

Что такое NFT и криптопанки?
NFT (Non Fungible Token) – это невзаимозаменяемый, уникальный токен, которым торгуют и обмениваются на блокчейне Ethereum.
Криптопанки (CryptoPunks) – набор из 10 000 уникальных коллекционных персонажей, каждый из которых представляет собой уникальный аватар размером 24x24 пикселя в 8-битном стиле. Доказательство прав собственности хранится на блокчейне Ethereum.
Их создание началось как эксперимент, проведенный разработчиками программного обеспечения Мэттом Холлом и Джоном Аткинсоном в 2017 году. Криптопанки послужили вдохновением для стандарта ERC-721, на котором сегодня основано большинство цифровых произведений искусства и коллекционных предметов.
Это самая первая серия NFT, которая вызвала интерес у публики, и одна из наиболее активно торгуемых и «хайповых» сегодня.
Рыночная капитализация всех 10 000 CryptoPunks на текущий момент оценивается в более чем несколько миллиардов долларов США.
В этом материале мы будем использовать DCGAN (Deep Convolutional Generative Adversarial Network – Глубокая Сверточная Генеративно-Состязательная Сеть) и обучать ее на наборе данных CryptoPunks для того, чтобы попытаться сгенерировать новых «панков» на основе существующих. Вы можете скачать данные для проекта отсюда. Если вы ещё не знакомы с платформой Kaggle и тем, как ей пользоваться, рекомендуем вам ознакомиться со следующим материалом: 📊 Kaggle за 30 минут: практическое руководство для начинающих.
Почему нейросеть с таким сложным названием?
Группа GAN-нейросетей принадлежит к методам обучения без учителя, называемым генеративными моделями. Это тип моделей в машинном обучении, которые используются для более подробного описания явлений в данных, что позволяет обучить нашу модель с лучшим результатом.
Генеративные модели и GAN были одними из самых успешных разработок последних лет в области компьютерного зрения. Их можно использовать для автоматизированного изучения признаков, параметров и многих других составляющих того набора данных, над которым мы хотим провести наше исследование.
Загрузка данных и препроцессинг
Весь код находится в github репозитории. Ниже приведены основные моменты, необходимые для понимания нашей нейросети:
# загрузим данные
base_dir = '/kaggle/input/cryptopunks/'
os.listdir(base_dir)
data_dir = '../input/cryptopunks/txn_history-2021-10-07.jsonl'
image_dir = "../input/cryptopunks/imgs/imgs"
image_root = "../input/cryptopunks/imgs"
df = pd.read_json(base_dir + 'txn_history-2021-10-07.jsonl', lines=True)
Посмотрим на первые 100 изображений, перед этим определив количество строк и столбцов:

Очистим наш датасет и оставим те столбцы, которые нам действительно нужны.
df = df[["txn_type", "date", "eth", "punk_id", "type", "accessories"]]
Здесь:
eth – цена в криптовалюте Ethereum.
punk_id – id криптопанка.
type – его вид (пришелец, зомби, мужчина/женщина).
accessories – особенности изображения.
Сравним цену NFT-токенов исходя из их типа («Пришелец», «Зомби» и.т.д.):
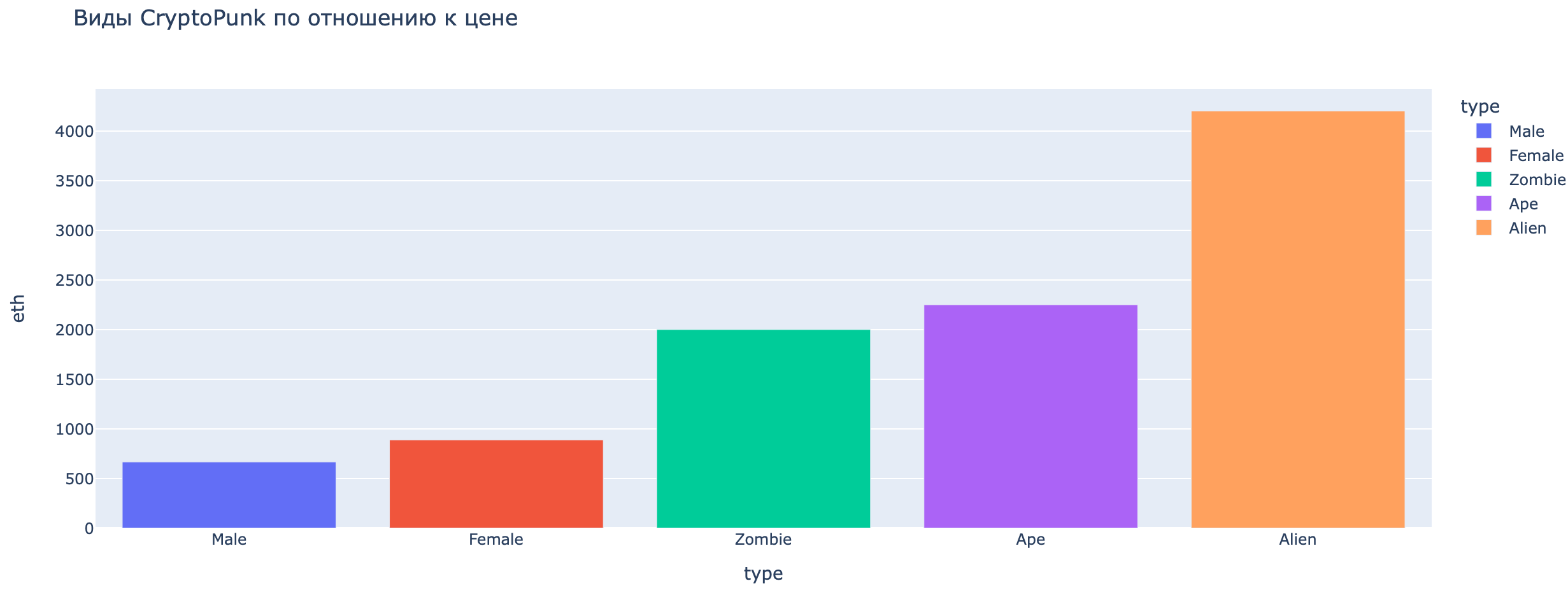
Как мы видим, наибольшую цену имеют «панки» категории Alien.
Для того чтобы наша GAN-нейросеть работала корректно, необходимо чтобы наш код имел следующую структуру:
- Функция для отображения картинок и загрузки данных
- Генератор
- Дискриминатор
- Параметры модели и функция потерь
- Код для старта тренировки и генерации изображений
Функции
def tensor_imshow() – функция для отображения изображений. Сюда мы прописываем общую переменную для картинок и их размерность.
def get_dataloader() – функция для загрузки данных, куда мы прописываем трансформер (созданный для изменения картинок в подходящий формат), переменную самого датасета и его загрузчика.
Структура генератора
Класс генератора создает фейковые данные с помощью обратной связи от дискриминатора (о нём ниже). Таким образом, он обучает дискриминатор обнаружению настоящих данных. Это необходимо для более точной работы модели и является неотъемлемой частью GAN. Обучение генератора требует более тесной интеграции между генератором и дискриминатором, чем обучение самого дискриминатора.
class Generator(nn.Module):
def __init__() – функция инициализации размерности класса Генератор
def make_gen_block() – «начинка» генератора, которая преобразует случайный input в экземпляр данных
return nn.Sequential(*layers) – возвращаем слои нейросети
Структура дискриминатора
Дискриминатор в GAN-нейросети является простым классификатором. Его цель – отличить реальные данные от тех данных, которые созданы генератором. Он может использовать любую архитектуру, если она соответствует типу данных, которые классифицирует дискриминатор.
class Discriminator(nn.Module):
def __init__() – функция инициализации размерности класса Генератор
def make_disc_block() – «начинка» генератора
return nn.Sequential(*layers) – возвращаем слои нейросети
Дискриминатор классифицирует наши входные данные и определяет их категорию. То есть, дискриминационный класс сопоставляет образы с категорией. Его основная задача – исключительно осуществление данной корреляции.
Параметры для модели
В первую очередь нам необходимо инициализировать размерность. По мнению Ian Goodfellow, который является одним из отцов-основателей современного Deep Learning, оптимальное значение для коэффициентов mean=0, stdev=0.2.
def weights_init_normal(m):
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
torch.nn.init.normal_(m.weights, 0.0, 0.02)
if isinstance(m, nn.BatchNorm2d):
torch.nn.init.normal_(m.weights, 0.0, 0.02)
torch.nn.init.constant_(m.bias, 0)
Функция потерь
Она используется для расчета ошибки между реальными и полученными ответами. Наша главная цель – сделать эту ошибку меньше, насколько это возможно. Таким образом, функция потерь эффективно приближает обучение нейронной сети к этой цели.
Теперь мы инициализируем критерий и параметры функции потерь, размер batch-а и лейблы:
def real_loss() – реальная потеря.
def fake_loss() – фейковая потеря. Необходима для работы генератора.
В каждой из них мы инициализируем критерий (criterion) и параметры функции потерь, размер batch-а (batch_size) и лейблы (labels).
Тренировка модели
def print_tensor_images() – функция для отображения изображений: даем тензор, получаем картинку.
def train() – функция будущей тренировки с необходимыми гиперпараметрами для генератора и дискриминатора.
И наконец, тренируем саму модель!
Вводим общепринятые числа для всех гиперпараметров.
z_dim = 100
beta_1 = 0.5
beta_2 = 0.999
lr = 0.0002
n_epochs = 100
batch_size = 128
image_size = 64
Нам нужно максимально сбалансировать генератор и дискриминатор. Для лучшего результата добавим Adam-оптимизацию отдельно для каждого из элементов.
Инициализируем как generator, так и discriminator, после чего настроим Adam-оптимизацию с помощью g_optimizer и d_optimizer соответственно.
Начинаем тренировку! Вводим те параметры, которые указаны выше.
n_epochs = 100
train(необходимые параметры)
Мы видим, что дискриминатор несколько превосходит генератор, особенно на начальном этапе, потому что его работа проще. Сбалансировать эти две модели в стандартном GAN очень сложно, но то, что мы сделали ранее, имеет значение: иначе разрыв между двумя элементами внутри модели мог быть гораздо больше.
Сохраняем предобученную модель для того, чтобы использовать её для генерации новых изображений.
def save_model(generator,file_name):
generator = generator.to('cuda')
torch.save(generator.state_dict(),"cryptopunks_generator.pth")
save_model(generator, "kaggle")
Генерируем новых криптопанков
generator.to(device)
generator.eval()
sample_size=8
for i in range(8):
fixed_z = Generator.get_noise(n_samples=sample_size,
z_dim=z_dim,
device=device)
sample_image = generator(fixed_z)
print_tensor_images(sample_image)

Готово! Написанная нами нейросеть теперь генерирует изображения криптопанков. Мы проделали большую работу.
Основная цель этой статьи – предоставить вам базовое понимание пайплайна, с помощью которого мы строим нейросеть, генерирующую различные изображения. В данном случае в качестве примера мы взяли популярную тему NFT-токенов CryptoPunks.
Пайплайн включает в себя:
- Обзор данных для понимания того, какая нейросеть лучше всего подойдет (в нашем случае – GAN, генеративно-состязательная)
- Понимание интуиции, которая стоит за выбранной нейросетью. У нас это «соревнование» генератора и дискриминатора, которые необходимо написать.
- Определение правильных параметров для модели, ее тренировка и сохранение.
- Генерация новых изображений на основе натренированной модели.
Исходя из этого, вы можете усовершенствовать описанное выше базовое решение. Например, поэкспериментировать с другими параметрами перед тренировкой, или использовать другой способ оптимизации. Может быть, даже попробовать взять другую нейросеть для достижения лучшего результата.
Бескрайнее поле Глубокого Обучения (Deep Learning) – это целое искусство, освоить которое вы сможете, комбинируя самые смелые подходы с разнообразными техниками.
Комментарии