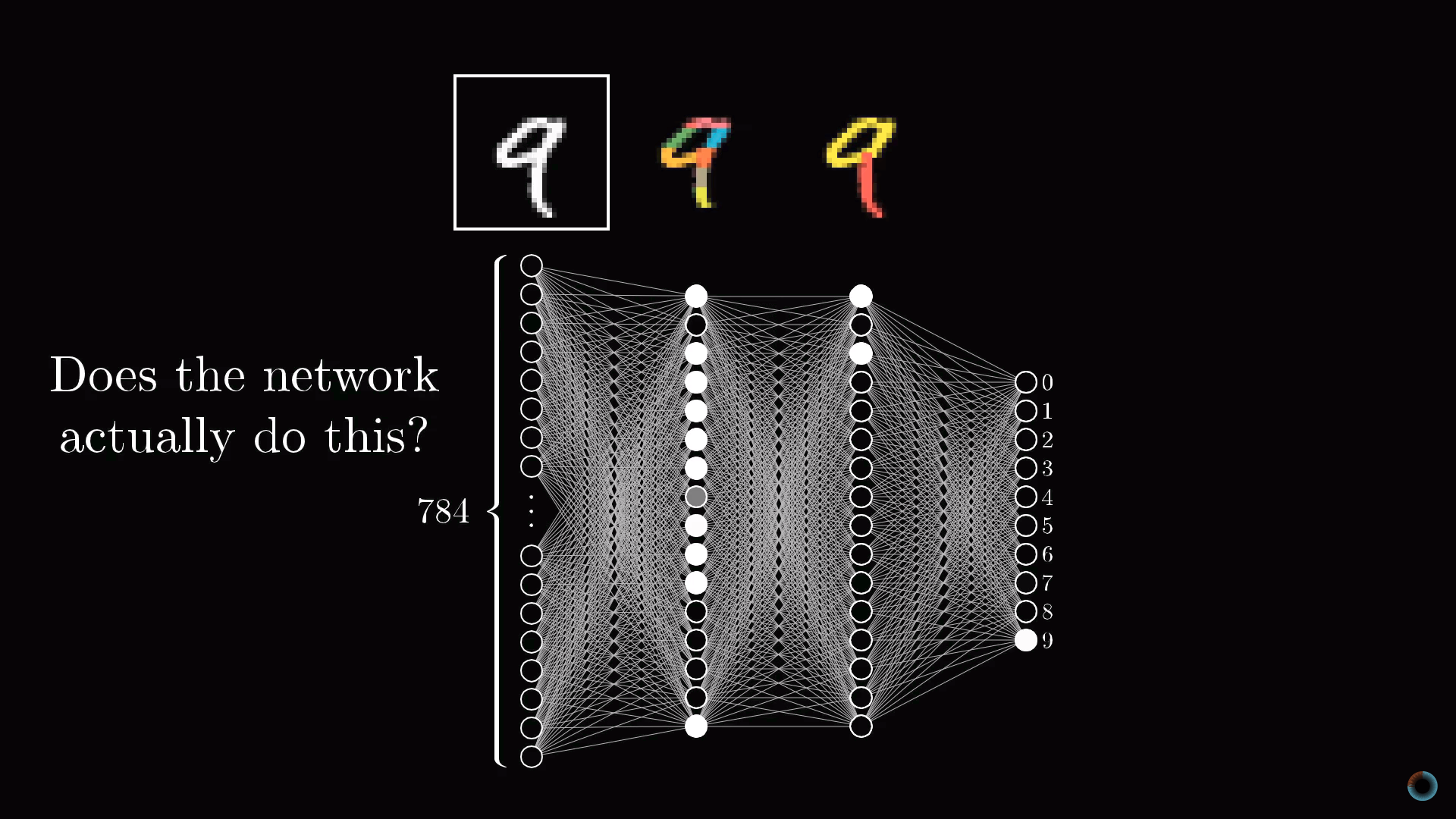
При помощи множества анимаций на примере задачи распознавания цифр и модели перцептрона дано наглядное введение в процесс обучения нейросети.
Статьи на тему, что такое искусственный интеллект, давно написаны. А вот математическая сторона медали :)
Продолжаем серию первоклассных иллюстративных курсов 3Blue1Brown (смотрите наши предыдущие обзоры по линейной алгебре и матанализу) курсом по нейронным сетям.
Первое видео посвящено структуре компонентов нейронной сети, второе – ее обучению, третье – алгоритму этого процесса. В качестве задания для обучения взята классическая задача распознавания цифр, написанных от руки.
Детально рассматривается многослойный перцептрон – базисная (но уже достаточно сложная) модель для понимания любых более современных вариантов нейронных сетей.
1. Компоненты нейронной сети
Цель первого видео состоит в том, чтобы показать, что собой представляет нейронная сеть. На примере задачи распознавания цифр визуализируется структура компонентов нейросети. Видео имеет русские субтитры.
Постановка задачи распознавания цифр
Представим, у вас есть число 3, изображенное в чрезвычайно низком разрешении 28х28 пикселей. Ваш мозг без труда узнает это число.
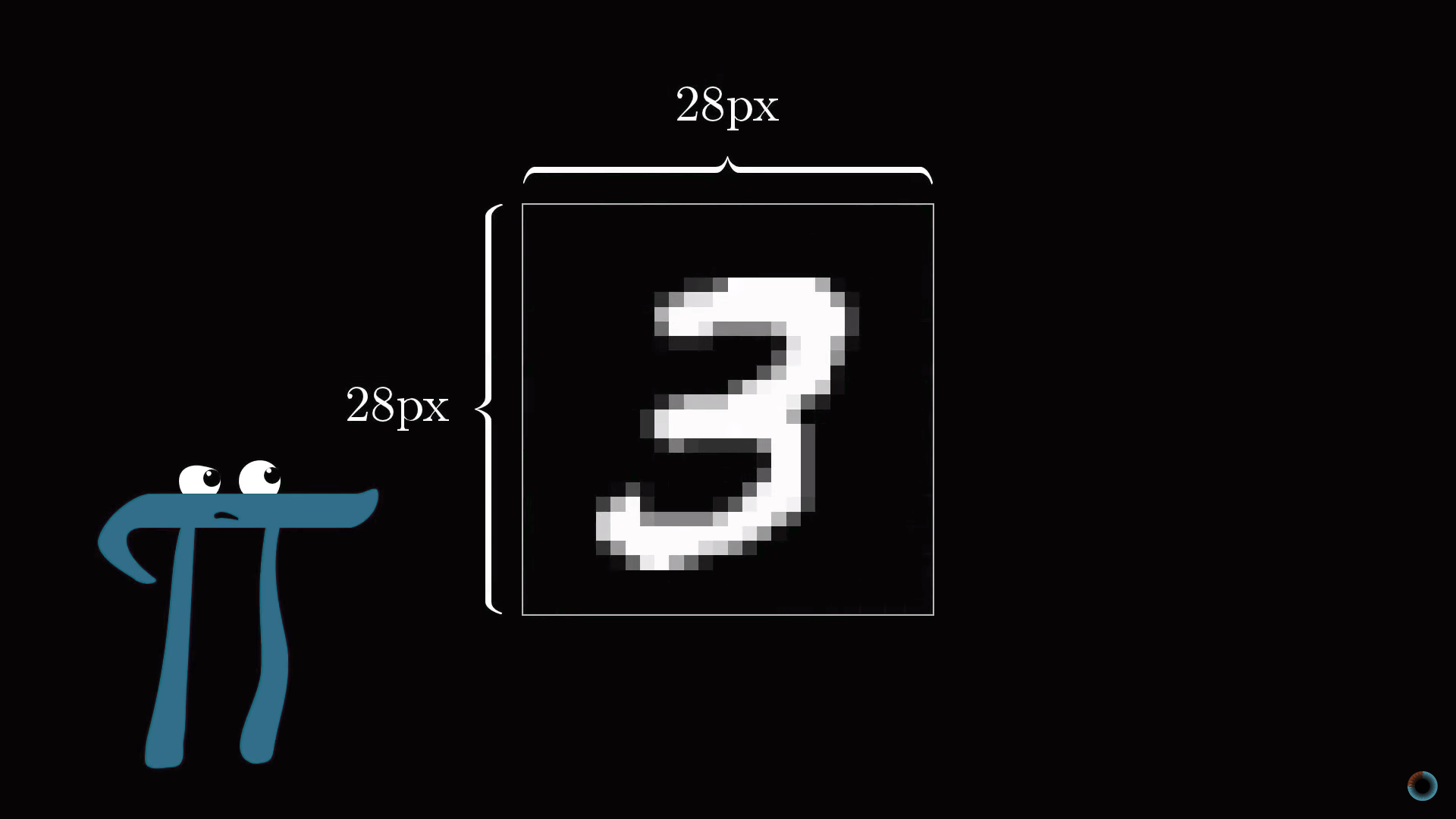
С позиций вычислительной техники удивительно, насколько легко мозг осуществляет эту операцию, при том что конкретное расположение пикселей сильно разнится от одного изображения к другому. Что-то в нашей зрительной коре решает, что все тройки, как бы они ни были изображены, представляют одну сущность. Поэтому задача распознавания цифр в таком контексте воспринимается как простая.
Но если бы вам предложили написать программу, которая принимает на вход изображение любой цифры в виде массива 28х28 пикселей и выдает на выходе саму «сущность» – цифру от 0 до 9, то эта задача перестала бы казаться простой.
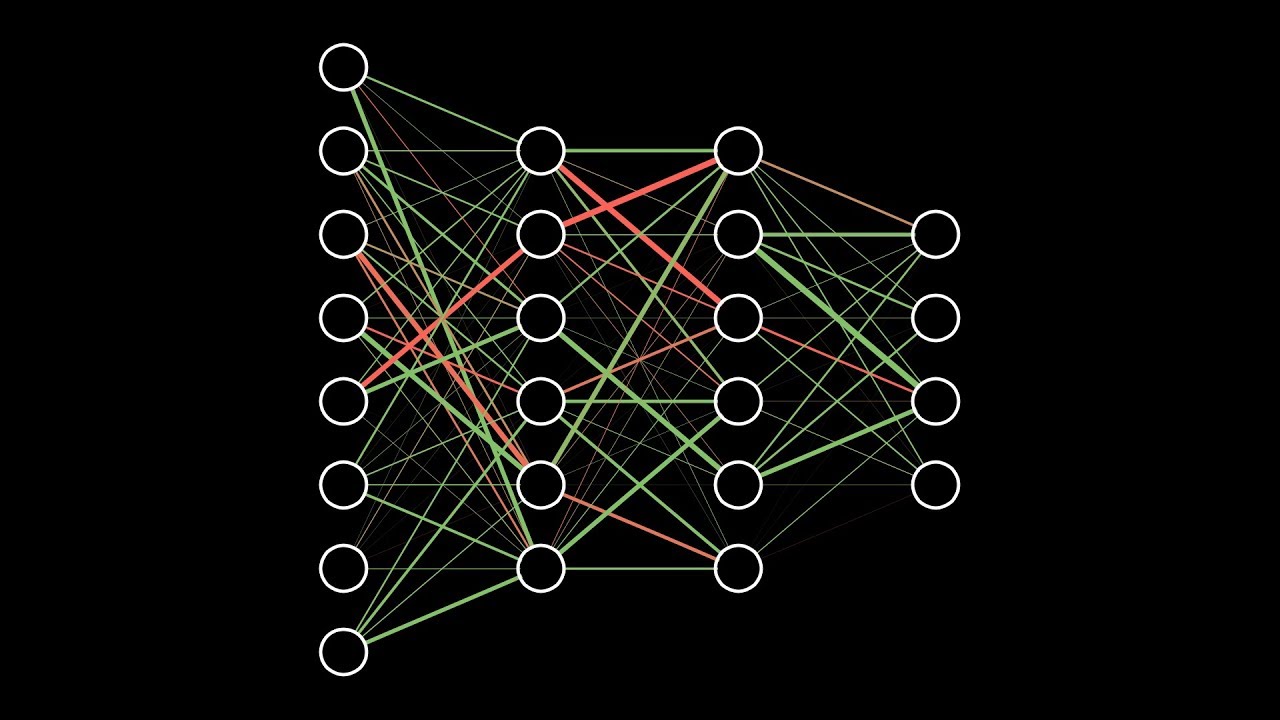
Как можно предположить из названия, устройство нейросети в чем-то близко устройству нейронной сети головного мозга. Пока для простоты будем представлять, что в математическом смысле в нейросетях под нейронами понимается некий контейнер, содержащий число от нуля до единицы.
Активация нейронов. Слои нейросети
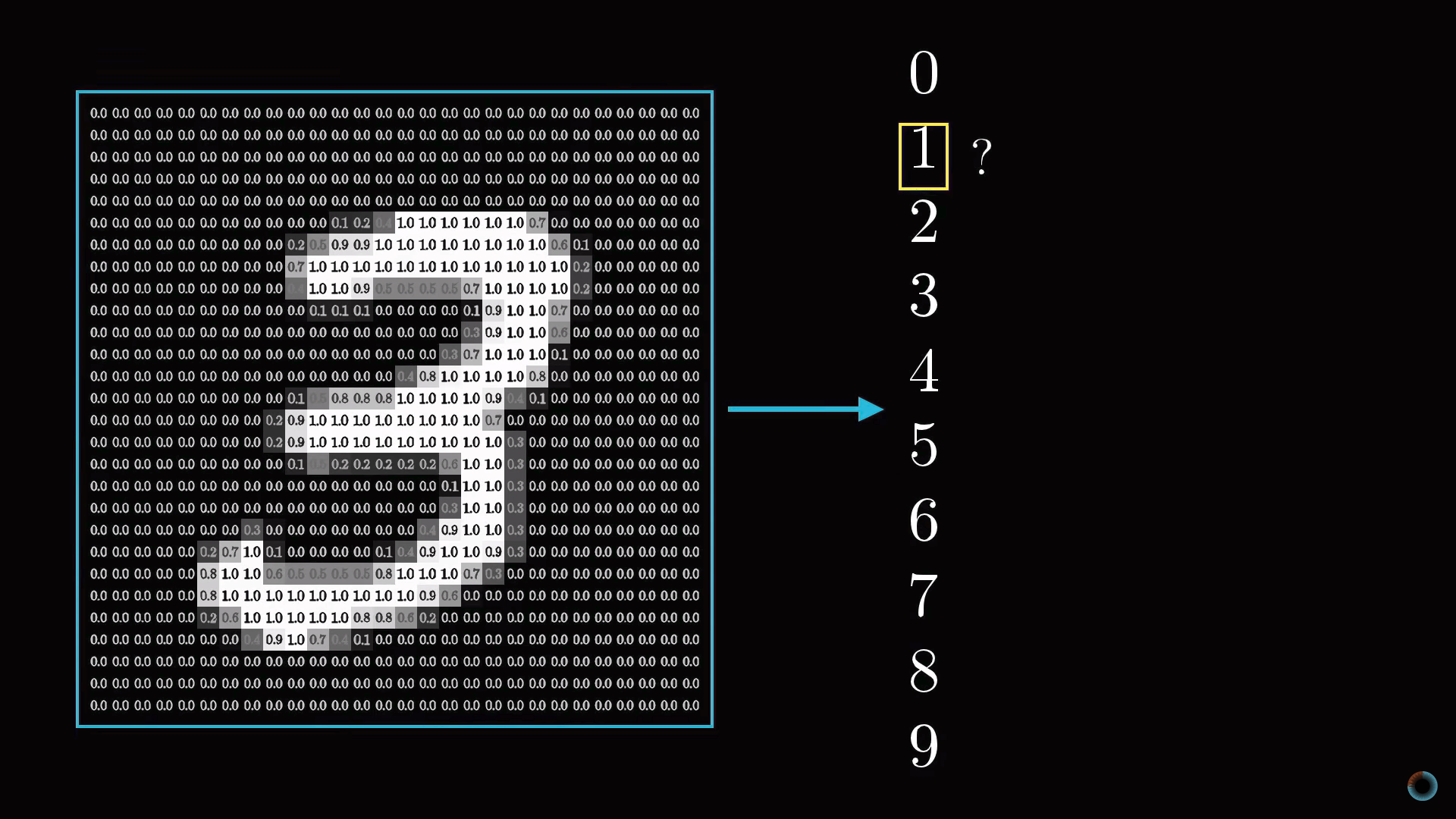
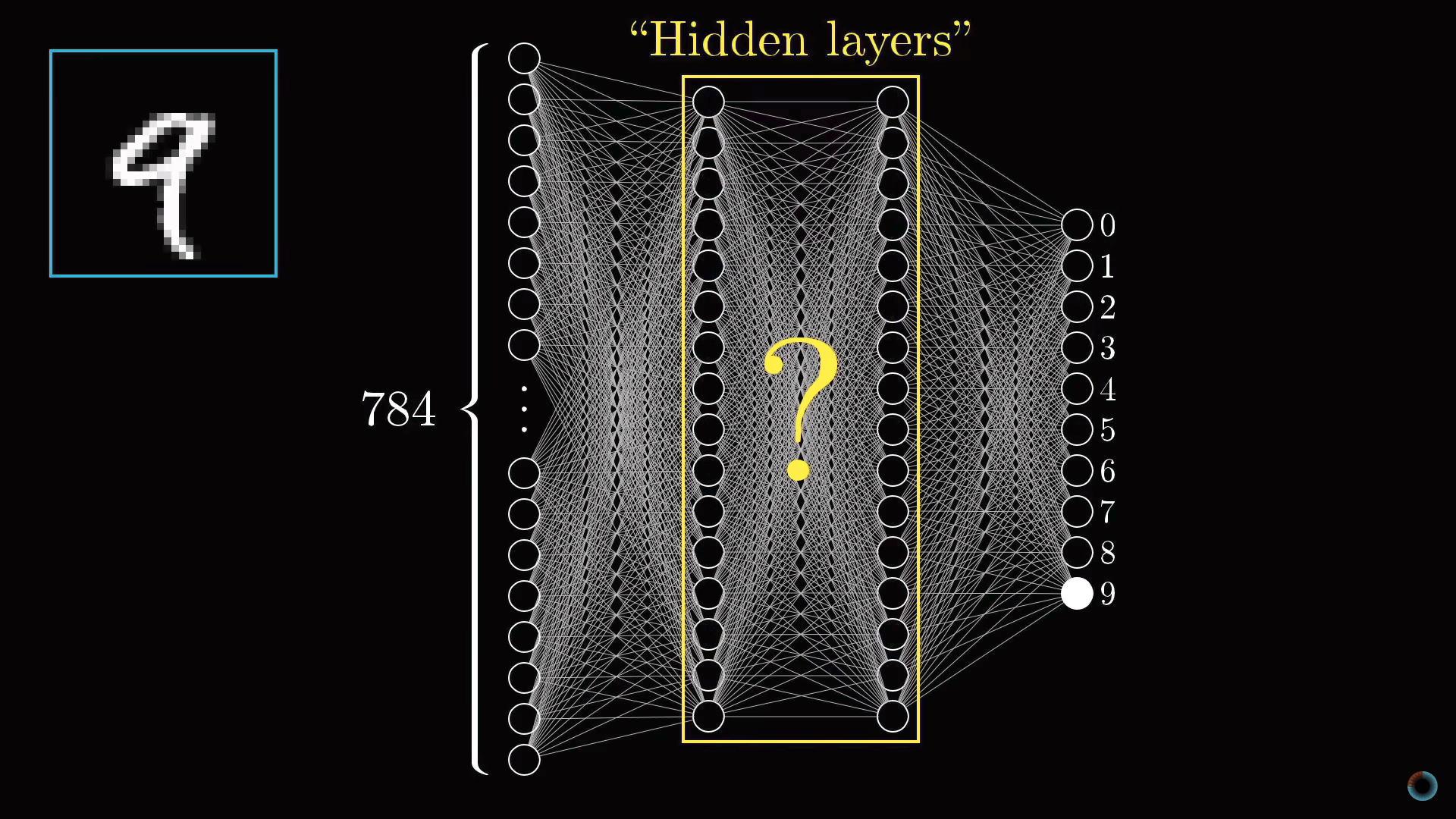
Так как наша сетка состоит из 28х28=784 пикселей, пусть есть 784 нейрона, содержащие различные числа от 0 до 1: чем ближе пиксель к белому цвету, тем ближе соответствующее число к единице. Эти заполняющие сетку числа назовем активациями нейронов. Вы можете себе представлять это, как если бы нейрон зажигался, как лампочка, когда содержит число вблизи 1 и гас при числе, близком к 0.

Описанные 784 нейрона образуют первый слой нейросети. Последний слой содержит 10 нейронов, каждый из которых соответствует одной из десяти цифр. В этих числах активация это также число от нуля до единицы, отражающее насколько система уверена, что входное изображение содержит соответствующую цифру.
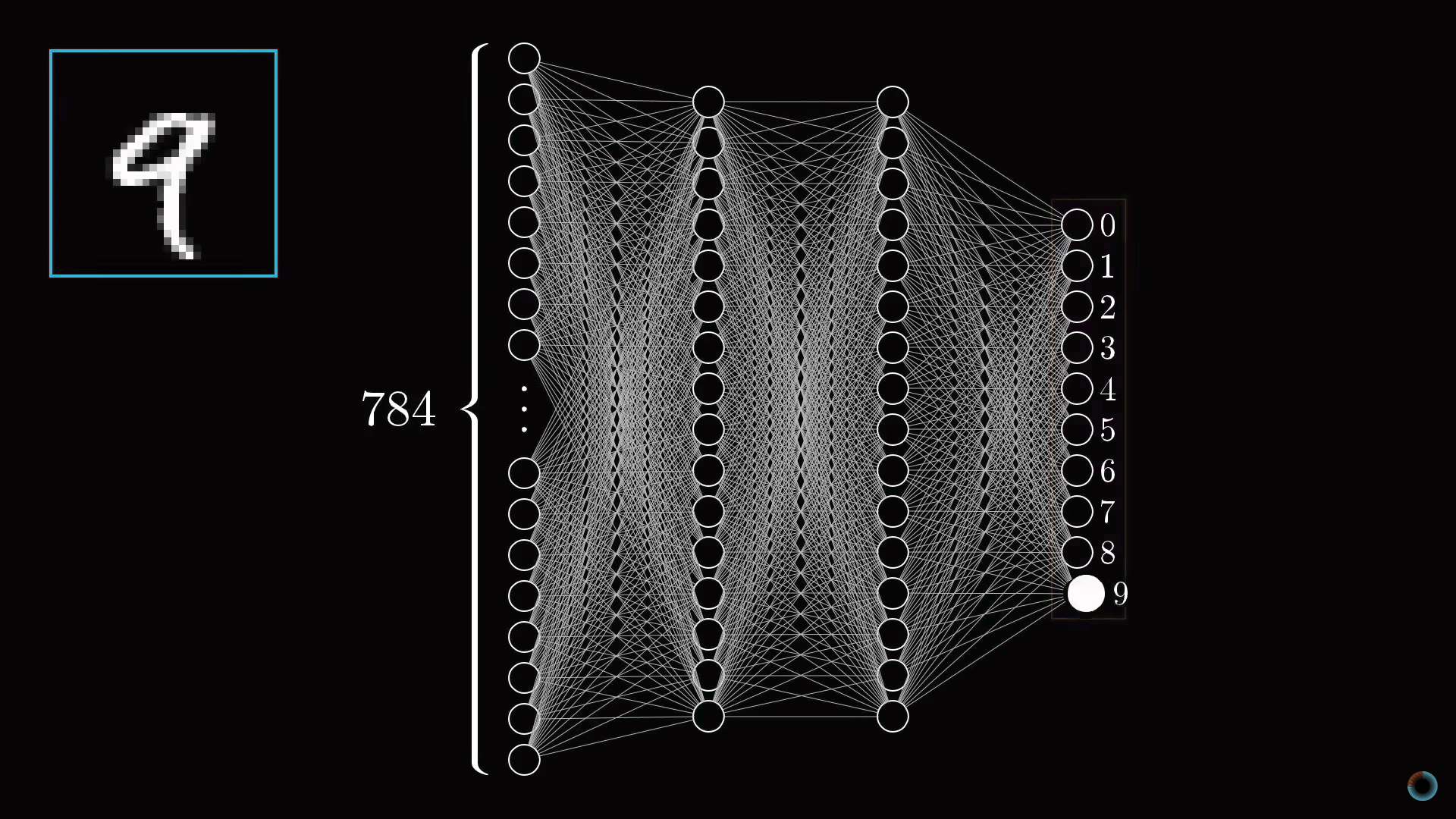
Также есть пара средних слоев, называемых скрытыми, к рассмотрению которых мы вскоре перейдем. Выбор количества скрытых слоев и содержащихся в них нейронов произволен (мы выбрали 2 слоя по 16 нейронов), однако обычно они выбираются из определенных представлений о задаче, решаемой нейронной сетью.
Принцип работы нейросети состоит в том, что активация в одном слое определяет активацию в следующем. Возбуждаясь, некоторая группа нейронов вызывает возбуждение другой группы. Если передать обученной нейронной сети на первый слой значения активации согласно яркости каждого пикселя картинки, цепочка активаций от одного слоя нейросети к следующему приведет к преимущественной активации одного из нейронов последнего слоя, соответствующего распознанной цифре – выбору нейронной сети.
Назначение скрытых слоев
Прежде чем углубляться в математику того, как один слой влияет на следующий, как происходит обучение и как нейросетью решается задача распознавания цифр, обсудим почему вообще такая слоистая структура может действовать разумно. Что делают промежуточные слои между входным и выходным слоями?
Слой образов фигур
В процессе распознавания цифр мы сводим воедино различные компоненты. Например, девятка состоит из кружка сверху и линии справа. Восьмерка также имеет кружок вверху, но вместо линии справа, у нее есть парный кружок снизу. Четверку можно представить как три определенным образом соединенные линии. И так далее.
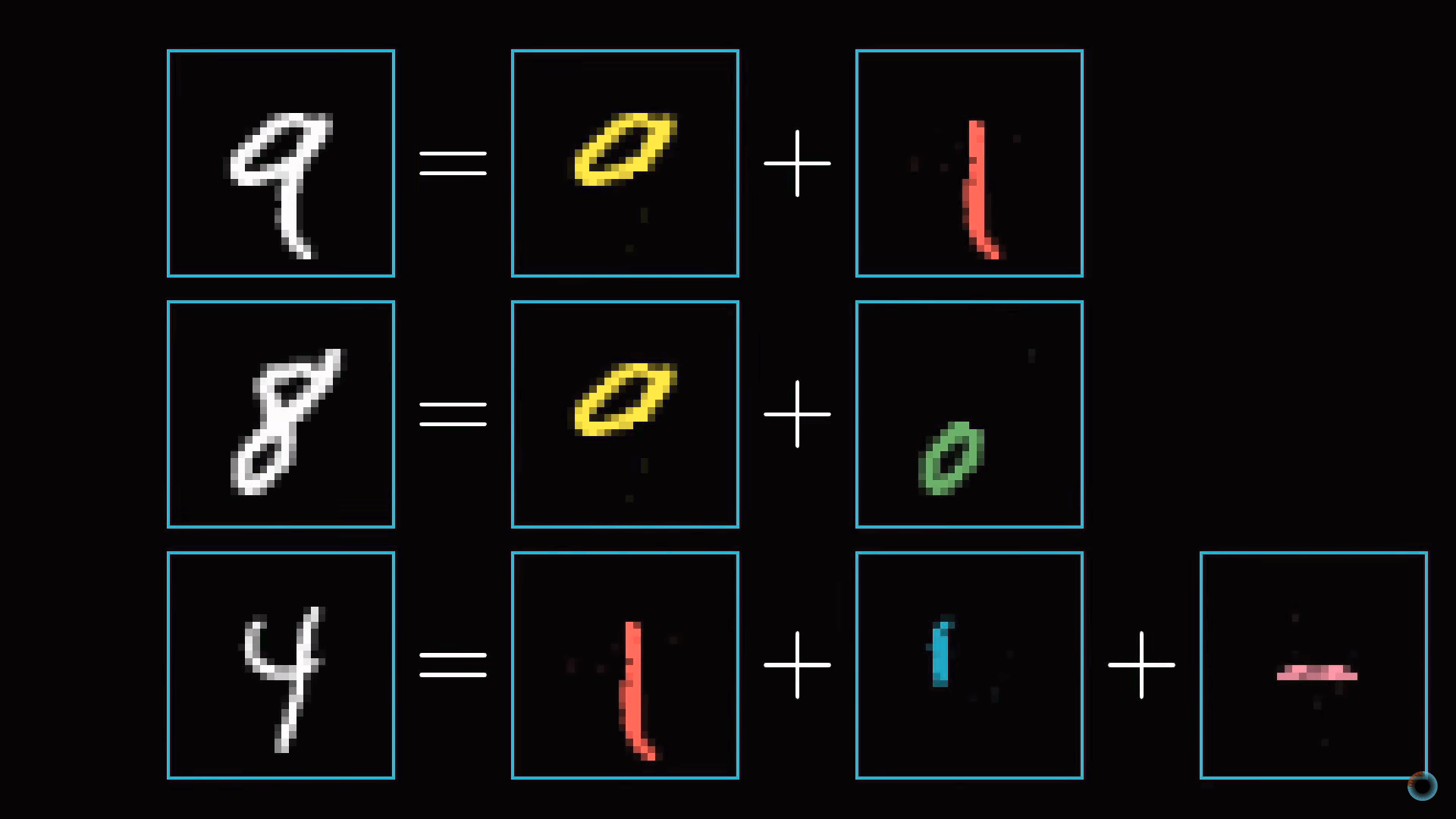
В идеализированном случае можно ожидать, что каждый нейрон из второго слоя соотносится с одним из этих компонентов. И, когда вы, например, передаете нейросети изображение с кружком в верхней части, существует определенный нейрон, чья активация станет ближе к единице. Таким образом, переход от второго скрытого слоя к выходному соответствует знаниям о том, какой набор компонентов какой цифре соответствует.
Слой образов структурных единиц
Задачу распознавания кружка так же можно разбить на подзадачи. Например, распознавать различные маленькие грани, из которых он образован. Аналогично длинную вертикальную линию можно представить как шаблон соединения нескольких меньших кусочков. Таким образом, можно надеяться, что каждый нейрон из первого скрытого слоя нейросети осуществляет операцию распознавания этих малых граней.
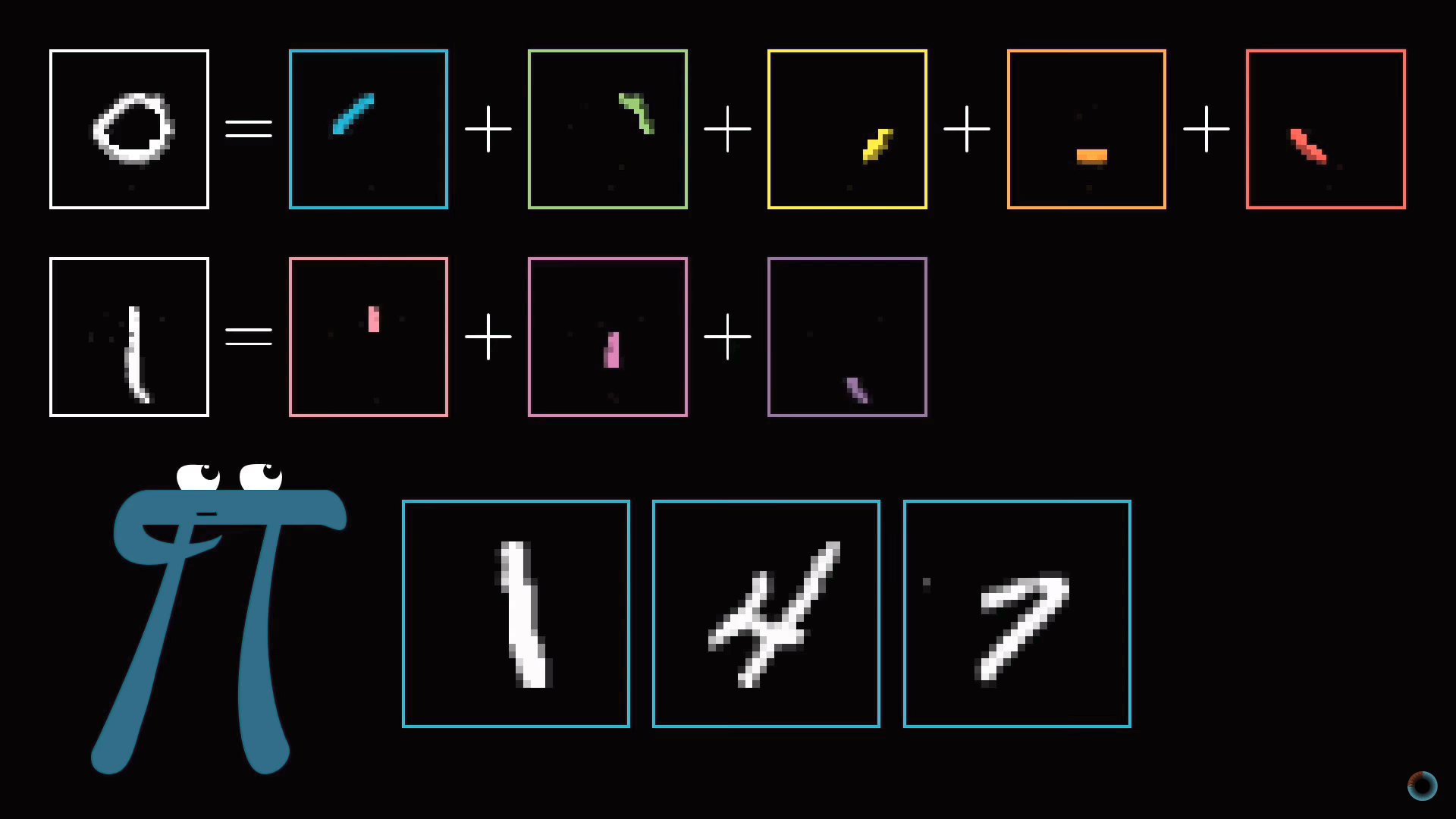
Таким образом введенное изображение приводит к активации определенных нейронов первого скрытого слоя, определяющих характерные малые кусочки, эти нейроны в свою очередь активируют более крупные формы, в результате активируя нейрон выходного слоя, ассоциированной определенной цифре.
Будет ли так действовать нейросеть или нет, это другой вопрос, к которому вы вернемся при обсуждении процесса обучения сети. Однако это может служить нам ориентиром, своего рода целью такой слоистой структуры.
С другой стороны, такое определение граней и шаблонов полезно не только в задаче распознавания цифр, но и вообще задаче определения образов.

И не только для распознавания цифр и образов, но и других интеллектуальных задач, которые можно разбить на слои абстракции. Например, для распознавания речи из сырого аудио выделяются отдельные звуки, слоги, слова, затем фразы, более абстрактные мысли и т. д.
Определение области распознавания
Для конкретики представим теперь, что цель отдельного нейрона в первом скрытом слое это определить, содержит ли картинка грань в отмеченной на рисунке области.
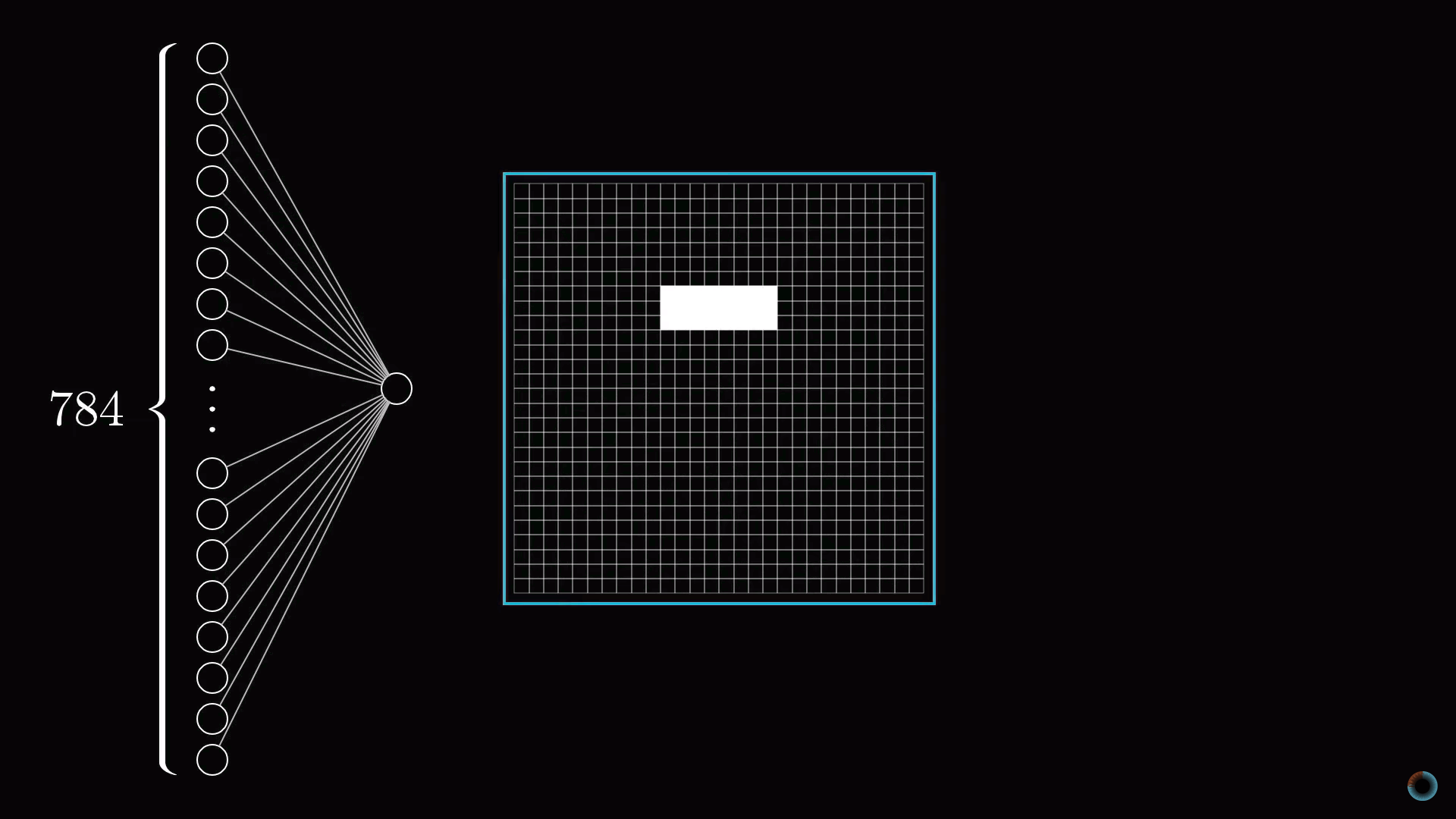
Первый вопрос: какие параметры настройки должны быть у нейросети, чтобы иметь возможность обнаружить этот шаблон или любой другой шаблон из пикселей.
Назначим числовой вес wi каждому соединению между нашим нейроном и нейроном из входного слоя. Затем возьмем все активации из первого слоя и посчитаем их взвешенную сумму согласно этим весам.
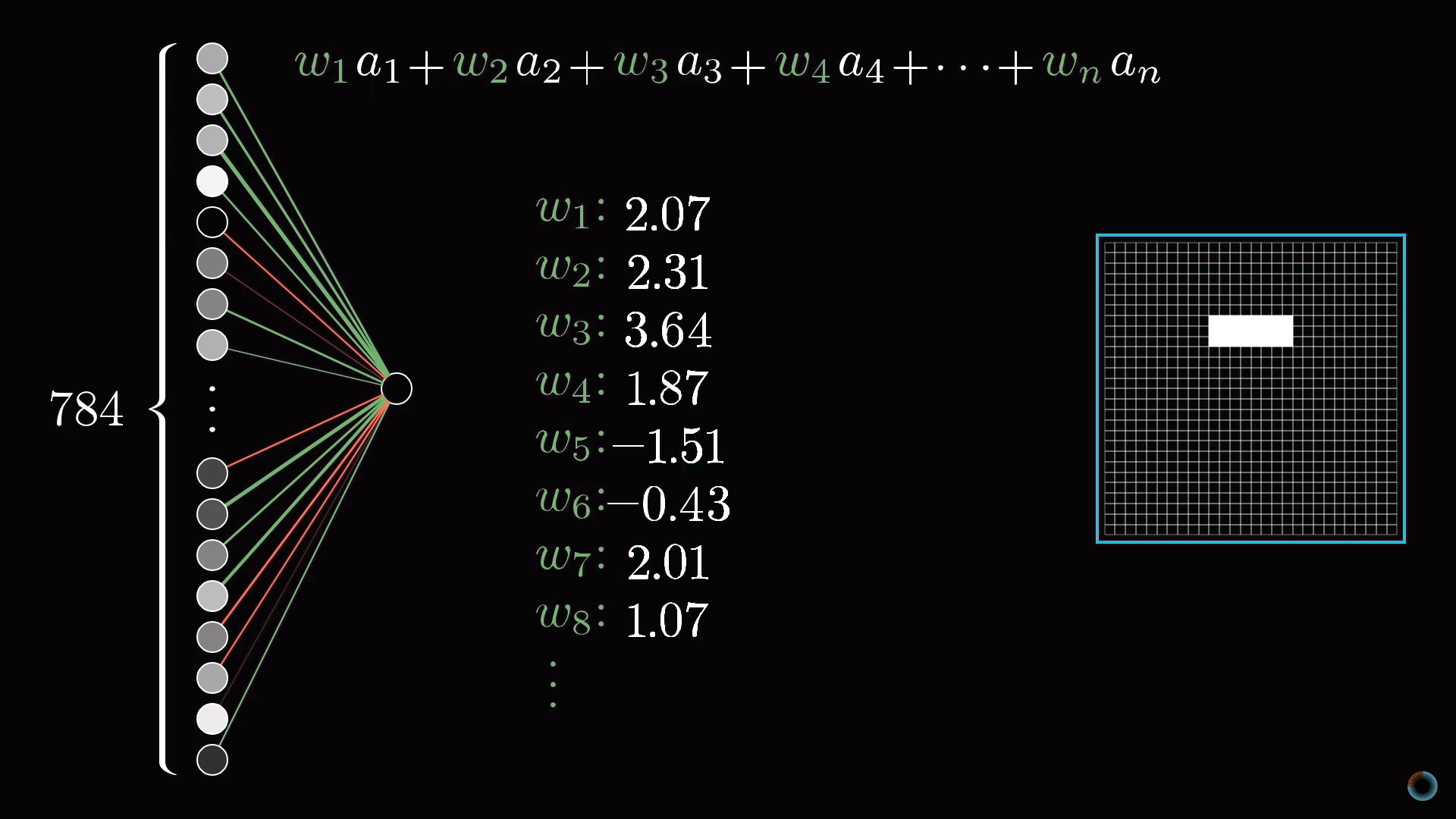
Так как количество весов такое же, как и число активаций, им также можно сопоставить аналогичную сетку. Будем обозначать зелеными пикселями положительные веса, а красными – отрицательные. Яркость пикселя будет соответствовать абсолютному значению веса.
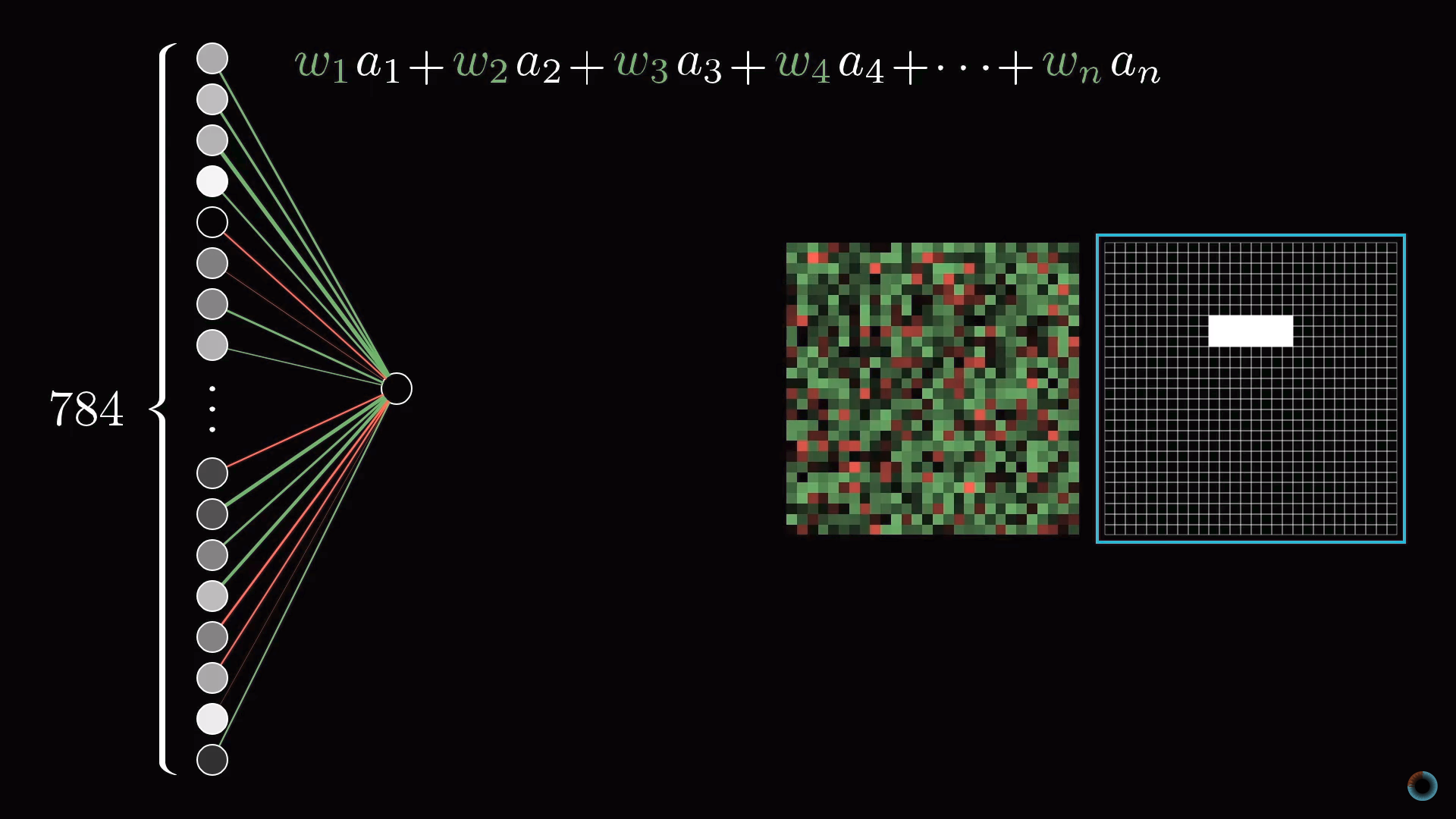
Теперь, если мы установим все веса равными нулю, кроме пикселей, соответствующих нашему шаблону, то взвешенная сумма сведется к суммированию значений активаций пикселей в интересующей нас области.
Если же вы хотите, определить есть ли там именно ребро, вы можете добавить вокруг зеленого прямоугольника весов красные весовые грани, соответствующие отрицательным весам. Тогда взвешенная сумма для этого участка будет максимальной, когда средние пиксели изображения в этой части ярче, а окружающих их пиксели темнее.

Масштабирование активации до интервала [0, 1]
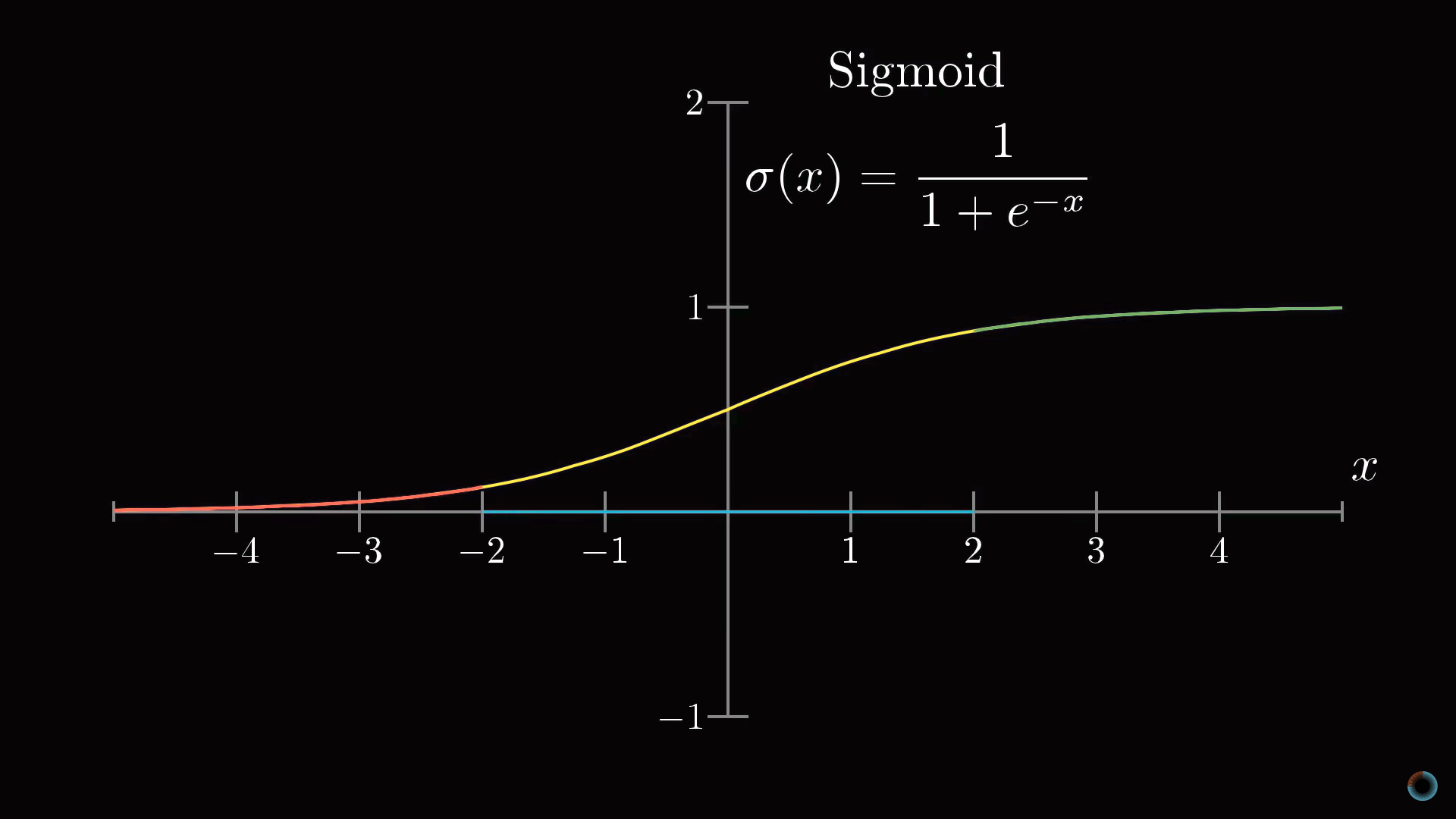
Вычислив такую взвешенную сумму, вы можете получить любое число в широком диапазоне значений. Для того, чтобы оно попадало в необходимый диапазон активаций от 0 до 1, разумно использовать функцию, которая бы «сжимала» весь диапазон до интервала [0, 1].

Часто для такого масштабирования используется логистическая функция сигмоиды. Чем больше абсолютное значение отрицательного входного числа, тем ближе выходное значение сигмоиды к нулю. Чем больше значение положительного входного числа, тем ближе значение функции к единице.
Таким образом, активация нейрона это по сути мера того, насколько положительна соответствующая взвешенная сумма. Чтобы нейрон не активировался при малых положительных числах, можно добавить к взвешенной сумме некоторое отрицательное число – сдвиг (англ. bias), определяющий насколько большой должна быть взвешенная сумма, чтобы активировать нейрон.
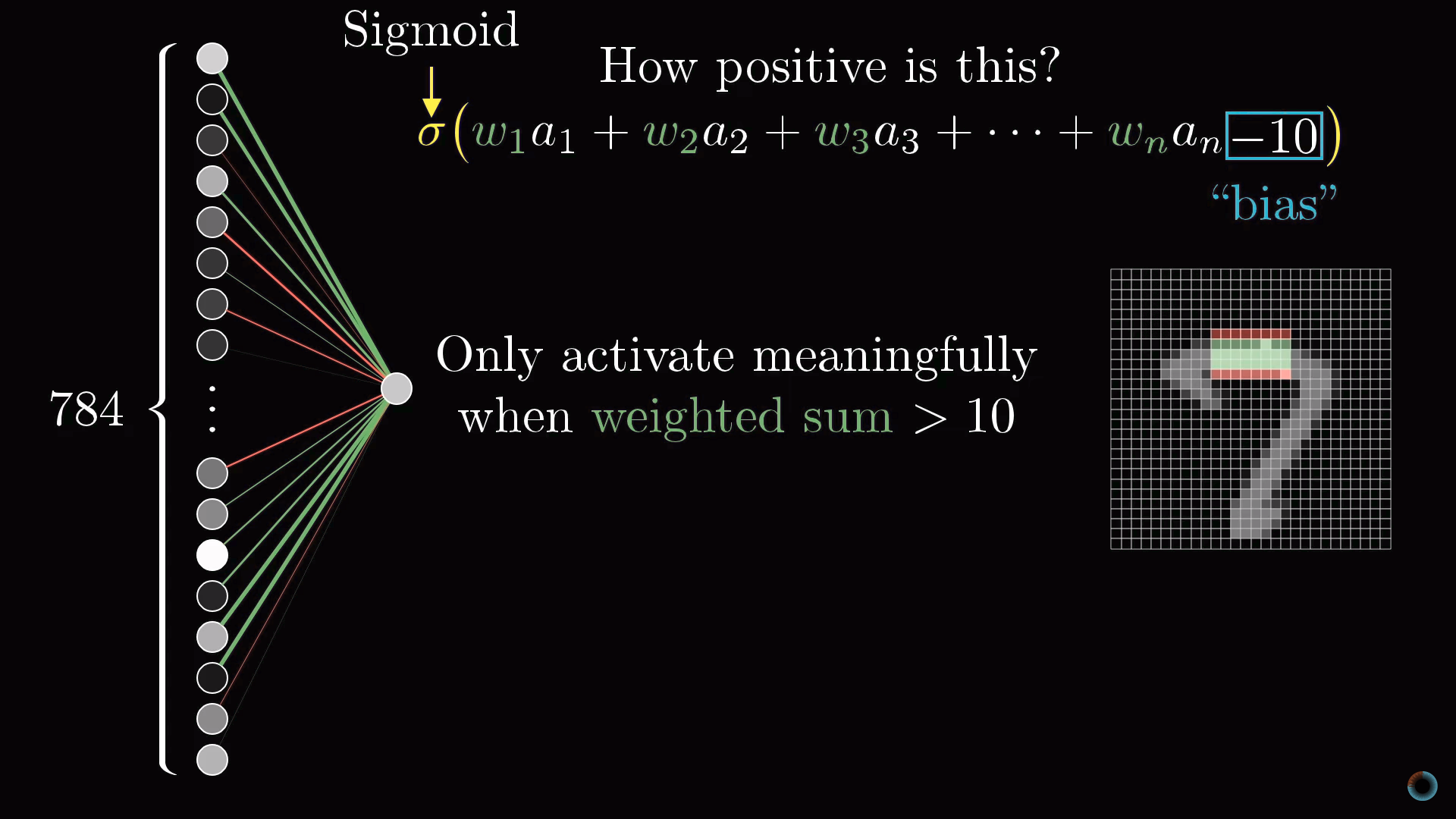
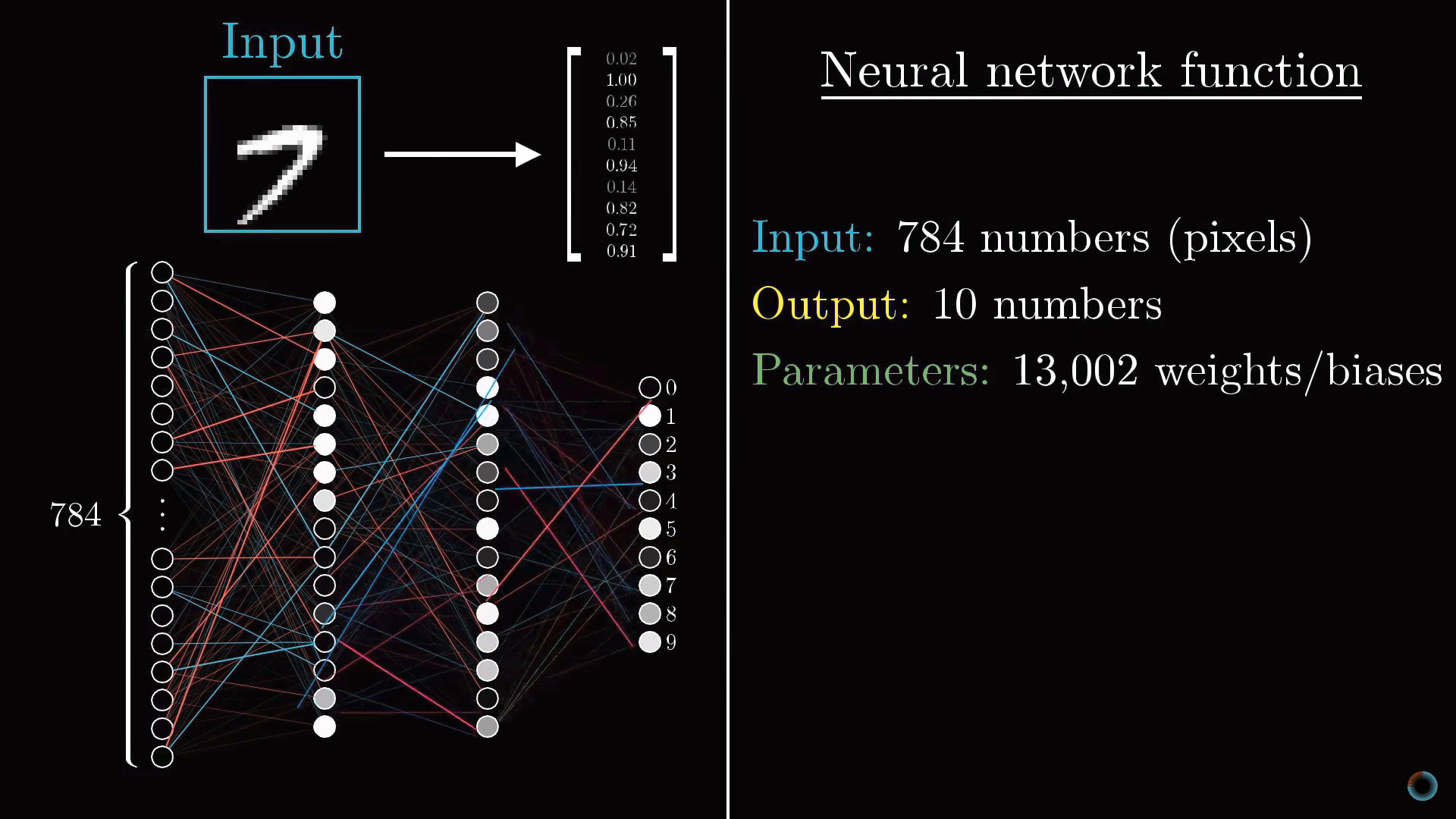
Разговор пока шел только об одном нейроне. Каждый нейрон из первого скрытого слоя соединен со всеми 784 пиксельными нейронами первого слоя. И каждое из этих 784 соединений будет иметь свой ассоциированный с ним вес. Также у каждого из нейронов первого скрытого слоя есть ассоциированный с ним сдвиг, добавляемый к взвешенной сумме перед «сжатием» этого значения сигмоидой. Таким образом, для первого скрытого слоя имеется 784х16 весов и 16 сдвигов.
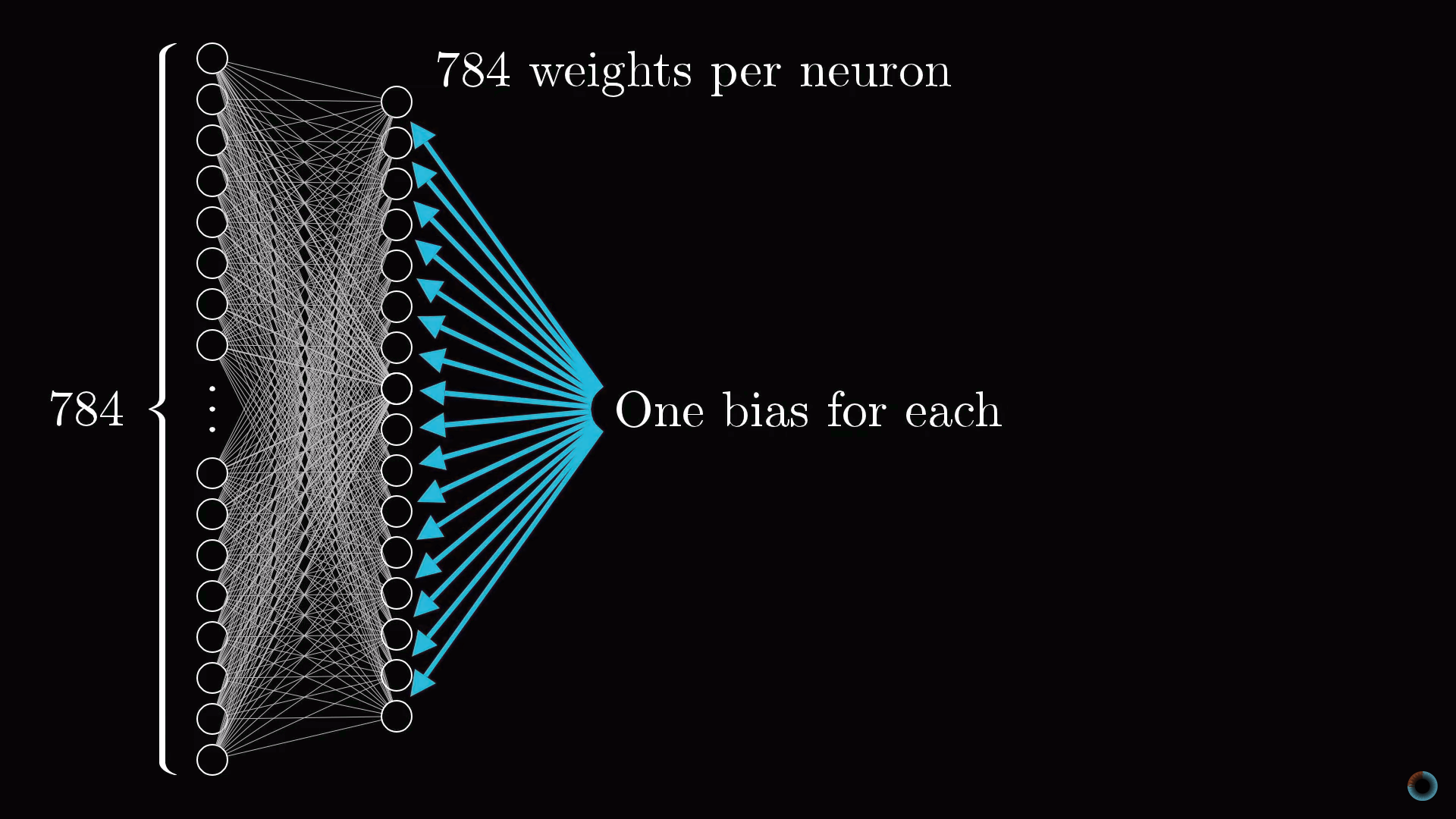
Соединение между другими слоями также содержат веса и сдвиги, связанные с ними. Таким образом, для приведенного примера в качестве настраиваемых параметров выступают около 13 тыс. весов и сдвигов, определяющих поведение нейронной сети.
Обучить нейросеть задаче распознавания цифр значит заставить компьютер найти корректные значения для всех этих чисел так, чтобы это решило поставленную задачу. Представьте себе настройку всех этих весов и сдвигу вручную. Это один из действенных аргументов, чтобы трактовать нейросеть как черный ящик – мысленно отследить совместное поведение всех параметров практически невозможно.
Описание нейросети в терминах линейной алгебры
Обсудим компактный способ математического представления соединений нейросети. Объединим все активации первого слоя в вектор-столбец. Все веса объединим в матрицу, каждая строка которой описывает соединения между нейронами одного слоя с конкретным нейроном следующего (в случае затруднений посмотрите описанный нами курс по линейной алгебре). В результате умножения матрицы на вектор получим вектор, соответствующий взвешенным суммам активаций первого слоя. Сложим матричное произведение с вектором сдвигов и обернем функцией сигмоиды для масштабирования интервалов значений. В результате получим столбец соответствующих активаций.
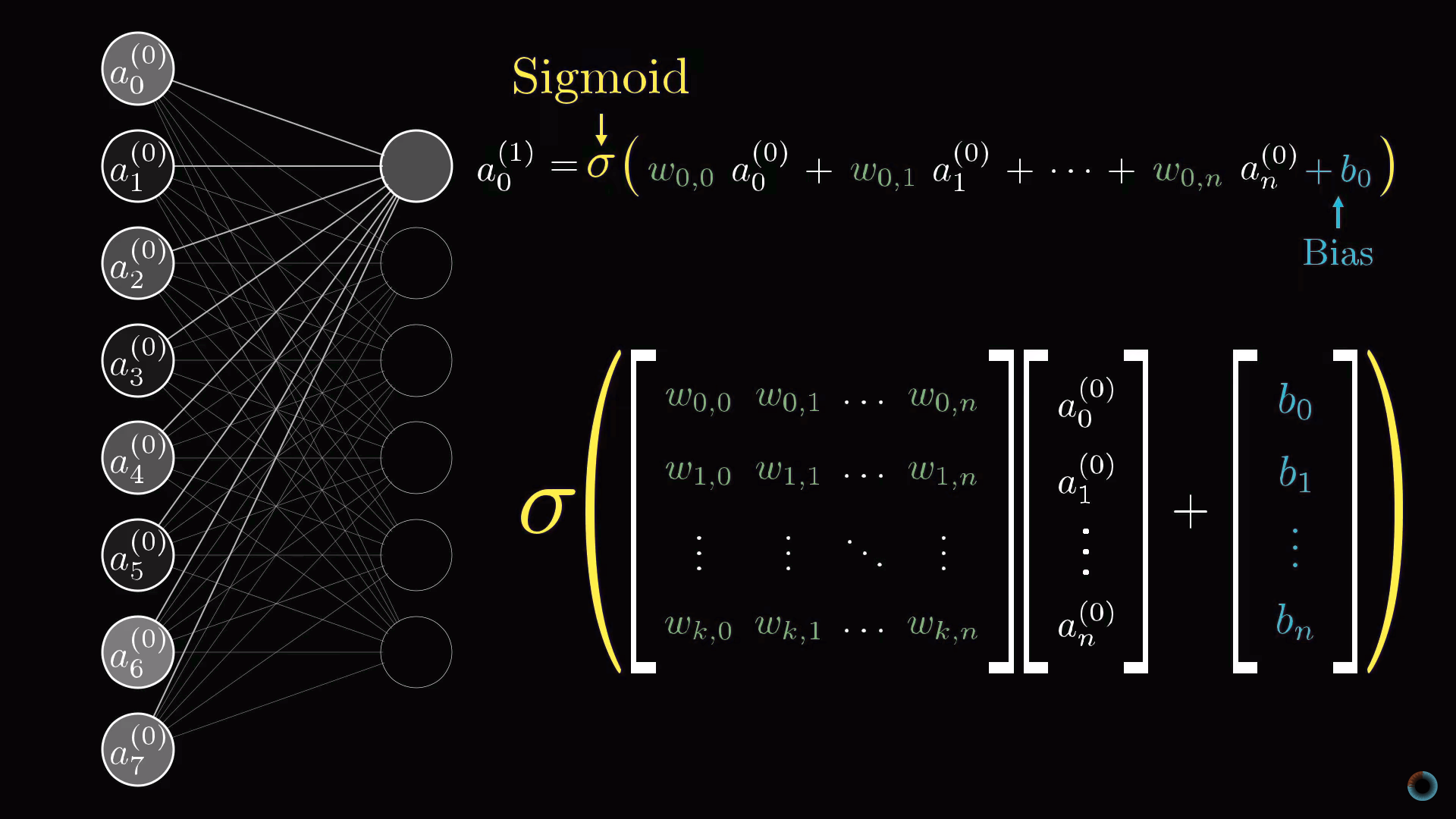
Очевидно, что вместо столбцов и матриц, как это принято в линейной алгебре, можно использовать их краткие обозначения. Это делает соответствующий программный код и проще, и быстрее, так как библиотеки машинного обучения оптимизированы под векторные вычисления.
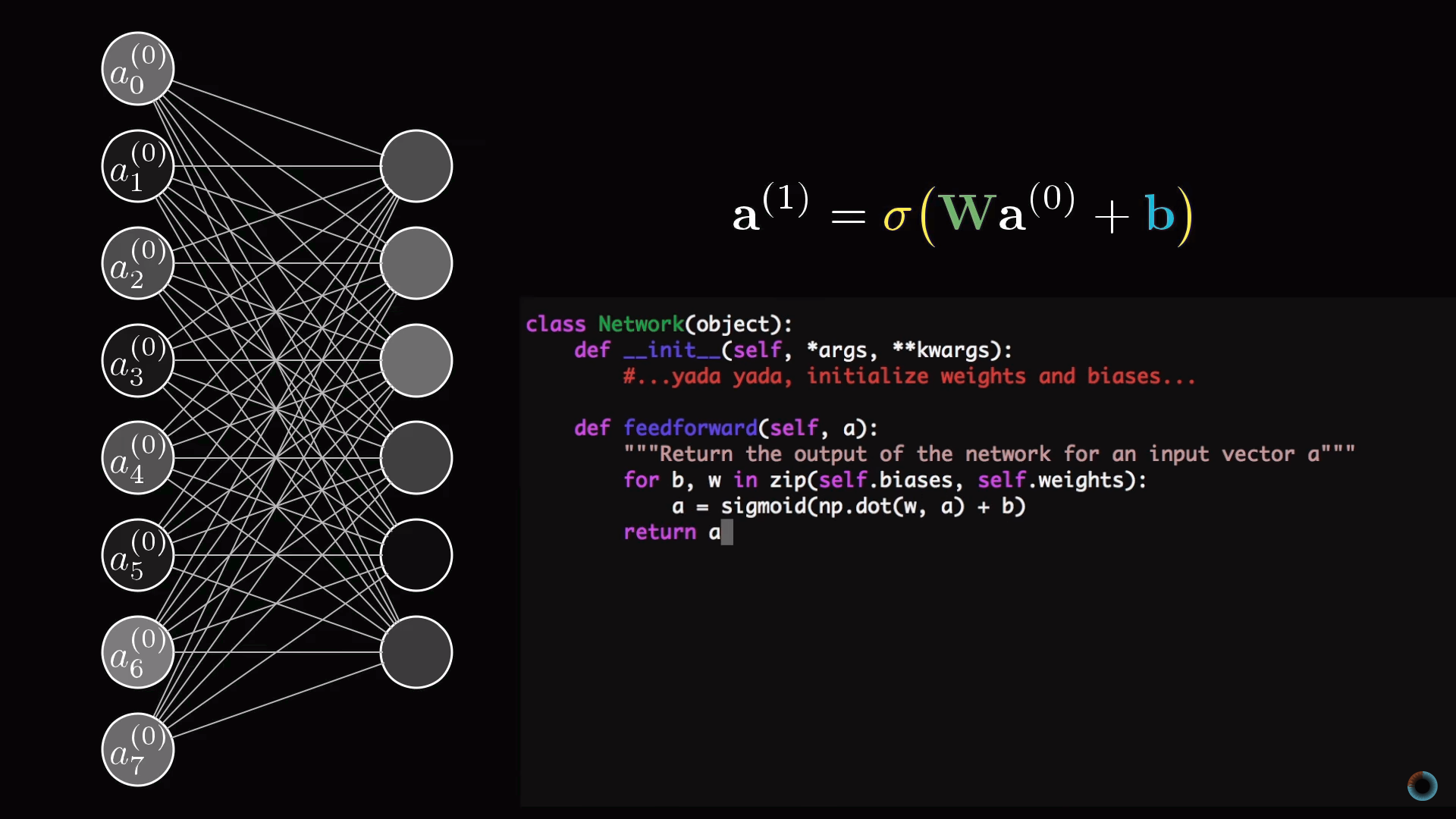
Уточнение об активации нейронов
Настало время уточнить то упрощение, с которого мы начали. Нейронам соответствуют не просто числа – активации, а функции активации, принимающие значения со всех нейронов предыдущего слоя и вычисляющие выходные значения в интервале от 0 до 1.
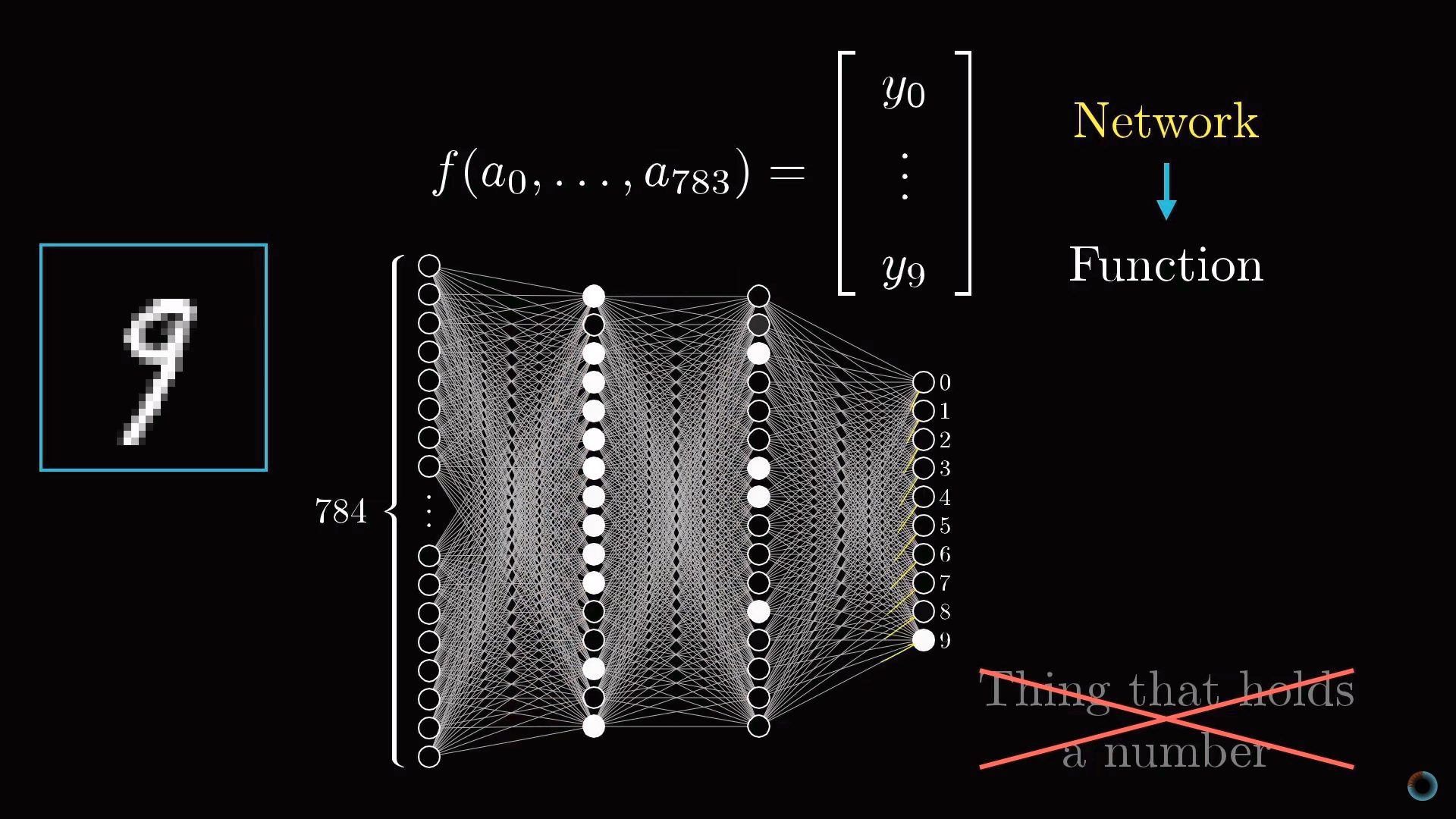
Фактически вся нейросеть это одна большая настраиваемая через обучения функция с 13 тысячами параметров, принимающая 784 входных значения и выдающая вероятность того, что изображение соответствует одной из десяти предназначенных для распознавания цифр. Тем не менее, не смотря на свою сложность, это просто функция, и в каком-то смысле логично, что она выглядит сложной, так как если бы она была проще, эта функция не была бы способна решить задачу распознавания цифр.
В качестве дополнения обсудим, какие функции активации используются для программирования нейронных сетей сейчас.
Дополнение: немного о функциях активации. Сравнение сигмоиды и ReLU
Затронем кратко тему функций, используемых для «сжатия» интервала значений активаций. Функция сигмоиды является примером, подражающим биологическим нейронам и она использовалась в ранних работах о нейронных сетях, однако сейчас чаще используется более простая ReLU функция, облегчающая обучение нейросети.
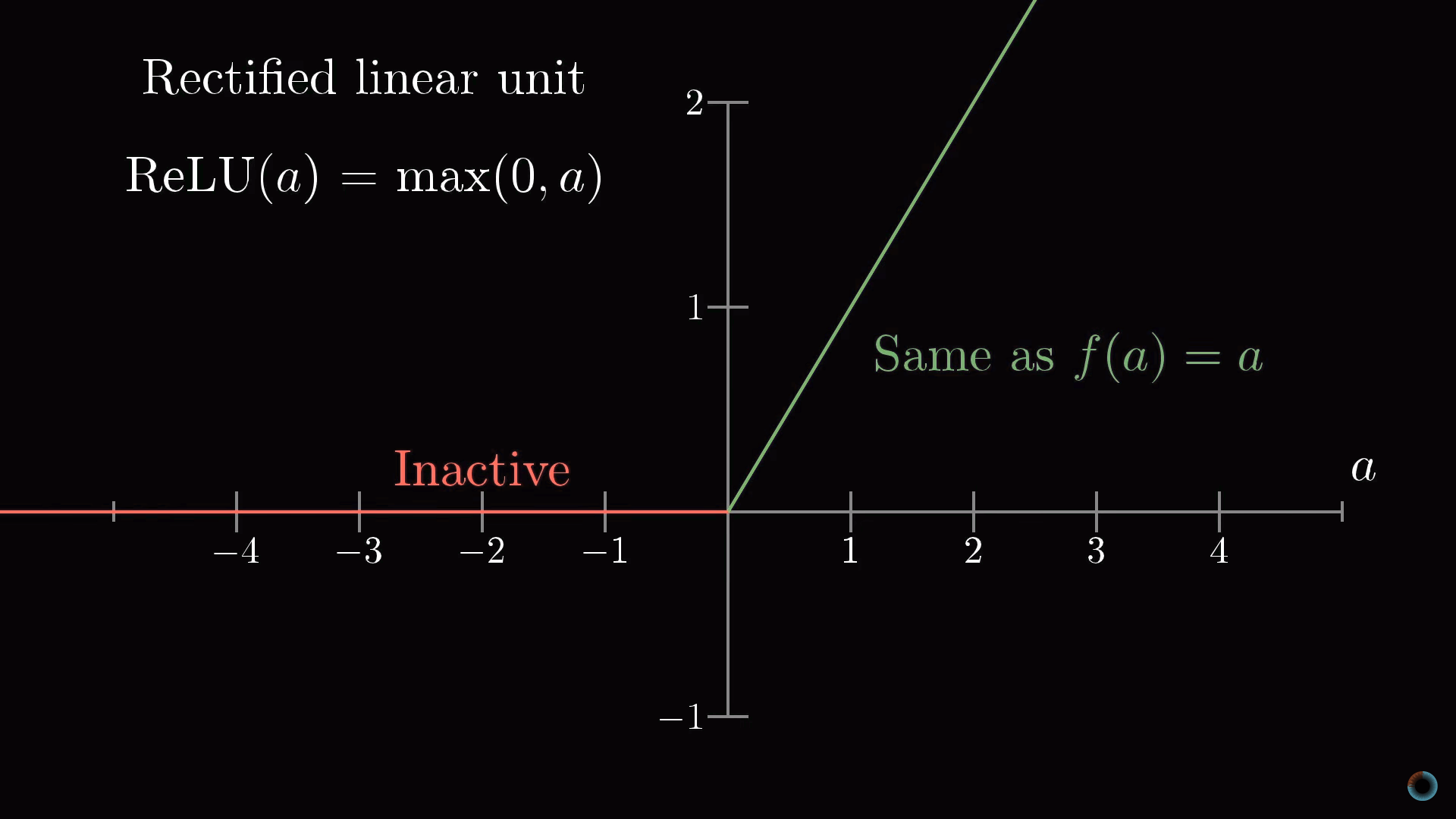
Функция ReLU соответствует биологической аналогии того, что нейроны могут находиться в активном состояни либо нет. Если пройден определенный порог, то срабатывает функция, а если не пройден, то нейрон просто остается неактивным, с активацией равной нулю.
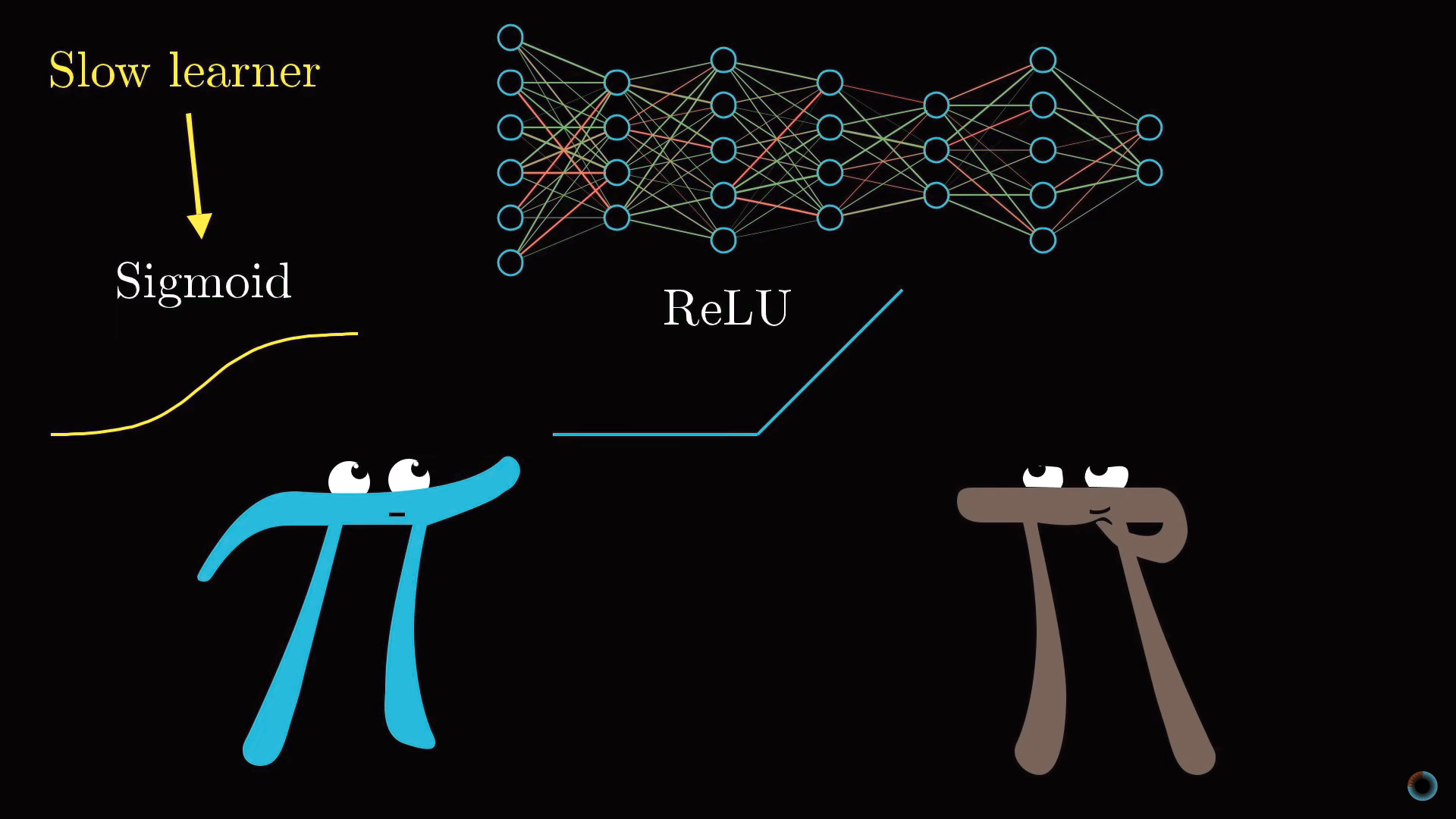
Оказалось, что для глубоких многослойных сетей функция ReLU работает очень хорошо и часто нет смысла использовать более сложную для расчета функцию сигмоиды.
2. Обучение нейронной сети для распознавания цифр
Возникает вопрос: как описанная в первом уроке сеть находит соответствующие веса и сдвиги только исходя из полученных данных? Об этом рассказывает второй урок.
В общем виде алгоритм состоит в том, чтобы показать нейросети множество тренировочных данных, представляющих пары изображений записанных от руки цифр и их абстрактных математических представлений.
В общих чертах
В результате обучения нейросеть должна правильным образом различать числа из ранее не представленных, тестовых данных. Соответственно в качестве проверки обучения нейросети можно использовать отношение числа актов корректного распознавания цифр к количеству элементов тестовой выборки.
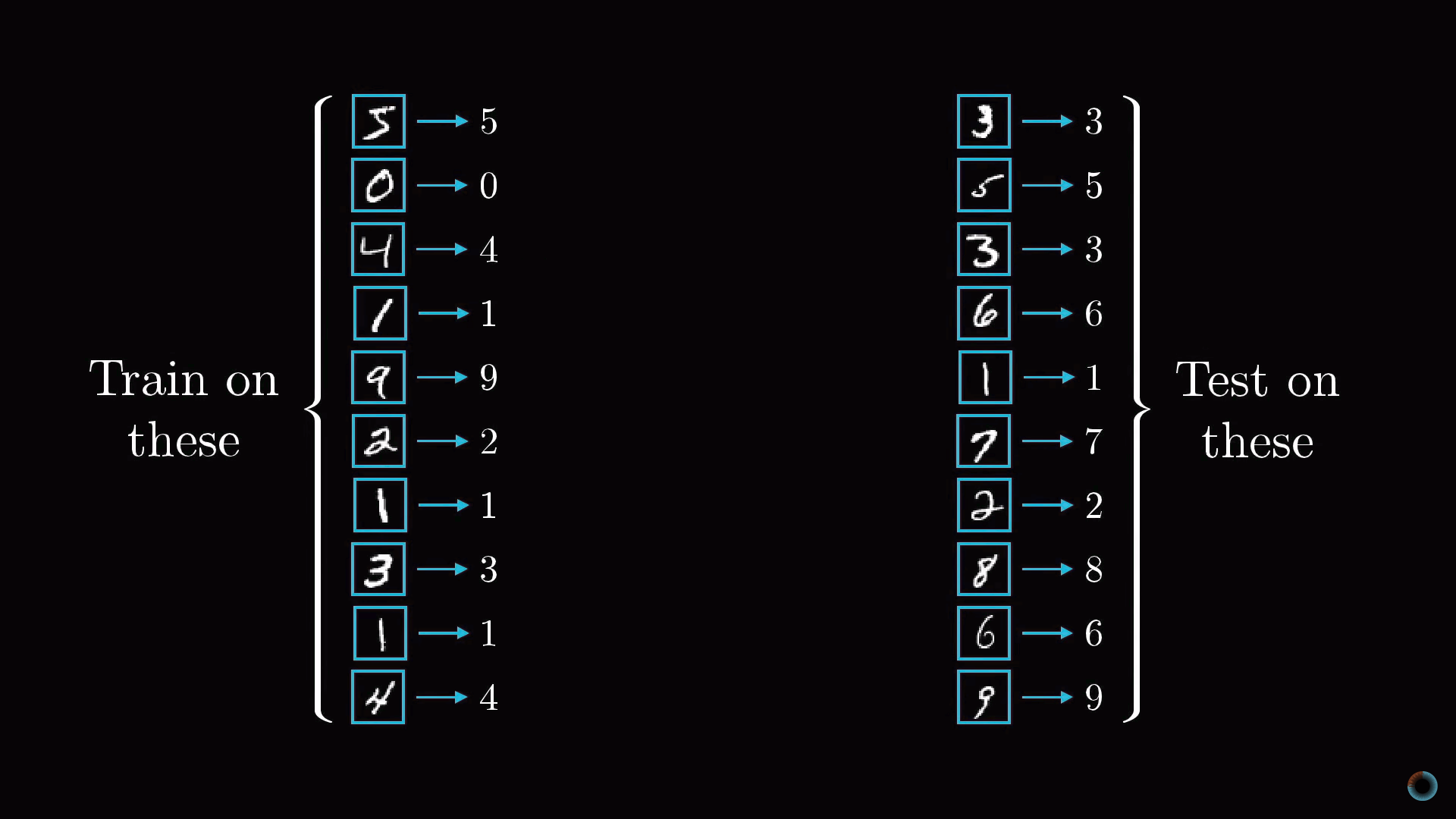
Откуда берутся данные для обучения? Рассматриваемая задача очень распространена, и для ее решения создана крупная база данных MNIST, состоящая из 60 тыс. размеченных данных и 10 тыс. тестовых изображений.

Функция стоимости
Концептуально задача обучения нейросети сводится к нахождению минимума определенной функции – функции стоимости. Опишем что она собой представляет.
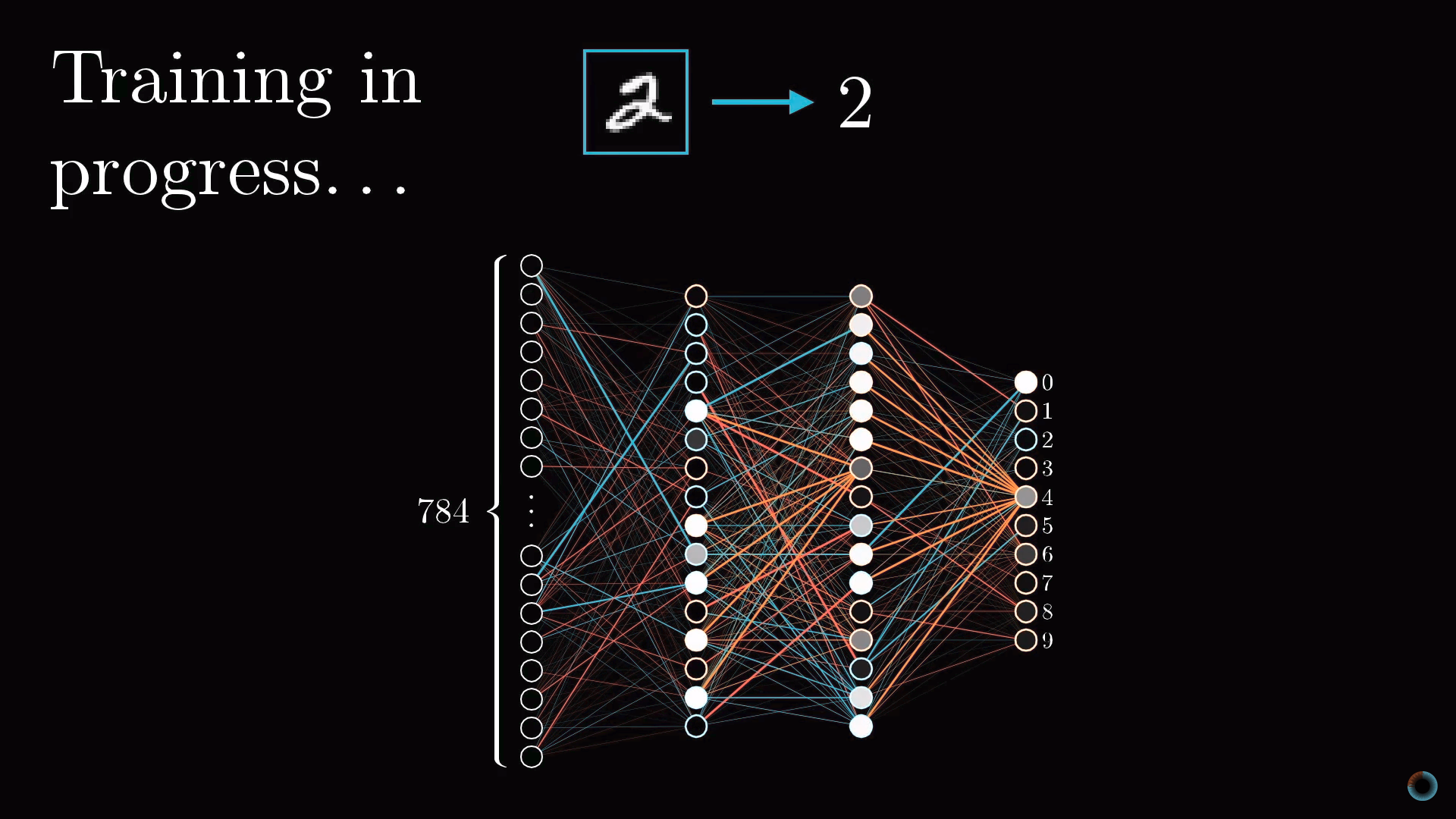
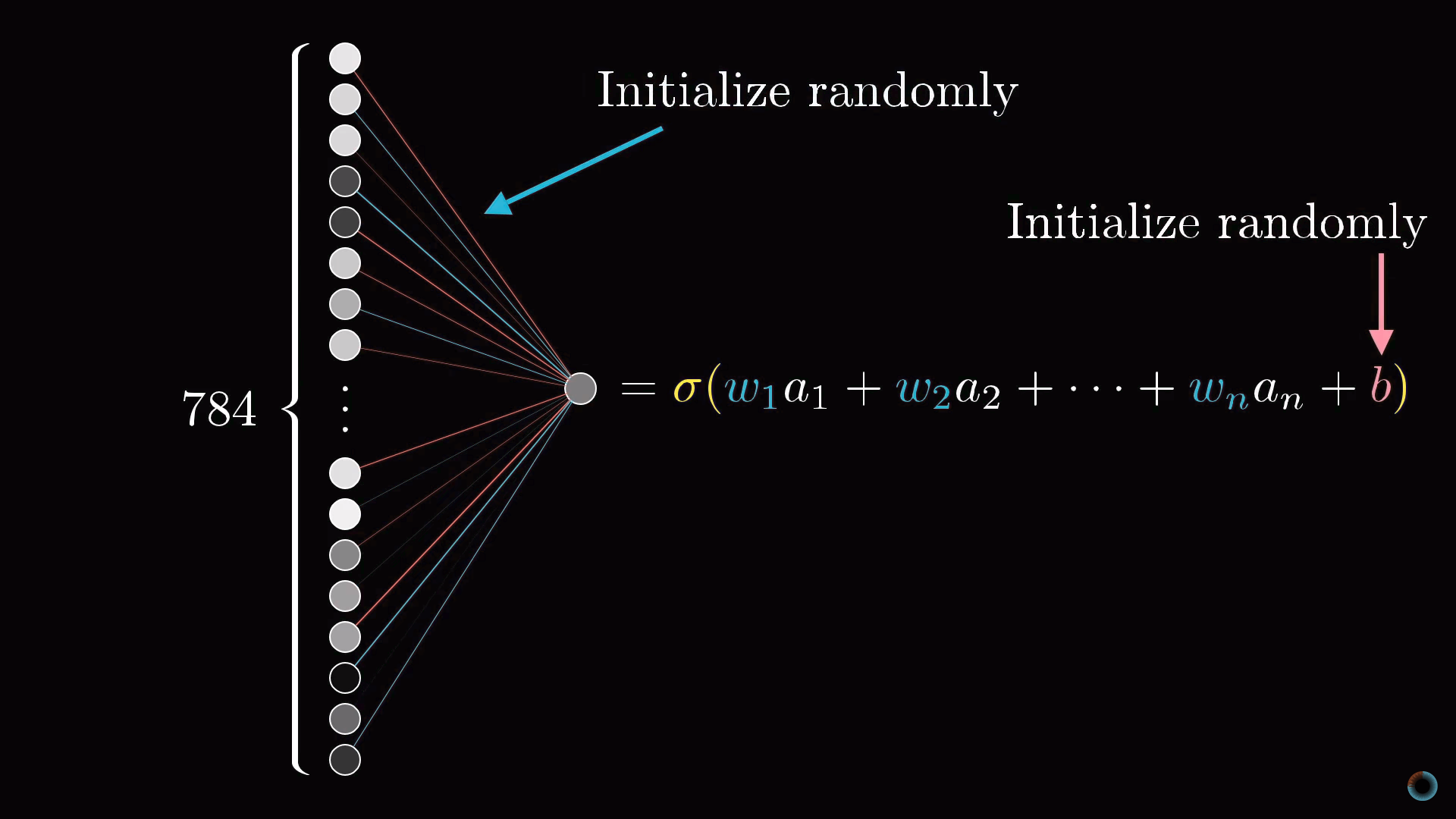
Как вы помните, каждый нейрон следующего слоя соединен с нейроном предыдущего слоя, при этом веса этих связей и общий сдвиг определяют его функцию активации. Для того, чтобы с чего-то начать мы можем инициализировать все эти веса и сдвиги случайными числами.
Соответственно в начальный момент необученная нейросеть в ответ на изображение заданного числа, например, изображение тройки, выходной слой выдает совершенно случайный ответ.
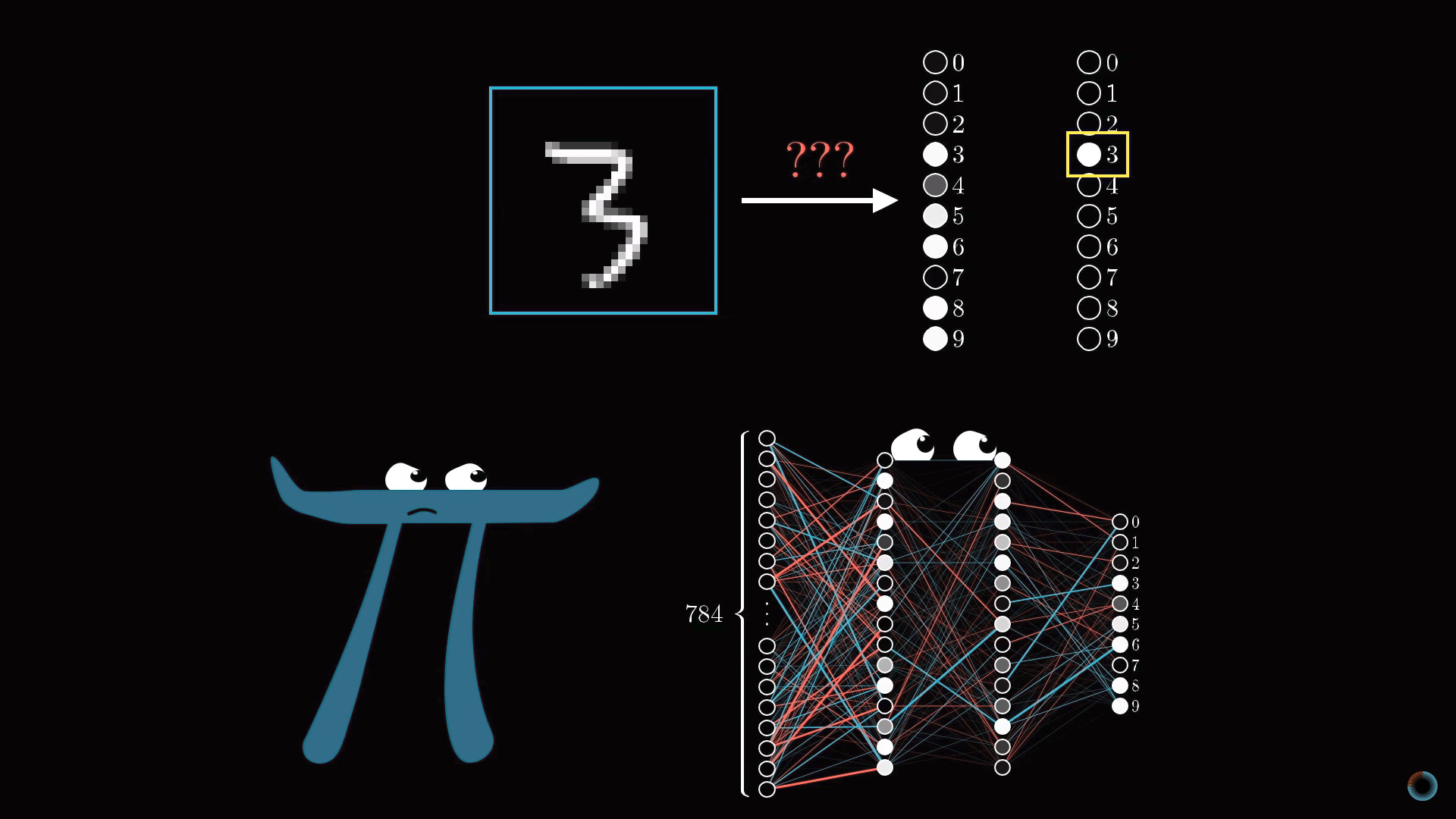
Чтобы обучать нейросеть, введем функцию стоимости (англ. cost function), которая будет как бы говорить компьютеру в случае подобного результата: «Нет, плохой компьютер! Значение активации должно быть нулевым у всех нейронов кроме одного правильного».
Задание функции стоимости для распознавания цифр
Математически эта функция представляет сумму квадратов разностей между реальными значениями активации выходного слоя и их же идеальными значениями. Например, в случае тройки активация должна быть нулевой для всех нейронов, кроме соответствующего тройке, у которого она равна единице.

Получается, что для одного изображения мы можем определить одно текущее значение функции стоимости. Если нейросеть обучена, это значения будет небольшим, в идеале стремящимся к нулю, и наоборот: чем больше значение функции стоимости, тем хуже обучена нейросеть.
Таким образом, чтобы впоследствии определить, насколько хорошо произошло обучение нейросети, необходимо определить среднее значение функции стоимости для всех изображений обучающей выборки.
Это довольно трудная задача. Если наша нейросеть имеет на входе 784 пикселя, на выходе 10 значений и требует для их расчета 13 тыс. параметров, то функция стоимости является функцией от этих 13 тыс. параметров, выдает одно единственное значение стоимости, которое мы хотим минимизировать, и при этом в качестве параметров выступает вся обучающая выборка.
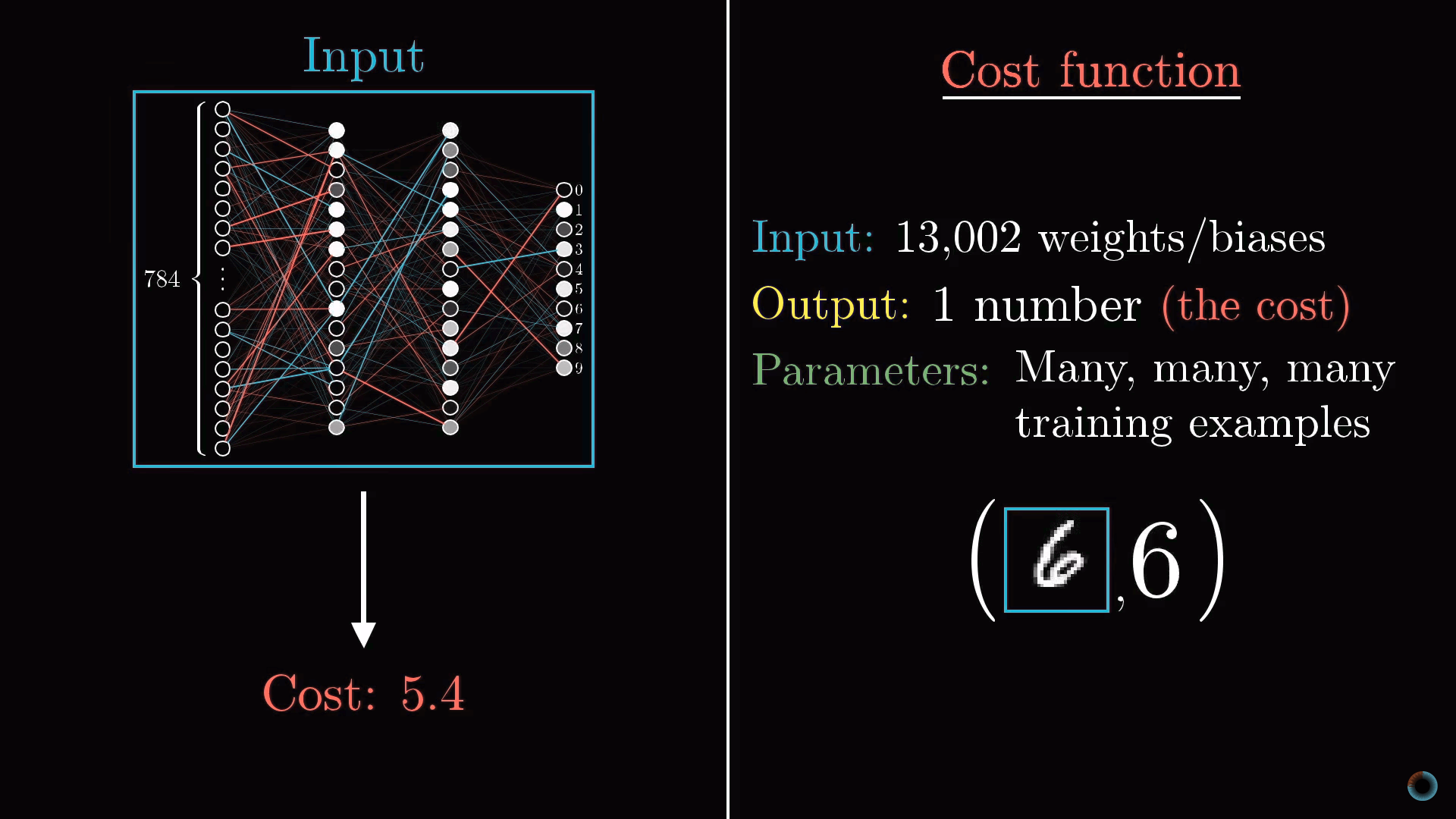
Как изменить все эти веса и сдвиги, чтобы нейросеть обучалась?
Градиентный спуск
Для начала вместо того, чтобы представлять функцию с 13 тыс. входных значений, начнем с функции одной переменной С(w). Как вы, наверное, помните из курса математического анализа, для того, чтобы найти минимум функции, нужно взять производную.
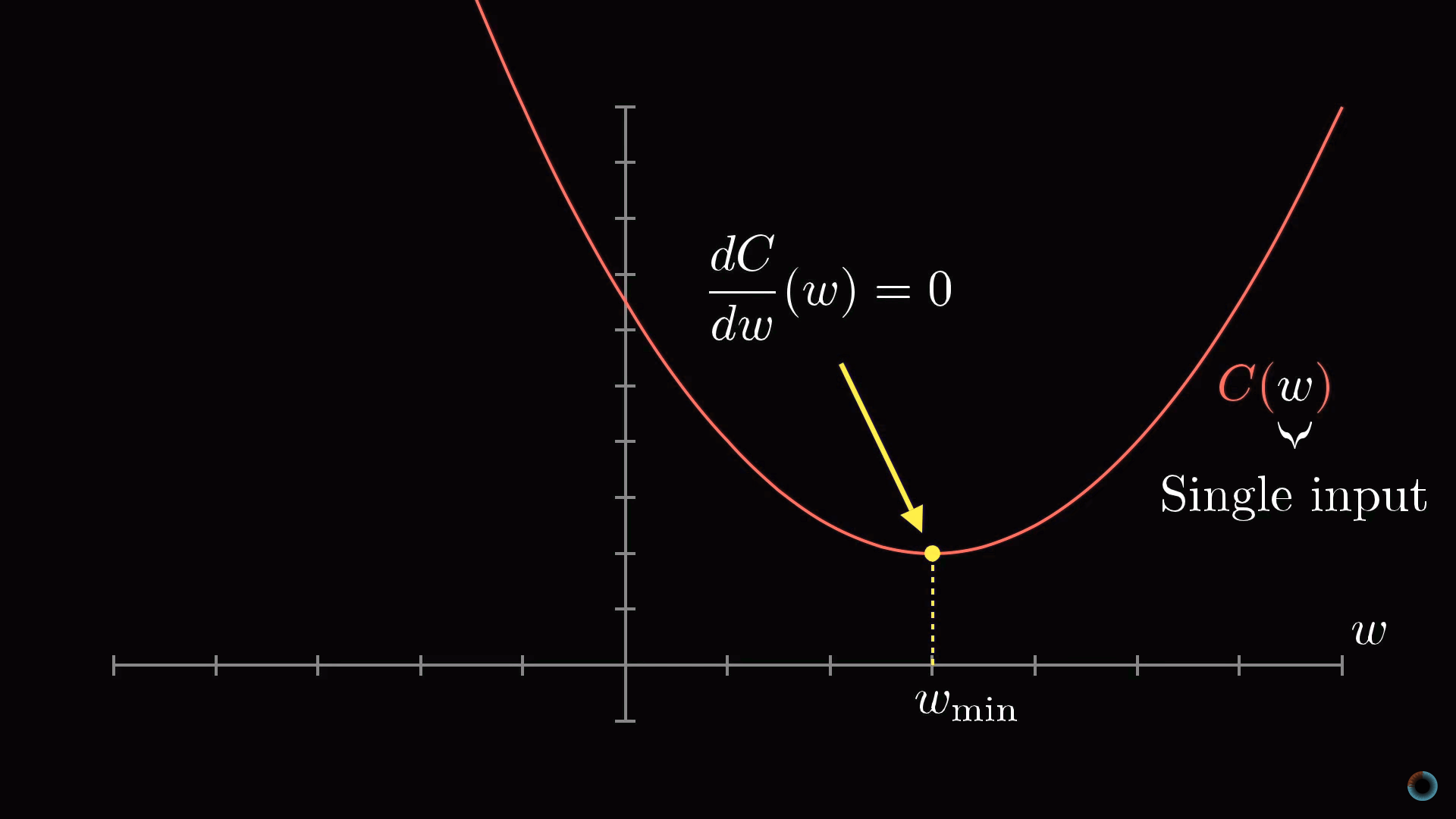
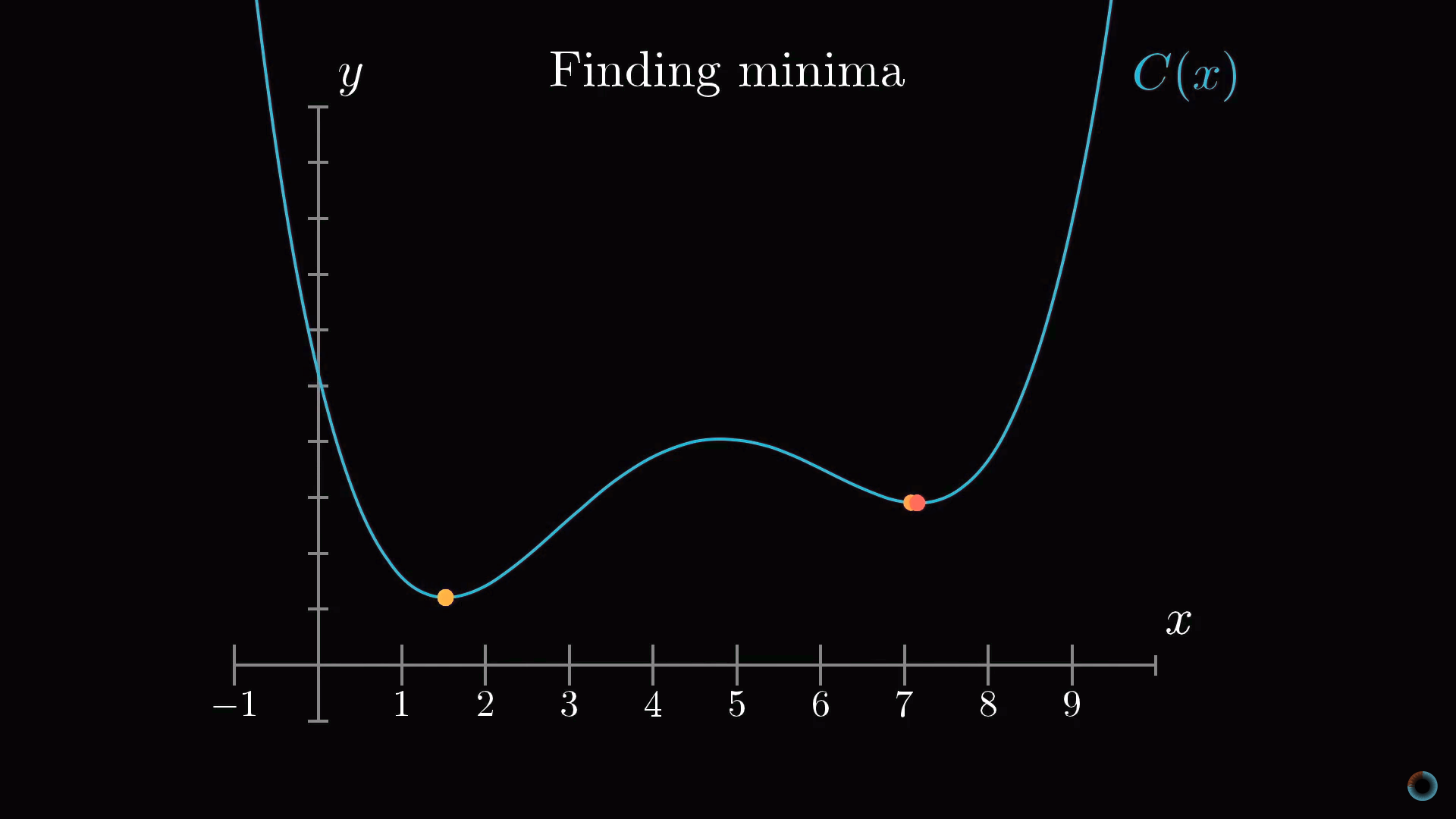
Однако форма функции может быть очень сложной, и одна из гибких стратегий состоит в том, чтобы начать рассмотрение с какой-то произвольной точки и сделать шаг в направлении уменьшения значения функции. Повторяя эту процедуру в каждой следующей точке, можно постепенно прийти к локальному минимуму функции, как это делает скатывающийся с холма мяч.
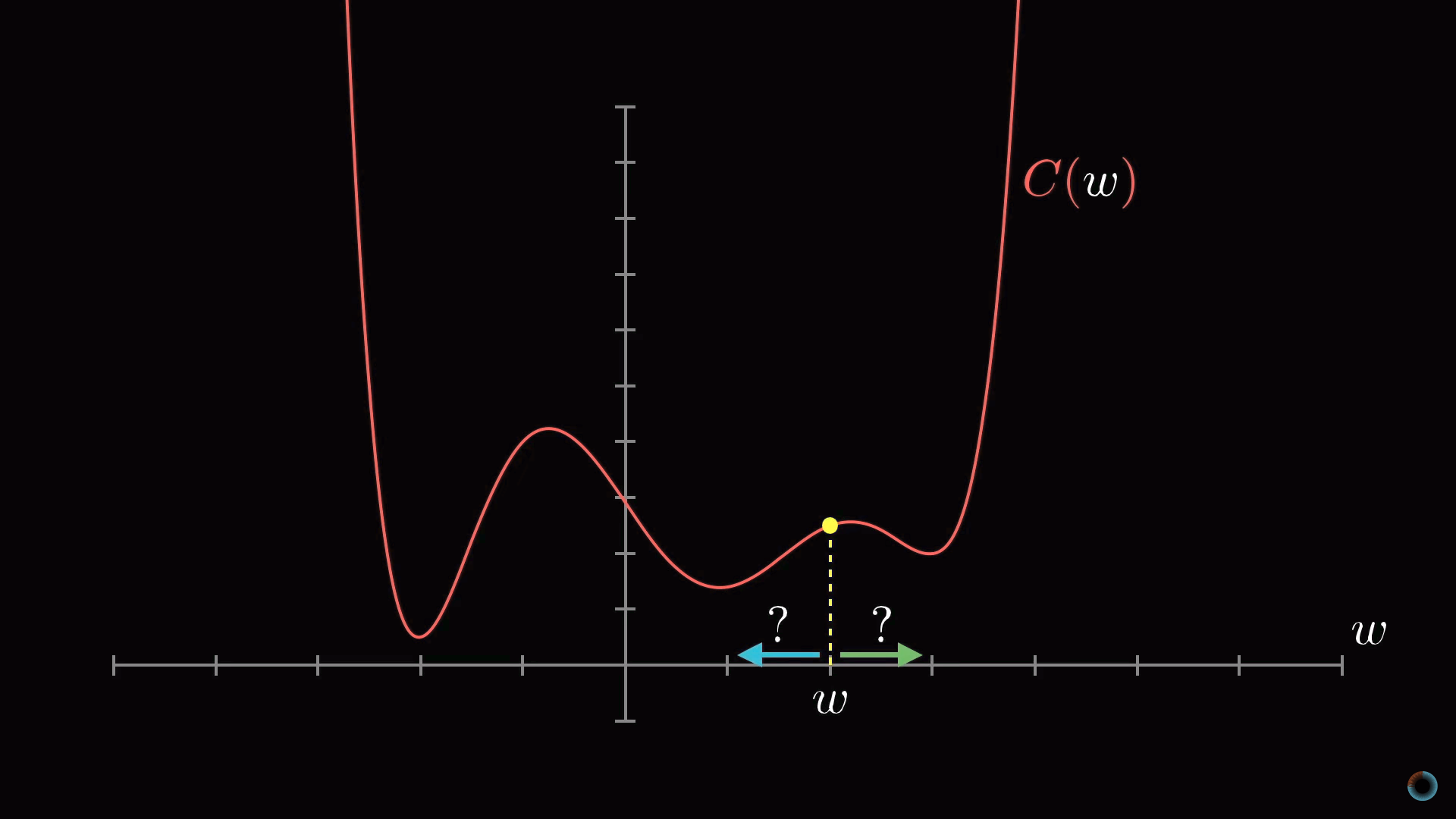
Как на приведенном рисунке показано, что у функции может быть множество локальных минимумов, и то, в каком локальном минимуме окажется алгоритм зависит от выбора начальной точки, и нет никакой гарантии, что найденный минимум является минимальным возможным значением функции стоимости. Это нужно держать в уме. Кроме того, чтобы не «проскочить» значение локального минимума, нужно менять величину шага пропорционально наклону функции.
Чуть усложняя эту задачу, вместо функции одной переменной можно представить функцию двух переменных с одним выходным значением. Соответствующая функция для нахождения направления наиболее быстрого спуска представляет собой отрицательный градиент -∇С. Рассчитывается градиент, делается шаг в направлении -∇С, процедура повторяется до тех пор, пока мы не окажемся в минимуме.
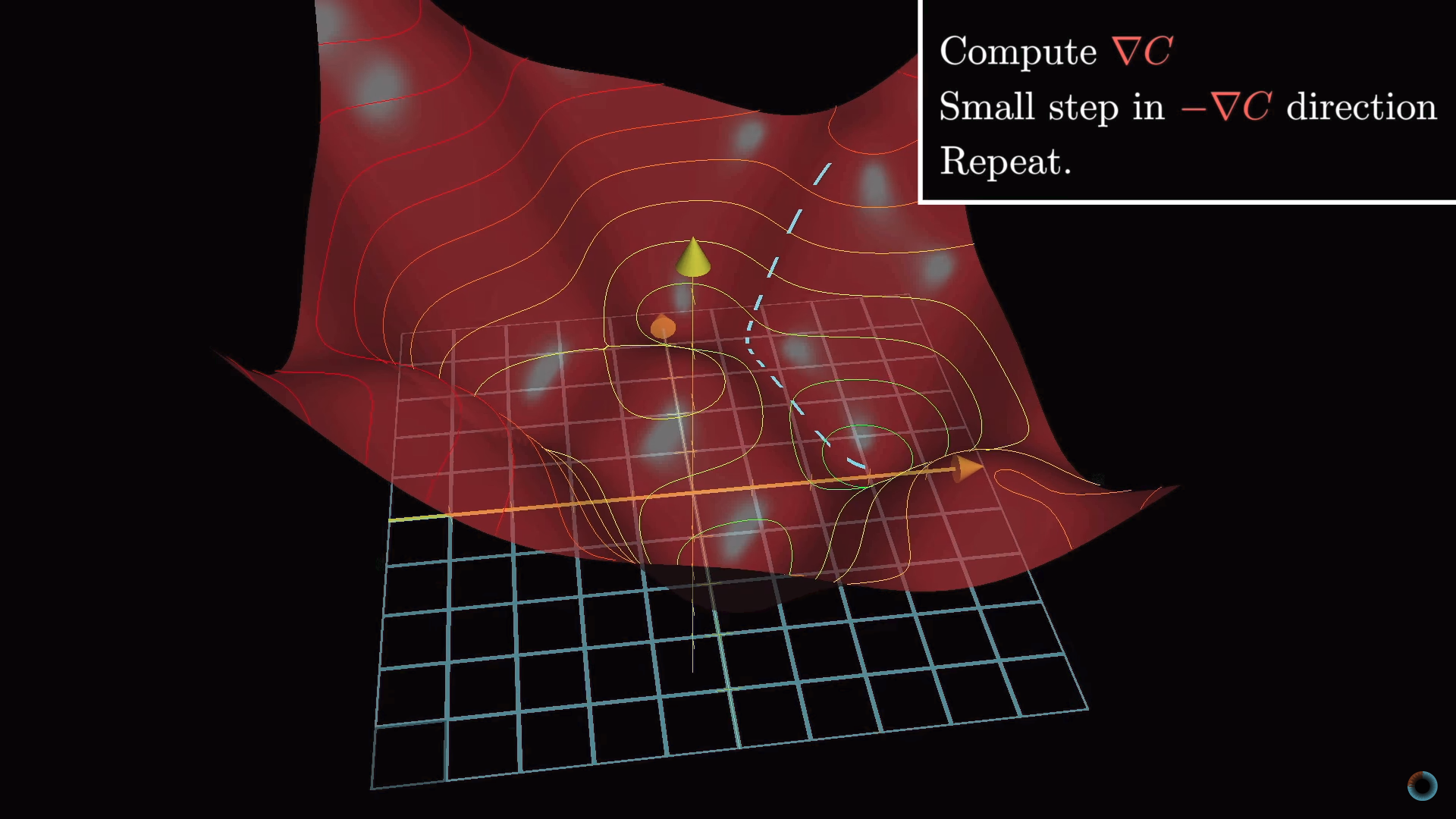
Описанная идея носит название градиентного спуска и может быть применена для нахождения минимума не только функции двух переменных, но и 13 тыс., и любого другого количества переменных. Представьте, что все веса и сдвиги образуют один большой вектор-столбец w. Для этого вектора можно рассчитать такой же вектор градиента функции стоимости и сдвинуться в соответствующем направлении, сложив полученный вектор с вектором w. И так повторять эту процедуру до тех пор, пока функция С(w) не прийдет к минимуму.

Компоненты градиентного спуска
Для нашей нейросети шаги в сторону меньшего значения функции стоимости будут означать все менее случайный характер поведения нейросети в ответ на обучающие данные. Алгоритм для эффективного расчета этого градиента называется метод обратного распространения ошибки и будет подробно рассмотрен в следующем разделе.
Для градиентного спуска важно, чтобы выходные значения функции стоимости изменялись плавным образом. Именно поэтому значения активации имеют не просто бинарные значения 0 и 1, а представляют действительные числа и находятся в интервале между этими значениями.
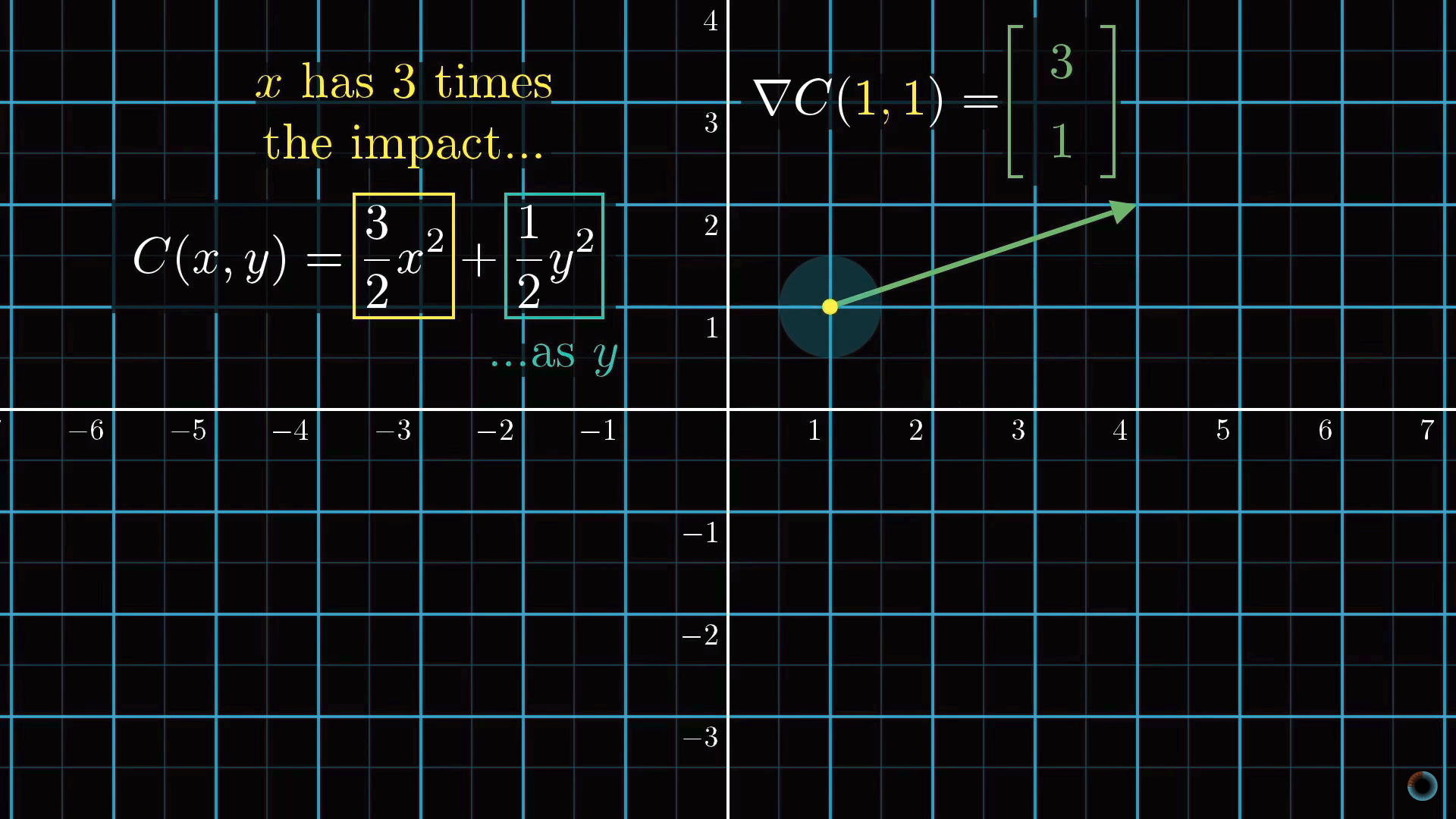
Каждый компонент градиента сообщает нам две вещи. Знак компонента указывает на направление изменения, а абсолютная величина – на влияние этого компонента на конечный результат: одни веса вносят больший вклад в функцию стоимости, чем другие.
Проверка предположения о назначении скрытых слоев
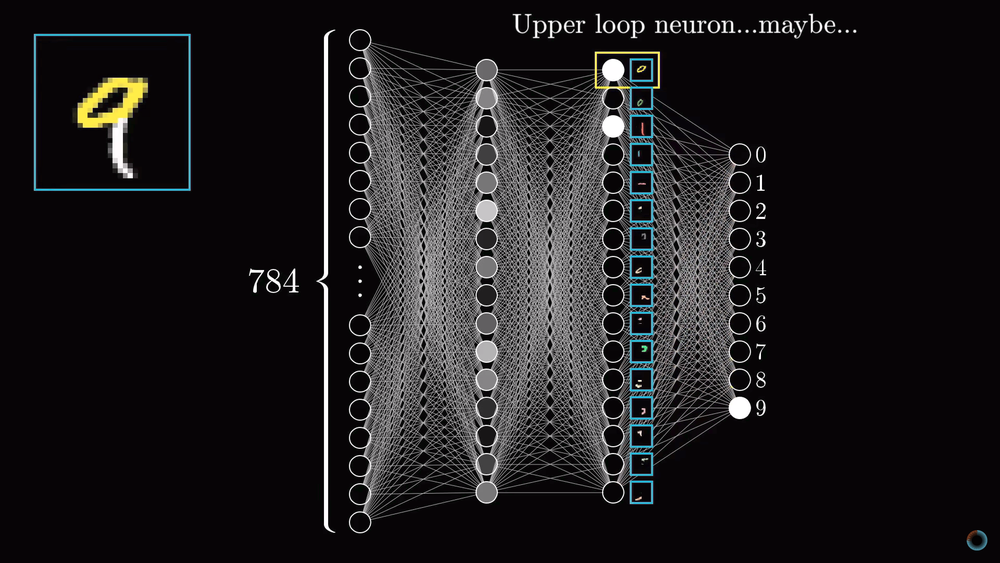
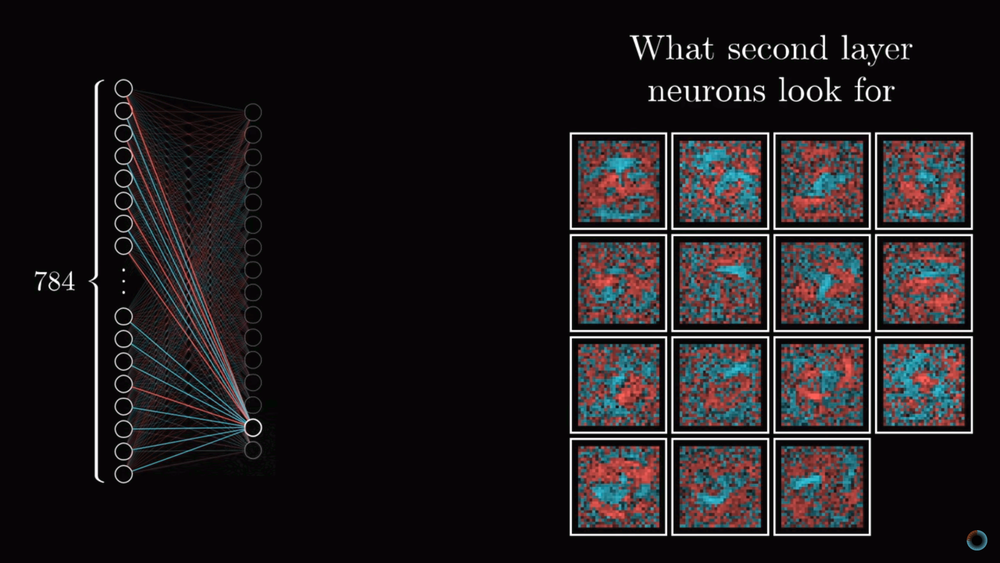
Обсудим вопрос того, насколько соответствуют слои нейросети нашим ожиданиям из первого урока. Если визуализировать веса нейронов первого скрытого слоя обученной нейросети, мы не увидим ожидавшихся фигур, которые бы соответствовали малым составляющим элементам цифр. Мы увидим гораздо менее ясные паттерны, соответствующие тому как нейронная сеть минимизировала функцию стоимости.
С другой стороны возникает вопрос, что ожидать, если передать нейронной сети изображение белого шума? Можно было бы предположить, что нейронная сеть не должна выдать никакого определенного числа и нейроны выходного слоя не должны активироваться или, если и активироваться, то равномерным образом. Вместо этого нейронная сеть в ответ на случайное изображение выдаст вполне определенное число.
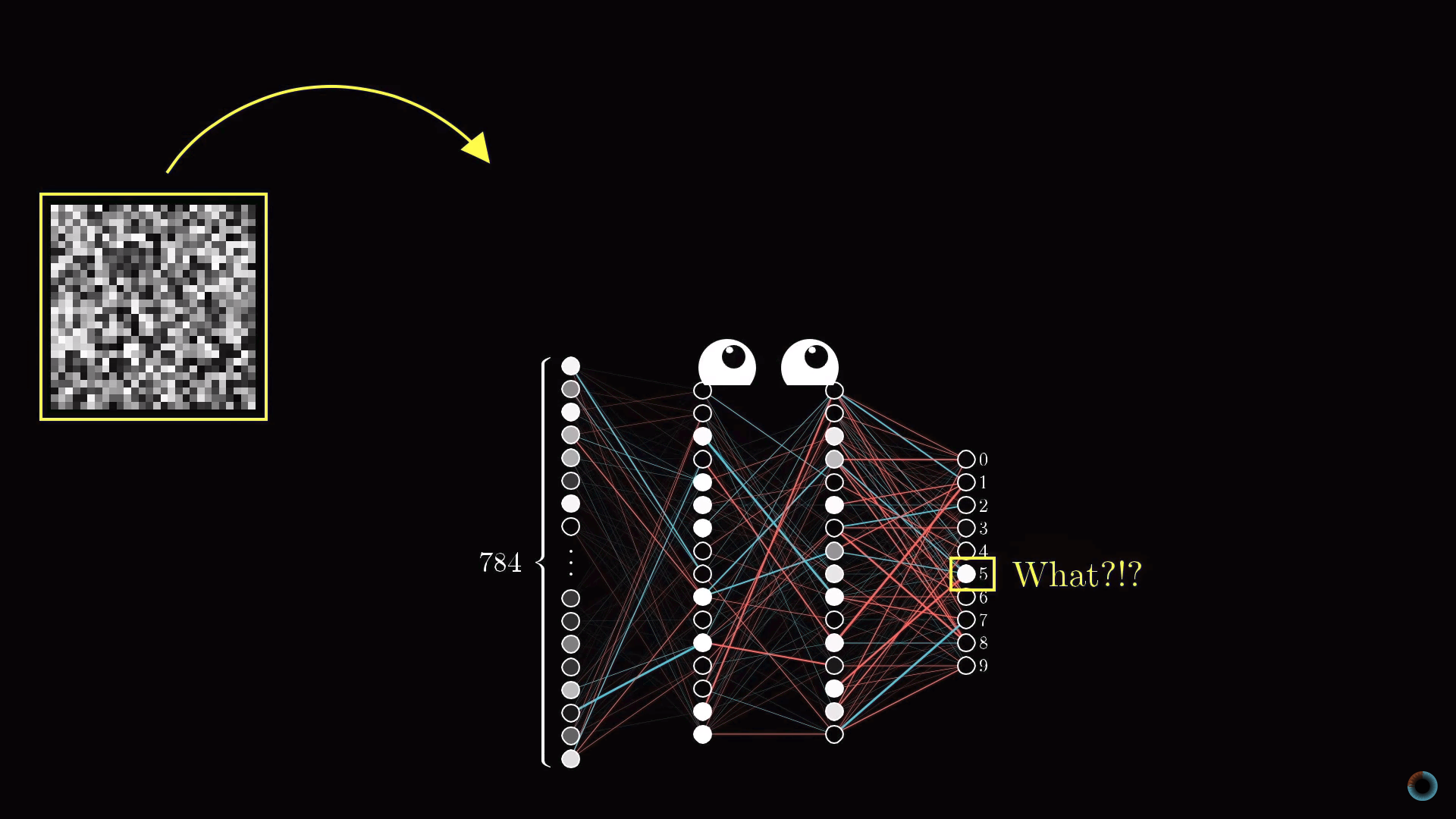
Хотя нейросеть выполняет операции распознавания цифр, она не имеет никаких представлений о том, как они пишутся. На самом деле такие нейросети это довольно старая технология, разработанная в 80-е-90-е годы. Однако понять работу такого типа нейросети очень полезно, прежде чем разбираться в современных вариантах, способных решать различные интересные проблемы. Но, чем больше вы копаетесь в том, что делают скрытые слои нейросети, тем менее интеллектуальной кажется нейросеть.
Обучение на структурированных и случайных данных
Рассмотрим пример современной нейросети для распознавания различных объектов реального мира.

Что произойдет, если перемешать базу данных таким образом, чтобы имена объектов и изображения перестали соответствовать друг другу? Очевидно, что так как данные размечены случайным образом, точность распознавания на тестовой выборке будет никудышной. Однако при этом на обучающей выборке вы будете получать точность распознавания на том же уровне, как если бы данные были размечены верным образом.
Миллионы весов этой конкретной современной нейросети будут настроены таким образом, чтобы в точности определять соответствие данных и их маркеров. Соответствует ли при этом минимизация функции стоимости каким-то паттернам изображений и отличается ли обучение на случайно размеченных данных от обучения на неверно размеченных данных?
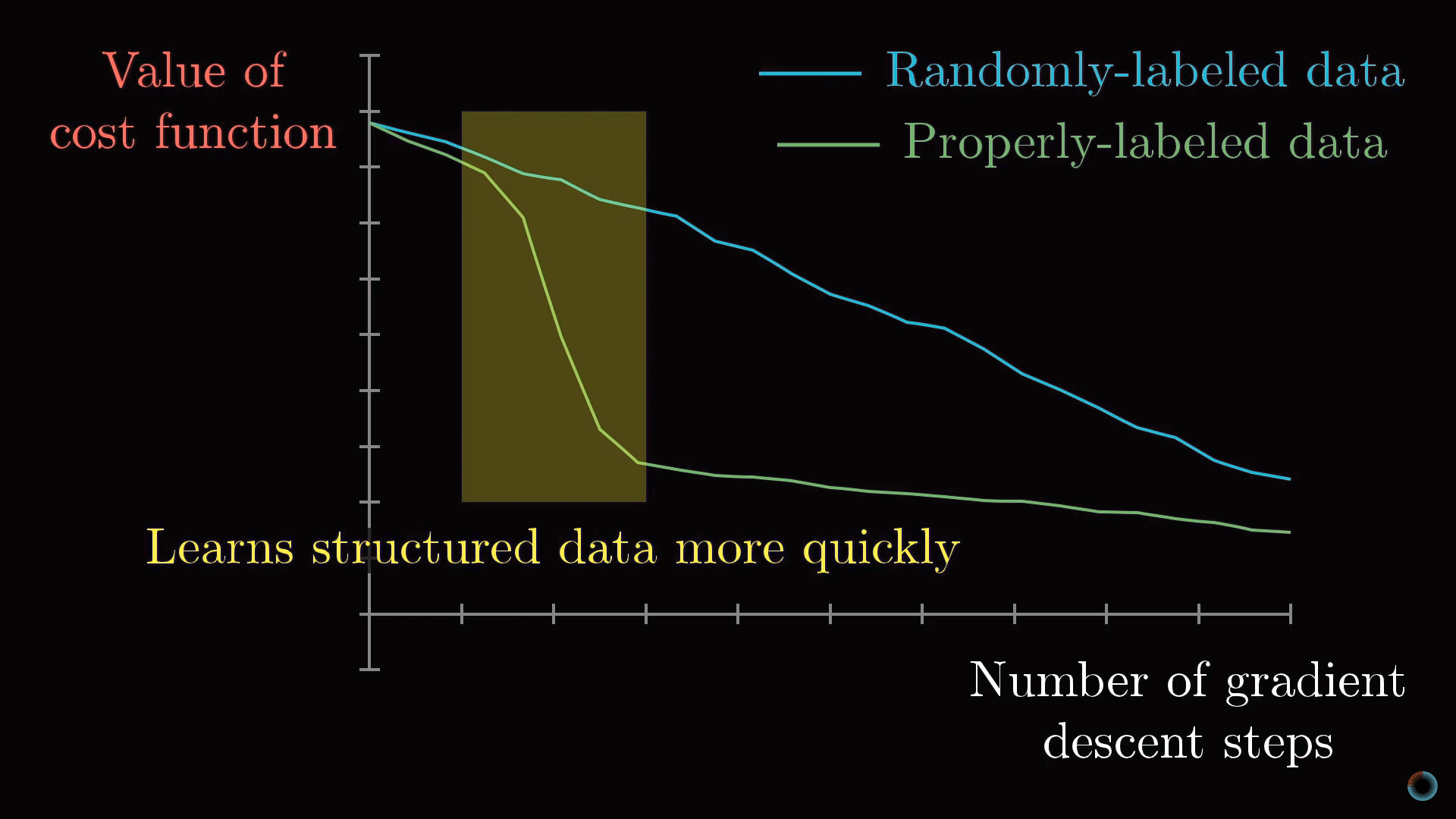
Если вы обучаете нейросеть процессу распознавания на случайным образом размеченных данных, то обучение происходит очень медленно, кривая стоимости от количества проделанных шагов ведет себя практически линейно. Если же обучение происходит на структурированных данных, значение функции стоимости снижается за гораздо меньшее количество итераций.
3. Метод обратного распространения ошибки
Обратное распространение это ключевой алгоритм обучения нейронной сети. Обсудим вначале в общих чертах, в чем заключается метод.
Управление активацией нейрона
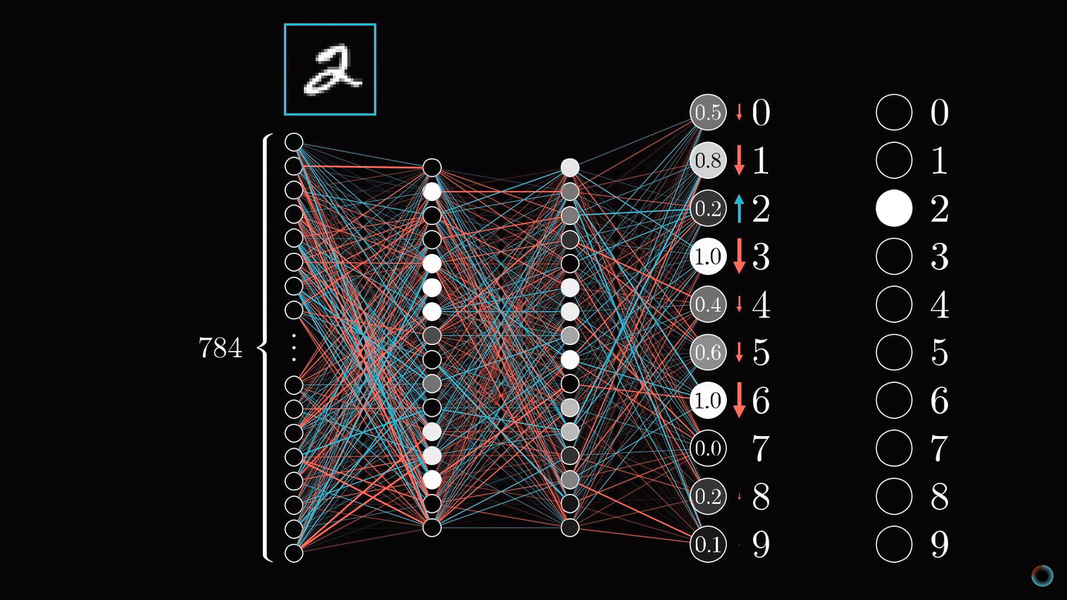
Каждый шаг алгоритма использует в теории все примеры обучающей выборки. Пусть у нас есть изображение двойки и мы в самом начале обучения: веса и сдвиги настроены случайно, и изображению соответствует некоторая случайная картина активаций выходного слоя.
Мы не можем напрямую изменить активации конечного слоя, но мы можем повлиять на веса и сдвиги, чтобы изменить картину активаций выходного слоя: уменьшить значения активаций всех нейронов, кроме соответствующего 2, и увеличить значение активации необходимого нейрона. При этом увеличение и уменьшение требуется тем сильнее, чем дальше текущее значение отстоит от желаемого.
Варианты настройки нейросети
Сфокусируемся на одном нейроне, соответствующем активации нейрона двойки на выходном слое. Как мы помним, его значение является взвешенной суммой активаций нейронов предыдущего слоя плюс сдвиг, обернутые в масштабирующую функцию (сигмоиду или ReLU).
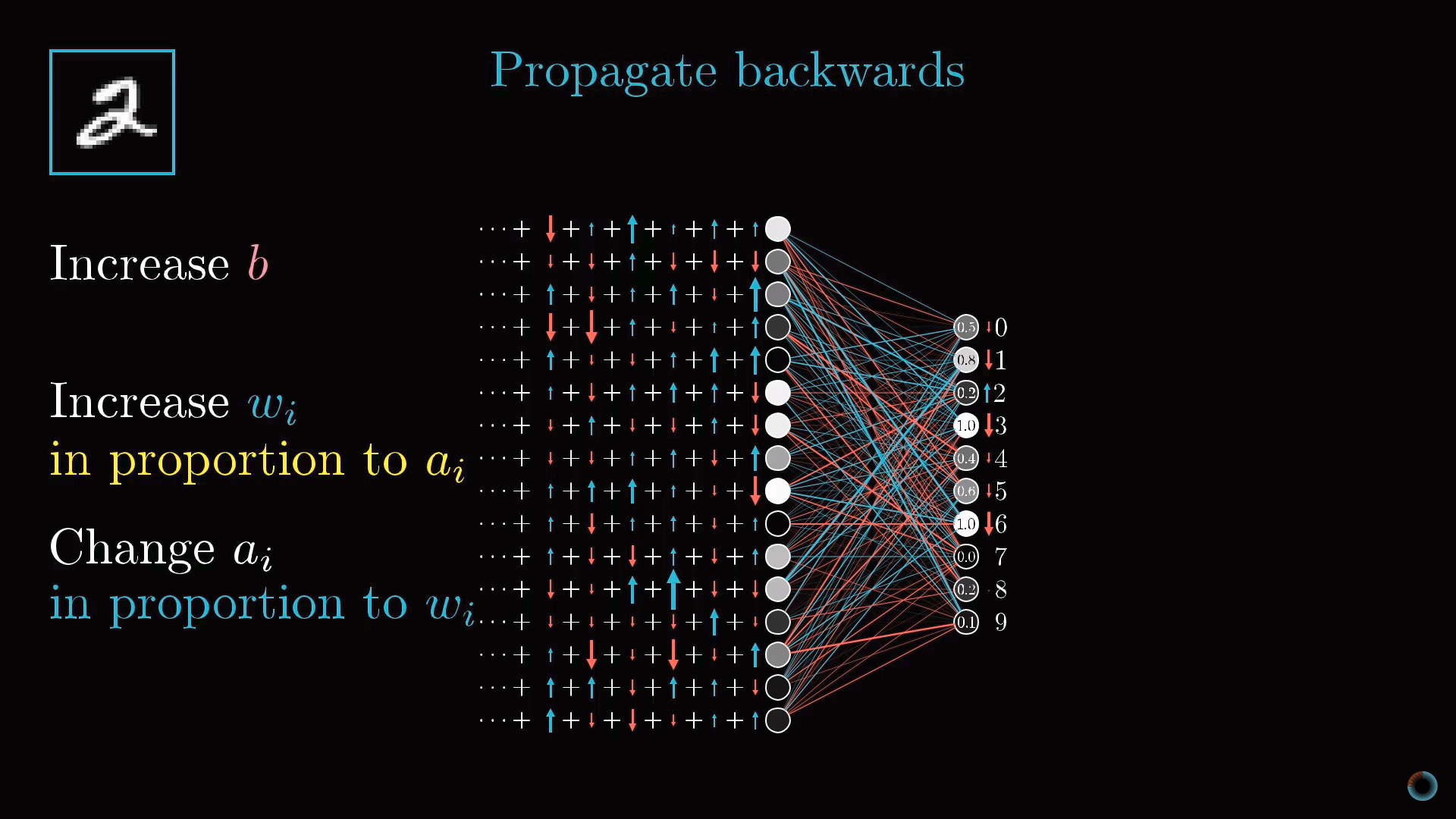
Таким образом, чтобы повысить значение этой активации, мы можем:
- Увеличить сдвиг b.
- Увеличить веса wi.
- Поменять активации предыдущего слоя ai.
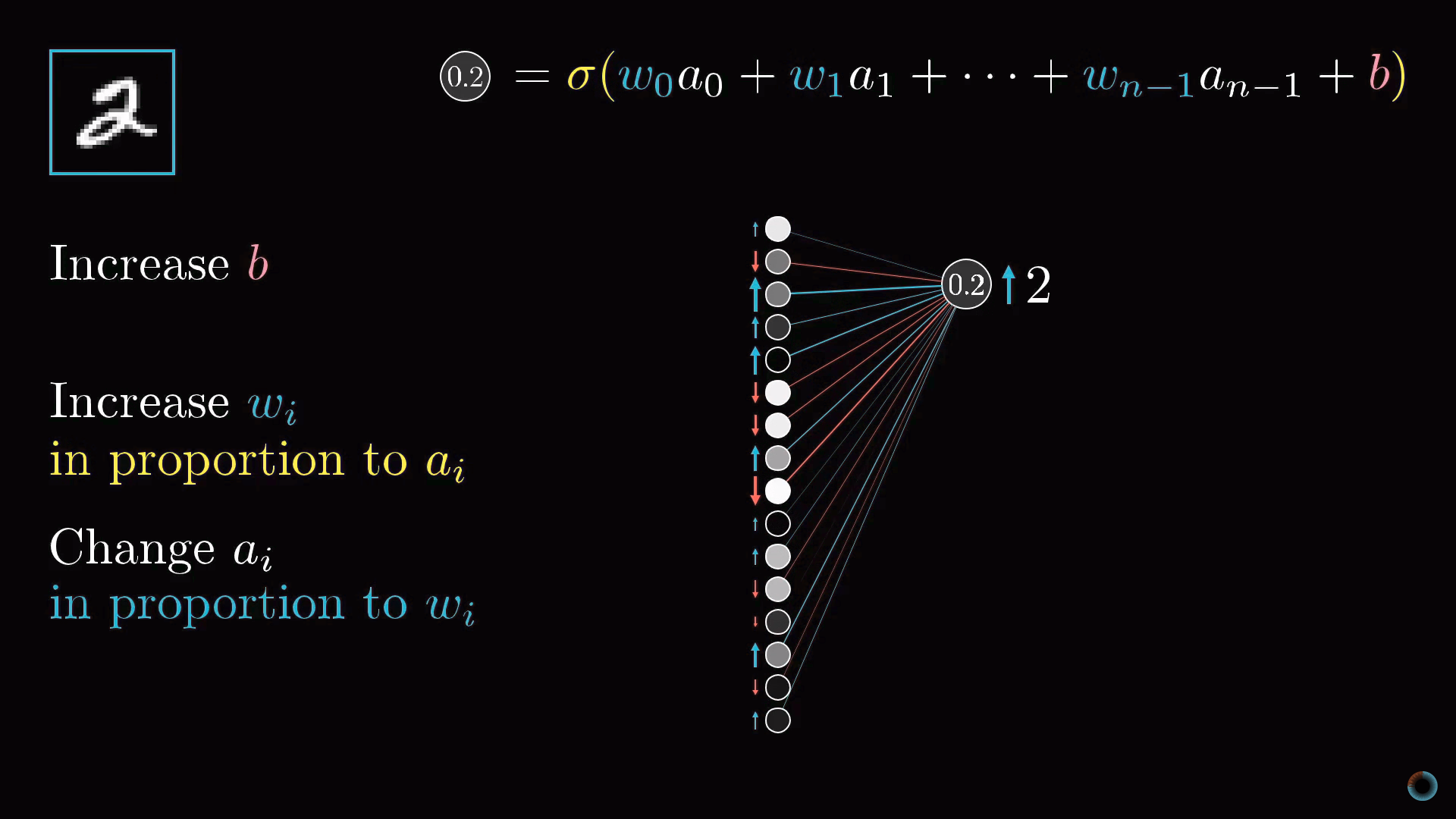
Из формулы взвешенной суммы можно заметить, что наибольший вклад в активацию нейрона оказывают веса, соответствующие связям с наиболее активированными нейронами. Стратегия, близкая к биологическим нейросетям заключается в том, чтобы увеличивать веса wi пропорционально величине активаций ai соответствующих нейронов предыдущего слоя. Получается, что наиболее активированные нейроны соединяются с тем нейроном, который мы только хотим активировать наиболее "прочными" связями.
Другой близкий подход заключается в изменении активаций нейронов предыдущего слоя ai пропорционально весам wi . Мы не можем изменять активации нейронов, но можем менять соответствующие веса и сдвиги и таким образом влиять на активацию нейронов.
Обратное распространение
Предпоследний слой нейронов можно рассматривать аналогично выходному слою. Вы собираете информацию о том, как должны были бы измениться активации нейронов этого слоя, чтобы изменились активации выходного слоя.
Важно понимать, что все эти действия происходят не только с нейроном, соответствующим двойке, но и со всеми нейронами выходного слоя, так как каждый нейрон текущего слоя связан со всеми нейронами предыдущего.
Просуммировав все эти необходимые изменения для предпоследнего слоя, вы понимаете, как должен измениться второй с конца слой. Далее рекурсивно вы повторяете тот же процесс для определения свойств весов и сдвигов всех слоев.
Классический градиентный спуск
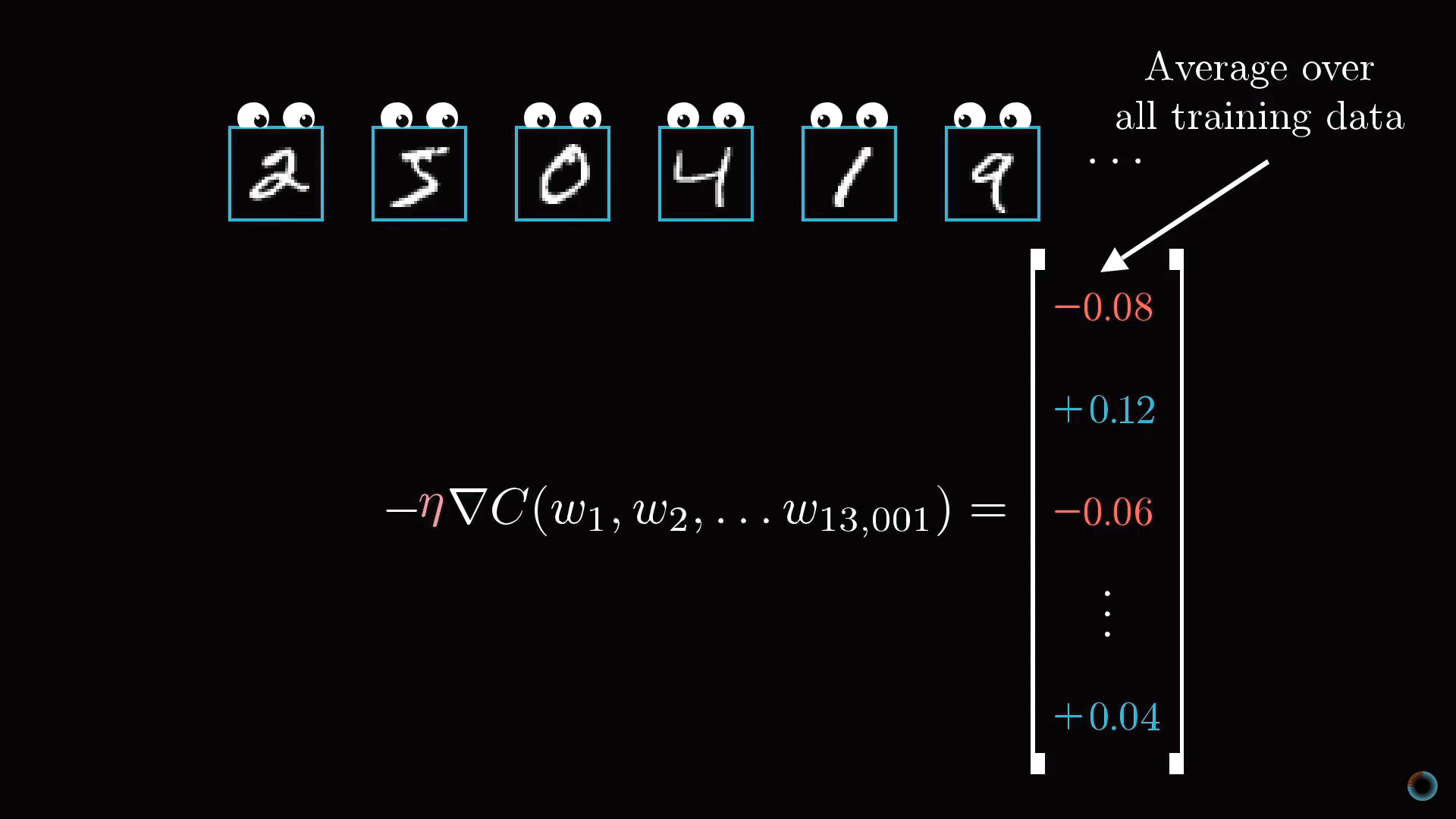
В результате вся операция на одном изображении приводит к нахождению необходимых изменений 13 тыс. весов и сдвигов. Повторяя операцию на всех примерах обучающей выборки, вы получаете значения изменений для каждого примера, которые далее вы можете усреднить для каждого параметра в отдельности.
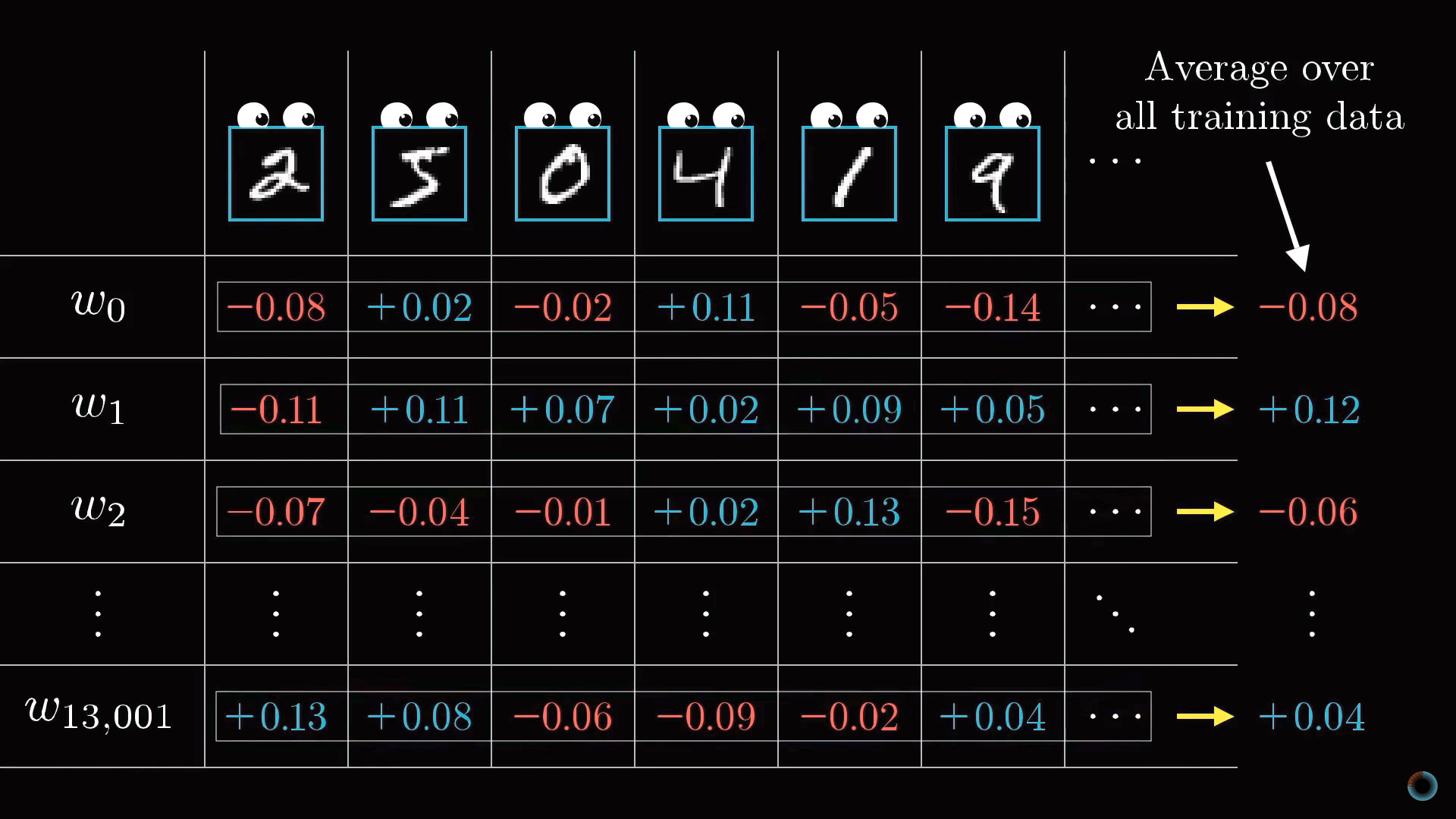
Результат этого усреднения представляет вектор столбец отрицательного градиента функции стоимости.
Стохастический градиентный спуск
Рассмотрение всей совокупности обучающей выборки для расчета единичного шага замедляет процесс градиентного спуска. Поэтому обычно делается следующее.
Случайным образом данные обучающей выборки перемешиваются и разделяются на подгруппы, например, по 100 размеченных изображений. Далее алгоритм рассчитывает шаг градиентного спуска для одной подгруппы.

Это не в точности настоящий градиент для функции стоимости, который требует всех данных обучающей выборки, но, так как данные выбраны случайным образом, они дают хорошую аппроксимацию, и, что важно, позволяют существенно повысить скорость вычислений.
Если построить кривую обучения такого модернизированного градиентного спуска, она будет похожа не на равномерный целенаправленный спуск с холма, а на петляющую траекторию пьяного, но делающего более быстрые шаги и приходящего также к минимуму функции.
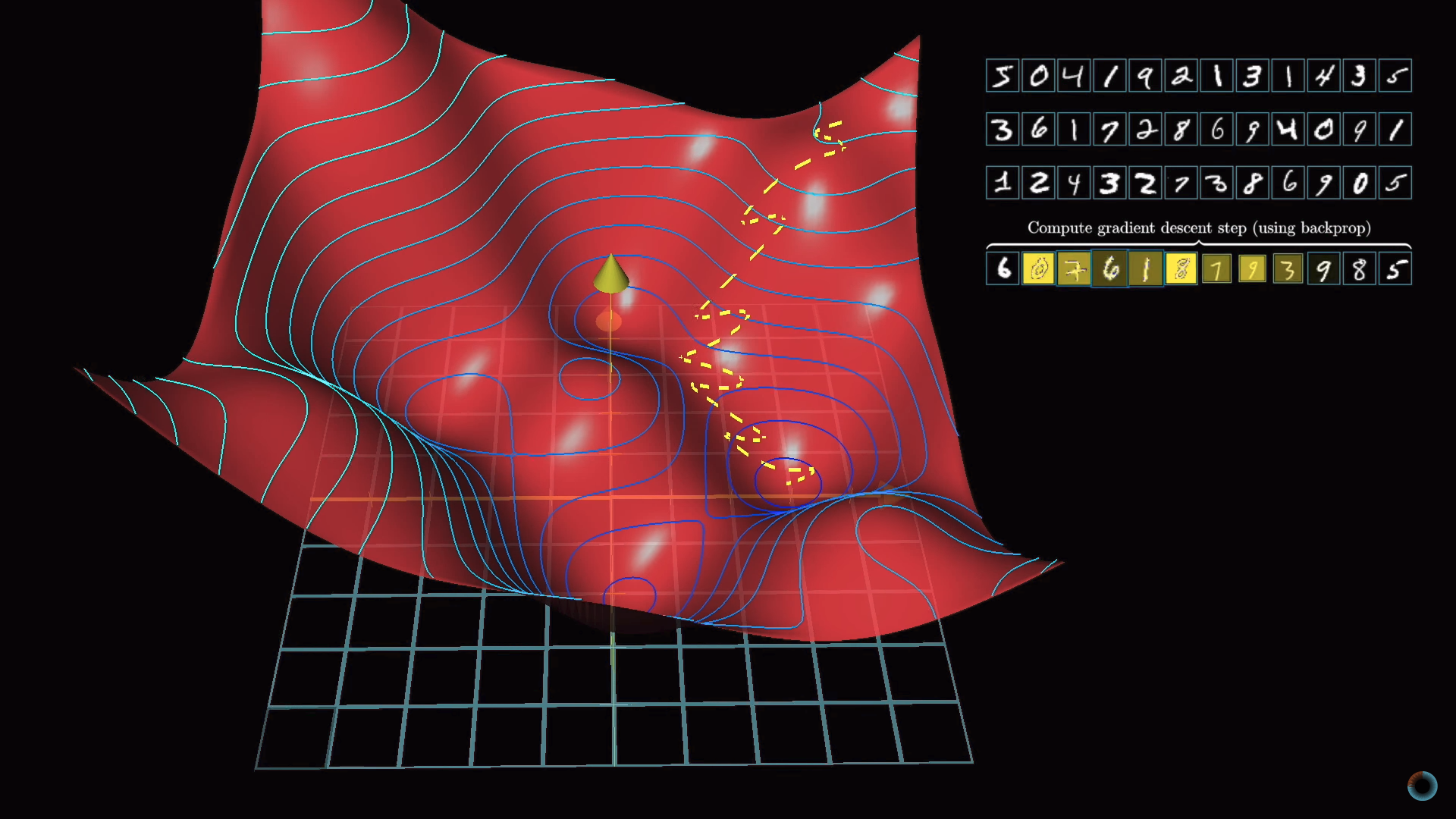
Такой подход называется стохастическим градиентным спуском.
Дополнение. Математическая составляющая обратного распространения
Разберемся теперь немного более формально в математической подоплеке алгоритма обратного распространения.
Примитивная модель нейронной сети
Начнем рассмотрение с предельно простой нейросети, состоящей из четырех слоев, где в каждом слое всего по одному нейрону. Соответственно у сети есть три веса и три сдвига. Рассмотрим, насколько функция чувствительна к этим переменным.
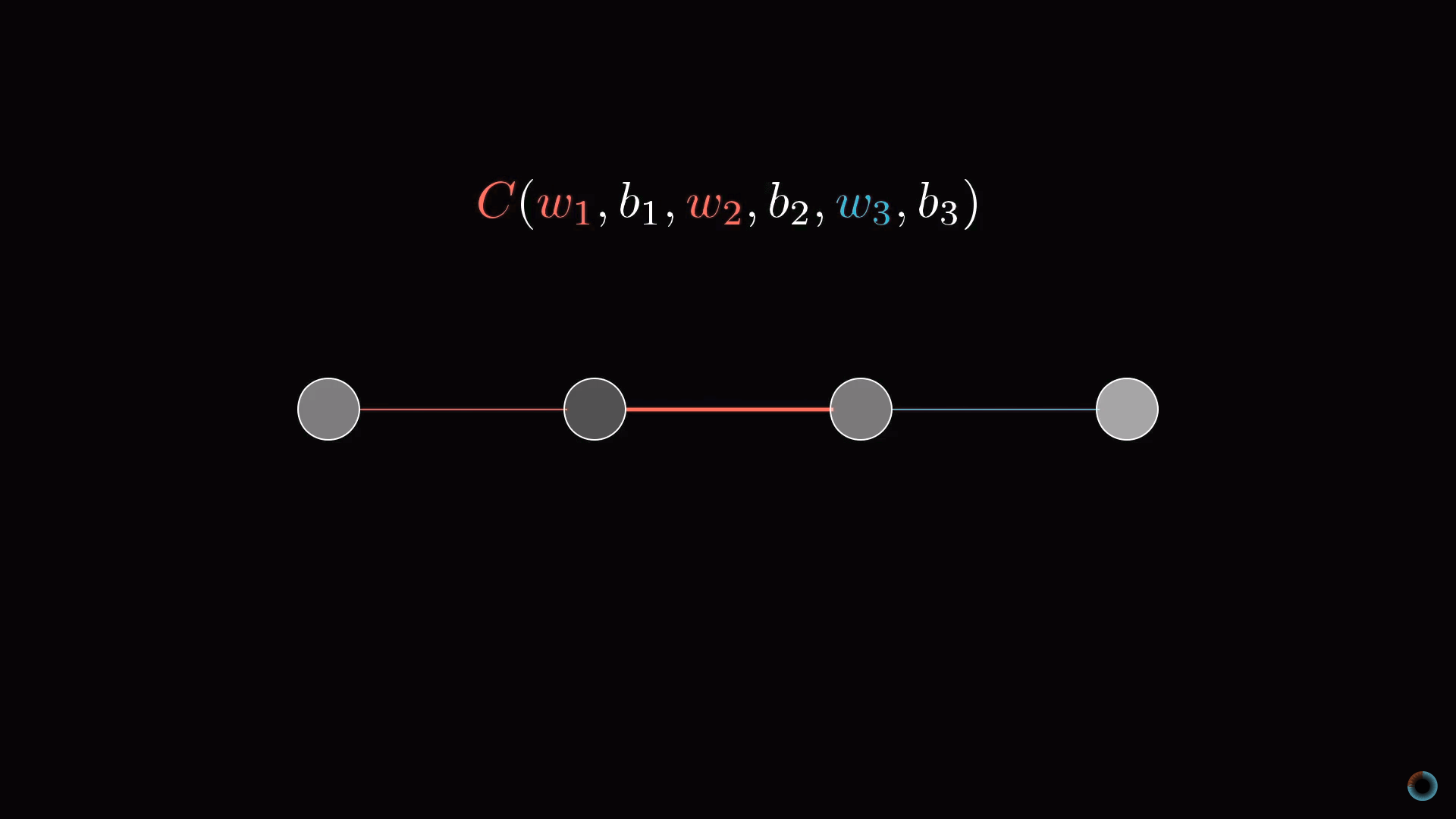
Начнем со связи между двумя последними нейронами. Обозначим последний слой L, предпоследний L-1, а активации лежащих в них рассматриваемых нейронов a(L), a(L-1).
Функция стоимости
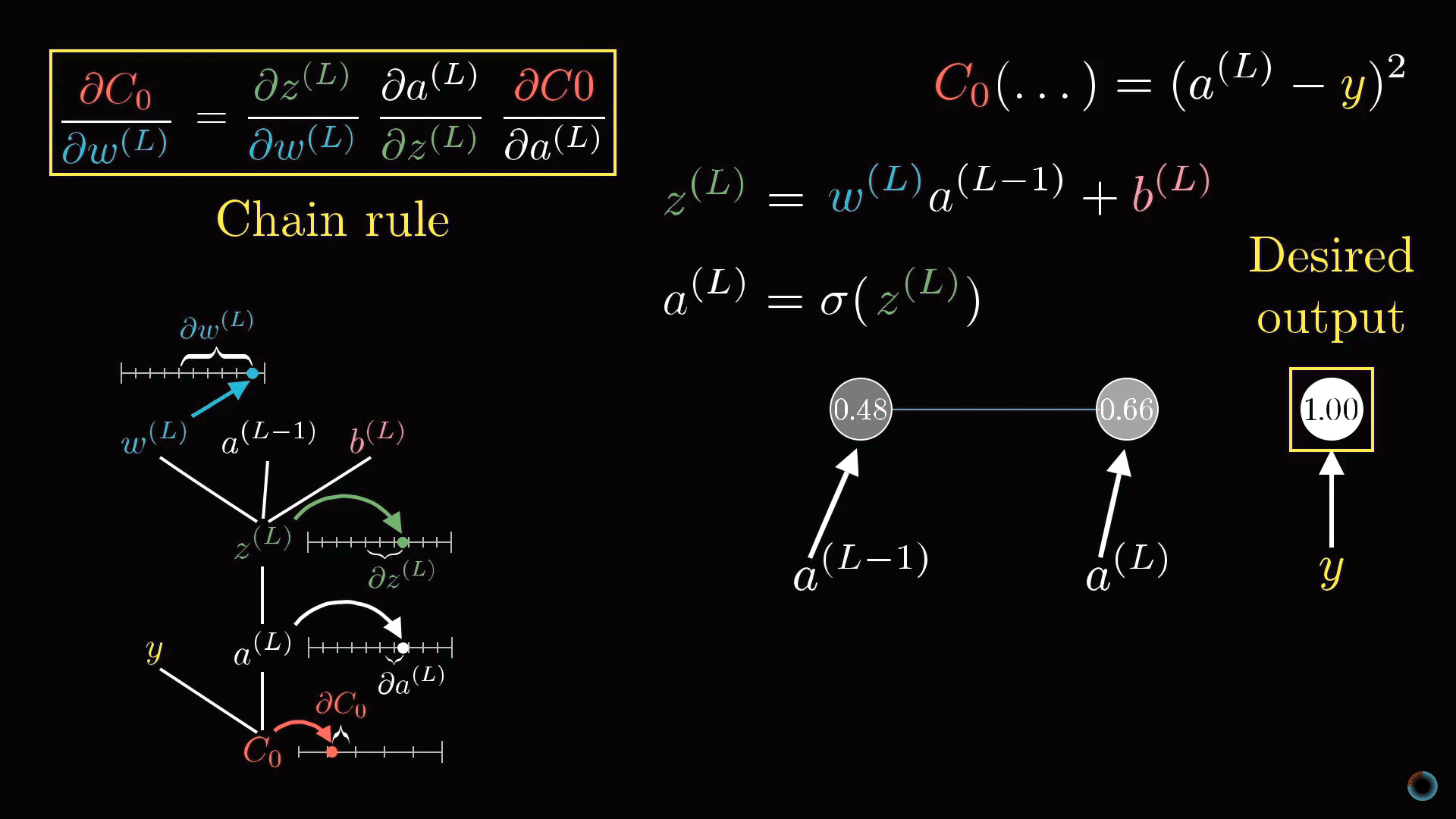
Представим, что желаемое значение активации последнего нейрона, данное обучающим примеров это y, равное, например, 0 или 1. Таким образом, функция стоимости определяется для этого примера как
C0 = (a(L) - y)2.
Напомним, что активация этого последнего нейрона задается взвешенной суммой, а вернее масштабирующей функцией от взвешенной суммы:
a(L) = σ(w(L)a(L-1) + b(L)).
Для краткости взвешенную сумму можно обозначить буквой с соответствующим индексом, например z(L):
a(L) = σ(z(L)).
Рассмотрим как в значении функции стоимости сказываются малые изменения веса w(L). Или математическим языком, какова производная функции стоимости по весу ∂C0/∂w(L)?
Можно видеть, что изменение C0 зависит от изменения a(L), что в свою очередь зависит от изменения z(L), которое и зависит от w(L). Соответственно правилу взятия подобных производных, искомое значение определяется произведением следующих частных производных:
∂C0/∂w(L) = ∂z(L)/∂w(L) • ∂a(L)/∂z(L) • ∂C0/∂a(L).
Определение производных
Рассчитаем соответствующие производные:
∂C0/∂a(L) = 2(a(L) - y)
То есть производная пропорциональна разнице между текущим значением активации и желаемым.
Средняя производная в цепочке является просто производной от масштабирующей функции:
∂a(L)/∂z(L) = σ'(z(L))
И наконец, последний множитель это производная от взвешенной суммы:
∂z(L)/∂w(L) = a(L-1)
Таким образом, соответствующее изменение определяется тем, насколько активирован предыдущий нейрон. Это соотносится с упоминавшейся выше идеей, что между загорающимися вместе нейронами образуется более «прочная» связь.
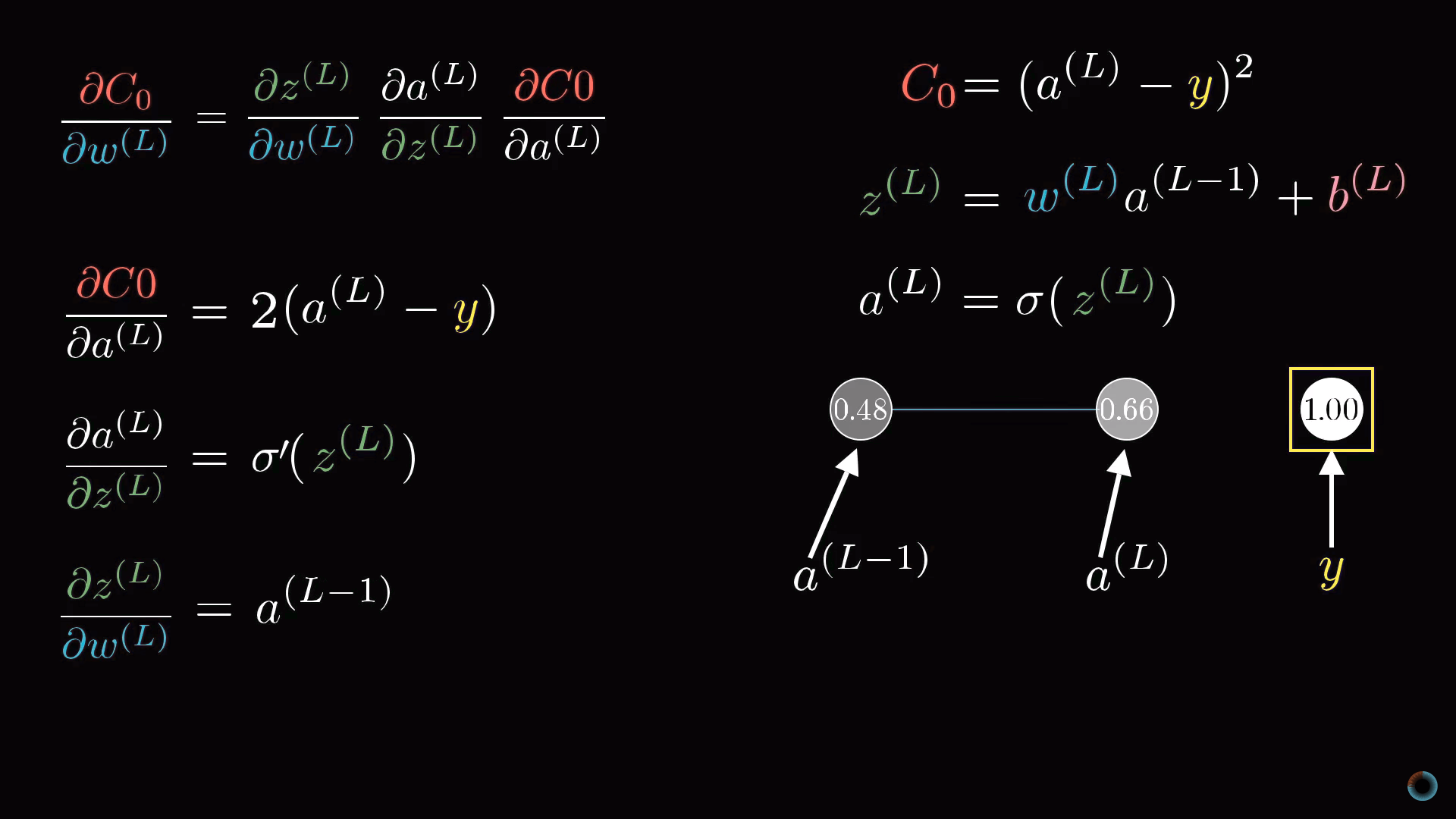
Конечное выражение:
∂C0/∂w(L) = 2(a(L) - y) σ'(z(L)) a(L-1)
Обратное распространение
Напомним, что определенная производная лишь для стоимости отдельного примера обучающей выборки C0. Для функции стоимости С, как мы помним, нужно производить усреднение по всем примерам обучающей выборки:
∂C/∂w(L) = 1/n Σ ∂Ck/∂w(L)
 Полученное усредненное значение для конкретного w(L) является одним из компонентов градиента функции стоимости. Рассмотрение для сдвигов идентично приведенному рассмотрению для весов.
Полученное усредненное значение для конкретного w(L) является одним из компонентов градиента функции стоимости. Рассмотрение для сдвигов идентично приведенному рассмотрению для весов.
Получив соответствующие производные, можно продолжить рассмотрение для предыдущих слоев.
Модель со множеством нейронов в слое
Однако как осуществить переход от слоев, содержащих по одному нейрону к исходно рассматриваемой нейросети. Все будет выглядеть аналогично, просто добавится дополнительный нижней индекс, отражающий номер нейрона внутри слоя, а у весов появятся двойные нижние индексы, например, jk, отражающие связь нейрона j из одного слоя L с другим нейроном k в слое L-1.
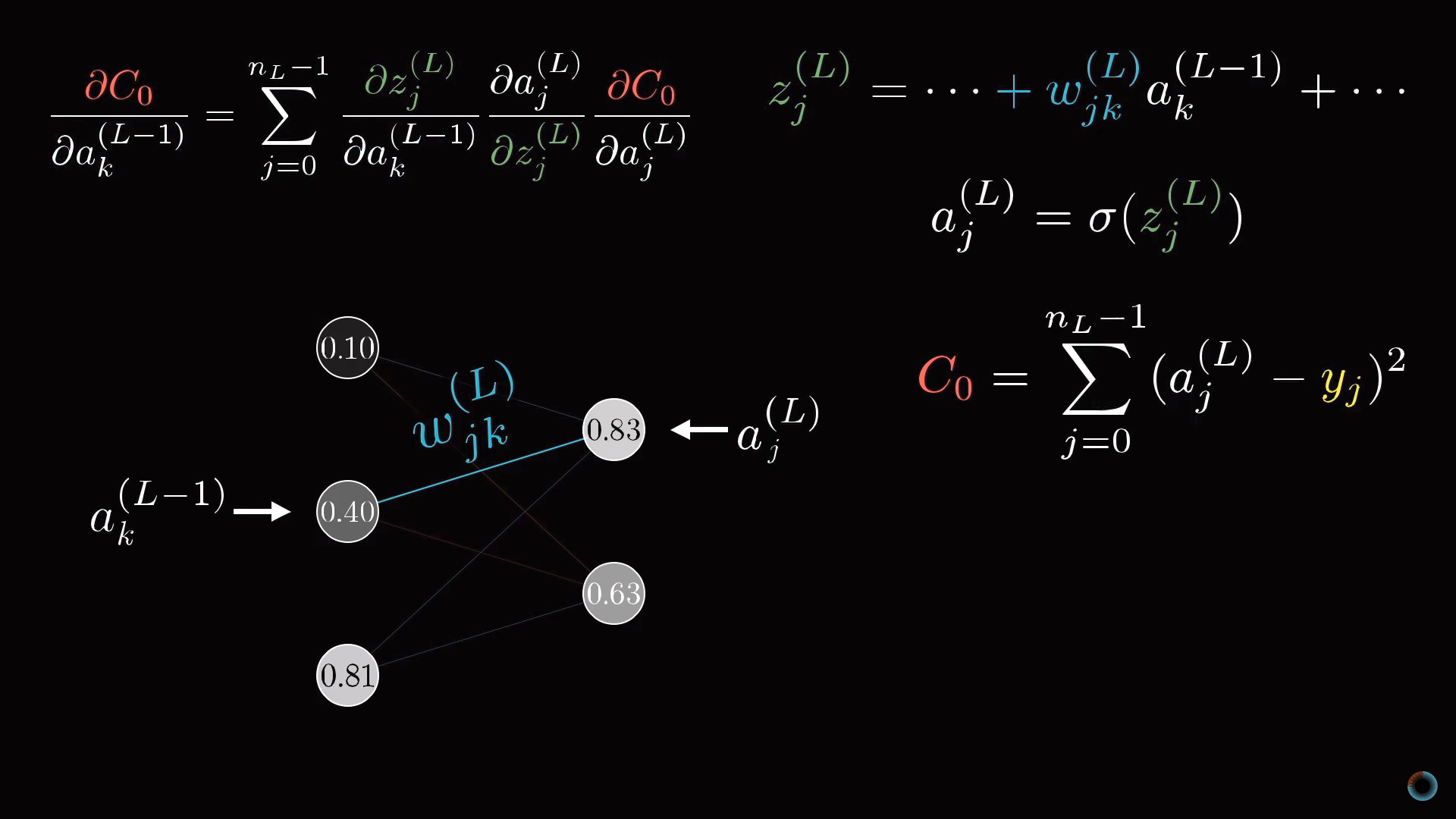
Конечные производные дают необходимые компоненты для определения компонентов градиента ∇C.

Потренироваться в описанной задаче распознавания цифр можно при помощи учебного репозитория на GitHub и упомянутого датасета для распознавания цифр MNIST.
Комментарии