

Текст статьи представляет собой незначительно сокращенный перевод публикации Ренато Кандидо Generative Adversarial Networks: Build Your First Models.
Генеративно-состязательные сети (англ. Generative adversarial networks, сокр. GAN) – нейронные сети, которые умеют генерировать изображения, музыку, речь и тексты, похожие на те, что делают люди. GAN стали активной темой исследований последних лет. Директор лаборатории искусственного интеллекта Facebook Ян Лекун назвал состязательное обучение «самой интересной идеей в области машинного обучения за последние 10 лет». Ниже мы изучим, как работают GAN и создадим две модели с помощью фреймворка глубокого обучения PyTorch.
Что такое генеративно-состязательная нейросеть?
Генеративно-состязательная нейросеть (англ. Generative adversarial network, сокращённо GAN) – это модель машинного обучения, умеющая имитировать заданное распределение данных. Впервые модель была предложена в статье NeurIPS 2014 г. экспертом в глубоком обучении Яном Гудфеллоу и его коллегами.
GAN состоят из двух нейронных сетей, одна из которых обучена генерировать данные, а другая – отличать смоделированные данные от реальных (отсюда и «состязательный» характер модели). Генеративно-состязательные нейросети показывают впечатляющие результаты в отношении генерации изображений и видео:
- перенос стилей (CycleGAN) – преобразование одного изображения в соответствии со стилем других изображений (например, картин известного художника);
- генерация человеческих лиц (StyleGAN), реалистичные примеры доступны на сайте This Person Does Not Exist.
GAN и другие структуры, генерирующие данные, называют генеративными моделями в противовес более широко изученным дискриминативным моделям. Прежде чем погрузиться в GAN, посмотрим на различия между двумя типами моделей.
Сравнение дискриминативных и генеративных моделей машинного обучения
Дискриминативные модели используются для большинства задач «обучения с учителем» на классификацию или регрессию. В качестве примера проблемы классификации предположим, что нужно обучить модель распознавания изображений рукописных цифр. Для этого мы можем использовать маркированный набор данных, содержащий фотографии рукописных цифр, которым соотнесены сами цифры.
Обучение сводится к настройке параметров модели с помощью специального алгоритма, минимизирующего функцию потерь. Функция потерь – критерий расхождения между истинным значением оцениваемого параметра и его ожиданием. После фазы обучения мы можем использовать модель для классификации нового (ранее не рассматриваемого) изображения рукописной цифры, сопоставив входному изображению наиболее вероятную цифру.
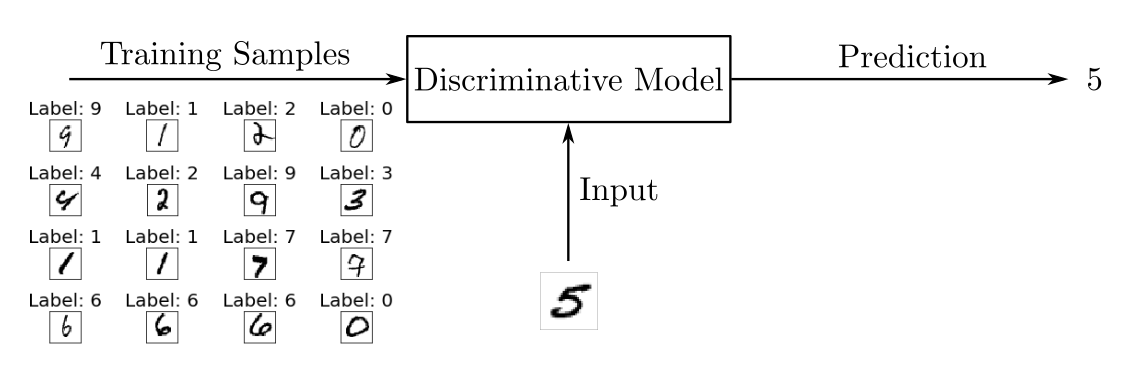
Дискриминативная модель использует обучающие данные для нахождения границ между классами. Найденные границы используются, чтобы различить новые входные данные и предсказать их класс. В математическом отношении дискриминативные модели изучают условную вероятность P(y|x) наблюдения y при заданном входе x.
Дискриминативные модели – это не только нейронные сети, но и логистическая регрессия, и метод опорных векторов (SVM).
В то время как дискриминативные модели используются для контролируемого обучения, генеративные модели обычно используют неразмеченный набор данных, то есть могут рассматриваться как форма обучения без учителя. Так, используя набор данных из рукописных цифр, можно обучить генеративную модель для генерации новых изображений.
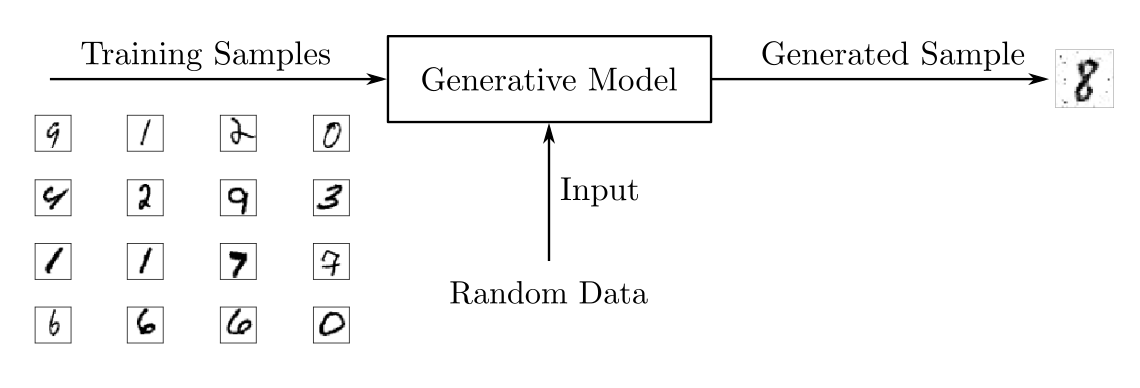
В отличие от дискриминативных моделей, генеративные модели изучают свойства функции вероятности P(x) входных данных 𝑥x. В результате они порождают не предсказание, а новый объект со свойствами, родственными обучающему набору данных.
Помимо GAN существуют другие генеративные архитектуры:
- Машина Больцмана
- Автокодировщик
- Скрытая марковская модель
- Модели, предсказывающие следующее слово в последовательности, например, GPT-2
В последнее время GAN привлекли большое внимание благодаря впечатляющим результатам в генерации визуального контента. Остановимся на устройстве генеративно-состязательных сетей подробнее.
Архитектура генеративно-состязательных нейросетей
Генеративно-состязательная сеть, как мы уже поняли, – это не одна сеть, а две: генератор и дискриминатор. Роль генератора – сгенерировать на основе реальной выборки датасет, напоминающий реальные данные. Дискриминатор обучен оценивать вероятность того, что образец получен из реальных данных, а не предоставлен генератором. Две нейросети играют в кошки-мышки: генератор пытается обмануть дискриминатор, а дискриминатор старается лучше идентифицировать сгенерированные образцы.
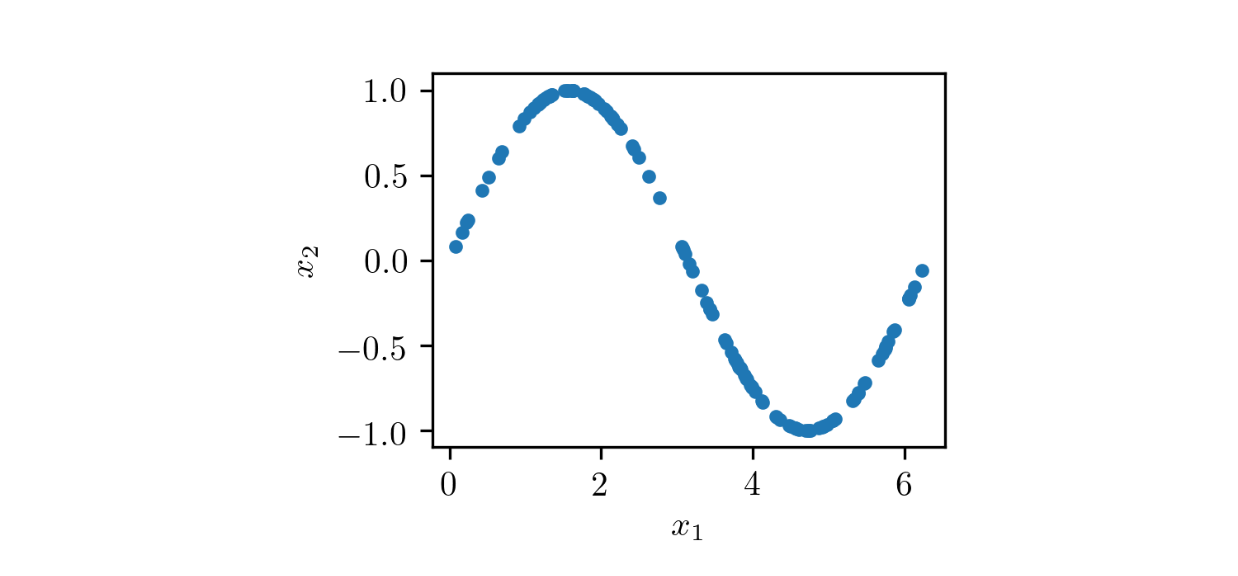
Чтобы понять, как работает обучение GAN, рассмотрим игрушечный пример с набором данных, состоящим из двумерных выборок (x1, x2), с x1 в интервале от 0 до 2π и x2=sin(x1).
Общая структура GAN для генерации пар (x̃1, x̃2), напоминающих точки из набора данных, показана на следующем рисунке.
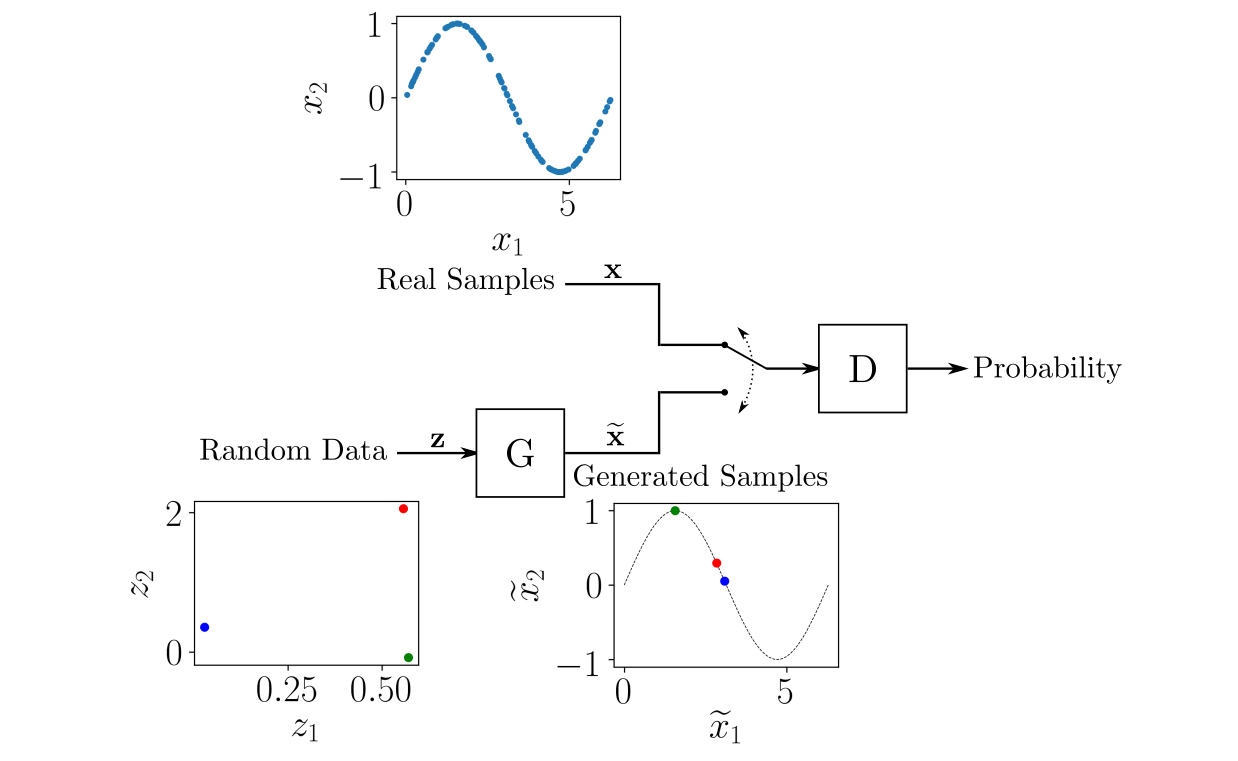
Генератор G получает на вход пары случайных чисел (z1, z2), преобразуя их так, чтобы они напоминали примеры из реальной выборки. Структура нейронной сети G может быть любой, например, многослойный персептрон или сверточная нейронная сеть.
На вход дискриминатора D попеременно поступают образцы из обучающего набора данных и смоделированные образцы, предоставленные генератором G. Роль дискриминатора заключается в оценке вероятности того, что входные данные принадлежат реальному набору данных. То есть обучение выполняется таким образом, чтобы D выдавал 1, получая реальный образец, и 0 для сгенерированного образца.
Как и в случае с генератором, можно выбрать любую структуру нейронной сети D с учетом размеров входных и выходных данных. В рассматриваемом примере вход является двумерным, а выходные данные – скаляром в диапазоне от 0 до 1.
В математическом плане процесс обучения GAN заключается в минимаксной игре двух игроков, в которой D адаптирован для минимизации ошибки различия реального и сгенерированного образца, а G адаптирован на максимизацию вероятности того, что D допустит ошибку.
На каждом этапе обучения происходит обновление параметров моделей D и G. Чтобы обучить D, на каждой итерации мы помечаем выборку реальных образцов единицами, а выборку сгенерированных образцов, созданных G – нулями. Таким образом, для обновления параметров D, как показано на схеме, можно использовать обычный подход обучения с учителем.
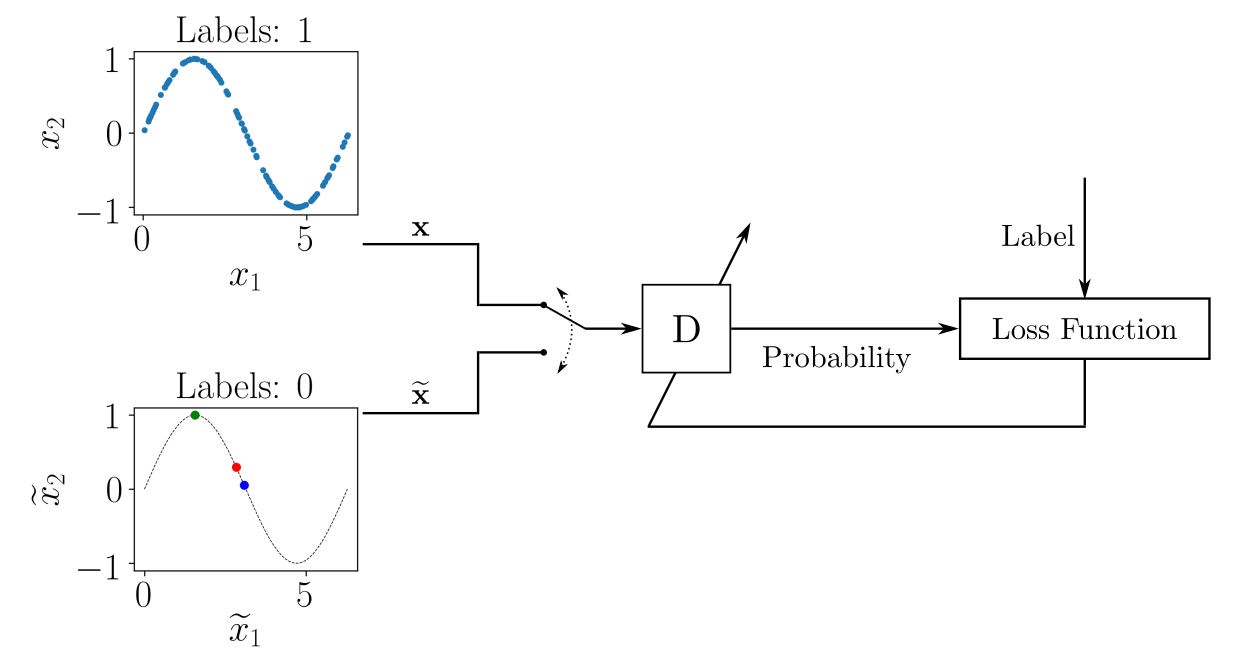
Для каждой партии обучающих данных, содержащих размеченные реальные и сгенерированные образцы, мы обновляем набор параметров модели D, минимизируя функцию потерь. После того как параметры D обновлены, мы обучаем G генерировать более качественные образцы. Набор параметров D «замораживается» на время обучения генератора.
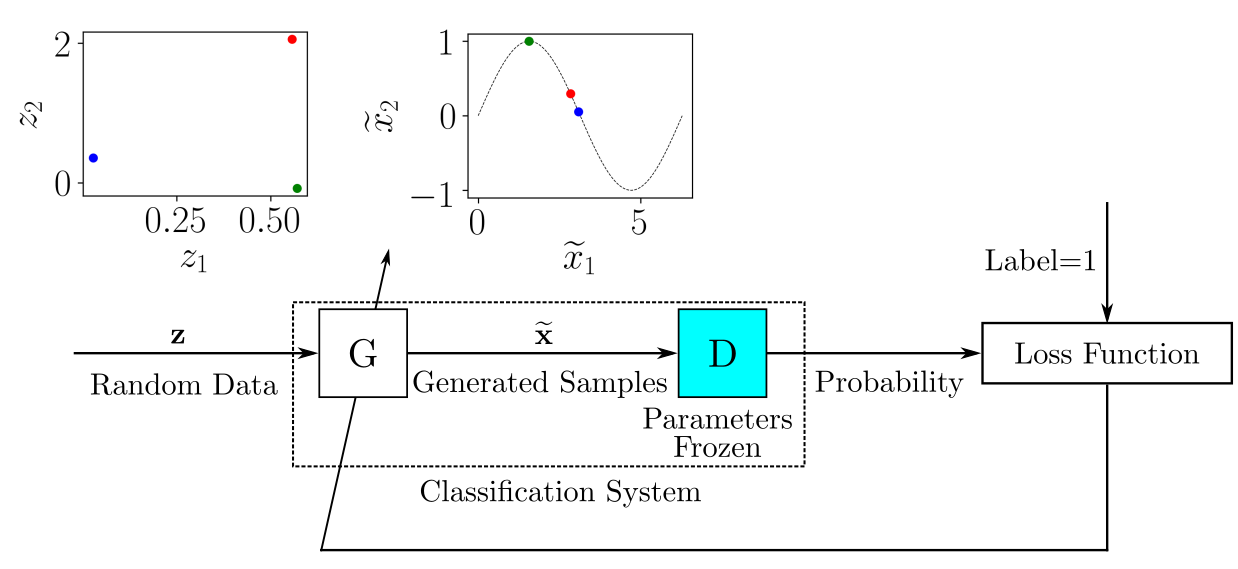
Когда G начинает генерировать образцы настолько хорошо, что D «обманывается», выходная вероятность устремляется к единице – D считает, что все образцы принадлежат к оригинальной выборке.
Теперь, когда мы знаем, как работает GAN, мы готовы реализовать собственный вариант нейросети, используя PyTorch.
Ваша первая генеративно-состязательная нейросеть
В качестве первого эксперимента с генеративно-состязательными сетями реализуем описаный выше пример с гармонической функцией. Для работы с примером будем использовать популярную библиотеку PyTorch, которую можно установить с помощью инструкции. Если вы серьезно заинтересовались Data Science, возможно, вы уже использовали дистрибутив Anaconda и систему управления пакетами и средами conda. Заметим, что среда облегчает процесс установки.
Устанавливаея PyTorch с помощью conda, вначале создайте окружение и активируйте его:
$ conda create --name gan
$ conda activate gan
Здесь создается окружение conda с именем gan. Внутри созданной среды можно установить необходимые пакеты:
$ conda install -c pytorch pytorch=1.4.0
$ conda install matplotlib jupyter
Поскольку PyTorch является активно развивающейся средой, API в новых версиях может измениться. Примеры кода проверены для версии 1.4.0.
Для работы с графиками мы будем использовать matplotlib.
При использовании Jupyter Notebook необходимо зарегистрировать окружение conda gan, чтобы было можно создавать блокноты, используя это окружение в качестве кернела. Для этого в активированной среде gan выполняем следующую команду:
$ python -m ipykernel install --user --name gan
Начнём с импорта необходимых библиотек:
import torch
from torch import nn
import math
import matplotlib.pyplot as plt
Здесь мы импортируем библиотеку PyTorch (torch). Из библиотеки отдельно импортируем компонент nn для более компактного обращения. Встроенная библиотека math нужна лишь для получения значения константы pi, а упомянутый выше инструмент matplotlib – для построения зависимостей.
Хорошей практикой является временное закрепление генератора случайных чисел так, чтобы эксперимент можно было воспроизвести на другой машине. Чтобы сделать это в PyTorch, запустим следующий код:
torch.manual_seed(111)
Число 111 мы используем для инициализации генератора случайных чисел. Генератор нам понадобится для задания начальных весов нейронной сети. Несмотря на случайный характер эксперимента, его течение будет воспроизводимо.
Подготовка данных для обучения GAN
Обучающая выборка состоит из пар чисел (x1, x2) – таких, что x2 соответствует значению синуса x1 для x1 в интервале от 0 до 2π. Данные для обучения можно получить следующим образом:
train_data_length = 1024
train_data = torch.zeros((train_data_length, 2))
train_data[:, 0] = 2 * math.pi * torch.rand(train_data_length)
train_data[:, 1] = torch.sin(train_data[:, 0])
train_labels = torch.zeros(train_data_length)
train_set = [
(train_data[i], train_labels[i]) for i in range(train_data_length)]
Здесь мы составляем набор данных для обучения, состоящий из 1024 пар (x1, x2). Затем инициализируем нулями train_data – матрицу из 1024 строк и 2 столбцов.
Первый столбец train_data заполняем случайными значениями в интервале от 0 до 2π. Вычисляем значения второго столбца, как синус от первого.
Затем нам формально потребуется массив меток train_labels, который мы передаем загрузчику данных PyTorch. Поскольку GAN реализует метод обучения без учителя, метки могут быть любыми.
Наконец, мы создаем из train_data и train_labels список кортежей train_set.
Отобразим данные для обучения, нанеся на график каждую точку (x1, x2):
plt.plot(train_data[:, 0], train_data[:, 1], ".")
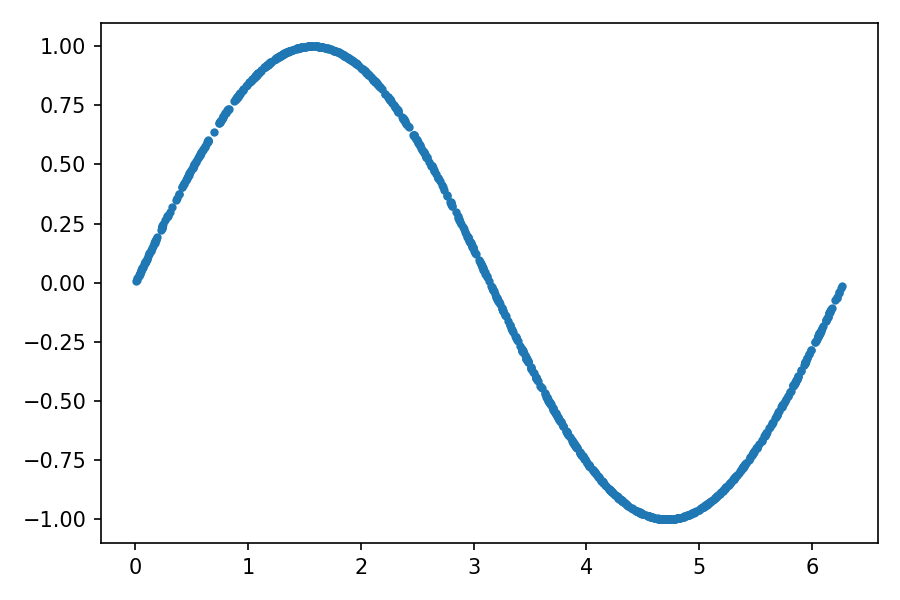
Создадим загрузчик данных с именем train_loader, который будет перетасовывать данные из train_set, возвращая пакеты по 32 образца (batch_size), используемые для обучения нейросети:
batch_size = 32
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size, shuffle=True)
Данные подготовлены, теперь нужно создать нейронные сети дискриминатора и генератора GAN.
Реализация дискриминатора GAN
В PyTorch модели нейронной сети представлены классами, которые наследуются от класса nn.Module. Если вы плохо знакомы с ООП, для понимания происходящего будет достаточно статьи «Введение в объектно-ориентированное программирование (ООП) на Python».
Дискриминатор – это модель с двумерным входом и одномерным выходом. Он получает выборку из реальных данных или от генератора и предоставляет вероятность того, что выборка относится к реальным обучающим данным. Код ниже показывает, как создать класс дискриминатора.
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(2, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(128, 64),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(64, 1),
nn.Sigmoid())
def forward(self, x):
output = self.model(x)
return output
Для построения модели нейронной сети используется стандартный метод классов __init__() . Внутри этого метода мы сначала вызываем super().__init__() для запуска соответствующего метода __init__() наследуемого класса nn.Module. В качестве архитектуры нейросети используется многослойный перцептрон. Его структура послойно задается с помощью nn.Sequential(). Модель имеет следующие характеристики:
- двумерный вход;
- первый скрытый слой состоит из 256 нейронов и имеет функцию активации ReLU;
- в последующих слоях происходит уменьшение числа нейронов до 128 и 64. Вывод имеет сигмоидальную функцию активации, характерную для представления вероятности (
Sigmoid); - чтобы избежать переобучения, после первого, второго и третьего скрытых слоев, делается дропаут части нейронов (
Dropout).
Для удобства вывода в классе также создан метод forward(). Здесь x соответствует входу модели. В этой реализации выходные данные получаются путем подачи входных данных x в определенную нами модель без предобработки.
После объявления класса дискриминатора создаем его экземпляр:
discriminator = Discriminator()
Реализация генератора GAN
В генеративно-состязательных сетях генератор – это модель, которая берет в качестве входных данных некоторую выборку из пространства скрытых переменных, напоминающих данные в обучающем наборе. В нашем случае это модель с двумерным вводом, которая будет получать случайные точки (z1, z2), и двумерный вывод, выдающий точки (x̃1, x̃2), похожие на точки из обучающих данных.
Реализация похожа на то, что мы написали для дискриминатора. Сначала нужно создать класс Generator, наследуемый от nn.Module, затем определить архитектуру нейронной сети, и, наконец, создать экземпляр объекта Generator:
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(2, 16),
nn.ReLU(),
nn.Linear(16, 32),
nn.ReLU(),
nn.Linear(32, 2))
def forward(self, x):
output = self.model(x)
return output
generator = Generator()
Генератор включает два скрытых слоя с 16 и 32 нейронами с функцией активацией ReLU, а на выходе слой с двумя нейронами с линейной функцией активации. Таким образом, выходные данные будут состоять из двух элементов, имеющих значение в диапазоне от −∞ до +∞, которое будет представлять (x̃1, x̃2). То есть исходно мы не накладываем на генератор никакие ограничения – он должен «всему научиться сам».
Теперь, когда мы определили модели для дискриминатора и генератора, мы готовы начать обучение.
Обучение моделей GAN
Перед обучением моделей необходимо настроить параметры, которые будут использоваться в процессе обучения:
lr = 0.001
num_epochs = 300
loss_function = nn.BCELoss()
Что здесь происходит:
- Задаем скорость обучения
lr(learning rate), которую мы будем использовать для адаптации весов сети. - Задаем количество эпох
num_epochs, которое определяет, сколько повторений процесса обучения будет выполнено с использованием всего датасета. - Переменной
loss_functionмы назначаем функцию логистической функции потерь (бинарной перекрестной энтропии)BCELoss(). Это та функция потерь, которую мы будем использовать для обучения моделей. Она подходит как для обучения дискриминатора (его задача сводится к бинарной классификации), так и для генератора, так как он подает свой вывод на вход дискриминатора.
Правила обновления весов (обучения модели) в PyTorch реализованы в модуле torch.optim. Мы будем использовать для обучения моделей дискриминатора и генератора алгоритм стохастического градиентного спуска Аdam. Чтобы создать оптимизаторы с помощью torch.optim, запустим следующий код:
optimizer_discriminator = torch.optim.Adam(discriminator.parameters(), lr=lr)
optimizer_generator = torch.optim.Adam(generator.parameters(), lr=lr)
Наконец, необходимо реализовать обучающий цикл, в котором образцы обучающей выборки подаются на вход модели, а их веса обновляются, минимизируя функцию потерь:
for epoch in range(num_epochs):
for n, (real_samples, _) in enumerate(train_loader):
# Данные для обучения дискриминатора
real_samples_labels = torch.ones((batch_size, 1))
latent_space_samples = torch.randn((batch_size, 2))
generated_samples = generator(latent_space_samples)
generated_samples_labels = torch.zeros((batch_size, 1))
all_samples = torch.cat((real_samples, generated_samples))
all_samples_labels = torch.cat(
(real_samples_labels, generated_samples_labels))
# Обучение дискриминатора
discriminator.zero_grad()
output_discriminator = discriminator(all_samples)
loss_discriminator = loss_function(
output_discriminator, all_samples_labels)
loss_discriminator.backward()
optimizer_discriminator.step()
# Данные для обучения генератора
latent_space_samples = torch.randn((batch_size, 2))
# Обучение генератора
generator.zero_grad()
generated_samples = generator(latent_space_samples)
output_discriminator_generated = discriminator(generated_samples)
loss_generator = loss_function(
output_discriminator_generated, real_samples_labels)
loss_generator.backward()
optimizer_generator.step()
# Выводим значения функций потерь
if epoch % 10 == 0 and n == batch_size - 1:
print(f"Epoch: {epoch} Loss D.: {loss_discriminator}")
print(f"Epoch: {epoch} Loss G.: {loss_generator}")
Здесь на каждой итерации обучения мы обновляем параметры дискриминатора и генератора. Как это обычно делается для нейронных сетей, учебный процесс состоит из двух вложенных циклов: внешний – для эпох обучения, а внутренний – для пакетов внутри каждой эпохи. Во внутреннем цикле всё начинается с подготовки данных для обучения дискриминатора:
- Получаем реальные образцы текущей партии из загрузчика данных и назначаем их переменной
real_samples. Обратите внимание, что первое измерение в размерности массива имеет количество элементов, равноеbatch_size. Это стандартный способ организации данных в PyTorch, где каждая строка тензора представляет один образец из пакета. - Используем
torch.ones()для создания меток со значением 1 для реальных образцов и назначаем метки переменнойreal_samples_labels. - Генерируем образцы, сохраняя случайные данные в
latent_space_samples, которые затем передаем в генератор для полученияgenerate_samples. Для меток сгенерированных образцов мы используем нулиtorch.zeros(), которые сохраняем вgenerate_samples_labels. - Остается объединить реальные и сгенерированные образцы и метки и сохранить соответственно в
all_samplesиall_samples_labels.
В следующем блоке мы обучаем дискриминатор:
- В PyTorch важно на каждом шаге обучения очищать значения градиентов. Мы делаем это с помощью метода
zero_grad(). - Вычисляем выходные данные дискриминатора, используя обучающие данные
all_samples. - Вычисляем значение функции потерь, используя выходные данные в
output_discriminatorи меткиall_samples_labels. - Вычисляем градиенты для обновления весов с помощью
loss_discriminator.backward(). - Находим обновленные веса дискриминатора, вызывая
optimizer_discriminator.step(). - Подготавливаем данные для обучения генератора. Рандомизированные данные хранятся в
latent_space_samples, количеством строк равноbatch_size. Используем два столбца, чтобы данные соответствовали двумерным данным на входе генератора.
Тренируем генератор:
- Очищаем градиенты с помощью метода
zero_grad(). - Передаем генератору
latent_space_samplesи сохраняем его выходные данные вgenerate_samples. - Передаем выходные данные генератора в дискриминатор и сохраняем его выходные данные в
output_discriminator_generated, который будет использоваться в качестве выходных данных всей модели. - Вычисляем функцию потерь, используя выходные данные системы классификации, сохраненные в
output_discriminator_generatedи меткиreal_samples_labels, равные 1. - Рассчитываем градиенты и обновляем веса генератора. Помните, что когда мы обучаем генератор, мы сохраняем веса дискриминатора в замороженном состоянии.
Наконец, в последних строчках цикла происходит вывод значения функций потерь дискриминатора и генератора в конце каждой десятой эпохи.
Проверка образцов, сгенерированных GAN
Генеративно-состязательные сети предназначены для генерации данных. Таким образом, после того как процесс обучения завершен, мы можем вызвать генератор для получения новых данных:
latent_space_samples = torch.randn(100, 2)
generated_samples = generator(latent_space_samples)
Построим сгенерированные данные и проверим, насколько они похожи на обучающие данные. Перед построением графика для сгенерированных образцов необходимо применить метод detach(), чтобы получить необходимые данные из вычислительного графа PyTorch:
generated_samples = generated_samples.detach()
plt.plot(generated_samples[:, 0], generated_samples[:, 1], ".")
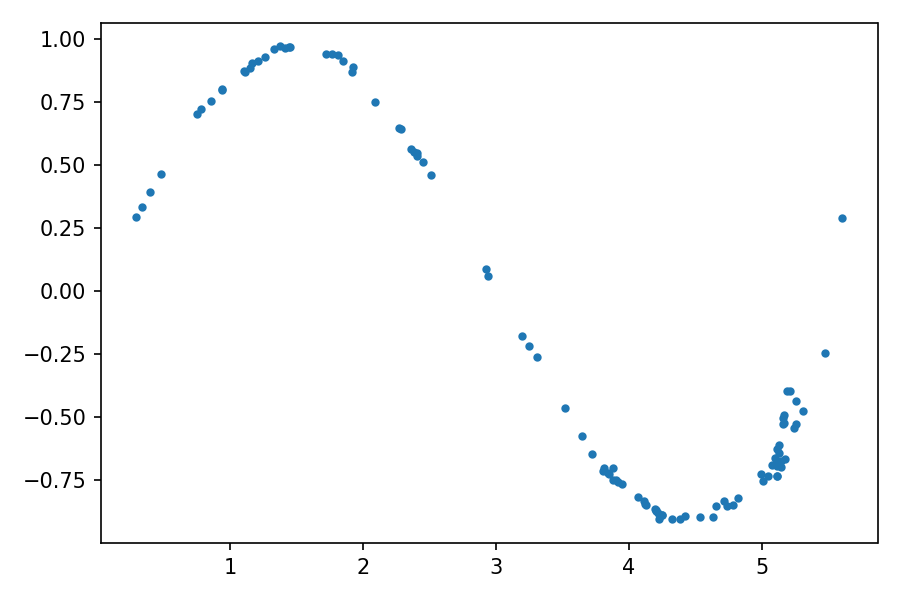
Распределение сгенерированных данных очень напоминает реальные данные – исходный синус. Анимацию эволюции обучения можно посмотреть по ссылке.
В начале процесса обучения распределение сгенерированных данных сильно отличается от реальных данных. Но по мере обучения генератор изучает реальное распределение данных, как бы подстраиваясь под него.
Теперь, когда мы реализовали первую модель генеративно-состязательной сети, мы можем перейти к более практичному примеру с генерацией изображений.
Генератор рукописных цифр с GAN
В следующем примере мы воспользуемся GAN для генерации изображений рукописных цифр. Для этого мы обучим модели, используя набор данных MNIST, состоящий из рукописных цифр. Этот стандартный набор данных включен в пакет torchvision.
Для начала в активированной среде gan необходимо установить torchvision:
$ conda install -c pytorch torchvision=0.5.0
Опять же, здесь мы указываем конкретную версию torchvision так же, как мы это делали с pytorch, чтобы обеспечить выполнение примеров кода.
Начинаем с импорта необходимых библиотек:
import torchvision
import torchvision.transforms as transforms
torch.manual_seed(111)
Помимо библиотек, которые мы импортировали ранее, нам понадобится torchvision и torchvision.transforms для преобразования информации, хранящейся в файлах изображений.
Поскольку в этом примере обучающий набор включает изображения, модели будут сложнее, обучение будет происходить существенно дольше. При обучении на центральном процессоре (CPU) на одну эпоху будет уходить порядка двух минут. Для получения приемлемого результата понадобится порядка 50 эпох, поэтому общее время обучения при использовании процессора составляет около 100 минут.
Чтобы сократить время обучения, можно использовать графический процессор (GPU).
Чтобы код работал независимо от характеристик компьютера, создадим объект device, который будет указывать либо на центральный процессор, либо (при наличии) на графический процессор:
device = ""
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
Окружение настроено, подготовим датасет для обучения.
Подготовка датасета MNIST
Набор данных MNIST состоит из изображений написанных от руки цифр от 0 до 9. Изображения выполнены в градациях серого и имеют размер 28 × 28 пикселей. Чтобы использовать их с PyTorch, понадобится выполнить некоторые преобразования. Для этого определим функцию transform, используемую при загрузке данных:
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
Функция состоит из двух частей:
transforms.ToTensor()преобразует данные в тензор PyTorch.transforms.Normalize()преобразует диапазон тензорных коэффициентов.
Исходные коэффициенты, заданные функцией transforms.ToTensor(), находятся в диапазоне от 0 до 1. Поскольку изображения имеют черный фон, большинство коэффициентов равны 0.
transforms.Normalize() представляют собой это два кортежа (M₁, ..., Mₙ) и (S₁, ..., Sₙ), где n соответствует количеству каналов в изображении. Картинки в градациях серого, как в наборе данных MNIST, имеют лишь один канал. Для каждого i-го канала изображения transforms.Normalize() вычитает Mᵢ из коэффициентов и делит результат на Sᵢ.Функция transforms.Normalize() изменяет диапазон коэффициентов на [−1,1][−1,1], вычитая 0.5 из исходных коэффициентов и деля результат на 0.5. Преобразование сокращает количество элементов входных выборок, равных 0. Это помогает в обучении моделей.
Теперь можно загрузить обучающие данные, вызвав torchvision.datasets.MNIST:
train_set = torchvision.datasets.MNIST(
root=".", train=True, download=True, transform=transform)
Аргумент download = True гарантирует, что при первом запуске кода набор данных MNIST будет загружен и сохранен в текущем каталоге, как указано в аргументе root.
Мы создали train_set, так что можно создать загрузчик данных, как делали это раньше:
batch_size = 32
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size, shuffle=True)
Для избирательного построения данных воспользуемся matplotlib. В качестве палитры хорошо подходит cmap = gray_r. Цифры будут изображаться черным цветом на белом фоне:
real_samples, mnist_labels = next(iter(train_loader))
for i in range(16):
ax = plt.subplot(4, 4, i + 1)
plt.imshow(real_samples[i].reshape(28, 28), cmap="gray_r")
plt.xticks([])
plt.yticks([])
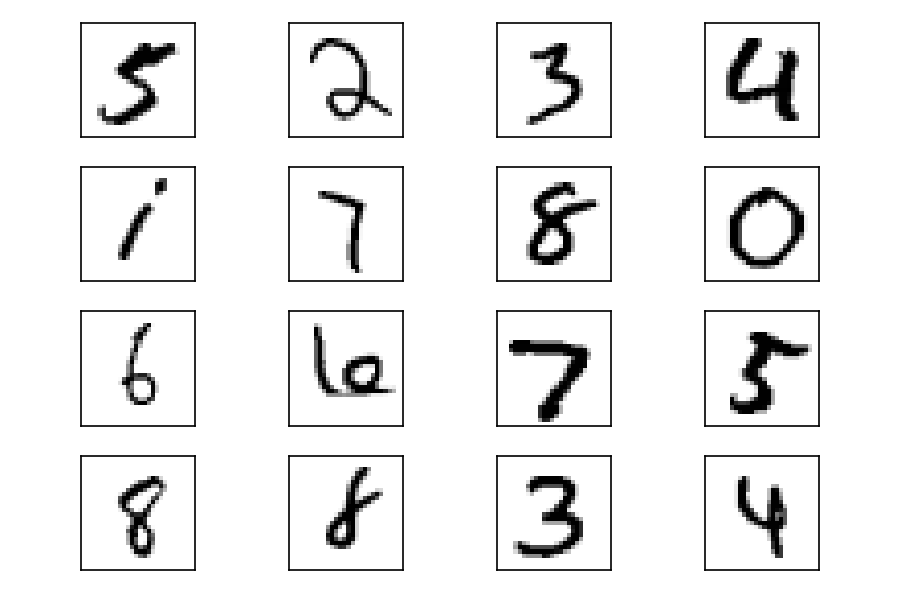
Как видите, в датасете есть цифры с разными почерками. По мере того как GAN изучает распределение данных, она также генерирует цифры с разными стилями рукописного ввода.
Мы подготовили обучающие данные, можно реализовать модели дискриминатора и генератора.
Реализация дискриминатора и генератора
В рассматриваемом случае дискриминатором является нейронная сеть многослойного перцептрона, которая принимает изображение размером 28 × 28 пикселей и находит вероятность того, что изображение принадлежит реальным обучающим данным.
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(784, 1024),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, x):
x = x.view(x.size(0), 784)
output = self.model(x)
return output
Для введения коэффициентов изображения в нейронную сеть перцептрона, необходимо их векторизовать так, чтобы нейронная сеть получала вектор, состоящий из 784 коэффициентов (28 × 28 = 784).
Векторизация происходит в первой строке метода forward() – вызов x.view() преобразует форму входного тензора. Исходная форма тензора 𝑥x – 32 × 1 × 28 × 28, где 32 – размер партии. После преобразования форма 𝑥x становится равной 32 × 784, причем каждая строка представляет коэффициенты изображения обучающего набора.
Чтобы запустить модель дискриминатора с использованием графического процессора, нужно создать его экземпляр и связать с объектом устройства с помощью метода to():
discriminator = Discriminator().to(device=device)
Генератор будет создавать более сложные данные, чем в предыдущем примере. Поэтому необходимо увеличить размеры входных данных, используемых для инициализации. Здесь мы используем 100-мерный вход и выход с 784 коэффициентами. Результат организуется в виде тензора 28 × 28, представляющего изображение.
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 1024),
nn.ReLU(),
nn.Linear(1024, 784),
nn.Tanh(),
)
def forward(self, x):
output = self.model(x)
output = output.view(x.size(0), 1, 28, 28)
return output
generator = Generator().to(device=device)
Выходные коэффициенты должны находиться в интервале от -1 до 1. Поэтому на выходе генератора мы используем гиперболическую функцию активации Tanh(). В последней строке мы создаем экземпляр генератора и связываем его с объектом устройства.
Осталось лишь обучить модели.
Обучение моделей
Для обучения моделей нужно определить параметры обучения и оптимизаторы:
lr = 0.0001
num_epochs = 50
loss_function = nn.BCELoss()
optimizer_discriminator = torch.optim.Adam(discriminator.parameters(), lr=lr)
optimizer_generator = torch.optim.Adam(generator.parameters(), lr=lr)
Мы уменьшаем скорость обучения по сравнению с предыдущим примером. Чтобы сократить время обучения, устанавливаем количество эпох равным 50.
Цикл обучения похож на тот, что мы использовали в предыдущем примере:
for epoch in range(num_epochs):
for n, (real_samples, mnist_labels) in enumerate(train_loader):
# Данные для тренировки дискриминатора
real_samples = real_samples.to(device=device)
real_samples_labels = torch.ones((batch_size, 1)).to(
device=device)
latent_space_samples = torch.randn((batch_size, 100)).to(
device=device)
generated_samples = generator(latent_space_samples)
generated_samples_labels = torch.zeros((batch_size, 1)).to(
device=device)
all_samples = torch.cat((real_samples, generated_samples))
all_samples_labels = torch.cat(
(real_samples_labels, generated_samples_labels))
# Обучение дискриминатора
discriminator.zero_grad()
output_discriminator = discriminator(all_samples)
loss_discriminator = loss_function(
output_discriminator, all_samples_labels)
loss_discriminator.backward()
optimizer_discriminator.step()
# Данные для обучения генератора
latent_space_samples = torch.randn((batch_size, 100)).to(
device=device)
# Обучение генератора
generator.zero_grad()
generated_samples = generator(latent_space_samples)
output_discriminator_generated = discriminator(generated_samples)
loss_generator = loss_function(
output_discriminator_generated, real_samples_labels)
loss_generator.backward()
optimizer_generator.step()
# Показываем loss
if n == batch_size - 1:
print(f"Epoch: {epoch} Loss D.: {loss_discriminator}")
print(f"Epoch: {epoch} Loss G.: {loss_generator}")
Проверка сгенерированных GAN образцов
Сгенерируем несколько образцов «рукописных цифр». Для этого передадим генератору инициирующий набор случайных чисел:
latent_space_samples = torch.randn(batch_size, 100).to(device=device)
generated_samples = generator(latent_space_samples)
Чтобы построить сгенерированные выборки, нужно переместить данные обратно в центральный процессор, если их обработка происходила на графическом процессоре. Для этого достаточно вызвать метод cpu(). Как и раньше, перед построением данных необходимо вызвать метод detach():
generated_samples = generated_samples.cpu().detach()
for i in range(16):
ax = plt.subplot(4, 4, i + 1)
plt.imshow(generated_samples[i].reshape(28, 28), cmap="gray_r")
plt.xticks([])
plt.yticks([])
На выходе должны получиться цифры, напоминающие обучающие данные.

После пятидесяти эпох обучения есть несколько цифр, будто бы написанных рукой человека. Результаты можно улучшить, проводя более длительное обучение (с бо́льшим количеством эпох). Как и в предыдущем примере, можно визуализировать эволюцию обучения, используя фиксированный тензор входных данных и подавая его на генератор в конце каждой эпохи (анимация эволюции обучения).
В начале процесса обучения сгенерированные изображения абсолютно случайны. По мере обучения генератор изучает распределение реальных данных, и примерно через двадцать эпох некоторые сгенерированные изображения цифр уже напоминают реальные данные.
Заключение
Поздравляем! Вы узнали, как реализовать собственную генеративно-состязательную нейросеть. Сначала мы построили игрушечный пример, чтобы понять структуру GAN, а затем рассмотрели сеть для генерации изображений по имеющимся примерам данных.
Несмотря на сложность тематики GAN, интегрированные среды машинного обучения, такие как PyTorch, делают реализацию очень легкой.
В этом тексте вы, возможно, встретили множество новых понятий. Если вы серьезно заинтересовались профессией Data Science, хорошим ориентиром будет наша публикация «Как научиться Data Science онлайн: 12 шагов от новичка до профи».
Хочу подтянуть знания по математике, но не знаю, с чего начать. Что делать?
Если базовые концепции языка программирования можно достаточно быстро освоить самостоятельно, то с математикой могут возникнуть сложности. Чтобы помочь освоить математический инструментарий, «Библиотека программиста» совместно с преподавателями ВМК МГУ разработала курс по математике для Data Science, на котором вы:
- подготовитесь к сдаче вступительных экзаменов в Школу анализа данных Яндекса;
- углубитесь в математический анализ, линейную алгебру, комбинаторику, теорию вероятностей и математическую статистику;
- узнаете роль чисел, формул и функций в разработке алгоритмов машинного обучения.
- освоите специальную терминологию и сможете читать статьи по Data Science без постоянных обращений к поисковику.
Курс подойдет как начинающим специалистам, так и действующим программистам и аналитикам, которые хотят повысить свой уровень или перейти в новую область.
Комментарии